Há alguns anos, concluí um projeto de migração na rede de um de nossos clientes, a tarefa era alterar a plataforma, que distribui a carga entre os servidores. O esquema de prestação de serviços desse cliente evoluiu ao longo de quase 10 anos, junto com os novos desenvolvimentos no setor de data center, de modo que o “exigente”, no bom sentido da palavra, esperava uma solução que satisfizesse não apenas os requisitos de tolerância a falhas de equipamentos de rede, balanceadores de carga e servidores , mas também possuiria propriedades como escalabilidade, flexibilidade, mobilidade e simplicidade. Neste artigo, tentarei consistentemente, do simples ao complexo, definir os principais exemplos do uso de balanceadores de carga sem referência ao fabricante, seus recursos e métodos de emparelhamento com a rede de entrega de dados.
Os balanceadores de carga agora são cada vez mais referidos como Application Delivery Controllers (ADCs). Mas se os aplicativos estão em execução no servidor, por que eles devem ser entregues em algum lugar? Por motivos de tolerância a falhas ou dimensionamento, o aplicativo pode ser executado em mais de um servidor; nesse caso, você precisa de um tipo de servidor proxy reverso que oculte a complexidade interna dos consumidores, seleciona o servidor desejado, entrega uma solicitação a ele e garante que o servidor retorne o correto. , do ponto de vista do protocolo, o resultado, caso contrário, ele selecionará outro servidor e enviará uma solicitação para ele. Para implementar essas funções, o ADC deve entender a semântica do protocolo da camada de aplicativos com o qual trabalha, o que permite configurar regras específicas de aplicação para entrega de tráfego, análise do resultado e verificação do status do servidor. Por exemplo, um entendimento da semântica do HTTP possibilita a configuração quando solicitações HTTP
GET /docs/index.html HTTP/1.1 Host: www.company.com Accept-Language: en-us Accept-Encoding: gzip, deflate
são enviados para um grupo de servidores com compactação subsequente dos resultados e armazenamento em cache e solicitações
POST /api/object-put HTTP/1.1 HOST: b2b.company.com X-Auth: 76GDjgtgdfsugs893Hhdjfpsj Content-Type: application/json
processado de acordo com regras completamente diferentes.
A compreensão da semântica do protocolo permite organizar a sessão no nível dos objetos do protocolo do aplicativo, por exemplo, usando cabeçalhos HTTP, cookie RDP ou solicitações multiplex para preencher uma sessão de transporte com muitas solicitações do usuário, se o nível do aplicativo do protocolo permitir.
Às vezes, o escopo de aplicação do ADC é imaginado de maneira irracional apenas ao servir o tráfego HTTP; na verdade, a lista de protocolos suportados para a maioria dos fabricantes é muito mais ampla. Mesmo trabalhando sem entender a semântica do protocolo da camada de aplicativos, o ADC pode ser útil para resolver várias tarefas, por exemplo, participei da construção de um farm virtual auto-suficiente de servidores SMTP. Durante os ataques de spam, o número de instâncias aumenta usando o controle de feedback ao longo da fila de mensagens para fornecer um tempo satisfatório para a verificação de mensagens com algoritmos que consomem muitos recursos. Durante a ativação, o servidor se registrou no ADC e recebeu parte das novas sessões TCP. No caso do SMTP, esse esquema de operação foi totalmente justificado devido à alta entropia de conexões nos níveis de rede e transporte; para distribuição uniforme de carga durante ataques de spam ADC, apenas o suporte TCP é necessário. Um esquema semelhante pode ser usado para criar um farm a partir de servidores de banco de dados, DNS, DHCP, AAA ou clusters de servidores de acesso remoto muito carregados quando os servidores podem ser considerados equivalentes no domínio e quando suas características de desempenho não diferem muito umas das outras. Não irei adiante no tópico dos recursos do protocolo; esse aspecto é muito extenso para indicar na introdução, se algo parecer interessante - escreva, talvez seja uma ocasião para um artigo com uma apresentação mais profunda de algum aplicativo, e agora vamos ao que interessa.
Na maioria das vezes, o ADC fecha a camada de transporte, para que a sessão TCP de ponta a ponta entre o consumidor e o servidor se torne composta, o consumidor estabelece uma sessão com o ADC e o ADC com um dos servidores.
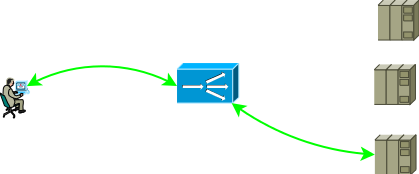 Fig. 1
Fig. 1A configuração de rede e as configurações de endereçamento devem fornecer esse avanço de tráfego para que duas partes da sessão TCP passem pelo ADC. A opção mais fácil para tornar o tráfego da primeira parte a chegar ao ADC é atribuir um endereço de serviço a um dos endereços de interface do ADC, com a segunda parte as seguintes opções são possíveis:
- ADC como o gateway padrão para a rede do servidor;
- Transmitir para endereços de consumidor ADC em um de seus endereços de interface.
De fato, uma visão um pouco mais realista do primeiro esquema de aplicação é semelhante a esta, é a base a partir da qual começaremos:
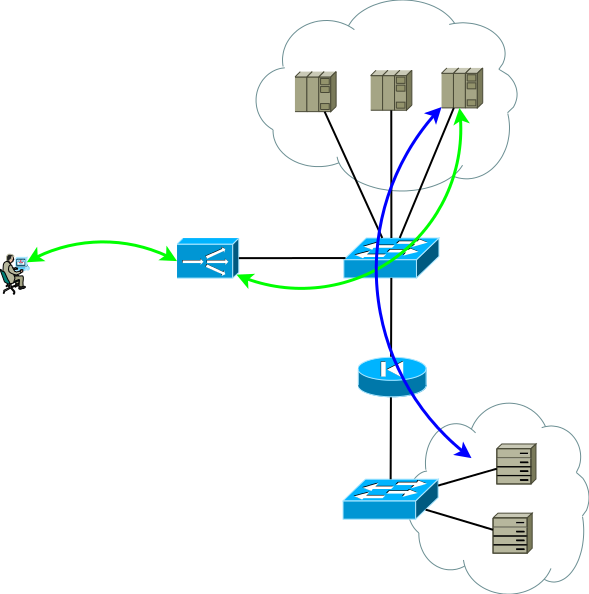 Fig.2
Fig.2O segundo grupo de servidores pode ser bancos de dados, back-end de aplicativos, armazenamento em rede ou front-end para outro conjunto de serviços no caso de decomposição de um aplicativo clássico em microsserviços. Esse grupo de servidores pode ser um domínio de roteamento separado, com suas próprias políticas, localizado em outro datacenter ou ser completamente isolado por razões de segurança. Os servidores raramente estão localizados no mesmo segmento; na maioria das vezes, são colocados em segmentos para os fins a que se destinam, com políticas de acesso claramente reguladas, a figura mostra isso como um firewall.
Estudos mostram que aplicativos multicamadas modernos geram mais tráfego oeste-leste, e é improvável que você queira que todo o tráfego intra-código / entre segmentos passe pelo ADC. Os comutadores na Figura 2 não são necessariamente físicos - os domínios de roteamento podem ser implementados usando entidades virtuais, chamadas de roteador virtual, vrf, vr, instância vpn ou uma tabela de roteamento virtual para diferentes fabricantes.
A propósito, também há uma opção de emparelhamento com a rede, sem exigir simetria dos fluxos de tráfego do consumidor para o ADC e do ADC para os servidores, é uma demanda em casos de sessões de longa duração que transmitem uma quantidade muito grande de tráfego em uma direção, por exemplo, streaming ou transmitir conteúdo de vídeo. Nesse caso, o ADC vê apenas o fluxo do cliente para os servidores, esse fluxo é entregue ao endereço da interface ADC e, após um processamento simples, que consiste em substituir o endereço MAC pela interface MAC de um dos servidores, a solicitação é enviada ao servidor em que o endereço de serviço está atribuído a uma das interfaces lógicas. O tráfego reverso do servidor para o consumidor passa ignorando o ADC de acordo com a tabela de roteamento do servidor. O suporte a um único domínio de broadcast para todo o front-end pode ser muito difícil; além disso, a capacidade da ADC de analisar respostas e oferecer suporte à sessões neste caso é muito limitada; na verdade, é apenas uma opção, portanto, essa opção não é considerada mais, embora algumas limitações tarefas podem ser usadas.
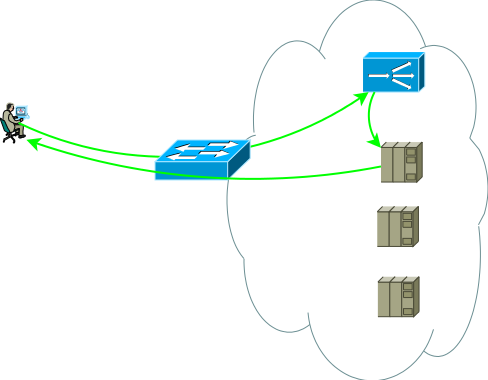 Fig.3
Fig.3Portanto, como temos um data center básico, mostrado na Figura 2, vamos pensar em quais problemas podem levar o data center básico à evolução. Vejo dois tópicos para análise:
- Suponha que o subsistema de comutação seja totalmente reservado, não vamos pensar em como ou por que, o tópico é muito extenso. Os aplicativos são executados em vários servidores e são feitos backup usando o ADC, mas como faço para reservar o próprio ADC?
- Se a análise mostrar que o próximo pico de carga sazonal pode exceder os recursos do ADC, é claro que você pensa em escalabilidade.
Essas tarefas são semelhantes, pois, no processo de resolvê-las, o número de instâncias do ADC aumentará definitivamente. Ao mesmo tempo, a tolerância a falhas pode ser organizada de acordo com o esquema Ativo / Backup e Ativo / Ativo, e a escala só pode ser feita de acordo com o esquema Ativo / Ativo. Vamos tentar resolvê-los individualmente e ver quais propriedades as diferentes soluções têm.
Os ADCs de muitos fabricantes podem ser considerados elementos de uma infraestrutura de rede, RIP, OSPF, BGP - tudo isso existe, o que significa que você pode criar um esquema trivial de backup ativo / de backup. O ADC ativo passa os prefixos de serviço para o roteador upstream e aceita a rota padrão para preencher sua tabela e transferir para o datacenter para a tabela de roteamento virtual correspondente. O ADC de backup faz o mesmo, mas, usando a semântica do protocolo de roteamento selecionado, gera anúncios menos atraentes. Com essa abordagem, os servidores podem ver o endereço IP real do consumidor, pois não há motivo para usar a conversão de endereços. Esse esquema também funciona normalmente se houver mais de um roteador upstream, mas para evitar uma situação em que o ADC ativo perca o padrão e a conectividade com o roteador, enquanto ainda recebe o padrão do ADC de backup e continua a anuncia-lo em direção ao data center, tente evitar a proximidade entre eles. ADC e o uso de rotas estáticas.
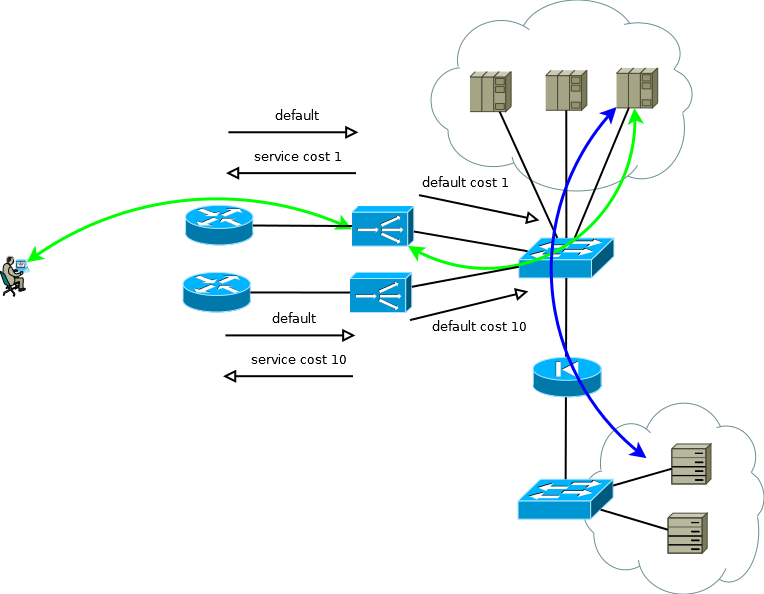 Fig. 4
Fig. 4Se os servidores não precisarem operar com endereços IP de consumidor reais ou o protocolo da camada de aplicativo permitir incorporá-lo em cabeçalhos, como HTTP, o esquema se tornará Ativo / Ativo com uma dependência quase linear do desempenho no número de ADCs. No caso de mais de um roteador upstream, deve-se tomar cuidado para garantir que o tráfego recebido chegue em porções mais ou menos uniformes. Essa tarefa pode ser facilmente resolvida se no domínio de roteamento ECMP a transferência iniciar para esses roteadores, se for difícil ou se o domínio de roteamento não for atendido por você - você pode usar conexões de malha completa entre o ADX e os roteadores, para que a transferência ECMP comece diretamente a eles.
 Fig.5
Fig.5No início desta parte, escrevi que a tolerância a falhas e o dimensionamento são duas grandes diferenças. As soluções para esses problemas têm um nível diferente de utilização de recursos. Se você estiver projetando um esquema Ativo / Em Espera, precisará aceitar o fato de que metade dos recursos ficará ociosa. E se acontecer que você precise dar o próximo passo quantitativo, esteja preparado para multiplicar os recursos necessários por mais dois no futuro.
Os benefícios do Active / Active começam a aparecer quando você opera com mais de dois dispositivos. Suponha que você precise garantir o desempenho de 8 unidades arbitrárias (8 mil conexões por segundo ou 8 milhões de sessões simultâneas) e forneça um cenário de falha de dispositivo único. Na versão Ativo / Ativo, você precisa de apenas três instâncias ADC com capacidade de 4, no caso de Ativo / Standby - dois por 8. Se você traduzir esses números em recursos inativos, receberá um terço e meio. O mesmo princípio de cálculo pode ser usado para estimar a proporção de conexões interrompidas durante um período de falha parcial. Com um aumento no número de instâncias Ativo / Ativo, a matemática se torna ainda mais agradável e o sistema obtém a oportunidade de aumentar gradualmente a produtividade, em vez de Ativo / Em espera gradual.
Será correto mencionar outra maneira de esquemas de trabalho Ativo / Ativo ou Ativo / Em espera - clustering. Mas não será muito correto dedicar muito tempo a isso, pois tentei escrever sobre abordagens e não sobre os recursos dos fabricantes. Ao escolher esta solução, você precisa entender claramente o seguinte:
- A arquitetura de cluster às vezes impõe restrições a essa ou aquela funcionalidade; em alguns projetos, isso é fundamental; em alguns, pode se tornar importante no futuro, tudo depende do fabricante e cada solução precisa ser trabalhada individualmente;
- Geralmente, o cluster é um domínio de falha; haverá erros no software.
- O cluster é fácil de montar, mas muito difícil de desmontar. A tecnologia tem menos mobilidade - você não pode controlar partes do sistema.
- Você cai no abraço tenaz de seu fabricante.
No entanto, existem coisas positivas:
- O cluster é fácil de instalar e fácil de operar.
- Às vezes, você pode esperar uma utilização quase ideal dos recursos.
Portanto, como nosso data center da Figura 5 continua a crescer, a tarefa que você pode precisar resolver é aumentar o número de servidores. Nem sempre é possível fazer isso em um data center existente, portanto, suponha que um novo local espaçoso com servidores adicionais tenha aparecido.
 Fig.6
Fig.6Como um novo site pode não estar muito longe, você resolverá o problema com êxito renovando domínios de roteamento. Um caso mais geral, que não exclui a aparência do site em outra cidade ou em outro país, apresentará novos desafios para o data center:
- Utilização de canais entre sites;
- A diferença no tempo de processamento para solicitações que o ADC enviou para processamento em servidores próximos e distantes.
Manter um amplo canal entre sites pode ser um empreendimento muito caro, e escolher um local não será mais uma tarefa trivial - um site sobrecarregado com um tempo de resposta curto ou gratuito com um grande. Pensar nisso fará com que você crie uma configuração de data center distribuída geograficamente. Essa configuração, por um lado, é amigável para os consumidores, pois permite que você receba serviço em um ponto próximo a você; por outro, pode reduzir significativamente os requisitos para a banda do canal entre sites.
No caso em que os endereços IP reais não precisam estar acessíveis aos servidores ou quando o protocolo da camada de aplicação permite que eles sejam transmitidos nos cabeçalhos, o dispositivo de um datacenter geograficamente distribuído não é muito diferente do que chamei de datacenter básico. O ADC em qualquer site pode enviar solicitações de processamento para servidores locais ou enviá-las para processamento para um vizinho. A transmissão do endereço do consumidor torna isso possível. Alguma atenção deve ser prestada ao monitoramento do volume de tráfego recebido, a fim de manter a quantidade de ADC dentro do site adequada à proporção de tráfego que o site recebe. A tradução de endereço do consumidor permite aumentar / diminuir o número de ADCs ou até mover instâncias entre sites de acordo com as alterações na matriz de tráfego de entrada ou durante a migração / inicialização. Apesar de sua simplicidade, o esquema é bastante flexível, possui características operacionais agradáveis e é facilmente replicado para mais de dois sites.
 Fig. 7
Fig. 7Se você trabalha com um protocolo que permite encaminhar solicitações, como no redirecionamento HTTP, esse recurso pode ser usado como uma alavanca adicional para controlar a carga do canal entre sites, como um mecanismo para realizar manutenção de rotina em servidores ou como um método de criar farms de servidores Active / Backup em diferentes sites. No momento necessário, automaticamente ou após alguns eventos de gatilho, o ADC pode remover o tráfego dos servidores locais e mover os consumidores para um site vizinho. Vale a pena prestar muita atenção ao desenvolvimento desse algoritmo para que o trabalho coordenado da ADC exclua a possibilidade de encaminhamento mútuo de solicitações ou ressonância.
De particular interesse é o caso em que os servidores precisam de endereços IP reais dos consumidores e o protocolo da camada de aplicativos não tem a capacidade de transmitir cabeçalhos adicionais ou quando os ADCs funcionam sem entender a semântica do protocolo da camada de aplicativos. Nesse caso, não é possível fornecer uma conexão consistente entre os segmentos de sessão TCP simplesmente declarando uma rota no padrão ADC. Se você fizer isso, os servidores do primeiro site começarão a usar o ADC local como o gateway padrão para as sessões que vieram do segundo site, a sessão TCP não será estabelecida nesse caso porque o ADC do primeiro site verá apenas um ombro da sessão.
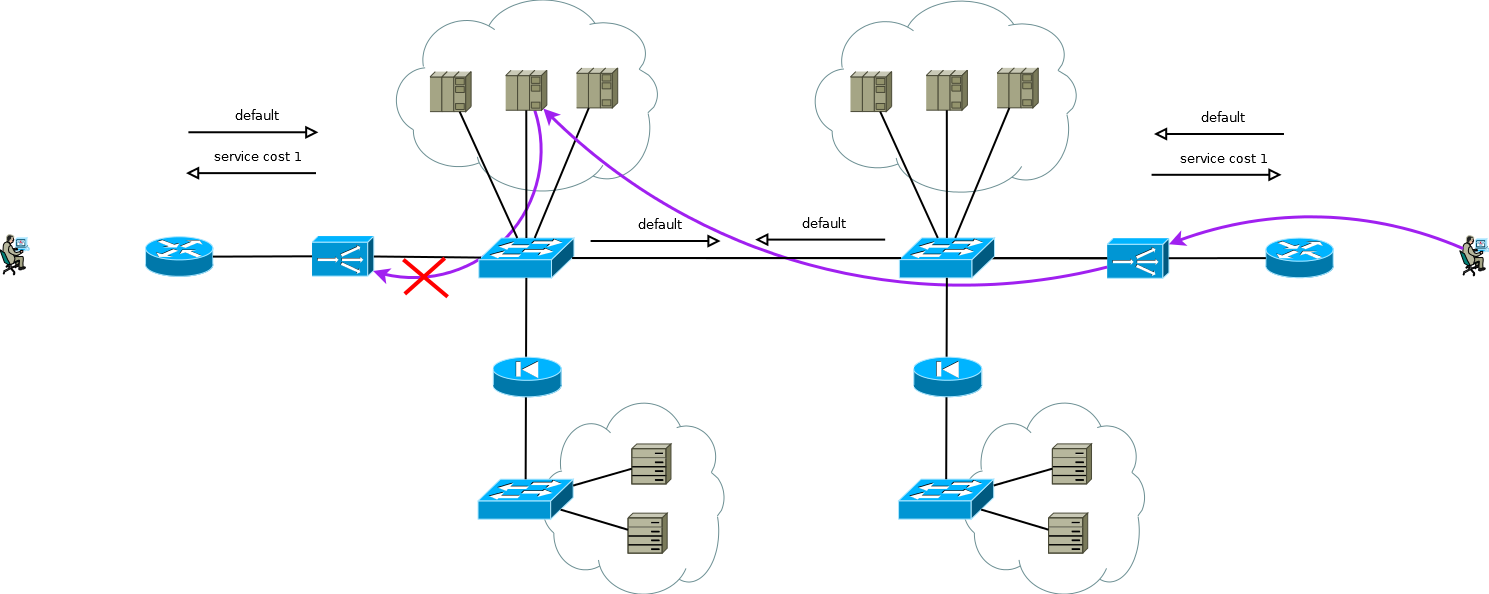 Fig. 8
Fig. 8Há um pequeno truque que ainda permite que você execute o ADC Ativo / Ativo em combinação com farms de servidores Ativo / Ativo em sites diferentes (não considero o caso do Ativo / Backup em dois sites, uma leitura cuidadosa do descrito acima permitirá que você resolva esse problema sem discussão adicional). O truque é usar no ADC do segundo site não os endereços da interface do servidor, mas o endereço lógico do ADC, que corresponde ao farm de servidores no primeiro site. Ao mesmo tempo, os servidores recebem tráfego como se fosse do ADC local e usam o gateway padrão local. Para manter esse modo de operação no ADC, é necessário ativar a função de memória da interface da qual veio o primeiro pacote para configurar a sessão TCP. Fabricantes diferentes chamam essa função de maneira diferente, mas a essência é a mesma - lembre-se da interface na tabela de status da sessão e use-a para o tráfego de resposta sem prestar atenção à tabela de roteamento. O esquema é totalmente funcional e permite distribuir a carga de maneira flexível em todos os servidores disponíveis, onde quer que estejam. No caso de dois ou mais sites, a falha de um ADC não afeta a disponibilidade do serviço como um todo, mas exclui completamente a possibilidade de processar o tráfego nos servidores do site com ADCs com falha; isso deve ser lembrado ao prever o comportamento e a carga durante falhas parciais.
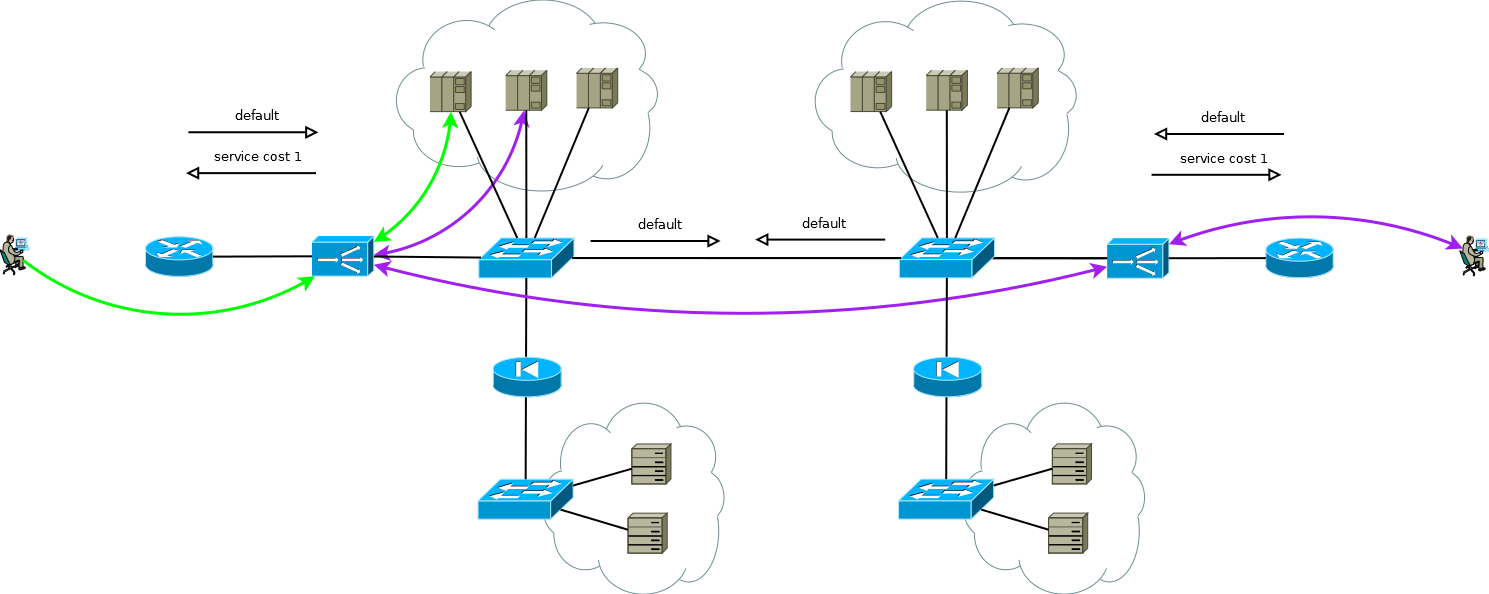 Fig. 9
Fig. 9Os serviços de nosso cliente funcionaram aproximadamente da mesma maneira quando comecei a trabalhar em um projeto de migração para a nova plataforma ADC. Não foi difícil simplesmente recriar o comportamento dos dispositivos da plataforma antiga na nova dentro da estrutura de um esquema comprovado e amigável ao cliente, era o que eles esperavam de nós.
Mas olhe novamente para a Figura 9, você vê o que pode ser otimizado lá?
A principal desvantagem de trabalhar com a cadeia ADC é que ela consome os recursos de duas ADCs para processar parte da sessão. No caso desse cliente, a escolha foi absolutamente consciente, devido às especificidades dos aplicativos e à necessidade de poder redistribuir muito rapidamente (de 20 a 50 segundos) a carga entre servidores de sites diferentes. Em diferentes períodos de tempo, o processamento duplo consumia uma média de 15 a 30% dos recursos da ADC, basta pensar na otimização. Tendo discutido esse ponto com os engenheiros do cliente, propusemos substituir o suporte para a tabela de sessões ADC pela ligação de interface com o roteamento de origem em servidores usando PBR na pilha IP do Linux. Como chave, consideramos opções como:
- endereço IP adicional em servidores em uma interface comum para cada ADC;
- interface de endereço IP em servidores em um 802.1q separado para cada ADC;
- Rede de túnel de sobreposição separada nos servidores para cada ADC.
A primeira e a segunda opções afetariam de alguma forma a rede como um todo. Entre os efeitos colaterais da opção número um, parecia-nos inaceitável que um aumento múltiplo do número de tabelas ADC e ARP nos comutadores e a segunda opção exigiriam um aumento no número de domínios de difusão ponto a ponto entre sites ou instâncias individuais de tabelas de roteamento virtual. A natureza local da terceira opção parecia muito atraente para nós, e começamos a trabalhar, o que resultou em um controlador simples que automatiza a configuração de túneis em servidores e ADC, bem como a configuração de PBR na pilha IP de servidores Linux.
 Fig. 10
Fig. 10Como escrevi, a migração foi concluída, o cliente conseguiu o que queria - uma nova plataforma, simplicidade, flexibilidade, escalabilidade e, como resultado da mudança para uma sobreposição, simplificando a configuração do equipamento de rede como parte da manutenção desses serviços - em vez de várias cópias de tabelas virtuais e grandes domínios de transmissão, descobriu-se que - IP .
Colegas que trabalham com fabricantes de ADC, este parágrafo se concentra mais em você. Alguns de seus produtos são bons, mas tente prestar atenção à maior integração com aplicativos em servidores, à automação de suas configurações e à orquestração de todo o processo de desenvolvimento e operação. Isso me parece na forma de uma interação clássica entre controlador e agente, fazendo alterações no ADC, o usuário inicia o apelo do controlador aos agentes registrados, foi o que fizemos com o cliente, mas "pronto para uso".Além disso, alguns clientes podem achar conveniente mudar de um modelo PULL de interação com servidores para um modelo PUSH. Os recursos do aplicativo nos servidores são muito amplos; portanto, às vezes é mais fácil organizar uma verificação específica do aplicativo no serviço, no próprio agente. Se a verificação der um resultado positivo, o agente transmitirá informações, por exemplo, de forma semelhante à Comunidade de custo do BGP, para uso em algoritmos de cálculo ponderado.Freqüentemente, diferentes departamentos da organização realizam a manutenção do servidor e do ADC; a mudança para um modelo de interação PUSH pode ser interessante porque esse modelo elimina a necessidade de coordenação entre os departamentos em uma interface humano-a-humano. Os serviços dos quais o servidor participa podem ser transferidos diretamente do agente para o ADC na forma de algo semelhante ao avançado BGP Flow-Spec.Há muito mais para escrever. Por que estou com tudo isso? Sendo uma escolha livre, tomamos uma decisão em favor de uma opção mais conveniente, mais adequada ou a favor de uma opção que expande a janela de oportunidade para minimizar nossos riscos. Grandes players da indústria da Internet inventam algo completamente inovador para resolver seus problemas, algo que dita amanhã, players menores e empresas com experiência em desenvolvimento de software usam cada vez mais tecnologias e produtos que permitem uma personalização profunda. Muitos fabricantes de balanceadores de carga observam uma diminuição na demanda por seus produtos. Em outras palavras, os servidores e aplicativos executados neles, comutadores e roteadores há algum tempo, já mudaram qualitativamente e entraram na era SDN. Os balanceadores estão no limiardê esse passo enquanto a porta estiver aberta; caso contrário, você corre o risco de perder vantagem competitiva e se mudar para a periferia.