
Hoje é 27 de setembro, o que
significa que, durante o horário de trabalho (de acordo com o fuso horário dos EUA), podemos esperar o próximo lançamento do Kubernetes - 1.12 (no entanto, seu anúncio oficial às vezes é adiado). Em geral, é hora de continuar a gloriosa tradição e contar as mudanças mais significativas que faremos com base nas informações públicas do projeto: o
Kubernetes apresenta a tabela de rastreamento ,
CHANGELOG-1.12 , numerosos problemas, solicitações de
recebimento e propostas de design. Então, o que há de novo no K8s 1.12?
Instalações de armazenamento
Se você destacar uma coisa mencionada com mais frequência do que qualquer outra dentre todas as questões relacionadas ao lançamento do Kubernetes 1.12, talvez seja a
CSI (Container Storage Interface) , que
já escrevemos sobre o outro dia. Por esse motivo, vamos começar com as alterações no suporte de armazenamento.
Dessa forma
, os plug-ins CSI mantêm o status beta e espera-se que sejam estáveis para a próxima versão do Kubernetes (1.13). O que há de novo no suporte CSI?
Em fevereiro deste ano
, o trabalho sobre o
conceito de topologia começou na própria especificação CSI. Em resumo, topologia são informações sobre segmentação de cluster (por exemplo, por "racks" para instalações locais ou por "regiões" e "zonas" para ambientes em nuvem), que os sistemas de orquestração precisam conhecer e levar em consideração. Porque Os volumes alocados pelos provedores de armazenamento não serão necessariamente igualmente acessíveis em todo o cluster e, portanto, o conhecimento da topologia é necessário para planejar com eficiência os recursos e tomar decisões de provisionamento.
O resultado do surgimento de topologias no CSI (
adotado na especificação em 1º de junho) foi o suporte no Kubernetes 1.12:
Mas isso não termina com atualizações relacionadas ao CSI. Outra inovação importante na versão Kubernetes 1.12 é o
suporte para snapshots para CSI (enquanto no status alfa). As
capturas instantâneas de volumes apareceram no
lançamento do K8s 1.8 . A implementação principal, que inclui o controlador e o provisionador (dois binários separados), foi decidida como transferida para
um repositório externo . Desde então, foi adicionado suporte a volumes do GCE PD, AWS EBS, OpenStack Cinder, GlusterFS e Kubernetes
hostPath .
A nova
proposta de design visa "continuar esta iniciativa adicionando suporte de captura instantânea para drivers de volume CSI" (o suporte de captura instantânea na especificação CSI é descrito
aqui ). Como o Kubernetes segue o princípio de incluir um conjunto mínimo de recursos na API principal, essa implementação (como para instantâneos no Volume Snapshot Controller) usa CRD (
CustomResourceDefinitions ).
E alguns novos recursos para drivers CSI:
- A versão alfa da capacidade do driver de se registrar na API do Kubernetes (para facilitar a localização de drivers instalados no cluster e permitir que os drivers influenciem os processos de interação do Kubernetes com eles);
- A versão alfa da capacidade do driver de receber informações sobre a unidade que está solicitando o volume através do
NodePublish .
Introduzido na última versão do Kubernetes, o
mecanismo para limitar dinamicamente os volumes nos nós mudou de alfa para beta,
recebendo ... você adivinhou, suporte para CSI e Azure.
Finalmente, o recurso de
propagação de espaço para nome Mount , que permite montar o volume como
rshared (para que todos os diretórios de contêineres montados fiquem visíveis no host) e tenha um status beta na versão
K8s 1.10 , é declarado estável.
Planejador
No planejador, o Kubernetes 1.12 melhora o desempenho graças à versão alfa do
mecanismo de restrição de pesquisa em um cluster de nós adequado para agendar lares
(nós viáveis) . Se antes, para cada tentativa de planejar cada pod, o
kube-scheduler verificou a disponibilidade de todos os nós e os passou para avaliação, agora o planejador encontrará apenas um certo número deles e interromperá o trabalho. Ao mesmo tempo, o mecanismo prevê a seleção obrigatória de nós de diferentes regiões e zonas, bem como a necessidade de visualizar nós diferentes em diferentes ciclos de planejamento (não selecione os 100 primeiros nós a cada início). A decisão de implementar esse mecanismo foi tomada, guiada pelos resultados da análise de dados sobre o desempenho do agendador (se o percentil 90 mostrou um tempo de 30 ms para uma lareira, então o percentil 99 já tinha 60 ms).
Além disso, os seguintes recursos do planejador foram aprimorados para a versão beta:
- Manuseie o nó por Condição , que apareceu no K8s 1.8 e permite marcar um nó com um certo status (para ações posteriores) quando certos eventos ocorrerem: agora o controlador do ciclo de vida do nó cria automaticamente manchas, e o planejador as verifica (em vez de condições );
- Planejamento da lareira no
DaemonSet usando o kube-scheduler (em vez do controlador DaemonSet ): também foi ativado por padrão; - especificando uma classe de prioridade em
ResourceQuota .
Nós de cluster
Uma inovação interessante foi a aparência (no status da versão alfa) do
RuntimeClass - um novo recurso em nível de cluster projetado para atender aos parâmetros do
tempo de execução do
contêiner (tempo de execução do contêiner) .
RuntimeClasses são atribuídos aos pods pelo mesmo campo no
PodSpec e implementam suporte para o uso de vários ambientes executáveis em um cluster ou nó. Porque
“O interesse em usar diferentes tempos de execução em um cluster está crescendo. No momento, o principal motivador disso são as caixas de areia e o desejo dos contêineres Kata e gVisor de se integrar ao Kubernetes. Outros modelos de tempo de execução, como contêineres do Windows ou mesmo ambientes de tempo de execução remoto, também precisarão de suporte no futuro. O RuntimeClass oferece uma maneira de escolher entre diferentes tempos de execução configurados em um cluster e alterar suas propriedades (tanto pelo cluster quanto pelo usuário). ”
Para escolher entre as configurações predefinidas, o
RuntimeHandler passado para o CRI (Container Runtime Interface), que visa substituir as anotações atuais da lareira:

E a configuração em containsererd para kata-runtime é mais ou menos assim:
[plugins.cri.containerd.kata-runtime] runtime_type = "io.containerd.runtime.v1.linux" runtime_engine = "/opt/kata/bin/kata-runtime" runtime_root = ""
O critério
RuntimeClass para a versão alfa é uma
validação de CRI bem-sucedida.
Além disso, o
mecanismo para registrar plug-ins locais (incluindo CSI) no
Kubelet e
shareProcessNamespace (o recurso foi ativado por padrão) aumentou para o status de uma versão beta.
Redes
As principais notícias na parte de rede do Kubernetes são a
versão alfa do suporte ao
SCTP (Protocolo de Controle de Transmissão de Controle de Fluxo). Tendo recebido suporte em
Pod ,
Service ,
Endpoint e
NetworkPolicy , esse protocolo de telecomunicações se juntou às fileiras de TCP e UDP. Com o novo recurso “aplicativos que requerem SCTP como protocolo L4 para suas interfaces, será mais fácil implantar em clusters Kubernetes; por exemplo, eles poderão usar a descoberta de serviços com base no
kube-dns , e sua interação será controlada pelo
NetworkPolicy . " Os detalhes da implementação estão disponíveis
neste documento .
Dois recursos de rede introduzidos no K8s 1.8 também alcançaram status estável:
suporte a políticas para o tráfego
EgressRules saída na API NetworkPolicy e
aplicação de regras CIDR para origem / destino via
ipBlockRule .
Dimensionamento
As melhorias no autoscaler de pod horizontal incluem:
O
dimensionamento vertical das lareiras , que antes de chegar à versão beta carecia de teste do usuário, não fica parado. Os autores consideraram suficiente para o lançamento do K8s 1.12 e
lembram que esse recurso é provavelmente uma adição ao Kubernetes (não incluído no kernel). Todo o desenvolvimento é realizado em um repositório separado, no qual a versão beta será programada para coincidir com a versão do Kubernetes.
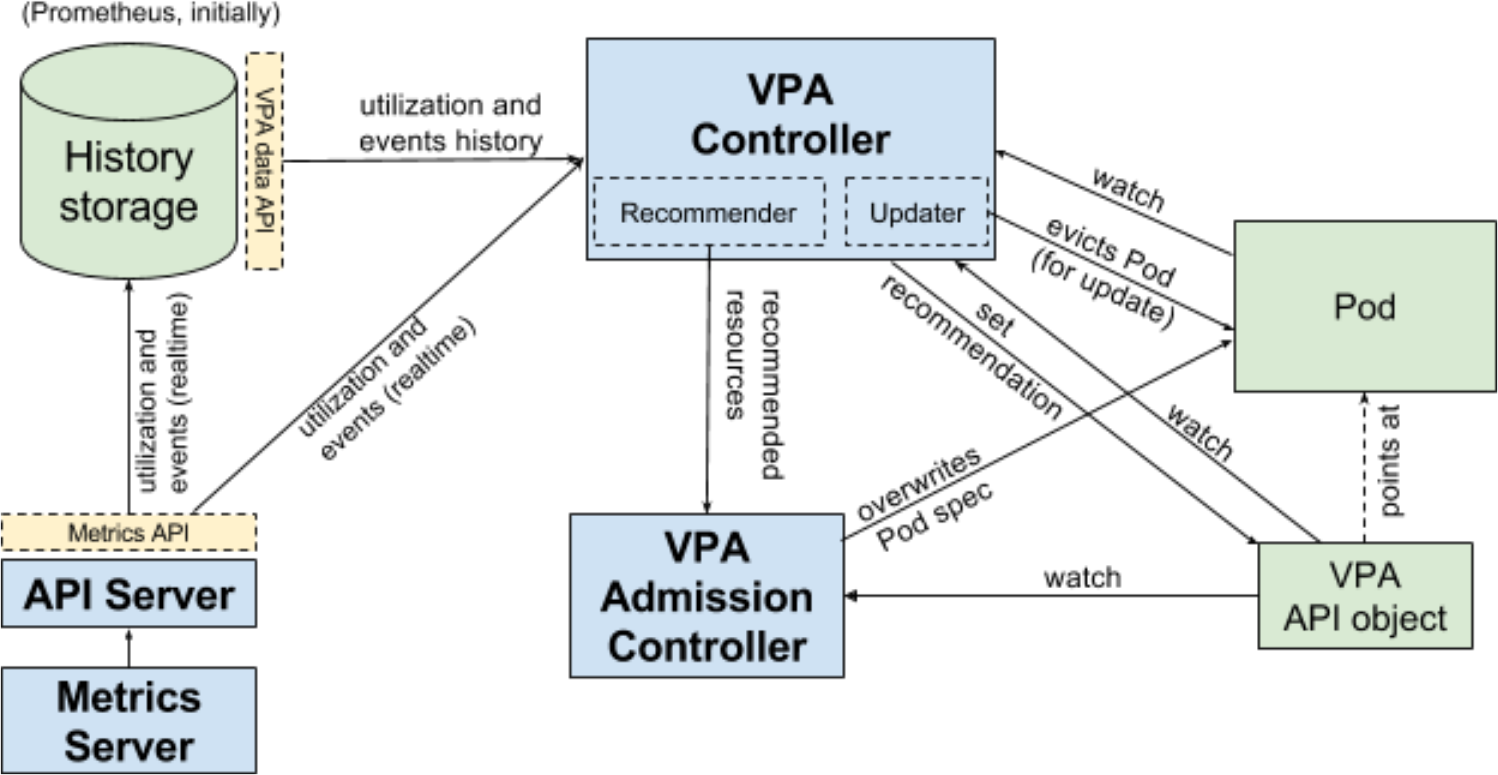 Fluxo de trabalho de autoscaler de pod vertical (VPA) para Kubernetes
Fluxo de trabalho de autoscaler de pod vertical (VPA) para KubernetesFinalmente, o K8s 1.12 inclui (em formato alfa) os resultados do
trabalho sobre "simplificar a instalação usando o
ComponentConfig " (como parte do ciclo de vida do sig-cluster), que está em andamento há quase dois anos. Infelizmente, por algum motivo (uma simples supervisão?), O acesso ao
documento da proposta de design com detalhes é fechado para usuários anônimos.
Outras mudanças
API
Dois novos recursos são implementados no grupo api-machinery:
dry-run para apiserver (versão alfa), que imita a validação e processamento de solicitações;- API de cota de recursos (beta imediatamente) que define recursos limitados por padrão (em vez do comportamento atual quando o consumo de recursos é ilimitado se uma cota não estiver definida).
Azure
Estável declarado:
As primeiras implementações (versões alfa) são adicionadas:
Kubectl
- Uma versão alfa do mecanismo de plug-in atualizado foi implementada, o que permite adicionar novos comandos ou reescrever subcomandos existentes de qualquer nível de aninhamento. Ele é semelhante ao Git e examina os executáveis que começam com
kubectl- no $PATH do usuário. Veja a proposta de design para mais detalhes. - Uma versão beta da idéia de isolar o
pkg/kubectl/genericclioptions do kubectl em um repositório independente foi implementada. - A função de impressão no servidor foi declarada estável.
Outros
- É apresentada a versão alfa do novo mecanismo TTL após o término , projetado para limitar a vida útil dos trabalhos e pods que concluíram a execução. Depois que o TTL especificado expirar, os objetos serão limpos automaticamente sem a necessidade de intervenção do usuário.
- A geração de uma chave privada e CSR (TLS Bootstrap) para assinar um certificado no nível do cluster no Kubelet é declarada estável.
- A rotação do certificado TLS do servidor no Kubelet entrou no status beta.
PS
Leia também em nosso blog: