Amigos, boa tarde.
Existe um entendimento claro de que a maioria dos projetos da OIC é essencialmente um ativo intangível. O projeto da OIC não é um carro da Mercedes-Benz - ele dirige independentemente de quem o ama ou não. E a principal influência na OIC é feita pelo humor das pessoas - tanto pela atitude em relação ao fundador / fundador da OIC quanto pelo próprio projeto.
Seria bom avaliar de alguma forma a atitude das pessoas em relação ao fundador da OIC e / ou do projeto da OIC. O que foi feito. O relatório está abaixo.
O resultado foi uma ferramenta para coletar humores positivos / negativos da Internet, em particular do Twitter.
Meu ambiente é o Windows 10 x64, usei a linguagem Python 3 no editor Spyder no Anaconda 5.1.0, uma conexão de rede com fio.
Coleta de dados
Eu entendo as postagens do Twitter. Primeiro, vou descobrir o que o fundador da OIC está fazendo agora e quão positivamente eles respondem sobre isso com o exemplo de um par de personalidades famosas.
Vou usar a biblioteca tweepy python. Para trabalhar com o Twitter, você precisa se registrar como desenvolvedor, consulte twitter / . Obtenha critérios de acesso ao Twitter.
O código é o seguinte:
import tweepy API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr" API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr" ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr" ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr" auth = tweepy.OAuthHandler(API_KEY, API_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth)
Agora podemos recorrer à API do Twitter e obter algo com ela, ou vice-versa. A coisa foi feita no início de agosto. Você precisa obter alguns tweets para encontrar o projeto atual do fundador. Procurado assim:
import pandas as pd searchstring = searchinfo+' -filter:retweets' results = pd.DataFrame() coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500) for tweet in coursor.items(): my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted']) result = pd.DataFrame(my_series).transpose() results = results.append(result, ignore_index = True) results.to_excel('results.xlsx')
Na busca, substituímos o nome necessário e encaminhamos. O resultado foi salvo no results.xlsx excel.
Criativo
Então eu decidi fazer um criativo. Precisamos encontrar os projetos do fundador. Os nomes dos projetos são próprios e estão em maiúsculas. Suponha que também pareça verdade que, com uma letra maiúscula em cada tweet, esteja escrito: 1) o nome do fundador, 2) o nome do seu projeto, 3) a primeira palavra do tweet e 4) palavras estranhas. As palavras 1 e 2 serão encontradas com frequência nos tweets, e 3 e 4 são raras, na frequência somos 3 e 4 e eliminamos. Sim, também ocorreu que os links geralmente aparecem em tweets, 5) nós os removeremos também.
Aconteceu assim:
import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, len(results.index)): review1 = [] mystr = results['text'][i]
Análise de dados criativos
Na variável de nomes, temos as palavras e na variável X - os locais onde são mencionadas. Tabela "Desligar" X - obtenha o número de referências. Excluímos palavras que raramente são mencionadas. Salve no Excel. E no Excel, criamos um belo gráfico de barras com informações sobre a frequência com que palavras são mencionadas em qual consulta.
Nossas super estrelas da OIC são Le Minh Tam e Mike Novogratz. Gráficos:
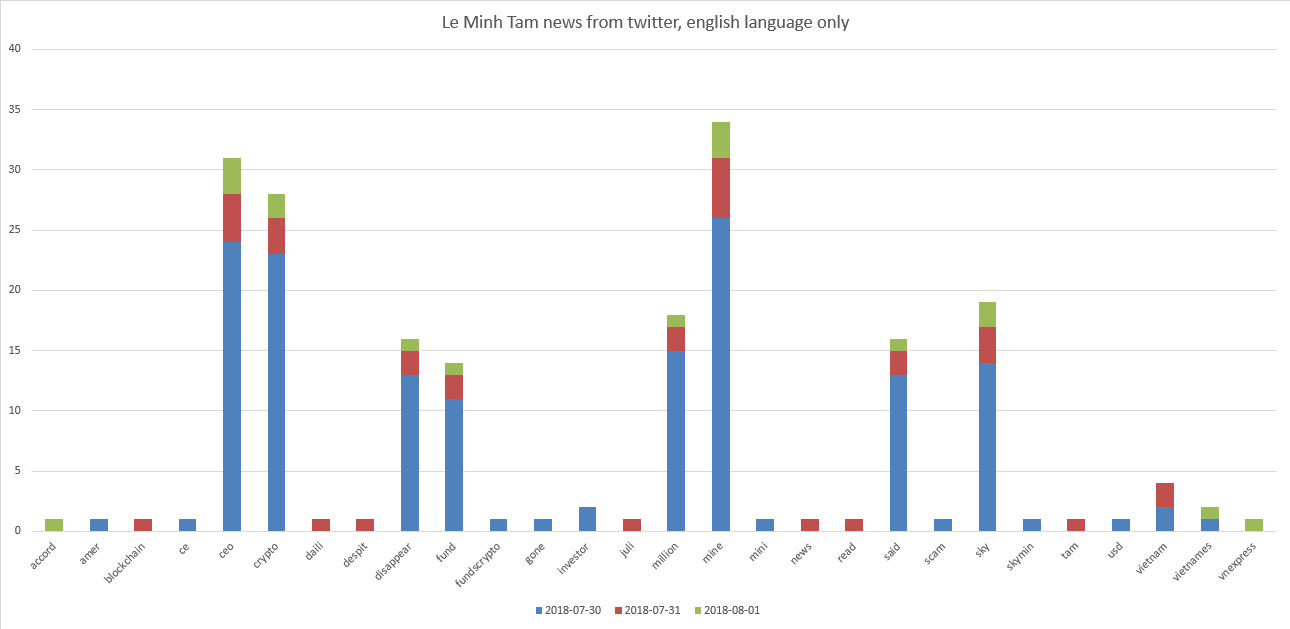
Pode-se ver que Le Minh Tam está relacionado a "CEO, cripto, mina, céu". E um pouco para "desaparecer, financiar, milhões".
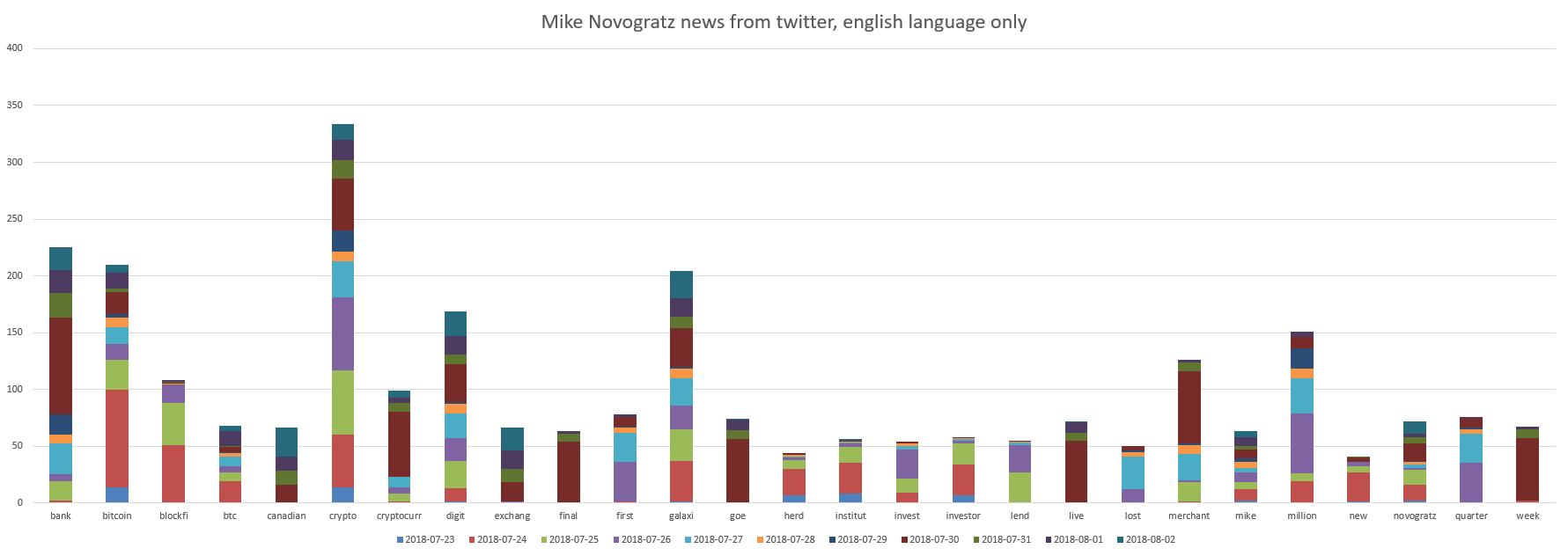
Pode-se ver que Mike Novogratz está relacionado a "banco, bitcoin, criptografia, dígito, galáxia".
Os dados do X podem ser derramados em uma rede neural e podem aprender a determinar qualquer coisa, mas você pode:
Análise de dados
E então paramos brincar seja criativo e comece a usar a biblioteca python TextBlob . A biblioteca é um milagre quão bom.
Pessoas inteligentes dizem que ela pode:
- Realçar frases
- fazer marcação de peças
- analisar o humor (isso é útil para nós abaixo),
- classificação (bayes ingênuos, árvore de decisão),
- traduzir e definir o idioma usando o Google Translate,
- faça tokenização (divida o texto em palavras e frases),
- identificar as frequências de palavras e frases,
- fazer análise
- detectar n-gramas
- revelar \ inflexão \ declinação \ conjugação de palavras (pluralização e singularização) e lematização,
- ortografia correta.
A biblioteca permite adicionar novos modelos ou idiomas por meio de extensões e possui integração com o WordNet. Em uma palavra, a PNL é um prodígio infantil .
Salvamos os resultados da pesquisa no arquivo results.xlsx acima. Faça o download e analise-o com a biblioteca TextBlob para fins de avaliação de humor:
from textblob import TextBlob results = pd.read_excel('results.xlsx') polarity = 0 for i in range(0, len(results.index)): polarity += TextBlob(results['text'][i]).sentiment.polarity print(polarity/i)
Ótimo! Algumas linhas de código e um resultado estrondo.
Visão geral dos resultados
Acontece que, no início de agosto de 2018, os tweets encontrados na consulta "Le Minh Tam" mostram algo que refletiu negativamente nos tweets com uma classificação média de todos os tweets menos 0,13 . Se assistirmos os tweets, veremos, por exemplo, "O CEO da Crypto Mining disse que desapareceu com US $ 35 milhões em fundos O CEO da empresa de mineração Crypto Sky Mining, Le Minh Tam, r ...".
E o amigo de Mike Novogratz fez algo que refletiu positivamente nos tweets com uma classificação média de todos os tweets mais 0,03 . Você pode interpretá-lo para que tudo avance com calma.
Plano de ataque
Para fins de avaliação da OIC, vale a pena monitorar as informações sobre os fundadores da OIC e sobre a própria OIC de várias fontes. Por exemplo:
Planeje o monitoramento de uma OIC:
- Crie uma lista dos nomes dos fundadores da OIC e da própria OIC,
- Criamos uma lista de recursos para monitoramento,
- Criamos um robô que coleta dados para cada linha de 1 - para cada recurso de 2, exemplo acima,
- Criamos um robô que avalia a cada 3, o exemplo acima,
- Salve os resultados 4 (e 3),
- Repita as etapas 3 a 5 a cada hora, de maneira automatizada, os resultados da avaliação podem ser postados / enviados / salvos em algum lugar,
- Monitoramos automaticamente os saltos na avaliação no parágrafo 6. Se houver saltos na avaliação no parágrafo 6, esta é uma ocasião para realizar um estudo adicional do que está acontecendo de maneira especializada. E aumente o pânico, ou vice-versa, regozija-se.
Bem, algo assim.
PS Bem, ou compre essas informações, por exemplo, aqui thomsonreuters