Sim, eu também sou um idiota. Mas isso eu não esperava de mim. Parece que "não é o primeiro ano de casamento". Parece estar lendo um monte de artigos inteligentes sobre tolerância a falhas, redundância etc., algo razoável uma vez que ele mesmo escreveu aqui. Por mais de 10 anos, sou CEO de um provedor de hospedagem operando sob a marca
ua-hosting.company e prestando serviços de hospedagem e aluguel de servidores na Holanda, EUA, e há apenas uma semana no Reino Unido (não pergunte por que o nome ua, a resposta pode ser encontrada
em nosso artigo autobiográfico ), fornecemos aos clientes soluções com graus variados de complexidade, às vezes de forma que até nós mesmos achamos difícil entender o que fizemos.
Mas caramba ... Hoje eu me superei. Nós mesmos demolimos completamente o site e o faturamento, com todas as transações, dados de clientes sobre serviços e outras coisas, e foi minha culpa, eu mesmo disse "excluir". Alguns de vocês já notaram isso. Aconteceu hoje, sexta-feira às 11:20, horário padrão do leste dos EUA (EST). Além disso, nosso site e faturamento não estavam hospedados no mesmo servidor e nem na nuvem, deixamos a nuvem do data center há dois meses em favor da nossa própria solução. Tudo isso foi localizado em um geo-cluster tolerante a falhas de dois servidores virtuais - nosso novo produto,
VPS (KVM) com unidades dedicadas , VPS
INDEPENDENTE , localizados em dois continentes - na Europa e nos EUA. Um em Amsterdã e outro em Manassas, perto de Washington, pelo fato de a DC In dois data centers confiáveis. Conteúdo em que era duplicado constantemente e em tempo real, e a tolerância a falhas se baseava em um cluster DNS normal, as solicitações podiam chegar a qualquer um dos servidores, qualquer um deles servido como MASTER, e em caso de inacessibilidade, ele assumia as tarefas do segundo.
Eu pensei que isso só pode matar um meteorito, bem, ou algo semelhante ao global, que pode desativar dois data centers ao mesmo tempo. Mas tudo acabou sendo mais simples.
Podemos ser nós mesmos, se somos idiotas. No mundo, existem apenas duas coisas ilimitadas - o Universo e a estupidez humana, e se o primeiro é controverso, o segundo se tornou óbvio.
Sempre adotei o princípio da redundância de som. Não sou uma daquelas pessoas que gritarão "perco 1000 dólares por uma hora de inatividade", mas ao mesmo tempo pago 15 dólares por toda a minha infraestrutura. Não, certamente não perco muito. Embora, talvez, às vezes eu perco. A maioria dos idiotas gritando sobre isso nem pensa que às vezes o tempo de inatividade por segundo pode custar US $ 1.000, US $ 10.000 ou até um milhão de dólares em lucro a longo prazo. Como É muito simples: neste momento, pode entrar um cliente que fará seu primeiro pedido e, no futuro, trará esses milhões de dólares, porque você sempre tem a oportunidade de provar sua singularidade e receber a recomendação dele. E se ele vir o erro 504 ou "Sinto muito, mas o servidor está indisponível no momento", a transação pode não ocorrer. Isso aconteceu conosco, não, não um erro 504 durante a chamada de um visitante importante, mas o primeiro. Puramente por acaso, eu me encontrei no lugar certo na hora certa, quando grandes clientes, como Dmitry Sukhanov, o criador do Kinopoisk, visitaram nosso site, embora este não seja um exemplo muito bom, porque ele trabalhou conosco por apenas 2 anos, até A Yandex não a comprou por US $ 60 milhões ou por quanto. Então, foi Dmitry, e não nós, que conseguimos milhões aqui, mas ficamos felizes em cooperar com um projeto tão interessante e útil, e isso, por sua vez, nos fez um anúncio e proporcionou muitos clientes novos e satisfeitos.
Em geral, por que eu sou tudo isso. As perdas e a redundância necessária devem ser avaliadas com sensibilidade. Embora exista o risco de perder mais de um milhão de dólares, é necessário analisar a probabilidade de um evento desse tipo. Provavelmente, se Dmitry visse 1 erro de tempo 504, nada de crítico teria acontecido e ele voltou para nós novamente. Porque Naquela época, éramos provavelmente um dos poucos que podiam oferecer conectividade de mais de 1 Gb / s na Ucrânia com alta qualidade e latência mínima para baixo custo, o que era extremamente importante para seus recursos naquele momento, a fim de garantir acesso de alta qualidade ao público ucraniano. portal, pois o tráfego estrangeiro era de baixa qualidade e ainda caro. Portanto, é importante garantir a exclusividade da solução, pois o tempo de atividade não será muito crítico para você. E como somos únicos - podemos nos permitir (mesmo agora), com milhares de clientes de servidor, ficar inativos por várias horas ou até mais. Não precisamos de nuvens tolerantes a falhas mega que ofereçam 99,9999% de tempo de atividade por muito dinheiro, porque mesmo que caiam e se caem, a prática as mostra há muito tempo, pois o problema que causou inacessibilidade provavelmente não é comum. E eles não ajudarão em caso de vulnerabilidade. Eles não vão ajudar.
Por isso, construímos nossa decisão por nós mesmos é muito simples. Pegamos dois VPS (KVM) nos nós Dell R730xd, o mesmo VPS (KVM) que oferecemos aos nossos clientes, porque esse é nosso princípio inicial - para dar às pessoas o que usamos:
VPS (KVM) - 2 x Intel Dodeca-Core Xeon E5-2650 v4 (24 núcleos) / 40GB / 4x240GB SSD RAID10 / Datatraffic - 40TB - a partir de US $ 99 / mês, e você pode
obter um desconto de 30% no primeiro pagamento se encontrar uma promoção código em nosso
artigo de publicidade .
Um na Holanda e outro nos EUA. Sim, nesses nós, além do site e do faturamento, existem mais 2 clientes reais, cada um dos quais pode influenciar a operação do site na teoria e não na prática. Por que - está escrito em um artigo publicitário, não entrarei em detalhes aqui uma segunda vez. Agora, isso não é sobre isso. Em geral, a solução não é pior do que servidores dedicados de nível de entrada e pode lidar com uma carga muito grande.
Entre outras coisas, é tolerante a falhas, os dados são constantemente replicados em tempo real. E se um servidor estiver indisponível, o segundo assumirá a função MASTER. Idealmente, você pode fazer com que o tráfego do continente americano seja processado pelo servidor americano e da Europa, Rússia e Ásia - o servidor na Holanda.
Vinculamos os servidores à nossa conta em nosso faturamento WHMCS, um produto licenciado público, mas adaptado para nós, que é usado por muitos provedores de hospedagem em todo o mundo, inclusive nós, já que escrever nosso próprio sistema de contabilidade é uma franca debilidade (no nosso caso) . Especialmente nos casos em que a função desejada é implementada gravando seu próprio módulo no faturamento existente, o que aumenta sua tolerância a falhas, pois reduz o risco de vulnerabilidades críticas. Afinal, sozinho ou mesmo com uma equipe pequena, você não poderá escrever um sistema mais confiável do que o existente, que foi escrito ao longo dos anos por um grupo de desenvolvedores, onde milhares de bugs já foram corrigidos e pelos quais agora os desenvolvedores estão pedindo apenas US $ 30 / mês por uma licença e recebem milhões de dólares por ano que podem ser gastos, inclusive em outras melhorias.
Falando em vulnerabilidades críticas, nosso programador recentemente cometeu um erro ao escrever um dos módulos de serviço, que tinha acesso a um banco de dados de cobrança somente leitura, que foi descoberto por um especialista independente e nos pediu que pagássemos US $ 550 por um bug encontrado, por ser uma vulnerabilidade SQL -injeção:
A injeção de SQL está entre os 10 principais OWASP, escrevi para você sobre a quantia de US $ 550, essa é a quantia mínima, já que o banco de dados sofre, comprometendo os dados do usuário.
Mas alguns montantes chegam a US $ 10.000 como recompensa, como é o caso do vk.com.
Obviamente, apoiamos esse começo e pagamos indenizações sem questionar. Como nosso programador examinou os dados fornecidos e confirmou a existência de um problema, justificativa do pentester. Afinal, ainda não mantemos nosso próprio pentester no estado, e este trabalho requer conhecimento e tempo consideráveis, pois inclui uma série de estudos:
Auditoria de segurança de todo o recurso, e esta é uma verificação de acordo com os seguintes parâmetros, e nosso relatório no final da auditoria inclui:
• injeção de código A1
• Autenticação incorreta A2 e gerenciamento de sessões
• Script A3 Crossite
• Violação de acesso A4
• Configuração insegura A5
• A6 vazamento de dados sensíveis
• A7 proteção insuficiente contra ataques
• A8 falsificação de solicitação entre sites
• A9 Usando componentes com vulnerabilidades conhecidas
• A10 Registro e monitoramento inadequados
Porque sim, a decisão foi tomada de maneira inequívoca e rápida. Além disso, como observou Pentester, esses estudos aumentam a segurança da web como um todo:
Esse é o meu hobby, se todo desenvolvedor como você tivesse um diálogo com caçadores de bugs, a Internet seria 80% segura.
Portanto, no geral, pagamos um pouco, especialmente se dividirmos o valor pelo número de meses em que o funcionário responsável pelo teste de penetração não foi mantido na equipe. Muito obrigado ao Pentester pelo bug encontrado e pelo fato de ele ter demorado um pouco para nós, somos muito gratos a ele. Se alguém precisar de seus serviços, entre em contato, forneceremos contatos com sua permissão.
Mas desta vez não foi a vulnerabilidade que nos matou. Éramos nós e o recurso do produto WHMCS. Em cada nota, instalamos um conveniente produto de gerenciamento de contêiner virtual - VM Manager, ao qual o WHMCS tem acesso para criar, pausar e excluir, além de clientes - para gerenciar o contêiner virtual criado.
Todos os dias, no WHMCS, recebemos dezenas ou mesmo centenas de pedidos que precisam ser aceitos (aceitos), excluídos ou marcados como Fraude se o cliente estiver tentando pagar por um pedido com cartão de crédito roubado. Às vezes, há um grande número de pedidos e não podemos determinar imediatamente qual status atribuir a ele, pois realizamos nossa verificação interna ou exigimos que o usuário se identifique corretamente se suspeitarmos de seu pedido, e esses usuários, é claro, nem sempre respondem ou passam identificação com sucesso. Portanto, periodicamente, acumulam-se mil ou dois pedidos não ativados ou com status desconhecido, mais fáceis de excluir do que processar. Quem realmente precisa - reordenar.
Há dois meses, decidimos abandonar completamente o produto de data center baseado em nuvem, quando começamos a fornecer nossa própria solução com o VM Manager, que permite colocar o sistema em um clique ou até na sua imagem:

E eles até o ofereceram nos SSDs NVMe PCIe, que são uma ordem de magnitude mais rápida que os SSDs regulares para leitura e até três vezes para gravação, a solução, como a nuvem, precisa ser atualizada, os servidores custam US $ 15 e incluem um conveniente painel de controle do VM Manager e ISP Manager 5, mediante solicitação, suporte para atualização com uma etapa mínima de 5 GB de RAM DDR4, 60 GB NVMe PCIe SSD e 3 núcleos E5-2650 v4
para um plano tarifário mais alto em Amsterdã, Manassas e Londres:
VPS (KVM) - E5-2650 v4 (3 núcleos) / 5 GB DDR4 / 60 GB SSD NVMe / 1 Gbps 5 TB - US $ 15 / mês
VPS (KVM) - E5-2650 v4 (6 núcleos) / 10 GB DDR4 / 120 GB SSD NVMe / 1 Gbps 10 TB - US $ 30 / mês
VPS (KVM) - E5-2650 v4 (9 núcleos) / 15 GB DDR4 / 180 GB SSD NVMe / 1 Gbps 15 TB - US $ 45 / mês
...
VPS (KVM) - E5-2650 v4 (24 núcleos) / 40GB DDR4 / 480GB NVMe SSD / 1Gbps 40TB - US $ 120 / mês
...
VPS (KVM) - E5-2650 v4 (24 núcleos) / 65GB DDR4 / 780GB NVMe SSD / 1Gbps 65TB - US $ 195 / mês
VPS (KVM) - E5-2650 v4 (24 núcleos) / 70GB DDR4 / 840GB NVMe SSD / 1Gbps 70TB - US $ 210 / mês
VPS (KVM) - E5-2650 v4 (24 núcleos) / 75GB DDR4 / 900GB SSD NVMe / 1Gbps 75TB - US $ 225 / mês
Portanto, não faz sentido alugar uma grande parte da nuvem do data center e oferecer aos clientes os antigos processadores E3-1230, embora a partir de US $ 3,99 por mês tenha acabado. Acreditamos que os clientes devem receber a mais alta qualidade e desempenho máximo, a um preço mínimo, sim, não podemos oferecer um produto por US $ 3,99 e talvez não atendamos às necessidades de alguns desenvolvedores que precisam de recursos mínimos e desempenho, mas o nó custa mais 7.000 euros e não podemos, pelo menos por enquanto, colocar mais de 15 clientes nele, pois estamos prontos para garantir a qualidade. E a qualidade implica não apenas estabilidade, mas também a máxima relação desempenho / preço e, em seguida, relação custo-benefício.
Para comemorar, cancelamos toda a infraestrutura de nuvem (que é milhares de VPS), pedimos 2 servidores virtuais independentes para nós (sim, pagamos por nossos servidores), implantamos um site e faturamos há 2 meses em uma nova solução, como descrevemos tudo acima, trazido para o grupo de proteção, para que o sistema não pare, se você se esqueceu de pagar pontualmente ... Parece ter feito tudo.
E hoje, após 2 meses, decidimos "Cancelar" (não excluir, existe um botão assim, mas tentamos nunca excluir nada, para que haja sempre um histórico) Mais de 1000 pedidos pendentes que ainda não receberam um status no faturamento do WHMCS . Adivinhou? Sim é isso. Eles me perguntaram - posso cancelar? Eu confirmei "excluir".
Às vezes, apesar da grande quantidade de recursos, já que a amostragem de dados é grande e algum processo não se encaixa no limite de tempo alocado, o WHMCS comete um erro 504, tudo é feito e o faturamento continua a funcionar, mas aqui temos indisponibilidade. O faturamento e o site não estão mais disponíveis. Não entendemos imediatamente o motivo. Mas então eles perceberam. O pedido de nossos 2 VPS não foi aceito (sim, nós não aceitamos nosso pedido!) E, como resultado, foi "Cancelado" pelo sistema, o que levou ao lançamento do módulo e à remoção de dois contêineres de uma só vez, supostamente não criados, mas criados pelos virtuais, usando nosso amado VM Manager. Tendo entrado em um dos nós, como esperado, nossos administradores viram a imagem “Adeus”:
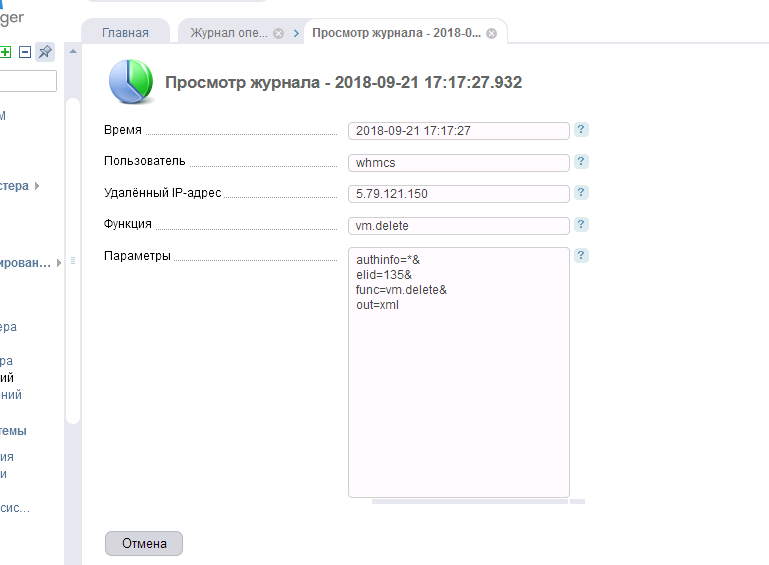
O que é isso - uma falha nos desenvolvedores do WHMCS, que leva à remoção de pedidos não aceitos e, na verdade, criados com seu ID VPS, quando eles são cancelados, ou nossa estupidez (do departamento de vendas) não é mais importante. O resultado foi um - "Adeus ao site com cobrança". O painel acabou de limpá-los. E os administradores tinham apenas uma pergunta para nós (vendas):
Naher crie um serviço com seu site principal e cobrança.
E então também a mate no inferno.
E, embora tivéssemos backups, também em duas regiões geograficamente distribuídas, me senti desconfortável. Como não tinha certeza da atualização dos backups, não tinha certeza de que nossos administradores fizeram tudo certo, como foi originalmente prescrito naqueles. a tarefa de backup do banco de dados a cada hora ou mais frequentemente, os dados foram atualizados e várias versões anteriores dos arquivos foram armazenadas. Que os backups de algum erro de software não pararam de ser executados (afinal, eu pessoalmente não o controlei, por que devo ter certeza de que nossos administradores ficarão preocupados com nossos dados se eu tiver esse controle?). Um monte de pensamentos negativos ... Não deixe o universo sobreviver a isso!
Já reuni a ideia de que pelo menos 1 hora, ou pior, não haverá transações, e você precisará restaurar os pagamentos dos clientes manualmente, comparar dados de transações anteriores e gravar nos titulares de contas que recriamos uma conta e pagamos por ela. , para nos mostrar do lado errado, para enviar uma notificação de que somos tolos e fizemos um mau funcionamento do software ... E se não houver um novo backup - geralmente é um cano, teria que ser muito longo e triste para restaurar tudo ...
Nesse caso, temos uma tabela interna na qual muitos dados principais são duplicados manualmente e que são atualizados por nós, o que elimina uma falha de software e a reescrita de dados incorretos. Apesar da disponibilidade de backups, ainda usamos esse método. Afinal, ninguém cancela a possibilidade de um zvezdets global.
Felizmente, tudo acabou não sendo tão ruim, e até isso. um especialista que teve que resolver um problema e que no começo anunciou:
A noite foi um sucesso, obrigado a todos.
Eu fui buscá-lo.
No entanto, a noite foi um sucesso. Como inicialmente a solução oferecia o uso do lvm e um novo contêiner virtual ainda não havia sido criado - era possível restaurar os dados reais, embora com uma dança com um pandeiro:
Tudo através do utilitário lvm, usando seus comandos, restaurou o grupo de volumes virtuais, depois o virtual, ativou a partição, montou na pasta esquerda, criou o servidor e colocou os dados lá. Isso foi possível de outras maneiras, mas essa opção, no nosso caso, foi a mais rápida e específica das configurações do servidor virtual, cada uma com seu próprio ataque.
Que conclusões são feitas? Redundância e redundância devem incluir contabilidade de vulnerabilidades e o cenário mais estúpido de desenvolvimento, quando tudo, mesmo os backups, podem ser destruídos. Não sofremos e não sofremos grandes perdas apenas pelo fato de os dados não terem sido completamente excluídos. Se for necessário restaurar a partir de backups, haverá uma perda de transações por hora e uma perda significativa de tempo de trabalho. Pareceu-nos que a probabilidade de os backups serem úteis ao usar um geocluster é mínima - estávamos errados. Não levamos em conta que é possível excluir os dois servidores de uma só vez e que não excluiremos os servidores, mas sim.
É sempre necessário ter um armazenamento externo independente do seu sistema, com acesso, preferencialmente apenas por algum código, que também é reservado, para garantir que os dados não sejam perdidos. No momento, apesar da presença de backups em nossa infraestrutura em duas regiões, considero seriamente a possibilidade de usar algo como o Amazon Glacier, embora o último seja muito caro. De acordo com os administradores, tudo está bem lá apenas em termos de marketing, mas quando você começa a usá-lo, você se depara com o fato de a solução ser bastante cara, porque você precisa pagar por cada solicitação e cada arquivo que é muito interessante considerar sua aplicação aws-cli, especialmente se os dados precisam ser restaurados. Recentemente, um cliente da Grã-Bretanha pediu para fazer uma reserva lá, após alguns meses de uso, ele recusou - acabou por ser muito caro. Mas, ainda assim, precisamos determinar o que é mais caro. — . — , , . , .
, — , , , . , , , , , .
PS , ( , EST ). , , . , - . , , . , — , . . !
.
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
, 30% VPS , ,
.
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?