Parece que o tópico está hackeado - muito foi dito e escrito sobre backup, portanto, não há nada para reinventar a roda, apenas pegue e faça. No entanto, toda vez que o administrador do sistema de um projeto da Web enfrenta a tarefa de configurar backups, para muitos ele fica no ar com um grande ponto de interrogação. Como coletar o backup de dados corretamente? Onde armazenar backups? Como fornecer o nível necessário de armazenamento retrospectivo de cópias? Como unificar o processo de backup para todo o zoológico de vários softwares?

Por nós mesmos, resolvemos esse problema pela primeira vez em 2011. Em seguida, nos sentamos e escrevemos nossos scripts de backup. Ao longo dos anos, usamos apenas eles, e eles forneceram um processo confiável para coletar e sincronizar backups de projetos da web de nossos clientes. Os backups foram armazenados em nosso ou em algum outro armazenamento externo, com a possibilidade de ajuste para um projeto específico.
Devo dizer que esses scripts funcionaram ao máximo. Porém, quanto mais crescemos, mais tínhamos projetos diversos com diferentes softwares e repositórios externos que nossos scripts não suportavam. Por exemplo, não tínhamos suporte para Redis e os backups quentes do MySQL e PostgreSQL que apareceram mais tarde. O processo de backup não foi monitorado, havia apenas alertas por email.
Outro problema foi o processo de suporte. Ao longo dos anos, nossos scripts compactos cresceram e se transformaram em um enorme monstro estranho. E quando nos reunimos e lançamos uma nova versão, valeu a pena o esforço de lançar a atualização para a parte dos clientes que usavam a versão anterior com algum tipo de personalização.
Como resultado, no início deste ano, tomamos uma decisão forte: substituir nossos scripts de backup antigos por algo mais moderno. Portanto, no início, nos sentamos e escrevemos toda a lista de desejos para uma nova solução. Aconteceu aproximadamente o seguinte:
- Faça backup dos dados do software usado com mais freqüência:
- Arquivos (cópia discreta e incremental)
- MySQL (backups frios / quentes)
- PostgreSQL (backups frios / quentes)
- Mongodb
- Redis
- Armazene backups em repositórios populares:
- Local
- FTP
- Ssh
- SMB
- Nfs
- Webdav
- S3
- Receba alertas em caso de problemas durante o processo de backup
- Possui um único arquivo de configuração que permite gerenciar backups centralmente
- Adicione suporte para novo software conectando módulos externos
- Especifique opções extras para coletar despejos
- Ter a capacidade de restaurar backups por meios regulares
- Fácil configuração inicial
Analisamos as soluções disponíveis
Analisamos as soluções de código aberto que já existem:
- Bacula e seus garfos, por exemplo, Bareos
- Amanda
- Borg
- Duplicidade
- Duplicidade
- Rsnapshot
- Rdiff-backup
Mas cada um deles tinha suas desvantagens. Por exemplo, o Bacula está sobrecarregado com funções que não precisamos, a configuração inicial é uma tarefa bastante trabalhosa devido à grande quantidade de trabalho manual (por exemplo, para escrever / procurar scripts de backup de banco de dados) e, para recuperar cópias, é necessário usar utilitários especiais, etc.
No final, chegamos a duas conclusões importantes:
- Nenhuma das soluções existentes nos convinha totalmente;
- Parece que nós mesmos tivemos experiência e insanidade suficientes para começar a escrever nossa decisão.
Então nós fizemos.
O nascimento do nxs-backup
O Python foi escolhido como a linguagem para implementação - é fácil de escrever e manter, flexível e conveniente. Decidiu-se descrever os arquivos de configuração no formato yaml.
Para a conveniência de oferecer suporte e adicionar backups de novo software, foi escolhida uma arquitetura modular onde o processo de coleta de backups de cada software específico (por exemplo, MySQL) é descrito em um módulo separado.
Suporte para arquivos, bancos de dados e armazenamento remoto
Atualmente, os seguintes tipos de backups de arquivos, bancos de dados e repositórios remotos são suportados:
DB:
- MySQL (backups a quente / frio)
- PostgreSQL (backups a quente / frio)
- Redis
- Mongodb
Arquivos:
- Cópia discreta
- Cópia incremental
Repositórios remotos:
- Local
- S3
- SMB
- Nfs
- FTP
- Ssh
- Webdav
Backup discreto
Para tarefas diferentes, backups discretos ou incrementais são adequados; portanto, eles implementaram os dois tipos. Você pode especificar qual método usar no nível de arquivos e diretórios individuais.
Para cópias discretas (arquivos e bancos de dados), você pode definir uma retrospectiva no formato de dias / semanas / meses.
Backup incremental
Cópias incrementais de arquivos são feitas da seguinte maneira:
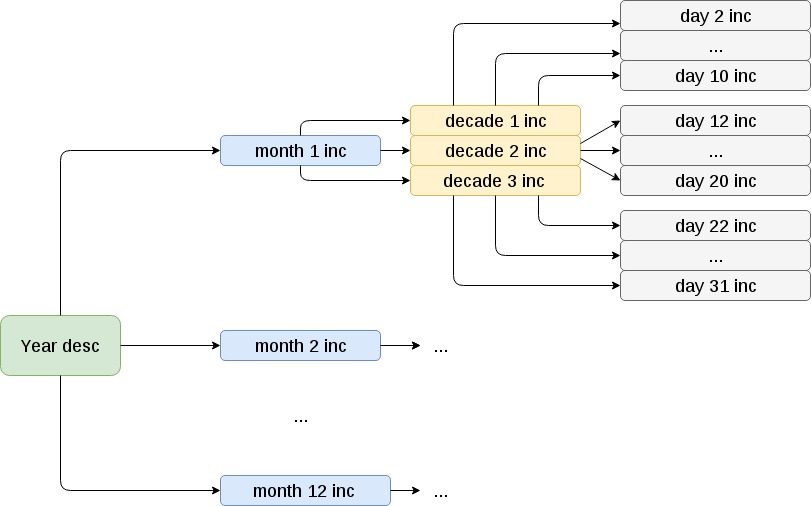
No início do ano, um backup completo será realizado. Em seguida, no início de cada mês - uma cópia mensal incremental em relação à anual. Dentro da menstruação - decadal incremental em relação ao mensal. Dentro de cada dia incremental de dez dias em relação ao período de dez dias.
Note-se que, embora haja alguns problemas ao trabalhar com diretórios que contêm um grande número de subdiretórios (dezenas de milhares). Nesses casos, a coleção de cópias é significativamente mais lenta e pode levar mais de um dia. Estamos tratando ativamente dessa lacuna.
Nós nos recuperamos de backups incrementais
Não há problemas com a recuperação de backups discretos - basta fazer uma cópia para a data necessária e implantá-la com o tar do console habitual. Cópias incrementais são um pouco mais complicadas. Para recuperar, por exemplo, em 24 de julho de 2018, você deve fazer o seguinte:
- Expanda um backup de um ano, mesmo que, no nosso caso, comece em 1 de janeiro de 2018 (na prática, pode ser qualquer data, dependendo de quando foi decidido implementar backups incrementais)
- Role nele um backup mensal para julho
- Enrole o backup da década de 21 de julho
- Acumule backup diário para 24 de julho
Ao mesmo tempo, para completar 2 a 4 pontos, adicione a opção -G ao comando tar, indicando assim que é um backup incremental. Obviamente, esse não é o processo mais rápido, mas quando você considera que não é tão necessário recuperar-se de backups e que a relação custo-benefício é importante, esse esquema acaba sendo bastante eficaz.
Exceções
Freqüentemente, você precisa excluir arquivos ou diretórios individuais dos backups, por exemplo, diretórios com cache. Isso pode ser feito especificando as regras de exceção apropriadas:
exemplo de arquivo de configuração- target: - /var/www/*/data/ excludes: - exclude1/exclude_file - exclude2 - /var/www/exclude_3
Rotação de backup
Em nossos scripts antigos, a rotação foi implementada para que a cópia antiga fosse excluída somente depois que a nova fosse montada com êxito. Isso levou a problemas em projetos nos quais o espaço para backups, em princípio, foi alocado exatamente para uma cópia - uma cópia nova não pôde ser coletada lá devido à falta de espaço.
Na nova implementação, decidimos mudar essa abordagem: primeiro exclua a antiga e depois colete uma nova cópia. E o processo de coleta de backups deve ser monitorado para descobrir quaisquer problemas.
Para backups discretos, um arquivo morto é considerado uma cópia antiga que vai além do esquema de armazenamento especificado no formato dias / semanas / meses. No caso de backups incrementais, os backups são armazenados por padrão por um ano, e as cópias antigas são excluídas no início de cada mês, enquanto os arquivos do mesmo mês do ano passado são considerados backups antigos. Por exemplo, antes de coletar um backup mensal em 1º de agosto de 2018, o sistema verificará se há backups para agosto de 2017 e, se houver, os excluirá. Isso permite o uso ideal do espaço em disco.
Registo
Em qualquer processo, e especialmente nos backups, é importante manter-se a par e descobrir se algo deu errado. O sistema mantém um registro de seu trabalho e captura o resultado de cada etapa: início / parada de fundos, início / fim de uma tarefa específica, resultado da coleta de uma cópia em um diretório temporário, resultado da cópia / movimentação de uma cópia de um diretório temporário para um local permanente, o resultado da rotação de backup etc. ..
Os eventos são divididos em 2 níveis:
- Info : nível de informação - o vôo é normal, a próxima etapa foi concluída com êxito, uma entrada de informações correspondente é feita no log
- Erro : nível de erro - algo deu errado, o estágio seguinte falhou, um registro de erro correspondente é feito no log
Notificações por email
No final da coleção de backup, o sistema pode enviar notificações por email.
2 listas de destinatários são suportadas:
- Administradores são aqueles que atendem ao servidor. Eles recebem apenas notificações de erros; não estão interessados em notificações de operações bem-sucedidas
- Usuários corporativos - no nosso caso, esses são clientes que às vezes desejam receber notificações para garantir que tudo esteja bem com os backups. Ou, inversamente, na verdade não. Eles podem optar por receber um log completo ou apenas um log com erros.
Estrutura do arquivo de configuração
A estrutura dos arquivos de configuração é a seguinte:
exemplo de estrutura /etc/nxs-backup ├── conf.d │ ├── desc_files_local.conf │ ├── external_clickhouse_local.conf │ ├── inc_files_smb.conf │ ├── mongodb_nfs.conf │ ├── mysql_s3.conf │ ├── mysql_xtradb_scp.conf │ ├── postgresql_ftp.conf │ ├── postgresql_hot_webdav.conf │ └── redis_local_ftp.conf └── nxs-backup.conf
Aqui /etc/nxs-backup/nxs-backup.conf é o principal arquivo de configuração no qual as configurações globais são indicadas:
arquivo de configuração main: server_name: SERVER_NAME admin_mail: project-tech@nixys.ru client_mail: - '' mail_from: backup@domain.ru level_message: error block_io_read: '' block_io_write: '' blkio_weight: '' general_path_to_all_tmp_dir: /var/nxs-backup cpu_shares: '' log_file_name: /var/log/nxs-backup/nxs-backup.log jobs: !include [conf.d
A matriz de tarefas (tarefas) contém uma lista de tarefas (tarefas), que são uma descrição do que exatamente fazer backup, onde armazenar e em que quantidade. Como regra, eles são movidos para arquivos separados (um arquivo por trabalho), que são conectados via include no arquivo de configuração principal.
Eles também cuidaram de otimizar o processo de preparação desses arquivos o máximo possível e escreveram um gerador simples. Portanto, o administrador não precisa gastar tempo procurando o modelo de configuração para algum serviço, por exemplo, MySQL, mas simplesmente execute o comando:
nxs-backup generate --storage local scp --type mysql --path /etc/nxs-backup/conf.d/mysql_local_scp.conf
A saída gera o arquivo /etc/nxs-backup/conf.d/mysql_local_scp.conf :
Conteúdo do arquivo - job: PROJECT-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: '' db_port: '' socket: '' db_user: '' db_password: '' auth_file: '' target: - all excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump store: days: '' weeks: '' month: '' - storage: scp enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump user: '' host: '' port: '' password: '' path_to_key: '' store: days: '' weeks: '' month: ''
No qual resta apenas substituir alguns valores necessários.
Vamos dar um exemplo. Suponha que em nosso servidor no diretório / var / www haja dois sites da loja online 1C-Bitrix (bitrix-1.ru, bitrix-2.ru), cada um dos quais trabalhe com seu próprio banco de dados em diferentes instâncias do MySQL (porta 3306 para bitrix_1_db e porta 3307 para bitrix_2_db).
A estrutura do arquivo de um projeto típico do Bitrix é aproximadamente a seguinte:
├── ... ├── bitrix │ ├── .. │ ├── admin │ ├── backup │ ├── cache │ ├── .. │ ├── managed_cache │ ├── .. │ ├── stack_cache │ └── .. ├── upload └── ...
Como regra, o diretório de upload pesa muito e cresce apenas com o tempo, portanto, o backup é feito de forma incremental. Todos os outros diretórios são discretos, com exceção dos diretórios com cache e backups coletados pelas ferramentas nativas do Bitrix. Deixe o esquema de armazenamento de backup desses dois sites ser o mesmo, enquanto as cópias dos arquivos devem ser armazenadas localmente e no armazenamento ftp remoto, e o banco de dados deve ser armazenado apenas no armazenamento smb remoto.
Os arquivos de configuração resultantes para essa configuração terão a seguinte aparência:
bitrix-desc-files.conf (arquivo de configuração com descrição da tarefa para backup discreto) - job: Bitrix-desc-files type: desc_files tmp_dir: /var/nxs-backup/files/desc/dump_tmp sources: - target: - /var/www/*/ excludes: - bitrix/backup - bitrix/cache - bitrix/managed_cache - bitrix/stack_cache - upload gzip: yes storages: - storage: local enable: yes backup_dir: /var/nxs-backup/files/desc/dump store: days: 6 weeks: 4 month: 6 - storage: ftp enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: ftp_host user: ftp_usr password: ftp_usr_pass store: days: 6 weeks: 4 month: 6
bitrix-inc-files.conf (arquivo de configuração com descrição da tarefa para backup incremental) - job: Bitrix-inc-files type: inc_files sources: - target: - /var/www/*/upload/ gzip: yes storages: - storage: ftp enable: yes backup_dir: /nxs-backup/files/inc host: ftp_host user: ftp_usr password: ftp_usr_pass - storage: local enable: yes backup_dir: /var/nxs-backup/files/inc
bitrix-mysql.conf (arquivo de configuração com descrição da tarefa para backups do MySQL) - job: Bitrix-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: localhost db_port: 3306 db_user: bitrux_usr_1 db_password: password_1 target: - bitrix_1_db excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' - connect: db_host: localhost db_port: 3307 db_user: bitrix_usr_2 db_password: password_2 target: - bitrix_2_db excludes: - information_schema - performance_schema - mysql - sys gzip: yes is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: smb enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: smb_host port: smb_port share: smb_share_name user: smb_usr password: smb_usr_pass store: days: 6 weeks: 4 month: 6
Opções para começar a coletar backups
No exemplo anterior, preparamos arquivos de configuração de tarefas para coletar backups de todos os elementos de uma só vez: arquivos (discretos e incrementais), dois bancos de dados e armazená-los em armazenamentos locais e externos (ftp, smb).
Resta executar a coisa toda. O lançamento é realizado pelo comando:
nxs-backup start $JOB_NAME -c $PATH_TO_MAIN_CONFIG
Existem vários nomes de trabalhos reservados:
- files - execução arbitrária de todos os trabalhos com os tipos desc_files , inc_files (ou seja, em essência, apenas o backup dos arquivos é feito )
- bancos de dados - executando aleatoriamente todos os trabalhos com os tipos mysql , mysql_xtradb , postgresql , postgresql_hot , mongodb , redis (ou seja, faça backup apenas do banco de dados)
- external - executando aleatoriamente todos os trabalhos com o tipo externo (executando apenas scripts personalizados adicionais, mais sobre isso abaixo)
- all - imitação de executar o comando um por um com arquivos de trabalho, bancos de dados , externos (valor padrão)
Como precisamos obter backups de dados dos arquivos e do banco de dados ao mesmo tempo (ou com uma diferença mínima) na saída, é recomendável executar o nxs-backup com o job all , o que garantirá a execução consistente do job descrito (Bitrix-desc- arquivos, Bitrix-inc_files, Bitrix-mysql).
Ou seja, um ponto importante - os backups não serão coletados em paralelo, mas sequencialmente, um após o outro, com uma diferença de tempo mínima. Além disso, na próxima partida, o próprio software verifica o processo em execução no sistema e, se for detectado, encerrará automaticamente seu trabalho com a marca correspondente no log. Essa abordagem reduz significativamente a carga no sistema. Menos - os backups de elementos individuais são coletados não de uma só vez, mas com alguma diferença de horário. Mas enquanto nossa prática mostra que isso não é crítico.
Módulos externos
Como mencionado acima, graças à arquitetura modular, os recursos do sistema podem ser expandidos usando módulos de usuário adicionais que interagem com o sistema por meio de uma interface especial. O objetivo é poder, no futuro, adicionar suporte para backups de novos softwares sem a necessidade de reescrever o nxs-backup.
exemplo de arquivo de configuração - job: TEST-external type: external dump_cmd: '' storages: ….
Atenção especial deve ser dada à chave dump_cmd , em que o valor é o comando completo para executar um script externo. Além disso, após a conclusão deste comando, espera-se que:
- Um arquivo pronto de dados de software será coletado
- Os dados serão enviados para stdout no formato json, no formato:
{ "full_path": "ABS_PATH_TO_ARCHIVE", "basename": "BASENAME_ARCHIVE", "extension": "EXTERNSION_OF_ARCHIVE", "gzip": true/false }
- Nesse caso, as chaves basename , extension , gzip são necessárias exclusivamente para a formação do nome do backup final.
- No caso de conclusão bem-sucedida do script, o código de retorno deve ser 0 e qualquer outro em caso de problemas.
Por exemplo, suponha que tenhamos um script para criar o instantâneo etcd /etc/nxs-backup-ext/etcd.py :
A configuração para executar este script é a seguinte:
arquivo de configuração - job: etcd-external type: external dump_cmd: '/etc/nxs-backup-ext/etcd.py' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/external/dump store: days: 6 weeks: 4 month: 6
Nesse caso, o programa ao executar o trabalho etcd-external :
- Execute o script /etc/nxs-backup-ext/etcd.py sem parâmetros
- Após a conclusão do script, ele verificará o código de conclusão e a disponibilidade dos dados necessários no stdout
- Se todas as verificações forem bem-sucedidas, o mesmo mecanismo será usado nos módulos já incorporados, em que o valor da chave full_path é usado como tmp_path. Caso contrário, ele concluirá esta tarefa com a marca correspondente no log.
Suporte e atualização
O processo de desenvolvimento e suporte do novo sistema de backup foi implementado com todos os cânones do CI / CD. Chega de atualizações e edições de script nos servidores de batalha. Todas as alterações passam pelo nosso repositório central do git no Gitlab, onde o conjunto de novas versões dos pacotes deb / rpm é registrado no pipeline, que é então carregado nos nossos repositórios deb / rpm. E depois disso, através do gerenciador de pacotes, eles são entregues aos servidores do cliente final.
Como baixar nxs-backup?
Criamos o projeto de código aberto nxs-backup. Qualquer um pode fazer o download e usá-lo para organizar o processo de backup em seus projetos, bem como modificar de acordo com suas necessidades, escrever módulos externos.
O código fonte do nxs-backup pode ser baixado do repositório do Github neste link . Há também instruções de instalação e configuração.
Também preparamos uma imagem do Docker e a publicamos no DockerHub .
Se você tiver dúvidas durante o processo de configuração ou uso, escreva-nos. Ajudaremos a entender e finalizar as instruções.
Conclusão
Em um futuro próximo, implementaremos a seguinte funcionalidade:
- Monitorando a integração
- Criptografia de backup
- Interface baseada na Web para gerenciar configurações de backup
- Implementando backups usando nxs-backup
- E muito mais