A primeira edição do CTP do SQL Server 2019 foi apresentada em 24 de setembro, e devo dizer que está cheia de todos os tipos de melhorias e novos recursos (muitos dos quais podem ser encontrados no formulário de visualização no banco de dados SQL do Azure). Tive uma oportunidade excepcional de conhecer isso um pouco antes, o que me permitiu expandir meu entendimento das mudanças, mesmo que superficialmente. Você também pode ler as
publicações mais recentes da equipe do SQL Server e a
documentação atualizada .
Sem entrar em detalhes, discutirei os seguintes novos recursos do kernel: desempenho, solução de problemas, segurança, disponibilidade e desenvolvimento. No momento, tenho um pouco mais de detalhes do que outros, e alguns deles já estão preparados para publicação. Voltarei a esta seção, bem como a muitos outros artigos e documentação, e os publicarei. Apresso-me a informá-lo de que esta não é uma revisão abrangente, mas apenas uma parte da funcionalidade que eu consegui "tocar", até o CTP 2.0. Ainda há muito o que conversar.
Desempenho
Variáveis de tabela: construção do plano atrasado
As variáveis da tabela têm uma reputação não muito boa, principalmente no campo da estimativa de custos. Por padrão, o SQL Server supõe que uma variável de tabela possa conter apenas uma linha, o que às vezes leva a uma escolha inadequada de plano quando a variável contém muitas vezes mais linhas. OPTION (RECOMPILE) geralmente é usado como uma solução alternativa, mas isso requer alterações de código e é um desperdício, em relação aos recursos, executar a reconstrução sempre, enquanto o número de linhas geralmente é o mesmo. Para emular a reconstrução,
o sinalizador de rastreamento 2453 foi introduzido, mas também requer um lançamento com o sinalizador e só funciona quando ocorre uma alteração significativa nas linhas.
No nível de compatibilidade 150, a construção adiada é executada se houver variáveis da tabela e o plano de consulta não for construído até que a variável da tabela seja preenchida uma vez. O custo será estimado com base nos resultados do primeiro uso da variável de tabela, sem reconstrução adicional. Esse é um compromisso entre a reconstrução constante para obter o custo exato e a ausência completa de reconstrução com custo constante 1. Se o número de linhas permanecer relativamente constante, esse é um bom indicador (e melhor ainda se o número exceder 1), mas pode ser menos lucrativo se há uma grande variação no número de linhas.
Apresentei uma análise mais profunda em um artigo recente
Variáveis Tabulares: Compilação Atrasada no SQL Server , e Brent Ozar também falou sobre isso no artigo
Variáveis Tabulares Rápidas (E Novos Problemas de Análise de Parâmetros) .
Feedback de alocação de memória no modo String
O SQL Server 2017 possui um feedback de alocação de memória em lote, descrito em detalhes
aqui . Essencialmente, para qualquer alocação de memória associada a um plano de consulta que inclua instruções em modo de lote, o SQL Server avaliará a memória usada pela consulta e a comparará com a memória solicitada. Se a memória solicitada for muito pequena ou muito, o que levará a drenos no tempdb ou a um desperdício de memória, na próxima inicialização a memória alocada para o plano de consulta correspondente será ajustada. Esse comportamento reduzirá o volume alocado e expandirá a simultaneidade, ou aumentará, para melhorar o desempenho.
Agora, obtemos o mesmo comportamento para consultas no modo de string, no nível de compatibilidade 150. Se a consulta foi forçada a mesclar dados para o disco, para as partidas subsequentes, a memória alocada será aumentada. Se, após a conclusão da solicitação, metade da memória foi necessária e foi alocada, as solicitações subsequentes serão ajustadas. Bretn Ozar descreve isso com mais detalhes em seu artigo
Alocação condicional de memória .
Modo de lote para armazenamento linha por linha
A partir do SQL Server 2012, a consulta de tabelas com índices de coluna se beneficiou do desempenho aprimorado do modo em lote. As melhorias de desempenho são devidas a um processador de consultas que executa o processamento em lote e não em linhas. As linhas também são processadas pelo núcleo de armazenamento em pacotes, o que evita declarações de troca de simultaneidade. Paul White (
@SQL_Kiwi ) me lembrou que, se você usar uma tabela vazia com armazenamento de colunas para possibilitar operações em lote, as linhas processadas serão coletadas em pacotes por uma declaração invisível. No entanto, essa muleta pode negar qualquer melhoria recebida no processamento em lote. Algumas informações sobre isso estão na
resposta ao Stack Exchange .
No nível de compatibilidade 150, o SQL Server 2019 selecionará automaticamente o modo de lote como meio intermediário em certos casos, mesmo quando não houver índices de coluna. Você pode pensar que por que não criar um índice de coluna e um chapéu? Ou continua usando a muleta mencionada acima? Essa abordagem foi estendida aos objetos tradicionais com armazenamento baseado em linhas, porque nem sempre são possíveis índices de coluna, incluindo limitações funcionais (por exemplo, gatilhos), sobrecarga durante operações de atualização ou exclusão altamente carregadas e também a falta de suporte de fabricantes de terceiros. E nada de bom pode ser esperado dessa muleta.
Criei uma tabela muito simples com 10 milhões de linhas e um índice clusterizado em uma coluna inteira e executei esta consulta:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
O plano mostra claramente pesquisas de concorrência em cluster e simultaneidade, mas nenhuma palavra sobre o índice da coluna (como mostra o
SentryOne Plan Explorer ):
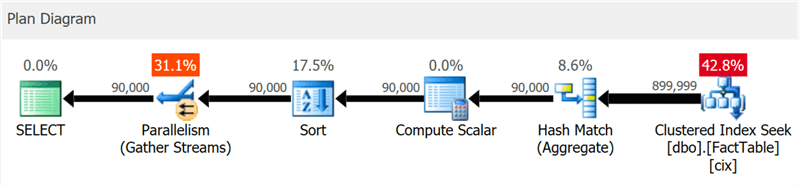
Porém, se você se aprofundar um pouco mais, poderá ver que quase todos os operadores foram executados no modo em lote, até mesmo cálculos de classificação e escalar:

Você pode desativar esse recurso mantendo um nível de compatibilidade mais baixo alterando a configuração do banco de dados ou usando o prompt DISALLOW_BATCH_MODE na consulta:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
Nesse caso, um operador de troca adicional aparece, todos os operadores são executados no modo linha por linha e o tempo de execução da consulta é quase triplicado.

Até um certo nível, você pode ver isso no diagrama, mas na árvore de detalhes do plano também pode ver a influência de uma condição de seleção que não pode excluir linhas até que a classificação ocorra:

A escolha do modo de lote nem sempre é uma boa etapa - a heurística incluída no algoritmo de tomada de decisão leva em consideração o número de linhas, os tipos de operadores propostos e os benefícios esperados do modo de lote.
APPROX_COUNT_DISTINCT
Essa nova função agregada destina-se a cenários de data warehousing e é equivalente a COUNT (DISTINCT ()). No entanto, em vez de executar classificações dispendiosas para determinar a quantidade real, a nova função depende de estatísticas para obter dados relativamente precisos. Você precisa entender que o erro está dentro de 2% da quantidade exata e, em 97% dos casos que são a norma para análises de alto nível, esses são os valores exibidos nos indicadores ou usados para estimativas rápidas.
No meu sistema, criei uma tabela com colunas inteiras que incluíam valores exclusivos no intervalo de 100 a 1.000.000 e colunas de linha, com valores exclusivos no intervalo de 100 a 100.000.Ele não tinha índices, exceto a chave primária em cluster na primeira coluna inteira. Aqui estão os resultados da execução de COUNT (DISTINCT ()) e APPROX_COUNT_DISTINCT () nessas colunas, nas quais você pode ver pequenas discrepâncias (mas sempre dentro de 2%):
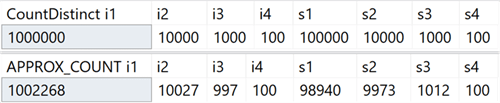
O ganho é enorme se houver limitações de memória, o que se aplica à maioria de nós. Se você observar os planos de consulta, nesse caso específico, poderá ver uma enorme diferença no consumo de memória pelo operador de correspondência de hash:

Observe que você geralmente notará melhorias significativas no desempenho se já estiver ligado à memória. No meu sistema, a execução durou um pouco mais devido à alta utilização da CPU do novo recurso:

Talvez a diferença fosse mais significativa se eu tivesse tabelas maiores, menos memória disponível para o SQL Server, simultaneidade mais alta ou alguma combinação dos itens acima.
Dicas para usar o nível de compatibilidade em uma consulta
Você tem uma consulta especial que funciona melhor sob um certo nível de compatibilidade, diferente do banco de dados atual? Agora isso é possível graças às novas dicas de consulta que suportam seis níveis diferentes de compatibilidade e cinco modelos diferentes para estimar o número de elementos. A seguir estão os níveis de compatibilidade disponíveis, uma sintaxe de exemplo e um modelo de nível de compatibilidade usado em cada caso. Veja como isso afeta as classificações, mesmo para visualizações do sistema:

Resumindo: não há mais necessidade de lembrar os sinalizadores de rastreamento, ou se você precisa se preocupar se o patch TF 4199 para o otimizador de consultas é distribuído ou se foi cancelado por algum outro service pack. Observe que essas dicas adicionais também foram adicionadas recentemente ao SQL Server 2017 na atualização cumulativa nº 10 (consulte
o blog de Pedro Lopez para obter detalhes). Você pode ver todas as dicas disponíveis com o seguinte comando:
SELECT name FROM sys.dm_exec_valid_use_hints;
Mas não esqueça que as dicas são uma medida excepcional, geralmente são adequadas para sair de uma situação difícil, mas não devem ser planejadas para uso a longo prazo, pois seu comportamento pode mudar com as atualizações subseqüentes.
Solução de problemas
Perfil padrão simplificado
Compreender essa melhoria requer alguns pontos para lembrar. O SQL Server 2014 introduziu a exibição DMV sys.dm_exec_query_profiles, que permite ao usuário que está executando a consulta coletar informações de diagnóstico sobre todas as instruções em todas as partes da consulta. As informações coletadas ficam disponíveis após a conclusão da consulta e permitem determinar quais operadores realmente gastaram os principais recursos e por quê. Qualquer usuário que não atender a uma solicitação específica poderá receber esses dados para qualquer sessão na qual a instrução STATISTICS XML ou STATISTICS PROFILE foi incluída ou para todas as sessões, usando o evento query_post_execution_showplan estendido, embora esse evento, em particular, possa afetar o desempenho geral.
No Management Studio 2016, foi adicionada uma funcionalidade que permite exibir fluxos de dados que passam pelo plano de consulta em tempo real com base nas informações coletadas do DMV, o que o torna ainda mais poderoso para a solução de problemas. O Plan Explorer também oferece a capacidade de visualizar dados passando pela consulta, em tempo real e no modo de reprodução.
A partir do SQL Server 2016 Service Pack 1 (SP1), você também pode habilitar uma versão leve da coleta desses dados para todas as sessões usando o sinalizador de rastreamento 7412 ou a propriedade query_thread_profile avançada, que permite obter informações atualizadas imediatamente sobre qualquer sessão, sem a necessidade de nada incluir explicitamente (em particular, coisas que afetam negativamente o desempenho). Isso é descrito
em mais detalhes no
blog de Pedro Lopez .
No SQL Server 2019, esse recurso é ativado por padrão, portanto, você não precisa executar nenhuma sessão com eventos estendidos ou usar sinalizadores de rastreamento e instruções STATISTICS em qualquer consulta. Basta olhar para os dados da DMV a qualquer momento para todas as sessões simultâneas. Mas é possível desativar esse modo usando LIGHTWEIGHT_QUERY_PROFILING; no entanto, essa sintaxe não funciona no CTP 2.0 e será corrigida em edições futuras.
Estatísticas de índice de coluna em cluster agora estão disponíveis em bancos de dados clonados
Nas versões atuais do SQL Server, ao clonar um banco de dados, apenas as estatísticas do objeto original dos índices da coluna em cluster são usadas, excluindo as atualizações feitas na tabela após sua criação. Se você usar um clone para configurar consultas e outros testes de desempenho, com base nas classificações de energia, esses exemplos poderão não funcionar. Parikshit Savyani descreveu as limitações
nesta publicação e forneceu uma solução temporária - antes de criar o clone, você precisa criar um script que execute DBCC SHOW_STATISTICS ... WITH STATS_STREAM para cada objeto. É caro e, é claro, fácil de esquecer.
No SQL Server 2019, essas estatísticas atualizadas estarão automaticamente disponíveis no clone, para que você possa testar vários cenários de consulta e obter planos objetivos com base em estatísticas reais, sem executar manualmente STATS_STREAM para todas as tabelas.
Previsão de compactação para armazenamento de colunas
Nas versões atuais, o procedimento sys.sp_estimate_data_compression_savings possui a seguinte verificação:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
Isso significa que permite verificar a compactação de uma linha ou página (ou ver o resultado da exclusão da compactação atual). No SQL Server 2019, essa verificação agora fica assim:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
Essa é uma ótima notícia, pois permite prever aproximadamente o efeito de adicionar um índice de coluna a uma tabela que não a possui, ou converter tabelas ou partições em um formato de armazenamento de coluna ainda mais compactado, sem precisar restaurar a tabela para outro sistema. Eu tinha uma tabela com 10 milhões de linhas, para a qual realizei um procedimento armazenado com cada um dos cinco parâmetros:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE';
Resultados:

Como em outros tipos de compactação, a precisão depende inteiramente das linhas disponíveis e da representatividade do restante dos dados. No entanto, esta é uma maneira bastante poderosa de obter resultados previsíveis sem muita dificuldade.
Novo recurso para obter informações da página
Por um longo tempo, DBCC PAGE e DBCC IND foram usados para coletar informações sobre páginas que continham uma seção, índice ou tabela. Mas eles não são documentados e não são suportados, e pode ser entediante automatizar a solução de tarefas associadas a vários índices ou páginas.
Posteriormente, uma função administrativa dinâmica (DMF) sys.dm_db_database_page_allocations apareceu, retornando um conjunto que representa todas as páginas no objeto especificado. Ainda sem documentos e com falhas que podem se tornar um problema real em grandes tabelas: mesmo para obter informações sobre uma página, ele deve ler toda a estrutura, o que pode ser bastante caro.
No SQL Server 2019, outro DMF apareceu - sys.dm_db_page_info. Ele basicamente retorna todas as informações da página, sem a sobrecarga da distribuição do DMF. No entanto, para usar a função nas compilações atuais, você precisa saber o número da página que está procurando com antecedência. Talvez este passo tenha sido dado intencionalmente, porque essa é a única maneira de garantir o desempenho. Portanto, se você estiver tentando identificar todas as páginas em um índice ou tabela, ainda precisará usar a distribuição DMF. No próximo artigo, descreverei essa questão com mais detalhes.
Segurança
Criptografia permanente usando um ambiente seguro (enclave)
No momento, a criptografia permanente protege dados confidenciais durante a transmissão e na memória por criptografia / descriptografia em cada final do processo. Infelizmente, isso muitas vezes leva a sérias limitações ao trabalhar com dados, como a incapacidade de executar cálculos e filtragem, portanto, você deve transferir todo o conjunto de dados para o lado do cliente para realizar, por exemplo, uma pesquisa por intervalo.
Um ambiente seguro (enclave) é uma área protegida da memória na qual esses cálculos e filtros podem ser delegados (o Windows usa
segurança baseada em virtualização ) - os dados permanecem criptografados no kernel, mas podem ser descriptografados ou criptografados com segurança em um ambiente seguro. Você só precisa adicionar o parâmetro ENCLAVE_COMPUTATIONS à chave primária usando o SSMS, por exemplo, marcando a caixa "Permitir cálculos em um ambiente seguro":
Agora você pode criptografar dados quase instantaneamente, em comparação com o método antigo (no qual o assistente, o cmdlet Set-SqlColumnEncyption ou seu aplicativo, precisaria obter completamente o conjunto inteiro do banco de dados, criptografá-lo e enviá-lo de volta):
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9)
Penso que, para muitas organizações, essa melhoria será a principal notícia, mas no CTP atual, alguns desses subsistemas ainda estão sendo aprimorados; portanto, eles estão desativados por padrão, mas
aqui você pode ver como ativá-los.
Gerenciamento de certificados no Configuration Manager
O gerenciamento de certificados SSL e TLS sempre foi trabalhoso e muitas pessoas foram forçadas a fazer o trabalho tedioso de criar seus próprios scripts para implantar e manter seus certificados corporativos. O Gerenciador de Configurações atualizado para SQL Server 2019 ajuda a exibir e verificar rapidamente certificados de qualquer instância, encontrar certificados que estão prestes a expirar no futuro próximo e sincronizar implantações de certificados em todas as replicações em um grupo de disponibilidade ou em todos os nós em uma instância de cluster de failover.
Não tentei todas essas operações, mas elas devem funcionar para versões anteriores do SQL Server se o gerenciamento vier do SQL Server 2019 Configuration Manager.
Classificação e auditoria de dados incorporadas
A equipe de desenvolvimento do SQL Server adicionou a capacidade de classificar dados no SSMS 17.5, permitindo identificar qualquer coluna que possa conter informações confidenciais ou contradizer vários padrões (HIPAA, SOX, PCI e GDPR, é claro). O assistente usa um algoritmo que oferece colunas que supostamente causam problemas, mas você pode ajustar sua sentença removendo essas colunas da lista ou adicionar suas próprias. Para armazenar a classificação, são usadas propriedades avançadas; O relatório interno do SSMS usa as mesmas informações para exibir seus dados. Fora do relatório, essas propriedades não são tão óbvias.
O SQL Server 2019 introduziu uma nova instrução para esses metadados, já disponível no Banco de Dados SQL do Azure, e denominada ADD SENSITIVITY CLASSIFICATION. Ele permite que você faça o mesmo que o assistente no SSMS, mas as informações não são mais armazenadas na propriedade estendida e qualquer acesso a esses dados é exibido automaticamente na auditoria como uma nova coluna XML data_sensitivity_information. Ele contém todos os tipos de informações que foram afetadas durante a auditoria.
Como um exemplo rápido, suponha que eu tenha uma tabela para contratados externos:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
Observando essa estrutura, fica claro que todas as quatro colunas são potencialmente vulneráveis a vazamentos ou devem estar acessíveis apenas a um círculo limitado de pessoas. Aqui você pode obter permissões, mas pelo menos precisa se concentrar nelas. Assim, podemos classificar essas colunas de diferentes maneiras:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
Agora, em vez de olhar para sys.extended_properties, você pode vê-los em sys.sensitivity_classifications:

E se realizarmos amostragem de auditoria (ou DML) para esta tabela, não precisaremos alterar nada especificamente; Após criar a classificação,
SELECT * registrará no log de auditoria um registro desse tipo de informação em uma nova coluna data_sensitivity_information:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
Obviamente, isso não resolve todos os problemas de conformidade com os padrões, mas pode dar uma vantagem real. O uso do assistente para identificar automaticamente colunas e converter chamadas sp_addextendedproperty em comandos ADD SENSITIVITY CLASSIFICATION pode simplificar bastante a tarefa de conformidade com os padrões. Mais tarde, escreverei um artigo separado sobre isso.
Você também pode automatizar a criação (ou atualização) de permissões com base no rótulo nos metadados - a criação de um script SQL dinâmico que proíbe o acesso a todas as colunas confidenciais (GDPR), o que permitirá gerenciar usuários, grupos ou funçõesb. Eu trabalharei sobre esta questão no futuro.
Disponibilidade
Criação de índice renovável em tempo real
No SQL Server 2017, tornou-se possível suspender e retomar a reconstrução do índice em tempo real, o que pode ser muito útil se você precisar alterar o número de processadores usados, continuar a partir do momento da suspensão após uma falha ou simplesmente preencher a lacuna entre as janelas de serviço. Eu falei sobre esse recurso em um
artigo anterior .
No SQL Server 2019, você pode usar a mesma sintaxe para criar índices em tempo real, pausar e continuar, além de limitar o tempo de execução (definindo o tempo de pausa):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
Se essa consulta funcionar por muito tempo, para pausar, você poderá executar o ALTER INDEX em outra sessão (mesmo que o índice ainda não exista fisicamente):
ALTER INDEX foo ON dbo.bar PAUSE;
Nas versões atuais, o grau de paralelismo durante a renovação não pode ser reduzido, como é o caso da reconstrução. Ao tentar reduzir o DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
Temos o seguinte:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
De fato, se você tentar fazer isso e executar o comando sem parâmetros adicionais, receberá o mesmo erro, pelo menos nas compilações atuais. Eu acho que a tentativa de renovação foi registrada em algum lugar e o sistema queria usá-la novamente. Para continuar, você deve especificar o valor DOP correto (ou superior):
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
Para deixar claro: você pode aumentar o DOP ao retomar a criação de um índice em pausa, mas não reduzi-lo.
Um benefício adicional de tudo isso é que você pode configurar a criação e / ou renovação de índices em tempo real como o modo padrão usando as cláusulas ELEVATE_ONLINE e ELEVATE_RESUMABLE para o novo banco de dados.
Criação / reconstrução em tempo real de índices de colunas em cluster
Além da criação de índice renovável, também temos a oportunidade de criar ou reconstruir índices de colunas clusterizadas em tempo real. Essa é uma alteração significativa, que permite que você não gaste mais o tempo das janelas de serviço na manutenção desses índices ou (para maior certeza) converter os índices de linha para coluna:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
Um aviso: se um índice em cluster tradicional existente foi criado em tempo real, sua conversão em um índice de coluna em cluster também é possível apenas nesse modo. Se fizer parte da chave primária, embutida ou não ... CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO
Temos o seguinte erro: Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
Você deve primeiro remover a restrição para convertê-la em um índice de coluna em cluster, mas ambas as operações podem ser executadas em tempo real: ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
Isso funciona, mas provavelmente levará mais tempo em tabelas grandes do que se a chave primária fosse implementada como um índice clusterizado exclusivo. Não posso ter certeza se isso é uma restrição intencional ou apenas uma limitação do CTP atual.Redirecionando uma conexão de replicação de um servidor secundário para um primário
Essa função permite configurar o redirecionamento sem escutar, para que você possa alternar a conexão com o servidor principal, mesmo se o secundário for especificado diretamente na cadeia de conexão. Essa função pode ser usada quando a tecnologia de cluster não oferece suporte à escuta, ao usar AGs sem um cluster ou quando existe um esquema de redirecionamento complexo em um cenário com várias sub-redes. Isso impedirá que a conexão tente, por exemplo, gravar operações para replicação no modo somente leitura (e falhas, respectivamente).Desenvolvimento
Recursos adicionais do gráfico
Os relacionamentos de gráfico agora suportam a instrução MERGE para um nó ou tabelas de limites usando predicados MERGE; Agora, um operador pode atualizar uma aresta existente ou inserir uma nova. A nova restrição de borda permite determinar quais nós a borda pode se conectar.Utf-8
O SQL Server 2012 adicionou suporte para UTF-16 e caracteres adicionais, definindo a classificação especificando um nome com o sufixo _SC, como Latin1_General_100_CI_AI_SC, para usar colunas Unicode (nchar / nvarchar). No SQL Server 2017, você pode importar e exportar dados UTF-8 de e para essas colunas usando ferramentas como BCP e BULK INSERT .No SQL Server 2019, há novas opções de agrupamento para oferecer suporte à retenção forçada de dados UTF-8 em sua forma original. Portanto, você pode criar facilmente colunas char ou varchar e armazenar dados UTF-8 corretamente usando o novo agrupamento com o sufixo _SC_UTF8, como Latin1_General_100_CI_AI_SC_UTF8. Isso pode ajudar a melhorar a compatibilidade com aplicativos externos e DBMS, sem o custo de processamento e armazenamento do nvarchar.Ovo de páscoa que encontrei
Tanto quanto me lembro, os usuários do SQL Server reclamam dessa vaga mensagem de erro: Msg 8152 String or binary data would be truncated.
Nas versões do CTP com as quais experimentei, foi notada uma mensagem de erro interessante que não existia antes: Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
Não acho que seja necessário mais nada aqui; esta é uma grande melhoria (embora muito tarde) e promete fazer muitos felizes. No entanto, essa funcionalidade não estará disponível no CTP 2.0; Só lhe dou a oportunidade de olhar um pouco à frente. Brent Ozar listou todas as novas mensagens que encontrou no CTP atual e as temperou com alguns comentários úteis em seu artigo sys.messages: descobrindo recursos adicionais .Conclusão
O SQL Server 2019 oferece bons recursos adicionais que ajudarão a melhorar o trabalho com sua plataforma de banco de dados relacional favorita, e há várias mudanças sobre as quais eu não falei. Memória com uso eficiente de energia, clustering para serviços de aprendizado de máquina, replicação e transações distribuídas no Linux, Kubernetes, conectores para Oracle / Teradata / MongoDB, replicações síncronas de AG aumentaram para oferecer suporte ao Java (uma implementação semelhante ao Python / R) e, igualmente importante, um novo salto, intitulado Big Data Cluster. Para usar alguns desses recursos, você deve se registrar usando este formulário EAP .O próximo livro de Bob Ward, Pro SQL Server no Linux - incluindo a implantação baseada em contêiner com Docker e Kubernetes, pode fornecer algumas dicas sobre outras coisas que estão por vir em breve. E esta publicação de Brent Ozar fala sobre uma possível correção futura para uma função escalar definida pelo usuário.Mas, mesmo neste primeiro CTP público, há algo significativo para quase todo mundo, e peço que tente você mesmo!