1. Introdução
Olá Habr!
Quero compartilhar a experiência de escrever migrações para o postgres e o django. Isso será principalmente sobre o postgres, o django é uma boa adição aqui, uma vez que possui uma migração automática do esquema de dados para mudanças de modelo prontas para uso, ou seja, possui uma lista bastante completa de operações de trabalho para alterar o esquema. O Django pode ser substituído por qualquer estrutura / biblioteca favorita - as abordagens provavelmente serão semelhantes.
Não vou descrever como cheguei a isso, mas agora, lendo a documentação, entendo que era necessário fazer isso antes com mais cuidado e conscientização, por isso recomendo vivamente.
Antes de prosseguir, deixe-me fazer as seguintes suposições.
Você pode dividir a lógica de trabalhar com o banco de dados da maioria dos aplicativos em 3 partes:
- Migrações - alterando o esquema do banco de dados (tabelas), suponha que sempre as executemos em um encadeamento.
- Lógica comercial - trabalho direto com dados (em tabelas de usuários), trabalha com os mesmos dados de forma constante e competitiva.
- Migrações de dados - não alteram os esquemas de dados, eles funcionam essencialmente como lógica de negócios; por padrão, quando falamos de lógica de negócios, também queremos dizer migrações de dados.
O tempo de inatividade é um estado em que uma parte de nossa lógica de negócios não está disponível / cai / é carregada por um tempo perceptível para o usuário, suponha que esse seja um par de segundos.
A ausência de tempo de inatividade pode ser uma condição crítica para uma empresa, que deve ser respeitada por qualquer esforço.
Processo de lançamento
Os principais requisitos ao implantar:
- nós temos uma base de trabalho.
- Temos várias máquinas onde a lógica de negócios gira.
- carros com lógica de negócios estão escondidos atrás do balanceador.
- nosso aplicativo funciona bem antes, durante e após a migração contínua (o código antigo funciona corretamente com o esquema antigo e o novo banco de dados).
- Nosso aplicativo funciona bem antes, durante e depois da atualização do código nos carros (o código antigo e o novo funcionam corretamente com o esquema de banco de dados atual).
Se houver um grande número de alterações e a implementação deixar de atender a essas condições, ela será dividida no número necessário de implementações menores que atendam a essas condições, caso contrário, teremos um tempo de inatividade.
Ordem de lançamento direto:
- inundou a migração;
- removeu uma máquina do balanceador, atualizou a máquina e reiniciou, devolveu a máquina ao balanceador;
- repetiu o passo anterior para atualizar todos os carros.
A ordem de implementação inversa é relevante para excluir tabelas e colunas em uma tabela, quando criamos migrações automaticamente de acordo com o esquema alterado e validamos a presença de todas as migrações para o IC:
- removeu uma máquina do balanceador, atualizou a máquina e reiniciou, devolveu a máquina ao balanceador;
- repetiu o passo anterior para atualizar todos os carros;
- inundou a migração.
Teoria
O Postgres é um excelente banco de dados, podemos escrever um aplicativo que escreverá e lerá os mesmos dados em centenas e milhares de fluxos, e com alta probabilidade, podemos ter certeza de que nossos dados permanecerão válidos e não serão corrompidos, em geral, o ACID completo. O Postgres implementa vários mecanismos para conseguir isso; um deles está bloqueando.
O Postgres possui vários tipos de bloqueios, mais detalhes podem ser encontrados aqui . Como parte do tópico, tocarei apenas na tabela e bloqueios em nível de registro.
Bloqueios no nível da tabela
No nível da tabela, o postgres possui vários tipos de bloqueios , o principal recurso é que eles têm conflitos, ou seja, duas operações com bloqueios conflitantes não podem ser executadas simultaneamente:
| ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE |
|---|
ACCESS SHARE | | | | | | | | X |
ROW SHARE | | | | | | | X | X |
ROW EXCLUSIVE | | | | | X | X | X | X |
SHARE UPDATE EXCLUSIVE | | | | X | X | X | X | X |
SHARE | | | X | X | | X | X | X |
SHARE ROW EXCLUSIVE | | | X | X | X | X | X | X |
EXCLUSIVE | | X | X | X | X | X | X | X |
ACCESS EXCLUSIVE | X | X | X | X | X | X | X | X |
Por exemplo, ALTER TABLE tablename ADD COLUMN newcolumn integer e SELECT COUNT(*) FROM tablename devem ser estritamente executados um por um, caso contrário, não podemos descobrir quais colunas retornar a COUNT(*) .
Nas migrações de django (lista completa abaixo), existem as seguintes operações e seus bloqueios correspondentes:
| bloqueio | operações |
|---|
ACCESS EXCLUSIVE | CREATE SEQUENCE , CREATE SEQUENCE DROP SEQUENCE , CREATE TABLE , DROP TABLE , ALTER TABLE , DROP INDEX |
SHARE | CREATE INDEX |
SHARE UPDATE EXCLUSIVE | CREATE INDEX CONCURRENTLY , DROP INDEX CONCURRENTLY , ALTER TABLE VALIDATE CONSTRAINT |
Dos comentários, nem todas as ALTER TABLE têm bloqueio ACCESS EXCLUSIVE , também as migrações do django não têm CREATE INDEX CONCURRENTLY e ALTER TABLE VALIDATE CONSTRAINT , mas serão necessárias para uma alternativa mais segura às operações padrão um pouco mais tarde.
Se as migrações forem executadas em um encadeamento sequencialmente, tudo parecerá bom, pois a migração não entrará em conflito com outra migração, mas nossa lógica de negócios funcionará apenas durante a migração e o conflito.
| bloqueio | operações | conflitos com bloqueios | conflitos com operações |
|---|
ACCESS SHARE | SELECT | ACCESS EXCLUSIVE | ALTER TABLE , DROP INDEX |
ROW SHARE | SELECT FOR UPDATE | ACCESS EXCLUSIVE , EXCLUSIVE | ALTER TABLE , DROP INDEX |
ROW EXCLUSIVE | INSERT , UPDATE , DELETE | ACCESS EXCLUSIVE , EXCLUSIVE , SHARE ROW EXCLUSIVE , SHARE | ALTER TABLE , DROP INDEX , CREATE INDEX |
Dois pontos podem ser resumidos aqui:
- se houver uma alternativa com bloqueio mais fácil, você poderá usá-lo como
CREATE INDEX e CREATE INDEX CONCURRENTLY . - a maioria das migrações para alterar o esquema de dados entra em conflito com a lógica de negócios; além disso, elas entram em conflito com
ACCESS EXCLUSIVE , ou seja, não podemos fazer SELECT enquanto mantemos esse bloqueio e esperamos um tempo de inatividade aqui, exceto no caso em que essa operação não funcione imediatamente e nosso tempo de inatividade será alguns segundos.
Deve haver uma opção, ou sempre evitamos o ACCESS EXCLUSIVE , ou seja, criamos novas placas e copiamos os dados lá - de maneira confiável, mas por um longo período de tempo para uma grande quantidade de dados, ou fazemos o ACCESS EXCLUSIVE mais rápido possível e fazemos avisos adicionais contra o tempo de inatividade - é potencialmente perigoso, mas rápido.
Bloqueios de registro
No nível da gravação, também existem bloqueios https://www.postgresql.org/docs/current/static/explicit-locking.html#LOCKING-ROWS , eles também entram em conflito, mas afetam apenas nossa lógica de negócios:
| FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE |
|---|
FOR KEY SHARE | | | | X |
FOR SHARE | | | X | X |
FOR NO KEY UPDATE | | X | X | X |
FOR UPDATE | X | X | X | X |
Esse é o ponto principal nas migrações de dados, ou seja, se fizermos UPDATE migração de dados em toda a placa, o restante da lógica de negócios, que atualiza os dados, aguardará a liberação do bloqueio e poderá exceder nosso limite de tempo de inatividade, portanto, é melhor fazer atualizações em partes para migrações de dados. Também é importante notar que, ao usar consultas sql mais complexas para migrações de dados, a divisão em partes pode funcionar mais rapidamente, pois pode usar um plano e índices mais ideais.
A ordem das operações
Outro conhecimento importante é como as operações serão executadas, quando e como elas recebem e liberam bloqueios:
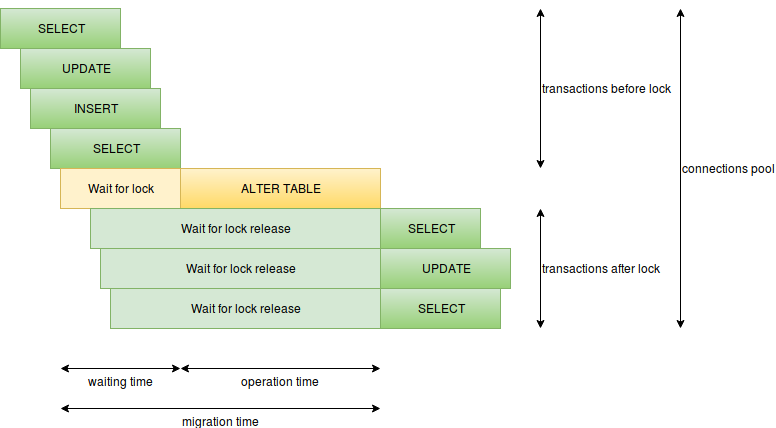
Aqui você pode destacar os seguintes itens:
- tempo de execução da operação - para migração, é o tempo de manter o bloqueio, se o bloqueio pesado for mantido por um longo tempo, teremos um tempo de inatividade, por exemplo, pode ser com
CREATE INDEX ou ALTER TABLE ADD COLUMN SET DEFAULT (no postgres 11, isso é melhor). - o tempo de espera para bloqueios conflitantes - ou seja, a migração aguarda até que todas as solicitações conflitantes funcionem e, nesse momento, novas solicitações aguardam nossa migração, solicitações lentas podem ser muito perigosas aqui, simplesmente não ideais ou analíticas, portanto, não deve haver solicitações lentas durante migração.
- o número de solicitações por segundo - se tivermos muitas solicitações funcionando por um longo período de tempo, as conexões gratuitas poderão terminar rapidamente e, em vez de um local problemático, todo o banco de dados poderá entrar em tempo de inatividade (haverá apenas um limite de conexão para o superusuário); aqui, você deve evitar solicitações lentas, reduzir o número de solicitações por exemplo, inicie as migrações durante o carregamento mínimo, separe os componentes críticos em diferentes serviços com seus próprios bancos de dados.
- existem muitas operações de migração em uma transação - quanto mais operações em uma transação, mais tempo o bloqueio pesado é mantido, portanto, é melhor separar operações pesadas, sem
ALTER TABLE VALIDATE CONSTRAINT ou migrações de dados em uma transação com um bloqueio pesado.
Timeouts
lock_timeout possui configurações como lock_timeout e statement_timeout , que podem proteger o início das migrações, tanto da migração mal escrita quanto das más condições nas quais a migração pode ser acionada. Eles podem ser instalados globalmente e para a conexão atual.
SET lock_timeout TO '2s' evitará o tempo de inatividade ao aguardar solicitações / transações lentas antes da migração: https://www.postgresql.org/docs/current/static/runtime-config-client.html#GUC-LOCK-TIMEOUT .
SET statement_timeout TO '2s' evitará o tempo de inatividade ao iniciar uma migração pesada com um bloqueio pesado: https://www.postgresql.org/docs/current/static/runtime-config-client.html#GUC-STATEMENT-TIMEOUT .
Deadlocks
Os deadlocks nas migrações não se limitam ao tempo de inatividade, mas não é agradável quando a migração é escrita, funciona bem em um ambiente de teste, mas os bloqueia durante a rolagem no produto. As principais fontes de problemas podem ser um grande número de operações em uma transação e uma Chave Externa, uma vez que cria bloqueios nas duas tabelas; portanto, é melhor separar as operações de migração, quanto mais atômica, melhor.
Armazenamento de registros
O Postgres armazena valores de tipos diferentes de maneiras diferentes : se os tipos forem armazenados de maneira diferente, a conversão entre eles exigirá uma reescrita completa de todos os valores, felizmente alguns tipos são armazenados da mesma maneira e não precisam ser reescritos quando alterados. Por exemplo, as linhas são armazenadas da mesma forma, independentemente do tamanho, e diminuir / aumentar a dimensão de uma linha não exigirá reescrita, mas diminuir exige verificar se todas as linhas não excedem um tamanho menor. Outros tipos também podem ser armazenados de maneira semelhante e têm características semelhantes.
Controle de Concorrência Multiversão (MVCC)
De acordo com a documentação , a consistência do postgres é baseada na multiversão de dados, ou seja, cada transação e operação vê sua própria versão dos dados. Esse recurso lida perfeitamente com o acesso competitivo e também oferece um efeito interessante ao alterar um esquema, como adicionar e remover colunas, apenas altera o esquema, se não houver operações adicionais para alterar dados, índices ou constantes, após o que as operações de inserção e atualização em um nível baixo criarão novas registros com todos os valores necessários, a exclusão marcará o registro correspondente excluído. VACUUM ou AUTO VACUUM é responsável pela limpeza dos resíduos restantes.
Exemplo de Django
Agora, temos uma idéia do que o tempo de inatividade pode depender e como evitá-lo, mas antes de aplicar o conhecimento, você pode ver o que o django fornece imediatamente ( https://github.com/django/django/blob/2.1.2/django /db/backends/base/schema.py e https://github.com/django/django/blob/2.1.2/django/db/backends/postgresql/schema.py ):
| operação |
|---|
| 1 | CREATE SEQUENCE |
| 2 | DROP SEQUENCE |
| 3 | CREATE TABLE |
| 4 | DROP TABLE |
| 5 | ALTER TABLE RENAME TO |
| 6 | ALTER TABLE SET TABLESPACE |
| 7 | ALTER TABLE ADD COLUMN [SET DEFAULT] [SET NOT NULL] [PRIMARY KEY] [UNIQUE] |
| 8 | ALTER TABLE ALTER COLUMN [TYPE] [SET NOT NULL|DROP NOT NULL] [SET DEFAULT|DROP DEFAULT] |
| 9 | ALTER TABLE DROP COLUMN |
| 10 | ALTER TABLE RENAME COLUMN |
| 11 | ALTER TABLE ADD CONSTRAINT CHECK |
| 12 | ALTER TABLE DROP CONSTRAINT CHECK |
| 13 | ALTER TABLE ADD CONSTRAINT FOREIGN KEY |
| 14 | ALTER TABLE DROP CONSTRAINT FOREIGN KEY |
| 15 | ALTER TABLE ADD CONSTRAINT PRIMARY KEY |
| 16 | ALTER TABLE DROP CONSTRAINT PRIMARY KEY |
| 17 | ALTER TABLE ADD CONSTRAINT UNIQUE |
| 18 | ALTER TABLE DROP CONSTRAINT UNIQUE |
| 19 | CREATE INDEX |
| 20 | DROP INDEX |
O Django cobre minhas necessidades de migração muito bem, agora podemos discutir operações seguras e perigosas para migrações sem tempo de inatividade com o nosso conhecimento.
Chamaremos migrações mais seguras com o bloqueio SHARE UPDATE EXCLUSIVE ou ACCESS EXCLUSIVE , que funciona instantaneamente.
Chamaremos migrações perigosas com bloqueios SHARE e ACCESS EXCLUSIVE , que levam um tempo considerável.
Deixarei um link útil para a documentação com ótimos exemplos.
Crie e exclua uma tabela
CREATE SEQUENCE , DROP SEQUENCE , CREATE TABLE , DROP TABLE pode ser chamado de seguro, uma vez que a lógica de negócios não funciona mais com a tabela migrada, o comportamento de excluir uma tabela com FOREIGN KEY será um pouco mais tarde.
Operações de planilha altamente suportadas
ALTER TABLE RENAME TO - Não posso chamá-lo de seguro, pois é difícil escrever uma lógica que funcione com essa tabela antes e depois da migração.
ALTER TABLE SET TABLESPACE - inseguro, pois move fisicamente a placa, e isso pode demorar muito tempo em um grande volume.
Por outro lado, essas operações são extremamente raras, como alternativa, você pode oferecer a criação de uma nova tabela e copiar dados nela.
Criar e excluir colunas
ALTER TABLE ADD COLUMN , ALTER TABLE DROP COLUMN - pode ser chamado de seguro (criação sem DEFAULT / NOT NULL / PRIMARY KEY / UNIQUE), porque a lógica de negócios não funciona mais com uma coluna migrada, o comportamento de excluir uma coluna com FOREIGN KEY, outras constantes e índices virão mais tarde.
ALTER TABLE ADD COLUMN SET DEFAULT , ALTER TABLE ADD COLUMN SET NOT NULL , ALTER TABLE ADD COLUMN PRIMARY KEY , ALTER TABLE ADD COLUMN UNIQUE - operações inseguras, porque adicionam uma coluna e, sem liberar bloqueios, atualizam dados com padrões ou criam construções como alternativas, colunas anuláveis e outras alterações.
Vale mencionar o SET DEFAULT mais rápido no postgres 11, que pode ser considerado seguro, mas não se torna muito útil no django, pois o django usa SET DEFAULT apenas para preencher a coluna e depois faz o DROP DEFAULT , e no intervalo entre a migração e a atualização de máquinas com o django. lógica de negócios, é possível criar registros nos quais o padrão estará ausente, ou seja, mesmo assim, faça a migração de dados.
Operações altamente suportadas em uma planilha
ALTER TABLE RENAME COLUMN - Também não posso chamá-lo de seguro, pois é difícil escrever uma lógica que funcione com essa coluna antes e depois da migração. Em vez disso, essa operação também não será frequente, pois uma alternativa pode ser proposta para criar uma nova coluna e copiar dados para ela.
Alteração de coluna
ALTER TABLE ALTER COLUMN TYPE - a operação pode ser perigosa e segura. Seguro se o postgres alterar apenas o esquema, e os dados já estiverem armazenados no formato necessário e não forem necessárias verificações adicionais de tipo, por exemplo:
- alteração de tipo de
varchar(LESS) para varchar(MORE) ; - digite mudar de
varchar(ANY) para text ; - digite alteração de
numeric(LESS, SAME) para numeric(MORE, SAME) .
ALTER TABLE ALTER COLUMN SET NOT NULL é perigoso, porque passa pelos dados internos e verifica NULL; felizmente, essa construção pode ser substituída por outra CHECK IS NOT NULL . Vale ressaltar que essa substituição levará a um esquema diferente, mas com propriedades idênticas.
ALTER TABLE ALTER COLUMN DROP NOT NULL , ALTER TABLE ALTER COLUMN SET DEFAULT , ALTER TABLE ALTER COLUMN DROP DEFAULT - operações seguras.
Criando e excluindo índices e constantes
ALTER TABLE ADD CONSTRAINT CHECK e ALTER TABLE ADD CONSTRAINT FOREIGN KEY são operações inseguras, mas podem ser declaradas como NOT VALID e, em seguida, ALTER TABLE VALIDATE CONSTRAINT .
ALTER TABLE ADD CONSTRAINT PRIMARY KEY e ALTER TABLE ADD CONSTRAINT UNIQUE não ALTER TABLE ADD CONSTRAINT UNIQUE seguras, porque criam um índice exclusivo dentro, mas você pode criar um índice exclusivo como CONCURRENTLY , em seguida, crie a constante correspondente usando um índice pronto usando USING INDEX .
CREATE INDEX é uma operação insegura, mas um índice pode ser criado como CONCURRENTLY .
ALTER TABLE DROP CONSTRAINT CHECK , ALTER TABLE DROP CONSTRAINT FOREIGN KEY , ALTER TABLE DROP CONSTRAINT PRIMARY KEY , ALTER TABLE DROP CONSTRAINT UNIQUE , DROP INDEX - operações seguras.
Vale ressaltar que ALTER TABLE ADD CONSTRAINT FOREIGN KEY e ALTER TABLE DROP CONSTRAINT FOREIGN KEY bloqueiam duas tabelas ao mesmo tempo.
Aplicando conhecimento no django
O Django possui uma operação em migrações para executar qualquer SQL: https://docs.djangoproject.com/en/2.1/ref/migration-operations/#django.db.migrations.operations.RunSQL . Por meio dele, você pode definir os tempos limites necessários e aplicar operações alternativas para migrações, indicando state_operations - a migração que estamos substituindo.
Isso funciona bem para seu código, embora exija gravação adicional, mas você pode deixar o trabalho sujo no db backend, por exemplo, https://github.com/tbicr/django-pg-zero-downtime-migrations/blob/master/django_zero_downtime_migrations_postgres_backend/schema .py coleta as práticas descritas e substitui operações inseguras por contrapartes seguras, e isso funcionará para bibliotecas de terceiros.
No final
Essas práticas me permitiram obter um esquema idêntico criado pelo django imediatamente, com a exceção de substituir a construção CHECK IS NOT NULL vez de NOT NULL e alguns nomes de construção (por exemplo, para ALTER TABLE ADD COLUMN UNIQUE e uma alternativa). Outro trade-off pode ser a falta de transacionalidade para operações de migração alternativas, especialmente quando CREATE INDEX CONCURRENTLY e ALTER TABLE VALIDATE CONSTRAINT .
Se você não vai além do postgres, pode haver muitas opções para alterar o esquema de dados e elas podem variar em combinação sob condições específicas:
- usando jsonb como solução sem schamaless
- a oportunidade de ir para o tempo de inatividade
- requisito para fazer migrações sem tempo de inatividade
De qualquer forma, espero que o material tenha sido útil para aumentar o tempo de atividade ou expandir a consciência.