 Tradução de um passo a passo completo do projeto de aprendizado de máquina em Python: parte um .
Tradução de um passo a passo completo do projeto de aprendizado de máquina em Python: parte um .Quando você lê um livro ou ouve um curso de treinamento em análise de dados, geralmente sente que está enfrentando partes separadas de uma imagem que não podem ser reunidas. Você pode se assustar com a perspectiva de dar o próximo passo e resolver completamente um problema com a ajuda do aprendizado de máquina, mas com a ajuda desta série de artigos, você ganhará confiança na capacidade de resolver qualquer problema no campo da ciência de dados.
Para que você possa finalmente ter uma imagem completa em sua cabeça, sugerimos analisar do início ao fim o projeto de uso do aprendizado de máquina usando dados reais.
Siga sucessivamente as etapas:
- Limpeza e formatação de dados.
- Análise exploratória de dados.
- Design e seleção de recursos.
- Comparação das métricas de vários modelos de aprendizado de máquina.
- Ajuste hiperparamétrico do melhor modelo.
- Avaliação do melhor modelo em um conjunto de dados de teste.
- Interpretação dos resultados do modelo.
- Conclusões e trabalho com documentos.
Você aprenderá como os estágios se entrelaçam e como implementá-los no Python.
Todo o projeto está disponível no GitHub, a primeira parte está
aqui. Neste artigo, consideraremos os três primeiros estágios.
Descrição da tarefa
Antes de escrever o código, você precisa entender o problema que está sendo resolvido e os dados disponíveis. Neste projeto, trabalharemos com
dados de eficiência energética disponíveis ao público
para edifícios em Nova York.
Nosso objetivo: usar os dados disponíveis para criar um modelo que preveja o número de Energy Star Score para um edifício em particular e interpretar os resultados para encontrar fatores que influenciam a pontuação final.
Os dados já incluem o Energy Star Score atribuído, portanto, nossa tarefa é o aprendizado de máquina com regressão controlada:
- Supervisionado: Conhecemos os sinais e o objetivo, e nossa tarefa é treinar um modelo que possa comparar o primeiro com o segundo.
- Regressão: O Energy Star Score é uma variável contínua.
Nosso modelo deve ser preciso - para que possa prever o valor do Energy Star Score próximo ao verdadeiro - e interpretável - para que possamos entender suas previsões. Conhecendo os dados de destino, podemos usá-los ao tomar decisões à medida que nos aprofundamos nos dados e criamos o modelo.
Limpeza de dados
Nem todo conjunto de dados é um conjunto de observações perfeitamente correspondido, sem anomalias e valores ausentes (uma dica dos
conjuntos de dados mtcars e
íris ). Em dados reais, há pouca ordem; portanto, antes de iniciar a análise, é necessário
limpá-la e trazê-la para um formato aceitável. A limpeza de dados é um procedimento desagradável, mas obrigatório, para solucionar a maioria das tarefas de análise de dados.
Primeiro, você pode carregar os dados como um quadro de dados do Pandas e examiná-los:
import pandas as pd import numpy as np # Read in data into a dataframe data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv') # Display top of dataframe data.head()
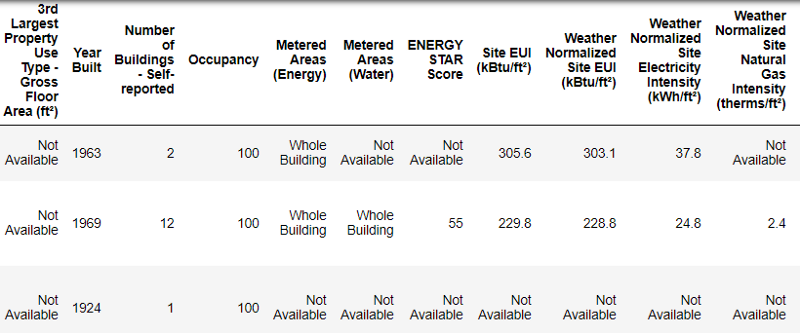 É assim que os dados reais são exibidos.
É assim que os dados reais são exibidos.Este é um fragmento de uma tabela de 60 colunas. Mesmo aqui, vários problemas são visíveis: precisamos prever o
Energy Star Score , mas não sabemos o que todas essas colunas significam. Embora isso não seja necessariamente um problema, porque muitas vezes você pode criar um modelo preciso sem saber nada sobre variáveis. Mas a interpretabilidade é importante para nós, portanto, precisamos descobrir o significado de pelo menos algumas colunas.
Quando recebemos esses dados, não perguntamos sobre os valores, mas analisamos o nome do arquivo:
e decidiu procurar a "Lei local 84". Encontramos
esta página , que dizia que era uma lei de Nova York, segundo a qual os proprietários de todos os edifícios de um determinado tamanho deveriam informar sobre o consumo de energia. Uma pesquisa adicional ajudou a encontrar
todos os valores da coluna . Portanto, não negligencie os nomes dos arquivos, eles podem ser um bom ponto de partida. Além disso, este é um lembrete de que você não se apressa e não perde algo importante!
Não estudaremos todas as colunas, mas definitivamente lidaremos com o Energy Star Score, descrito a seguir:
A classificação percentual é de 1 a 100, calculada com base em relatórios anuais sobre o consumo de energia pelos próprios proprietários do edifício. O Energy Star Score é uma medida relativa usada para comparar o desempenho energético dos edifícios.
O primeiro problema foi resolvido, mas o segundo permaneceu - valores ausentes, marcados como "Não disponível". Este é um valor de string no Python, o que significa que mesmo as strings com números serão armazenadas como tipos de dados do
object , porque se houver alguma string na coluna, o Pandas o converterá em uma coluna que consiste inteiramente de string. Os tipos de dados da coluna podem ser encontrados usando o método
dataframe.info() :
# See the column data types and non-missing values data.info()
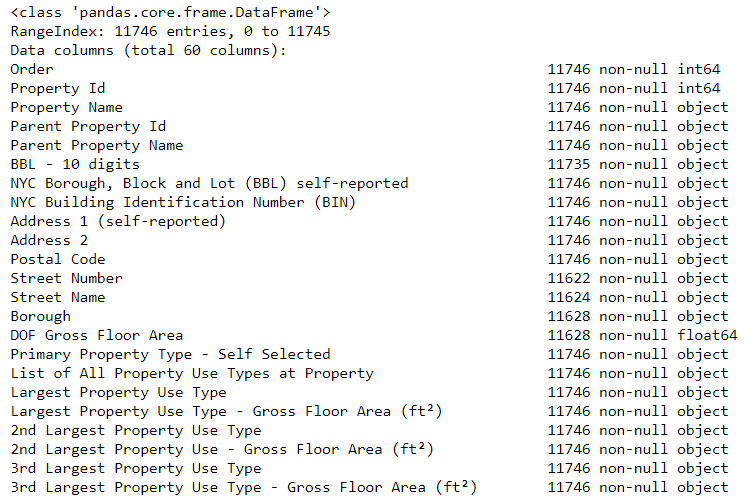
Certamente algumas colunas que contêm explicitamente números (como ft²) são armazenadas como objetos. Como não podemos aplicar a análise numérica a valores de string, convertemos-os em tipos de dados numéricos (especialmente
float )!
Esse código substitui primeiro todos os "Não disponíveis" por
não um número (
np.nan ), que pode ser interpretado como números e, em seguida, converte o conteúdo de determinadas colunas em um tipo de
float :
# Replace all occurrences of Not Available with numpy not a number data = data.replace({'Not Available': np.nan}) # Iterate through the columns for col in list(data.columns): # Select columns that should be numeric if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col): # Convert the data type to float data[col] = data[col].astype(float)
Quando os valores nas colunas correspondentes conosco se tornam números, podemos começar a examinar os dados.
Dados ausentes e anormais
Juntamente com os tipos de dados incorretos, um dos problemas mais comuns está faltando valores. Eles podem estar ausentes por vários motivos e, antes de treinar o modelo, esses valores devem ser preenchidos ou excluídos. Primeiro, vamos descobrir quantos valores temos em cada coluna (o
código está aqui ).
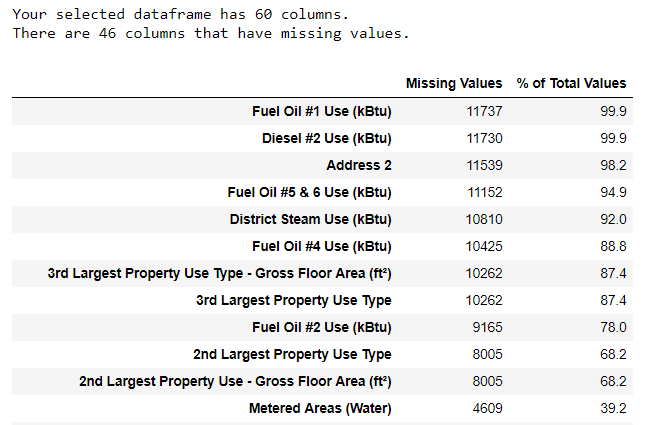 Para criar uma tabela, uma função de uma ramificação no StackOverflow foi usada .
Para criar uma tabela, uma função de uma ramificação no StackOverflow foi usada .As informações sempre devem ser removidas com cuidado e, se houver muitos valores na coluna, provavelmente não beneficiará nosso modelo. O limite após o qual é melhor descartar as colunas depende da sua tarefa (
aqui está uma discussão ) e, em nosso projeto, excluiremos as colunas que estiverem mais da metade vazias.
Também nesta fase, é melhor remover os valores anormais. Eles podem ocorrer devido a erros de digitação ao inserir dados ou devido a erros nas unidades de medida, ou podem estar corretos, mas com valores extremos. Nesse caso, removeremos os valores "extras", guiados pela
definição de anomalias extremas :
- Abaixo do primeiro quartil, há uma faixa interquartil de 3..
- Acima do terceiro quartil + 3 range intervalo interquartil.
O código que remove colunas e anomalias está listado no Bloco de Notas no Github. Após a conclusão do processo de limpeza de dados e remoção de anomalias, temos mais de 11.000 prédios e 49 placas.
Análise exploratória de dados
A fase chata, mas necessária da limpeza dos dados está concluída, você pode ir para o estudo!
A análise exploratória de dados (RAD) é um processo de tempo ilimitado durante o qual calculamos estatísticas e procuramos tendências, anomalias, padrões ou relacionamentos nos dados.
Em suma, o RAD é uma tentativa de descobrir o que os dados podem nos dizer. Geralmente, a análise começa com uma revisão superficial, depois encontramos fragmentos interessantes e os analisamos com mais detalhes. As descobertas podem ser interessantes por si só, ou podem contribuir para a escolha do modelo, ajudando a decidir quais recursos usaremos.
Gráficos de variável única
Nosso objetivo é prever o valor do Energy Star Score (renomeado para nossa
score em nossos dados), portanto, faz sentido começar examinando a distribuição dessa variável. Um histograma é uma maneira simples, mas eficaz, de visualizar a distribuição de uma única variável e pode ser facilmente construído usando o
matplotlib .
import matplotlib.pyplot as plt # Histogram of the Energy Star Score plt.style.use('fivethirtyeight') plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k'); plt.xlabel('Score'); plt.ylabel('Number of Buildings'); plt.title('Energy Star Score Distribution');
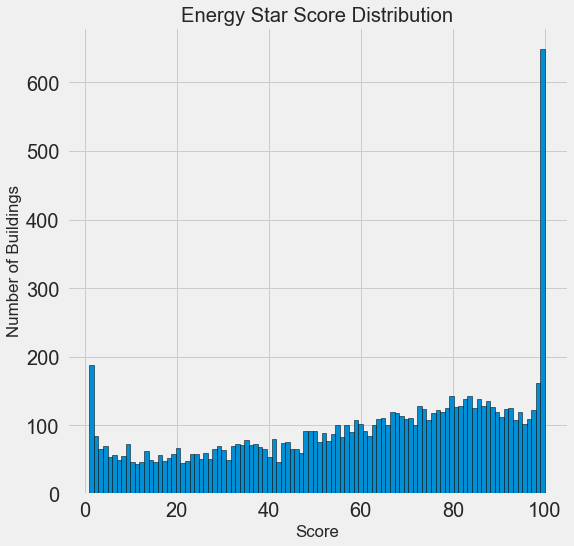
Parece suspeito! O Energy Star Score é um percentil, portanto, você deve esperar uma distribuição uniforme quando cada ponto for atribuído ao mesmo número de edifícios. No entanto, um número desproporcionalmente grande de edifícios recebeu os resultados mais altos e mais baixos (para o Energy Star Score, quanto maior, melhor).
Se olharmos novamente para a definição dessa pontuação, veremos que ela é calculada com base em "relatórios preenchidos independentemente pelos proprietários dos prédios", o que pode explicar o excesso de valores muito grandes. Pedir aos proprietários dos edifícios que relatem seu consumo de energia é como pedir aos alunos que relatem suas notas nos exames. Portanto, esse talvez não seja o critério mais objetivo para avaliar a eficiência energética dos imóveis.
Se tivéssemos um suprimento ilimitado de tempo, poderíamos descobrir por que tantos prédios tinham pontos muito altos e muito baixos. Para fazer isso, teríamos que escolher os edifícios apropriados e analisá-los cuidadosamente. Mas precisamos apenas aprender a prever pontuações e não desenvolver um método de avaliação mais preciso. Você pode marcar a si mesmo que os pontos têm uma distribuição suspeita, mas vamos nos concentrar na previsão.
Pesquisa de relacionamento
A parte principal do AHFR é a busca pela relação entre sinais e nosso objetivo. Variáveis correlacionadas a ele são úteis para uso no modelo, porque podem ser usadas para previsão. Uma maneira de estudar o efeito de uma variável categórica (que leva apenas um conjunto limitado de valores) sobre o objetivo é plotar a densidade usando a biblioteca Seaborn.
O gráfico de densidade pode ser considerado um histograma suavizado porque mostra a distribuição de uma única variável. Você pode colorir classes individuais no gráfico para ver como uma variável categórica altera a distribuição. Este código plota o gráfico de densidade do Energy Star Score, colorido de acordo com o tipo de edifício (para uma lista de edifícios com mais de 100 dimensões):
# Create a list of buildings with more than 100 measurements types = data.dropna(subset=['score']) types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index) # Plot of distribution of scores for building categories figsize(12, 10) # Plot each building for b_type in types: # Select the building type subset = data[data['Largest Property Use Type'] == b_type] # Density plot of Energy Star Scores sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8); # label the plot plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
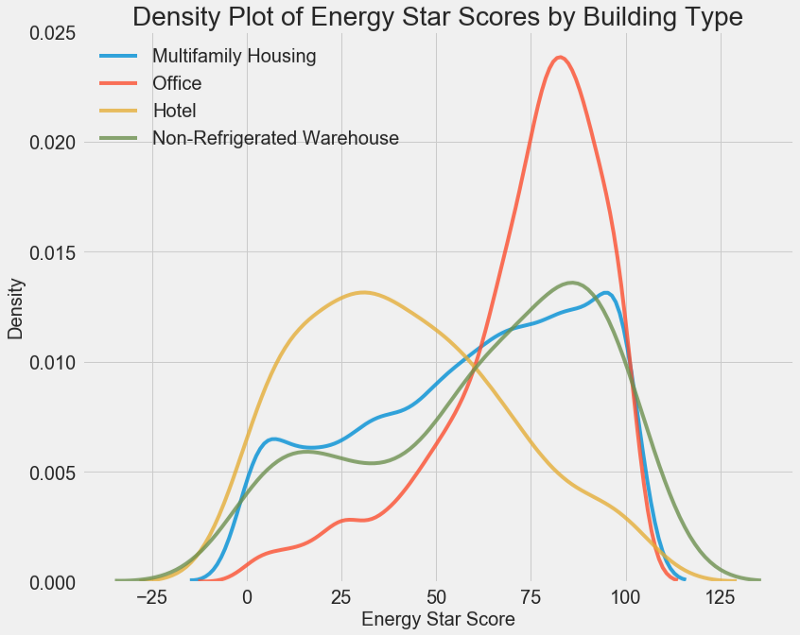
Como você pode ver, o tipo de construção afeta muito o número de pontos. Os edifícios de escritórios costumam ter uma pontuação mais alta e os hotéis mais baixos. Portanto, você precisa incluir o tipo de construção no modelo, porque esse sinal afeta nosso objetivo. Como variável categórica, devemos executar a codificação one-hot do tipo de construção.
Um gráfico semelhante pode ser usado para estimar o Energy Star Score por distrito da cidade:
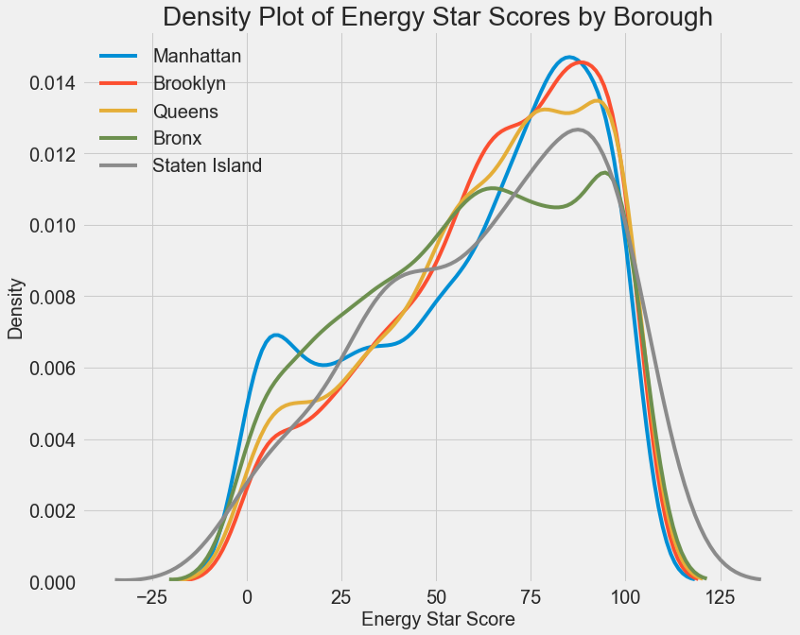
A área não afeta a pontuação tanto quanto o tipo de construção. No entanto, vamos incluí-lo no modelo, porque há uma pequena diferença entre as regiões.
Para calcular o relacionamento entre as variáveis, você pode usar
o coeficiente de correlação de Pearson . Esta é uma medida da intensidade e direção de um relacionamento linear entre duas variáveis. Um valor de +1 significa uma relação positiva perfeitamente linear e -1 significa uma relação negativa perfeitamente linear. Aqui estão alguns exemplos dos valores do
coeficiente de correlação de
Pearson :

Embora esse coeficiente não possa refletir dependências não lineares, é possível começar com ele para avaliar os relacionamentos das variáveis. No Pandas, você pode calcular facilmente as correlações entre quaisquer colunas em um dataframe:
# Find all correlations with the score and sort correlations_data = data.corr()['score'].sort_values()
As correlações mais negativas com a meta:

e o mais positivo:

Existem várias correlações negativas fortes entre os atributos e a meta, e a maior delas pertence a diferentes categorias da EUI (os métodos para calcular esses indicadores diferem ligeiramente).
EUI (Energy Use Intensity ) é a quantidade de energia consumida por um edifício dividido por um pé quadrado de área. Esse valor específico é usado para avaliar a eficiência energética e, quanto menor, melhor. A lógica sugere que essas correlações sejam justificadas: se a EUI aumentar, o Energy Star Score deverá declinar.
Gráficos de duas variáveis
Usamos gráficos de dispersão para visualizar os relacionamentos entre duas variáveis contínuas. Você pode adicionar informações adicionais às cores dos pontos, por exemplo, uma variável categórica. A relação entre o Energy Star Score e o EUI é mostrada abaixo; as cores indicam diferentes tipos de edifícios:
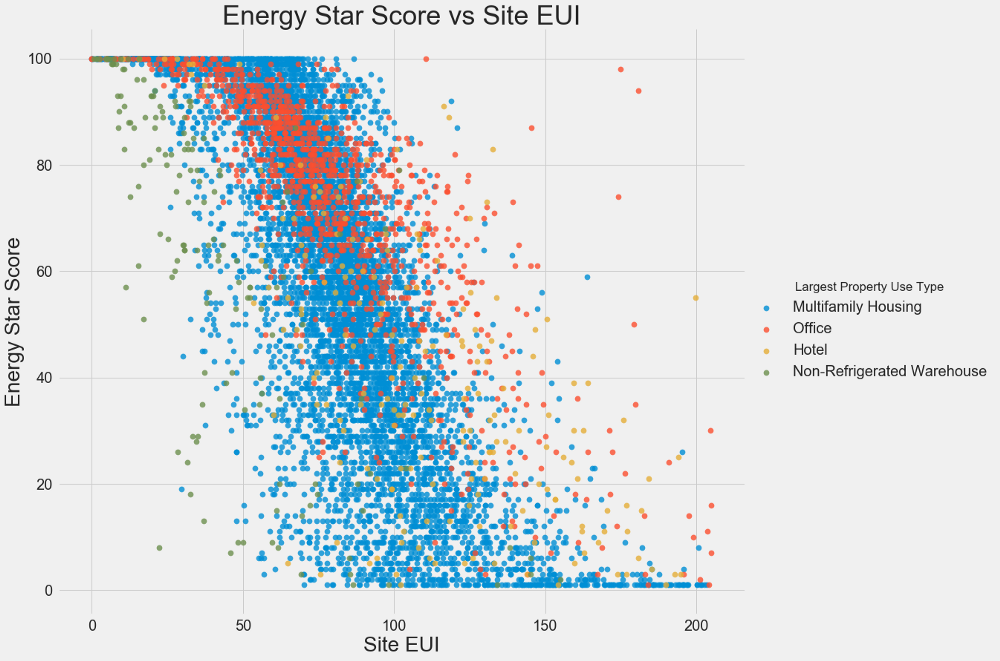
Este gráfico permite visualizar um coeficiente de correlação de -0,7. À medida que o EUI diminui, o Energy Star Score aumenta, essa relação é observada em diferentes tipos de edifícios.
Nosso gráfico de pesquisa mais recente é chamado de
Gráfico de pares . Essa é uma ótima ferramenta para ver os relacionamentos entre diferentes pares de variáveis e a distribuição de variáveis únicas. Usaremos a biblioteca Seaborn e a função PairGrid para criar um gráfico de pares com um gráfico de dispersão no triângulo superior, com um histograma diagonal, um gráfico de densidade de núcleo bidimensional e coeficientes de correlação no triângulo inferior.
# Extract the columns to plot plot_data = features[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)', 'log_Total GHG Emissions (Metric Tons CO2e)']] # Replace the inf with nan plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # Rename columns plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI', 'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI', 'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'}) # Drop na values plot_data = plot_data.dropna() # Function to calculate correlation coefficient between two columns def corr_func(x, y, **kwargs): r = np.corrcoef(x, y)[0][1] ax = plt.gca() ax.annotate("r = {:.2f}".format(r), xy=(.2, .8), xycoords=ax.transAxes, size = 20) # Create the pairgrid object grid = sns.PairGrid(data = plot_data, size = 3) # Upper is a scatter plot grid.map_upper(plt.scatter, color = 'red', alpha = 0.6) # Diagonal is a histogram grid.map_diag(plt.hist, color = 'red', edgecolor = 'black') # Bottom is correlation and density plot grid.map_lower(corr_func); grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds) # Title for entire plot plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
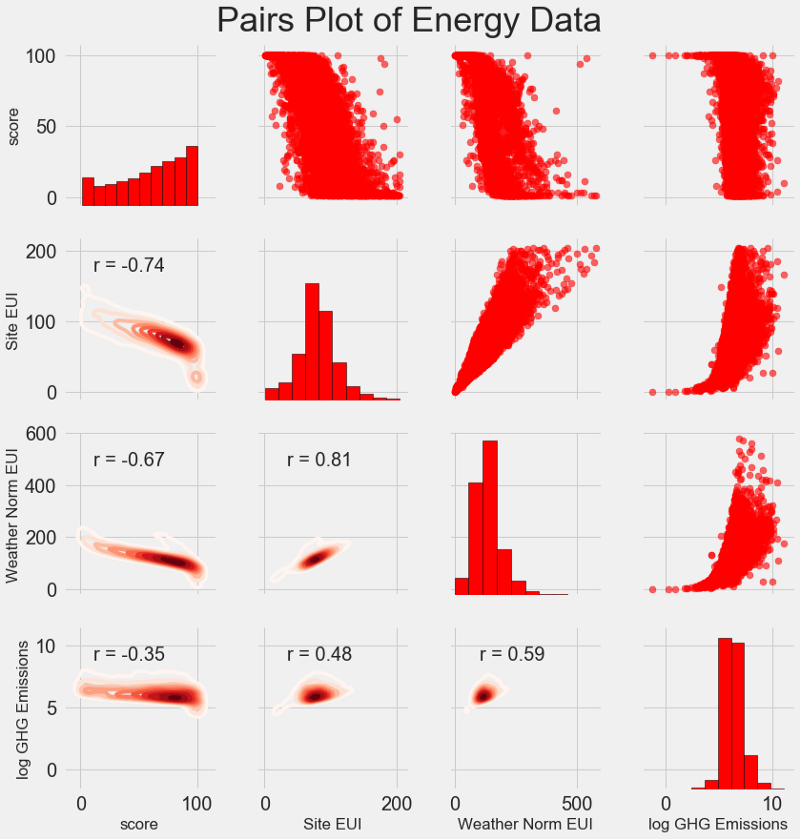
Para ver o relacionamento das variáveis, procure a interseção de linhas e colunas. Suponha que você queira examinar a correlação entre a
Weather Norm EUI e a
score ; em seguida, procuraremos a série
Weather Norm EUI e a coluna de
score , na interseção na qual existe um coeficiente de correlação de -0,67. Esses gráficos não apenas parecem legais, mas também ajudam a escolher variáveis para o modelo.
Design e seleção de recursos
Projetar e selecionar recursos geralmente traz o maior retorno em termos de tempo gasto em aprendizado de máquina. Primeiro, damos as definições:
- Construção de características: o processo de extrair ou criar novas características dos dados brutos. Para usar variáveis no modelo, pode ser necessário transformá-las, digamos, pegar o logaritmo natural, extrair a raiz quadrada ou aplicar uma codificação de variáveis categóricas de um só ponto. O design de características pode ser considerado como a criação de recursos adicionais a partir de dados brutos.
- Seleção de recursos: o processo de seleção dos recursos mais relevantes dos dados, durante o qual removemos alguns recursos para ajudar o modelo a generalizar melhor os novos dados, a fim de obter um modelo mais interpretável. A escolha dos sinais pode ser considerada como a remoção de “supérfluo”, de modo que apenas o mais importante permanece.
O modelo de aprendizado de máquina só pode aprender com os dados que fornecemos, por isso é extremamente importante garantir que incluamos todas as informações relevantes para nossa tarefa. Se você não fornecer o modelo com os dados corretos, ele não poderá aprender e não produzirá previsões precisas!
Faremos o seguinte:
- Aplicável a variáveis categóricas (trimestre e tipo de propriedade) codificação one-hot.
- Adicione o logaritmo natural de todas as variáveis numéricas.
A codificação one-hot é necessária para incluir variáveis categóricas no modelo. O algoritmo de aprendizado de máquina não será capaz de entender o tipo de "escritório"; portanto, se o prédio for um escritório, atribuiremos a ele um sinal de 1 e, se não for um escritório, então 0.
A adição de recursos transformados ajudará o modelo a aprender sobre relacionamentos não lineares nos dados. Na análise dos dados, é prática comum
extrair raízes quadradas, obter logaritmos naturais ou de alguma forma transformar os sinais , isso depende da tarefa específica ou do seu conhecimento das melhores técnicas. Nesse caso, adicionaremos o logaritmo natural de todos os sinais numéricos.
Esse código seleciona sinais numéricos, calcula seus logaritmos, seleciona dois sinais categóricos, aplica codificação one-hot a eles e combina os dois conjuntos em um. A julgar pela descrição, ainda há muito trabalho a ser feito, mas no Pandas tudo é bem simples!
# Copy the original data features = data.copy() # Select the numeric columns numeric_subset = data.select_dtypes('number') # Create columns with log of numeric columns for col in numeric_subset.columns: # Skip the Energy Star Score column if col == 'score': next else: numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Select the categorical columns categorical_subset = data[['Borough', 'Largest Property Use Type']] # One hot encode categorical_subset = pd.get_dummies(categorical_subset) # Join the two dataframes using concat # Make sure to use axis = 1 to perform a column bind features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Agora, temos mais de 11.000 observações (edifícios) com 110 colunas (tags). Nem todos os sinais serão úteis para prever o Energy Star Score, portanto, selecionaremos os sinais e removeremos algumas das variáveis.
Seleção de Recursos
Muitos dos 110 sinais disponíveis são redundantes porque se correlacionam fortemente entre si. Por exemplo, aqui está um gráfico do EUI e do Site Normalizado do Tempo EUI, com um coeficiente de correlação de 0,997.
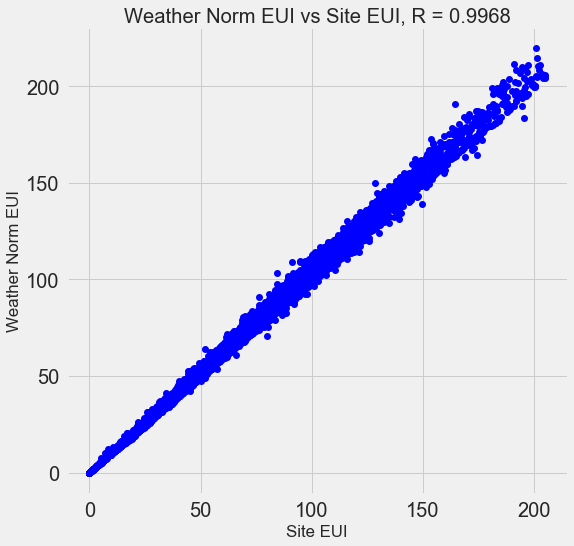
Sinais que se correlacionam fortemente são chamados de
colineares . A remoção de uma variável nesses pares de atributos geralmente ajuda o
modelo a generalizar e a ser mais interpretável . Observe que estamos falando sobre a correlação de alguns sinais com outros, e não sobre a correlação com a meta, o que apenas ajudaria nosso modelo!
Existem vários métodos para calcular a colinearidade de recursos, e um dos mais populares é o
fator de inflação da
variação . Usaremos o coeficiente de correlação b para pesquisar e remover recursos colineares. Descartamos um par de sinais se o coeficiente de correlação entre eles for maior que 0,6. O código está no bloco de notas (e em resposta ao
estouro de pilha ).
Esse valor parece arbitrário, mas, na verdade, tentei limites diferentes, e o exposto acima me permitiu criar o melhor modelo. O aprendizado de máquina é
empírico e, muitas vezes, é necessário experimentar para encontrar a melhor solução. Após a seleção, temos 64 atributos e um objetivo.
# Remove any columns with all na values features = features.dropna(axis=1, how = 'all') print(features.shape) (11319, 65)
Escolha um nível básico
Limpamos os dados, realizamos uma análise exploratória e construímos os sinais. E antes de prosseguir com a criação do modelo, é necessário selecionar o nível base inicial (linha de base ingênua) - um tipo de suposição com a qual compararemos os resultados dos modelos. Se eles ficarem abaixo do nível básico, assumiremos que o aprendizado de máquina não é aplicável a esta tarefa ou que uma abordagem diferente deve ser tentada.
Para tarefas de regressão, como nível básico, é razoável adivinhar o valor mediano da meta no conjunto de treinamento para todos os exemplos no conjunto de testes. Esses kits estabelecem uma barreira relativamente baixa para qualquer modelo.
Como métrica, adotamos o
erro absoluto médio (mae) nas previsões. Existem muitas outras métricas para regressões, mas eu gosto do
conselho de escolher uma métrica e usá-la para avaliar modelos. E o erro absoluto médio é fácil de calcular e interpretar.
Antes de calcular o nível básico, é necessário dividir os dados em conjuntos de treinamento e teste:
- Um conjunto de atributos de treinamento é o que fornecemos ao nosso modelo, juntamente com as respostas durante o treinamento. O modelo deve aprender a corresponder às características da meta.
- Um conjunto de recursos de teste é usado para avaliar o modelo treinado. Quando ela processa o conjunto de testes, ela não vê as respostas corretas e deve prever com base apenas nos recursos disponíveis. Conhecemos as respostas para os dados de teste e podemos comparar os resultados da previsão com eles.
Para treinamento, usamos 70% dos dados e para teste - 30%:
# Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42)
Agora calculamos o indicador para o nível base inicial:
# Function to calculate mean absolute error def mae(y_true, y_pred): return np.mean(abs(y_true - y_pred)) baseline_guess = np.median(y) print('The baseline guess is a score of %0.2f' % baseline_guess) print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
O palpite de linha de base é uma pontuação de 66,00
Desempenho da linha de base no conjunto de testes: MAE = 24.5164O erro absoluto médio no conjunto de testes foi de cerca de 25 pontos. Como avaliamos no intervalo de 1 a 100, o erro é de 25% - uma barreira bastante baixa para o modelo!
Conclusão
Você neste artigo, passamos pelas três primeiras etapas da solução de um problema usando o aprendizado de máquina. Depois de definir a tarefa, nós:
- Dados brutos limpos e formatados.
- Realizou análise exploratória para estudar os dados disponíveis.
- Desenvolvemos um conjunto de recursos que usaremos para nossos modelos.
, , .
Scikit-Learn , .