
O teste de regressão é uma parte muito importante do trabalho com a qualidade do produto. E quanto mais produtos e mais rápido eles desenvolvem, mais esforço é necessário.
A Yandex aprendeu como dimensionar tarefas de teste manual para a maioria dos produtos usando avaliadores - funcionários remotos trabalhando meio período, peça por peça, e agora centenas de avaliadores participam dos testes do produto Yandex, além dos testadores regulares.
Este post diz:
- Como você conseguiu tornar as tarefas manuais de teste o mais formalizadas possível e treinar centenas de funcionários remotos com eles;
- Como você conseguiu colocar o processo nos trilhos industriais, fornecer testes em vários ambientes, suportar SLA em velocidade e qualidade;
- Que dificuldades eles encontraram e como foram resolvidos (e alguns ainda não decidiram);
- Qual foi a contribuição dos testes dos avaliadores no desenvolvimento dos produtos Yandex, como isso afetou a frequência dos lançamentos e o número de bugs passados.
O texto é baseado na transcrição do
relatório de
Olga Megorskaya da nossa conferência de maio de Heisenbug 2018 Piter:
A partir do dia do relatório, alguns números conseguiram mudar, nesses casos, indicamos os dados reais entre colchetes. A seguir, é apresentada uma perspectiva em primeira pessoa:Hoje, falaremos sobre o uso de técnicas de crowdsourcing para aumentar as tarefas de teste manual.
Tenho um cargo bastante estranho: chefe do departamento de avaliações de especialistas. Vou tentar contar com exemplos o que faço. No Yandex, tenho dois vetores principais de responsabilidade:

Por um lado, tudo isso está relacionado ao crowdsourcing. Sou responsável por nossa plataforma de crowdsourcing Yandex.Tolok.
E, por outro lado, equipes que, se você tentar dar uma definição universal, podem ser atribuídas a "vagas improdutivas em massa". Inclui muitas coisas diferentes, incluindo um de nossos projetos recentes: teste manual com a ajuda de multidões, que chamamos de "teste por avaliadores".
Minha principal atividade no Yandex é reunir as colunas esquerda e direita da imagem e tentar otimizar tarefas e processos na produção em massa usando crowdsourcing. E hoje vamos falar sobre isso usando o exemplo de tarefas de teste.
O que é crowdsourcing?
Vamos começar com o que é crowdsourcing. Podemos dizer que isso substitui a experiência de um especialista específico pela chamada "sabedoria da multidão" nos casos em que a experiência de um especialista é muito cara ou difícil de ser dimensionada.
O crowdsourcing tem sido usado ativamente em vários campos por muitos anos. Por exemplo, a NASA gosta muito de projetos de crowdsourcing. Lá, com a ajuda da "multidão", eles exploram e descobrem novos objetos na galáxia. Parece uma tarefa muito difícil, mas com a ajuda do crowdsourcing, tudo se resume a uma tarefa bastante simples. Existe um
site especial no qual centenas de milhares de fotos tiradas por telescópios espaciais são postadas, e elas perguntam a quem quiser procurar certos objetos lá. E quando muitas pessoas são suspeitamente parecidas com o objeto de que precisam, especialistas de nível superior já estão conectados e começam a explorá-lo.
De um modo geral, o crowdsourcing é um método desse tipo quando pegamos algumas tarefas de alto nível e as dividimos em muitas subtarefas simples e homogêneas, nas quais muitos artistas independentes se reúnem. Cada um dos artistas pode resolver uma ou várias dessas pequenas tarefas e, juntos, trabalham para uma grande causa comum e coletam ótimos resultados para uma tarefa de alto nível.
Yandex crowdsourcing
Já começamos vários anos a desenvolver nosso sistema de crowdsourcing. Inicialmente, era usado para tarefas relacionadas ao aprendizado de máquina: coletar dados de treinamento, configurar redes neurais, algoritmos de busca e assim por diante.
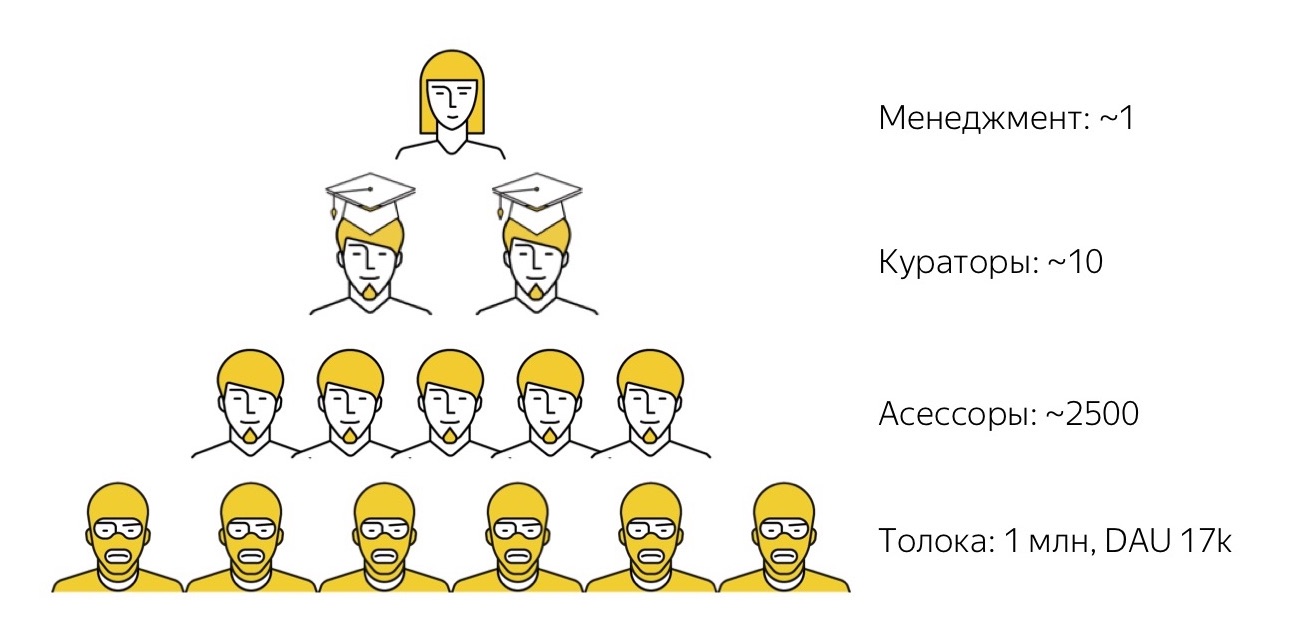
Como o nosso ecossistema de crowdsourcing funciona? Em primeiro lugar, temos o
Yandex.Toloka . Esta é uma plataforma aberta de crowdsourcing na qual qualquer pessoa pode se registrar como cliente (postar suas tarefas, definir um preço para eles e coletar dados) ou como executor (encontre tarefas interessantes, conclua-as e receba uma pequena recompensa). Lançamos o teto alguns anos atrás. Agora, temos mais de um milhão de artistas registrados (os chamamos de tokers) e todos os dias no sistema cerca de 17.000 pessoas realizam tarefas.
Desde que criamos o Toloka inicialmente de olho nas tarefas relacionadas ao aprendizado de máquina, tradicionalmente é costume que a maioria das tarefas executadas pelos tolokers sejam tarefas muito simples e triviais para uma pessoa, mas ainda bastante difíceis para o algoritmo. Por exemplo, olhe para uma foto e diga se tem conteúdo adulto ou não, ou ouça uma gravação de áudio e descriptografe o que ouviu.
O Toloka é uma ferramenta muito poderosa em termos de desempenho e quantidade de dados que ajuda a coletar, mas não é trivial de usar. As pessoas na foto estão usando capuz amarelo porque todos os artistas em Tolok são anônimos e desconhecidos pelos clientes. E gerenciar esses milhares de anônimos, garantir que eles façam exatamente o que você precisa não é uma tarefa fácil. Portanto, nem todas as tarefas que temos, até agora somos capazes de resolver com a ajuda dessa multidão absolutamente "louca". Embora nos esforcemos para isso, falarei mais sobre isso mais tarde.
Portanto, para tarefas de nível superior, temos o próximo nível de artistas. Essas são as pessoas que chamamos de avaliadores. A própria palavra "assessores" pode ser um pouco estranha. Veio da palavra “avaliação”, ou seja, “avaliação”, porque inicialmente os avaliadores foram usados conosco para coletar avaliações subjetivas da qualidade dos resultados da pesquisa. Esses dados foram usados como destino para o aprendizado de máquina da função de classificação de pesquisa. Desde então, muito tempo se passou, os avaliadores começaram a executar muitas outras tarefas diferentes, então agora essa é uma palavra comum: as tarefas mudaram, mas a palavra permanece.
De fato, nossos avaliadores são funcionários em tempo integral da Yandex, mas trabalham meio período e de forma totalmente remota. São caras que trabalham em seus próprios equipamentos. Só interagimos com eles remotamente: os selecionamos remotamente, treinamos remotamente, trabalhamos remotamente com eles e, se necessário, os acionamos remotamente. Com a maioria deles, nunca nos cruzamos pessoalmente na vida. Eles trabalham de acordo com qualquer programação conveniente para si mesmos, dia ou noite: eles têm padrões mínimos equivalentes a cerca de 10 a 15 horas por semana e podem trabalhar dessa vez da maneira que melhor lhes convier. Os avaliadores resolvem uma variedade de problemas: eles estão conectados à pesquisa e ao suporte técnico, além de algumas traduções de baixo nível e aos testes, sobre os quais falaremos mais adiante.
Como regra, independentemente da tarefa que realizamos, as pessoas mais talentosas sempre se destacam do grupo de avaliadores que a desempenham melhor, para quem essa tarefa é mais interessante. Nós os destacamos, damos-lhes o título alto de super-falantes, e esses caras já estão desempenhando funções de curadores de nível superior: eles verificam a qualidade do trabalho de outras pessoas, as consultam, as apóiam e assim por diante.
E somente no topo de nossa pirâmide, temos o primeiro funcionário em tempo integral que fica no escritório e gerencia esses processos. Temos muito menos pessoas que já estão em um nível muito mais alto e possuem fortes habilidades técnicas e administrativas, literalmente poucas. Esse sistema permite concluir que essas unidades de pessoas de "alto nível" constroem oleodutos e gerenciam cadeias de produção, nas quais dezenas, centenas e até milhares de pessoas estão envolvidas.
Por si só, esse esquema não é novo, mas Genghis Khan o aplicou com sucesso. Ela tem várias propriedades interessantes que estamos tentando usar. A primeira propriedade é bastante compreensível - esse esquema é muito fácil de dimensionar. Se uma tarefa precisa começar repentinamente a fazer mais, não precisamos procurar espaço adicional no escritório para plantar uma pessoa em algum lugar. Em geral, podemos pensar muito pouco sobre o quê: apenas despeje mais dinheiro, contrate mais artistas por esse dinheiro, e caras mais talentosos em academias provavelmente crescerão com esses artistas, e todo esse sistema continuará em escala.
A segunda propriedade (e foi surpreendente para mim) é que essa pirâmide é muito bem replicada, independentemente da área de assunto em que é aplicada. Isso também se aplica à área sobre a qual falaremos hoje - tarefas de teste manual.
Teste de Multidão
Quando começamos o processo de teste com a ajuda de multidões, o maior problema foi a falta de uma referência positiva. Não havia experiência a que pudéssemos nos referir e dizer: “Bem, esses caras fizeram isso, eles já estão testando com a ajuda de multidões em um circuito muito semelhante ao nosso, e está tudo bem lá, o que significa que tudo ficará bem conosco”. Portanto, tivemos que confiar apenas em nossa experiência pessoal, que foi separada da área de teste e mais relacionada à criação de processos de produção semelhantes, mas em outras áreas.
Portanto, tivemos que fazer o que podemos. O que podemos fazer? Em essência, decompor uma tarefa em tarefas de diferentes níveis de dificuldade e espalhá-las pelos pisos de nossa pirâmide. Vamos ver o que temos.
Primeiro, analisamos as tarefas com as quais nossos testadores em Yandex estão ocupados e pedimos que dispersassem condicionalmente essas tarefas em diferentes níveis de dificuldade. Esta é uma "média hospitalar":
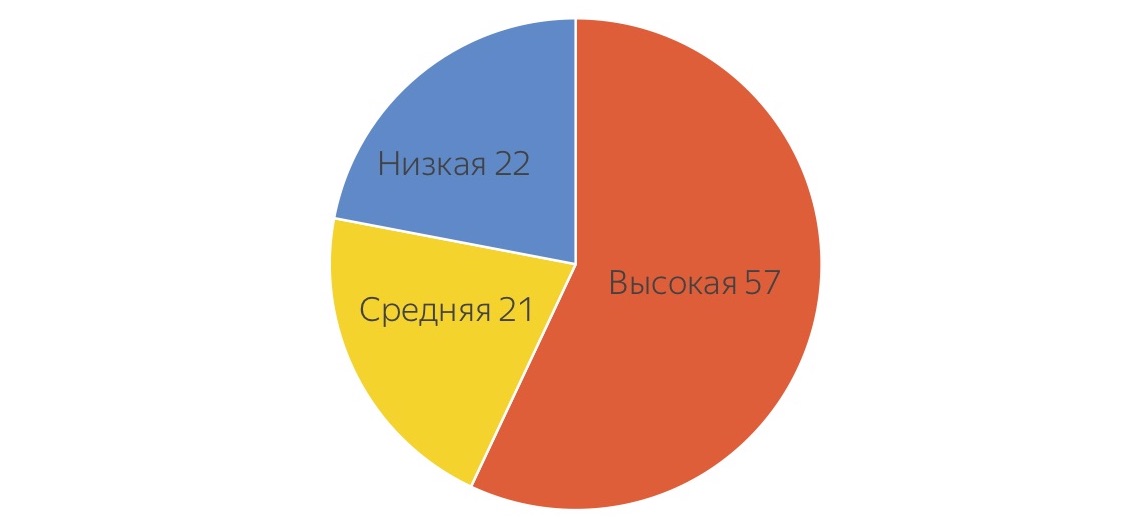
Eles estimaram que apenas 57% do tempo é gasto em tarefas complexas de alto nível, e cerca de 20% é gasto em uma rotina de nível muito baixo, da qual todos querem se livrar, e em tarefas um pouco mais complicadas, que também podem ser delegadas. Encorajados por esses números, mostrando que quase metade do trabalho pode ser transferido para algum lugar, passamos a fazer testes usando multidões.
Quais são os nossos objetivos?
- Faça do teste não mais o gargalo que ele apareceu periodicamente nos processos de produção quando a liberação estiver pronta, mas aguarda a aprovação do teste.
- Alivie nossos especialistas legais, muito inteligentes e de alto nível - testadores em tempo integral - da rotina, ocupando-os com tarefas realmente interessantes e de nível superior.
- Aprimore a variedade de ambientes nos quais testamos produtos.
- Aprendendo a lidar com cargas de pico, porque nossos testadores disseram que costumam ter cargas desiguais. Mesmo que, em média, uma equipe lide com as tarefas, quando ocorre um pico, leva muito tempo para fazer a varredura.
- Como em Yandex ainda gastamos bastante dinheiro em testes de terceirização em alguns projetos, pensamos que gostaríamos de obter um pouco mais de resultados pelo dinheiro que gastamos, para otimizar nossas despesas de terceirização.
Quero enfatizar que, entre esses objetivos, não há tarefa de substituir os testadores por multidões, de alguma forma os infringir, e assim por diante. Tudo o que queríamos fazer era ajudar as equipes de teste, eliminando a rotina de baixo nível.
Vamos ver com o que acabamos. Eu direi imediatamente que as principais tarefas dos testes agora são realizadas não pelo nível mais baixo da “pirâmide”, pelos tolkers, mas pelos avaliadores, nossos funcionários em período integral. Além disso, discutiremos principalmente sobre eles, exceto no final.
Os avaliadores agora estão realizando as tarefas de teste de regressão para nós e realizando todos os tipos de pesquisas como "olhe para este aplicativo e deixe seu feedback". Agora, cerca de 300 pessoas estão qualificadas para a tarefa de recurso completo (
nota: desde que o relatório se tornou 500 ). Mas esse número é condicional, porque o sistema que construímos funciona para um número arbitrário de pessoas: o quanto for necessário. Agora, nossas necessidades de produção são atendidas por aproximadamente tantas pessoas. Isso não significa que a todo momento eles estejam prontos e prontos para executar a tarefa: como os avaliadores trabalham em um horário flexível, a qualquer momento, 100 a 150 pessoas estão prontas para se conectar. Mas o conjunto de artistas é praticamente o mesmo. E tarefas simples, como pesquisas, quando você só precisa coletar feedback informal dos usuários, passamos por muito mais pessoas: centenas e milhares de avaliadores participam dessas pesquisas.
Como são pessoas que trabalham em seu próprio equipamento, cada avaliador possui seus próprios dispositivos pessoais. Por padrão, esse é um desktop e algum tipo de dispositivo móvel. Dessa forma, testamos nossos produtos em dispositivos pessoais de avaliadores. Mas é claro que eles não possuem todos os dispositivos possíveis; portanto, se precisarmos de testes em algum ambiente raro, usaremos o acesso remoto através do farm de dispositivos.
Agora, o teste de multidão já é usado como um processo de produção padrão para cerca de 40 (
nota: agora 60 ) serviços e equipes Yandex: isto é Correio, Disco e Navegador (móvel e desktop), Mapas e Pesquisa, e muitos, muitos quem Isso é curioso. Quando nos propusemos planos para o final do terceiro trimestre no outono de 2017, tínhamos um objetivo ambicioso: atrair pelo menos de alguma forma, "mesmo por fraude, até subornando", pelo menos cinco equipes que usariam nossos processos de teste com a ajuda de multidões. E nós convencemos muito a todos: "Não tenha medo, vamos lá, experimente!" Mas depois de alguns meses, tínhamos dezenas de equipes.
E agora estamos resolvendo outro problema: como conseguir conectar cada vez mais novas equipes que desejam ingressar nesses processos. Portanto, podemos assumir que agora essa já é uma prática padrão no Yandex, que voa muito bem.
O que fizemos em termos de indicadores de produção? Agora, estamos realizando cerca de 3.000 casos de teste de regressão por dia (
nota: em outubro de 2018, já existem 7.000 casos ). As execuções de teste, dependendo do tamanho, levam de várias horas a (no pico) 2 dias. A maioria passa em poucas horas, dentro de um dia. A introdução desse sistema nos permitiu reduzir o custo em cerca de 30% em comparação com o período em que usamos a terceirização. Isso permitiu que as equipes lançassem com muito mais frequência, em média, várias vezes, porque os lançamentos começaram a passar na velocidade disponível para o desenvolvimento, em vez da disponível para teste, quando às vezes se tornava um gargalo.
Agora tentarei contar como geralmente construímos o processo de produção, o que nos permitiu chegar a esse esquema.
A infraestrutura
Vamos começar com a infraestrutura técnica. Aqueles de vocês que viram Toloka como uma plataforma, imaginam como é sua interface: você pode efetuar login no sistema, selecionar tarefas que lhe interessam e concluí-las. Para funcionários internos, temos uma instância interna da Toloka, na qual, entre outras coisas, distribuímos tarefas de vários tipos para nossos avaliadores.
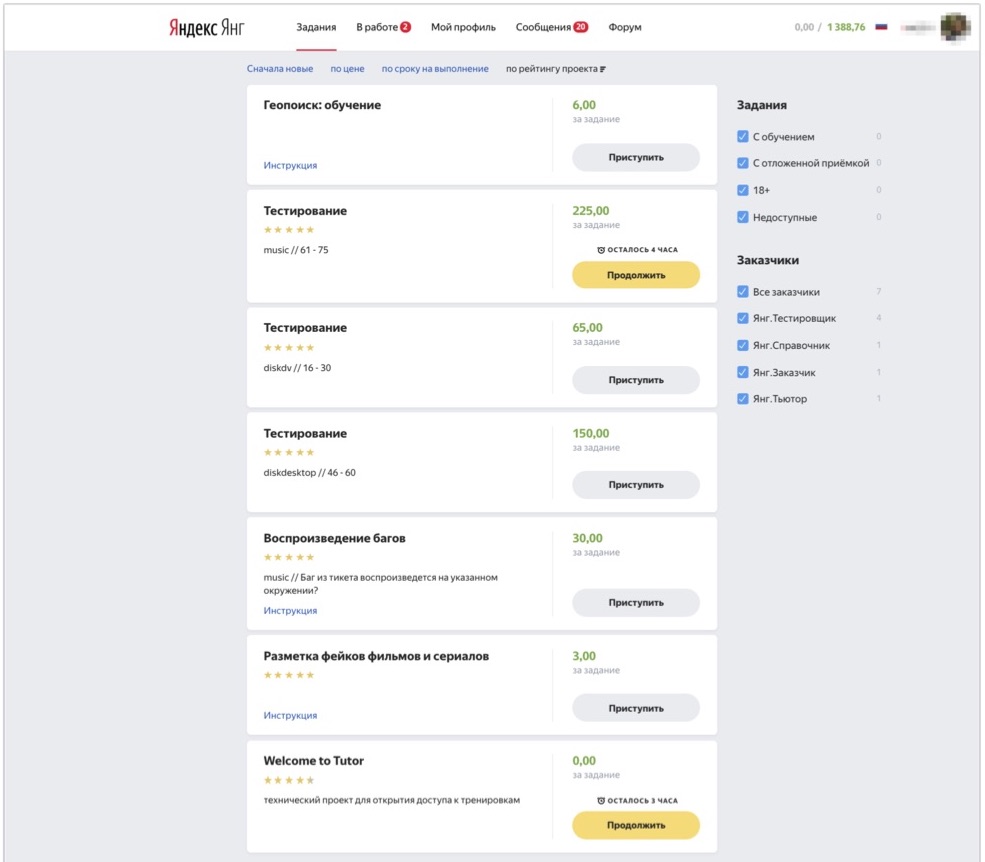
A imagem mostra como é essa interface. Aqui você pode ver as tarefas disponíveis para o avaliador: aqui existem várias tarefas para teste e várias tarefas de um tipo diferente, que o avaliador deste exemplo também sabe executar. E assim a pessoa vem, vê as tarefas disponíveis para ele no momento, clica em "Continuar", recebe casos de teste para análise e começa a executá-los.
Uma parte importante de nossa infraestrutura são as fazendas. Como nem todos os dispositivos estão disponíveis, a tarefa é, de fato, um par: um caso de teste e o ambiente em que você precisa verificá-lo. Quando uma pessoa clica no botão Continuar, o sistema verifica se há um ambiente no qual testar. Se houver, a pessoa simplesmente pega a tarefa e a testa em um dispositivo pessoal. Caso contrário, enviamos através do acesso remoto ao farm.
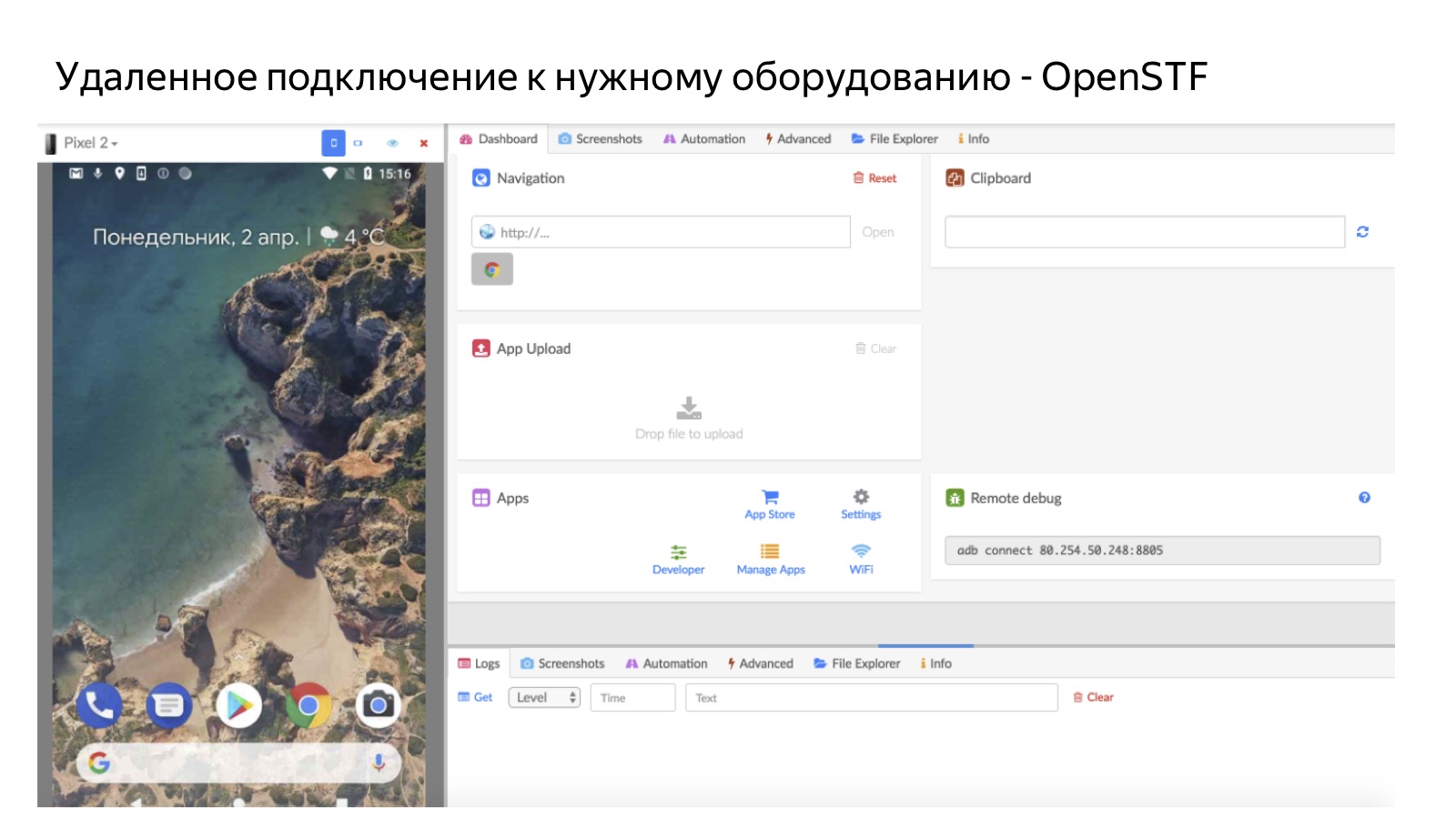
A imagem mostra como fica, usando o exemplo de um farm móvel. Portanto, uma pessoa se conecta remotamente a um telefone celular que fica em nosso escritório na fazenda. Para Android, usamos soluções de código aberto OpenSTF. Não há boas soluções para iOS - na medida em que já criamos nossas próprias (mas falaremos sobre isso em detalhes na próxima vez), porque não conseguimos encontrar código aberto ou algo que faria sentido comprar. É claro que o farm é útil nos casos em que não temos pessoas com os dispositivos certos.
E outra vantagem importante é que a fazenda possui uma taxa de utilização muito alta: sempre e independentemente da pessoa que entra, podemos enviá-la para a fazenda a qualquer momento. Isso é melhor do que distribuir dispositivos pessoalmente, porque os dispositivos que são entregues a uma pessoa só estão disponíveis para trabalho quando ela está pronta para funcionar.Conversamos um pouco sobre como foi implementado para nossos avaliadores do ponto de vista técnico, e agora a parte mais interessante para mim: os princípios de como organizamos essa produção.Os princípios de organização da produção na multidão
Para mim, neste projeto, foi interessante que a área de assunto pareça ser muito específica, mas todos os princípios de organização da produção são bastante universais: os mesmos que são usados na organização da produção em massa em outras áreas de assunto.1. Formalização
O primeiro princípio (não o mais importante, mas um dos mais importantes, um de nossos "baleias, elefantes e tartarugas") é a formalização de tarefas. Eu acho que todos vocês sabem disso por conta própria. Quase qualquer tarefa é mais fácil de se fazer. É um pouco mais difícil de explicar ao seu colega que está sentado ao seu lado na sala para que ele faça exatamente o que você precisa. E a tarefa é garantir que centenas de artistas que você nunca viu, que trabalham remotamente, a qualquer momento arbitrário, façam exatamente o que você espera deles - essa tarefa é várias ordens de magnitude mais complicada e envolve um limite bastante alto para entrar para começar a fazer isso. No contexto das tarefas de teste, a tarefa conosco, é claro, é um caso de teste que precisa ser aprovado e processado.E que casos de teste devem existir para poder usá-los em uma tarefa como teste de multidão?Em primeiro lugar - e acabou que isso não é fato - os casos de teste geralmente deveriam ser. Houve momentos em que as equipes vieram até nós que queriam se conectar aos testes pelos avaliadores, e dissemos: “Ótimo, traga seus casos de teste, nós os analisaremos!” Nesse momento, o cliente ficou triste, saiu, nem sempre voltou. Depois de vários apelos, percebemos que provavelmente preciso de ajuda neste local. Porque se um testador de uma equipe de algum serviço testa regularmente seus serviços, ele realmente não precisa de casos de teste completos e bem descritos. E se queremos delegar essa tarefa a um grande número de artistas, simplesmente não podemos prescindir dela.Mas mesmo nos casos em que havia casos de teste, eles quase sempre eram compreensíveis apenas para as pessoas que estão profundamente imersas no serviço. E todas as outras pessoas que estão fora de contexto, foi muito difícil entender o que está acontecendo aqui e o que precisa ser feito. Portanto, era importante revisar os casos de teste para que fossem compreensíveis para uma pessoa não imersa no contexto.E a última coisa: se reduzirmos a tarefa de teste a casos específicos estritamente formais, é muito importante garantir que esses casos sejam constantemente atualizados, atualizados e atualizados.Vou dar alguns exemplos.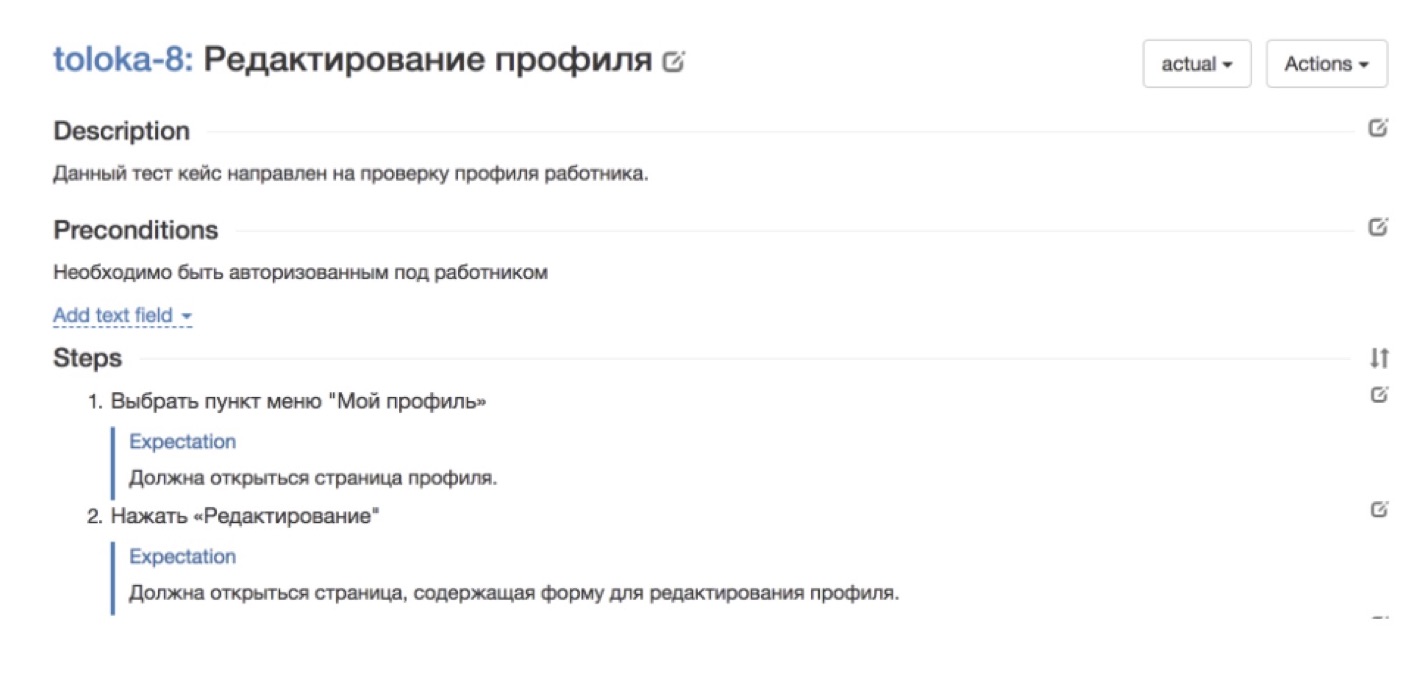 A imagem acima, por exemplo, mostra um bom exemplo do serviço Tolok nativo, no qual você precisa verificar a exatidão do perfil do artista. Tudo está dividido em etapas. Há todos os passos a serem dados. Há uma expectativa do que deve acontecer a cada passo. Tal caso ficará claro para qualquer um.
A imagem acima, por exemplo, mostra um bom exemplo do serviço Tolok nativo, no qual você precisa verificar a exatidão do perfil do artista. Tudo está dividido em etapas. Há todos os passos a serem dados. Há uma expectativa do que deve acontecer a cada passo. Tal caso ficará claro para qualquer um.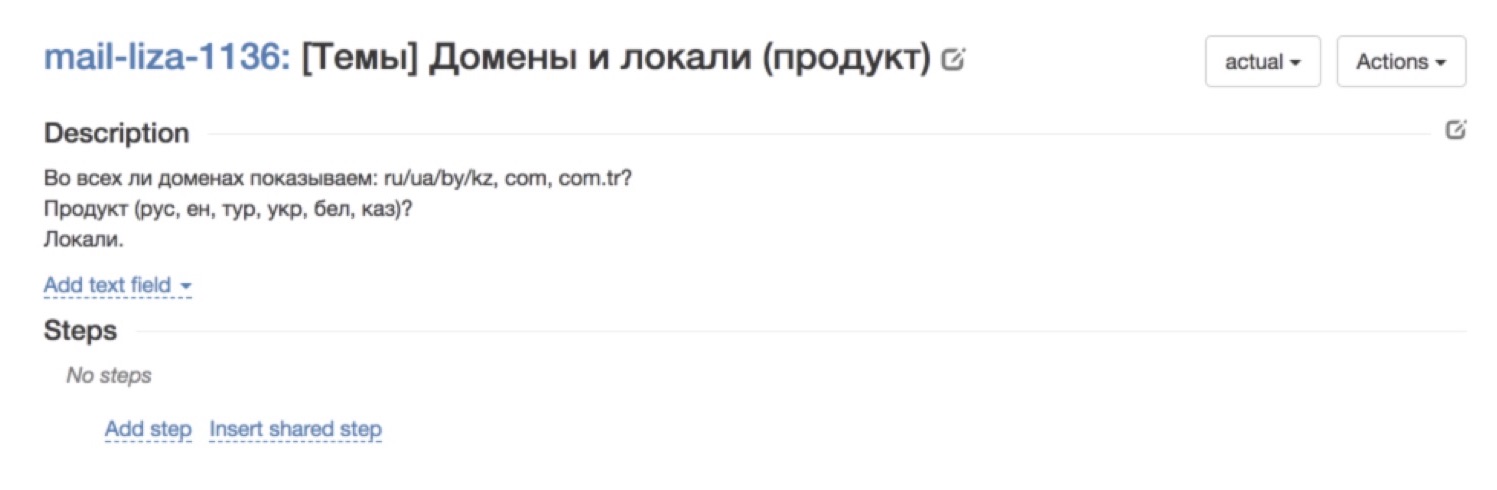 E aqui está um exemplo de um caso não tão bem-sucedido. Em geral, não está claro o que está acontecendo. A descrição parece estar lá, mas na realidade - o que é isso, o que você quer de mim? Casos desse tipo - não é imediato, eles passam muito mal.Como construímos o processo de formalização de casos de teste para que, em primeiro lugar, tínhamos todos eles, aparecessem e reabastecessem constantemente e, em segundo lugar, que fossem compreensíveis o suficiente para os avaliadores?Por tentativa e erro, chegamos a esse esquema:
E aqui está um exemplo de um caso não tão bem-sucedido. Em geral, não está claro o que está acontecendo. A descrição parece estar lá, mas na realidade - o que é isso, o que você quer de mim? Casos desse tipo - não é imediato, eles passam muito mal.Como construímos o processo de formalização de casos de teste para que, em primeiro lugar, tínhamos todos eles, aparecessem e reabastecessem constantemente e, em segundo lugar, que fossem compreensíveis o suficiente para os avaliadores?Por tentativa e erro, chegamos a esse esquema: Nosso cliente, ou seja, algum tipo de serviço ou equipe, vem e, de forma arbitrária e arbitrária, conveniente para ele, descreve os casos de teste de que ele precisa.Depois disso, nosso avaliador inteligente, que analisa esse texto formulado livremente e o traduz em casos de teste bem formalizados, bem formalizados e pintados em pequenos detalhes. Por que é importante que esse avaliador? Porque ele próprio estava no lugar daquelas pessoas que tomam casos de teste de áreas completamente diferentes e entende o quão detalhado o caso de teste deve ser para os colegas entenderem.Depois disso, executamos um caso: damos atribuições aos avaliadores e coletamos feedback. O processo é organizado para que, se uma pessoa não entender o que é necessário em um caso de teste, ela o ignore. Como regra, após a primeira vez, há uma porcentagem bastante grande de passes. De qualquer forma, não importa quão formalizamos os casos de teste no estágio anterior, nunca é impossível adivinhar o que será incompreensível para as pessoas. Portanto, a primeira execução é quase sempre uma versão de teste, suas funções mais importantes são coletar feedback. Depois de coletarmos o feedback, recebemos comentários dos avaliadores, aprendemos o que eles entendiam e o que não era, reescrevemos, anexamos os casos de teste mais uma vez. Depois de algumas iterações, obtemos casos de teste legais e bem claramente formulados, compreensíveis para todos.Essa arrumação tem um efeito colateral interessante. Em primeiro lugar, descobriu-se que, para tantas equipes, esse é geralmente um recurso matador. Todo mundo vem até nós e diz: "Você pode realmente escrever casos de teste para mim?" Essa é a coisa mais importante que atraímos nossos clientes. O segundo efeito, inesperado para mim - a ordem nos casos de teste tem outros efeitos pendentes. Por exemplo, temos escritores técnicos que escrevem a documentação do usuário, e escrever com base nesses casos de teste bem projetados e compreensíveis é muito mais fácil para eles. Antes, eles precisavam distrair o serviço para descobrir o que precisava ser descrito, mas agora podemos usar nossos casos de teste claros e interessantes.Eu darei um exemplo
Nosso cliente, ou seja, algum tipo de serviço ou equipe, vem e, de forma arbitrária e arbitrária, conveniente para ele, descreve os casos de teste de que ele precisa.Depois disso, nosso avaliador inteligente, que analisa esse texto formulado livremente e o traduz em casos de teste bem formalizados, bem formalizados e pintados em pequenos detalhes. Por que é importante que esse avaliador? Porque ele próprio estava no lugar daquelas pessoas que tomam casos de teste de áreas completamente diferentes e entende o quão detalhado o caso de teste deve ser para os colegas entenderem.Depois disso, executamos um caso: damos atribuições aos avaliadores e coletamos feedback. O processo é organizado para que, se uma pessoa não entender o que é necessário em um caso de teste, ela o ignore. Como regra, após a primeira vez, há uma porcentagem bastante grande de passes. De qualquer forma, não importa quão formalizamos os casos de teste no estágio anterior, nunca é impossível adivinhar o que será incompreensível para as pessoas. Portanto, a primeira execução é quase sempre uma versão de teste, suas funções mais importantes são coletar feedback. Depois de coletarmos o feedback, recebemos comentários dos avaliadores, aprendemos o que eles entendiam e o que não era, reescrevemos, anexamos os casos de teste mais uma vez. Depois de algumas iterações, obtemos casos de teste legais e bem claramente formulados, compreensíveis para todos.Essa arrumação tem um efeito colateral interessante. Em primeiro lugar, descobriu-se que, para tantas equipes, esse é geralmente um recurso matador. Todo mundo vem até nós e diz: "Você pode realmente escrever casos de teste para mim?" Essa é a coisa mais importante que atraímos nossos clientes. O segundo efeito, inesperado para mim - a ordem nos casos de teste tem outros efeitos pendentes. Por exemplo, temos escritores técnicos que escrevem a documentação do usuário, e escrever com base nesses casos de teste bem projetados e compreensíveis é muito mais fácil para eles. Antes, eles precisavam distrair o serviço para descobrir o que precisava ser descrito, mas agora podemos usar nossos casos de teste claros e interessantes.Eu darei um exemplo É assim que o caso de teste era antes de passar pelo nosso moedor de carne: é muito escasso, o campo de descrição não é preenchido, diz "bem, olhe a captura de tela no aplicativo" e é isso.
É assim que o caso de teste era antes de passar pelo nosso moedor de carne: é muito escasso, o campo de descrição não é preenchido, diz "bem, olhe a captura de tela no aplicativo" e é isso.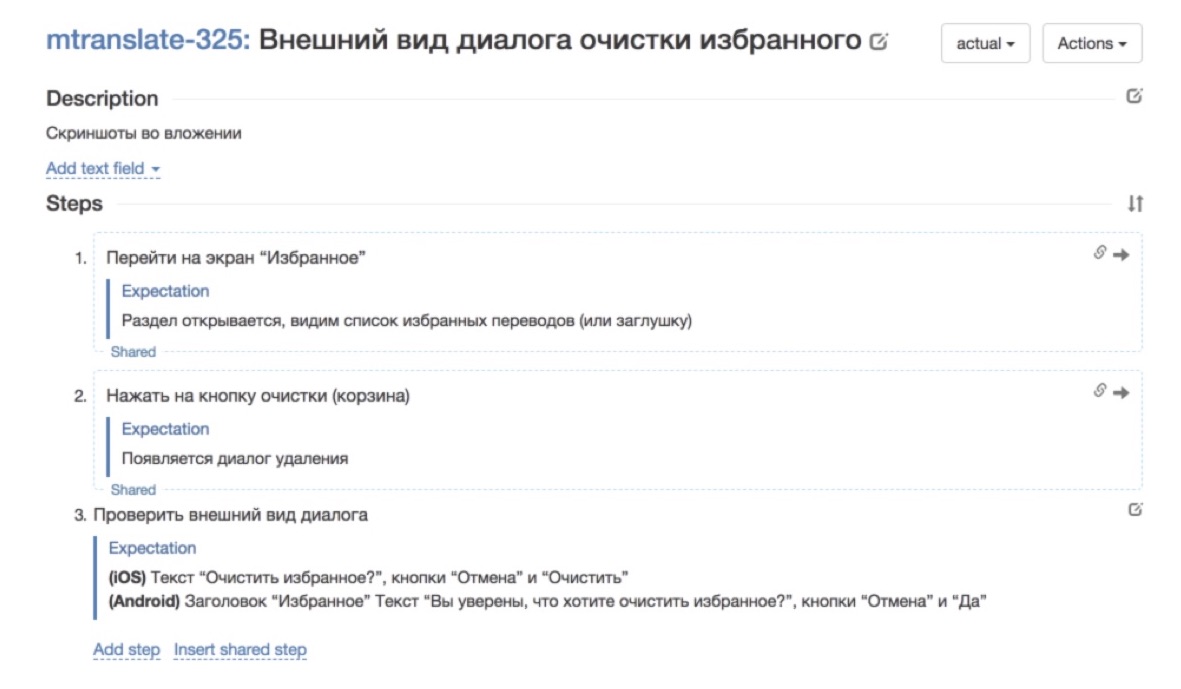 Foi assim que ele começou a cuidar da reescrita - etapas e expectativas adicionadas a cada etapa. Muito melhor já. É muito mais agradável trabalhar com esse caso de teste.
Foi assim que ele começou a cuidar da reescrita - etapas e expectativas adicionadas a cada etapa. Muito melhor já. É muito mais agradável trabalhar com esse caso de teste.2. Aprendizado Escalável
A próxima tarefa é a minha favorita, a mais, me parece, criativa em tudo isso. Esta é uma tarefa de aprendizado escalável. Para operarmos com esses números - "aqui temos 200 assessores, aqui estão 1.000 e aqui geralmente 17.000 trabalhadores trabalham todos os dias" - é importante poder treinar pessoas de maneira rápida e escalável.
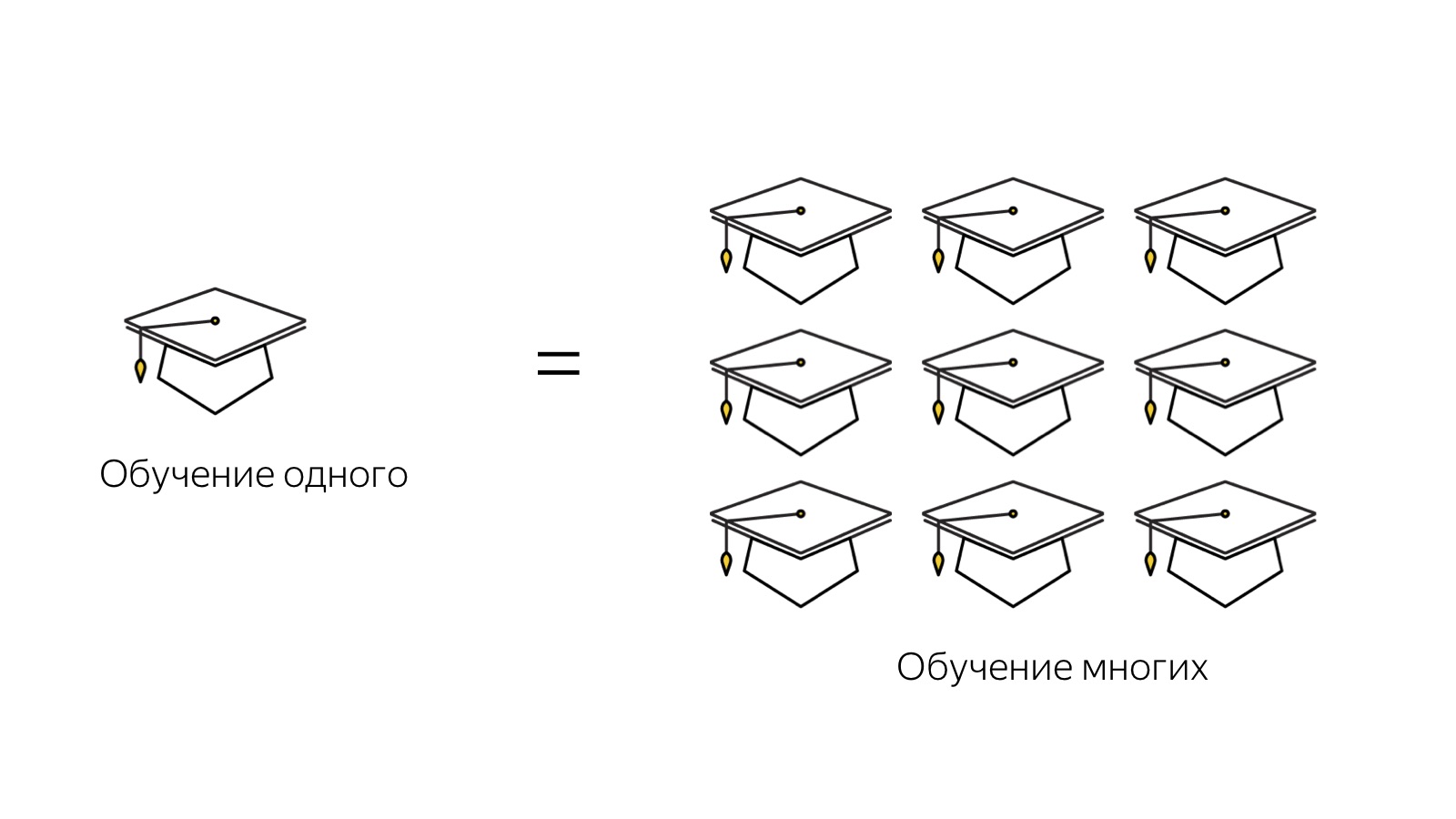
É muito importante chegar a esse sistema quando você não passa mais tempo treinando um número arbitrário de pessoas do que treinando um especialista específico. Por exemplo, foi o que encontramos ao trabalhar com terceirização. Os especialistas são muito legais, mas para mergulhá-los no contexto do trabalho, o serviço levou muito tempo e, na saída, ainda temos uma pessoa que está imersa no contexto por seis meses. E este é um esquema tão escalável. Acontece que cada pessoa seguinte precisa ficar imersa no contexto da tarefa por mais seis meses. E foi necessário expandir esse gargalo.
Para todas as vagas em massa, não apenas nos testes, recrutamos pessoas através de vários canais. Para testes, fazemos isso. Em primeiro lugar, atraímos pessoas que, em princípio, estão interessadas em testar tarefas, caras em algum nível do nível de iniciantes, para eles, este é um bom começo, imersão na área de assunto. Mas ainda existe um número limitado de pessoas no mercado, e precisamos que não tenhamos restrições à contratação de pessoas, para nunca descansarmos no número de artistas.
Portanto, além de encontrar testadores especificamente para essas tarefas, realizamos um conjunto de pessoas que simplesmente responderam à posição geral do avaliador. Estamos promovendo essa abordagem: não importa quais pessoas você adquira, se houver muitas delas, é possível criar um processo para selecionar as mais capazes delas e direcioná-las para resolver o problema que você está perseguindo. No contexto dos testes, construímos treinamento para que pessoas arbitrárias que nem sabiam nada sobre o teste ensinassem pelo menos o básico mínimo para começar a entender alguma coisa. Graças a essa abordagem, nunca encontramos uma falta de artistas e o número de pessoas que trabalham para nós nessas tarefas, tudo se resume à questão de quanto dinheiro estamos dispostos a gastar nela.
Não sei com que frequência você se depara com esse tópico, mas em todos os tipos de artigos científicos populares, especialmente sobre aprendizado de máquina e redes neurais, geralmente está escrito que o aprendizado de máquina é muito semelhante ao treinamento humano. Mostramos à criança 10 cartas com a imagem da bola e, pela 11ª vez, ela entenderá e dirá: “Oh! Isso é uma bola! De fato, a visão computacional e qualquer outra tecnologia de aprendizado de máquina também funcionam em essência.
Quero falar sobre a situação oposta: o treinamento de pessoas pode ser construído da mesma maneira formal que o treinamento de máquinas. Do que precisamos para isso? Precisamos de um conjunto de treinamento - um conjunto de exemplos pré-marcados nos quais uma pessoa será treinada. Precisamos de um conjunto de controle, no qual possamos verificar se ele estudou bem ou não. Como no aprendizado de máquina, você precisa de um conjunto de testes no qual entendemos como nossa função geralmente funciona. E precisamos de uma métrica formal que meça a qualidade do trabalho realizado. É sobre esses princípios que construímos treinamento nas tarefas dos testes de regressão mais simples.
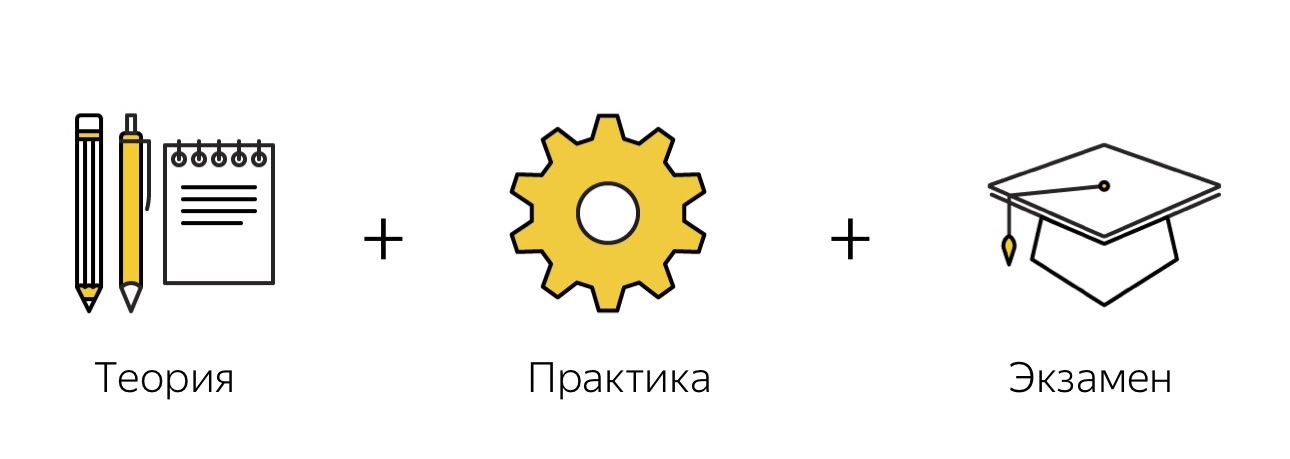
A imagem mostra como esse treinamento se parece conosco. Consiste em várias partes. Primeiro, existe uma teoria, depois a prática e, em seguida, um exame, no qual verificamos se uma pessoa entendeu a essência do problema ou não.
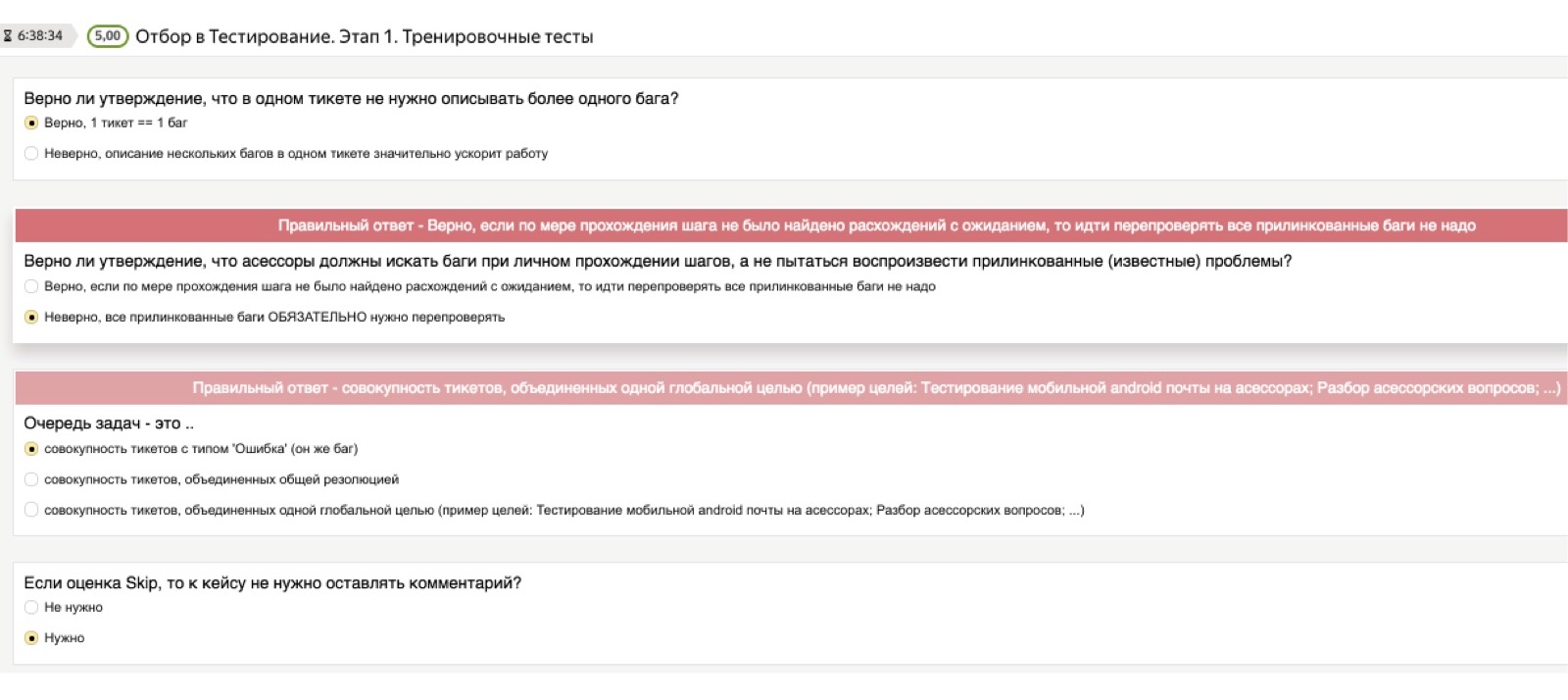
Vamos começar com a teoria. É claro que, para qualquer tarefa que o avaliador realiza, temos uma instrução grande, pesada e de pleno direito, com um grande número de exemplos, onde tudo é descrito em detalhes. Mas ninguém lê.
Portanto, para verificar se o conhecimento teórico realmente se estabeleceu na cabeça de uma pessoa, sempre damos acesso a instruções, mas depois usamos o que chamamos condicionalmente de "teste teórico". Esse é um teste, no qual pré-carregamos perguntas importantes para nós e as respostas corretas. As perguntas podem ser as mais estúpidas. Penso que, para você, serão exemplos cômicos, mas para as pessoas que enfrentam tarefas de teste pela primeira vez em suas vidas, essas não são coisas absolutamente óbvias. Por exemplo: "Se eu encontrei vários bugs, preciso iniciar vários tickets - um para cada bug - ou despejar tudo em uma pilha?" Ou: "E se eu quiser tirar uma captura de tela, mas a imagem não funcionar para mim?"
Podem ser questões muito diferentes, arbitrariamente de nível inferior, e é importante para nós que uma pessoa as trabalhe de forma independente na fase de estudo da teoria. Portanto, o teste teórico consiste em perguntas desse tipo: “Encontrei vários bugs, devo ter um ticket ou vários?” Se uma pessoa escolhe a resposta errada, cai um dado vermelho que diz: "Não, espere, a resposta certa é diferente, preste atenção nela". Mesmo se uma pessoa não leu as instruções, ela não pode passar neste teste.

O próximo ponto é a prática. Como garantir que as pessoas que não sabiam nada sobre o teste e não respondessem especificamente à vaga do testador entendessem o que deveria ser feito a seguir? Aqui chegamos a esse conjunto de treinamento. Eu acho que você encontrará imediatamente um grande número de bugs que estão nesta imagem. É assim que a tarefa de treinamento do avaliador é exibida: aqui está uma captura de tela à sua frente, encontre todos os erros nela. O que há de errado aqui? A calculadora está saindo. O que mais? Layout foi.

Ou aqui está um exemplo mais complexo, com um asterisco. A caixa de correio do destinatário principal está aberta. Fui eu quem enviou esta carta. Então eu vejo uma foto assim na minha frente. Qual é o erro aqui? O maior problema aqui é que uma cópia oculta é exibida e, como destinatário da carta, vejo quem era a cópia oculta.
Depois de passar algumas dezenas de exemplos, mesmo uma pessoa que está infinitamente longe de testar, já começa a entender o que é e o que é exigido dele mais ao passar nos casos de teste. A parte prática é um conjunto de exemplos em que já conhecemos bugs; pedimos à pessoa para encontrá-los e, no final, mostramos a ele: “Veja, o bug estava aqui”, para que ele correlacione suas suposições com nossas respostas corretas.
E a última parte é o que chamamos de exame. Temos uma montagem de teste especial, cujos bugs já são conhecidos por nós, e pedimos à pessoa para passar por ela. Aqui, não mostramos mais as respostas corretas e incorretas, mas apenas olhe o que ele conseguiu encontrar.
A beleza desse sistema e sua escalabilidade estão no fato de que todos esses processos ocorrem de maneira absolutamente autônoma, sem a participação de um gerente. Executamos quantas pessoas você quiser: todo mundo que quiser ler as instruções, todo mundo que quiser fazer o teste teórico, todo mundo que quiser fazer a prática - tudo isso acontece automaticamente com o toque de um botão e não temos nenhuma preocupação.
A última parte - o exame - também é aprovada por todos que desejam e, finalmente, começamos a examiná-los cuidadosamente. Como este é um conjunto de teste e conhecemos todos os seus bugs antecipadamente, podemos determinar automaticamente qual a porcentagem de bugs que uma pessoa encontrou. Se estiver muito baixo, não procuramos mais, escrevemos uma batida automática: "Muito obrigado por seus esforços!" - e não dê a essa pessoa acesso a missões de combate. Se percebermos que quase todos os bugs foram encontrados, nesse momento uma pessoa já está se conectando e olhando como os tickets são emitidos corretamente, o quanto tudo é feito corretamente de acordo com o procedimento, do ponto de vista de nossas instruções.
Se percebermos que uma pessoa dominou independentemente a teoria e a prática e passou bem no exame, deixamos essas pessoas entrar em nossos processos de produção. Esse esquema é bom, pois não depende de quantas pessoas passamos por ele. Se precisarmos de mais pessoas, apenas inundaremos mais pessoas na entrada e obteremos mais na saída.
Este é um sistema interessante, mas, é claro, seria ingênuo acreditar que, depois disso, você já poderá ter um testador pronto. Até os caras que concluíram nosso treinamento com êxito têm muitas perguntas que precisam ajudar rapidamente. E aqui estamos diante de muitos problemas inesperados para nós.
As pessoas fazem muitas perguntas. Além disso, essas perguntas podem ser tão estranhas que você nunca teria pensado em sua vida que as respostas a essas perguntas deveriam ser adicionadas às instruções, descritas em um teste ou algo parecido. Se você pensar bem, esta é uma situação normal. É improvável que cada um de nós, quando nos encontramos em uma área desconhecida, faça uma pergunta que pareça tola para um especialista.
Aqui a situação é agravada pelo fato de termos várias centenas dessas pessoas, e mesmo que cada um de nós pergunte a uma pessoa específica, a probabilidade de fazer uma pergunta estúpida é baixa, no total ocorre: “Ahhh! Oh deus O que está havendo? Isso nos domina! ”
Às vezes as perguntas parecem estranhas. Por exemplo, uma pessoa escreve: "Eu não entendo o que significa" tocar em Desfazer "". Eles dizem para ele: “Amigo! É o mesmo que clicar no botão "Cancelar". " Ele: “Oh! Obrigada Agora eu entendo tudo.
Ou outra pessoa diz: "Tudo parece estar bem, mas algo está um pouco quebrado, não consigo entender se isso é um erro ou não". Mas depois de um minuto, ele próprio entende onde entrou na tarefa de teste; provavelmente uma foto quebrada não é muito normal. Aqui ele entendeu, e tudo bem.
Ou aqui está um exemplo interessante que realmente nos mergulhou no abismo da pesquisa por um longo tempo. Um homem vem e diz:

Todo mundo não entende o que está acontecendo, de onde ele vem - tentamos tanto, descrevemos casos de teste - até descobrirmos que ele tem uma extensão especial de navegador que se traduz do russo para o inglês e depois do inglês para o russo , e no final temos uma heresia.
De fato, existem muitas dessas perguntas, o estudo de cada uma delas leva algum tempo diferente de zero. E, em algum momento, nossos clientes - os serviços da equipe Yandex que usavam testes por avaliadores - começaram a arrancar os cabelos e dizer: “Escute, gastaríamos muito menos tempo se testássemos tudo isso do que sentar nessas salas de bate-papo e responder a essas perguntas estranhas. ”
Portanto, chegamos a um sistema de bate-papo em dois níveis. Há uma inundação condicional, na qual nossos avaliadores se comunicam com seus curadores, esses “caras de chapéu” - 90% dos problemas são resolvidos aqui. E apenas os problemas mais importantes e complexos são encaminhados para um bate-papo dedicado, no qual a equipe de serviço fica. Isso facilitou muito a vida de todas as equipes, todos suspiraram com calma.
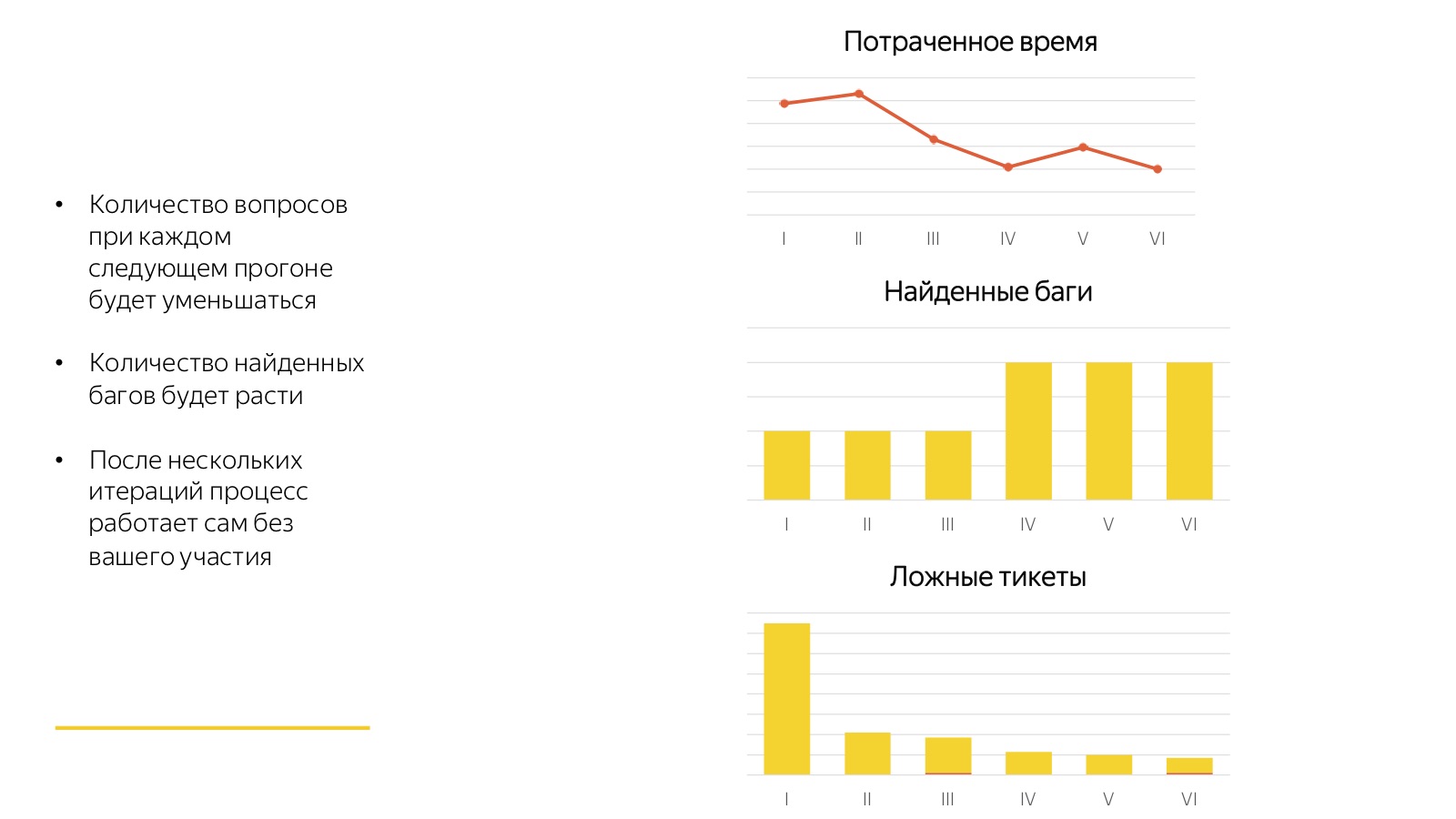
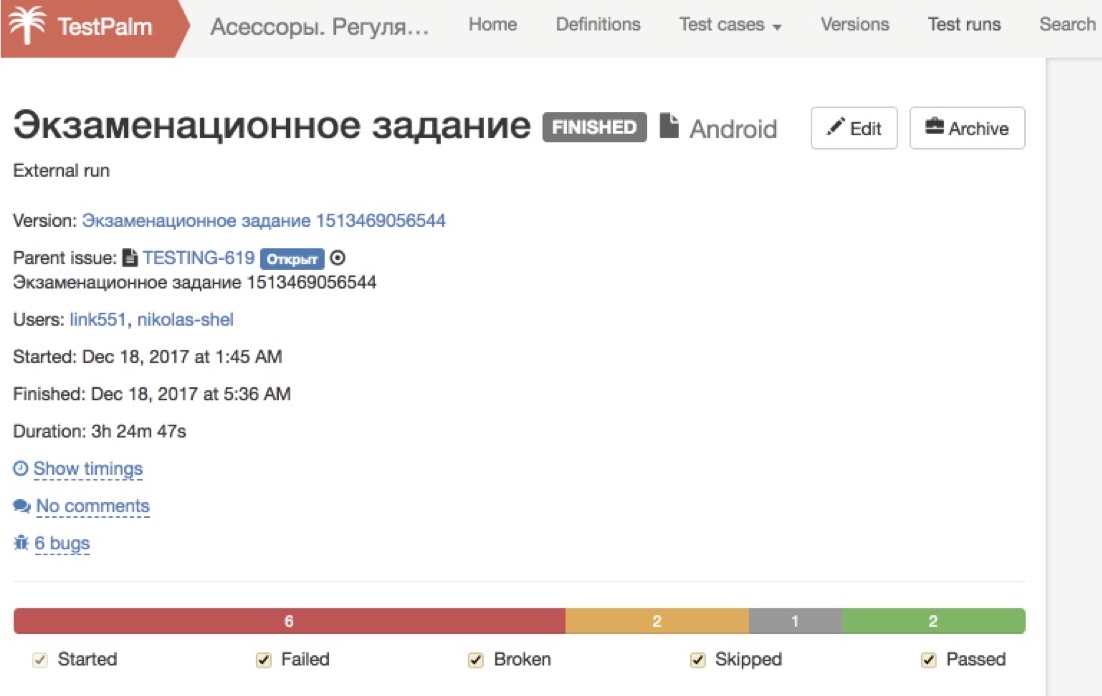
Esses horrores de que estou falando não são tão terríveis. A boa notícia é que todos esses processos convergem muito rapidamente. Qualquer primeiro lançamento é sempre muito ruim. Na figura acima, 6 partidas consecutivas da mesma regressão são visíveis.
Veja quanto tempo os funcionários gastaram em responder perguntas, pela primeira vez quando os avaliadores não entenderam o que estavam falando e o que queriam deles. Eles encontraram poucos bugs, começaram muitos tickets sobre nada. Portanto, a primeira vez é horror-horror-horror, a segunda vez é horror-horror e, pela terceira vez, 80% de todos os processos convergem. E então vem o processo elaborado: os avaliadores se acostumam à nova tarefa e, após cada lançamento, coletamos feedback, complementamos os casos de teste e resolvemos algo. E é uma fábrica bacana que funciona com o clique de um botão e não requer nenhum envolvimento de um especialista em período integral.
3. controle de qualidade
Um ponto muito importante, sem o qual tudo isso não funcionará, é o controle de qualidade.
Nossos avaliadores trabalham com salários por peça: todas as suas tarefas são claramente reguladas e quantificadas, cada unidade de trabalho tem sua própria tarifa padrão e recebe pagamento pelo número de unidades concluídas. Toloka funciona exatamente da mesma maneira, e em geral qualquer multidão. Este sistema tem muitas vantagens, é muito flexível, mas também tem suas desvantagens. Em um sistema com pagamento por peça, qualquer contratado tentará otimizar seu trabalho - gaste o mínimo de tempo e esforço possível na tarefa para obter muito mais dinheiro por unidade de tempo. Portanto, é garantido que qualquer sistema construído com crowdsourcing funcione com a qualidade mínima que você permitir. Se você não tiver controle sobre a qualidade, ela cairá o mais baixo possível.
A boa notícia é que você pode lutar contra isso, pode ser controlado. Se pudermos quantificar a qualidade do trabalho, a tarefa se resume a uma tarefa bastante simples. Isso está na teoria. Na prática, não é tão simples, especialmente em tarefas de teste. Porque o teste, ao contrário de muitas outras tarefas em massa que resolvemos com a ajuda de avaliadores, lida com eventos raros e todo tipo de estatística funciona muito mal lá. É muito difícil entender com que frequência uma pessoa realmente encontra bugs, se em princípio há muito poucos bugs. Portanto, temos que perverter e usar vários métodos de controle de qualidade de uma só vez, que juntos nos darão uma certa imagem de com qual qualidade o artista trabalha.
O primeiro é uma verificação na sobreposição. "Sobreposição" significa que atribuímos cada tarefa a várias pessoas. Fazemos isso naturalmente, porque cada caso de teste precisa ser testado em vários ambientes. Assim, verifica-se que o mesmo caso de teste foi verificado nos ambientes A, B e C. Temos três resultados de três pessoas - passando no mesmo caso de teste. Depois, analisamos se os resultados divergiram.
Às vezes acontece que um bug foi encontrado em um ambiente, mas não em outros dois. Talvez seja realmente, ou talvez o erro de alguém: uma pessoa encontrou um bug extra ou as duas trapacearam e não encontraram algo. De qualquer forma, este é um caso suspeito. Se encontrarmos isso, enviaremos uma nova verificação adicional para garantir e verificar quem estava certo e quem era o culpado. Esse esquema nos permite capturar pessoas que, por exemplo, iniciaram tickets extras onde não eram necessários ou perderam onde eram necessários. Ao mesmo tempo, examinamos como o ticket foi aberto corretamente, se tudo está de acordo com o procedimento: são adicionadas capturas de tela, se necessário, uma descrição clara adicionada e assim por diante.
Além disso - e especialmente isso diz respeito apenas à correção da emissão de bilhetes -, é bom e conveniente controlar automaticamente algumas coisas que, por um lado, parecem insignificantes, mas, por outro lado, afetam fortemente o fluxo de trabalho. Portanto, verificamos automaticamente se existe um aplicativo no ticket, se são adicionadas capturas de tela, se há comentários no ticket ou se ele foi simplesmente fechado sem verificar quanto tempo foi gasto com ele para identificar casos suspeitos. Aqui você pode criar muitas heurísticas diferentes e aplicá-las. O processo é quase infinito.
Verificar a sobreposição é uma coisa boa, mas fornece uma avaliação um tanto tendenciosa, porque apenas verificamos casos controversos. Às vezes, você deseja fazer uma verificação honesta no local. Para fazer isso, usamos execuções de teste. Na fase de treinamento, montamos assembléias de teste especialmente nas quais sabemos com antecedência onde há bugs e onde não. Usamos lançamentos semelhantes para controle de qualidade e verificamos quantos bugs uma pessoa encontrou e quantos erraram. Essa é uma maneira legal, fornece a imagem mais completa do mundo. Mas é muito caro usar: enquanto ainda coletamos um novo conjunto de teste ... Usamos essa abordagem muito raramente, a cada poucos meses.
O último ponto importante: mesmo que já tenhamos feito tudo, devemos definitivamente analisar por que os bugs foram ignorados. Verificamos se foi possível encontrar esse bug seguindo as etapas do caso de teste. Se possível, mas a pessoa errou, então, a pessoa é uma caneca e você precisa ter algum efeito nela. E se esse caso não estava lá, você precisa complementar de alguma forma, atualizar os casos de teste.
Como resultado, reduzimos todas as métricas de qualidade em uma única classificação de avaliadores, o que afeta sua carreira e destino em nosso sistema. Quanto maior a classificação de uma pessoa, mais ela recebe tarefas e reivindicações de prêmios mais difíceis. Quanto menor a classificação do avaliador, maior a probabilidade de ser demitido. Quando uma pessoa trabalha de forma estável com uma classificação baixa, acabamos por nos separar dela.
4. Delegação
O último dos pilares do nosso esquema piramidal escalável sobre o qual quero falar são as tarefas de delegação.
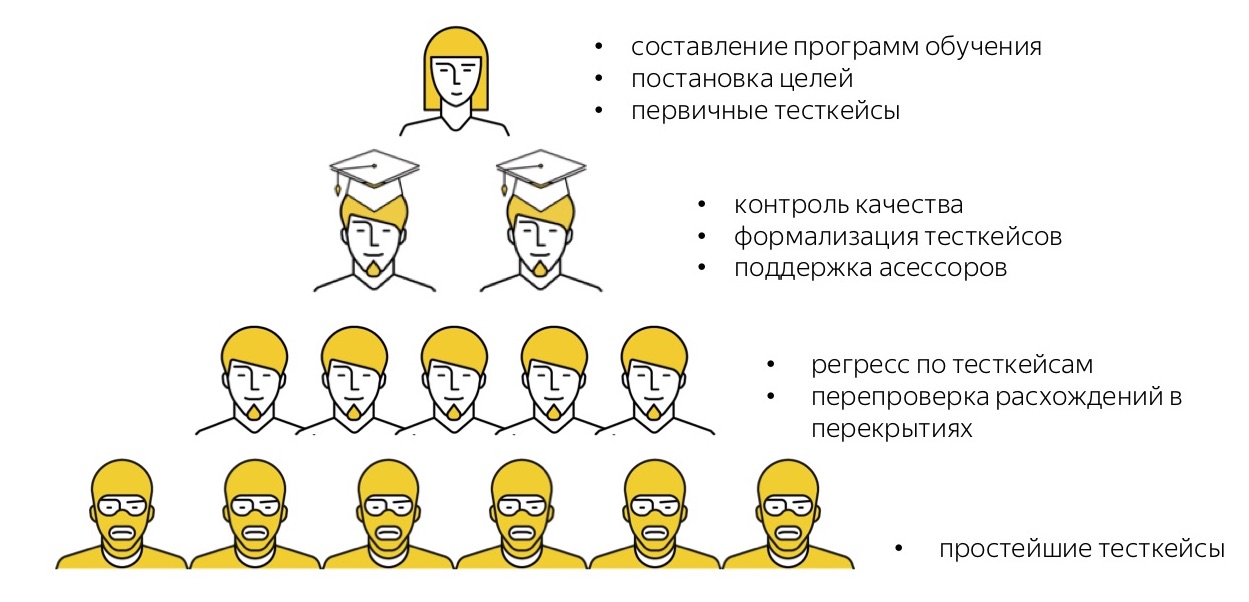
Lembrarei mais uma vez como nossa pirâmide se parece com tarefas de teste manuais. Temos pessoas de "alto nível" - são testadores em tempo integral, representantes da equipe de serviço que compõem programas de treinamento para o serviço que precisam testar, formam uma estratégia para o que precisa ser testado, escrevem casos de teste primários de forma livre.
Além disso, temos os avaliadores mais talentosos que transferem os casos de teste de forma livre para os formalizados, ajudam outros avaliadores, os apoiam em salas de bate-papo e realizam verificações cruzadas e controle de qualidade seletivo.
Além disso, há uma nuvem de muitos artistas que realizam regressão passo a passo.
Em seguida, temos Toloka, sobre o qual não esquecemos. Agora estamos no estágio de experimentos: entendemos que os casos mais simples podem ser dados para testes a uma multidão impessoal em Toloka.
Vai ser muito mais barato e mais rápido, porque há ainda mais artistas por lá. Mas enquanto estamos no processo de construção deste sistema. Agora damos apenas o mais simples, mas espero que daqui a alguns meses cheguemos ao fato de delegarmos mais lá. É muito importante monitorar o desenvolvimento adequado dessa pirâmide. Em primeiro lugar (essas perguntas costumam ser feitas para mim, portanto, desejo respondê-las de maneira proativa), o crowdsourcing não é uma rejeição do trabalho de especialistas de alto nível em favor das multidões, mas uma ferramenta de dimensionamento. Não podemos recusar o topo desta pirâmide, nossa "cabeça", só podemos usar o crowdsourcing para adicionar mais mãos a esse sistema, por isso é realmente muito fácil escalá-lo gratuitamente.Em segundo lugar, isso não é ciência do foguete, mas você precisa se lembrar constantemente disso: a história toda funciona bem e corretamente se as tarefas mais difíceis para esse nível forem resolvidas em cada nível. Grosso modo, se a mesma coisa pode ser feita em vários níveis da pirâmide, isso deve ser feito no nível mais baixo. Esta não é uma história estática, mas dinâmica. Começamos com o fato de que apenas pessoas de "alto nível" podem executar algumas tarefas, refinar gradualmente o processo e reduzi-las abaixo, dimensionando e barateando todo o processo.E muitas vezes ouço um comentário assim: "Por que se preocupar com esse jardim, é melhor automatizar tudo e gastar energia nele"? Mas o crowdsourcing não substitui a automação, é uma coisa paralela. Fazemos isso não em vez de automação, mas além disso. Esse sistema apenas permite liberar trabalhadores que possam estar envolvidos na automação, por um lado, e, por outro lado, formalizar o processo muito bem, o que será muito mais fácil de automatizar.
É muito importante monitorar o desenvolvimento adequado dessa pirâmide. Em primeiro lugar (essas perguntas costumam ser feitas para mim, portanto, desejo respondê-las de maneira proativa), o crowdsourcing não é uma rejeição do trabalho de especialistas de alto nível em favor das multidões, mas uma ferramenta de dimensionamento. Não podemos recusar o topo desta pirâmide, nossa "cabeça", só podemos usar o crowdsourcing para adicionar mais mãos a esse sistema, por isso é realmente muito fácil escalá-lo gratuitamente.Em segundo lugar, isso não é ciência do foguete, mas você precisa se lembrar constantemente disso: a história toda funciona bem e corretamente se as tarefas mais difíceis para esse nível forem resolvidas em cada nível. Grosso modo, se a mesma coisa pode ser feita em vários níveis da pirâmide, isso deve ser feito no nível mais baixo. Esta não é uma história estática, mas dinâmica. Começamos com o fato de que apenas pessoas de "alto nível" podem executar algumas tarefas, refinar gradualmente o processo e reduzi-las abaixo, dimensionando e barateando todo o processo.E muitas vezes ouço um comentário assim: "Por que se preocupar com esse jardim, é melhor automatizar tudo e gastar energia nele"? Mas o crowdsourcing não substitui a automação, é uma coisa paralela. Fazemos isso não em vez de automação, mas além disso. Esse sistema apenas permite liberar trabalhadores que possam estar envolvidos na automação, por um lado, e, por outro lado, formalizar o processo muito bem, o que será muito mais fácil de automatizar.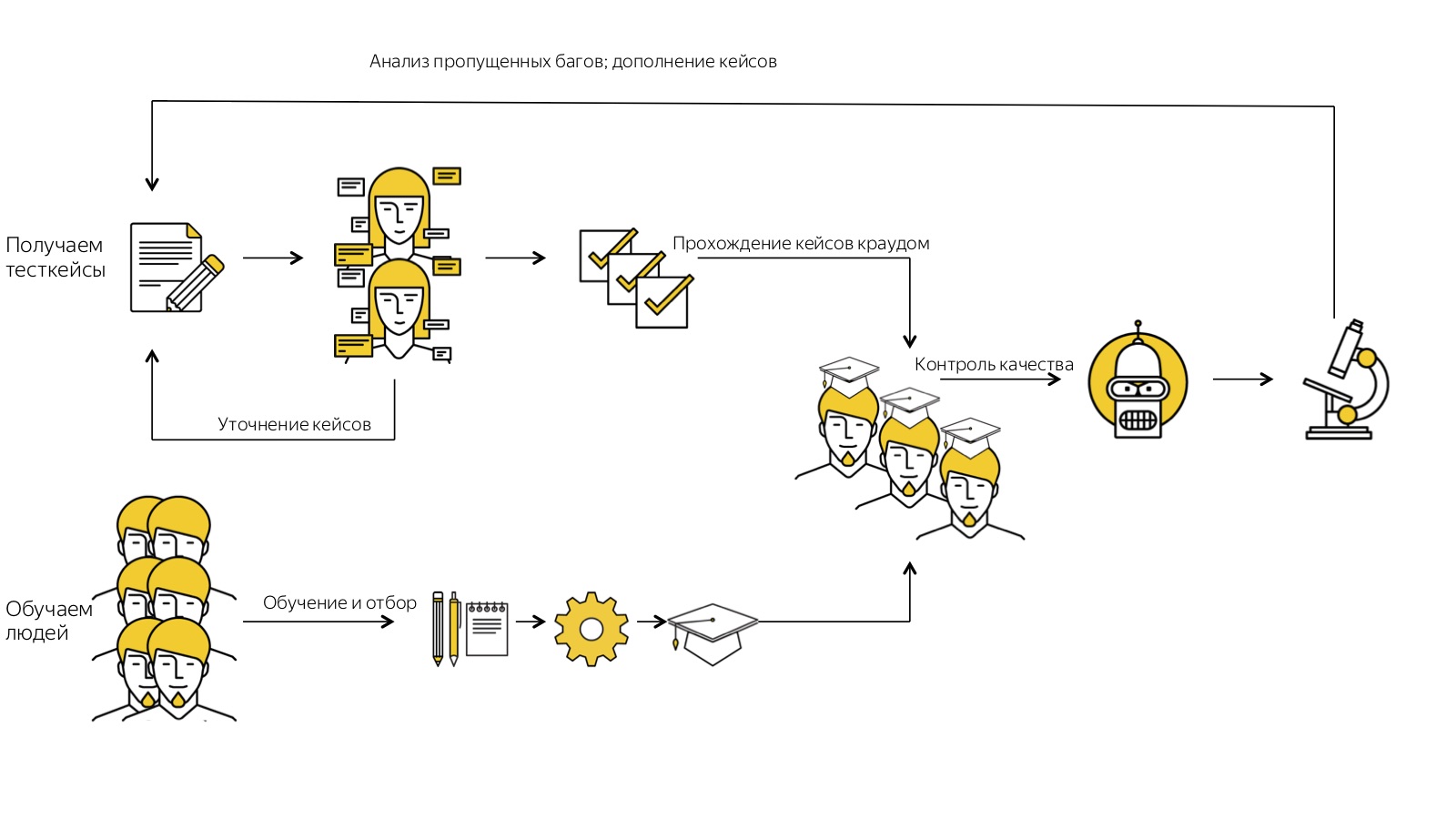 No final, lembrarei mais uma vez como toda a nossa história se parece. Começamos obtendo casos de teste de forma livre. Nós os executamos várias vezes através de avaliadores, coletamos feedback e os especificamos. Depois disso, ficamos legais, já lambemos os casos de teste. Paralelamente, recrutamos muitas, muitas pessoas, colocamo-las no sistema de treinamento automático e, na saída, temos apenas aqueles que foram capazes de lidar com todas as etapas por conta própria e percebemos o que queríamos dele. Temos uma multidão treinada. Ele trabalha com casos de teste formalizados para nós e controlamos sua qualidade: verificamos constantemente, analisamos casos com erros perdidos para melhorar nossos processos.E esse sistema funciona para nós, voa. Não sei se minha história será útil agora para alguém do ponto de vista prático, mas espero que isso nos permita pensar um pouco mais amplamente e assumir que algumas tarefas podem ser resolvidas dessa maneira. Porque - e muitas vezes nos deparamos com isso - um de vocês já pode se pensar pensando: “Bem, talvez isso funcione em algum lugar, mas definitivamente não é para mim. Eu tenho tarefas tão difíceis que não é sobre mim. ” Porém, nossa experiência sugere que praticamente todas as tarefas de praticamente qualquer área, se forem decompostas corretamente, formalizadas e incorporadas a um processo claro, podem ser dimensionadas pelo menos parcialmente com a ajuda de multidões.
No final, lembrarei mais uma vez como toda a nossa história se parece. Começamos obtendo casos de teste de forma livre. Nós os executamos várias vezes através de avaliadores, coletamos feedback e os especificamos. Depois disso, ficamos legais, já lambemos os casos de teste. Paralelamente, recrutamos muitas, muitas pessoas, colocamo-las no sistema de treinamento automático e, na saída, temos apenas aqueles que foram capazes de lidar com todas as etapas por conta própria e percebemos o que queríamos dele. Temos uma multidão treinada. Ele trabalha com casos de teste formalizados para nós e controlamos sua qualidade: verificamos constantemente, analisamos casos com erros perdidos para melhorar nossos processos.E esse sistema funciona para nós, voa. Não sei se minha história será útil agora para alguém do ponto de vista prático, mas espero que isso nos permita pensar um pouco mais amplamente e assumir que algumas tarefas podem ser resolvidas dessa maneira. Porque - e muitas vezes nos deparamos com isso - um de vocês já pode se pensar pensando: “Bem, talvez isso funcione em algum lugar, mas definitivamente não é para mim. Eu tenho tarefas tão difíceis que não é sobre mim. ” Porém, nossa experiência sugere que praticamente todas as tarefas de praticamente qualquer área, se forem decompostas corretamente, formalizadas e incorporadas a um processo claro, podem ser dimensionadas pelo menos parcialmente com a ajuda de multidões.Heisenbug 2018 Piter , : 6-7 Heisenbug , , .