Olá pessoal!
Hoje vou lhe contar como nós do
hh.ru consideramos estatísticas manuais sobre experimentos. Vamos ver de onde vêm os dados, como os processamos e quais as armadilhas que encontramos. Neste artigo, compartilharei uma arquitetura e uma abordagem comuns, haverá um mínimo de scripts e códigos reais. O público principal são analistas iniciantes interessados na estrutura da infraestrutura de análise de dados em hh.ru. Se este tópico for interessante - escreva nos comentários, podemos nos aprofundar no código nos seguintes artigos.
Você pode ler sobre como as métricas automáticas para experimentos A / B são consideradas em nosso
outro artigo .

Quais dados analisamos e de onde eles vêm
Analisamos logs de acesso e quaisquer logs personalizados que escrevemos por nós mesmos.
95.108.213.12 - - [13 / Ago / 2018: 04: 00: 02 +0300] GET de 200 "/ empregador / 2574971 HTTP / 1.1" 12012 "-" "Mozilla / 5.0 (compatível; YandexBot / 3.0; + http: / /yandex.com/bots) "" - "" gardabani.headhunter.ge "" 0.063 "-" "1534122002.858" - "192.168.2.38:1500" "[0.064]" {15341220027959c8c01c51a6e01b682f} 200 https 1 - " - "- - [35827] [0,000 0]
178.23.230.16 - - [13 / Ago / 2018: 04: 00: 02 +0300] 200 "GET / vacancy / 24266672 HTTP / 1.1" 24229 " hh.ru/vacancy/24007186?query=bmw " "Mozilla / 5.0 ( Macintosh; Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML, como Gecko) Versão / 10.1.2 Safari / 603.3.8 "-" "hh.ru" "0.210" "last_visit = 1534111115966 :: 1534121915966; hhrole = anônimo; regiões = 1; tmr_detect = 0% 7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558 "" 1534122002.859 "" - "" 192.168.2.239:1500 "" [0.208] "{1534122002649b7eef2e901d8c9c0469} 200 https 1 -" - "- - [35927] [0,001 0]
Em nossa arquitetura, cada serviço grava logs localmente e, em seguida, através dos logs cliente-servidor auto-gravados (incluindo logs de acesso nginx) são coletados em um repositório central (a seguir denominado log). Os desenvolvedores têm acesso a esta máquina e podem registrar manualmente os logs, se necessário. Mas como, em um tempo razoável, pode devolver centenas de gigabytes de logs? Claro, coloque-os no hadoop!
De onde vêm os dados no hadoop?
O Hadoop não apenas armazena logs de serviço, mas também carrega o banco de dados prod. Todos os dias no hadoop, carregamos algumas das tabelas necessárias para análise.
Os logs de serviço entram no hadoop de três maneiras.
- Caminho para a testa - o cron é iniciado a partir do armazenamento de logs à noite e o rsync carrega os logs brutos nos hdfs.
- O caminho está na moda - os logs dos serviços são despejados não apenas no armazenamento comum, mas também no kafka, onde o flume os lê, faz o pré-processamento e os salva em hdfs.
- O caminho é antiquado - nos dias anteriores ao kafka, escrevemos nosso próprio serviço, que lê logs brutos do repositório, faz o pré-processamento e o carrega em hdfs.
Vamos considerar cada abordagem em mais detalhes.
Caminho da testa
Cron executa um script bash regular.
Como lembramos, no repositório de logs todos os logs estão na forma de arquivos comuns, a estrutura de pastas é aproximadamente a seguinte: /logging/java/2018/08/08/10/{service_nameasure/*.log
O Hadoop armazena seus arquivos aproximadamente na mesma estrutura de pastas hdfs-raw / banner-versions / year = 2018 / month = 08 / day = 10
ano, mês, dia que usamos como partições.
Portanto, precisamos apenas formar os caminhos corretos (linhas 3-4) e, em seguida, selecionar todos os logs necessários (linha 6) e usar o rsync para preenchê-los no hadoop (linha 8).
As vantagens desta abordagem:- Desenvolvimento rápido
- Tudo é transparente e claro.
Contras:Maneira elegante
Como carregamos os logs no repositório com um script auto-escrito, era lógico estragar a capacidade de carregá-los não apenas no servidor, mas também no kafka.
Prós- Logs online (os logs no hadoop aparecem quando você preenche o kafka)
- Você pode fazer o pré-processamento
- Ele suporta bem a carga e você pode fazer upload de logs grandes
Contras- Configuração mais difícil
- Eu tenho que escrever código
- Mais partes do processo de fundição
- Monitoramento e análise de incidentes mais complicados
Maneira antiquado
Difere da moda apenas na ausência de kafka. Portanto, ele herda todas as desvantagens e apenas algumas das vantagens da abordagem anterior. Um serviço separado (ustats-uploader) em java lê periodicamente os arquivos necessários, os pré-processa e os envia para o hadoop.
Prós- Você pode fazer o pré-processamento
Contras- Configuração mais difícil
- Eu tenho que escrever código
E assim os dados entraram no hadoop e prontos para análise. Vamos parar um pouco e lembrar o que é o hadoop e por que centenas de gigabytes podem ser consumidos nele muito mais rapidamente que o grep comum.
Hadoop
O Hadoop é um armazém de dados distribuído. Os dados não estão em nenhum servidor separado, mas são distribuídos entre várias máquinas e também são armazenados não em uma instância, mas em várias - isso foi feito para garantir a confiabilidade. A base da velocidade do processamento de dados está em uma mudança na abordagem em comparação aos bancos de dados convencionais.
No caso de um banco de dados regular, extraímos dados e os enviamos para o cliente, que faz algum tipo de análise e retorna o resultado ao analista. Portanto, para contar mais rapidamente, precisamos ter muitos clientes e paralelizar solicitações (por exemplo, para dividir dados por meses - e cada cliente pode ler dados para seu mês).
No hadoop, o oposto é verdadeiro. Enviamos o código (exatamente o que queremos calcular) para os dados, e esse código é executado no cluster. Como sabemos, os dados estão em muitas máquinas, portanto, cada máquina executa apenas o código em seus dados e retorna o resultado ao cliente.
Muitos provavelmente já ouviram falar de
redução de
mapa , mas escrever código para análise não é muito conveniente e rápido, enquanto escrever em SQL é muito mais simples. Portanto, surgiram serviços que podem transformar o SQL em redução de mapa de forma transparente para o usuário, e o analista pode não suspeitar de como sua solicitação é realmente considerada.
No hh.ru, usamos o hive e presto para isso. O Hive foi o primeiro, mas estamos gradualmente migrando para o presto, porque é muito mais rápido para nossos pedidos. Como uma GUI, usamos matiz e zeppelin.
É mais conveniente considerar a análise em python no jupyter, pois isso permite que você a leia com um clique e seja executado corretamente nas tabelas do excel na saída, o que economiza muito tempo. Escreva nos comentários, este tópico chama para um artigo separado.
Vamos voltar às análises em si.
Como entender o que queremos considerar?
O gerente de produto veio com a tarefa de calcular os resultados do experimento
Enviamos um boletim informativo por e-mail, no qual enviamos vagas adequadas para o solicitante (todo mundo gosta dessas correspondências?). Decidimos mudar um pouco o design da carta e queremos entender se ela se tornou melhor. Para isso, consideraremos:
- o número de transições para vagas da carta;
- feedback após a transição
Deixe-me lembrá-lo de que tudo o que temos é log de acesso e banco de dados. Precisamos formular nossas métricas em termos de cliques no link.
Número de transições para uma vaga de uma carta
A transição é uma solicitação GET para
hh.ru/vacancy/26646861 . Para entender de onde veio a transição, adicionamos tags utm do formulário? Utm_source = email_campaign_123. Para solicitações GET no log de acesso, haverá informações sobre os parâmetros e podemos filtrar as transições apenas da nossa lista de correspondência.
O número de respostas após a transição
Aqui, poderíamos simplesmente calcular o número de respostas a vagas da newsletter, mas as estatísticas ficariam incorretas, porque as respostas poderiam ser afetadas por outra coisa, exceto por nossa carta, por exemplo, um anúncio no ClickMe foi comprado para uma vaga e, portanto, o número de respostas. muito crescido.
Temos duas opções para formular o número de respostas:
- A resposta é um POST em hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861 , que possui um referenciador hh.ru/vacancy/26646861?utm_source=email_campaign_123 .
- A nuance dessa abordagem é que, se o usuário mudar para uma vaga e, em seguida, percorrer o site um pouco e responder a uma vaga, não contaremos.
- Podemos lembrar o ID do usuário que mudou para hh.ru/vacancy/26646861 e calcular o número de avaliações da vaga durante o dia com base no banco de dados.
A escolha da abordagem é determinada pelos requisitos de negócios, geralmente a primeira opção é suficiente, mas tudo depende do que o gerente de produto está esperando.
Armadilhas que podem ocorrer
- Nem todos os dados estão no hadoop, você precisa adicionar dados do banco de dados prod. Por exemplo, nos logs geralmente apenas o ID e, se você precisar de um nome - ele estará no banco de dados. Às vezes, você precisa procurar um usuário por resume_id, e isso também é armazenado no banco de dados. Para fazer isso, descarregamos parte do banco de dados no hadoop para que a junção seja mais simples.
- Os dados podem ser curvas. Isso geralmente é um desastre para o hadoop e a maneira como carregamos dados nele. Dependendo dos dados, um valor vazio pode ser nulo, Nenhum, nenhum, uma sequência vazia etc. Você precisa ter cuidado em cada caso, porque os dados são realmente diferentes, carregados de maneiras diferentes e para propósitos diferentes.
- Contagem longa para todo o período. Por exemplo, precisamos calcular nossas transições e respostas para o mês. Isso representa aproximadamente 3 terabytes de logs. Até o hadoop leva isso por algum tempo. Normalmente, escrever uma solicitação de trabalho 100% na primeira vez é bastante difícil, por isso, escrevemos por tentativa e erro. Cada tempo para esperar 20 minutos é muito longo. Maneiras de resolver:
- Depurando a solicitação nos logs em 1 dia. Como particionamos os dados no hadoop, é muito rápido calcular algo para 1 dia de logs.
- Faça o upload dos logs necessários para a tabela temporária. Como regra, entendemos em quais URLs estamos interessados e podemos criar uma tabela temporária para os logs dessas URLs.
Pessoalmente, a primeira opção é mais conveniente para mim, mas, às vezes, preciso fazer uma tabela temporária, depende da situação. - Distorções nas métricas finais
- É melhor filtrar os logs. Você precisa prestar atenção, por exemplo, ao código de resposta, redirecionar etc. Melhor menos dados, mas mais precisos, dos quais você tem certeza.
- O menor número possível de etapas intermediárias na métrica. Por exemplo, alternar para uma vaga é uma etapa (solicitação GET para / vacancy / 123). A resposta é duas (transição para vaga + POST). Quanto menor a cadeia, menos erros e mais precisa a métrica. Às vezes acontece que os dados entre transições são perdidos e geralmente é impossível calcular algo. Para resolver esse problema, precisamos pensar sobre o que consideraremos e como antes de desenvolver um experimento. Seu log separado de eventos necessários ajuda muito. Podemos filmar os eventos necessários e, portanto, a cadeia de eventos será mais precisa e a contagem será mais fácil.
- Bots podem gerar várias transições. Você precisa entender para onde os robôs podem ir (por exemplo, nas páginas onde a autorização é necessária, eles não deveriam estar) e filtrar esses dados.
- Grandes inchaços - por exemplo, em um dos grupos, pode haver um candidato, o que gera 50% de todas as respostas. Haverá uma distorção das estatísticas, esses dados também precisam ser filtrados.
- É difícil formular o que considerar em termos de log de acesso. Isso ajuda o conhecimento da base de código, experiência e ferramentas de desenvolvimento do chrome. Lemos a descrição da métrica do produto, repetimos com as mãos no site e vemos quais transições são geradas.
Por fim, vamos falar sobre como deve ser o resultado dos cálculos.
Resultado do cálculo
No nosso exemplo, existem 2 grupos e 2 métricas que formam um funil.
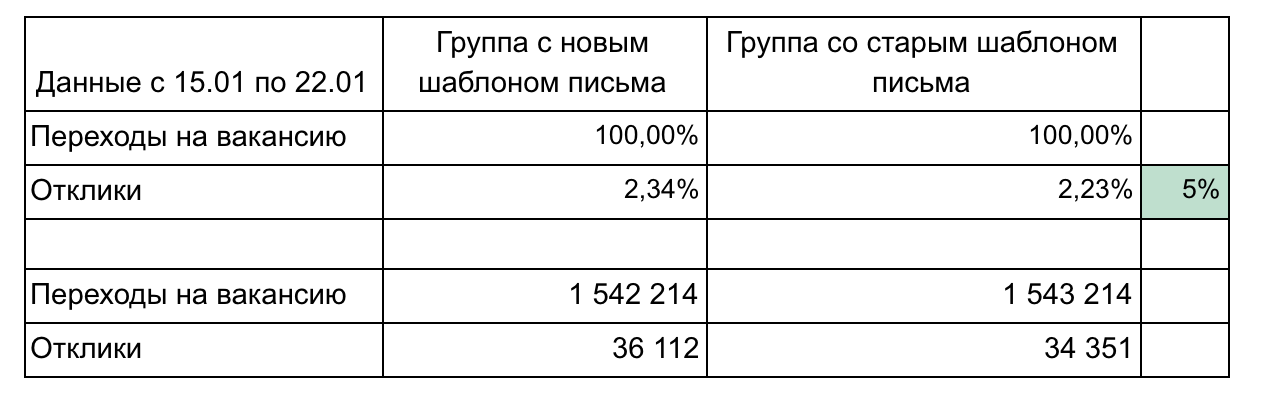
Recomendações para relatar resultados:
- Não sobrecarregue as peças até que seja necessário. Simples e menor é melhor (por exemplo, aqui podemos mostrar cada vaga separadamente ou cliques por dia). Concentre-se em uma coisa.
- Detalhes podem ser necessários durante os resultados da demonstração, portanto, pense sobre quais perguntas você pode fazer e prepare os detalhes. (No nosso exemplo, o detalhamento pode estar de acordo com a velocidade de transição após o envio do email - 1 dia, 3 dias, por semana, agrupando as vagas por área profissional)
- Lembre-se da significância estatística. Por exemplo, uma alteração de 1% com 100 cliques e 15 cliques é insignificante e pode ser aleatória. Use calculadoras
- Automatize o máximo possível, porque você terá que contar várias vezes. Geralmente, no meio de um experimento, já se quer entender como estão as coisas. Após o experimento, perguntas podem surgir e você terá que esclarecer alguma coisa. Assim, será necessário contar de 3 a 4 vezes e, se cada cálculo for uma sequência de 10 consultas e, em seguida, uma cópia manual para o Excel, isso prejudicará e passará muito tempo. Aprenda python, ele economizará uma tonelada de tempo.
- Use uma representação gráfica dos resultados quando necessário. As ferramentas incorporadas de colmeia e zeppelin permitem criar gráficos simples imediatamente.
É necessário considerar várias métricas com bastante frequência, porque emitimos quase todas as tarefas como parte de um experimento A / B. Não há nada complicado nos cálculos; após 2-3 experimentos, é possível entender como fazer isso. Lembre-se de que os logs de acesso armazenam muitas informações úteis que podem economizar dinheiro das empresas, ajudar a promover sua ideia e provar qual das opções de alteração é melhor. O principal é ser capaz de obter essas informações.