Os editores de texto modernos são capazes não apenas de emitir um bipe e de deixar o programa. Acontece que um metabolismo muito complexo ferve dentro deles. Deseja saber quais truques estão sendo feitos para recalcular rapidamente as coordenadas, como estilos, dobras e softwraps são anexados ao texto e como tudo é atualizado, o que a estrutura de dados funcional e a fila de prioridade têm a ver com ele, bem como como enganar o usuário - bem-vindo ao gato!

O artigo é baseado no
relatório de Alexei Kudryavtsev com o Joker 2017. Alexei escreve Intellij IDEA no JetBrains há 10 anos. Abaixo do corte, você encontrará a transcrição em vídeo e texto do relatório.
Estruturas de dados dentro de editores de texto
Para entender como o editor funciona, vamos escrever.

É isso aí, nosso editor mais simples está pronto.
Dentro do editor, o texto é mais fácil de armazenar em uma matriz de caracteres ou, o que é o mesmo (em termos de organização da memória), na classe Java StringBuffer. Para obter algum caractere por deslocamento, chamamos o método StringBuffer.charAt (i). E para inserir nele o caractere digitado no teclado, chamamos o método StringBuffer.insert (), que insere o caractere em algum lugar no meio.
O mais interessante, apesar de toda a simplicidade e idiotice deste editor, é a melhor idéia que você pode inventar. É simples e quase sempre rápido.
Infelizmente, um problema de escala surge com este editor. Imagine que imprimimos muito texto e vamos inserir outra letra no meio. O seguinte acontecerá. Precisamos urgentemente liberar espaço para esta carta movendo todas as outras letras para um caractere. Para fazer isso, trocamos esta carta por uma posição, depois a seguinte e assim por diante, até o final do texto.
Aqui está como ficaria na memória:
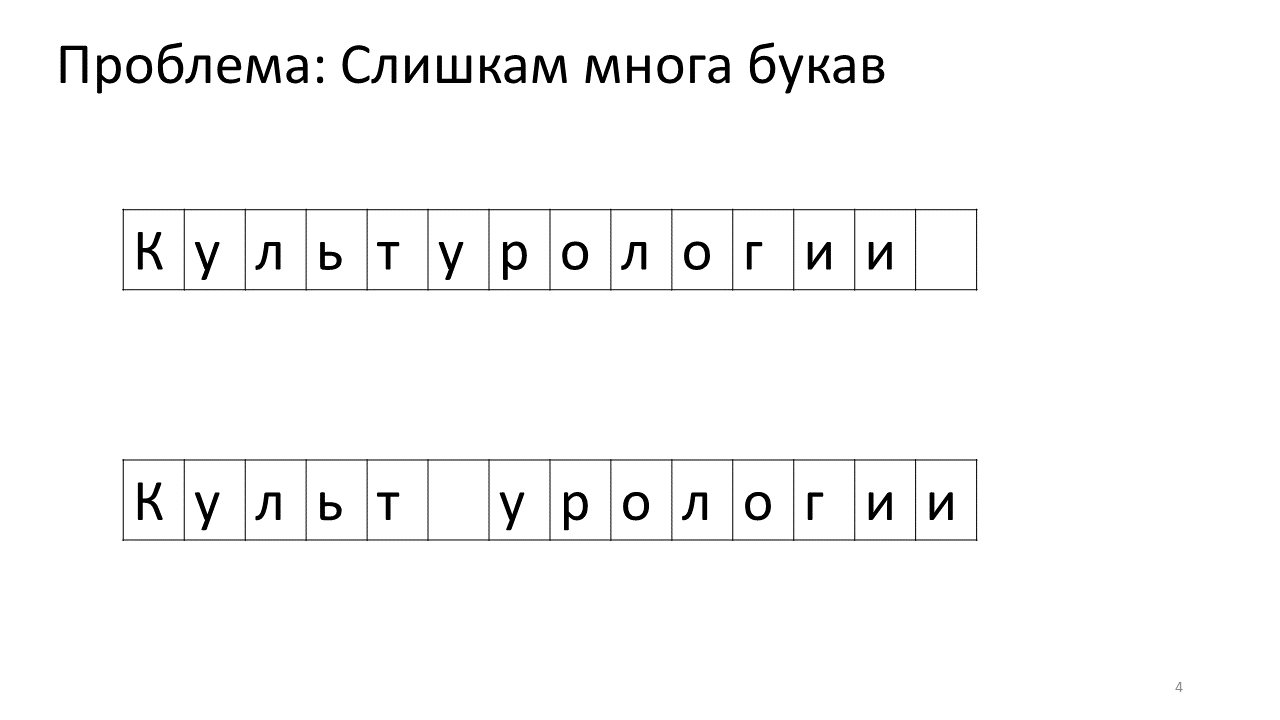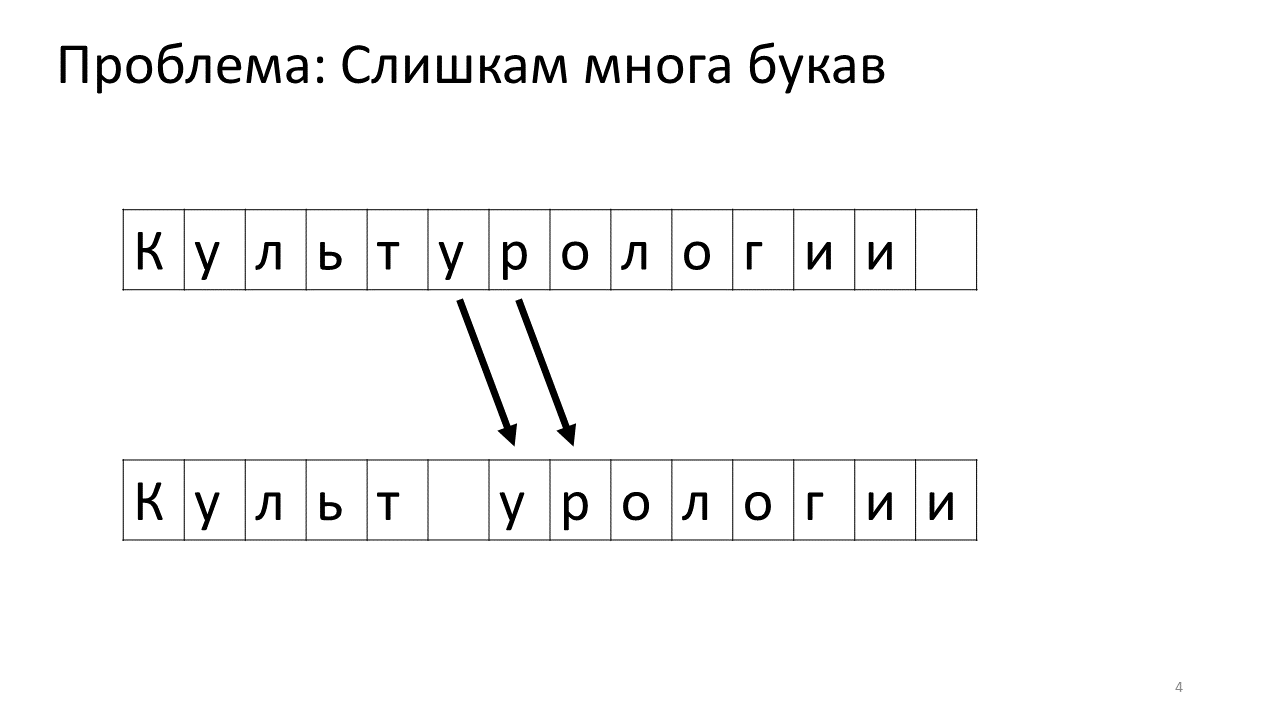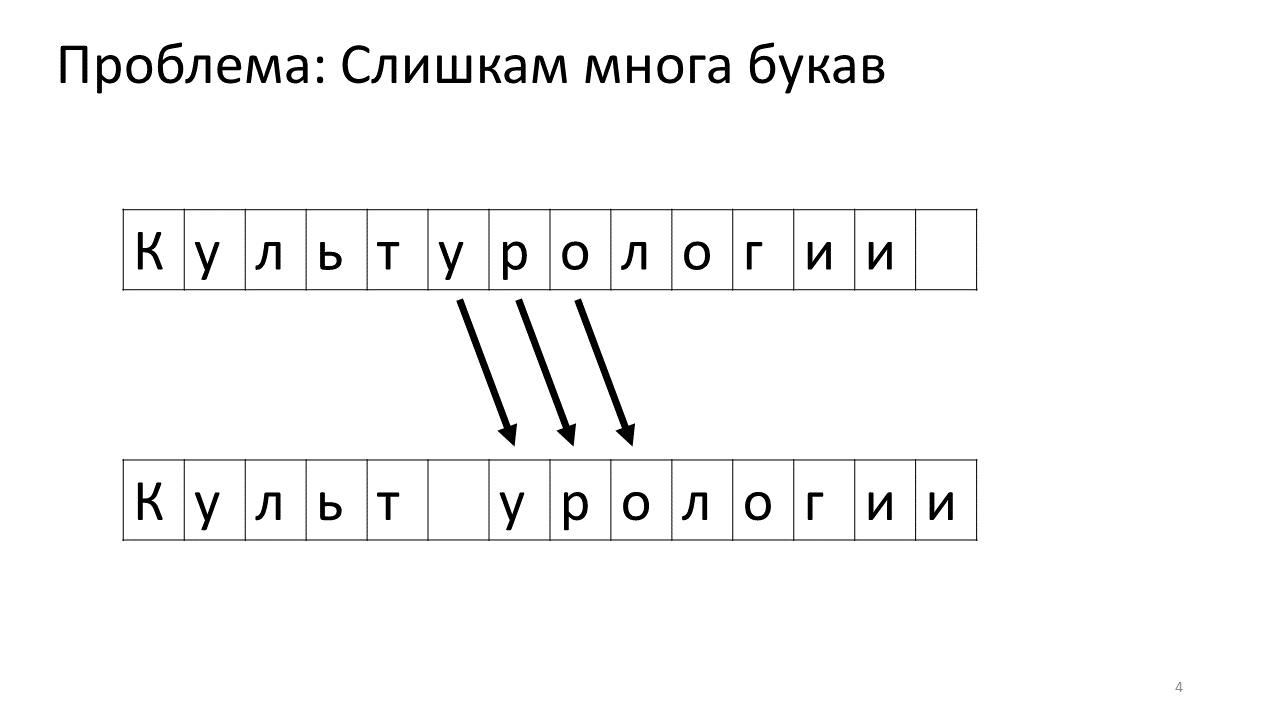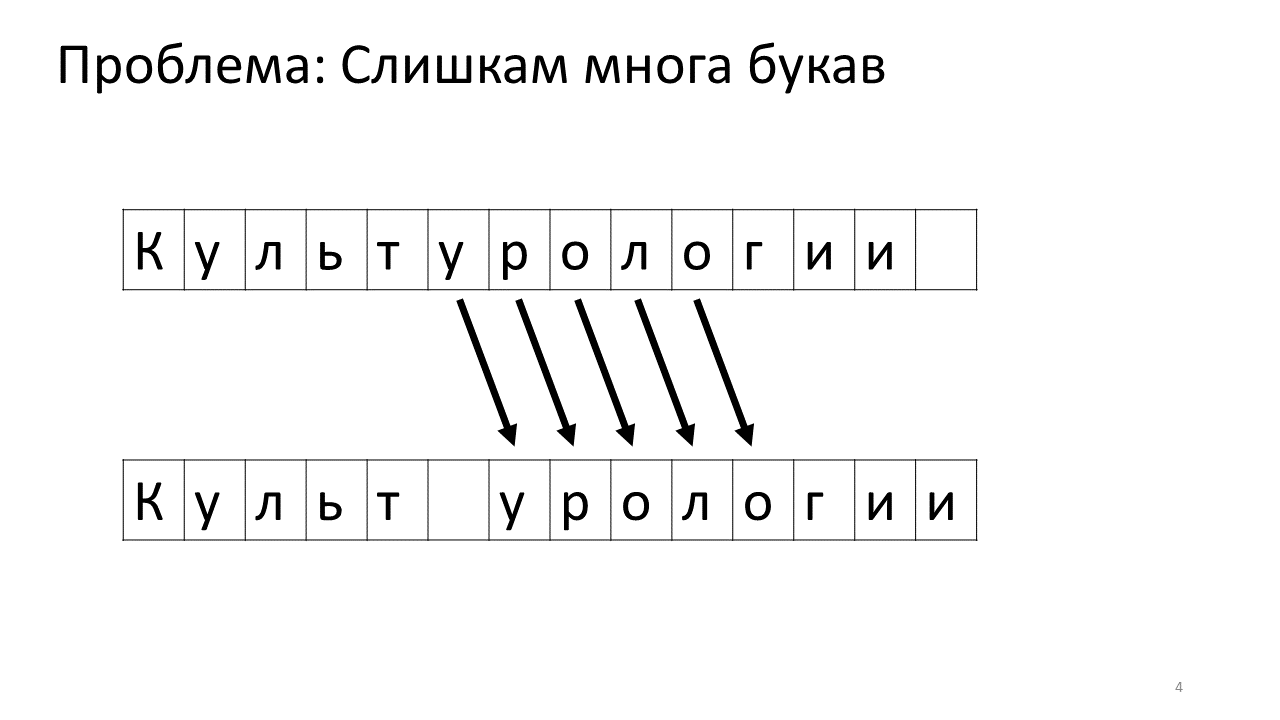
Mudar todos esses megabytes não é muito bom: é lento. Obviamente, para um computador moderno, isso é uma questão insignificante - algum tipo de megabytes patético para se mover de um lado para o outro. Mas para uma alteração de texto muito ativa, isso pode ser perceptível.
Para resolver esse problema de inserção de um caractere no meio, há muito tempo surgiu uma solução alternativa chamada "Gap Buffer".
Buffer de lacuna
Lacuna é a lacuna. Buffer é, como você pode imaginar, um buffer. A estrutura de dados do Gap Buffer é um buffer tão vazio que mantemos no meio do nosso texto, apenas por precaução. Se precisarmos imprimir algo, usamos esse pequeno buffer de texto para digitação rápida.

A estrutura dos dados mudou um pouco - a matriz permaneceu no local, mas dois ponteiros apareceram: no início do buffer e no final. Para pegar um caractere do editor em algum deslocamento, precisamos entender se é antes ou depois desse buffer e corrigir um pouco o deslocamento. E para inserir um caractere, primeiro precisamos mover o Gap Buffer para esse local e preenchê-lo com esses caracteres. E, é claro, se formos além do nosso buffer, de alguma forma o recrie. É assim que fica na imagem.

Como você pode ver, primeiro movemos por um longo período de tempo em um pequeno buffer de espaço (retângulo azul) para o local de edição (simplesmente trocando os caracteres pelas bordas esquerda e direita). Então usamos esse buffer, digitando caracteres lá.
Como você pode ver, não há movimento de megabytes de caracteres, a inserção é muito rápida, por um tempo constante, e parece que todos estão felizes. Tudo parece estar bem, mas se nosso processador estiver muito lento, será desperdiçado um tempo bastante perceptível movendo o buffer de lacuna e o texto para frente e para trás. Isso foi especialmente notável na época de megahertz muito pequeno.
Tabela de peças
Naquele momento, uma empresa chamada Microsoft escreveu um editor de texto Word. Eles decidiram aplicar outra idéia para acelerar a edição chamada "Tabela de peças", ou seja, "Tabela de peças". E eles propuseram salvar o texto do editor na mesma matriz mais simples de caracteres, que não será alterada, e colocar todas as alterações em uma tabela separada dessas mesmas partes editadas.

Portanto, se precisarmos encontrar algum caractere por deslocamento, precisamos encontrar essa peça que editamos e extraí-la e, se não estiver lá, vá para o texto original. Inserir um símbolo fica mais fácil, basta criar e adicionar esta nova peça à tabela. Aqui está como fica a figura:
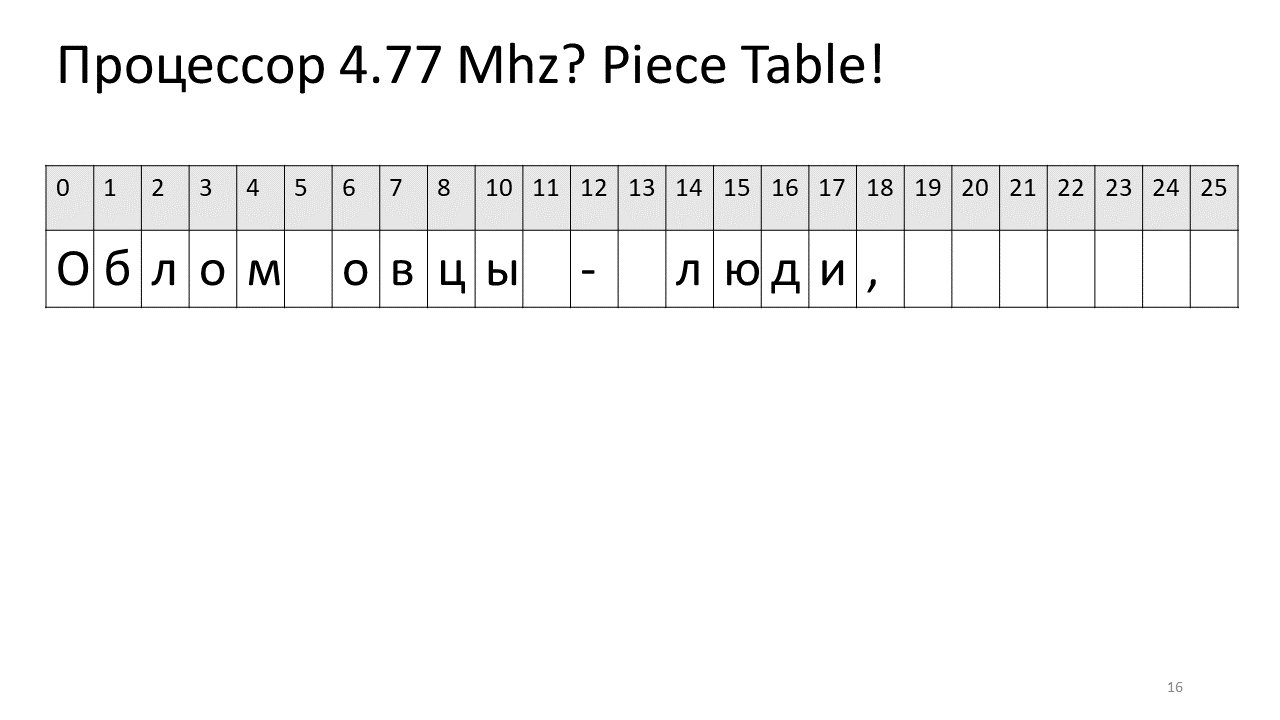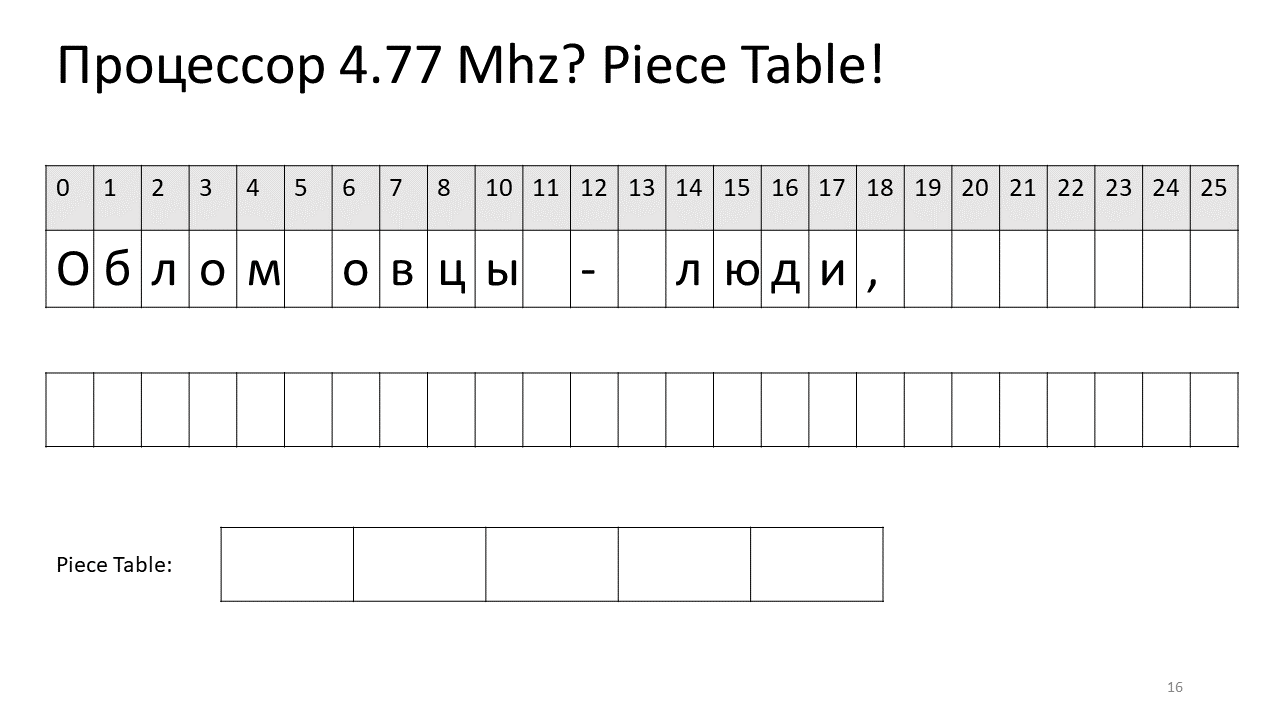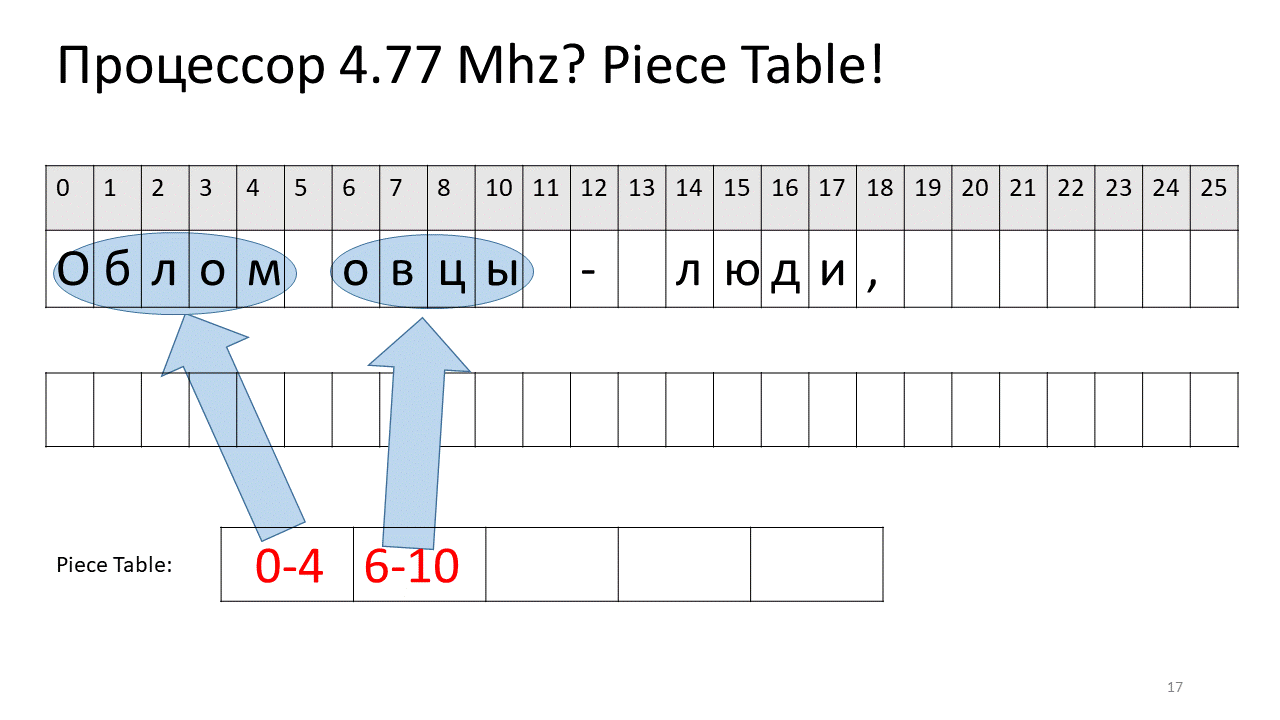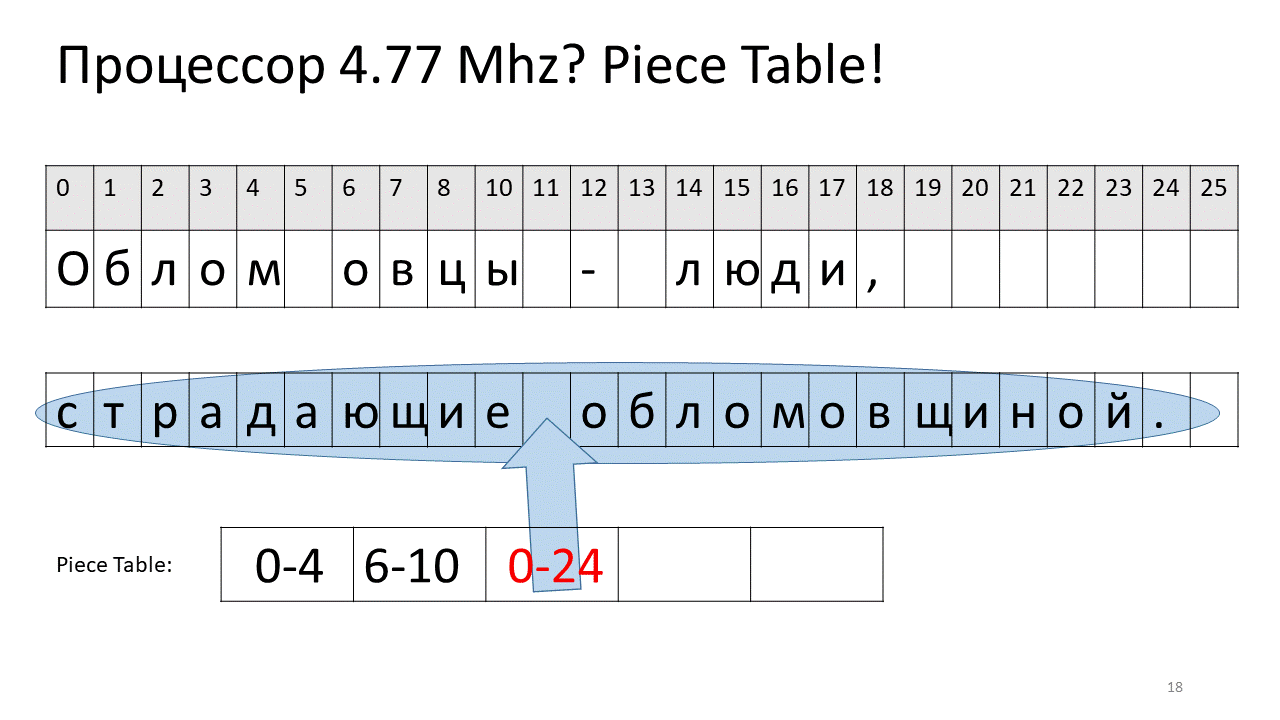
Aqui, desejamos remover o espaço no deslocamento 5. Para fazer isso, adicionamos duas novas peças à tabela de fatias: uma indica o primeiro fragmento ("Bummer") e a segunda indica o fragmento após a edição ("ovelha"). Acontece que a lacuna desaparece, essas duas peças são coladas e temos um novo texto já sem espaço: “Oblomovtsy”. Em seguida, adicionamos o novo texto ("sofrendo de oblomovismo") ao final. Use um buffer adicional e adicione uma nova fatia à tabela de peças que aponta para esse texto mais recente adicionado.
Como você pode ver, não há movimento para a frente e para trás, todo o texto permanece no lugar. A má notícia é que está ficando mais difícil chegar ao símbolo, porque é difícil classificar todas essas peças.
Para resumir.
O que há de bom na
Piece Table :
- Incorporar rapidamente;
- Fácil de desfazer;
- Anexar somente.
O que é ruim:
- É terrivelmente difícil acessar um documento;
- É terrivelmente difícil de implementar.
Vamos ver quem geralmente usamos o quê.
O NetBeans, Eclipse e Emacs usam o Gap Buffer - muito bem! Vi não se incomoda e usa apenas uma lista de linhas. O Word usa a tabela de peças (eles recentemente expuseram seus tipos antigos e você pode até entender alguma coisa).
Atom é mais interessante. Até recentemente, eles não se incomodavam e usavam uma lista de linhas JavaScript. E então eles decidiram reescrever tudo em C ++ e montaram uma estrutura bastante complicada, que parece ser semelhante à Tabela de Peças. Mas essas peças não são armazenadas na lista, mas na árvore e na chamada árvore de reprodução - essa é uma árvore que se ajusta automaticamente quando inserida nela, para que inserções recentes sejam mais rápidas. Eles fizeram uma coisa muito complicada.
O que o Intellij IDEA usa?
Não, não gap gap. Não, você também está errado, não é uma mesa de peças.
Sim, muito bem, sua própria bicicleta.
O fato é que os requisitos do IDE para armazenar texto são ligeiramente diferentes dos de um editor de texto comum. O IDE precisa de suporte para várias coisas complicadas, como competitividade, ou seja, acesso paralelo ao texto do editor. Por exemplo, para que muitos produtos assados diferentes possam lê-lo e fazer alguma coisa. (Inspeção é um pequeno pedaço de código que analisa o programa de uma maneira ou de outra - por exemplo, procurando locais que geram uma NullPointerException). O IDE também precisa de suporte à versão de texto editável. Várias versões estão simultaneamente na memória enquanto você trabalha com um documento para que esses processos longos continuem analisando a versão antiga.
Os problemas
Competitividade / Versão
Para manter o paralelismo, as operações de texto geralmente são agrupadas em "sincronizadas" ou em bloqueios de leitura / gravação. Infelizmente, isso não escala muito bem. Outra abordagem é o texto imutável, ou seja, um repositório de texto imutável.

Aqui está a aparência de um editor com um documento imutável como uma estrutura de dados de suporte.
Como a estrutura de dados funciona?
Em vez de uma matriz de caracteres, teremos um novo objeto do tipo ImmutableText, que armazena texto na forma de uma árvore, onde pequenas substrings são armazenadas nas planilhas. Ao acessar em algum deslocamento, ele tenta alcançar a folha inferior desta árvore e já lhe será solicitado o símbolo ao qual estávamos nos referindo. E quando você insere um texto, ele cria uma nova árvore e a salva no local antigo.

Por exemplo, temos um documento com o texto "Sem calorias". É implementado como uma árvore com duas folhas de substituições "Demônio" e "alto teor calórico". Quando queremos inserir a linha "bonita" no meio, uma nova versão do nosso documento é criada. E, precisamente, é criada uma nova raiz, na qual três folhas já estão anexadas: "Demônio", "suficiente" e "alto teor calórico". Além disso, duas dessas novas folhas podem se referir à primeira versão do nosso documento. E para a planilha em que inserimos a linha “bonita”, um novo vértice é alocado. Aqui, a primeira e a segunda versão estão disponíveis ao mesmo tempo e são todas imutáveis, imutáveis. Tudo parece bom.
Quem usa quais estruturas complicadas?

Por exemplo, no GNOME, alguns de seus widgets padrão usam uma estrutura chamada Rope. O Xi-Editor, o novo editor brilhante de
Raf Levien , usa Corda Persistente. E a Intellij IDEA usa essa Árvore Imutável. Por trás de todos esses nomes, de fato, há mais ou menos a mesma estrutura de dados com uma representação do texto em forma de árvore. Exceto que o GtkTextBuffer usa a Corda mutável, ou seja, uma árvore com vértices mutáveis, e Intellij IDEA e Xi-Editor - Imutável.
A próxima coisa a considerar ao desenvolver um repositório de caracteres nos IDEs modernos é chamada multicats. Esse recurso permite imprimir em vários locais ao mesmo tempo, usando vários carros.

Podemos imprimir algo e, ao mesmo tempo, em vários locais do documento, inserimos o que imprimimos lá. Se observarmos como nossas estruturas de dados, que examinamos, reagem aos multicaretas, veremos algo interessante.
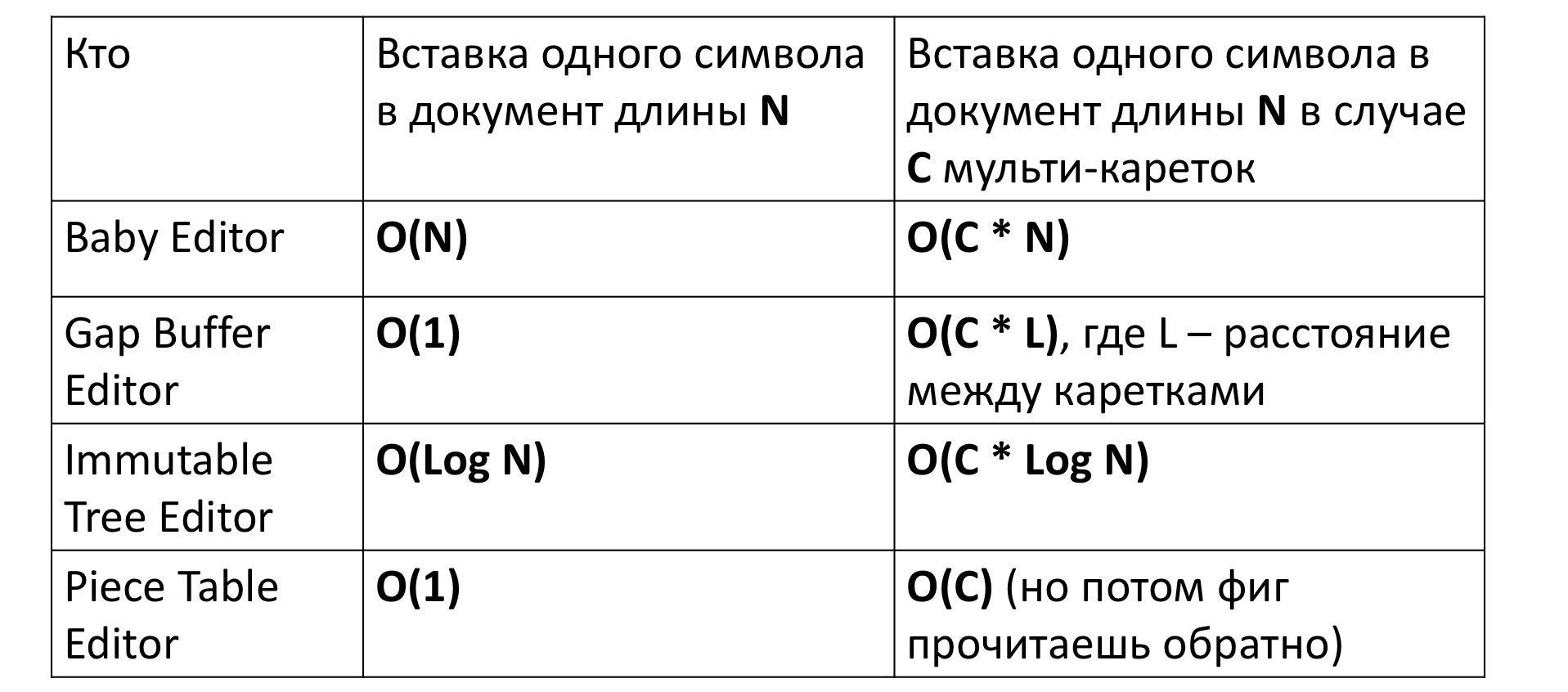
Se inserirmos um caractere em nosso primeiro editor primitivo, naturalmente levará um tempo linear para mover um monte de caracteres para frente e para trás. Isso está escrito como O (N). Para o editor baseado no Gap Buffer, por sua vez, é necessário tempo constante, para o qual ele foi cunhado.
Para uma árvore imutável, o tempo depende logaritmicamente do tamanho, porque você deve primeiro ir do topo da árvore até a folha - este é o logaritmo e, em seguida, para todos os vértices no caminho para criar novos vértices para a nova árvore - esse é novamente o logaritmo. A tabela de peças também requer uma constante.
Mas tudo muda um pouco se tentarmos medir o tempo de inserção de um personagem em um editor com várias carruagens, ou seja, inserindo simultaneamente em vários lugares. À primeira vista, o tempo parece aumentar proporcionalmente por um fator de C - o número de lugares onde o símbolo é inserido. É exatamente isso que acontece, com exceção do Gap Buffer. No caso dele, o tempo, em vez de C, aumenta inesperadamente alguns tempos C * L incompreensíveis, onde L é a distância média entre as carruagens. Por que isso está acontecendo?
Imagine que precisamos inserir a linha ", on" em dois lugares em nosso documento.
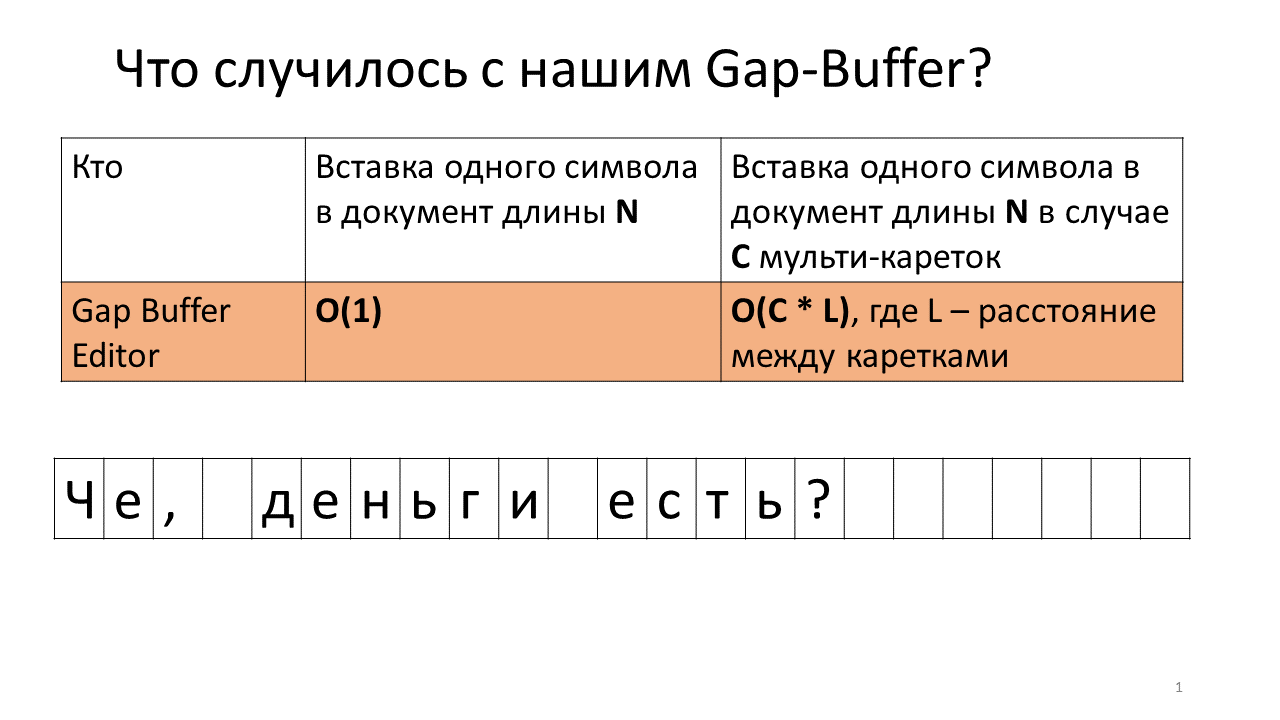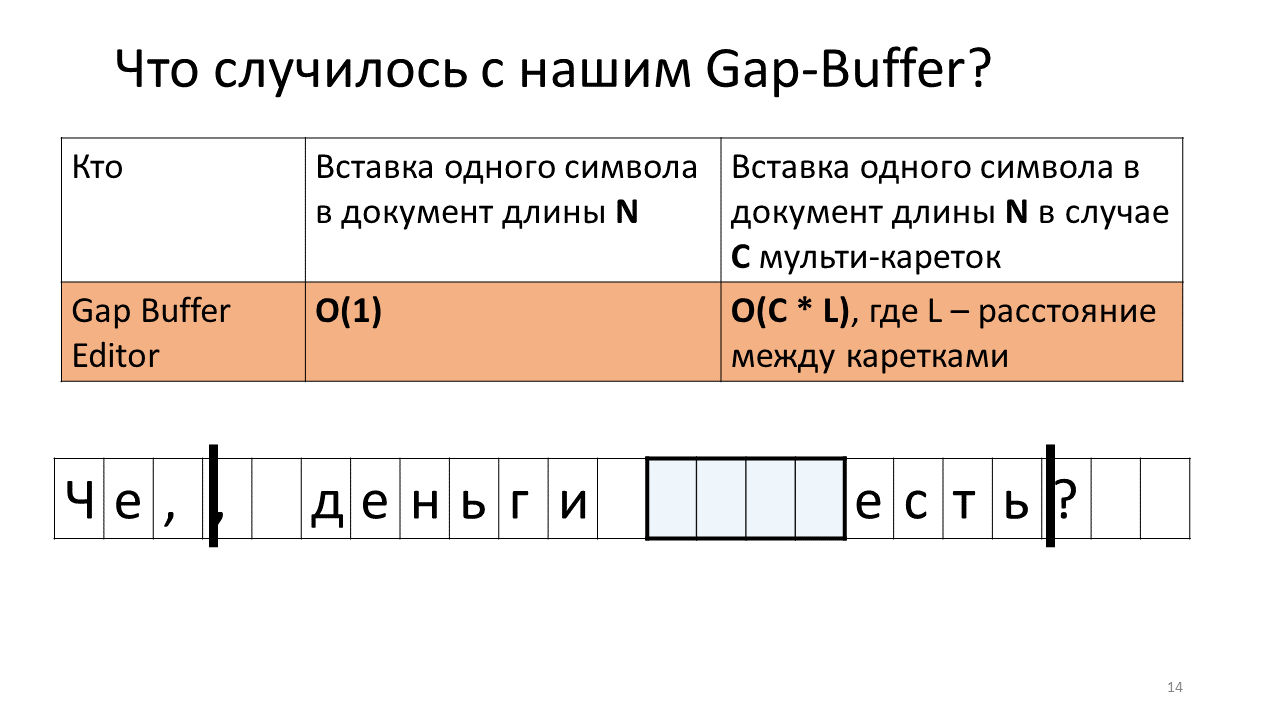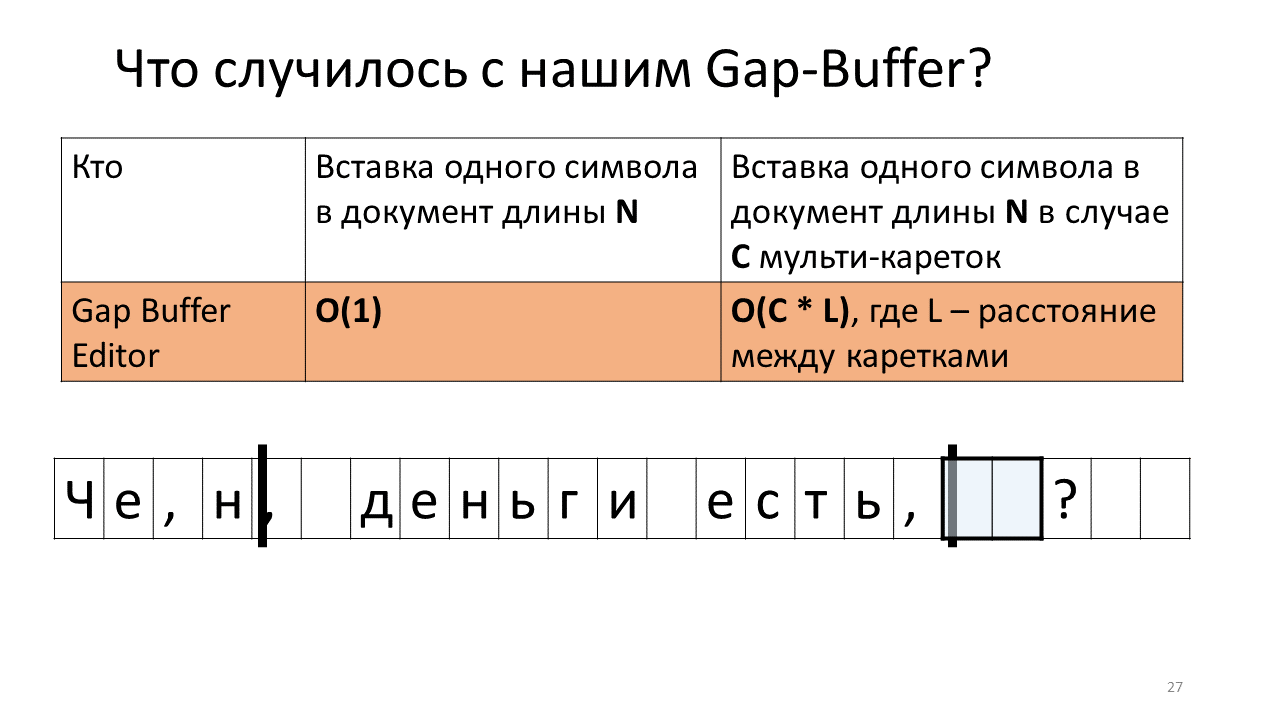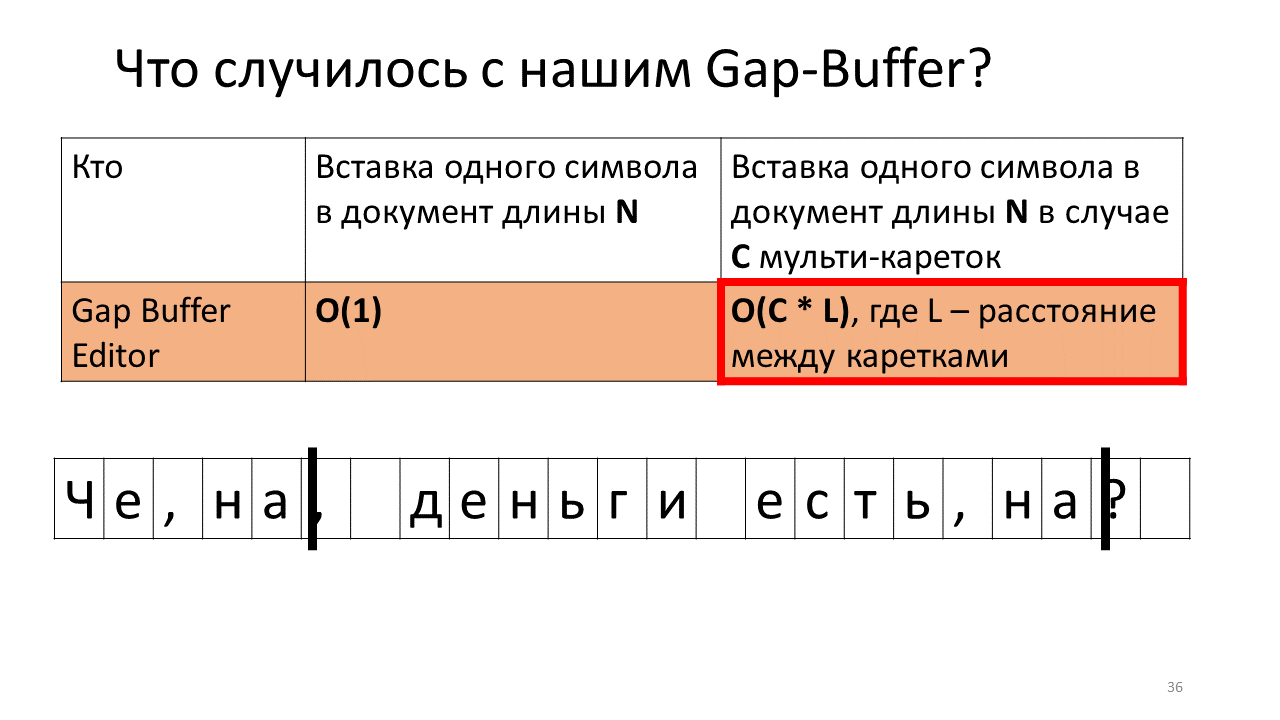
É o que acontece no editor no momento.
- Crie um buffer de diferença no editor (um pequeno retângulo azul na imagem);
- Iniciamos duas carruagens (linhas verticais em negrito e pretas);
- Estamos tentando imprimir;
- Inserir uma vírgula em nosso Gap Buffer;
- Agora você deve inseri-lo no lugar do segundo carro;
- Para fazer isso, precisamos mover nosso Gap Buffer para a posição do próximo carro;
- Imprima uma vírgula em segundo lugar;
- Agora você precisa inserir o próximo caractere na posição do primeiro carro;
- E temos que empurrar nosso Gap Buffer de volta;
- Inserir a letra "n";
- E movemos nosso amortecedor de sofrimento para o local da segunda carruagem;
- Nós inserimos nosso "n" lá;
- Mova o buffer de volta para inserir o próximo caractere.
Sente para onde está indo tudo?
Sim, acontece que, devido a esses numerosos movimentos do buffer, o tempo total aumenta. Honestamente, não é que esteja diretamente horrorizado à medida que aumenta - mover megabytes e gigabytes patéticos para um computador moderno não é um problema, mas é interessante que essa estrutura de dados funcione radicalmente de maneira diferente no caso de multicats.
Linhas demais? LineSet!
Que outros problemas existem em um editor de texto comum? O problema mais difícil é rolar, ou seja, redesenhar o editor enquanto move o carro para a próxima linha.

Quando o editor rola, precisamos entender a partir de qual linha, de qual símbolo precisamos começar a desenhar o texto em nossa pequena janela. Para fazer isso, precisamos entender rapidamente qual linha corresponde a qual deslocamento.
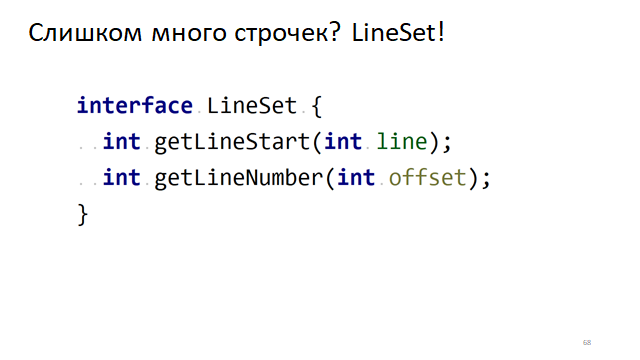
Existe uma interface óbvia para isso, quando precisamos entender seu deslocamento no texto pelo número da linha. E vice-versa, pelo deslocamento no texto para entender em que linha está. Como isso pode ser feito rapidamente?
Por exemplo, assim:
Organize essas linhas em uma árvore e marque cada vértice dessa árvore, deslocando o início da linha e o final da linha. E então, para entender pelo deslocamento em que linha está localizada, basta executar uma pesquisa logarítmica nessa árvore e localizá-la.
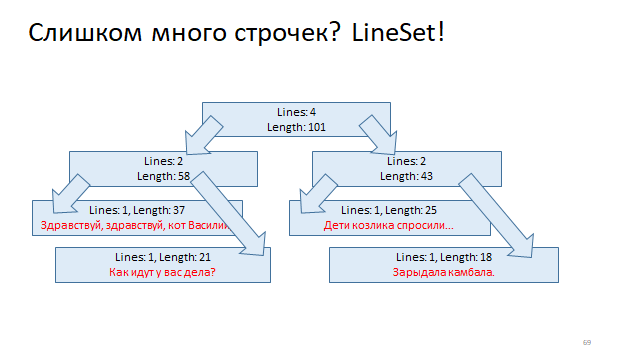
Outra maneira é ainda mais fácil.
Escreva na tabela o deslocamento do início das linhas e do final das linhas. E então, para encontrar o deslocamento do começo e do fim pelo número da linha, você precisará acessar o índice.
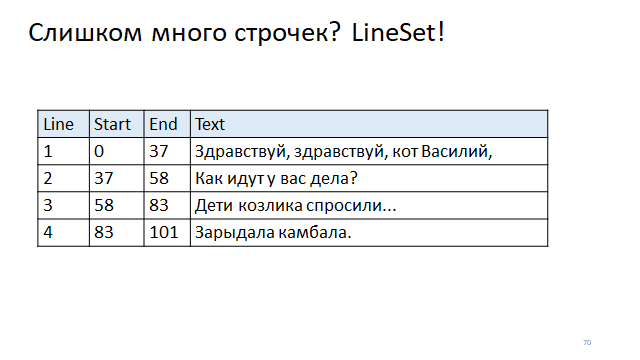
Curiosamente, no mundo real, os dois métodos são usados.

Por exemplo, o Eclipse usa uma estrutura de madeira que, como você pode ver, funciona em um tempo logarítmico para leitura e atualização. E o IDEA usa uma estrutura de tabela, para a qual a leitura é uma constante rápida, é uma reversão de índice em uma tabela, mas a reconstrução é bastante lenta, porque você precisa reconstruir a tabela inteira ao alterar o comprimento de uma linha.
Ainda há muitas linhas? Foldings!
O que mais há de ruim entre os editores de texto? Por exemplo, dobras. Estes são pedaços de texto que você pode "recolher" e mostrar outra coisa.

Esses pontos em um plano de fundo verde na imagem escondem muitos símbolos atrás de nós, mas se não estivermos interessados em examiná-los (como no caso, por exemplo, dos documentos Java ou listas de importação mais longos e chatos), os ocultamos e os reduzimos reticências.
E aqui novamente você precisa entender quando termina e quando começa a região que precisamos mostrar, e como atualizar tudo rapidamente? Como isso está organizado, vou contar um pouco mais tarde.
Linhas muito longas? Envoltório macio!

Além disso, os editores modernos não podem viver sem o Soft wrap. A imagem mostra que o desenvolvedor abriu o arquivo JavaScript após a minimização e se arrependeu imediatamente. Essa enorme linha JavaScript, quando tentamos mostrá-la no editor, não cabe em nenhuma tela. Portanto, o envoltório macio o força em várias linhas e o empurra para a tela.
Como é organizado - mais tarde.
Muito pouca beleza

E, finalmente, também quero trazer beleza aos editores de texto. Por exemplo, destaque algumas palavras. Na figura acima, as palavras-chave são destacadas em azul negrito, alguns métodos estáticos em itálico, algumas anotações - também em cores diferentes.
Então, como você ainda armazena e processa dobras, envolvimentos suaves e destaques?
Acontece que tudo isso, em princípio, é uma e a mesma tarefa.
Pouca beleza? Marcadores de gama!

Para suportar todos esses recursos, tudo o que precisamos fazer é fixar alguns atributos de texto em um determinado deslocamento no texto, por exemplo, cor, fonte ou texto para dobrar. Além disso, esses atributos de texto devem ser atualizados o tempo todo neste local para que possam sobreviver a todos os tipos de inserções e exclusões.
Como isso geralmente é implementado? Naturalmente, na forma de uma árvore.
Problema: muita beleza? Árvore de intervalo!

Por exemplo, aqui temos vários destaques amarelos que queremos manter no texto. Nós adicionamos os intervalos desses destaques em uma árvore de pesquisa, a chamada árvore de intervalo. Essa é a mesma árvore de pesquisa, mas um pouco mais complicada porque precisamos armazenar intervalos em vez de números.
E como existem intervalos saudáveis e pequenos, como classificá-los, compará-los entre si e colocá-los em uma árvore é uma tarefa não trivial. Embora muito conhecido na ciência da computação. Então olhe de alguma forma para o seu lazer como funciona. Então, pegamos e colocamos todos os nossos intervalos em uma árvore, e cada mudança no texto em algum lugar no meio leva a uma mudança logarítmica nessa árvore. Por exemplo, a inserção de um caractere deve resultar na atualização de todos os intervalos à direita desse caractere. Para fazer isso, encontramos todos os vértices dominantes desse símbolo e indicamos que todos os seus vértices devem ser movidos um símbolo para a direita.
Ainda quer beleza? Ligaduras!

Ainda existe uma coisa tão terrível - as ligaduras, que eu também gostaria de apoiar. Essas são belezas diferentes, como o sinal “! =” É desenhado na forma de um grande glifo “diferente” e assim por diante. Felizmente, aqui estamos contando com um mecanismo de giro para apoiar essas ligaduras. E, em nossa experiência, ele aparentemente trabalha da maneira mais simples. Dentro da fonte, é armazenada uma lista de todos esses pares de caracteres que, quando combinados, formam algum tipo de ligadura complicada. Então, ao desenhar a linha, o Swing simplesmente itera sobre todos esses pares, encontra os necessários e os desenha de acordo. Se você tiver muitas ligaduras na fonte, aparentemente, exibi-la diminuirá proporcionalmente.
Freios basculantes
E o mais importante - outro problema encontrado nos modernos editores complexos é a otimização da gorjeta, ou seja, pressionar as teclas e exibir o resultado.

Se você entrar no Intellij IDEA e ver o que acontece quando você pressiona um botão, acontece o seguinte horror:
- Com o clique de um botão, devemos ver se estamos no pop-up de conclusão para fechar o menu para conclusão, se, por exemplo, digitarmos “Enter”.
- Você precisa ver se o arquivo está sob algum sistema de controle de versão complicado, como o Perforce, que precisa executar alguma ação para iniciar a edição.
- Verifique se há alguma região especial no documento que não possa ser impressa, como alguns textos gerados automaticamente.
- Se o documento estiver bloqueado por uma operação que não terminou, você precisará concluir a formatação e só então continuar.
- injected-, , , - .
- auto popup handler, , , .
- info , , . selection remove, selection , . selection , .
- typed handler, , .
- .
- undo, virtual space' write action.
- , .
!
, , . , . , listener , , - . editor view. - listener'.
, , - DocumentListener?
Editor.documentChanged() :
- error stripe;
- gutter size, ;
- editor component size, ;
- ;
- soft wrap, ;
- repaint().
repaint() — Swing, . , Repaint Swing.
- , repaint , :

paint-, , .
, , ?

, , . Intellij IDEA .

, - - , , , . ! , , , - — ! , - . . «Zero latency typing».
— .
? , — , Google Docs - - .
:
, , .
- . , , . . — , «intention preservation». , - , , , . — . , - , .
Operation transformation
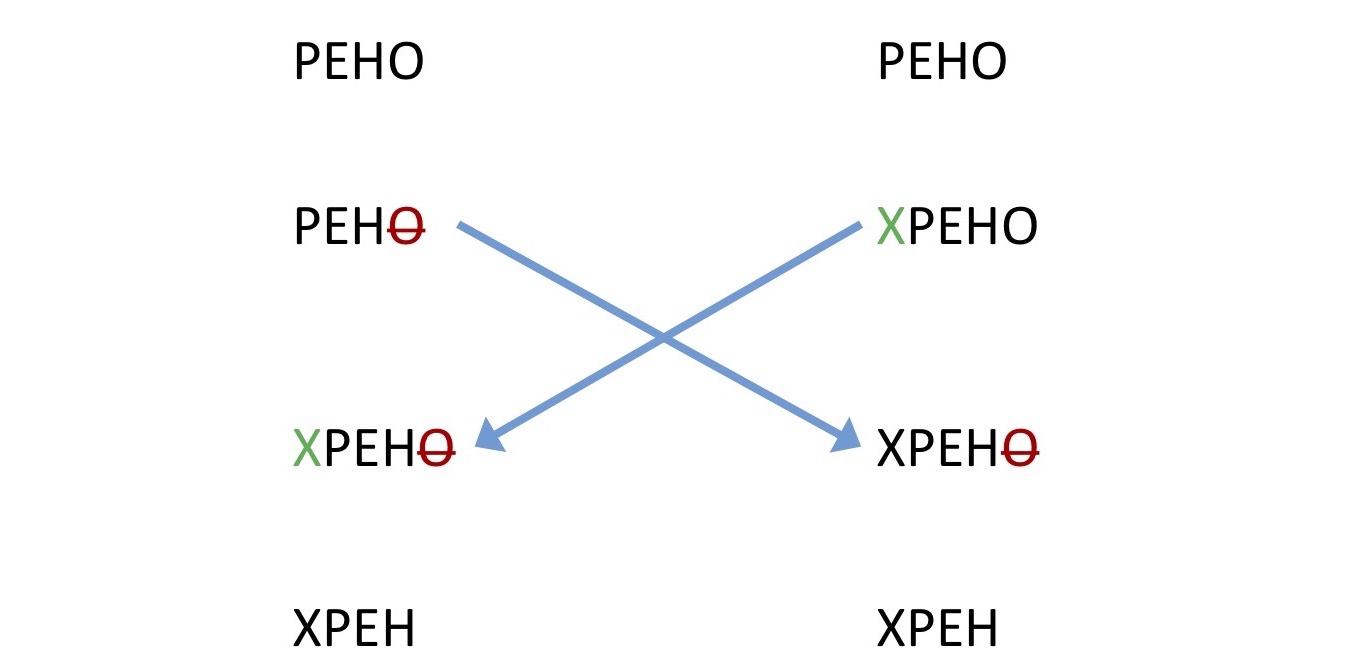
, , «operation transformation». . , - : , . Operation transformation . , , , - . , . , - . , , .
, , , . «TP2 puzzle».
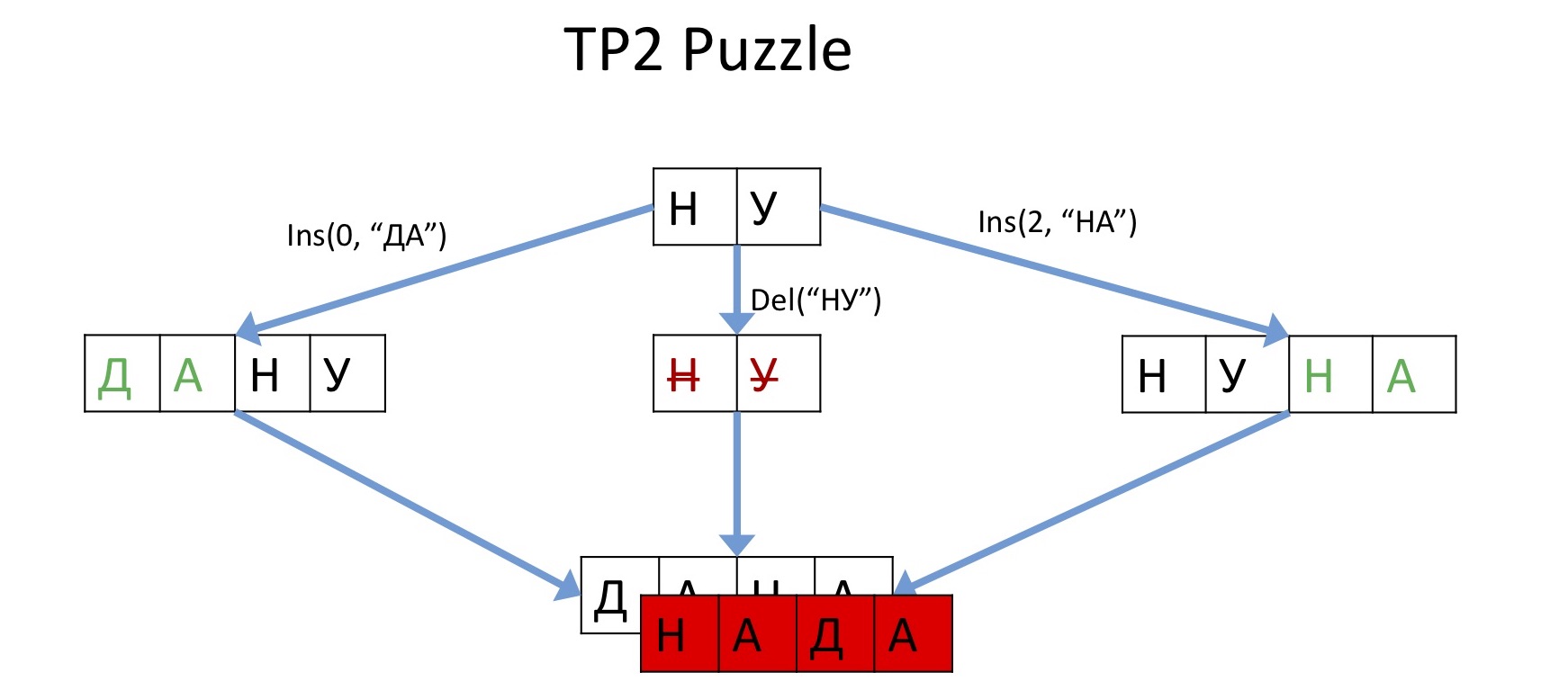
- , , . , Operation transformation , , , («»). («»). , . , Operation transformation, - .
, Google Docs, Google Wave - Etherpad. Operation transformation .
Conflict-free replicated data type
: « , OT!» , , . , , , , 100% . «CRDT» (Conflict-free replicated data type).

, , . , , , . , . - ( ), () ( ).

?
Sim , G-counter', , . , . «+1» , «+1» , , — «2». , , . G-counter, , . G-counter, . , , . . — . , CRDT. , .
Conflict-free replicated inserts
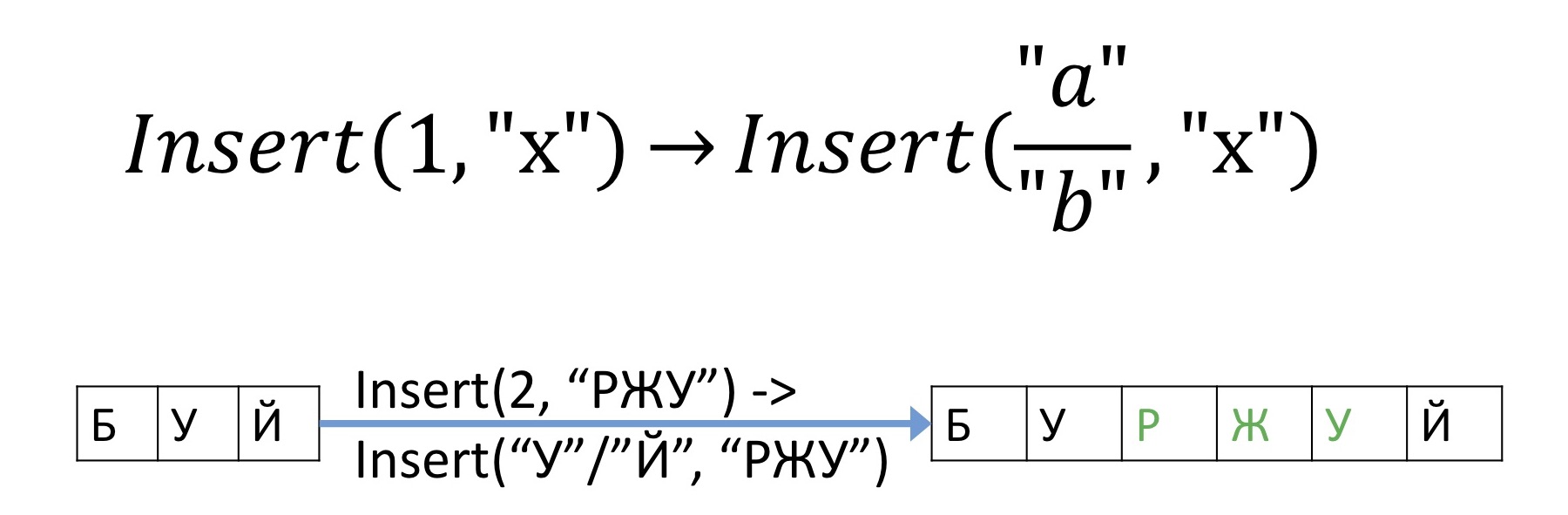
, , , . , , .
, , - - , , , , . , , , , . , , , , 2 «», , «» «» «».
Conflict-free replicated deletes
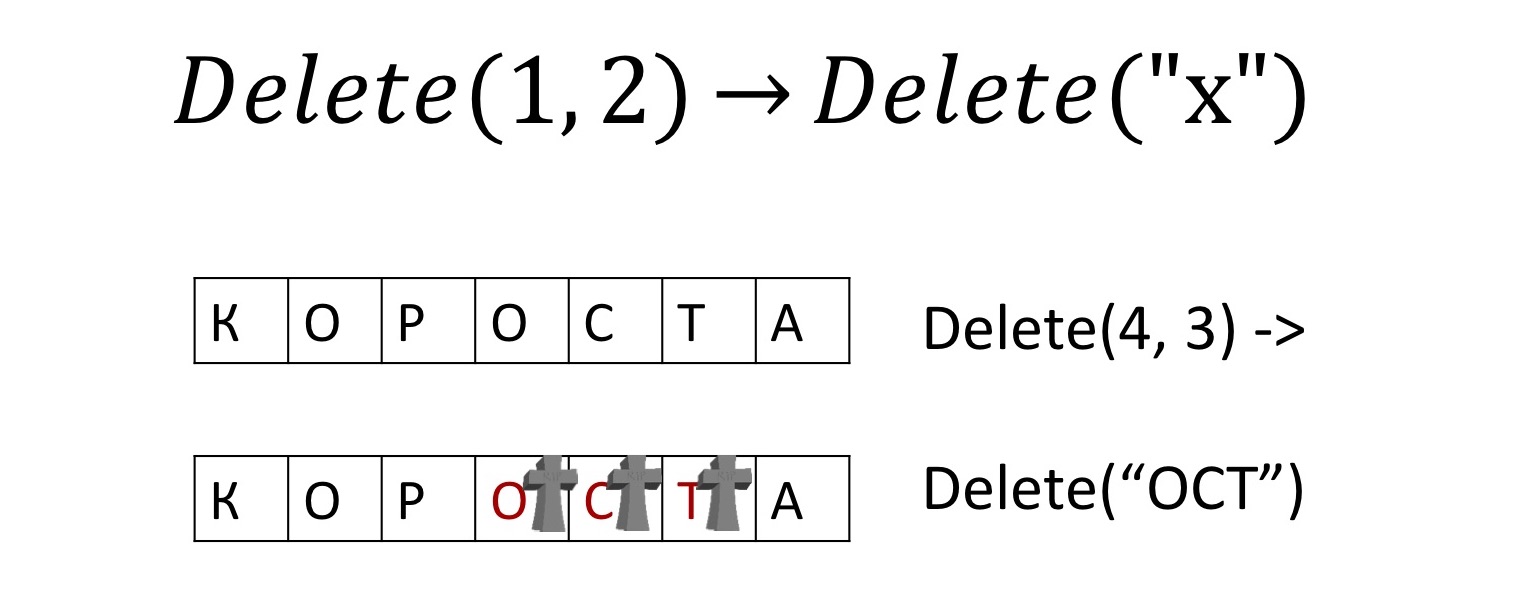
. , , , - . , , . , , , .
, .
Conflict-free replicated edits
, , CRDT - , , Xi-Editor, Fuchsia. , , .
Zipper
, «Zipper». , , . , , . , ( «» , , « »). , - . , - , . Zipper.
, . .
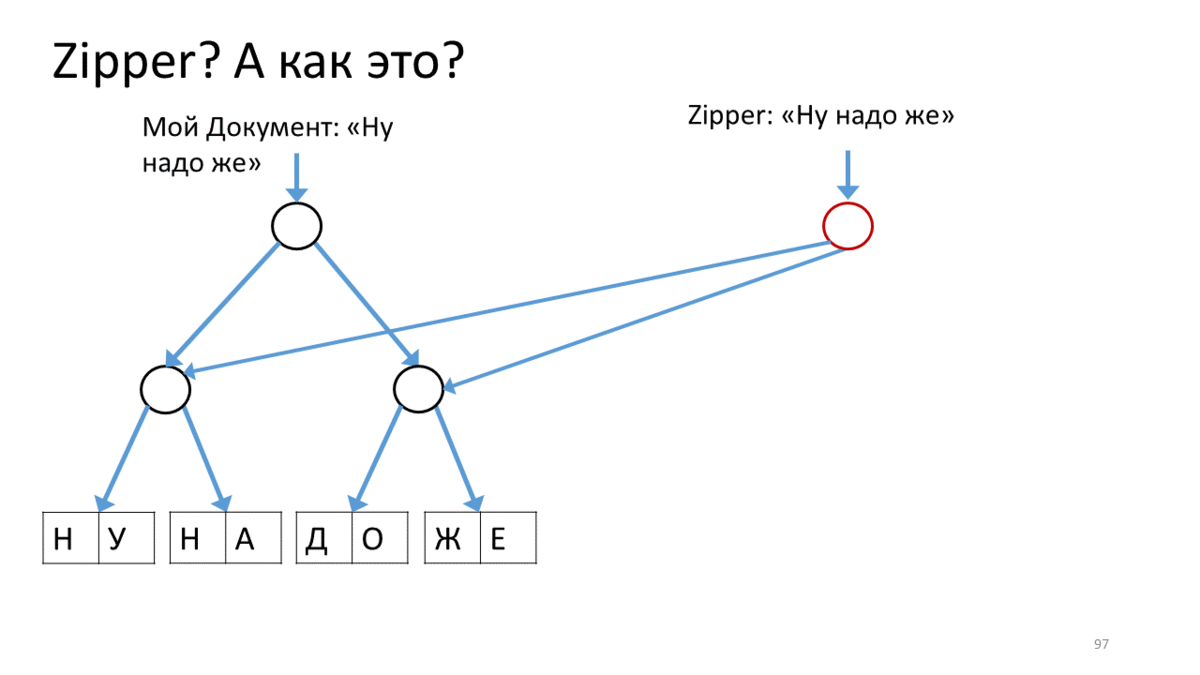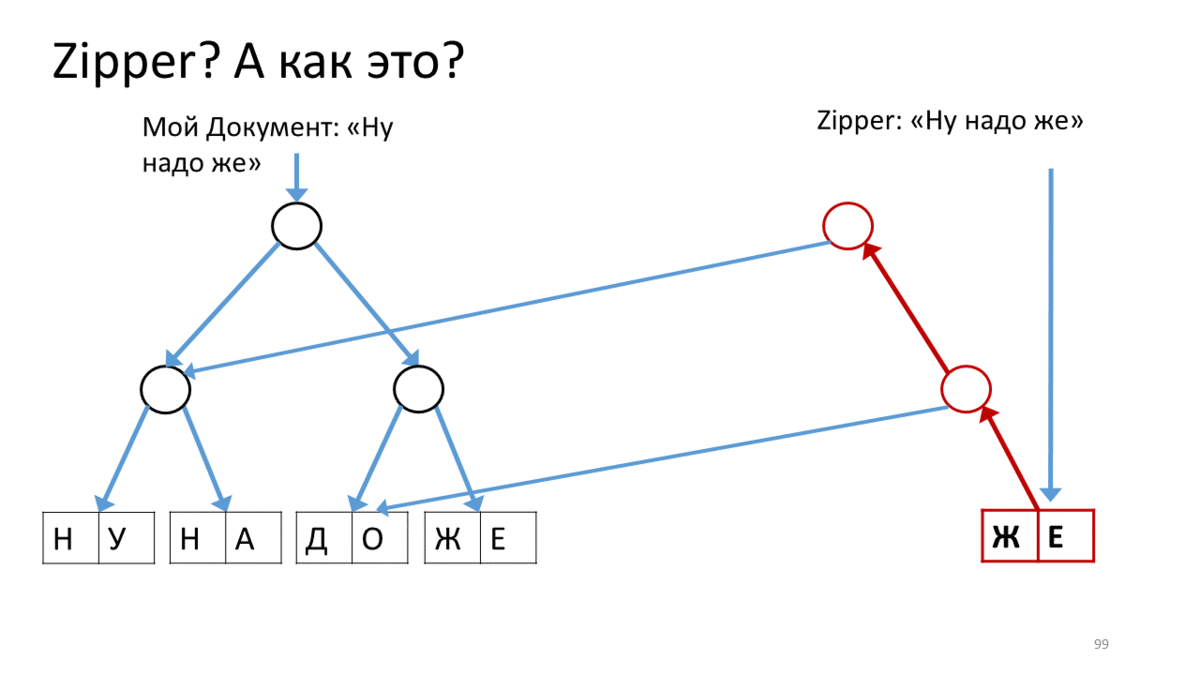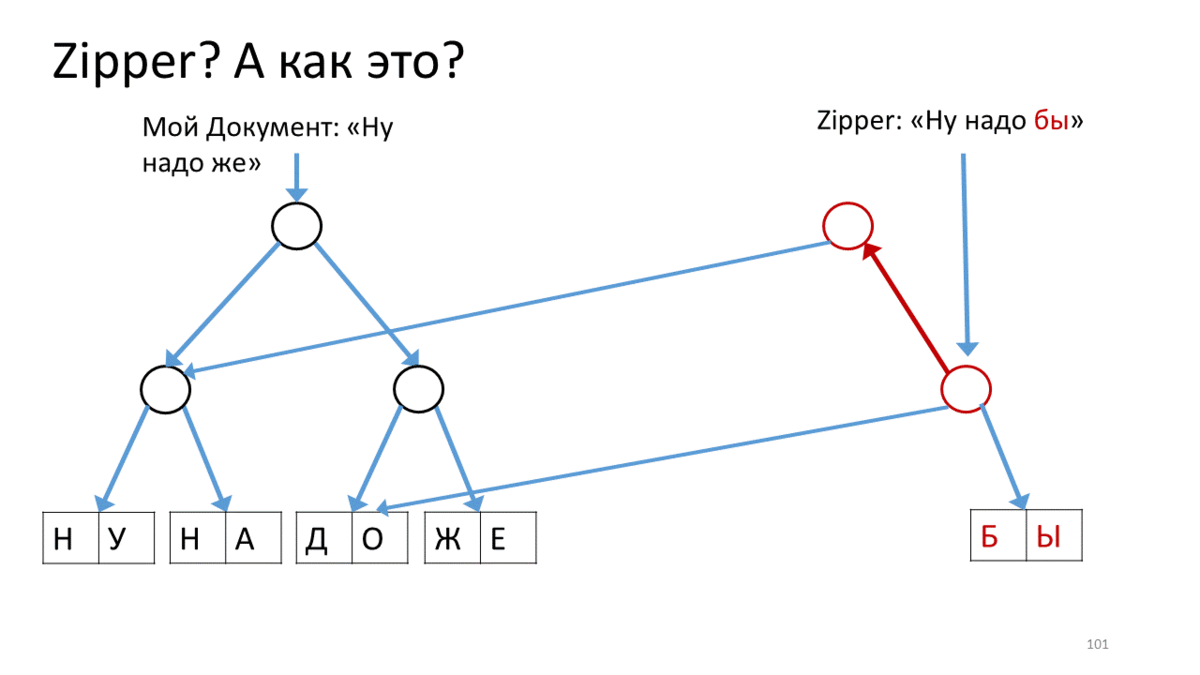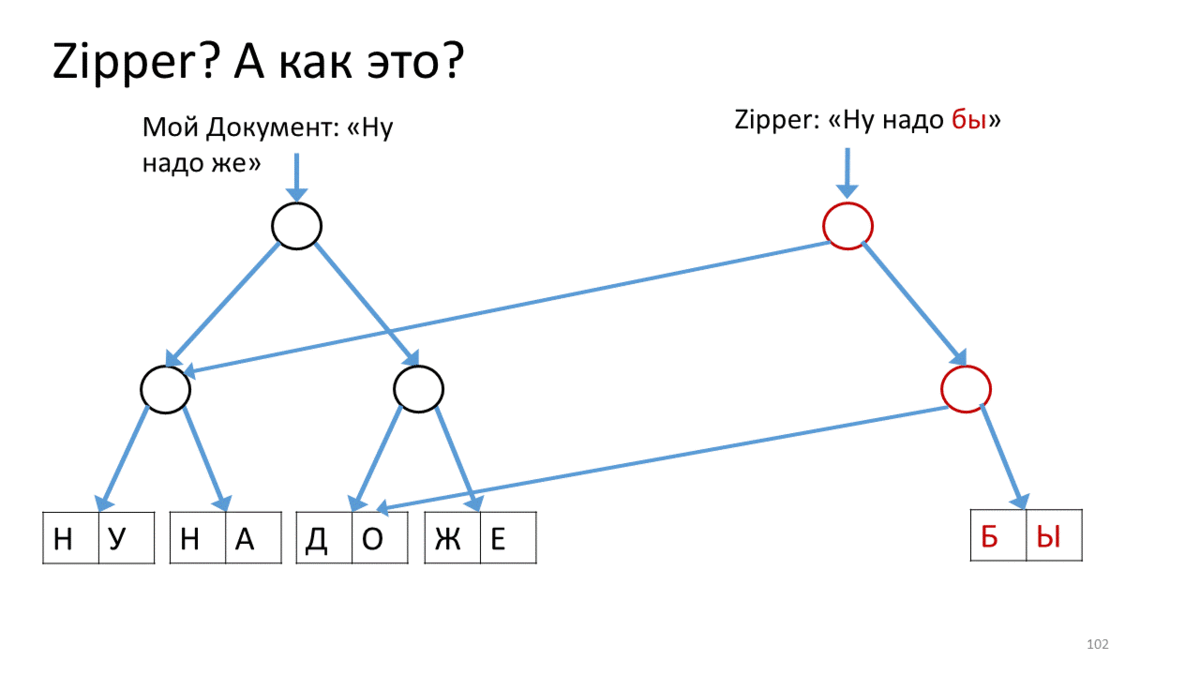
Zipper , (« »). Zipper' . — . (), , . , Zipper, - , . , , , ( ). , ( ). , . , .
, .
? -, , , , . , , . -, , . . .
→
→
Referências
Zipper data structureCRDT in Xi Editor,
Visual Studio Code editor Piece Table .
, -
.
Deseja relatórios ainda mais poderosos, incluindo o Java 11? Então, estamos esperando por você no Joker 2018 . Palestrantes deste ano: Josh Long, John McClean, Marcus Hirth, Robert Scholte e outros palestrantes igualmente legais. Faltam 17 dias para a conferência. Ingressos no site.