O tópico da conversa de hoje é o que o Python aprendeu ao longo de todos os anos de sua existência no trabalho com imagens. De fato, além dos antigos de ImageMagick e GraphicsMagick de 1990, existem modernas bibliotecas eficazes. Por exemplo, Pillow e Pillow-SIMD mais produtivo. O desenvolvedor ativo Alexander Karpinsky (
homm ) da MoscowPython comparou diferentes bibliotecas para trabalhar com imagens em Python, apresentou benchmarks e falou sobre recursos não óbvios que sempre são suficientes. Neste artigo, uma transcrição do relatório ajudará você a escolher uma biblioteca para o seu aplicativo e a fazê-lo funcionar da maneira mais eficiente possível.
Sobre o palestrante: Alexander Karpinsky trabalha na
Uploadcare e está envolvido no serviço de rápida modificação de imagem em tempo real. Ele está envolvido no desenvolvimento do
Pillow , uma biblioteca popular para trabalhar com imagens em Python, e está desenvolvendo seu próprio fork dessa biblioteca, o
Pillow-SIMD , que usa instruções modernas do processador para obter o máximo desempenho.
Antecedentes
O serviço de modificação de imagem do Uploadcare é um servidor que recebe uma solicitação HTTP com um identificador de imagem e algumas operações que um cliente precisa executar. O servidor deve concluir as operações e responder o mais rápido possível. O cliente costuma atuar como um navegador.
Todo o serviço pode ser descrito como um invólucro em torno da biblioteca de gráficos. A qualidade de todo o projeto depende da qualidade, desempenho e usabilidade da biblioteca de gráficos. É fácil adivinhar que o Uploadcare usa Pillow como uma biblioteca de gráficos.
Bibliotecas
Analisaremos brevemente que tipo de bibliotecas gráficas geralmente existem no Python para entender melhor o que será discutido mais adiante.
Travesseiro
Travesseiro - garfo do PIL (Python Imaging Library). Este é um projeto muito antigo, lançado em 1995 para o Python 1.2. Você pode imaginar quantos anos ele tem! Em algum momento, a Python Imaging Library foi abandonada e seu desenvolvimento foi interrompido. Um garfo do Pillow foi criado para instalar e construir a Python Imaging Library em sistemas modernos. Gradualmente, o número de mudanças necessárias para as pessoas na Biblioteca de Imagens Python aumentou e o Pillow 2.0 foi lançado, o que adicionou suporte ao Python 3. Isso pode ser considerado o começo de uma vida separada do projeto Pillow.
Pillow é um módulo nativo para Python, metade do código é escrito em C, metade em Python. As versões mais diversas do Python são suportadas: 2.7, 3.3+, PYP, .
Travesseiro-SIMD
Este é o meu garfo do Pillow, lançado em maio de 2016. SIMD significa Instrução Única, Vários Dados
- Uma abordagem na qual o processador pode executar um número maior de ações por ciclo usando instruções modernas.
Pillow-SIMD não é um garfo no sentido clássico quando um projeto começa a viver sua própria vida. Esta é uma substituição do Pillow, ou seja, você instala uma biblioteca em vez de outra, não altera uma linha no seu código-fonte e obtém mais desempenho.
Pillow-SIMD pode ser montado com instruções SSE4 (padrão). Este é um conjunto de instruções encontradas em quase todos os processadores x86 modernos. O PillD-SIMD também pode ser montado com o conjunto de instruções AVX2. Este conjunto de instruções é, começando com a arquitetura Haswell, ou seja, aproximadamente a partir de 2013.
Opencv
Outra biblioteca para trabalhar com imagens em Python que você provavelmente já ouviu falar é o
OpenCV (Open Computer Vision). Trabalha desde 2000. A ligação Python está incluída. Isso significa que a encadernação é constantemente relevante, não há sincronicidade entre a própria biblioteca e a encadernação.
Infelizmente, essa biblioteca ainda não é suportada no PyPy, porque o OpenCV é baseado em numpy e o numpy só recentemente começou a trabalhar no PyPy, e o PyC ainda não suporta o OpenCV.
VIPS
Outra biblioteca que vale a pena prestar atenção é o VIPS. A idéia principal do
VIPS é que você não precisa carregar a imagem inteira na memória para trabalhar com a imagem. A biblioteca pode carregar alguns pedaços pequenos, processá-los e salvar. Portanto, para processar imagens de gigapixel, você não precisa gastar gigabytes de memória.
Esta é uma biblioteca bastante antiga - 1993, mas ultrapassou seu tempo. Por um longo tempo, pouco se ouviu sobre isso, mas recentemente começaram a aparecer os ligantes do VIPS para vários idiomas, incluindo Go, Node.js e Ruby.
Durante muito tempo, quis experimentar esta biblioteca, senti-la, mas não tive sucesso por uma razão muito estúpida. Não consegui descobrir como instalar o VIPS, porque a ligação era muito complicada. Mas agora (em 2017) o pyvips binding foi liberado pelo próprio autor do VIPS, com o qual não há mais problemas. Instalar e usar o VIPS agora é muito fácil. Suportado: Python 2.7, 3.3+, RuPu, RuPuZ.
ImageMagick e GráficosMagick
Se falamos em trabalhar com gráficos, não podemos deixar de mencionar os idosos - bibliotecas
ImageMagick e
GraphicsMagick . Este último era originalmente um fork do ImageMagick com maior desempenho, mas agora seu desempenho parece ser igual. Até onde eu sei, não há outras diferenças fundamentais entre eles. Portanto, você pode usar qualquer um, mais precisamente, aquele que preferir.
Estas são as bibliotecas mais antigas que mencionei hoje (1990). Durante todo esse tempo, houve vários fichários para o Python, e quase todos eles morreram com segurança até agora. Daqueles que podem ser usados, existem:
- Associação de varinha, que é criada em ctypes, mas também não é mais atualizada.
- A ligação pgmagick usa Boost.Python, portanto, compila por um período muito longo e não funciona no PyPy. Mas, no entanto, você pode usá-lo, eu diria que é preferível ao Wand.
Desempenho
Quando falamos em trabalhar com imagens, a primeira coisa que nos interessa (pelo menos para mim) é o desempenho, porque, caso contrário, poderíamos escrever algo em Python com as mãos.
O desempenho não é uma coisa tão simples. Você não pode simplesmente dizer que uma biblioteca é mais rápida que outra. Cada biblioteca possui um conjunto de funções e cada função funciona em uma velocidade diferente.
Portanto, é correto dizer apenas que o desempenho de uma função é maior ou menor em uma biblioteca específica. Ou você tem um aplicativo que precisa de um certo conjunto de funcionalidades e faz uma referência específica para essa funcionalidade e diz que essa e essa biblioteca funciona mais rápido (mais lentamente) para o seu aplicativo.
É importante verificar o resultado.
Quando você faz benchmarks, é muito importante observar o resultado obtido. Mesmo que você tenha escrito o mesmo código à primeira vista, isso não significa que é o mesmo.
Recentemente, em um artigo comparando o desempenho do Pillow e do OpenCV, deparei-me com este código:
from PIL import Image, ImageFilter.BoxBlur im.filter(ImageFilter.BoxBlur(3)) ... import cv2 cv2.blur(im, ksize=(3, 3)) ...
Parece estar lá, e ali, BoxBlur, e ali, e ali, argumento 3, mas na verdade o resultado é diferente. Porque no Pillow (3) esse é o raio de desfoque e no OpenCV ksize = (3, 3) é o tamanho do kernel, ou seja, o diâmetro. Nesse caso, o valor correto para o OpenCV seria 3 * 2 + 1, ou seja, (7, 7).
Qual é o problema?
Por que o desempenho geralmente é um problema ao trabalhar com gráficos? Como a complexidade de qualquer operação depende de vários parâmetros e, na maioria das vezes, a complexidade cresce linearmente com cada um deles. E se, por exemplo, existem três desses fatores, e a complexidade depende linearmente de cada um, obtemos complexidade em um cubo.
Exemplo: Desfoque Gaussiano no OpenCV.

À esquerda, há um raio de 3, à direita, 30. Como você pode ver, a diferença de velocidade é mais de 10 vezes.
Quando me deparei com a tarefa de adicionar desfoque gaussiano ao meu aplicativo, não fiquei feliz por, hipoteticamente, 900 ms poderem ser gastos em uma operação. Existem milhares de operações desse tipo por minuto no aplicativo, e gastar tanto tempo com um deles é impraticável. Portanto, estudei a questão e implementei o borrão gaussiano no Pillow, que funciona em tempo constante em relação ao raio. Ou seja, apenas o tamanho da imagem afeta o desempenho do desfoque gaussiano.
Mas o principal aqui não é que algo funcione mais rápido ou mais devagar.
Quero transmitir que, quando você está construindo algum tipo de sistema, é importante entender de quais parâmetros depende a complexidade da saída. Em seguida, você pode limitar esses parâmetros ou de outras maneiras para lidar com essa complexidade.
Provavelmente, a operação mais comum que fazemos com as imagens depois que elas são abertas é o redimensionamento.
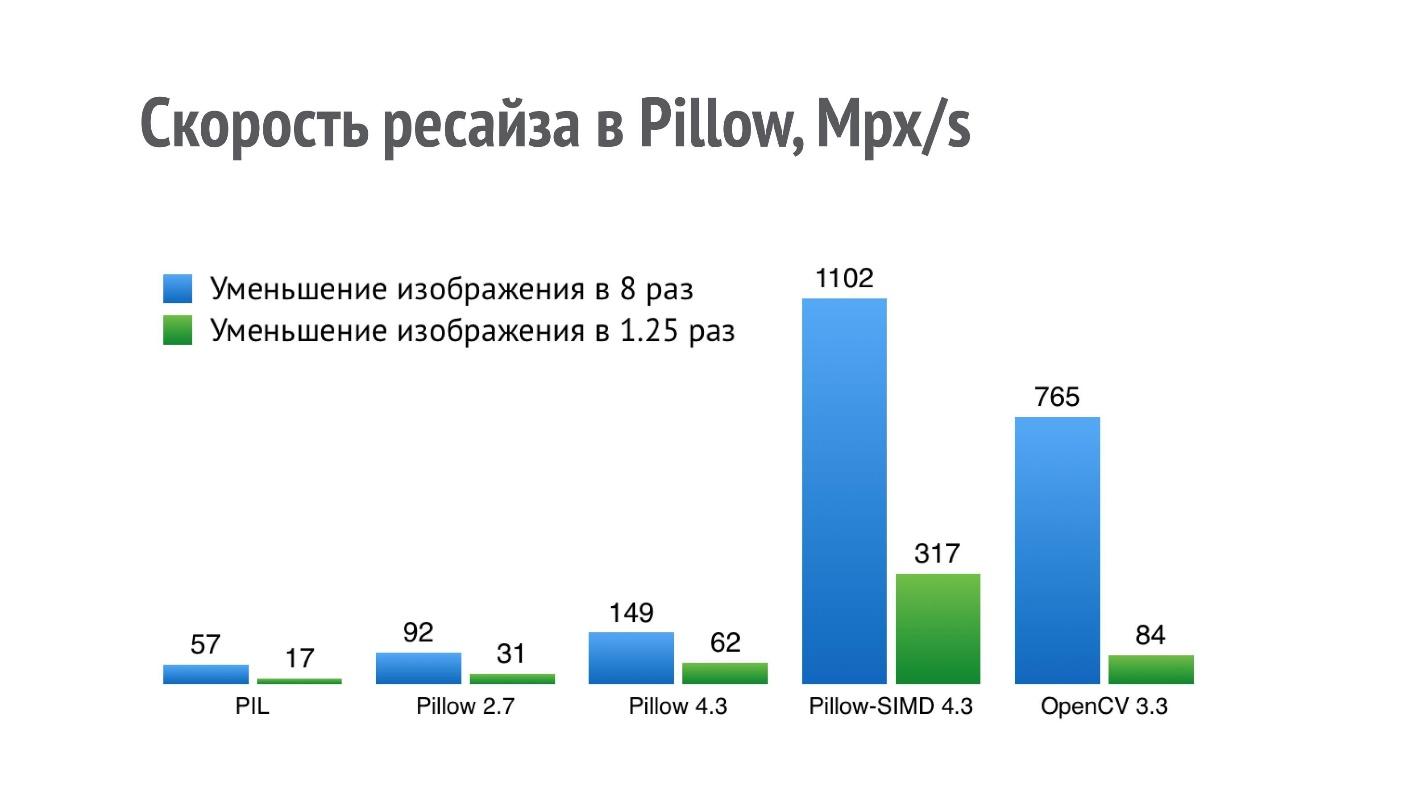
O gráfico mostra o desempenho (mais é melhor) de diferentes bibliotecas para a operação de reduzir a imagem em 8 e 1,25 vezes.
Para PIL, um resultado de 17 Mpx / s significa que a foto de um iPhone (12 Mpx) pode ser reduzida 1,25 vezes um pouco em menos de um segundo. Esse desempenho não é suficiente para um aplicativo sério que executa muitas dessas operações.
Comecei a otimizar o desempenho do redimensionamento e, no Pillow 2.7, consegui um aumento duplo na produtividade e no Pillow 4.3 - três vezes (a versão do Pillow 5.3 é atualmente relevante, mas o desempenho de redimensionamento é o mesmo).
Mas a operação de redimensionamento é algo que se encaixa muito bem no SIMD. Ele aborda instruções únicas, vários dados e, portanto, na versão atual do Pillow-SIMD, eu fui capaz
de aumentar a velocidade de redimensionamento em 19 vezes em comparação com a Python Imaging Library original, usando os mesmos recursos.
Isso é significativamente maior que o desempenho de redimensionamento do OpenCV. Mas a comparação não está totalmente correta, porque o OpenCV usa um método de redimensionamento um pouco menos de alta qualidade com um filtro de caixa e, no Pillow-SIMD, o redimensionamento é implementado usando convoluções.
Esta é uma lista incompleta daquelas operações que são aceleradas no Pillow-SIMD em comparação com o Pillow normal.
- Redimensionar: 4 a 7 vezes.
- Desfoque: 2,8 vezes.
- Aplicação do núcleo 3 × 3 ou 5 × 5: 11 vezes.
- Multiplicação e divisão por canal alfa: 4 e 10 vezes.
- Composição alfa: 5 vezes.
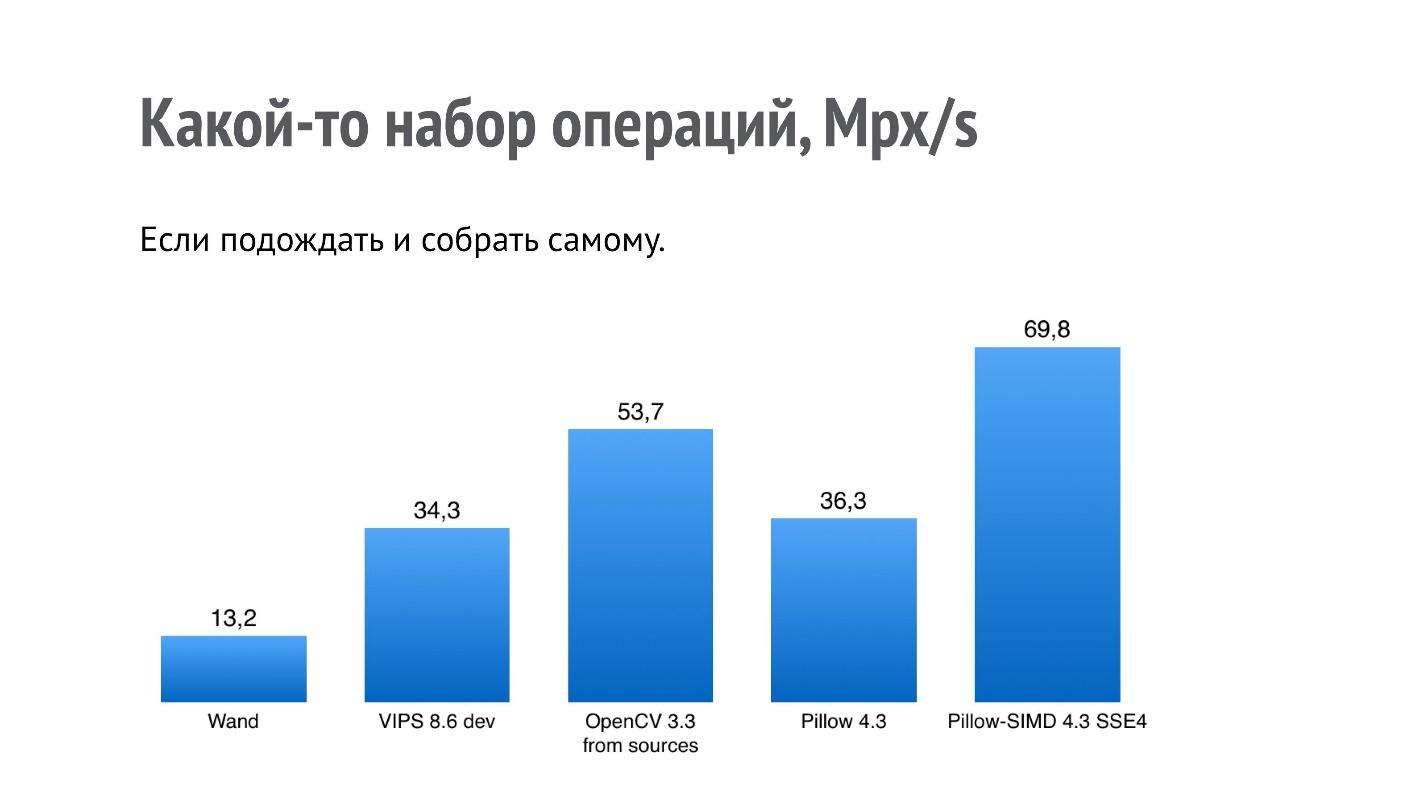
Eu já disse que não se pode dizer que uma biblioteca funciona mais rapidamente que outra, mas você pode criar um conjunto de operações que seja do seu interesse. Eu escolhi um conjunto de operações que são interessantes na minha aplicação, fiz uma referência e obtive esses resultados.

Descobriu-se que o Pillow-SIMD neste conjunto funciona 2 vezes mais rápido que o Pillow. No final está Wand (lembre-se de que é o ImageMagick).
Mas eu estava interessado em outra coisa - por que o OpenCV e o VIPS são tão pobres em resultados, porque essas são bibliotecas que também são projetadas com o objetivo de desempenho? Verificou-se que, no caso do OpenCV, o assembly binário do OpenCV instalado usando o pip foi montado com um codec JPEG lento (o autor do assembly foi notificado, esse problema já foi resolvido para 2018). Ele é construído com libjpeg, enquanto a maioria dos sistemas, pelo menos com base em debian, usa libjpeg-turbo, que é várias vezes mais rápido. Se você mesmo criar o OpenCV a partir da fonte, o desempenho será maior.
No caso do VIPS, a situação é diferente. Entrei em contato com o autor do VIPS, mostrei a ele essa referência e nos correspondemos por muito tempo e proveitosamente. Depois disso, o autor do VIPS encontrou vários locais no próprio VIPS, onde a execução não estava na rota ideal, e os corrigiu.
É o que acontecerá com o desempenho se você criar o OpenCV a partir das fontes da versão atual e o VIPS do master, que já está lá.
Mesmo se você encontrar algum tipo de referência, não é fato que tudo funcionará com essa velocidade exatamente na sua máquina.
Conjunto de benchmarks
Todos os benchmarks de que falei podem ser encontrados na
página de resultados . Este é um mini-projeto separado, onde escrevo benchmarks que eu próprio preciso desenvolver Pillow-SIMD, executá-los e publicar os resultados.
O GitHub tem um
projeto com estruturas de teste onde todos podem oferecer seus próprios benchmarks ou corrigir os existentes.
Trabalho paralelo
Até agora, tenho falado sobre desempenho puro, isto é, em um único núcleo de processador. Mas todos nós há muito tempo temos acesso a sistemas com mais núcleos, e eu gostaria de descartá-los. Aqui, devo dizer que, de fato, o Pillow é a única biblioteca de tudo o que não usa paralelização de tarefas. Vou tentar explicar por que isso acontece. Todas as outras bibliotecas de uma forma ou de outra a usam.
Métricas de desempenho
Em termos de desempenho, estamos interessados em 2 parâmetros:
- Tempo real de execução de uma operação. Existe uma operação (ou uma sequência de operações) e você está se perguntando a que tempo (relógio de parede) essa sequência será executada. Este parâmetro é importante na área de trabalho, onde há um usuário que deu o comando e está aguardando o resultado.
- Taxa de transferência de todo o sistema (fluxo de trabalho). Quando você tem um conjunto de operações em andamento, ou muitas operações independentes, e a velocidade de processamento dessas operações no seu hardware é importante para você. Essa métrica é mais importante em um servidor em que existem muitos clientes e você precisa atendê-los a todos. O tempo que leva para atender um cliente é importante, é claro, mas um pouco menos que a largura de banda total.
Com base nessas duas métricas, consideramos diferentes formas de operação paralela.
Métodos de trabalho paralelo
1.
No nível do aplicativo , quando você decide no nível do aplicativo que as operações são processadas em diferentes segmentos. Ao mesmo tempo, o tempo real de execução de uma operação não muda, porque, como antes, um núcleo está envolvido em uma sequência de operações. A taxa de transferência do sistema cresce proporcionalmente ao número de núcleos, ou seja, muito bom.
2.
No nível das operações gráficas - é exatamente isso que ocorre na maioria das bibliotecas gráficas. Quando uma biblioteca gráfica recebe algum tipo de operação, ela cria o número necessário de threads em si mesma, divide uma operação em várias menores e as executa. Ao mesmo tempo, o tempo real de execução é reduzido - uma operação é mais rápida. Mas a
taxa de transferência não cresce linearmente com o número de núcleos. Existem operações que não são paralelas, e um exemplo impressionante é a decodificação de arquivos PNG - ela não pode ser paralelada de forma alguma. Além disso, existe uma sobrecarga para a criação de threads, dividindo tarefas, que também não permitem que a largura de banda cresça linearmente.
3.
No nível dos comandos e dados do processador . Preparamos os dados de uma maneira especial e usamos comandos especiais para acelerar o processador com eles. Essa é a abordagem SIMD, que, de fato, é usada no Pillow-SIMD. O tempo de execução em tempo real está diminuindo, o rendimento está aumentando -
esta é
uma opção ganha-ganha .
Como combinar trabalho paralelo
Se queremos combinar um trabalho paralelo, o SIMD funciona bem com a paralelização dentro de uma operação e o SIMD funciona bem com a paralelização dentro de um aplicativo.

Mas a paralelização dentro do aplicativo e dentro da operação não é compatível entre si. Se você tentar fazer isso, obterá contras de ambas as abordagens. O tempo real da operação será o mesmo de um núcleo, e a taxa de transferência do sistema aumentará, mas não linearmente em relação ao número de núcleos.
Multithreading
Se estamos falando de threads, todos escrevemos em Python e sabemos que ele possui um GIL que impede a execução de dois threads ao mesmo tempo. Python é uma linguagem estritamente de thread único.
Obviamente, isso não é verdade, porque o GIL na verdade impede a execução de dois threads no Python, e se o código for escrito em outra linguagem e não usar estruturas internas do Python durante sua operação, esse código poderá liberar o GIL e, assim, liberar o intérprete. para outras tarefas.
Muitas bibliotecas gráficas lançam o GIL durante seu trabalho, incluindo Pillow, OpenCV, pyvips, Wand. Apenas um pgmagick não libera. Ou seja, você pode criar threads com segurança para executar algumas operações, e isso funcionará em paralelo com o restante do código.
Mas surge a pergunta:
quantos threads criar?Se criarmos um número infinito de threads para cada tarefa que temos, eles simplesmente ocuparão toda a memória e todo o processador - não obteremos nenhum trabalho efetivo. Eu formulei uma regra especial.
Regra N + 1
Para um trabalho produtivo, você precisa criar não mais que N + 1 trabalhadores, em que N é o número de núcleos ou threads de processador na máquina e o trabalhador é o processo ou thread envolvido no processamento.
Os processos são mais bem utilizados, porque mesmo dentro do mesmo intérprete há gargalos e sobrecarga.
Por exemplo, em nossa aplicação, é usada a instância N + 1 Tornado, cujo equilíbrio é realizado pelo ngnix. Se o Tornado for mencionado, vamos falar sobre operação assíncrona.
Operação assíncrona
O tempo em que a biblioteca gráfica realiza um trabalho realmente útil - processamento de imagem - pode e deve ser usado para entrada / saída, se você os tiver no aplicativo. Estruturas assíncronas são muito relevantes aqui.
Mas há um problema - quando chamamos algum tipo de processamento, ele é chamado de forma síncrona. Mesmo que a biblioteca libere o GIL naquele momento, o loop de eventos ainda está bloqueado.
@gen.coroutine def get(self, *args, **kwargs): im = process_image(...) ...
Felizmente, esse problema é muito fácil de resolver, criando um ThreadPoolExecutor com um único thread no qual o processamento da imagem é iniciado. Essa chamada já está acontecendo de forma assíncrona.
@run_on_executor(executor=ThreadPoolExecutor(1)) def process_image(self, ... @gen.coroutine def get(self, *args, **kwargs): im = yield process_image(...) ...
Essencialmente, aqui é criada uma fila com um trabalhador que executa operações gráficas, e o Loop de Eventos não é bloqueado e silenciosamente é executado em paralelo em outro encadeamento.
Entrada / saída
Outro tópico que gostaria de abordar na discussão de operações gráficas é entrada / saída. O fato é que raramente criamos qualquer tipo de imagem usando uma biblioteca de gráficos. Na maioria das vezes, abrimos imagens que chegam até nós de usuários na forma de arquivos codificados (JPEG, PNG, BMP, TIFF etc.).
Assim, a biblioteca de gráficos para criar um bom aplicativo deve ter alguns benefícios para entrada / saída de arquivos.
Carregamento lento
O primeiro desses bolos é o carregamento preguiçoso. Se, por exemplo, no Pillow você abre uma imagem, nesse momento a decodificação da imagem não ocorre. Você retorna com um objeto que parece que a imagem já está carregada e funcionando. Você pode examinar suas propriedades e decidir, com base nas propriedades desta imagem, se está pronto para continuar a trabalhar com ela, se o usuário tiver baixado, por exemplo, uma imagem de gigapixel para interromper seu serviço.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345))
Se você decidir o que fazer em seguida, usando a chamada explícita ou implícita para carregar, essa imagem será decodificada. Já neste momento a quantidade necessária de memória está alocada.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345)) >>> %time im.load() Wall time: 73.6 ms
Modo de imagem quebrada
O segundo item necessário ao trabalhar com conteúdo gerado pelo usuário é o modo de imagem interrompida. Os arquivos que recebemos dos usuários geralmente contêm algumas inconsistências com o formato em que são codificados.
Essas discrepâncias ocorrem por vários motivos. Às vezes, esses são erros de transmissão na rede, às vezes, são apenas algum tipo de codec torto que codifica a imagem. Por padrão, Pillow, quando vê imagens que não se ajustam ao formato até o fim, apenas lança uma exceção.
from PIL import Image Image.open('trucated.jpg').save('trucated.out.jpg') IOError: image file is truncated (143 bytes not processed)
Mas o usuário não é o culpado pelo fato de sua imagem estar quebrada, ele ainda deseja obter o resultado. Felizmente, o Pillow possui um modo de imagem quebrado. Alteramos uma configuração e o Pillow tenta ignorar ao máximo todos os erros de decodificação que estão na imagem. Assim, o usuário vê pelo menos alguma coisa.
from PIL import Image, ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True Image.open('trucated.jpg').save('trucated.out.jpg')

Mesmo uma imagem cortada ainda é melhor do que nada - apenas uma página com erro.
Tabela Resumo
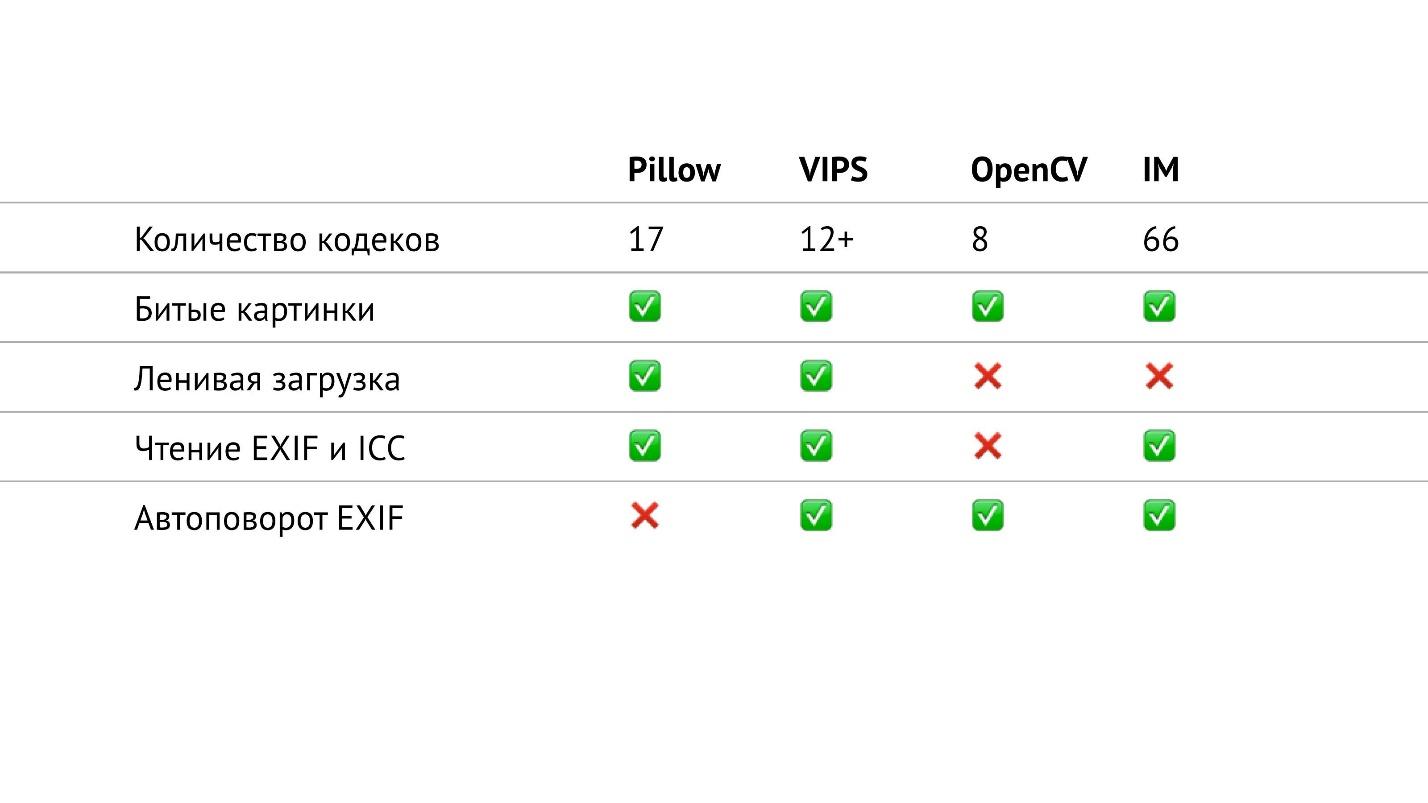
Na tabela acima, coletei tudo relacionado à entrada / saída nas bibliotecas de que estou falando. Em particular, contei o número de codecs de vários formatos que estão nas bibliotecas. Descobriu-se que no OpenCV eles são os menores, no ImageMagick - os mais. Parece que no ImageMagick você pode abrir qualquer imagem que encontrar. O VIPS possui 12 codecs nativos, mas o VIPS pode usar o ImageMagick como intermediário. Eu não testei como isso funciona, espero que seja perfeito.
Pillow possui 17 codecs. Agora é a única biblioteca na qual não há rotação automática EXIF. Mas agora esse é um pequeno problema, porque você pode ler EXIF e girar a imagem de acordo com ela. É uma questão de um pequeno trecho, que é facilmente google e leva no máximo 20 linhas.
Recursos do OpenCV
Se você olhar atentamente esta tabela, poderá ver que no OpenCV, de fato, nem tudo é tão bom com entrada / saída. Possui o menor número de codecs, sem carregamento lento e você não pode ler EXIF e o perfil de cores.
Mas isso não é tudo. De fato, o OpenCV tem mais recursos. Quando simplesmente abrimos uma imagem, a
cv2.imread(filename) gira os arquivos JPEG de acordo com EXIF (consulte a tabela), mas ignora o canal alfa dos arquivos PNG - um comportamento bastante estranho!
Felizmente, o OpenCV possui um sinalizador:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED) .
Se você especificar o sinalizador IMREAD_UNCHANGED, o OpenCV deixará o canal alfa para arquivos PNG, mas parará de transformar arquivos JPEG de acordo com EXIF. Ou seja, o mesmo sinalizador afeta duas propriedades completamente diferentes. Como pode ser visto na tabela, o OpenCV não tem a capacidade de ler EXIF e, no caso desse sinalizador, é impossível girar o JPEG.
E se você não souber com antecedência qual é o formato da sua imagem e precisar do canal alfa para PNG e da rotação automática para JPEG? Nada a fazer - o OpenCV não funciona assim.
A razão pela qual o OpenCV tem esses problemas está no nome desta biblioteca. Possui muitas funcionalidades para visão de computador e análise de imagens. De fato, o OpenCV foi projetado para funcionar com fontes verificadas. Esta é, por exemplo, uma câmera de vigilância externa que tira as imagens uma vez por segundo e faz isso por 5 anos no mesmo formato e na mesma resolução. Não há necessidade de variabilidade no problema de E / S.
As pessoas que precisam da funcionalidade OpenCV realmente não precisam da funcionalidade de conteúdo do usuário.
Mas e se o seu aplicativo ainda precisar de funcionalidade para trabalhar com o conteúdo do usuário e, ao mesmo tempo, você precisar de todo o poder do OpenCV para processamento e estatísticas?

A solução é combinar bibliotecas. O fato é que o OpenCV é construído com base no numpy, e o Pillow tem todos os meios para exportar imagens do Pillow para um array numpy. Ou seja, exportamos a matriz numpy, e o OpenCV pode continuar trabalhando com essa imagem, assim como com a sua. Isso é feito com muita facilidade:
import numpy from PIL import Image ... pillow_image = Image.open(filename) cv_image = numpy.array(pillow_image)
Além disso, quando fazemos mágica usando OpenCV (processamento), chamamos outro método Pillow e importamos a imagem do OpenCV de volta para o formato Pillow. Consequentemente, a E / S pode ser usada novamente.
import numpy from PIL import Image ... pillow_image = Image.fromarray(cv_image, "RGB") pillow_image.save(filename)
Assim, acontece que usamos entrada / saída do Pillow e o processamento do OpenCV, ou seja, pegamos o melhor dos dois mundos.
Espero que isso ajude a criar um aplicativo gráfico carregado.
Você pode aprender outros segredos de desenvolvimento em Python, aprender com experiências inestimáveis e às vezes inesperadas e, o mais importante, discutir suas tarefas muito em breve no Moscow Python Conf ++ . Por exemplo, preste atenção a esses nomes e tópicos na programação.
- Donald Whyte, com uma história sobre como tornar a matemática 10 vezes mais rápida usando bibliotecas populares, truques e esperteza, e o código é compreensível e suportado.
- Andrei Popov trata de coletar uma enorme quantidade de dados e analisá-los em busca de ameaças.
- Ephraim Matosyan em seu relatório “Torne o Python rápido novamente” mostrará como aumentar o desempenho do daemon que processa mensagens do barramento.
Uma lista completa do que será discutido para 22 e 23 de outubro aqui , tem tempo para participar.