Hoje falaremos sobre DevOps, ou melhor, principalmente sobre Ops. Eles dizem que há muito poucas pessoas satisfeitas com o nível de automação de suas operações. Mas a situação parece ser corrigível. Neste artigo, Nikolai Ryzhikov falará sobre sua experiência com a expansão do Kubernetes.

O material foi preparado com base no discurso de Nikolai na conferência de outono do DevOops 2017. Sob o corte - transcrição em vídeo e texto do relatório.
Atualmente, Nikolai Ryzhikov está trabalhando no setor de Saúde-TI para criar sistemas de informação médica. Membro da comunidade de programadores funcionais de São Petersburgo FPROG. Membro ativo da comunidade Online Clojure, membro do padrão de troca de informações médicas HL7 FHIR. Programa há 15 anos.
Que lado temos para o DevOps? Nossa fórmula de DevOps é bastante simples há 10 anos: os desenvolvedores são responsáveis pelas operações, os desenvolvedores são implantados, os desenvolvedores são mantidos. Com esse arranjo, que parece um pouco duro, você se tornará o DevOps. Se você deseja implementar DevOps de maneira rápida e dolorosa - torne os desenvolvedores responsáveis por sua produção. Se os caras são espertos, eles começam a sair e entender tudo.

Nossa história: há muito tempo, quando não havia Chef e automação, já implantamos o Capistrano automático. Então eles começaram a entediá-lo, para que ele fizesse moda. Mas então o Chef apareceu. Mudamos para ele e partimos para a nuvem: estávamos cansados de nossos data centers. Então Ansible apareceu, Docker se levantou. Depois disso, nos mudamos para a Terraform com o supervisor de portaria escrito à mão do Condomínio em Camel. E agora estamos nos mudando para Kubernetes.

Qual é a pior coisa das operações? Muito poucas pessoas estão satisfeitas com o nível de automação de suas operações. Isso é assustador, confirmo: gastamos muitos recursos e esforços para coletar todas essas pilhas para nós mesmos, e o resultado é insatisfatório.
Há um sentimento de que, com o advento do Kubernetes, algo pode mudar. Estou comprometido com a manufatura enxuta e, do ponto de vista dele, as operações geralmente não são úteis. Operações ideais são a ausência ou o mínimo de operações em um projeto. O valor é criado quando um desenvolvedor faz um produto. Quando está pronta, a entrega não agrega valor. Mas você precisa reduzir custos.

Para mim, o ideal sempre foi o heroku. Nós o usamos para aplicativos simples, onde o desenvolvedor implementou seu serviço, basta dizer git push e configurar heroku. Demora um minuto.

Como ser Você pode comprar NoOps - também heroku. E eu aconselho você a comprar, caso contrário, há uma chance de gastar mais dinheiro no desenvolvimento de operações normais.
Existem caras da Deis, eles estão tentando fazer algo como heroku no Kubernetes. Existe a fundição em nuvem, que também fornece uma plataforma na qual trabalhar.

Mas se você se incomodar com algo mais complexo ou grande, poderá fazer isso sozinho. Agora, junto com o Docker e o Kubernetes, isso se torna uma tarefa que pode ser concluída em um período de tempo razoável e a um custo razoável. Costumava ser muito duro.

Um pouco sobre o Docker e o Kubernetes
Um dos problemas das operações é a repetibilidade. A grande coisa que o docker trouxe são duas fases. Temos uma fase de construção.
O segundo ponto que agrada na janela de encaixe é uma interface universal para o lançamento de serviços arbitrários. Alguém montou o Docker, colocou algo dentro e as operações são suficientes para dizer que o Docker é executado e iniciado.

O que é o Kubernetes? Por isso, criamos o Docker e precisamos iniciá-lo, integrá-lo, configurá-lo e conectá-lo a outras pessoas em algum lugar. O Kubernetes permite que você faça isso. Ele introduz uma série de abstrações, chamadas "recurso". Iremos rapidamente examiná-los e até tentar criar.
Abstração
A primeira abstração é um POD ou um conjunto de contêineres. Feito corretamente, o que exatamente é um
conjunto de contêineres, e não um. Os conjuntos podem vasculhar entre si volumes que se vêem através do host local. Isso permite que você use um padrão como o side-car (é quando lançamos o contêiner principal e existem contêineres auxiliares nas proximidades que o ajudam).
Por exemplo, a abordagem do embaixador. É quando você não deseja que o contêiner pense onde alguns serviços estão localizados. Você coloca um contêiner próximo a ele que sabe onde estão esses serviços. E eles ficam disponíveis para o contêiner principal no host local. Assim, o ambiente começa a parecer que você está trabalhando localmente.

Vamos aumentar o POD e ver como ele é descrito. Localmente, você pode desenvolver o minikube. Ele consome várias CPUs, mas permite que você crie um pequeno cluster Kubernetes em uma caixa virtual e trabalhe com ele.
Vamos implantar o POD. Eu disse que o Kubernetes aplica e inundou o POD. Posso ver quais PODs tenho: vejo que um POD está implantado. Isso significa que o Kubernetes lançou esses contêineres.
Eu posso até entrar neste contêiner.
Nesta perspectiva, o Kubernetes é feito para pessoas. De fato, o que fazemos constantemente em operações, na ligação do Kubernetes, por exemplo, usando o utilitário kubectl, pode ser feito facilmente.
Mas o POD é mortal. Começa como uma execução no Docker: se alguém o interrompe, ninguém o levanta. Além dessa abstração, o Kubernetes começa a criar o seguinte - por exemplo, um conjunto de réplicas. Este é um supervisor que monitora os PODs, monitora seu número e, se os PODs caírem, ele os levanta. Este é um conceito importante de autocura em Kubernetes que permite que você durma em paz à noite.
Acima da replicaset, há uma abstração da implantação - também um recurso que permite fazer a implantação em tempo zero. Por exemplo, um replicaset funciona. Quando implantamos e alteramos a versão do contêiner, por exemplo a nossa, dentro da implantação, outro replicaset aumenta. Aguardamos até que esses contêineres sejam iniciados, passemos por suas verificações de integridade e depois mudamos rapidamente para o novo conjunto de replicas. Também clássico e boas práticas.

Vamos pegar um serviço simples. Por exemplo, temos uma implantação. No interior, ele descreve o padrão de PODs que ele buscará. Podemos aplicar essa implantação, ver o que temos. Funcionalidade interessante do Kubernetes - tudo está no banco de dados e podemos ver o que acontece no sistema.
Aqui vemos uma implantação. Se tentarmos olhar para os PODs, vemos que alguns PODs aumentaram. Podemos pegar e remover esse POD. O que acontece com os PODs? Um é destruído e o segundo se eleva imediatamente. Este controlador de replicaset não encontrou o POD desejado e lançou outro.
Além disso, se esse é algum tipo de serviço da Web, ou dentro de nossos serviços deve se comunicar, precisamos de uma descoberta de serviço. Você deve dar ao serviço um nome e um ponto de entrada. O Kubernetes oferece um recurso chamado serviço para isso. Ele pode lidar com o balanceamento de carga e ser responsável pela descoberta de serviços.

Vamos ver um serviço simples. Nós o conectamos à implantação e aos PODs por meio de etiquetas: um link tão dinâmico. Um conceito muito importante no Kubernetes: o sistema é dinâmico. Não importa em que ordem tudo isso será criado. O serviço tentará encontrar PODs com essas etiquetas e iniciar seu equilíbrio de carga.
Aplique serviço, veja quais serviços temos. Entramos em nosso teste de POD, que foi criado, e fazemos a pesquisa. O Kubernetes nos fornece um DNS-ku através do qual os serviços podem ver e descobrir um ao outro.
O serviço é mais uma interface. Existem várias implementações diferentes, porque as tarefas de balanceamento de carga e serviço são bastante complicadas: de uma maneira, trabalhamos com bancos de dados comuns, no outro com bancos de dados carregados, e alguns simples são simplificados. Este também é um conceito importante no Kubernetes: algumas coisas podem ser chamadas de interfaces, em vez de implementações. Eles não são corrigidos rigidamente e diferentes, por exemplo, os provedores de nuvem oferecem implementações diferentes. Ou seja, por exemplo, há um volume persistente de recurso, que já é implementado em cada nuvem específica por seus meios regulares.
Em seguida, geralmente queremos disponibilizar o serviço da web. Kubernetes tem uma abstração de entrada. Geralmente, o SSL é adicionado lá.

A entrada mais simples se parece com isso. Lá, escrevemos as regras: para quais URLs, para quais hosts, para qual serviço interno redirecionar a solicitação. Da mesma maneira, podemos aumentar nossa entrada.
Após o qual, após se registrar localmente nos hosts, você pode ver este serviço a partir daqui.
Essa é uma tarefa tão regular: implantamos um determinado serviço da web e nos encontramos um pouco com o Kubernetes.
Vamos limpar tudo, remover a entrada e analisar todos os recursos.
Existem vários recursos, como configmap e secret. Estes são recursos puramente informativos que você pode montar em um contêiner e transferir para lá, por exemplo, a senha do postgres. Você pode associar isso a variáveis de ambiente que serão injetadas no contêiner na inicialização. Você pode montar o sistema de arquivos. Tudo é bastante conveniente: tarefas padrão, soluções agradáveis.
Há um volume persistente - uma interface que é implementada de maneira diferente por diferentes provedores de nuvem. Ele é dividido em duas partes: há uma reivindicação de volume persistente (solicitação) e, em seguida, é criado um EBS que arrasta para o contêiner. Você pode trabalhar com um serviço com estado.

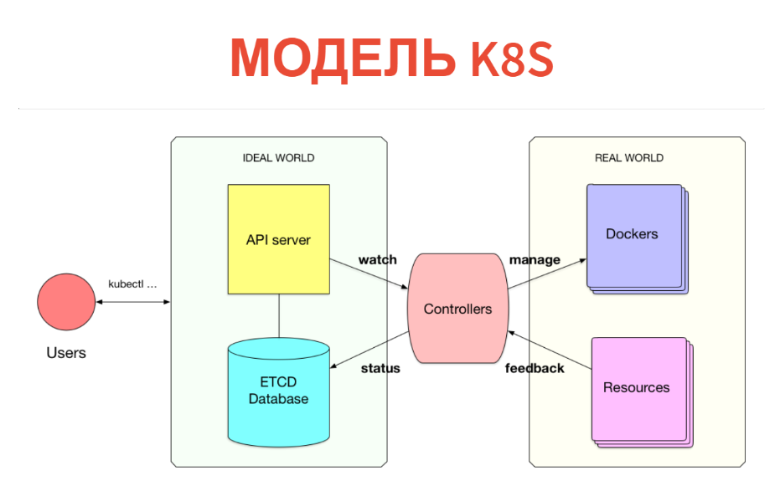
Mas como isso funciona por dentro? O conceito em si é muito simples e transparente. Kubernetes tem duas partes. Um é apenas um banco de dados no qual temos todos esses recursos. Os recursos podem ser considerados tablets: especificamente, essas instâncias são simplesmente registros em tablets. Além do Kubernetes, um servidor de API está configurado. Ou seja, quando você tem um cluster Kubernetes, geralmente se comunica com o servidor da API (mais precisamente, o cliente se comunica com ele).
Assim, o que criamos (PODs, serviços etc.) é simplesmente gravado no banco de dados. Este banco de dados é implementado pelo ETCD, ou seja, para que seja estável no nível de alta disponibilidade.
O que vem depois? Além disso, sob cada tipo de recursos, há um determinado controlador. Este é apenas um serviço que monitora seu tipo de recurso e faz algo no mundo exterior. Por exemplo, um Docker é executado. Se tivermos PODs, para cada Nó existe um serviço de kubelet que monitora os PODs que estão conectados a esse nó. E tudo o que ele faz é o Docker executar após a próxima verificação periódica se esse POD não está lá.
Além disso, o que é muito importante - tudo acontece em tempo real, portanto a potência deste controlador é maior que o mínimo. Freqüentemente, o controlador ainda pega as métricas e analisa o que foi iniciado. I.e. remove o feedback do mundo real e o grava no banco de dados, para que você ou outros controladores possam vê-lo. Por exemplo, o mesmo status de POD será gravado de volta no ETCD.
Assim, tudo é implementado no Kubernetes. É muito legal que o modelo de informações seja separado da sala de operações. No banco de dados através da interface CRUD usual, declaramos o que deveria ser. Em seguida, o conjunto de controladores tenta fazer tudo certo. É verdade que isso nem sempre acontece.
Este é um modelo cibernético. Temos uma certa predefinição: existe algum tipo de máquina que está tentando direcionar o mundo real ou a máquina para o local necessário. Nem sempre é assim: devemos ter um ciclo de feedback. Às vezes, uma máquina não pode fazer isso e deve recorrer a uma pessoa.
Em sistemas reais, pensamos em abstrações do próximo nível: temos alguns serviços, bancos de dados e todos nós o conectamos. Não pensamos em PODs e Ingresss e queremos criar um próximo nível de abstração.

Para que o desenvolvedor fosse o mais fácil possível: para que ele simplesmente dissesse: "Quero iniciar esse e tal serviço", e tudo o mais aconteceu por dentro.
Existe algo como HELM. Este é o caminho errado - modelagem de estilo ansible, onde estamos apenas tentando gerar um conjunto de recursos configurados e soltá-los em um cluster Kubernetes.
O problema, em primeiro lugar, é que isso é feito apenas no momento da rolagem. Ou seja, ele não pode implementar muita lógica. Em segundo lugar, em tempo de execução, essa abstração desaparece. Quando vou olhar para o meu cluster, vejo apenas PODs e serviços. Não vejo que esse e esse serviço seja implantado, que tal e qual base com replicação seja criada lá. Eu só vejo dezenas de lares lá. A abstração desaparece como em uma matriz.

Modelo de solução interna
Por outro lado, o próprio Kubernetes já fornece um modelo de extensão muito interessante e simples. Podemos declarar novos tipos de recursos, por exemplo implantação. Este é um recurso criado sobre PODs ou replicaset. Podemos escrever um controlador nesse recurso, colocá-lo no banco de dados e executar nosso loop cibernético para que tudo funcione. Isso parece interessante, e parece-me que este é o caminho certo para estender o Kubernetes.

Gostaria de poder apenas escrever algum manifesto para o meu serviço no estilo heroku. Um exemplo muito simples: quero implantar algum tipo de aplicativo no meu ambiente real. Já possui contratos, SSL, domínios comprados. Eu só gostaria de dar aos desenvolvedores a interface mais simples possível. O manifesto me diz qual contêiner levantar, quais recursos esse contêiner ainda precisa. Ele lança esse anúncio no cluster e tudo começa a funcionar.

Como isso ficará em termos de recursos e controladores personalizados? Aqui teremos um aplicativo de recurso no banco de dados. E o controlador do aplicativo gerará três recursos. Ou seja, ele anotará as regras de entrada sobre como encaminhar para esse serviço, iniciar o serviço de balanceamento de carga e iniciar a implantação com algum tipo de configuração.
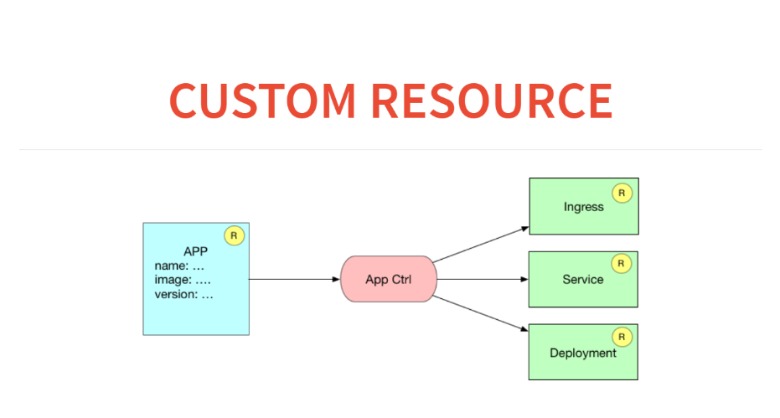
Antes de criarmos um recurso personalizado no Kubernetes, precisamos declará-lo. Para isso, existe um meta-recurso chamado CustomResourceDefinition.
Para declarar um novo recurso no Kubernetes, basta publicar esse anúncio. Considere esta tabela de criação.
Criou uma tabela. Depois disso, podemos examinar o kubectl e obter os recursos de terceiros que temos. Assim que anunciamos, também recebemos um banner. Podemos fazer, por exemplo, o kubeclt obter aplicativos. Mas até agora nenhum aplicativo.
Vamos escrever um aplicativo. Depois disso, podemos criar uma instância de recurso personalizado. Vamos dar uma olhada no YAML e criá-lo por postagem em um URL específico.
Se executarmos e examinarmos o kubectl, um aplicativo será exibido. Mas enquanto nada acontece, ele está apenas no banco de dados. Você pode, por exemplo, pegar e solicitar todos os recursos do aplicativo.
Podemos criar um segundo recurso desse tipo a partir do mesmo modelo, simplesmente alterando o nome. Aqui está o segundo recurso.
Além disso, nosso controlador deve fazer modelagem, semelhante ao que o HELM faz. Ou seja, depois de receber uma descrição do nosso aplicativo, preciso gerar uma implantação de recursos e um serviço de recursos, além de fazer uma entrada na entrada. Esta é a parte mais fácil: aqui no clojure é erlmacro. Eu passo a estrutura de dados, ele puxa a função de implantação, passa para depuração, que é o pipeline. E esta é uma função pura: modelagem simples. Dessa forma, da forma mais ingênua, eu poderia criá-lo imediatamente, transformá-lo em um utilitário de console e começar a distribuí-lo.
Fazemos o mesmo pelo serviço: a função de serviço aceita a declaração e gera o recurso Kubernetes para nós.
Fazemos o mesmo para a linha de entrada.
Como isso tudo vai funcionar? Haverá algo no mundo real e haverá o que queremos. O que queremos - pegamos o recurso do aplicativo e geramos nele o que deveria ser. E agora precisamos ver o que é. O que solicitamos através da API REST. Podemos obter todos os serviços, todas as implantações.
Como nosso controlador personalizado funcionará? Ele receberá o que queremos e o que é, tira dessa div e aplica-se ao Kubernetes. Isso é semelhante ao React. Eu vim com um DOM virtual quando algumas funções simplesmente geram uma árvore de objetos JS. E então um determinado algoritmo calcula o patch e o aplica ao DOM real.
Faremos o mesmo aqui. Isso é feito em 50 linhas de código. Quer - tudo está no Github. No final, devemos obter a função reconciliar ações.
Temos uma função de reconciliação de ações que não faz nada e apenas calcula essa div. Ela pega o que é, mais o que é necessário. E então ele mostra o que precisa ser feito para trazer o primeiro para o segundo.
Vamos puxá-la. Não há nada de errado com ela, ela pode ser prejudicada. Ela diz que você precisa criar um serviço de entrada, fazer duas entradas nele, criar uma implantação 1 e 2, criar um serviço 1 e 2.
Nesse caso, já deve haver apenas um serviço. Vimos pela entrada que resta apenas uma entrada.
Tudo o que resta é escrever uma função que aplique esse patch ao cluster Kubernetes. Para fazer isso, simplesmente transmitimos ações de reconciliação para a função de reconciliação, e tudo será aplicado. E agora vemos que o POD aumentou, a implantação se tornou e o serviço foi iniciado.
Vamos adicionar outro serviço: execute a função reconciliar ações novamente. Vamos ver o que aconteceu. Tudo começou, está tudo bem.
Como lidar com isso? Empacotamos tudo isso em um contêiner Docker. Depois disso, escrevemos uma função que acorda periodicamente, faz uma reconciliação e adormece. A velocidade não é muito importante, ela pode dormir por cinco segundos e executar ações de reconciliação com menos frequência.
Nosso controlador personalizado é apenas um serviço que será ativado e calculará periodicamente o patch.
Agora temos dois serviços zaddeloino, vamos excluir um dos aplicativos. Vamos ver como nosso cluster reagiu: está tudo bem. Excluímos o segundo: tudo está limpo.
Vamos ver através dos olhos do desenvolvedor. Ele só precisa dizer que o Kubernetes aplica e nomeia o novo serviço. Fazemos isso, nosso controlador pegou tudo e o criou.
Em seguida, coletamos tudo isso em um serviço de implantação e lançamos esse controlador personalizado no cluster usando as ferramentas padrão do Kubernetes. Criamos uma abstração para 200 linhas de código.
Tudo parece HELM, mas na verdade mais poderoso. O controlador trabalha em um cluster: vê a base, vê o mundo exterior e pode ser inteligente o suficiente.
IC próprio
Considere os exemplos de extensão Kubernetes. Decidimos que o IC deveria fazer parte da infraestrutura. Isso é bom, é conveniente do ponto de vista da segurança - um repositório privado. Tentamos usar o jenkins, mas é uma ferramenta desatualizada. Eu queria um CI hacker. Não precisamos de interfaces, amamos o ChatOps: diga no bate-papo se a compilação caiu ou não. Além disso, eu queria depurar tudo localmente.

Sentamos e escrevemos nosso IC em uma semana. Apenas como uma extensão para o Kubernetes. Se você pensa em CI, essa é apenas uma ferramenta que executa algum tipo de trabalho. Como parte desse trabalho, criamos algo, executamos testes e frequentemente implantamos.
Como tudo isso funciona? Ele é construído com o mesmo conceito de controladores personalizados.
Primeiro, deixamos no Kubernetes uma descrição de quais repositórios estamos seguindo. O controlador apenas acessa o github e adiciona gancho da web. Ainda temos introspecção.A seguir, vem o gancho da web, cuja única tarefa é processar o JSON recebido e soltá-lo no recurso de compilação personalizado, que também é dobrado no banco de dados Kubernetes. O recurso de construção é monitorado pelo controlador de construção, que lê o manifesto dentro do projeto e inicia o POD. Nesse POD, todos os serviços necessários são lançados.No POD, um agente muito simples que lê uma declaração no estilo travis ou circleci, e no YAML, um conjunto de etapas. Ele começa a cumpri-los. Então, no final da compilação, ele lança seu resultado no telegrama.Outro recurso que obtivemos com o Kubernetes é que um dos comandos na execução de seu IC ou entrega contínua pode ser definido simplesmente enquanto o sono for verdadeiro 10, e seu POD congelará nesta etapa. Você executa o kubectl exec, se encontra dentro da sua compilação e pode estrear.Outro recurso - tudo é construído em janelas de encaixe e você pode depurar o script localmente, iniciando a janela de encaixe. Tudo levou duas semanas e 300 linhas de código.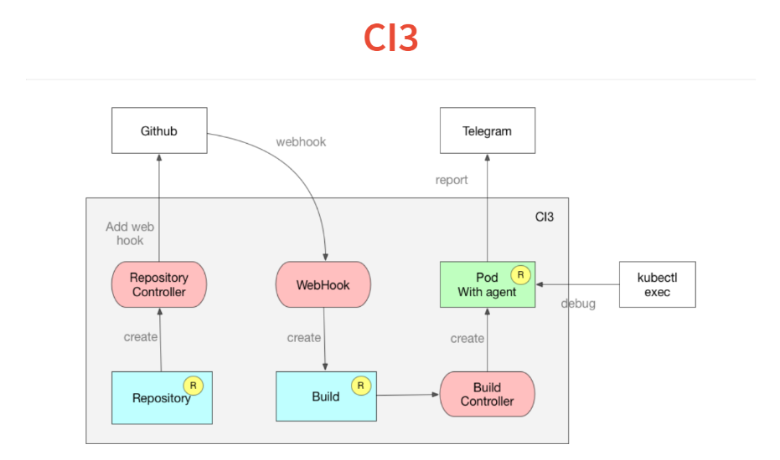
Trabalhar com o postgres
Nosso produto é construído no postgres, usamos todos os tipos de recursos interessantes. Até escrevemos várias extensões. Mas não podemos usar o RDS ou qualquer outra coisa.Agora estamos no processo de desenvolvimento de um operador para um postgres indestrutível. Vou soar arquitetura. Eu quero dizer: "Cluster, me dê um postgres que não possa ser morto". Adicione a isso que eu preciso de duas réplicas assíncronas, uma síncrona, backups diários e até um terabyte. Eu jogo tudo, então meu controlador de cluster começa a orquestrar e expandir meu contêiner. Ele cria recursos de instância que são responsáveis por cada postgres de instância. Este será o postgres de cluster.Controlador pginstance adicional, bastante simples, apenas tentando executar o POD ou a implantação lá com este postgres. O coração é volume persistente. Toda esta máquina assume o controle total do postgres. Você fornece a ela um contêiner Docker, que possui apenas postgres binários. Tudo o resto: o próprio controlador faz a configuração e a criação do cluster de início do postgres. Ele faz isso para que possamos reconfigurar mais tarde e para que ele possa configurar a replicação, os níveis de log etc. No início, o POD temporário é executado sobre o volume persistente e cria um cluster postgres para o mestre lá.Em seguida, além disso, a implantação começa com o mestre. Em seguida, um volume persistente é criado da mesma maneira. Outro POD é executado, faz um backup básico, faz o backup e, além disso, a implantação começa com um escravo.Em seguida, o controlador de cluster cria um recurso de backup (depois de ter sido descrito com backups). E o controlador de backup já pega e joga em algum S3.
O que vem a seguir?
Vamos apresentar o futuro próximo a você. Pode acontecer que, mais cedo ou mais tarde, tenhamos recursos personalizados tão interessantes, controladores personalizados que direi "Dê-me o postgres, dê-me kafka, deixe-me o IC e inicie tudo". Tudo será simples.Se não estamos falando sobre o futuro próximo, eu, como programador declarativo, acho que apenas a programação lógica ou relacional é superior à programação funcional. Lá, nossa semântica de operações é completamente separada da semântica de informações. Se olharmos atentamente para nossos controladores personalizados, fizemos, por exemplo, um aplicativo de recurso em nosso banco de dados. E extraímos mais três recursos adicionais. Isso é muito semelhante à exibição do banco de dados. Esta é uma descoberta de fato. Esta é uma visão lógica ou de relação.O próximo passo para o Kubernetes é fornecer uma certa ilusão de uma base relacional ou lógica em vez de uma API REST cortada, na qual você pode simplesmente escrever uma regra. Como, mais cedo ou mais tarde, tudo flui para o banco de dados, incluindo feedback, as regras podem parecer assim: "Se a carga aumentou assim, aumente a replicação assim". Teremos uma pequena regra sql ou lógica. Tudo que você precisa é de um mecanismo genérico que siga isso. Mas este é um futuro brilhante.
— DevOops 2018 ! — .
«The DevOps Handbook» , «Learning Chef: A Guide to Configuration Management and Automation» , «How to containerize your Go code» «Liquid Software: How to Achieve Trusted Continuous Updates in the DevOps World» — . - .
: !
: 1 Você pode reservar um ingresso para o DevOops 2018 com desconto.