TL; DR : o autor compilou um coletor NetFlow / sFlow da GoFlow , Kafka , ClickHouse , Grafana e uma muleta no Go.
Olá, sou um explorador e gosto muito de saber o que está acontecendo na infraestrutura. E também gosto de entrar nos assuntos de outras pessoas, e dessa vez entrei na rede.
Suponha que você tenha seu próprio equipamento de rede e um conjunto de monólitos, microsserviços e monólitos de microsserviços aderindo à Internet com suas dependências na forma de bancos de dados, caches e servidores FTP. E, às vezes, alguns habitantes desta bolsa começam a brincar de malcriado em rede.
Aqui estão apenas alguns exemplos dessas brincadeiras:
- backup fora da janela prescrita em 40 fluxos;
- erros de configuração ao enviar um aplicativo em um controlador de domínio para o cache de outro controlador de domínio;
- as perguntas do aplicativo no próximo rack para o mesmo cache "fornecem-me esse objeto de meio megabyte do cache" duzentas vezes por segundo.
Os contadores SNMP das portas do switch ou VMs fornecerão apenas uma compreensão aproximada do que está acontecendo, mas desejo precisão e velocidade na análise de problemas. Os protocolos NetFlow / IPFIX e sFlow vêm em socorro, o que gera informações de tráfego avançadas diretamente do equipamento de rede. Resta colocá-lo em algum lugar e processá-lo de alguma forma.
Dos coletores NetFlow disponíveis, o seguinte foi considerado:
- ferramentas de fluxo - não gostei do armazenamento em arquivos (demorou muito tempo para fazer seleções, especialmente operacionais durante a reação ao incidente) ou MySQL (ter uma tabela de bilhões de linhas parece uma idéia bastante sombria);
- O Elasticsearch + Logstash + Kibana é um grupo que consome muitos recursos, até 6 núcleos da CPU antiga de 2,2 GHz para receber 5000 fluxos por segundo. No entanto, o Kibana permite que você cole qualquer tipo de filtro no navegador, o que é valioso;
- vflow - não gostou do formato de saída (JSON, que sem modificação não pode ser adicionado à mesma Elasticsearch);
- soluções in a box - não gostou do preço alto ou da pequena diferença em relação ao selecionado.
E foi escolhido descrito na apresentação de Louis Poinsignon no RIPE 75 . O esquema geral de um coletor simples é o seguinte:
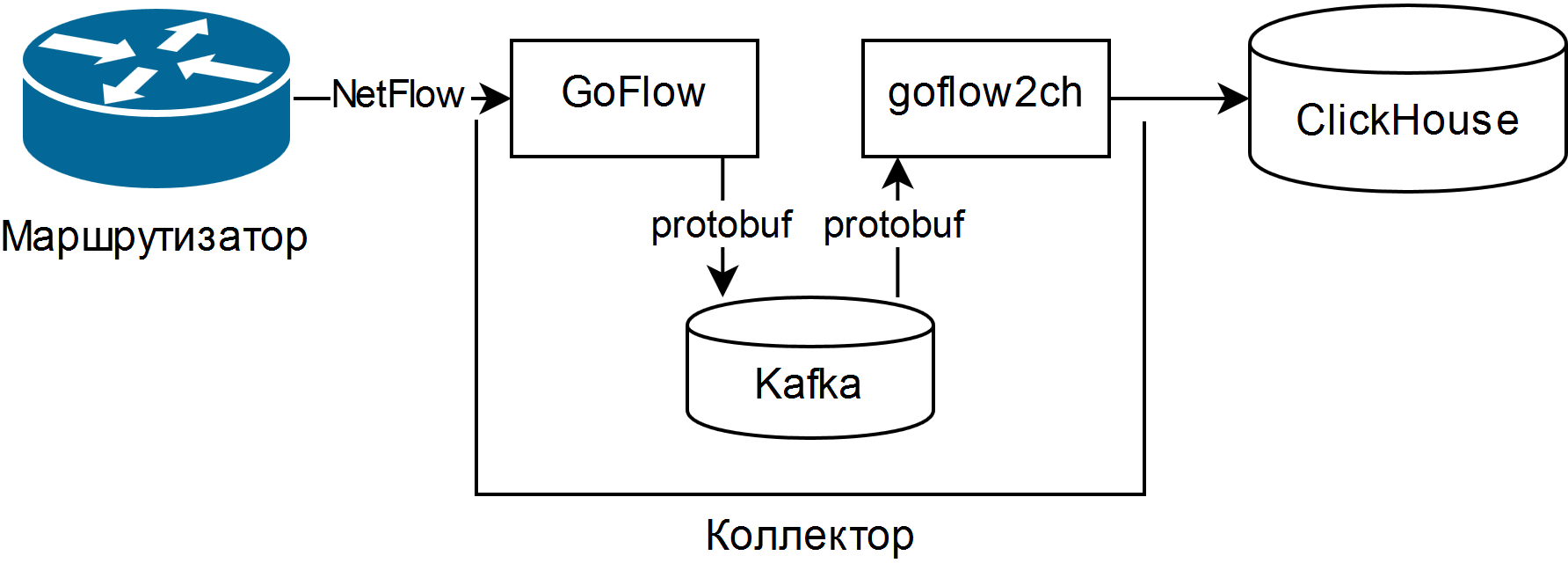
O GoFlow analisa pacotes NetFlow / sFlow e os coloca em um Kafka local no formato protobuf. O "shovel" auto-escrito goflow2ch pega as mensagens da Kafka e as transfere para a Clickhouse em lotes para aumentar a produtividade. O esquema não trata de maneira alguma a questão da alta disponibilidade, mas para cada componente há maneiras externas regulares ou mais ou menos simples de fornecê-lo.
Testes mostraram que os custos de CPU para analisar e manter os mesmos 5000 threads por segundo representam cerca de um quarto do núcleo da CPU, e o espaço em disco usado é de 11 a 14 bytes por fluxo ligeiramente truncado.
Para exibir informações, é usada a interface da Web da Web para ClickHouse chamada Tabix ou o plugin para Grafana .
As vantagens do esquema:
- a capacidade de fazer perguntas arbitrárias sobre o estado da rede usando o dialeto SQL;
- baixos requisitos de recursos e escalabilidade horizontal. Processadores antigos / lentos e discos rígidos magnéticos servirão;
- se necessário, um pipeline de dados completo é coletado para analisar os eventos da rede, inclusive em tempo real, usando Kafka Streams, Flink ou análogos;
- a capacidade de alterar o armazenamento para qualquer meio mínimo.
As desvantagens também são decentes:
- Para fazer perguntas, você precisa conhecer bem o SQL e seu dialeto ClickHouse: não há relatórios e gráficos prontos;
- muitas novas peças móveis na forma de Kafka, Zookeeper e ClickHouse. Os dois primeiros estão em Java, o que pode causar rejeição religiosa. Para mim, pessoalmente, isso não foi um problema, pois tudo isso já foi de alguma forma usado na organização;
- tem que escrever código. Uma “pá” transferindo dados do Kafka para o ClickHouse ou um adaptador para gravar diretamente do GoFlow.
Recursos encontrados:
- Certifique-se de ajustar a rotação de acordo com o tamanho dos dados no Kafka e ClickHouse e verifique se realmente funciona. No Kafka, há um limite para o tamanho da partição de log e no ClickHouse - particionamento por uma chave arbitrária. Uma nova partição a cada hora e a remoção de partições desnecessárias a cada 10 minutos funcionam bem para o monitoramento operacional e são criadas um script com apenas algumas linhas;
- O "pá" se beneficia do uso de grupos de consumidores , permitindo adicionar mais "pás" para tolerância de escala e falha;
- O Kafka permite que você não perca dados quando a "pá" ou o ClickHouse trava (por exemplo, devido a uma solicitação pesada e / ou recursos limitados incorretamente), mas é melhor, é claro, configurar cuidadosamente o banco de dados;
- se você coletar o sFlow, lembre-se de que alguns comutadores, por padrão, alteram a taxa de amostragem de pacotes em movimento e isso é indicado para cada fluxo.
Como resultado, foi obtida uma ferramenta para monitorar a situação da rede tanto em mais ou menos em tempo real e na perspectiva histórica a partir de componentes de código aberto e fita isolante azul. Apesar da profundidade do joelho, ele já ajudou a reduzir o tempo para resolver vários incidentes às vezes.