Começamos
a estudar os Grupos de Controle (Cgroups) no Red Hat Enterprise Linux 7 - um mecanismo no nível do kernel que permite controlar o uso dos recursos do sistema, examinamos brevemente os fundamentos teóricos e agora passamos à prática de gerenciar recursos de CPU, memória e E / S.
No entanto, antes de alterar qualquer coisa, é sempre útil descobrir como tudo está organizado agora.
Existem duas ferramentas com as quais você pode ver o status dos cgroups ativos no sistema. Em primeiro lugar, este é systemd-cgls - um comando que exibe uma lista semelhante a uma árvore de cgroups e processos em execução. Sua saída é algo como isto:
Aqui vemos os cgroups de nível superior: user.slice e system.slice. Como não temos máquinas virtuais, portanto, sob carga, esses grupos de nível superior recebem 50% dos recursos da CPU (já que a fatia da máquina não está ativa). Há duas fatias filho no user.slice: user-1000.slice e user-0.slice. As fatias do usuário são identificadas pelo ID do usuário (UID), portanto, pode ser difícil identificar o proprietário, exceto para processos em execução. No nosso caso, as sessões ssh mostram que o usuário 1000 é mrichter e o usuário 0 é root, respectivamente.
O segundo comando que usaremos é systemd-cgtop. Ele mostra uma imagem do uso de recursos em tempo real (a saída do systemd-cgls, a propósito, também é atualizada em tempo real). Na tela, parece algo como isto:
Há um problema no systemd-cgtop - ele mostra estatísticas apenas para os serviços e as fatias para os quais a contabilidade de uso de recursos está ativada. A contabilidade é ativada criando arquivos conf drop-in nos subdiretórios apropriados em / etc / systemd / system. Por exemplo, o menu suspenso na captura de tela abaixo permite o uso de CPU e memória para o serviço sshd. Para fazer isso sozinho, basta criar o mesmo drop-in em um editor de texto. Além disso, a contabilidade também pode ser ativada com o comando systemctl set-property sshd.service CPUAccounting = true comando MemoryAccounting = true.
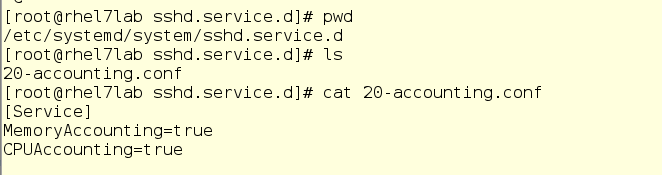
Após criar o drop-in, você deve inserir o comando systemctl daemon-reload, bem como o comando systemctl restart <service_name> para o serviço correspondente. Como resultado, você verá estatísticas sobre o uso de recursos, mas isso criará uma carga adicional, uma vez que os recursos também serão gastos em contabilidade. Portanto, a contabilidade deve ser incluída com cuidado e apenas para os serviços e grupos que precisam ser monitorados dessa maneira. No entanto, geralmente em vez de systemd-cgtop, você pode fazer com os comandos top ou iotop.
Troque as bolas da CPU por diversão e utilidade
Agora vamos ver como uma alteração na esfera do processador (compartilhamentos de CPU) afeta o desempenho. Por exemplo, teremos dois usuários não privilegiados e um serviço do sistema. O usuário com o login mrichter possui um UID de 1000, que pode ser verificado usando o arquivo / etc / passwd.
Isso é importante porque as fatias do usuário são nomeadas pelo UID e não pelo nome da conta.
Agora, vamos examinar o diretório suspenso e ver se já existe algo para sua fatia.
Não, não há nada. Embora exista algo mais - dê uma olhada nas coisas relacionadas ao foo.service:
Se você estiver familiarizado com os arquivos de unidade systemd, verá aqui um arquivo de unidade completamente comum que executa o comando / usr / bin / sha1sum / dev / zero como um serviço (em outras palavras, um daemon). Para nós, o importante é que o foo demore literalmente todos os recursos do processador que o sistema lhe permitirá usar. Além disso, aqui temos uma configuração drop-in para o serviço foo com o valor de bolas de CPU igual a 2048. Por padrão, como você se lembra, ele é usado com o valor 1024, portanto, em load foo receberá um compartilhamento duplo de recursos da CPU em system.slice , sua fatia de nível superior principal (já que foo é um serviço).
Agora execute foo no systemctl e veja o que o comando top nos mostra:
Como praticamente não existem outras coisas funcionando no sistema, o serviço foo (pid 2848) consome quase todo o tempo do processador de uma CPU.
Agora vamos introduzir mrichter na equação do usuário. Primeiro, cortamos uma bola de CPU para 256, depois ele faz o login e inicia o foo.exe, ou seja, o mesmo programa, mas como um processo do usuário.
Então mrichter lançou foo. E aqui está o que o comando top mostra agora:
Estranho, né? O usuário mrichter parece ter cerca de 10% do tempo do processador, já que ele tem = 256 bolas e foo.service tem até 2048, não?
Agora, introduzimos o dorf na equação. Este é outro usuário comum com uma bola de CPU padrão igual a 1024. Ele também rodará também, e novamente veremos como a distribuição do tempo do processador mudará.
dorf é um usuário da velha escola, ele apenas inicia o processo, sem scripts inteligentes ou qualquer outra coisa. E, novamente, analisamos a saída do top:
Então ... vamos dar uma olhada na árvore do cgroups e tentar descobrir o que é o que:
Se você se lembra, geralmente em um sistema existem três cgroups de nível superior: Sistema, Usuário e Máquina. Como não há máquinas virtuais em nosso exemplo, apenas as fatias do sistema e do usuário permanecem. Cada um deles possui uma CPU-ball de 1024 e, portanto, sob carga, recebe metade do tempo do processador. Como o foo.service vive no System e não há outros candidatos para o tempo de CPU nessa fatia, o foo.service recebe 50% dos recursos da CPU.
Além disso, os usuários dorf e mrichter vivem na fatia Usuário. A primeira bola é 1024, a segunda - 256. Portanto, o dorf recebe quatro vezes mais tempo de processador que o mrichter. Agora vamos ver o que mostra o topo: foo.service - 50%, dorf - 40%, mrichter - 10%.
Traduzindo isso para um idioma de caso de uso, podemos dizer que o dorf tem uma prioridade mais alta. Conseqüentemente, os cgroups são configurados para que o usuário rico corte recursos durante o tempo necessário. De fato, apesar de tudo, enquanto mrichter estava no sistema sozinho, ele recebeu 50% do tempo do processador, uma vez que na fatia do usuário ninguém mais competia pelos recursos da CPU.
De fato, as esferas da CPU são uma maneira de fornecer um certo "mínimo garantido" de tempo do processador, mesmo para usuários e serviços com uma prioridade mais baixa.
Além disso, temos uma maneira de definir uma cota fixa para recursos da CPU, um certo limite em números absolutos. Faremos isso para o usuário Richrich e veremos como a distribuição de recursos muda.
Agora vamos matar as tarefas do usuário dorf, e aqui está o que acontece:
Para mrichter, o limite absoluto de CPU é de 5%, portanto, foo.service obtém o restante do tempo do processador.
Continue com o bullying e pare com o foo.service:
O que vemos aqui: mrichter possui 5% do tempo do processador e os 95% restantes do sistema estão ociosos. Zombaria formal, sim.
De fato, essa abordagem permite pacificar efetivamente serviços ou aplicativos que gostam de mudar repentinamente e puxar todos os recursos do processador para si, em detrimento de outros processos.
Então, aprendemos como controlar a situação atual com cgroups. Agora, nos aprofundamos um pouco mais e vemos como o cgroup é implementado no nível do sistema de arquivos virtual.
O diretório raiz para todos os cgroups em execução está localizado em / sys / fs / cgroup. Quando o sistema é inicializado, ele é preenchido quando os serviços e outras tarefas são iniciadas. Ao iniciar e parar serviços, seus subdiretórios aparecem e desaparecem.
Na captura de tela abaixo, fomos a um subdiretório do controlador da CPU, ou seja, na fatia do sistema. Como você pode ver, o subdiretório para foo ainda não está aqui. Execute foo e verifique algumas coisas, a saber, seu PID e sua esfera atual de CPU:
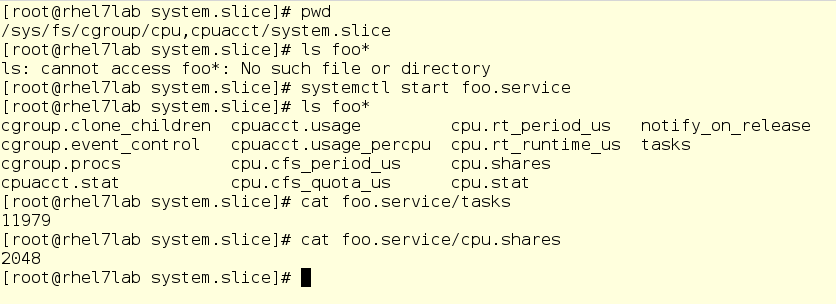
Advertência importante: aqui você pode alterar os valores em tempo real. Sim, em teoria, parece legal (e na realidade também), mas pode se transformar em uma grande bagunça. Portanto, antes de mudar qualquer coisa, avalie cuidadosamente tudo e nunca jogue em servidores de batalha. De qualquer forma, um sistema de arquivos virtual é algo para aprofundar à medida que você aprende como os cgroups funcionam.