
Quero compartilhar outra construção noturna de longo prazo, que mostra que você pode criar jogos mesmo com hardware fraco.
Sobre o que você tinha que fazer, como foi decidido e como fazer algo mais do que apenas mais um clone de Pong - bem-vindo ao Cat.
Cuidado: excelente artigo, tráfego e várias inserções de código!
Brevemente sobre o jogo
Atire neles! - agora no AVR.
Na verdade, este é outro shmap, então mais uma vez o personagem principal
Shepard deve salvar a galáxia de um ataque repentino de pessoas desconhecidas, percorrendo o espaço através das estrelas e campos de asteróides, limpando simultaneamente cada sistema estelar.
Todo o jogo é escrito em C e C ++ sem usar a biblioteca Wire do Arduino.
O jogo tem 4 navios para escolher (o último está disponível após a passagem), cada um com suas próprias características:
- manobrabilidade;
- durabilidade;
- poder de arma.
Também implementado:
- Gráficos em cores 2D;
- poder para armas;
- chefes no final dos níveis;
- níveis com asteróides (e sua animação de rotação);
- mudança de cor de fundo em níveis (e não apenas espaço em preto);
- o movimento de estrelas ao fundo em diferentes velocidades (para efeito de profundidade);
- pontuação e economia na EEPROM;
- os mesmos sons (tiros, explosões, etc.);
- um mar de oponentes idênticos.
Plataforma
O retorno do fantasma.
Esclarecemos antecipadamente que esta plataforma deve ser percebida como o antigo console de jogos da primeira terceira geração (anos 80, shiru8bit ).
Além disso, são proibidas modificações de hardware em relação ao hardware original, o que garante o lançamento em qualquer outra placa idêntica imediatamente.
Este jogo foi escrito para o conselho do Arduino Esplora, mas a transferência para o GBA ou qualquer outra plataforma, acho, não será difícil.
No entanto, mesmo neste recurso, este fórum foi abordado apenas algumas vezes, e outros conselhos não valiam a pena mencionar, apesar da grande comunidade de cada um:
- GameBuino META:
- Pokitto;
- makerBuino;
- Arduboy;
- UzeBox / FuzeBox;
- e muitos outros.
Para começar, o que não está no Esplora:
- muita memória (ROM 28kb, RAM 2.5kb);
- potência (CPU de 8 bits a 16 MHz);
- DMA
- gerador de caracteres;
- áreas de memória alocadas ou registros especiais. destino (paleta, ladrilhos, plano de fundo, etc.);
- controlar o brilho da tela (oh, tantos efeitos no lixo);
- extensores de espaço de endereço (mapeadores);
- depurador (
mas quem precisa quando há uma tela inteira! ).
Vou continuar com o fato de que existe:
- SPI de hardware (pode ser executado na velocidade F_CPU / 2);
- tela baseada em ST7735 160x128 1,44 ";
- uma pitada de temporizadores (apenas 4 peças);
- uma pitada de GPIO;
- um punhado de botões (5pcs. + joystick de dois eixos);
- poucos sensores (iluminação, acelerômetro, termômetro);
- emissor de
irritação piezo.
Aparentemente, não há quase nada lá. Não é de surpreender que ninguém quisesse fazer nada com ela, exceto o clone Pong e alguns jogos durante todo esse tempo!
Talvez o fato seja que escrever sob o controlador ATmega32u4 (e similares) é semelhante à programação para Intel 8051 (que tem quase 40 anos no momento da publicação), onde é necessário observar um grande número de condições e recorrer a vários truques e truques.
Processamento periférico
Um por tudo!
Tendo examinado o circuito, ficou claramente visível que todos os periféricos estão conectados através do expansor GPIO (74HC4067D multiplexador mais MUX) e são comutados usando o GPIO PF4, PF5, PF6, PF7 ou a mordidela PORTF sênior, e a saída MUX é lida no GPIO - PF1.
É muito conveniente alternar a entrada simplesmente atribuindo os valores à porta PORTF por máscara e de forma alguma esquecendo a menor mordidela:
uint16_t getAnalogMux(uint8_t chMux) { MUX_PORTX = ((MUX_PORTX & 0x0F) | ((chMux<<4)&0xF0)); return readADC(); }
Enquete de clique no botão:
#define SW_BTN_MIN_LVL 800 bool readSwitchButton(uint8_t btn) { bool state = true; if(getAnalogMux(btn) > SW_BTN_MIN_LVL) {
A seguir estão os valores para a porta F:
#define SW_BTN_1_MUX 0 #define SW_BTN_2_MUX 8 #define SW_BTN_3_MUX 4 #define SW_BTN_4_MUX 12
Adicionando um pouco mais:
#define BUTTON_A SW_BTN_4_MUX #define BUTTON_B SW_BTN_1_MUX #define BUTTON_X SW_BTN_2_MUX #define BUTTON_Y SW_BTN_3_MUX #define buttonIsPressed(a) readSwitchButton(a)
Você pode entrevistar com segurança a cruz certa:
void updateBtnStates(void) { if(buttonIsPressed(BUTTON_A)) btnStates.aBtn = true; if(buttonIsPressed(BUTTON_B)) btnStates.bBtn = true; if(buttonIsPressed(BUTTON_X)) btnStates.xBtn = true; if(buttonIsPressed(BUTTON_Y)) btnStates.yBtn = true; }
Observe que o estado anterior não é redefinido; caso contrário, você pode perder o fato de pressionar a tecla (ela também funciona como uma proteção adicional contra conversas).
Sfx
Um zumbido.
E se não houver DAC, nenhum chip da Yamaha e houver apenas um retângulo PWM de 1 bit para som?
No começo, parece não muito, mas, apesar disso, o astuto PWM é usado aqui para recriar a técnica “áudio PDM” e, com sua ajuda, você pode fazer
isso.Algo semelhante é fornecido pela biblioteca do Gamebuino e tudo o que é necessário é transferir o gerador de popping para outro GPIO e o timer para o Esplora (saída do timer4 e OCR4D). Para uma operação correta, o timer1 também é usado para gerar interrupções e recarregar o registro OCR4D com novos dados.
O mecanismo Gamebuino usa padrões de som (como na música do rastreador), o que economiza muito espaço, mas você precisa fazer todas as amostras sozinho, não há bibliotecas com as já prontas.
Vale ressaltar que esse mecanismo está vinculado a um período de atualização de cerca de 1/50 s ou 20 quadros / s.
Para ler os padrões de som, depois de ler o Wiki em formato de áudio, desenhei uma GUI simples no Qt. Não produz som da mesma maneira, mas fornece um conceito aproximado de como o padrão soará e permite carregar, salvar e editar.
Gráficos
Pixelart imortal.
A exibição codifica as cores em dois bytes (RGB565), mas como as imagens nesse formato ocupam muito, todas elas foram indexadas pela paleta para economizar espaço, que eu já descrevi mais de uma vez nos artigos anteriores.
Ao contrário do Famicom / NES, não há limites de cores para a imagem e há mais cores disponíveis na paleta.
Cada imagem no jogo é uma matriz de bytes na qual os seguintes dados são armazenados:
- largura, altura;
- iniciar marcador de dados;
- dicionário (se houver, mas mais sobre isso posteriormente);
- carga útil;
- fim do marcador de dados.
Por exemplo, essa imagem (ampliada 10 vezes):

no código, ficará assim:
pic_t weaponLaserPic1[] PROGMEM = { 0x0f,0x07, 0x02, 0x8f,0x32,0xa2,0x05,0x8f,0x06,0x22,0x41,0xad,0x03,0x41,0x22,0x8f,0x06,0xa2,0x05, 0x8f,0x23,0xff, };
Onde sem um navio neste gênero? Após centenas de esboços de teste com uma diferença de pixels, apenas esses navios permaneceram para o jogador:

Vale ressaltar que os navios não têm chama nos ladrilhos (aqui é para maior clareza), é aplicado separadamente para criar uma animação do escapamento do motor.
Não se esqueça dos pilotos de cada navio:

A variação das naves inimigas não é muito grande, mas lembre-se de que não há muito espaço, então aqui estão três naves:

Sem bônus canônicos na forma de melhorar armas e restaurar a saúde, o jogador não vai durar muito:

Obviamente, com o aumento do poder das armas, o tipo de projétil emitido muda:

Como foi escrito no começo, o jogo tem um nível de asteróides, depois de cada segundo chefe. É interessante que existem muitos objetos em movimento e rotação de tamanhos diferentes. Além disso, quando um jogador os atinge, eles entram em colapso parcial, ficando menores em tamanho.
Dica: Asteróides grandes ganham mais pontos.



Para criar esta animação simples, basta 12 imagens pequenas:

Eles são divididos em três para cada tamanho (grande, médio e pequeno) e para cada ângulo de rotação, você precisa de mais 4 rodados de 0, 90, 180 e 270 graus. No jogo, basta substituir o ponteiro do array pela imagem em um intervalo igual, criando a ilusão de rotação.
void rotateAsteroid(asteroid_t &asteroid) { if(RN & 1) { asteroid.sprite.pPic = getAsteroidPic(asteroid); ++asteroid.angle; } } void moveAsteroids(void) { for(auto &asteroid : asteroids) { if(asteroid.onUse) { updateSprite(&asteroid.sprite); rotateAsteroid(asteroid); ...
Isso é feito apenas devido à falta de recursos de hardware, e uma implementação de software como a transformação Affine levará mais do que as próprias imagens e será muito lenta.
Um pedaço de cetim para quem está interessado.
Você pode notar parte dos protótipos e o que aparece apenas nos créditos após a aprovação no jogo.
Além dos gráficos simples, para economizar espaço e adicionar um efeito retrô, os glifos em minúsculas e todos os glifos com até 30 e após 127 bytes de ASCII foram expulsos da fonte.
Importante!
Não esqueça que const e constexpr no AVR não significam que os dados estejam na memória do programa; aqui, para isso, é necessário usar PROGMEM adicionalmente.
Isso se deve ao fato de o núcleo do AVR ser baseado na arquitetura de Harvard, portanto, são necessários códigos de acesso especiais para a CPU para acessar os dados.
Espremendo a galáxia
A maneira mais fácil de embalar é o RLE.
Depois de estudar os dados compactados, você pode observar que o bit mais significativo no byte de carga útil no intervalo de 0x00 a 0x50 não é usado. Isso permite adicionar os dados e o marcador de início para o início da repetição (0x80) e o próximo byte para indicar o número de repetições, o que permite compactar uma série de 257 (+2 do fato de que o RLE de dois bytes é estúpido) de bytes idênticos em apenas dois.
Implementação e exibição do desempacotador:
void drawPico_RLE_P(uint8_t x, uint8_t y, pic_t *pPic) { uint16_t repeatColor; uint8_t tmpInd, repeatTimes; alphaReplaceColorId = getAlphaReplaceColorId(); auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); ++pPic;
O principal é não exibir a imagem fora da tela, caso contrário, será lixo, pois não há verificação de borda aqui.
A imagem de teste é descompactada em ~ 39ms. ao mesmo tempo, ocupando 3040 bytes, enquanto sem compactação seriam necessários 11.200 bytes ou 22.400 bytes sem indexação.
Imagem de teste (ampliada 2 vezes):

Na imagem acima, você pode ver o entrelaçamento, mas na tela é suavizado pelo hardware, criando um efeito semelhante ao CRT e, ao mesmo tempo, aumentando significativamente a taxa de compactação.
O RLE não é uma panacéia
Somos tratados por déjà vu.
Como você sabe, o RLE funciona bem com empacotadores do tipo LZ. O WiKi veio ao resgate com uma lista de métodos de compactação. O ímpeto foi o vídeo de "GameHut" sobre a análise da
introdução impossível
no Sonic 3D Blast.Tendo estudado muitos empacotadores (LZ77, LZW, LZSS, LZO, RNC, etc.), cheguei à conclusão de que seus desembaladores:
- requer muita RAM para dados descompactados (pelo menos 64kb. e mais);
- volumoso e lento (alguns precisam construir árvores Huffman para cada subunidade);
- tenha uma baixa taxa de compactação com uma pequena janela (requisitos de RAM muito rigorosos);
- tem ambigüidades com o licenciamento.
Após meses de adaptações fúteis, decidiu-se modificar o empacotador existente.
Por analogia com os empacotadores do tipo LZ, para obter a compactação máxima, o acesso ao dicionário foi usado, mas no nível de bytes - os pares de bytes repetidos com mais freqüência são substituídos por um ponteiro de byte no dicionário.
Mas há um problema: como distinguir um byte de "quantas repetições" de um "marcador de dicionário"?
Depois de uma longa sessão com um pedaço de papel e um jogo mágico com morcegos, isso apareceu:
- "Marcador de dicionário" é um marcador RLE (0x80) + byte de dados (0x50) + número da posição no dicionário;
- limite o byte "quantas repetições" ao tamanho do marcador do dicionário - 1 (0xCF);
- o dicionário não pode usar o valor 0xff (é para o marcador no final da imagem).
Aplicando tudo isso, obtemos um tamanho fixo de dicionário: não mais de 46 pares de bytes e redução de RLE para 209 bytes. Obviamente, nem todas as imagens podem ser empacotadas dessa maneira, mas não serão mais exibidas.
Nos dois algoritmos, a estrutura da imagem compactada será a seguinte:
- 1 byte por largura e altura;
- 1 byte para o tamanho do dicionário, é um ponteiro de marcador para o início dos dados compactados;
- de 0 a 92 bytes do dicionário;
- 1 a N bytes de dados compactados.
O utilitário empacotador resultante no D (pickoPacker) é suficiente para colocar em uma pasta com arquivos * .png indexados e executar a partir do terminal (ou cmd). Se precisar de ajuda, execute com a opção "-h" ou "--help".
Após a execução do utilitário, obtemos arquivos * .h, cujo conteúdo é conveniente para a transferência para o local certo no projeto (portanto, não há proteção).
Antes de desembalar, a tela, o dicionário e os dados iniciais são preparados:
void drawPico_DIC_P(uint8_t x, uint8_t y, pic_t *pPic) { auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); uint8_t tmpByte, unfoldPos, dictMarker; alphaReplaceColorId = getAlphaReplaceColorId(); auto pDict = &pPic[3];
Uma parte de dados lida pode ser compactada em um dicionário, portanto, a verificamos e descompactamos:
inline uint8_t findPackedMark(uint8_t *ptr) { do { if(*ptr >= DICT_MARK) { return 1; } } while(*(++ptr) != PIC_DATA_END); return 0; } inline uint8_t *unpackBuf_DIC(const uint8_t *pDict) { bool swap = false; bool dictMarker = true; auto getBufferPtr = [&](uint8_t a[], uint8_t b[]) { return swap ? &a[0] : &b[0]; }; auto ptrP = getBufferPtr(buf_unpacked, buf_packed); auto ptrU = getBufferPtr(buf_packed, buf_unpacked); while(dictMarker) { if(*ptrP >= DICT_MARK) { setPicWData(ptrU) = getPicWData(pDict, *ptrP); ++ptrU; } else { *ptrU = *ptrP; } ++ptrU; ++ptrP; if(*ptrP == PIC_DATA_END) { *ptrU = *ptrP;
Agora, a partir do buffer recebido, descompactamos o RLE de maneira familiar e o exibimos na tela:
inline void printBuf_RLE(uint8_t *pData) { uint16_t repeatColor; uint8_t repeatTimes, tmpByte; while((tmpByte = *pData) != PIC_DATA_END) {
Surpreendentemente, a substituição do algoritmo não afetou significativamente o tempo de descompactação e é de ~ 47ms. Isso é quase 8ms. por mais tempo, mas a imagem de teste leva apenas 1650 bytes!
Até a última medida
Quase tudo pode ser feito mais rápido!
Apesar da presença de SPI de hardware, o núcleo do AVR oferece muita dor de cabeça ao usá-lo.
Há muito se sabe que o SPI no AVR, além de rodar na velocidade F_CPU / 2, também possui um registro de dados de apenas 1 byte (não é possível carregar 2 bytes de uma vez).
Além disso, quase todo o código SPI no AVR que conheci funciona de acordo com este esquema:
- Baixar dados SPDR
- interrogar o bit SPIF no SPSR em um loop.
Como você pode ver, o fornecimento contínuo de dados, como é feito no STM32, não cheira aqui. Mas, mesmo aqui você pode acelerar a saída de ambos os desempacotadores em ~ 3ms!
Abrindo a folha de dados e observando a seção "Relógios do conjunto de instruções", é possível calcular os custos da CPU ao transmitir um byte via SPI:
- 1 ciclo para carregamento de registro com novos dados;
- 2 batidas por bit (ou 16 batidas por byte);
- 1 barra por linha mágica do relógio (um pouco mais tarde sobre "NOP");
- 1 relógio para verificar o bit de status no SPSR (ou 2 relógio na filial);
No total, para transmitir um pixel (dois bytes), 38 ciclos de clock ou ~ 425600 ciclos para a imagem de teste (11.200 bytes) devem ser gastos.
Sabendo que F_CPU == 16 MHz obtemos
0,0000000625 62,5 nanossegundos por ciclo de clock (
Process0169 ), multiplicando os valores, obtemos ~ 26 milissegundos. Surge a pergunta: “De onde escrevi anteriormente que o tempo de desempacotamento é de 39ms. e 47ms. "? Tudo é simples - lógica do desempacotador + manipulação de interrupção.
Aqui está um exemplo de saída de interrupção:
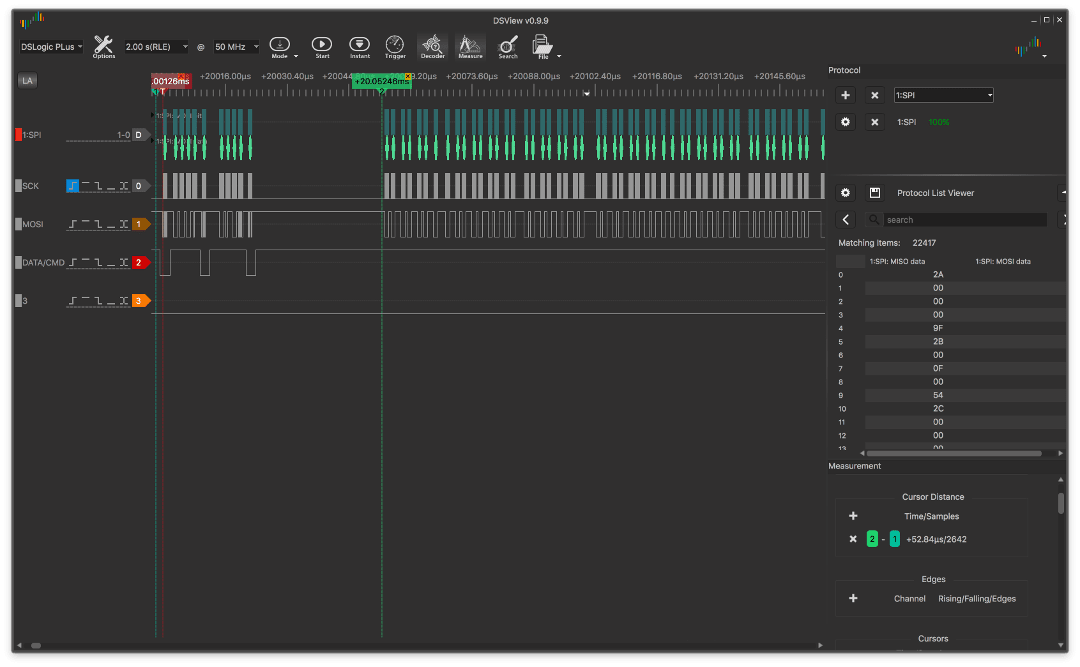
e sem interrupção:

Os gráficos mostram que o tempo entre a configuração da janela de endereço na tela VRAM e o início da transferência de dados na versão sem interrupções é menor e quase não há intervalos entre os bytes durante a transmissão (o gráfico é uniforme).
Infelizmente, você não pode desativar as interrupções para cada saída de imagem, caso contrário, o som e o núcleo de todo o jogo serão interrompidos (mais sobre isso mais tarde).
Foi escrito acima sobre um certo "NOP mágico" para uma linha de relógio. O fato é que, para estabilizar o CLK e definir o sinalizador SPIF, são necessários exatamente 1 ciclo de relógio e, quando este sinalizador é lido, ele já está configurado, o que evita ramificações em 2 barras na instrução BREQ.
Aqui está um exemplo sem um NOP:
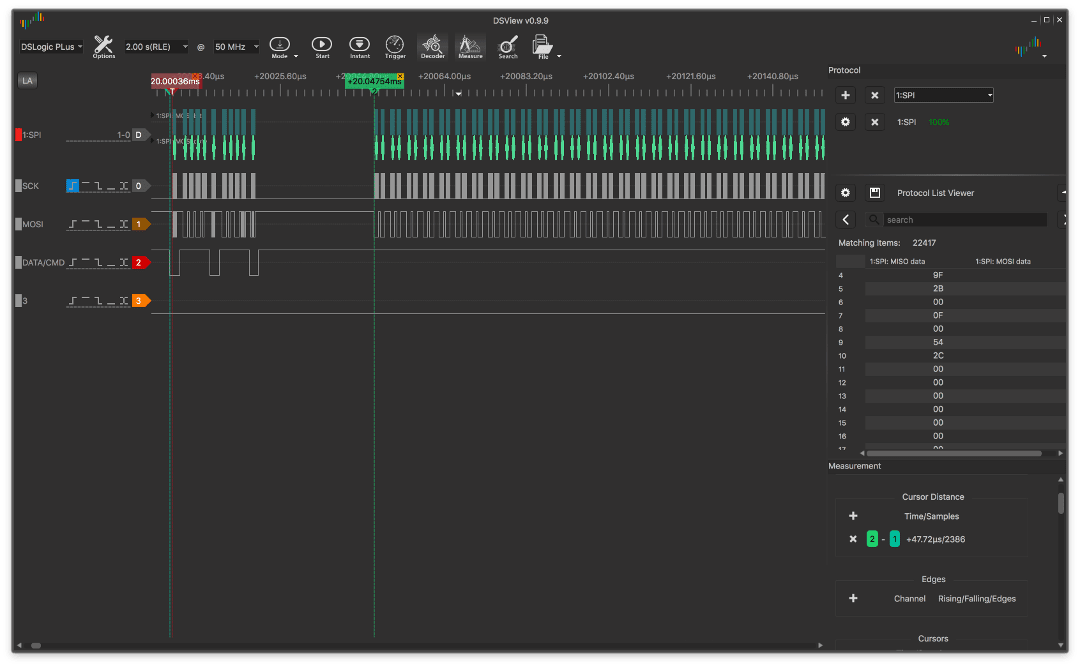
e com ele:

A diferença parece insignificante, apenas alguns microssegundos, mas se você tomar uma escala diferente:
NOP grande:
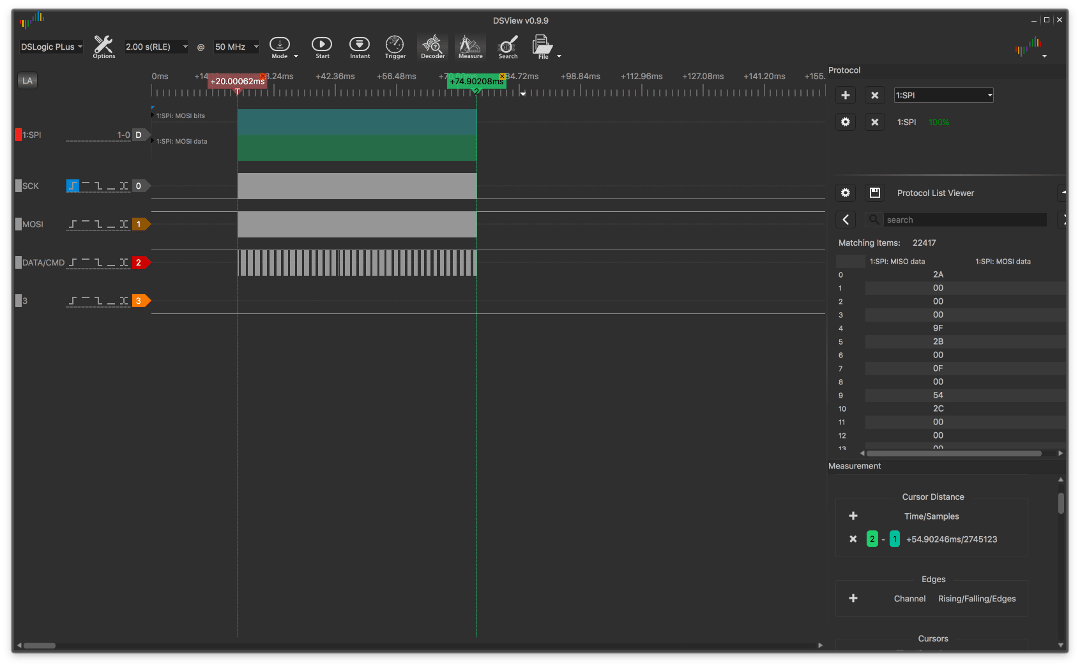
e com ele muito grande:

então a diferença se torna muito mais visível, atingindo ~ 4.3ms.
Agora vamos fazer o seguinte truque sujo:
Trocamos a ordem de carregamento e leitura dos registros e você não pode esperar em cada segundo byte do sinalizador SPIF, mas verifique-o apenas antes de carregar o primeiro byte do próximo pixel.
Aplicamos conhecimento e implantamos a função "pushColorFast (repeatColor);":
#define SPDR_TX_WAIT(a) asm volatile(a); while((SPSR & (1<<SPIF)) == 0); typedef union { uint16_t val; struct { uint8_t lsb; uint8_t msb; }; } SPDR_t; ... do { #ifdef ESPLORA_OPTIMIZE SPDR_t in = {.val = repeatColor}; SPDR_TX_WAIT(""); SPDR = in.msb; SPDR_TX_WAIT("nop"); SPDR = in.lsb; #else pushColorFast(repeatColor); #endif } while(--repeatTimes); } #ifdef ESPLORA_OPTIMIZE SPDR_TX_WAIT("");
Apesar da interrupção do timer, o uso do truque acima dá um ganho de quase 6ms.

É assim que o conhecimento simples do ferro permite extrair um pouco mais dele e gerar algo semelhante:

Colisões no Coliseu
A batalha das caixas.
Para começar, todo o conjunto de objetos (naves, conchas, asteróides, bônus) são estruturas (sprites) com os seguintes parâmetros:
- coordenadas X, Y atuais;
- novas coordenadas X, Y;
- ponteiro para a imagem.
Como a imagem armazena a largura e a altura, não há necessidade de duplicar esses parâmetros; além disso, essa organização simplifica a lógica em muitos aspectos.
O cálculo em si é simplificado para o banal - com base na interseção dos retângulos. Embora não seja preciso o suficiente e não calcule conflitos futuros, isso é mais do que suficiente.
A verificação ocorre alternadamente nos eixos X e Y. Por esse motivo, a ausência de interseção no eixo X reduz o cálculo da colisão.
Primeiro, o lado direito do primeiro retângulo com o lado esquerdo do segundo retângulo é verificado para a parte comum do eixo X. Se for bem-sucedido, uma verificação semelhante será realizada para o lado esquerdo do primeiro e do lado direito do segundo retângulo.
Após a detecção bem-sucedida de interseções ao longo do eixo X, uma verificação é realizada da mesma maneira para os lados superior e inferior dos retângulos ao longo do eixo Y.
O exposto acima parece muito mais fácil do que parece:
bool checkSpriteCollision(sprite_t *pSprOne, sprite_t *pSprTwo) { auto tmpDataOne = getPicSize(pSprOne->pPic, 0); auto tmpDataTwo = getPicSize(pSprTwo->pPic, 0); uint8_t objOnePosEndX = (pSprOne->pos.Old.x + tmpDataOne.u8Data1); if(objOnePosEndX >= pSprTwo->pos.Old.x) { uint8_t objTwoPosEndX = (pSprTwo->pos.Old.x + tmpDataTwo.u8Data1); if(pSprOne->pos.Old.x >= objTwoPosEndX) { return false;
Resta acrescentar isso ao jogo:
void checkInVadersCollision(void) { decltype(aliens[0].weapon.ray) gopher; for(auto &alien : aliens) { if(alien.alive) { if(checkSpriteCollision(&ship.sprite, &alien.sprite)) { gopher.sprite.pos.Old = alien.sprite.pos.Old; rocketEpxlosion(&gopher);
Curva de Bezier
Trilhos espaciais.
Como em qualquer outro jogo com esse gênero, os navios inimigos devem se mover ao longo das curvas.
Foi decidido implementar curvas quadráticas como as mais simples para o controlador e para esta tarefa. Três pontos são suficientes para eles: o inicial (P0), o final (P2) e o imaginário (P1). Os dois primeiros especificam o início e o fim da linha, o último ponto descreve o tipo de curvatura.
Ótimo artigo sobre curvas.Como essa é uma curva paramétrica de Bezier, ela também precisa de mais um parâmetro - o número de pontos intermediários entre os pontos inicial e final.
Total chegamos aqui a essa estrutura:
typedef struct {
Nele, position_t é uma estrutura de dois bytes das coordenadas X e Y.
A localização de um ponto para cada coordenada é calculada usando esta fórmula (thx Wiki):
B = ((1,0 - t) ^ 2) P0 + 2t (1,0 - t) P1 + (t ^ 2) P2,
t [> = 0 e& <= 1]
Por um longo tempo, sua implementação foi resolvida de frente, sem uma matemática de ponto fixo:
... float t = ((float)pItemLine->step)/((float)pLine->totalSteps); pPos->x = (1.0 - t)*(1.0 - t)*pLine->P0.x + 2*t*(1.0 - t)*pLine->P1.x + t*t*pLine->P2.x; pPos->y = (1.0 - t)*(1.0 - t)*pLine->P0.y + 2*t*(1.0 - t)*pLine->P1.y + t*t*pLine->P2.y; ...
Claro, isso não pode ser deixado. Afinal, livrar-se do flutuador não só poderia melhorar a velocidade, mas também liberar a ROM; portanto, as seguintes implementações foram encontradas:
- avrfix;
- stdfix;
- libfixmath;
- fixedptc.
O primeiro continua sendo um azarão, pois é uma biblioteca compilada e não queria mexer com o desmontador.
O segundo candidato do pacote GCC também não deu certo, pois o avr-gcc usado não foi corrigido e o tipo "short _Accum" permaneceu indisponível.
A terceira opção, apesar de possuir um grande número de mantas. possui operações de bits codificadas em bits específicos no formato Q16.16, o que torna impossível controlar os valores de Q e I.
Esta última pode ser considerada uma versão simplificada de "Fixedmath", mas a principal vantagem é a capacidade de controlar não apenas o tamanho da variável, que por padrão é de 32 bits com o formato Q24.8, mas também os valores de Q e I.
Resultados do teste em diferentes configurações:
| Tipo | QI | Sinalizadores adicionais | Byte de ROM | Tms. * |
|---|
| flutuar | - | - | 4236 | 35 |
| fixo | 16.16 | - | 4796 | 119 |
| fixo | 16.16 | FIXMATH_NO_OVERFLOW | 4664 | 89 |
| fixo | 16.16 | FIXMATH_OPTIMIZE_8BIT | 5036 | 92 |
| fixo | 16.16 | _NO_OVERFLOW + _8BIT | 4916 | 89 |
| fixedptc | 24,8 | FIXEDPT_BITS 32 | 4420 | 64 |
| fixedptc | 9,7 | FIXEDPT_BITS 16 | 3490 | 31 |
* A verificação foi realizada no padrão: "195,175,145,110,170,70,170" e na chave "-Os".
Pode ser visto na tabela que ambas as bibliotecas ocupavam mais ROM e se mostravam piores que o código compilado do GCC ao usar o float.
Também é visto que uma pequena revisão para o formato Q9.7 e uma diminuição na variável para 16 bits deram uma aceleração de 4ms. e liberando ROM a ~ 50 bytes.
O efeito esperado foi uma diminuição na precisão e um aumento no número de erros:

que neste caso não é crítico.
Alocando Recursos
Terça e quinta-feira trabalham por apenas uma hora.
Na maioria dos casos, todos os cálculos são executados em todos os quadros, o que nem sempre é justificado, pois pode não haver tempo suficiente no quadro para calcular algo e você terá que tentar alternar, contar quadros ou ignorá-los. Então fui mais longe - abandonei completamente a equipe.
Tendo dividido tudo em pequenas tarefas, seja: calcular colisões, processar sons, botões e exibir gráficos, basta executá-las em um determinado intervalo, e a inércia do olho e a capacidade de atualizar apenas parte da tela serão suficientes.Gerenciamos tudo isso nem uma vez com o sistema operacional, mas com a máquina de estado que eu criei alguns anos atrás, ou, mais simplesmente, não com o gerenciador de tarefas tinySM que está se aglomerando.Repito as razões para usá-lo em vez de qualquer um dos RTOS:- requisitos mínimos de ROM (núcleo de ~ 250 bytes);
- menores requisitos de RAM (~ 9 bytes por tarefa);
- princípio simples e compreensível do trabalho;
- determinismo de comportamento;
- menos tempo de CPU é desperdiçado;
- deixa o acesso ao ferro;
- plataforma independente;
- escrito em C e fácil de quebrar em C ++;
precisava da minha própria bicicleta.
Como descrevi uma vez, as tarefas para ele são organizadas em uma matriz de ponteiros para estruturas, onde um ponteiro para uma função e seu intervalo de chamada são armazenados. Esse agrupamento simplifica a descrição do jogo em estágios separados, o que também permite reduzir o número de ramificações e alternar dinamicamente o conjunto de tarefas.Por exemplo, durante a tela inicial, 7 tarefas são executadas e durante o jogo já existem 20 tarefas (todas as tarefas são descritas no arquivo gameTasks.c).Primeiro, você precisa definir algumas macros para sua conveniência: #define T(a) a##Task #define TASK_N(a) const taskParams_t T(a) #define TASK(a,b) TASK_N(a) PROGMEM = {.pFunc=a, .timeOut=b} #define TASK_P(a) (taskParams_t*)&T(a) #define TASK_ARR_N(a) const tasksArr_t a##TasksArr[] #define TASK_ARR(a) TASK_ARR_N(a) PROGMEM #define TASK_END NULL
A declaração da tarefa está realmente criando uma estrutura, inicializando seus campos e colocando-a na ROM: TASK(updateBtnStates, 25);
Cada uma dessas estruturas ocupa 4 bytes de ROM (dois por ponteiro e dois por intervalo).Um bom bônus para macros é que não funciona para criar mais de uma estrutura exclusiva para cada função.Depois de declarar as tarefas necessárias, as adicionamos à matriz e também as colocamos na ROM: TASK_ARR( game ) = { TASK_P(updateBtnStates), TASK_P(playMusic), TASK_P(drawStars), TASK_P(moveShip), TASK_P(drawShip), TASK_P(checkFireButton), TASK_P(pauseMenu), TASK_P(drawPlayerWeapon), TASK_P(checkShipHealth), TASK_P(drawSomeGUI), TASK_P(checkInVaders), TASK_P(drawInVaders), TASK_P(moveInVaders), TASK_P(checkInVadersRespawn), TASK_P(checkInVadersRay), TASK_P(checkInVadersCollision), TASK_P(dropWeaponGift), TASK_END };
Ao definir o sinalizador USE_DYNAMIC_MEM como 0 para memória estática, o principal a lembrar é inicializar os ponteiros para o armazenamento de tarefas na RAM e definir o número máximo deles que serão executados: ... tasksContainer_t tasksContainer; taskFunc_t tasksArr[MAX_GAME_TASKS]; ... initTasksArr(&tasksContainer, &tasksArr[0], MAX_GAME_TASKS); …
Configurando tarefas para execução: ... addTasksArray_P(gameTasksArr); …
A proteção contra estouro é controlada pelo sinalizador USE_MEM_PANIC; se você tiver certeza do número de tarefas, poderá desativá-lo para salvar a ROM.Resta apenas executar o manipulador: ... runTasks(); ...
Dentro, há um loop infinito que contém a lógica básica. Uma vez dentro dela, a pilha também é restaurada graças a "__attribute__ ((noreturn))".No loop, os elementos da matriz são varridos alternadamente para a necessidade de chamar a tarefa após o intervalo.A contagem regressiva dos intervalos foi feita com base no timer0 como um sistema com um quantum de 1ms ...Apesar da distribuição bem-sucedida de tarefas no tempo, às vezes elas se sobrepunham (tremulação), o que causava desbotamento a curto prazo de tudo e de tudo no jogo.Definitivamente tinha que ser decidido, mas como? Sobre como tudo foi traçado na próxima vez, mas, por enquanto, tente encontrar o ovo da Páscoa na fonte.O fim
Então, usando muitos truques (e muitos mais dos quais eu não descrevi), tudo se encaixava na ROM de 24kb e 1500 bytes de RAM. Se você tiver alguma dúvida, terei prazer em respondê-las.Para quem não encontrou ou não procurou um ovo de Páscoa:cavar para o lado: void invadersMagicRespawn(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
Nada notável, certo?Raaaaazvorachivaem macro invadersMagicRespawn: void action() { tftSetTextSize(1); for(;;) { tftSetCP437(RN & 1); tftSetTextColorBG((((RN % 192 + 64) & 0xFC) << 3), COLOR_BLACK); tftDrawCharInt(((RN % 26) * 6), ((RN & 15) * 8), (RN % 255)); tftPrintAt_P(32, 58, (const char *)creditP0); } } a(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
«(void)» , «action()» 10 , «disablePause();». «Matrix Falling code» . 130 ROM.
Para construir e executar, basta colocar a pasta (ou link) "esploraAPI" em "/ arduino / libraries /".Referências:
PS Você pode ver e ouvir como tudo fica um pouco mais tarde quando eu faço um vídeo aceitável.