A Enron Corporation é uma das figuras mais famosas dos negócios americanos nos anos 2000. Isso foi facilitado não por sua esfera de atividade (eletricidade e contratos para o seu fornecimento), mas pela ressonância devido a fraudes nela. Por 15 anos, a renda corporativa cresceu rapidamente e o trabalho prometia um bom salário. Mas tudo terminou de maneira igualmente fugaz: no período 2000-2001. o preço das ações caiu de US $ 90 / unidade para quase zero devido à fraude revelada com renda declarada. Desde então, a palavra "Enron" tornou-se uma palavra familiar e atua como um rótulo para empresas que operam em um padrão semelhante.
Durante o julgamento, 18 pessoas (incluindo os maiores réus neste caso: Andrew Fastov, Jeff Skilling e Kenneth Lay) foram condenadas.
![image! [image] (http: // https: //habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
Ao mesmo tempo, foram publicados um arquivo de correspondência eletrônica entre funcionários da empresa, mais conhecido como Enron Email Dataset, e informações privilegiadas sobre a renda dos funcionários dessa empresa.
O artigo examinará as fontes desses dados e criará um modelo baseado para determinar se uma pessoa é suspeita de fraude. Parece interessante? Bem-vindo ao habrakat.
Descrição do conjunto de dados
O conjunto de dados da Enron (conjunto de dados) é um conjunto composto de dados abertos que contém registros de pessoas que trabalham em uma empresa memorável com o nome correspondente.
Pode distinguir 3 partes:
- payment_features - um grupo que caracteriza movimentos financeiros;
- stock_features - um grupo que reflete sinais associados a ações;
- email_features - um grupo que reflete informações sobre os emails de uma determinada pessoa em um formulário agregado.
Obviamente, há também uma variável de destino que indica se a pessoa é suspeita de fraude (o sinal de 'poi' ).
Baixe nossos dados e comece a trabalhar com eles:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
Depois disso, transformamos o conjunto data_dict em um quadro de dados do Pandas para um trabalho mais conveniente com os dados:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
Agrupamos os sinais de acordo com os tipos indicados anteriormente. Isso deve facilitar o trabalho com os dados posteriormente:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
Dados financeiros
Nesse conjunto de dados, existe um NaN conhecido por muitos e expressa a lacuna usual nos dados. Em outras palavras, o autor do conjunto de dados não pôde encontrar nenhuma informação sobre um atributo específico associado a uma linha específica no quadro de dados. Como resultado, podemos assumir que NaN é 0, pois não há informações sobre uma característica específica.
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
Verificação de dados
Ao comparar com o PDF original subjacente ao conjunto de dados, verificou-se que os dados estão ligeiramente distorcidos, porque nem todas as linhas no quadro de dados de pagamentos , o campo total_payments é a soma de todas as transações financeiras de uma determinada pessoa. Você pode verificar isso da seguinte maneira:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

Vemos que BELFER ROBERT e BHATNAGAR SANJAY têm valores de pagamento incorretos.
Você pode corrigir esse erro movendo os dados nas linhas de erro para a esquerda ou direita e contando a soma de todos os pagamentos novamente:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
Dados de estoque
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
Execute uma verificação de validação também neste caso:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

Da mesma forma, corrigiremos o erro nos estoques:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
Correspondência por e-mail
Se para essas finanças ou ações o NaN for equivalente a 0, e isso se encaixar no resultado final de cada um desses grupos, no caso do email NaN, é mais razoável substituir por algum valor padrão. Para fazer isso, você pode usar o Imputer:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
Ao mesmo tempo, consideraremos o valor padrão de cada categoria (independentemente de suspeitarmos de uma pessoa de fraude) separadamente:
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
Conjunto de dados final após correção:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
Emissões
Na etapa final desta etapa, removeremos todos os valores discrepantes, o que pode distorcer o treinamento. Ao mesmo tempo, sempre surge a pergunta: quantos dados podemos remover da amostra e ainda não perder como modelo treinado? Eu segui o conselho de um dos palestrantes do curso de ML (Machine Learning) sobre Udacity - "Remova 10 e verifique as emissões novamente".
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
Ao mesmo tempo, não excluiremos registros discrepantes e suspeitos de fraude. O motivo é que existem apenas 18 linhas com esses dados e não podemos sacrificá-los, pois isso pode levar à falta de exemplos de treinamento. Como resultado, removemos apenas aqueles que não são suspeitos de fraude, mas ao mesmo tempo têm um grande número de sinais pelos quais as emissões são observadas:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
Finalizando
Normalizamos nossos dados:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
Permite segmentar a variável de destino para uma visualização compatível:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

Como resultado, 18 suspeitos e 121 aqueles que não foram suspeitos.
Seleção de Recursos
Talvez um dos pontos mais importantes antes de aprender qualquer modelo seja a seleção dos recursos mais importantes.
Teste de multicolinearidade
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
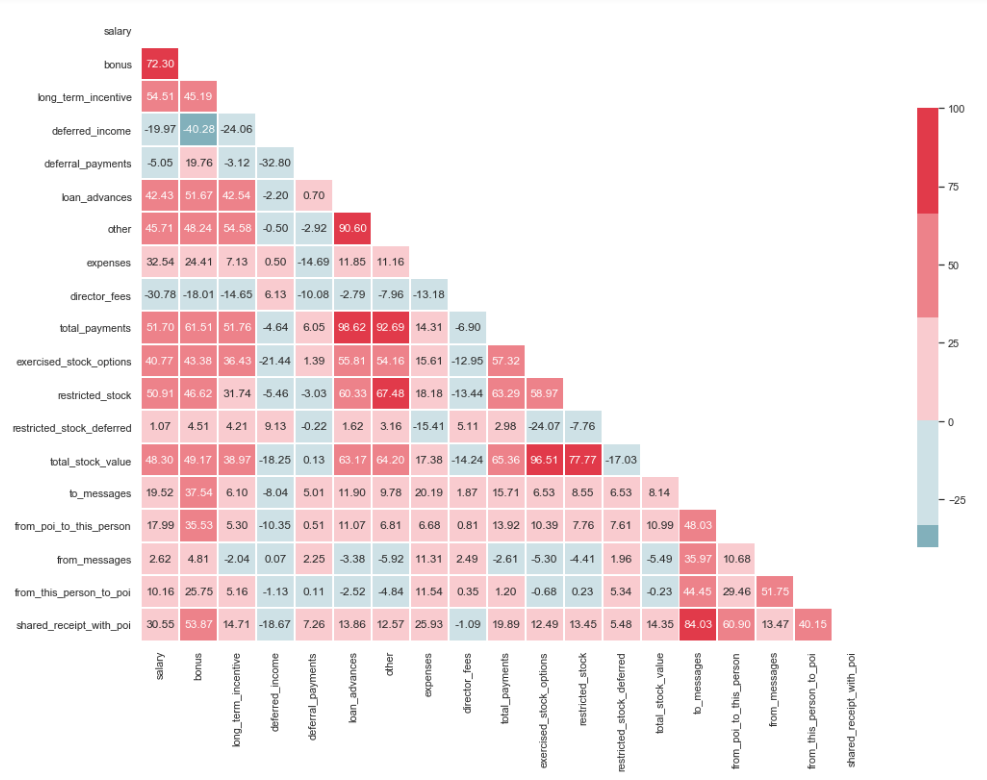
Como você pode ver na imagem, temos um relacionamento pronunciado entre 'loan_advanced' e 'total_payments', bem como entre 'total_stock_value' e 'strict_stock'. Como mencionado anteriormente, 'total_payments' e 'total_stock_value' são apenas o resultado da soma de todos os indicadores em um grupo específico. Portanto, eles podem ser excluídos:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
Criando novas características
Também existe a suposição de que os suspeitos escreviam para os cúmplices com mais frequência do que para os funcionários que não estavam envolvidos nisso. E, como resultado, a proporção dessas mensagens deve ser maior que a proporção de mensagens para funcionários comuns. Com base nesta declaração, você pode criar novos sinais que refletem a porcentagem de entrada / saída relacionada a suspeitos:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
Protegendo sinais desnecessários
No conjunto de ferramentas de pessoas associadas ao ML, existem muitas ferramentas excelentes para selecionar os recursos mais significativos (SelectKBest, SelectPercentile, VarianceThreshold, etc.). Nesse caso, o RFECV será usado, pois inclui a validação cruzada, que permite calcular os recursos mais importantes e verificá-los em todos os subconjuntos da amostra:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
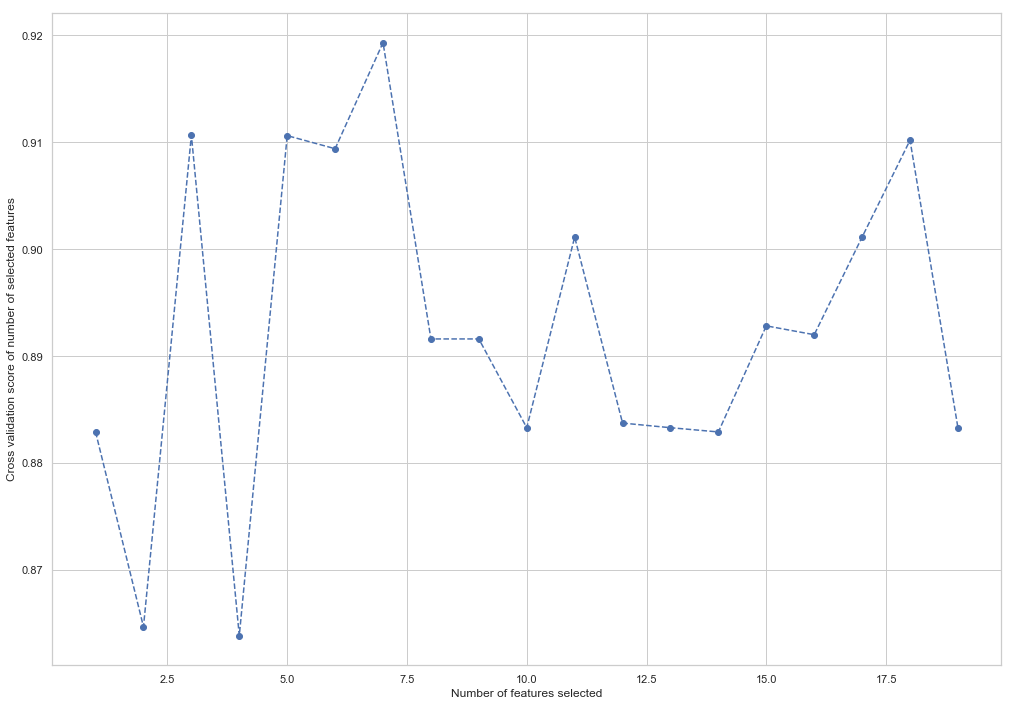
Como você pode ver, o RandomForestClassifier calculou que apenas 7 dos 18 atributos são importantes. Usar o resto reduz a precisão do modelo.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
Esses 7 recursos serão usados no futuro para simplificar o modelo e reduzir o risco de reciclagem:
- bônus
- deferred_income
- outro
- exercised_stock_options
- shared_receipt_with_poi
- ratio_of_poi_mail
- ratio_of_mail_to_poi
Altere a estrutura do treinamento e teste as amostras para o treinamento futuro do modelo:
X_train = X_train[columns] X_test = X_test[columns]
Este é o fim da primeira parte que descreve o uso do Enron Dataset como um exemplo de uma tarefa de classificação no ML. Com base nos materiais do curso Introdução ao aprendizado de máquina sobre Udacity. Há também um notebook python refletindo toda a sequência de ações.
A segunda parte está aqui