Em 22 de setembro, realizamos nossa primeira mitap não padronizada para desenvolvedores de sistemas altamente carregados. Foi muito legal, muito feedback positivo sobre os relatórios e, portanto, decidiu não apenas enviá-los, mas também descriptografar para Habr. Hoje publicamos um discurso de Ivan Bubnov, DevOps do BIT.GAMES. Ele falou sobre a implementação do serviço de descoberta da Consul em um projeto de alta carga já em funcionamento, para a possibilidade de dimensionamento e failover rápidos de serviços com estado. E também sobre a organização de um espaço de nome flexível para aplicativos de back-end e armadilhas. Agora uma palavra para Ivan.Administro a infraestrutura de produção no estúdio BIT.GAMES e conto a história da implementação do cônsul da Hashicorp em nosso projeto “Guild of Heroes” - RPG de fantasia com pvp assíncrono para dispositivos móveis. Disponível no Google Play, App Store, Samsung, Amazon. DAU cerca de 100.000, on-line de 10 a 13 mil. Como criamos o jogo no Unity, escrevemos o cliente em C # e usamos nossa própria linguagem de script BHL para a lógica do jogo. Nós escrevemos a parte do servidor em Golang (mudou para PHP). A seguir, a arquitetura esquemática do nosso projeto.
 De fato, existem muito mais serviços, existem apenas o básico da lógica do jogo.
De fato, existem muito mais serviços, existem apenas o básico da lógica do jogo.Então, o que temos. Dos serviços sem estado, estes são:
- nginx, que usamos como balanceadores de front-end e de carga e distribuímos clientes para nossos back-end por coeficientes de peso;
- back-end, aplicativos compilados do Go. Esse é o eixo central da nossa arquitetura, eles executam a maior parte do trabalho e se comunicam com todos os outros serviços de back-end.
Dos serviços com estado, os principais que temos são:
- Redis, que usamos para armazenar informações quentes (também usamos para organizar bate-papos no jogo e armazenar notificações para nossos jogadores);
- O Percona Server for Mysql é um repositório de informações persistentes (provavelmente o maior e o mais lento em qualquer arquitetura). Usamos o fork do MySQL e aqui falaremos mais detalhadamente hoje.
Durante o processo de design, nós (como todo mundo) esperávamos que o projeto fosse bem-sucedido e proporcionasse um mecanismo de fragmentação. Consiste em duas entidades do banco de dados MAINDB e nos próprios shards.

MAINDB é um tipo de índice - ele armazena informações sobre quais dados de fragmentos específicos sobre o progresso do player estão armazenados. Assim, a cadeia completa de recuperação de informações se parece com isso: o cliente acessa o front-end, que por sua vez o redistribui em peso a um dos back-end, o back-end vai para o MAINDB, localiza o shard do jogador e, em seguida, seleciona os dados diretamente do próprio shard.
Mas quando projetamos, não éramos um grande projeto, por isso decidimos fazer shards shards apenas nominalmente. Eles estavam todos localizados no mesmo servidor físico e provavelmente no particionamento de banco de dados no mesmo servidor.
Para backup, usamos a replicação principal de escravo mestre. Não era uma solução muito boa (vou dizer o porquê daqui a pouco), mas a principal desvantagem dessa arquitetura era que todos os nossos back-end conheciam outros serviços de back-end exclusivamente por endereços IP. E, no caso de outro acidente ridículo no datacenter do tipo "
desculpe, nosso engenheiro apertou o cabo do servidor enquanto fazia a manutenção de outro e demoramos muito tempo para descobrir por que o servidor não entra em contato " foram necessários movimentos consideráveis de nossa parte. Em primeiro lugar, trata-se da reconstrução e pré-instalação de back-end do servidor de backup IP para o local do que falhou. Em segundo lugar, após o incidente, é necessário restaurar nosso mestre do backup da reserva, porque ele estava em um estado inconsistente e trazê-lo para um estado coordenado usando a mesma replicação. Em seguida, remontamos os back-ends e recarregamos novamente. Tudo isso, é claro, causou tempo de inatividade.
Chegou um momento em que nosso diretor técnico (pelo qual agradeço muito a ele) disse: “Gente, parem de sofrer, precisamos mudar alguma coisa, vamos procurar maneiras de sair”. Antes de tudo, queríamos obter um processo simples, compreensível e mais importante - de gerenciamento fácil de dimensionamento e migração de um lugar para outro de nossos bancos de dados, se necessário. Além disso, queríamos obter alta disponibilidade automatizando o failover.
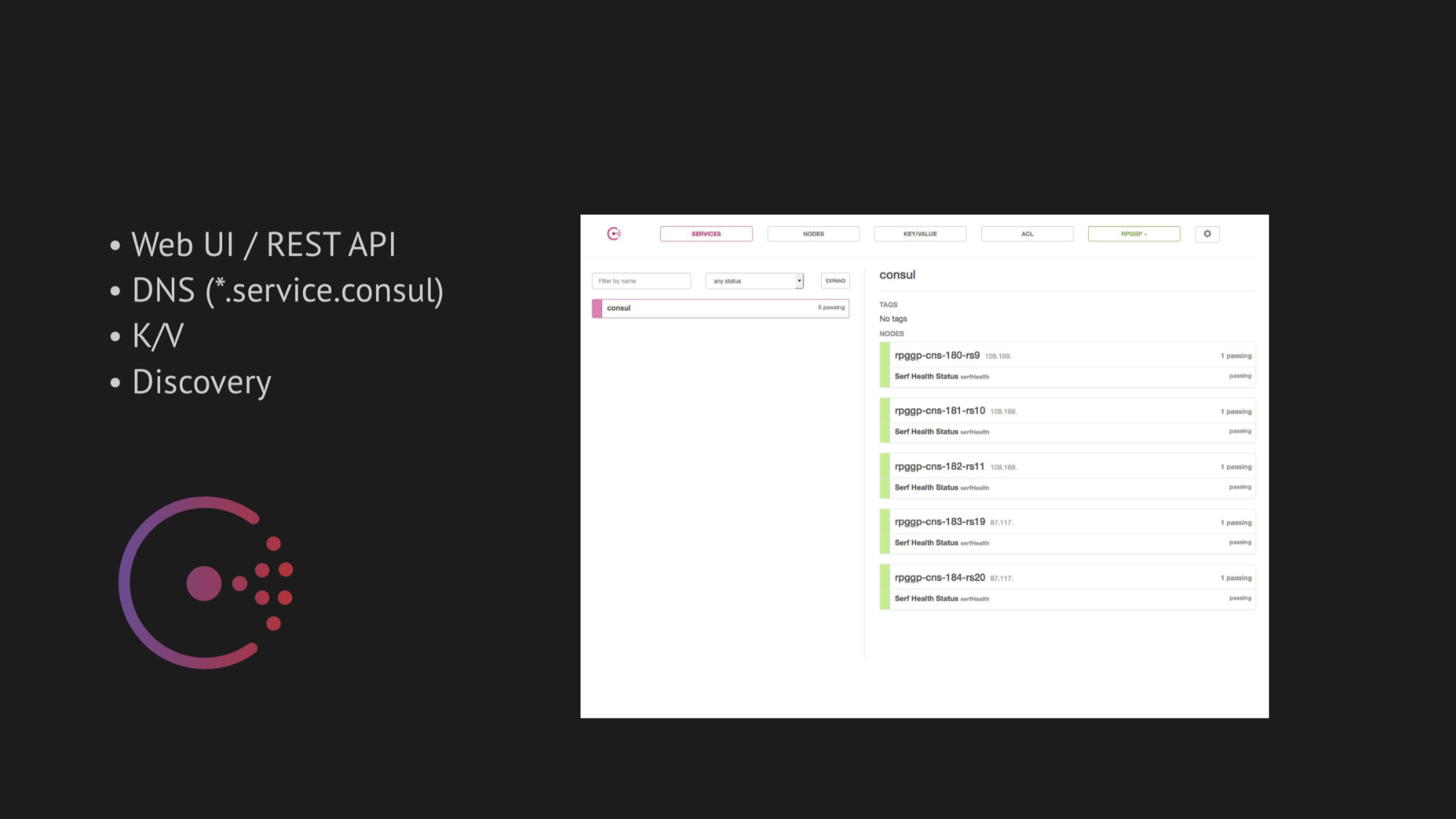
O eixo central de nossa pesquisa tornou-se o Consul da Hashicorp. Em primeiro lugar, fomos avisados e, em segundo lugar, ficamos muito atraídos por sua simplicidade, simpatia e excelente pilha de tecnologia em uma caixa: serviço de descoberta com verificação de saúde, armazenamento de valores-chave e a coisa mais importante que queríamos usar era DNS que resolve para nós endereços do domínio service.consul.
O Consul também fornece excelentes UIs da Web e APIs REST para gerenciar tudo isso.
Quanto à alta disponibilidade, escolhemos dois utilitários para failover automático:
- MHA para MySQL
- Redis-sentinela

No caso do MHA para MySQL, despejamos agentes em nós com bancos de dados e eles monitoravam seu estado. Houve um certo tempo limite com a falha do mestre, após o qual um escravo de parada foi feito para manter a consistência e nosso mestre de backup do mestre aparecido em um estado inconsistente não coletou os dados. E adicionamos um gancho da web a esses agentes, que registraram lá o novo IP do mestre de backup no próprio Consul, após o qual entrou na emissão do DNS.
Com o Redis-sentinel, tudo é ainda mais simples. Como ele próprio realiza a maior parte do trabalho, tudo o que nos resta a fazer é levar em consideração na verificação de saúde que o Redis-sentinela deve ocorrer exclusivamente no nó mestre.
No começo, tudo funcionou perfeitamente, como um relógio. Não tivemos problemas na bancada de testes. Mas valeu a pena mudar para o ambiente natural de transferência de dados de um data center carregado, pensando em algumas mortes por OOM (isso está sem memória, no qual o processo é morto pelo núcleo do sistema) e restaurando o serviço ou coisas mais sofisticadas que afetam a disponibilidade do serviço - como conseguimos imediatamente um sério risco de falsos positivos ou nenhuma resposta garantida (se você tentar fazer algumas tentativas para tentar escapar dos falsos positivos).

Antes de tudo, tudo depende da dificuldade de escrever a verificação de saúde correta. Parece que a tarefa é bastante trivial - verifique se o serviço está sendo executado no servidor e na porta pingani. Mas, como a prática subseqüente demonstrou, escrever uma verificação de saúde ao implementar o Consul é um processo extremamente complexo e demorado. Como muitos fatores que afetam a disponibilidade do seu serviço no datacenter não podem ser previstos - eles são detectados somente após um certo tempo.
Além disso, o datacenter não é uma estrutura estática com a qual você é inundado e funciona como planejado. Infelizmente, infelizmente (ou felizmente), descobrimos isso mais tarde, mas por enquanto estávamos inspirados e confiantes de que implementaríamos tudo na produção.

Quanto ao dimensionamento, direi brevemente: tentamos encontrar uma bicicleta pronta, mas todas elas foram projetadas para arquiteturas específicas. E, como no caso de Jetpants, não conseguimos atender às condições que ele impôs à arquitetura de um armazenamento persistente de informações.
Portanto, pensamos em nossa própria ligação de script e adiamos essa pergunta. Decidimos agir de forma consistente e começar com a implementação do Consul.

O Consul é um cluster distribuído e descentralizado que opera com base no protocolo de fofocas e no algoritmo de consenso Raft.
Temos um equorum independente de cinco servidores (cinco para evitar a situação do cérebro dividido). Para cada nó, aplicamos o agente Consul no modo de agente e aplicamos todas as verificações de saúde (ou seja, não foi possível enviar uma verificação de saúde para um servidor específico e outras para servidores específicos). A verificação de saúde foi escrita para que eles passem apenas onde houver um serviço.
Também usamos outro utilitário para que não precisássemos aprender nosso back-end para resolver endereços de um domínio específico em uma porta não padrão. Usamos o Dnsmasq - ele fornece a capacidade de resolver de forma totalmente transparente os endereços nos nós do cluster que precisamos (que, no mundo real, por assim dizer, não existem, mas existem exclusivamente dentro do cluster). Preparamos um script automático para preencher o Ansible, carregamos tudo para a produção, ajustamos o espaço para nome e garantimos que tudo estivesse completo. E, cruzando os dedos, recarregamos nossos back-end, que foram acessados não por endereços IP, mas por esses nomes no domínio server.consul.
Tudo começou da primeira vez, nossa alegria não tinha limites. Mas era muito cedo para se alegrar, porque em uma hora percebemos que em todos os nós em que nossos back-ends estão localizados, o indicador de carga média aumentou de 0,7 para 1,0, o que é um indicador bastante complexo.
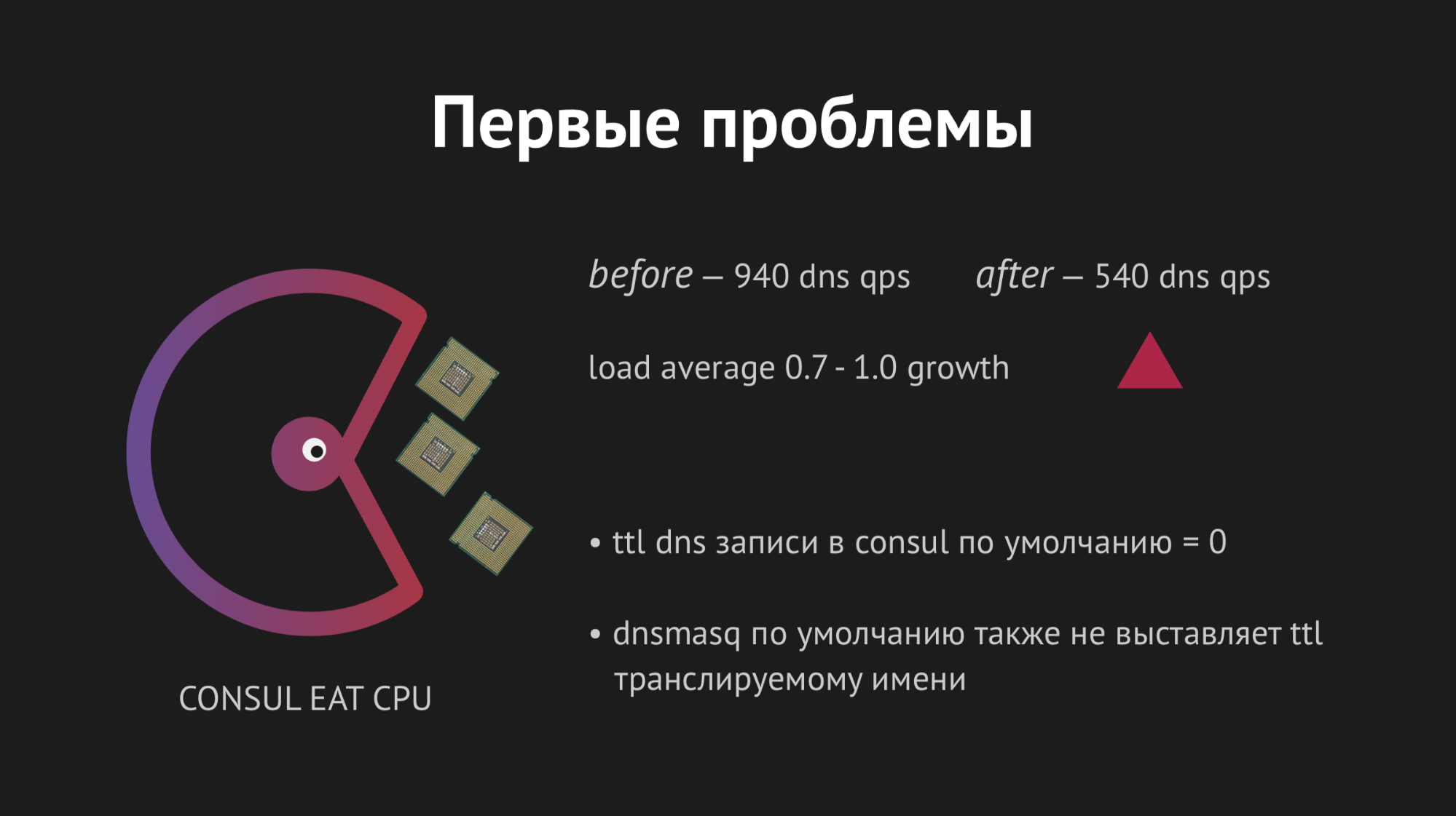
Entrei no servidor para ver o que estava acontecendo e ficou óbvio que a CPU estava comendo o Consul. Aqui começamos a descobrir, começamos a xamanizar com strace (um utilitário para sistemas unix que permite rastrear qual syscall o processo está executando), despejando as estatísticas do Dnsmasq para entender o que está acontecendo nesse nó, e percebemos que perdemos um ponto muito importante. Planejando a integração, perdemos o armazenamento em cache dos registros DNS e verificamos que nosso back-end extraía o Dnsmasq para cada um de seus movimentos e, por sua vez, recorreu ao Consul e tudo isso resultou em 940 consultas DNS doentias por segundo.
A saída parecia óbvia - basta girar ttl e tudo ficará melhor. Mas aqui era impossível ser fanático, porque queríamos implementar essa estrutura para obter um espaço para nome dinâmico, facilmente controlado e que mudasse rapidamente (portanto, não era possível definir, por exemplo, 20 minutos). Torcemos ttl para os valores ótimos máximos para nós, conseguimos reduzir a taxa de consultas por segundo para 540, mas isso não afetou o indicador de consumo da CPU.
Decidimos sair de uma maneira complicada, usando o arquivo hosts personalizado.
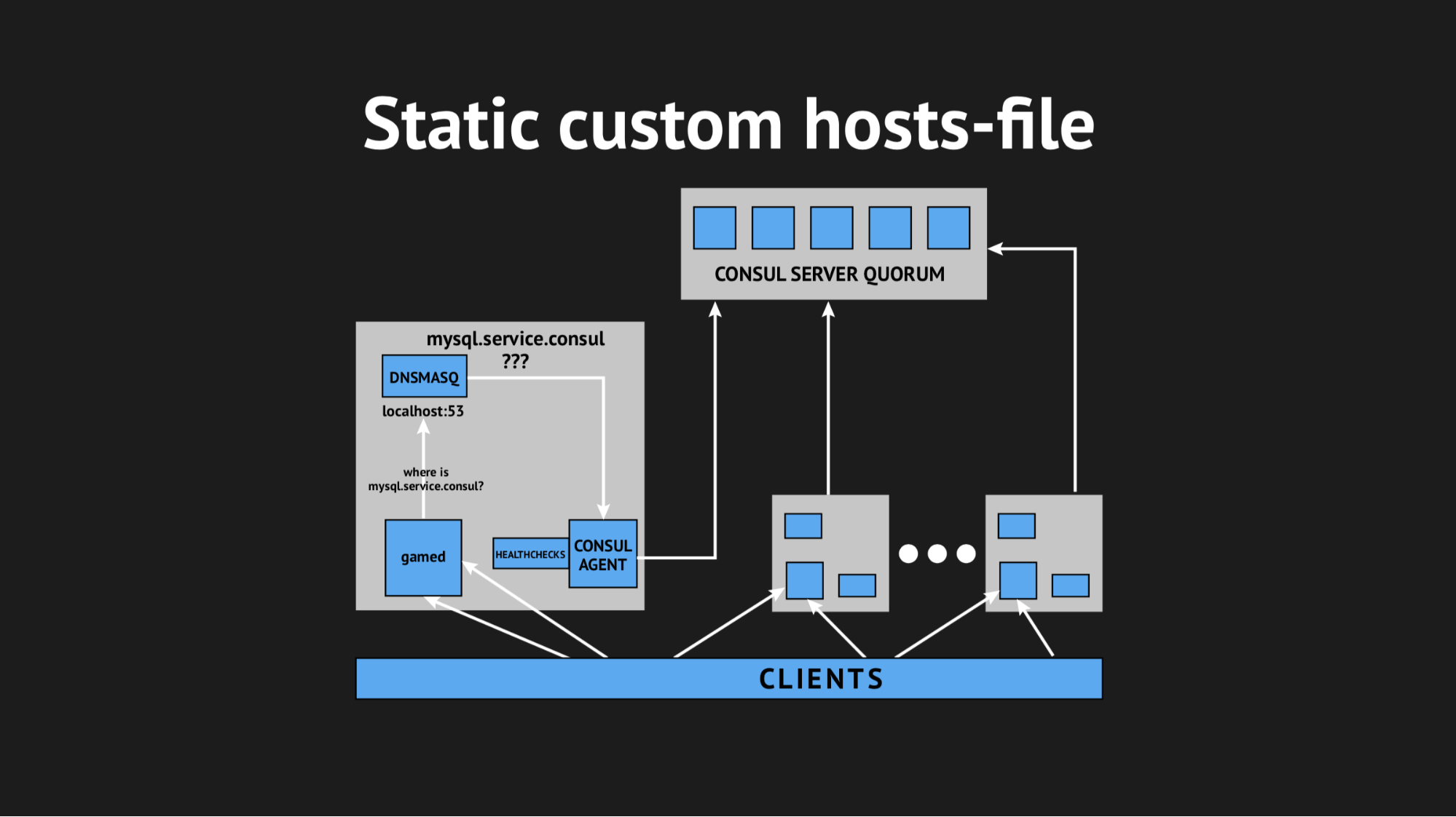
É bom termos tudo para isso: um excelente sistema de modelos da Consul, que, com base no estado do cluster e no script do modelo, gera um arquivo de qualquer tipo, qualquer configuração é tudo o que você deseja. Além disso, o Dnsmasq possui um parâmetro de configuração addn-hosts que permite usar um arquivo de hosts que não são do sistema como o mesmo arquivo de hosts adicionais.
O que fizemos, novamente preparamos o script em Ansible, o carregamos para produção e ele começou a ter algo parecido com isto:
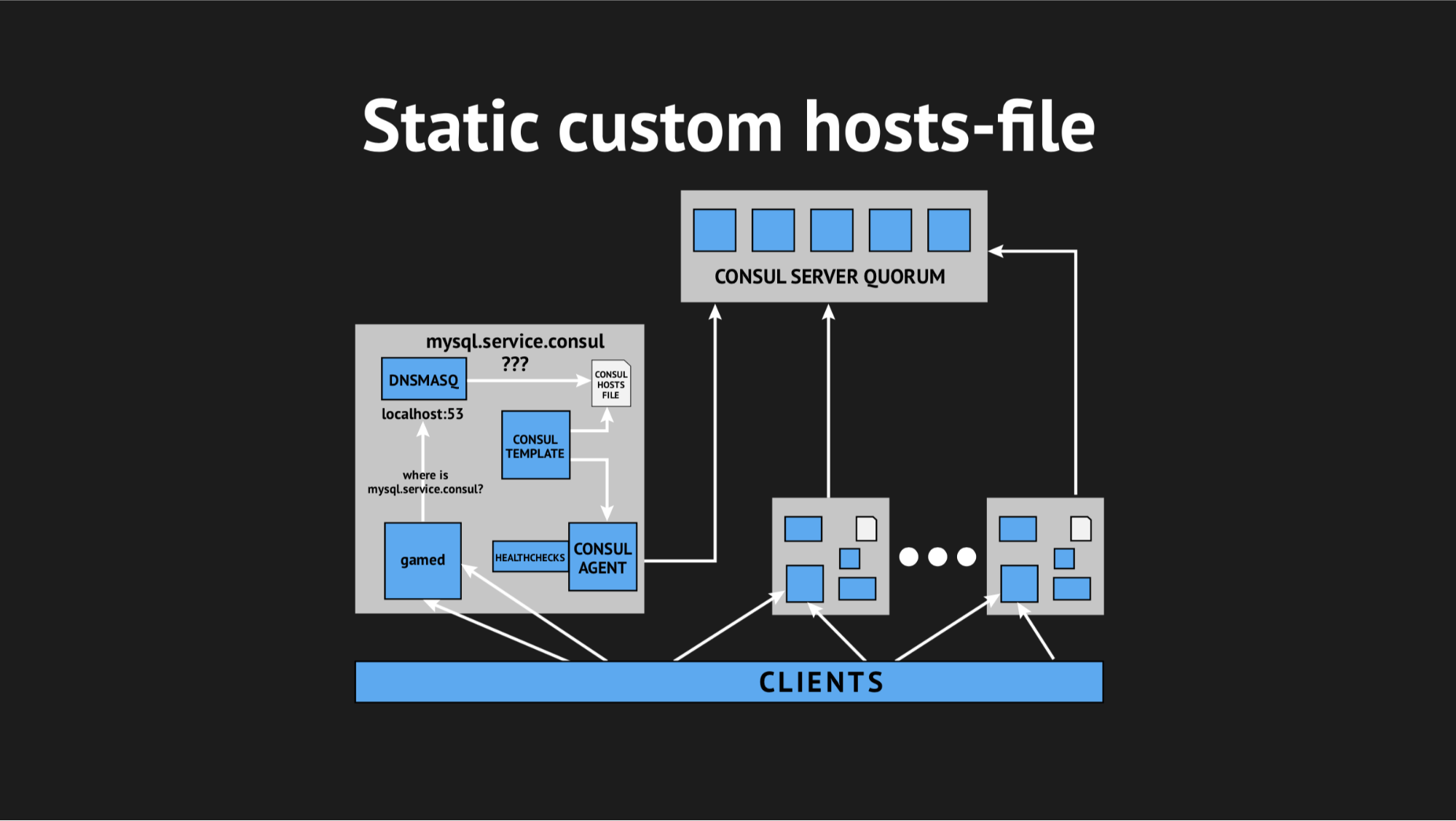
Havia um elemento adicional e um arquivo estático no disco, que é regenerado rapidamente. Agora a cadeia parecia bastante simples: o gamed virou-se para o Dnsmasq e, por sua vez (em vez de puxar o agente Consula, que perguntaria aos servidores onde tínhamos esse ou aquele nó) apenas olhava o arquivo. Isso resolveu o problema com o consumo de CPU pelo Consul.
Agora tudo começou a parecer como planejado - absolutamente transparente para a nossa produção, praticamente sem consumir recursos.
Ficamos bastante atormentados naquele dia e com grande apreensão fomos para casa. Eles não tiveram medo em vão, porque à noite um alerta de monitoramento me acordou e me informou que tínhamos uma explosão de erros em larga escala (embora a curto prazo).
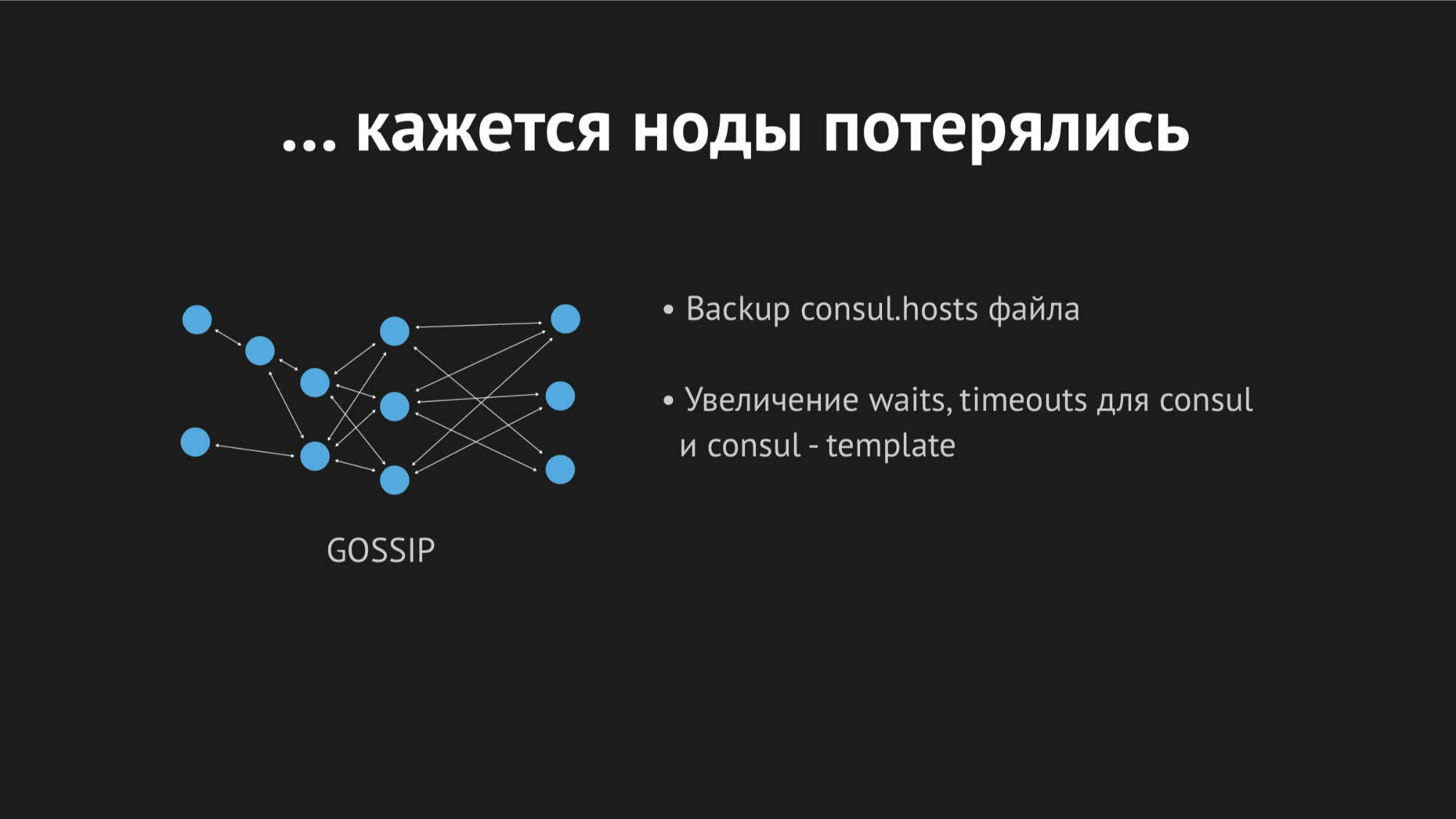
Lidando com os logs pela manhã, vi que todos os erros eram do mesmo tipo de host desconhecido. Não ficou claro por que o Dnsmasq não pôde usar um ou outro serviço de um arquivo - parecia que não existia. Para tentar entender o que estava acontecendo, adicionei uma métrica personalizada para gerar novamente o arquivo - agora eu sabia exatamente o momento em que ele seria regenerado. Além disso, o próprio modelo do Consul tem uma excelente opção de backup, ou seja, Você pode ver o estado anterior do arquivo regenerado.
Durante o dia, o incidente se repetiu várias vezes e ficou claro que em algum momento (embora fosse esporádico, de natureza assistemática), o arquivo de hosts sem serviços específicos seria renderizado novamente. Descobriu-se que em um data center específico (não farei anti-publicidade), existem redes bastante instáveis - devido às redes fracassadas, absolutamente imprevisivelmente paramos de passar por verificações de saúde ou mesmo os nós caíram do cluster. Parecia algo assim:
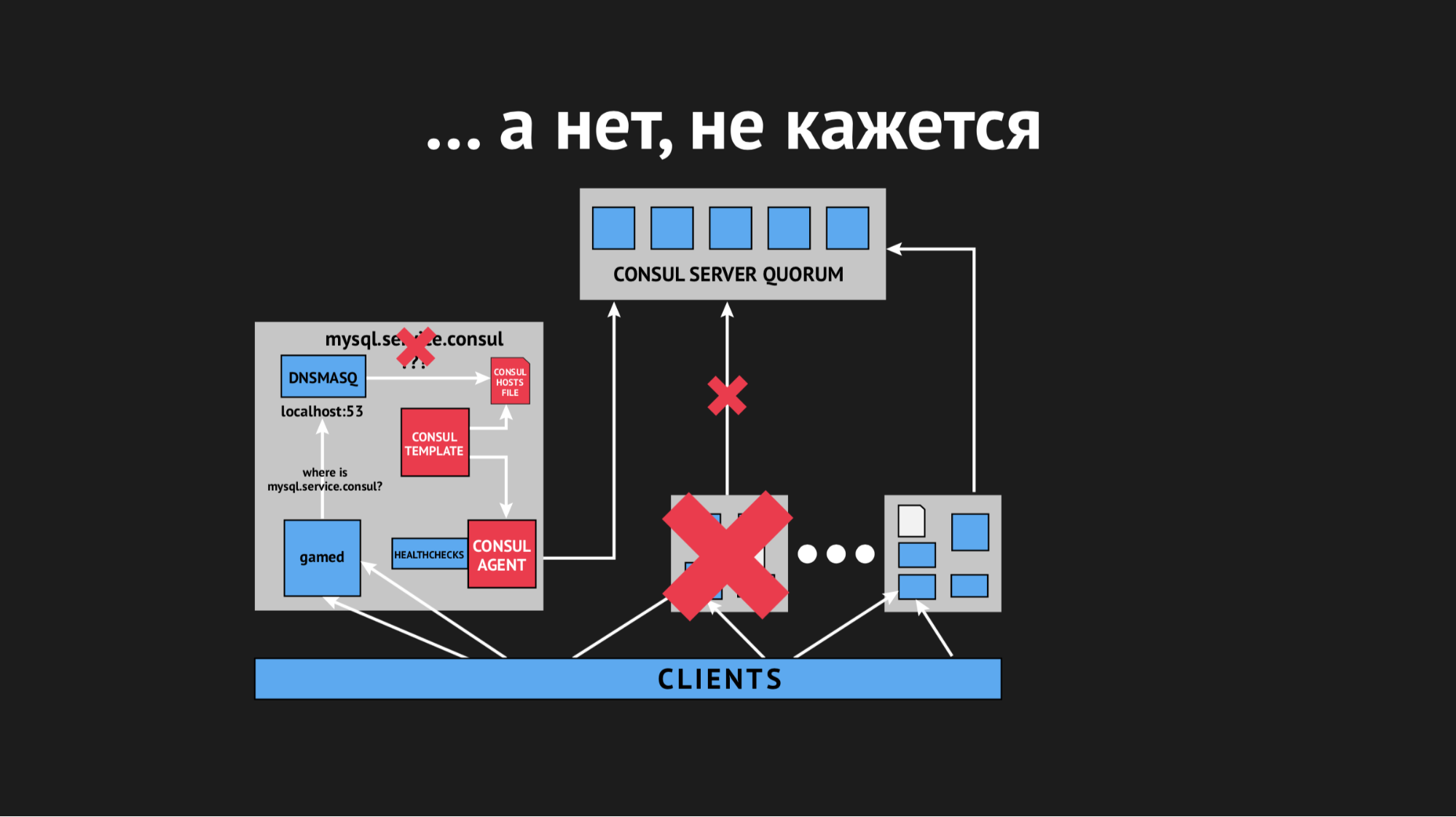
O nó caiu do cluster, o agente do Consul foi imediatamente notificado sobre isso e o modelo do Consul regenerou imediatamente o arquivo de hosts sem o serviço necessário. Isso geralmente era inaceitável, porque o problema é ridículo: se o serviço não estiver disponível por alguns segundos, configure tempos limite e repetições (eles não se conectaram uma vez, mas na segunda vez). Mas provocamos uma nova estrutura no vendedor quando o serviço simplesmente desaparece da vista e não havia como se conectar a ele.
Começamos a pensar no que fazer e torcer o parâmetro timeout no Consul, após o qual é identificado após o quanto o nó cai. Conseguimos resolver esse problema com um indicador bastante pequeno, os nós pararam de cair, mas isso não ajudou na verificação de saúde.
Começamos a pensar em escolher parâmetros diferentes para a verificação de saúde, tentando entender de alguma forma quando e como isso acontece. Mas, devido ao fato de que tudo aconteceu esporadicamente e imprevisivelmente, não fomos capazes de fazê-lo.
Em seguida, fomos ao modelo do Consul e decidimos fazer um tempo limite para ele, após o qual ele reage a uma alteração no estado do cluster. Novamente, era impossível ser fanático, porque poderíamos chegar a uma situação em que o resultado não seria melhor que o DNS clássico, quando buscávamos um completamente diferente.
E mais uma vez nosso diretor técnico veio em socorro e disse: “Gente, vamos tentar desistir de toda essa interatividade, estamos todos em produção e não há tempo para pesquisas, precisamos resolver esse problema. Vamos tirar proveito de coisas simples e compreensíveis. ” Então, chegamos ao conceito de usar o armazenamento de valores-chave como fonte para gerar um arquivo de hosts.
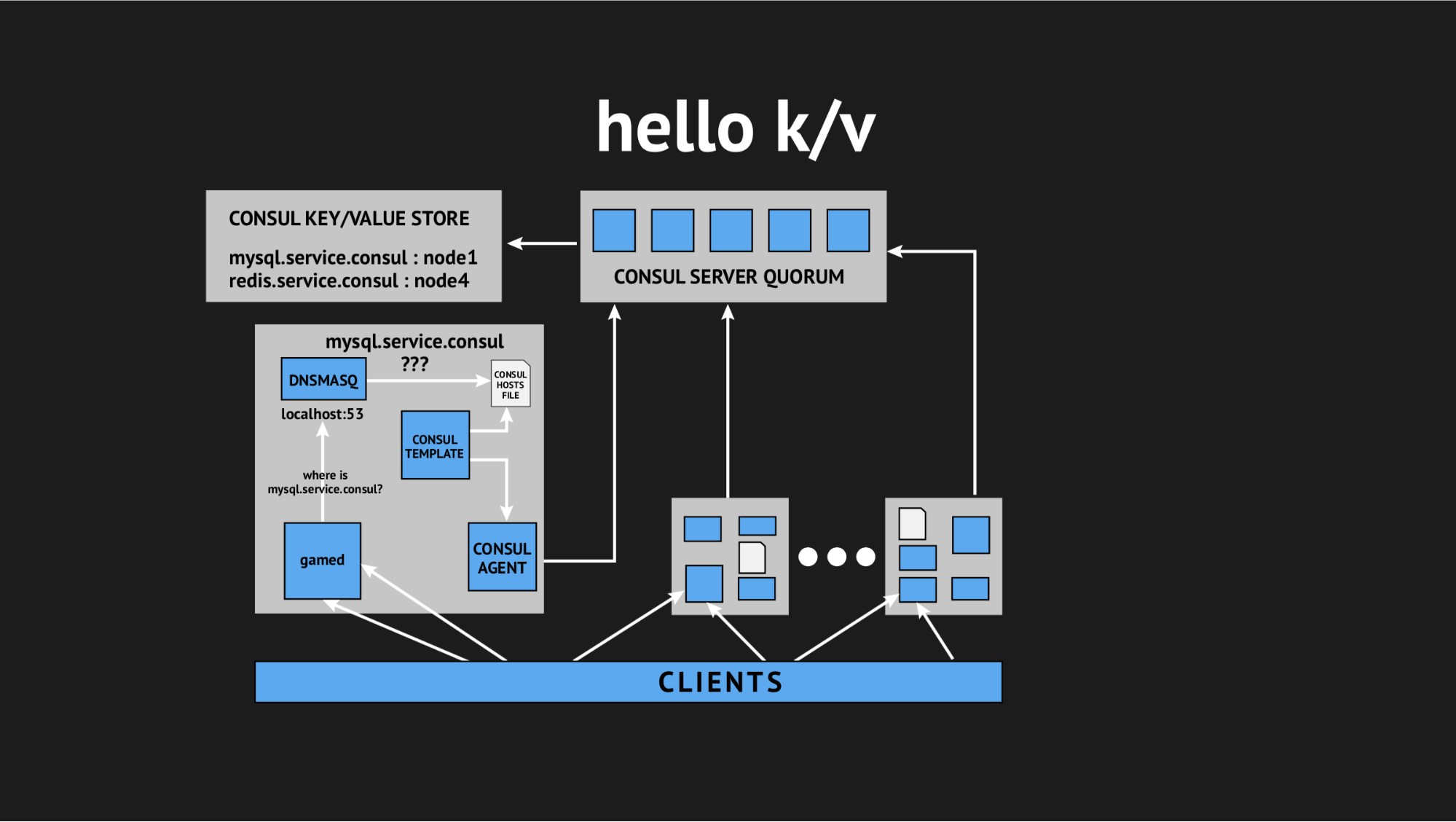
Como parece: recusamos todas as verificações de integridade dinâmicas, reescrevemos nosso script de modelo para gerar um arquivo com base nos dados registrados no armazenamento de valores-chave. No armazenamento de valores-chave, descrevemos toda a nossa infraestrutura na forma do nome da chave (este é o nome do serviço que precisamos) e o valor da chave (este é o nome do nó no cluster). I.e. se o nó estiver presente no cluster, obteremos seu endereço IP com muita facilidade e gravamos no arquivo hosts.
Testamos tudo, enchemos a produção e ela se tornou uma bala de prata em uma situação específica. Novamente, nós praticamente nos atormentamos o dia inteiro e voltamos para casa, mas voltamos descansados, entusiasmados, porque esses problemas não voltaram a ocorrer e não foram repetidos na submissão por um ano. Pelo qual concluo pessoalmente que essa foi a decisão certa (especificamente para nós).
Então Finalmente conseguimos o que queríamos e organizamos um espaço para nome dinâmico para nossos back-ends. Além disso, fomos no sentido de garantir alta disponibilidade.

Mas o fato é que, com muito medo da integração do Consul, e por causa dos problemas que encontramos, pensamos e decidimos que a introdução do failover automático não é uma solução tão boa, porque novamente corremos o risco de falsos positivos ou falhas. Este processo é opaco e incontrolável.
Portanto, seguimos um caminho mais simples (ou complexo): decidimos deixar o failover na consciência do administrador de plantão, mas fornecemos a ele outra ferramenta adicional. Substituímos a replicação principal do escravo pela replicação principal do mestre no modo Somente leitura. Isso remove uma enorme quantidade de dor de cabeça no processo de failover'ov - quando você obtém um assistente, tudo o que você precisa fazer é alterar o valor no armazenamento k / v usando a interface da Web da Web ou um comando na API e, antes disso, modo somente leitura mestre de backup.
Após o término do incidente, o mestre entra em contato e automaticamente entra em um estado coordenado sem nenhuma ação desnecessária. Paramos nessa opção e a usamos como antes - para nós, é o mais conveniente possível e, o mais importante, o mais simples, claro e controlado possível.
 Consul Web Interface
Consul Web InterfaceÀ direita está o armazenamento k / v e nossos serviços são visíveis, que usamos em jogos; value é o nome do nó.
Quanto ao dimensionamento - começamos a implementá-lo quando os shards já estavam lotados em um servidor, as bases cresceram, ficaram lentas, o número de jogadores aumentou, trocamos e tivemos a tarefa de distribuir todos os shards para nossos diferentes servidores separados.

Como ficou: usando o utilitário XtraBackup, restauramos nosso backup em um novo par de servidores, após o qual o novo mestre foi pendurado com um escravo no antigo. Chegou a um estado consistente, alteramos o valor da chave no armazenamento k / v do nome do nó do antigo mestre para o nome do nó do novo mestre. Então (quando acreditamos que tudo correu corretamente e todas as suas seleções, atualizações e inserções foram para o novo mestre), tivemos que matar a replicação e criar o cobiçado banco de dados de gota na produção, como todos gostamos de fazer com bancos de dados desnecessários.

Então nós quebramos os estilhaços. Todo o processo de mudança durou de 40 minutos a uma hora e não causou tempo de inatividade, era completamente transparente para os nossos back-ends e, por si só, foi completamente transparente para os jogadores (exceto que, assim que eles se mudaram, ficou mais fácil e agradável para eles jogarem).

Quanto aos processos de failover, aqui o tempo de comutação é de 20 a 40 segundos, mais o tempo de reação do administrador do sistema em serviço. É assim que tudo parece conosco agora.
O que eu gostaria de dizer em conclusão - infelizmente, nossas esperanças de uma automação abrangente e absoluta colidiram com a dura realidade do meio de transmissão de dados em um data center carregado e fatores aleatórios que não poderíamos prever.
Em segundo lugar, ele nos ensinou mais uma vez que um teta simples e comprovado nas mãos do administrador do sistema é melhor do que um guindaste auto-reagente e auto-dimensionado, em um lugar além das nuvens, que você nem entende se está desmoronando ou realmente começou a escalar.
A introdução de qualquer infraestrutura e automação em sua produção não deve causar dor de cabeça desnecessária para a equipe que a atende; não deve aumentar significativamente o custo de manutenção da produção de infraestrutura - a solução deve ser simples, clara, transparente para seus clientes, conveniente e controlada.
Perguntas da platéia
Como você escreve k / v com servidores - um script ou apenas o corrige?K/v- Consul- - , http- RESTful API Web UI.
, - , , .
, Redis?, - .
-, backend. -, backend', — . I.e. , MAINDB , . . - , .
- , inmemory key-value -.
?MySQL — Percona server.
? Maria, MHA for MySQL, Galera.Galera. - « » Galera , . , .
, — , , - , , , .
Pixonic DevGAMM Talks