Olá, Habr, neste artigo, falarei sobre a biblioteca de ignição , com a qual você pode treinar e testar facilmente redes neurais usando a estrutura PyTorch.
Com o ignite, você pode escrever ciclos para treinar a rede em apenas algumas linhas, adicionar cálculos de métricas padrão da caixa, salvar o modelo etc. Bem, para aqueles que mudaram do TF para o PyTorch, podemos dizer que a biblioteca de ignição é o Keras for PyTorch.
O artigo examinará em detalhes um exemplo de treinamento de uma rede neural para uma tarefa de classificação usando ignição.

Adicione mais fogo ao PyTorch
Não vou perder tempo falando sobre o quão legal é a estrutura do PyTorch. Qualquer um que já o tenha usado entende o que estou escrevendo. Mas, com todas as suas vantagens, ainda é de baixo nível em termos de ciclos de escrita para treinamento, teste e teste de redes neurais.
Se olharmos para exemplos oficiais de uso da estrutura PyTorch, veremos pelo menos dois ciclos de iterações por época e por lotes do treinamento definido no código de treinamento da grade:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
A idéia principal da biblioteca ignite é fatorar esses loops em uma única classe, enquanto permite ao usuário interagir com esses loops usando manipuladores de eventos.
Como resultado, no caso de tarefas padrão de aprendizado profundo, podemos economizar muito no número de linhas de código. Menos linhas - menos erros!
Por exemplo, para comparação, à esquerda está o código para treinamento e validação de modelo usando ignite , e à direita está o PyTorch puro:
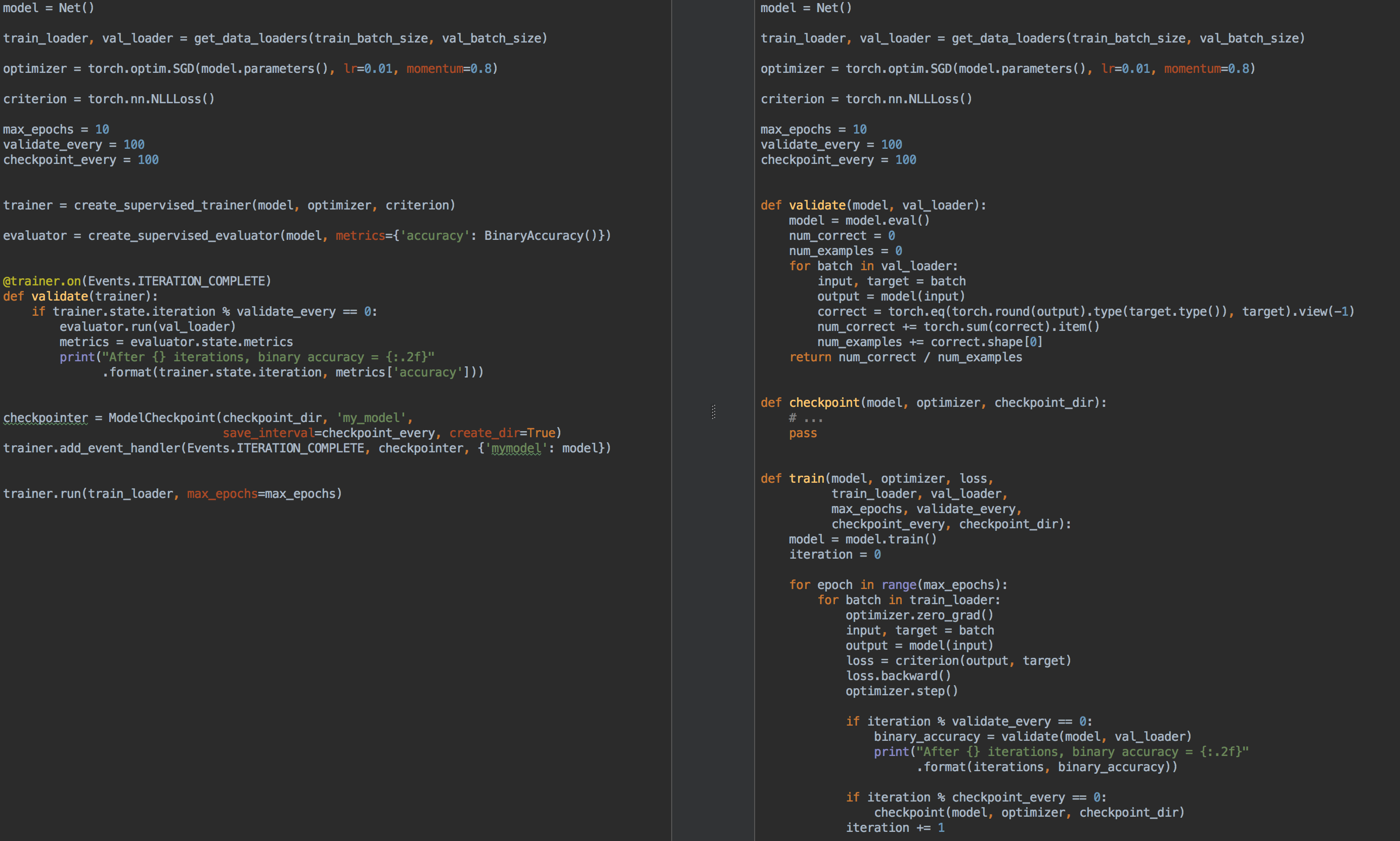
Então, novamente, para que serve a ignição ?
- não é mais necessário gravar em cada loop de tarefa
for epoch in range(n_epochs) e o for batch in data_loader . - permite que você fatore melhor o código
- permite calcular métricas básicas prontas para uso
- fornece "pãezinhos" do tipo
- salvar os melhores e mais recentes modelos (também otimizador e programador de taxas de aprendizado) durante o treinamento,
- parar de aprender cedo
- etc.
- integra-se facilmente às ferramentas de visualização: tensorboardX, visdom, ...
De certa forma, como já mencionado, a biblioteca de ignição pode ser comparada com todas as famosas Keras e sua API para treinamento e teste de redes. Além disso, à primeira vista, a biblioteca ignite é muito semelhante à biblioteca tnt , pois inicialmente as duas bibliotecas tinham objetivos comuns e idéias semelhantes para sua implementação.
Então, acenda:
pip install pytorch-ignite
ou
conda install ignite -c pytorch
A seguir, com um exemplo concreto, vamos nos familiarizar com a API da biblioteca de ignição .
Tarefa de classificação com ignição
Nesta parte do artigo, consideraremos um exemplo escolar de treinamento de uma rede neural para o problema de classificação usando a biblioteca de ignição .
Então, vamos tirar um conjunto de dados simples com fotos de frutas com kaggle . A tarefa é associar uma classe correspondente a cada figura de fruta.
Antes de usar o ignite , vamos definir os principais componentes:
Fluxo de dados
- carregador de amostras de treinamento,
train_loader val_loader lote de checkout, val_loader
Modelo:
- pegue a pequena grade
torchvision da torchvision da torchvision
Algoritmo de otimização:
Função de perda:
Código from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
Então agora é hora de executar ignição :
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
Vamos ver o que esse código significa.
Motor Engine
A classe ignite.engine.Engine é a estrutura da biblioteca e o objeto dessa classe é o trainer :
trainer = Engine(process_function)
É definido com a função de entrada process_function para processar um lote e serve para implementar passes para a amostra de treinamento. Dentro da classe ignite.engine.Engine , acontece o seguinte:
while epoch < max_epochs:
De volta à função process_function :
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
Vemos que, dentro da função, como de costume no caso do treinamento em modelo, calculamos as previsões y_pred , calculamos a função de loss , loss e gradientes. Este último permite atualizar o peso do modelo: optimizer.step() .
Em geral, não há restrições no código da função process_function . Observamos apenas que são necessários dois argumentos como entrada: o objeto Engine (no nosso caso, trainer ) e o lote do carregador de dados. Portanto, por exemplo, para testar uma rede neural, podemos definir outro objeto da classe ignite.engine.Engine , na qual a função de entrada simplesmente calcula as previsões e implementa uma passagem na amostra de teste uma vez. Leia mais tarde.
Portanto, o código acima define apenas os objetos necessários sem iniciar o treinamento. Basicamente, em um exemplo mínimo, você pode chamar o método:
trainer.run(train_loader, max_epochs=10)
e esse código é suficiente para "silenciosamente" (sem nenhuma derivação de resultados intermediários) treinar o modelo.
Uma notaObserve também que, para tarefas desse tipo, a biblioteca possui um método conveniente para criar o objeto de trainer :
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
Obviamente, na prática, o exemplo acima é de pouco interesse, então vamos adicionar as seguintes opções para o "coach":
- exibição do valor da função de perda a cada 50 iterações
- início do cálculo das métricas no conjunto de treinamento com um modelo fixo
- início do cálculo das métricas na amostra de teste após cada época
- salvando os parâmetros do modelo após cada época
- preservação dos três melhores modelos
- mudança na velocidade de aprendizado, dependendo da época (programação da taxa de aprendizado)
- treinamento de parada precoce (parada precoce)
Eventos e manipuladores de eventos
Para adicionar as opções acima para o "treinador", a biblioteca de ignição fornece um sistema de eventos e o lançamento de manipuladores de eventos personalizados. Assim, o usuário pode controlar um objeto da classe Engine em cada estágio:
- motor iniciado / lançamento concluído
- era começou / terminou
- a iteração em lote iniciada / finalizada
e execute seu código em todos os eventos.
Exibe valores da função de perda
Para fazer isso, basta determinar a função na qual a saída será exibida na tela e adicioná-la ao "treinador":
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
Na verdade, existem duas maneiras de adicionar um manipulador de eventos: através de add_event_handler ou através do decorador on . O mesmo que acima pode ser feito assim:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
Observe que qualquer argumento pode ser passado para a função de manipulação de eventos. Em geral, essa função terá a seguinte aparência:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
Então, vamos começar o treinamento em uma época e ver o que acontece:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
Nada mal! Vamos mais longe.
Iniciando o cálculo de métricas em amostras de treinamento e teste
Vamos calcular as seguintes métricas: precisão média, completude média após cada época da parte do treinamento e de toda a amostra de teste. Observe que calcularemos as métricas da parte da amostra de treinamento após cada era do treinamento, e não durante o treinamento. Assim, a medição da eficiência será mais precisa, pois o modelo não muda durante o cálculo.
Então, definimos as métricas:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
Em seguida, criaremos dois mecanismos para avaliar o modelo usando ignite.engine.create_supervised_evaluator :
from ignite.engine import create_supervised_evaluator
Criamos dois mecanismos para anexar ainda mais manipuladores de eventos adicionais a um deles ( val_evaluator ) para salvar o modelo e parar de aprender mais cedo (sobre tudo isso abaixo).
Vamos também dar uma olhada em como o mecanismo para avaliar o modelo é definido, como a função de entrada process_function definida para processar um lote:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
Continuamos mais. Vamos selecionar aleatoriamente a parte da amostra de treinamento na qual calcularemos as métricas:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
Em seguida, vamos determinar em que momento do treinamento iniciaremos o cálculo das métricas e produziremos na tela:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
Você pode correr!
output = trainer.run(train_loader, max_epochs=1)
Chegamos na tela
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
Já está melhor!
Alguns detalhes
Vejamos um pouco o código anterior. O leitor pode ter notado a seguinte linha de código:
metrics = train_evaluator.run(train_eval_loader).metrics
e provavelmente houve uma pergunta sobre o tipo de objeto obtido de train_evaluator.run(train_eval_loader) , que possui o atributo de metrics .
De fato, a classe Engine contém uma estrutura chamada state (type State ) para poder transferir dados entre manipuladores de eventos. Este atributo state contém informações básicas sobre a era atual, iteração, número de eras etc. Também pode ser usado para transferir quaisquer dados do usuário, incluindo os resultados do cálculo das métricas.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
Cálculo de métricas durante o treinamento
Se a tarefa tiver um grande conjunto de treinamentos e calcular métricas após cada época de treinamento, será caro, mas ainda RunningAverage algumas métricas sejam alteradas durante o treinamento, você poderá usar o seguinte manipulador de eventos RunningAverage na caixa. Por exemplo, queremos calcular e exibir a precisão do classificador:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
Para usar a funcionalidade RunningAverage , é necessário instalar o ignite a partir das fontes:
pip install git+https:
Programação da taxa de aprendizado
Existem várias maneiras de alterar a velocidade de aprendizado usando ignição . Em seguida, considere o método mais simples chamando a função lr_scheduler.step() no início de cada era.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
Salvando os melhores modelos e outros parâmetros durante o treinamento
Durante o treinamento, seria ótimo gravar os pesos do melhor modelo no disco, além de salvar periodicamente os pesos do modelo, os parâmetros do otimizador e os parâmetros para alterar a velocidade de aprendizado. O último pode ser útil para retomar a aprendizagem do último estado salvo.
O Ignite possui uma classe ModelCheckpoint especial para isso. Portanto, vamos criar um ModelCheckpoint eventos ModelCheckpoint e salvar o melhor modelo em termos de precisão no conjunto de testes. Nesse caso, definimos uma função score_function que fornece o valor de precisão ao manipulador de eventos e decide se o modelo deve ser salvo ou não:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
Agora crie outro ModelCheckpoint eventos ModelCheckpoint para manter o estado de aprendizado a cada 1000 iterações:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
Então, quase tudo está pronto, adicione o último elemento:
Treinamento de parada precoce (parada antecipada)
Vamos adicionar outro manipulador de eventos que interromperá o aprendizado se não houver melhoria na qualidade do modelo em mais de 10 épocas. Vamos avaliar a qualidade do modelo novamente usando a score_function score_function.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
Iniciar treinamento
Para iniciar o treinamento, basta chamar o método run() . Treinaremos o modelo por 10 épocas:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
Saída de tela Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
Agora verifique os modelos e parâmetros salvos no disco:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
e
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
Previsões de um modelo treinado
Primeiro, crie um carregador de dados de teste (por exemplo, tire uma amostra de validação) para que o lote de dados consista em imagens e seus índices:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
Usando ignite, criaremos um novo mecanismo de previsão para dados de teste. Para isso, definimos a função inference_update , que retorna o resultado da previsão e o índice da imagem. Para aumentar a precisão, também usaremos o truque conhecido "aumento do tempo de teste" (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
Em seguida, crie manipuladores de eventos que notificarão sobre o estágio das previsões e salvem as previsões em uma matriz dedicada:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
Antes de iniciar o processo, vamos baixar o melhor modelo:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
Lançamos:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
Em seguida, de maneira padrão, tomamos a média das previsões de TTA e calculamos o índice de classe com a maior probabilidade:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
E agora podemos mais uma vez calcular a precisão do modelo de acordo com as previsões:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
Conclusão
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
Obrigado pela atenção!