Alguns meses atrás, em uma das retrospectivas, decidimos tentar ler juntos.
Nosso formato:
- Escolha um livro.
- Determinamos a parte que precisa ser lida em uma semana. Escolha um pequeno volume.
- Na sexta-feira, discutimos o que lemos.
- Lemos durante o horário não comercial, discutimos durante o horário comercial.
- Depois de terminar o livro, escolhemos em conjunto o seguinte.
O que dá:
- Motivação para ler e ler.
- Desenvolvimento de habilidades (inclusive para o futuro).
- Alinhamento de mentalidade e terminologia em uma equipe.
- O crescimento da confiança.
- Outro motivo para conversar.
Um dos livros recentes que lemos é
Designing Applications-Intensive Data . Sim, esse mesmo livro com um porco. E todo mundo gostou tanto deste livro que decidi revê-lo aqui para que mais pessoas o leiam.
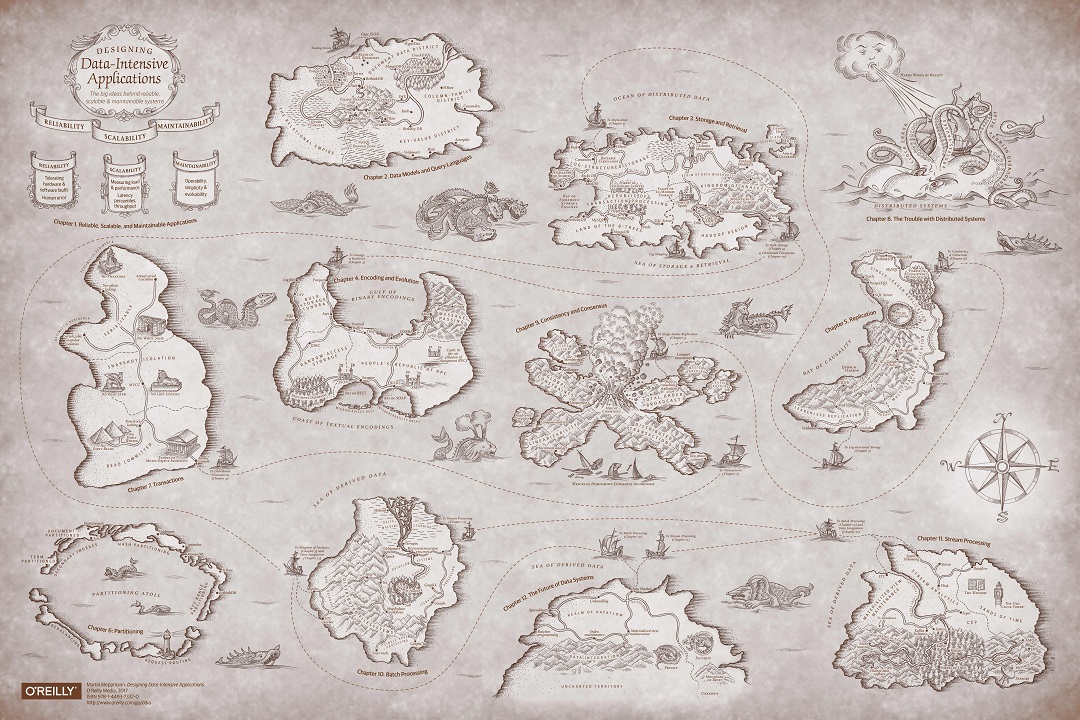 Mapa em qualidade original
Mapa em qualidade originalHá uma tradução deste livro para o russo do Publisher Peter. Mas lemos no original, então não prometo que as traduções dos termos corresponderão. Além disso, deliberadamente não traduzimos parte dos termos.
A parte inicial do livro é dedicada aos conceitos básicos de sistemas de processamento de dados.
O primeiro capítulo indica que propriedades importantes desses sistemas são confiabilidade, escalabilidade e facilidade de manutenção.
O segundo capítulo descreve vários modelos de dados. O DBMS relacional e orientado a documentos, bem como os bancos de dados de colunas e gráficos menos conhecidos, são descritos.
Os primeiros capítulos estão atualizados, estabelecem o escopo do livro. Em muitos lugares abaixo, o autor se refere aos primeiros capítulos. Para ser justo, podemos dizer que o livro está cheio de referências cruzadas.
O que é surpreendente nos primeiros capítulos é o número de fontes (há uma bibliografia após cada capítulo). Links para dezenas de artigos (blogs e científicos) e livros são escrupulosamente organizados em todos os capítulos. O número de fontes para alguns capítulos excede cem.
O terceiro capítulo começa com o código-fonte do armazenamento de valores-chave mais simples:
Até funcionará, muito bom em escrever, mas, é claro, não sem problemas de leitura.
E imediatamente, são oferecidas opções para melhorar o desempenho. Descreve os índices de hash, SSTable, b-tree e LSM-tree. Tudo isso é explicado nos dedos, mas é mostrado como essa ou aquela estrutura é usada nos bancos de dados familiares.
O foco na prática é outra característica do livro. A maioria dos exemplos e receitas é tão prática que me deparei com quase tudo relevante.
O
quarto capítulo descreve a codificação: do JSON e XML regulares ao Protobuf e AVRO. Nem sempre escolhemos o formato conscientemente, geralmente é imposto por uma ou outra tecnologia como um todo. Mas é legal entender como funciona por dentro, quais são os pontos fortes e fracos do formato.
O autor não usou especificamente o termo serialização, pois esse termo tem mais um significado nos bancos de dados.
O conteúdo dos capítulos é muito mais rico que minha breve apresentação. A primeira parte também descreve as diferenças entre OLTP e OLAP, como a pesquisa e a pesquisa de texto completo nos bancos de dados de colunas, REST e intermediários de mensagens são organizadas.
A segunda parte do livro fala sobre sistemas de processamento de dados distribuídos. Quase todos os sistemas modernos que são mais ou menos carregados possuem várias réplicas ou subsistemas (microsserviços).
Quando começamos a praticar a leitura juntos, simplesmente discutimos nossas anotações, lugares interessantes e pensamentos. Em algum momento, percebemos que simplesmente não tínhamos conversas suficientes, depois da discussão tudo é rapidamente esquecido. Então decidimos fortalecer nossa prática e adicionamos um preenchimento de mapa mental. A inovação tinha apenas este livro. A partir da segunda parte, começamos a manter um mapa mental para cada capítulo. Portanto, cada capítulo ainda estará com o nosso mapa mental. Usamos coggle.it
O quinto capítulo descreve a replicação.
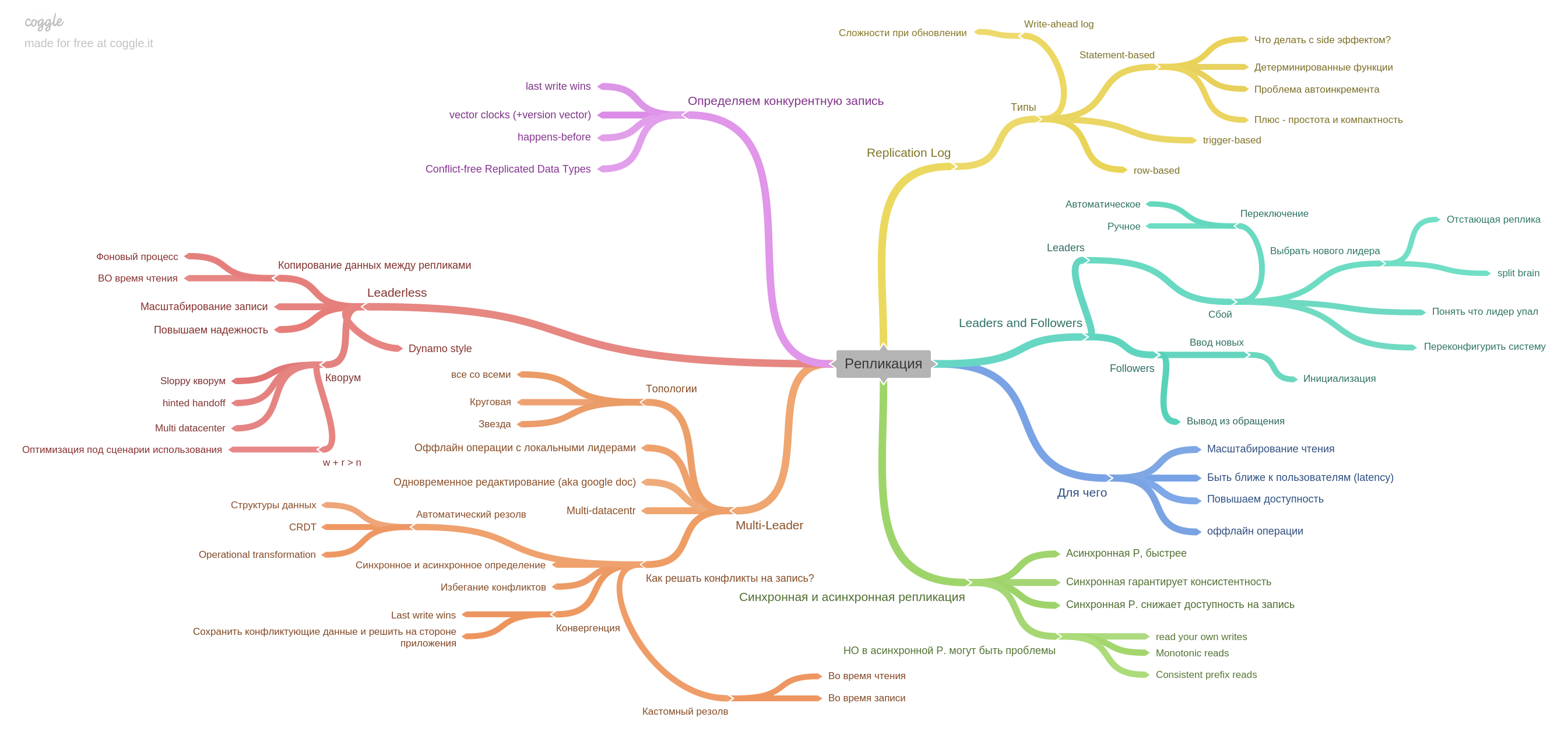
Aqui, todas as informações básicas sobre réplicas são coletadas: registro de mestre único, multimaster, replicação e como viver com um registro competitivo em sistemas sem líder.
O sexto capítulo descreve o particionamento (também conhecido como sharding e vários outros termos).
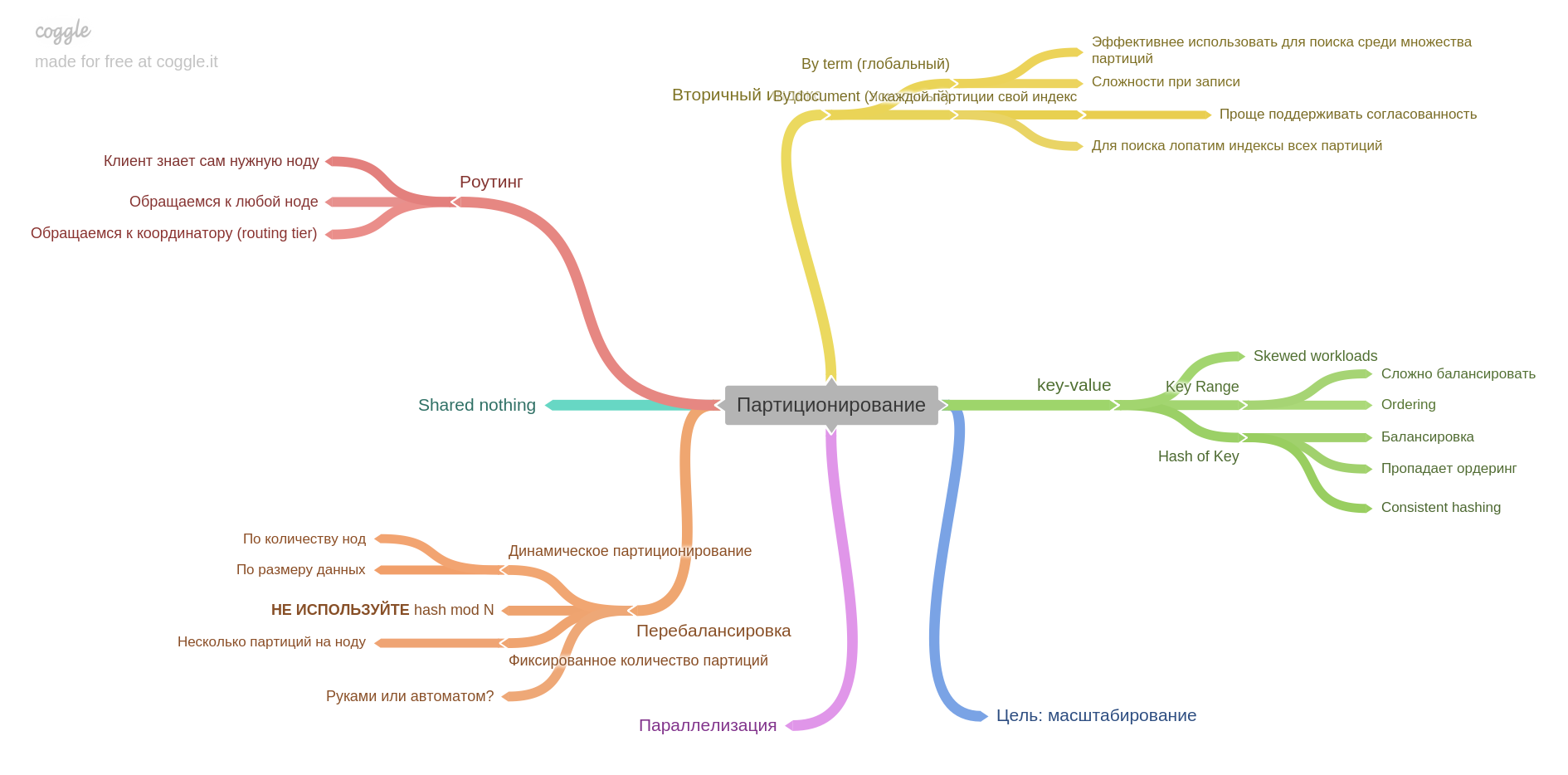
Você aprenderá como dividir dados em shards, quais problemas podem ser resolvidos e quais obter, como criar índices e equilibrar dados.
Sétimo capítulo : transações.
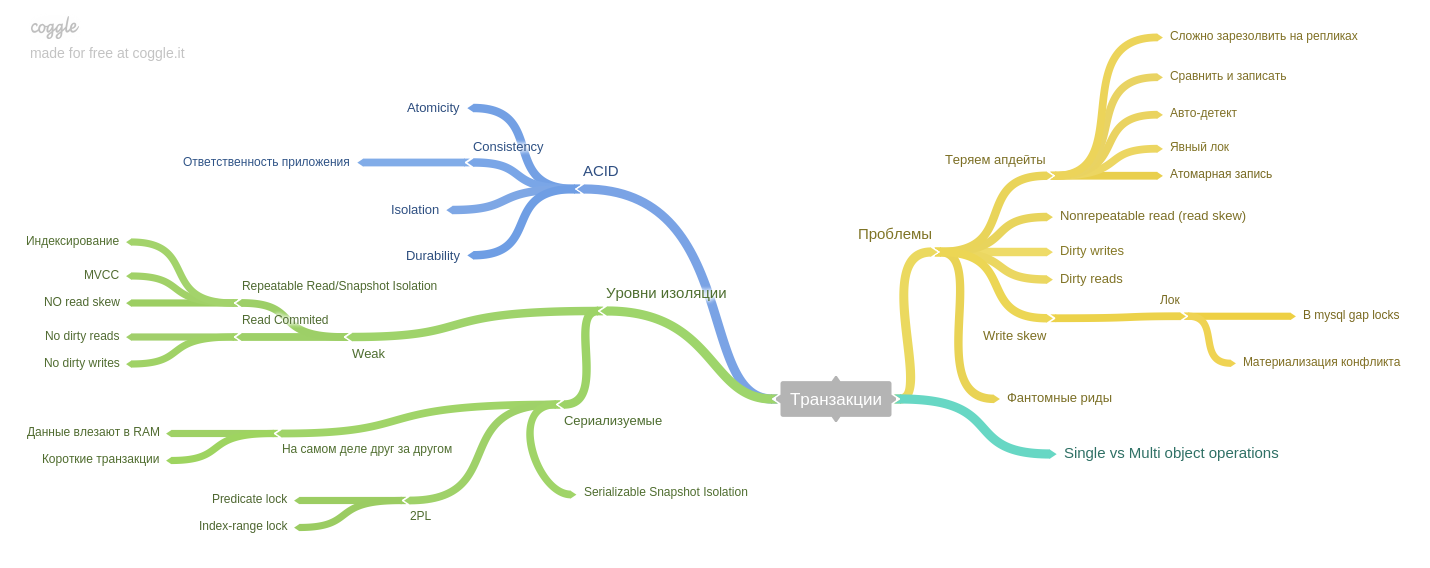
Os fenômenos (inclinação da leitura, inclinação da gravação, leitura fantasma etc.) são descritos e como os níveis de isolamento dos bancos de dados no estilo ACID ajudam a evitar problemas.
O oitavo capítulo: sobre problemas específicos para sistemas distribuídos.
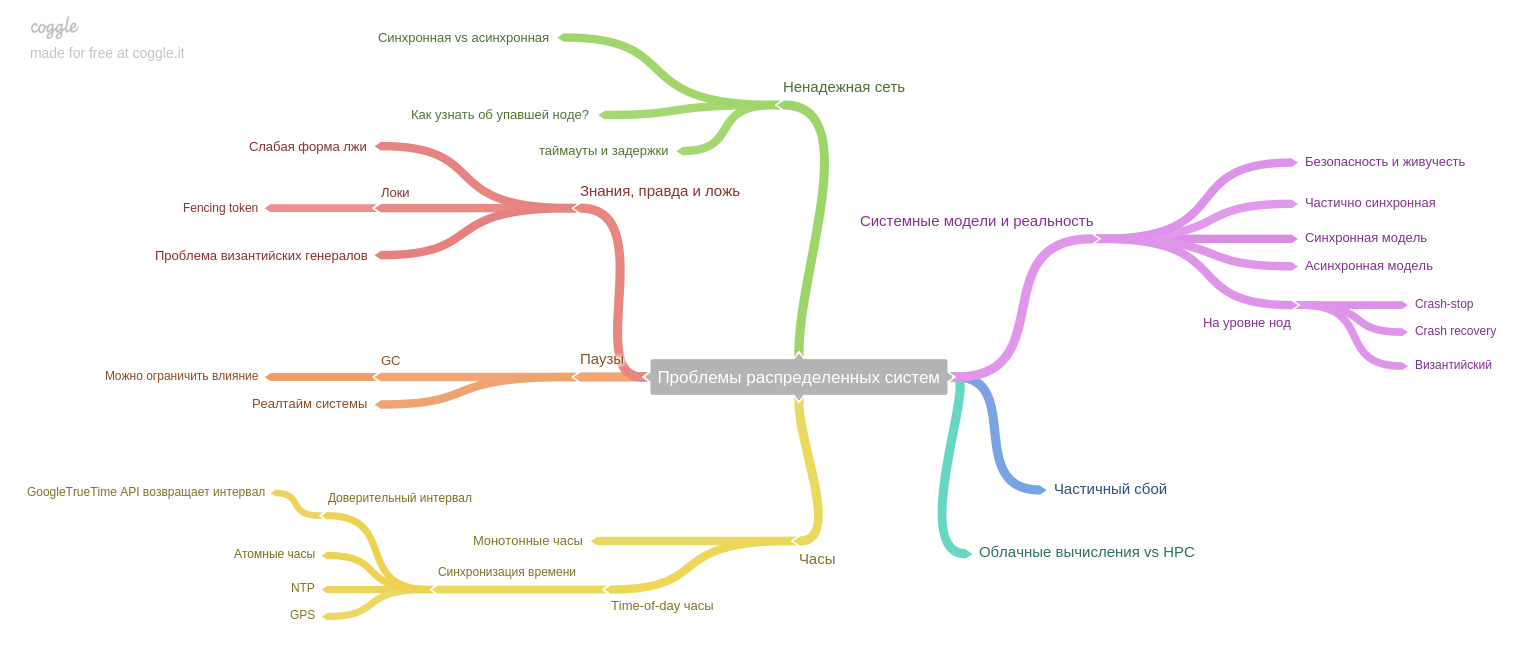
O autor enfatiza uma idéia importante: se anteriormente o sistema funcionava em uma máquina e, em caso de falha, o sistema inteiro parava de funcionar (e aceitava novos dados). Assim, os dados após falhas permaneceram em um estado consistente, mas hoje, na era das réplicas e microsserviços, apenas parte do sistema está sendo desligada. Assim, enfrentamos um novo problema: garantir a consistência dos dados nas condições de falha parcial, problemas persistentes com uma rede não confiável, etc.
O nono capítulo descreve coerência e consenso e introduz um conceito importante: linearizabilidade. Lembro que a cabeça entrou forte e se encaixou na minha cabeça)
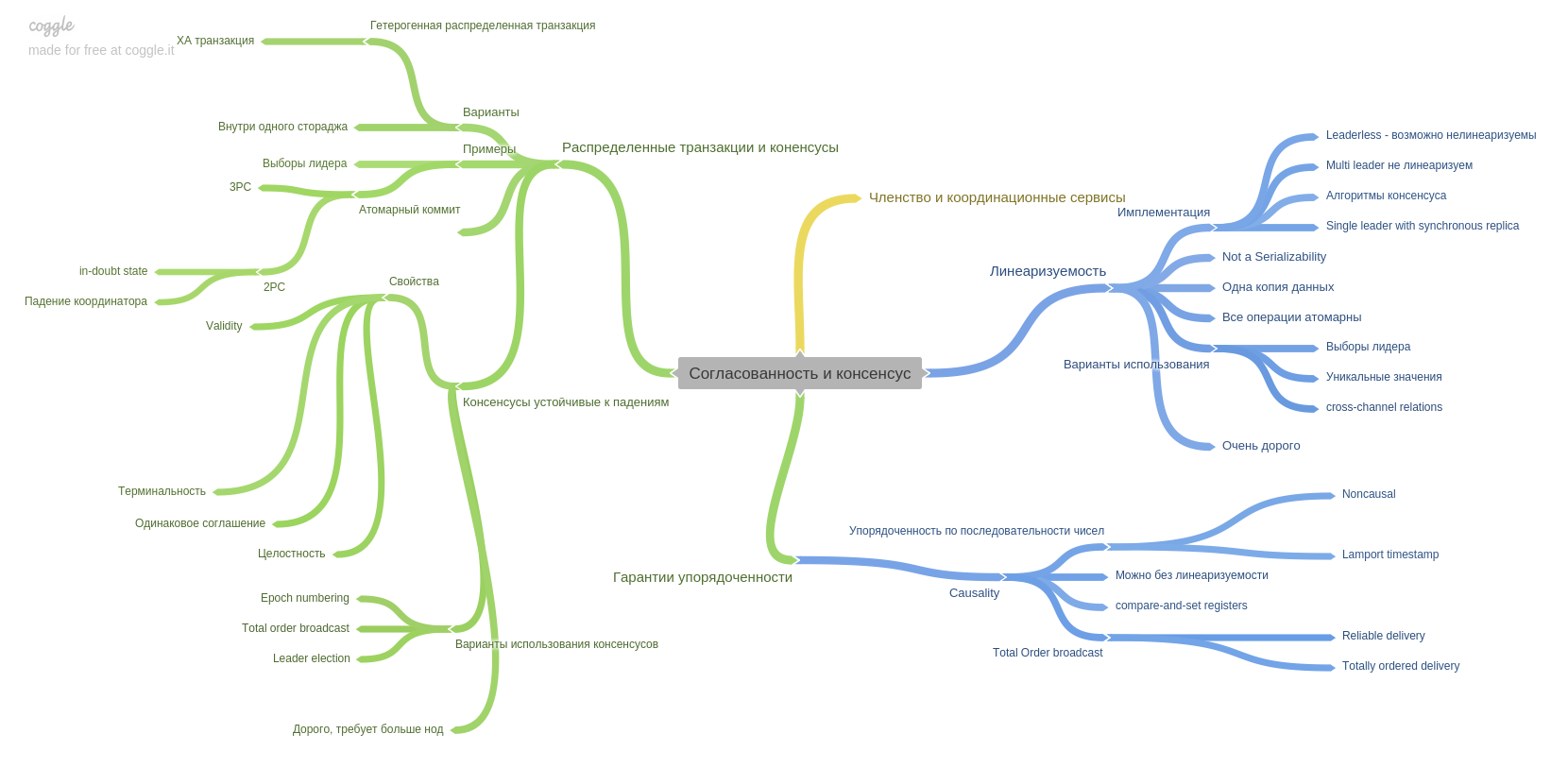
Este capítulo também descreve a técnica de confirmação em duas fases e seus pontos fracos. Também neste capítulo, você lerá sobre garantias de ordem. Como e quais sistemas modernos podem fornecer a você.
A terceira parte do livro é dedicada a dados derivados (não há tradução estabelecida). Como resultado, o autor expressa a ideia de que todos os índices, tabelas e visualizações materializadas são apenas um cache no log. Somente o log contém os dados mais relevantes, todo o resto está atrasado e é usado por conveniência.
O décimo capítulo.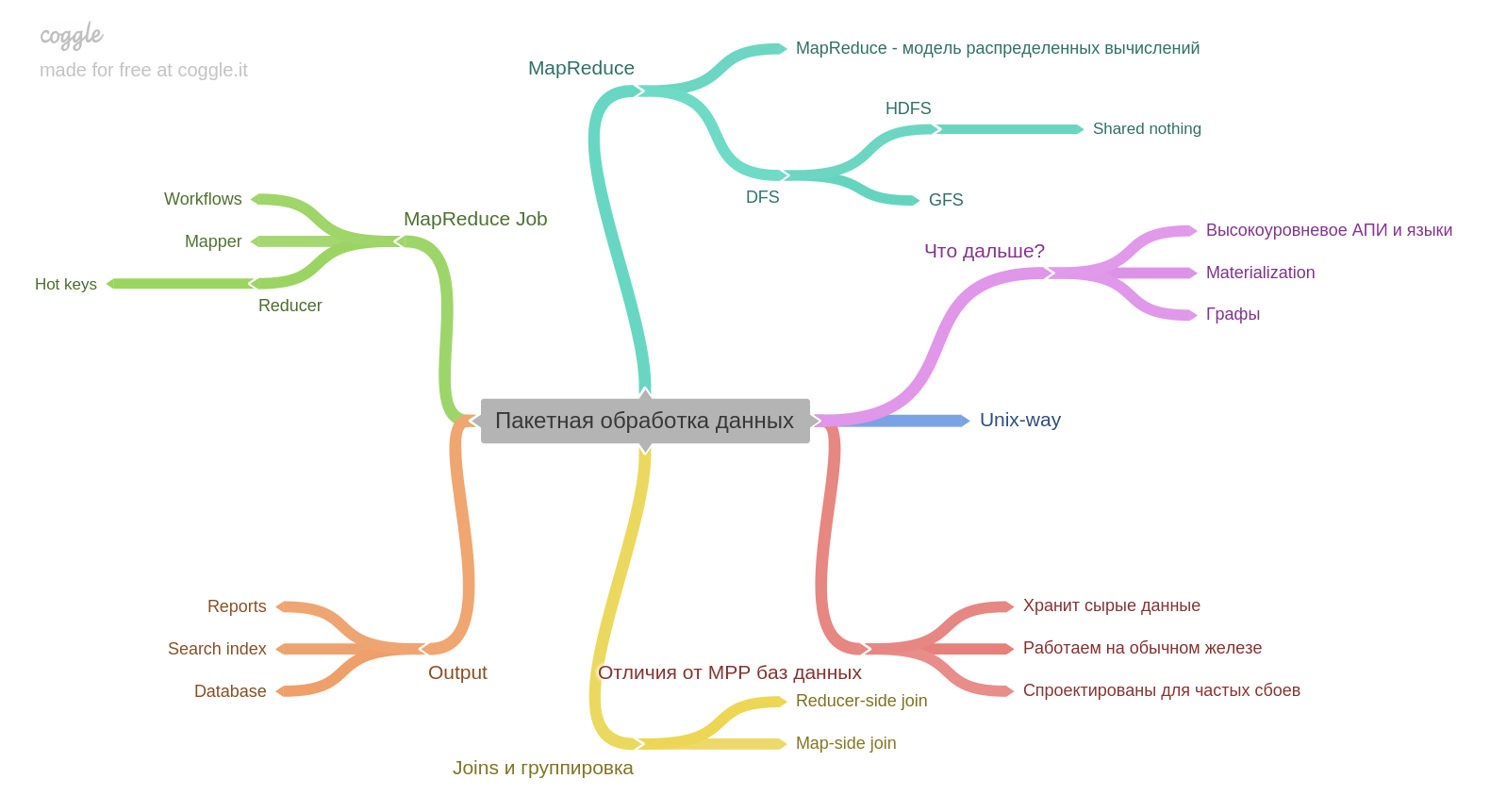
Se você tem experiência com Hadoop ou MapReduce, talvez você aprenda um pouco de novo. Mas eu não trabalhei e foi muito interessante. Um ponto importante para mim - o resultado do processamento em lote por si só pode se tornar a base para outro banco de dados.
Capítulo 11. Streaming de Processamento de Dados.
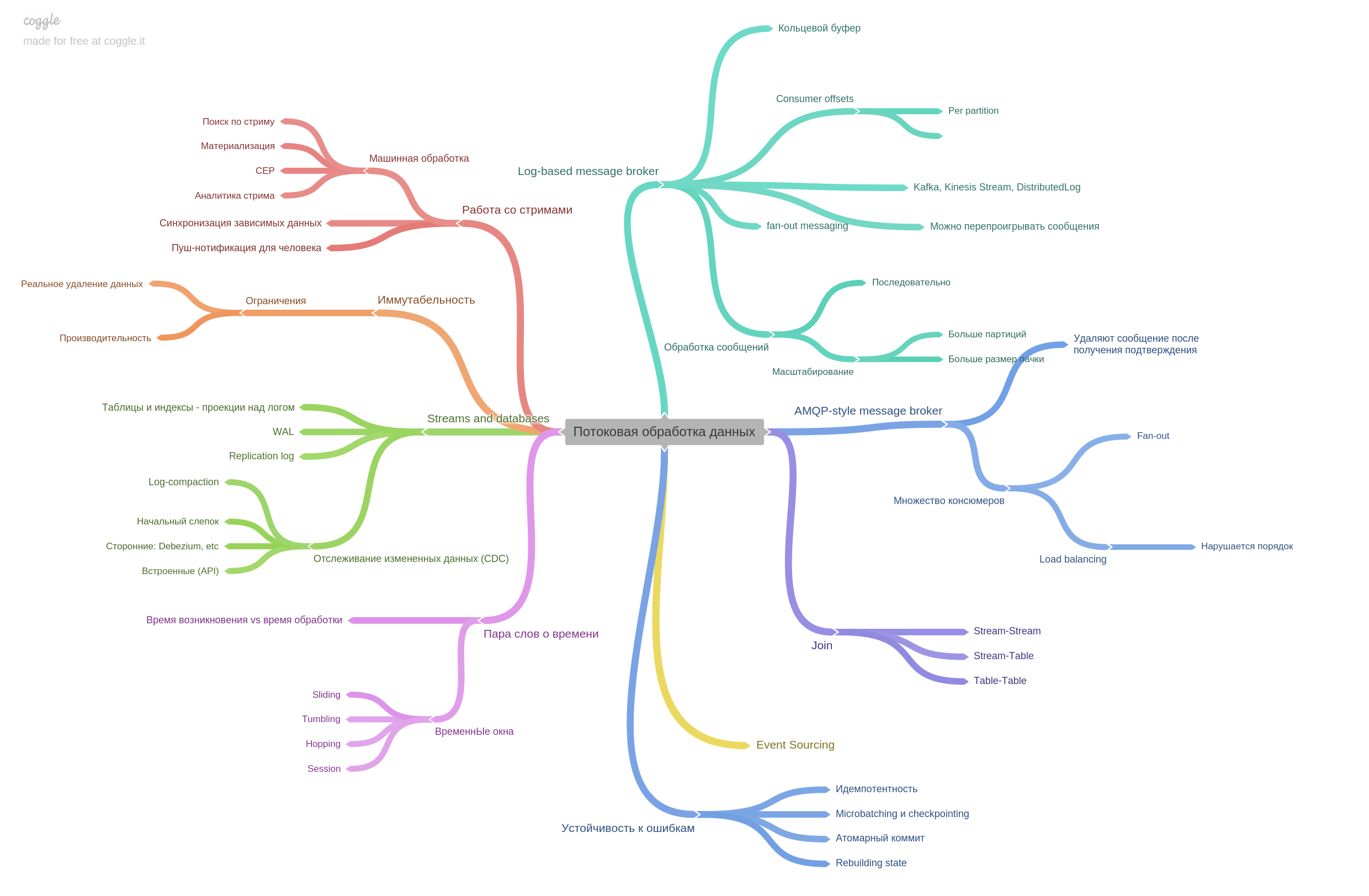
Os intermediários de mensagens são descritos e como o estilo AMPQ difere do baseado em log. De fato, o capítulo contém muitas outras informações. Foi muito interessante ler.
O último capítulo é sobre o futuro. O que esperar, com o que os pensamentos de pesquisadores e engenheiros já estão ocupados.
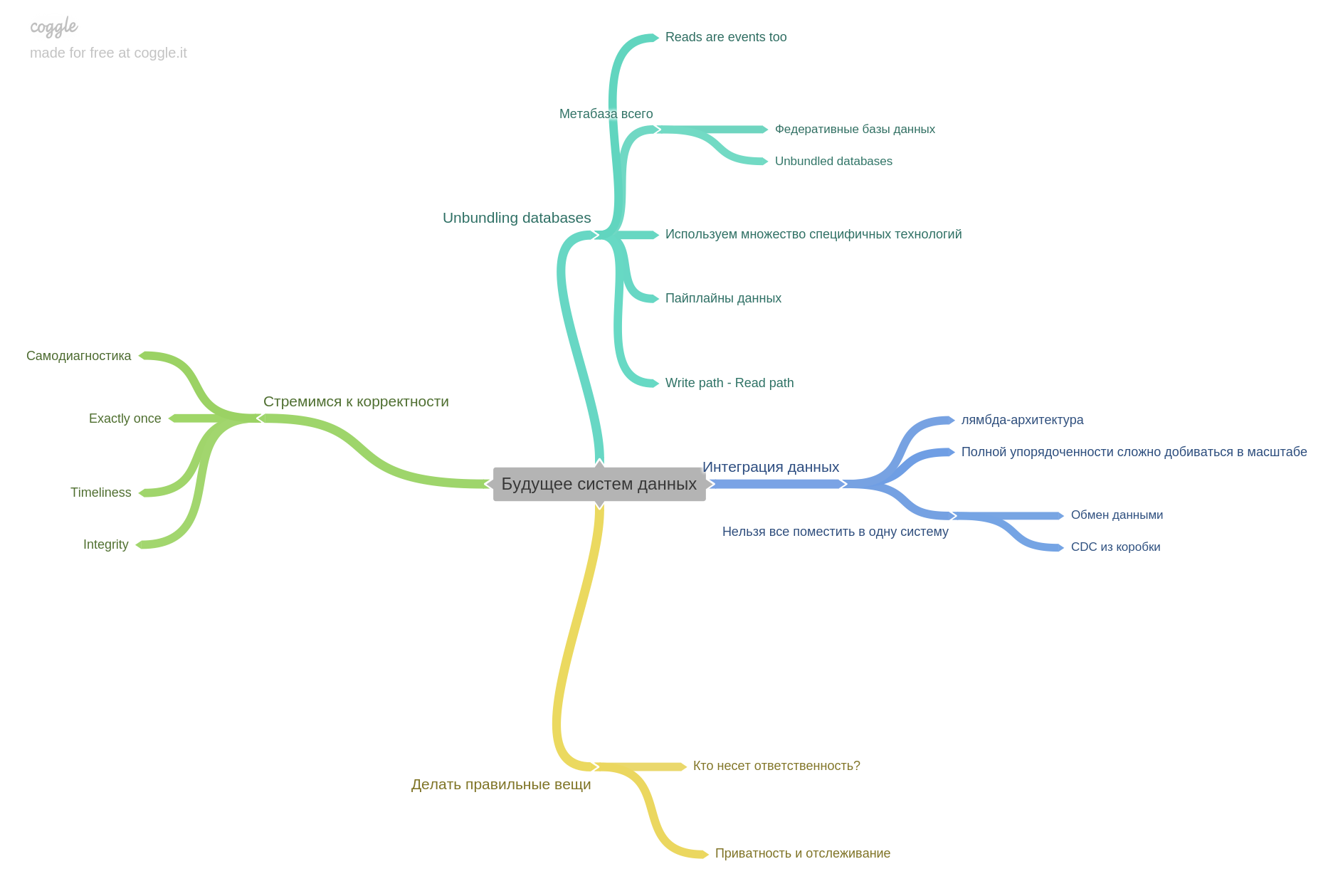
Isso conclui minha análise. É importante entender que fiz apenas parte das teses para cada capítulo. O livro tem um conteúdo tão denso que não é possível resumir, mas recontar completamente.
Pessoalmente, acho que este livro é o melhor técnico dos últimos anos. Eu recomendo a leitura. E não apenas leia, mas trabalhe duro. Siga os links da bibliografia, brinque com DBMSs reais.
Depois de ler este livro, você pode facilmente responder a muitas perguntas em uma entrevista técnica de banco de dados. Mas este não é o ponto. Você se tornará mais legal como desenvolvedor, conhecerá a estrutura interna, os pontos fortes e fracos de vários bancos de dados e pensará nos problemas dos sistemas distribuídos.
Estou pronto para discutir nos comentários o livro em si e nossa prática de ler juntos.
Leia livros!