Olá pessoal!
Enquanto
Leonid se prepara para sua primeira
lição aberta em nosso curso
Linux Administrator , continuamos a falar sobre o carregamento do kernel do Linux.
Vamos lá!
Entendendo como um sistema funciona sem falhas - Preparando-se para corrigir as falhas inevitáveis
A piada mais antiga do campo de código aberto é a afirmação de que "o código documenta a si próprio". A experiência mostrou que ler o código-fonte é como ouvir previsões do tempo: pessoas inteligentes ainda saem para olhar o céu. Abaixo estão algumas dicas para verificar e examinar a inicialização do sistema Linux usando ferramentas familiares de depuração. Uma análise do processo de inicialização de um sistema que funciona bem prepara usuários e desenvolvedores para resolver falhas inevitáveis.
Por um lado, o processo de download é surpreendentemente simples. O kernel do sistema operacional (kernel) é executado de thread único e de forma síncrona em um core (core), que pode parecer compreensível até para uma mente humana patética. Mas como o kernel do sistema operacional é iniciado? Quais funções o initrd (
um disco RAM para inicialização ) e os gerenciadores de inicialização? E espere, por que o LED na porta Ethernet está sempre aceso?

Continue lendo para obter respostas para essas e algumas outras perguntas; O código para as demos e exercícios descritos também está disponível no
GitHub .
Início da inicialização: status OFFWake-on-LANUm status OFF significa que o sistema não tem energia, certo? A aparente simplicidade é enganadora. Por exemplo, o LED Ethernet está aceso mesmo nesse estado, porque a ativação em LAN (WOL, ativação em [sinal da] rede local) está ativada em seu sistema. Certifique-se de escrever:
$# sudo ethtool <interface name>
Onde, em vez disso, pode estar, por exemplo, eth0 (ethtool está em pacotes Linux com o mesmo nome). Se a opção "
Ativar " na saída mostrar g, hosts remotos poderão inicializar o sistema enviando
MagicPacket . Se você não deseja ligar remotamente o seu sistema e dar essa oportunidade a outras pessoas, desative o WOL no menu BIOS do sistema ou use:
$# sudo ethtool -s <interface name> wol d
Um processador que responde ao MagicPacket pode ser um BMC (
Baseboard Management Controller ) ou parte de uma interface de rede.
Mecanismo de gerenciamento Intel, Hub do controlador de plataforma e MinixO BMC não é o único microcontrolador (MCU) que pode "ouvir" um sistema desligado nominalmente. Os sistemas X86_64 possuem o pacote de software Intel Management Engine (IME) para gerenciamento de sistemas remotos. Uma ampla variedade de dispositivos, de servidores a laptops, possui tecnologia que
possui recursos como o KVM Remote Control ou o Intel Capability Licensing Service. De acordo com a
própria ferramenta de Inte l, o
IME possui vulnerabilidades sem patches. A má notícia é que desativar o IME é difícil. Trammell Hudson criou
o projeto me_cleaner, que apaga alguns dos componentes mais flagrantes do IME, como o servidor da Web incorporado, mas ao mesmo tempo há uma chance de que o uso do projeto torne o sistema no qual está sendo executado.
O firmware IME e o programa SMM (System Management Mode) que o seguem na inicialização são baseados no
sistema operacional Minix e executados em um processador separado do Platform Controller Hub, não na CPU principal do sistema. Em seguida, o SMM lança o programa UEFI (Universal Extensible Firmware Interface) no processador principal, que foi
escrito mais de uma vez . O grupo Coreboot lançou no Google um projeto espetacularmente ambicioso
de firmware não extensível a reduções (NERF) , que visa substituir não apenas a UEFI, mas também os primeiros componentes do espaço do usuário Linux, como systemd. Enquanto isso, estamos aguardando os resultados, os usuários do Linux podem comprar laptops da Purism, System76 ou Dell, nos quais o
IME está desativado , além disso, podemos esperar laptops com um
processador ARM de 64 bits .
Carregadeiras
O que o firmware inicializável faz além do lançamento do spyware suspeito? A tarefa do carregador de inicialização é fornecer ao processador que acabou de ser ativado os recursos necessários para executar um sistema operacional de uso geral como o Linux. Durante a inicialização, não há apenas memória virtual, mas também DRAM até o momento de elevar seu controlador. O carregador de inicialização liga as fontes de alimentação e varre os barramentos e interfaces para encontrar a imagem do kernel e o sistema de arquivos raiz. Carregadores de inicialização populares, como U-Boot e GRUB, suportam interfaces comuns como USB, PCI e NFS, além de outros dispositivos embarcados mais especializados, como NOR e NAND-flash. Os carregadores também interagem com dispositivos de hardware de segurança, como o
Trusted Platform Module (TPM) , para estabelecer uma cadeia de confiança desde o início do download.
 Executando o carregador de inicialização em U na caixa de areia no servidor de compilação.
Executando o carregador de inicialização em U na caixa de areia no servidor de compilação.O popular gerenciador de
inicialização U-Boot de código aberto é suportado por sistemas do Raspberry Pi a dispositivos Nintendo, placas para carros e Chromebooks. Não há registro do sistema e, se algo der errado, pode até não haver saída do console. Para facilitar a depuração, a equipe do U-Boot fornece uma caixa de proteção para testar patches no host de compilação ou mesmo no sistema de Integração Contínua. Em um sistema com ferramentas de desenvolvimento comuns como o Git e o GNU Compiler Collection (GCC) instalado, é fácil entender a sandbox do U-Boot.
$# git clone git://git.denx.de/u-boot; cd u-boot $# make ARCH=sandbox defconfig $# make; ./u-boot => printenv => help
Isso é tudo: você lançou o U-Boot no x86_64 e pode testar recursos complicados, por exemplo, reparticionamento de
dispositivos de armazenamento fictícios , manipulação de chave secreta baseada em TPM e hotplug de dispositivos USB. A caixa de proteção U-Boot pode ser de um estágio no depurador GDB. O desenvolvimento usando a sandbox é 10 vezes mais rápido que o teste, substituindo o gerenciador de inicialização no quadro; além disso, a sandbox "brick" pode ser restaurada pressionando Ctrl + C.
Lançamento do kernelInicializando o fornecimento do kernelApós a conclusão de suas tarefas, o carregador de inicialização alternará para o código do kernel que ele carregou na memória principal e começará a executá-lo, passando todos os parâmetros da linha de comando especificados pelo usuário. Qual programa é o kernel? O arquivo / boot / vmlinuz mostra que é o bzImage. A árvore de origem do Linux possui
uma ferramenta extract-vmlinux que você pode usar para extrair o arquivo:
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux $# file vmlinux vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, stripped
O kernel é um arquivo binário
Executable and Linking Format (ELF) , como os programas de espaço para usuário do Linux. Isso significa que podemos usar comandos binutils como readelf para aprendê-lo. Compare, por exemplo, as seguintes conclusões:
$# readelf -S /bin/date $# readelf -S vmlinux
A lista de partições em arquivos binários é quase sempre semelhante.
Portanto, o kernel deve lançar outros binários ELF Linux ... Mas como os programas de espaço do usuário são executados? Na função
main() , certo? Na verdade não.
Antes de executar a função
main() , os programas precisam de um contexto de execução, incluindo memória heap- (heap) e stack- (stack), além de descritores de arquivo para
stdio ,
stdout e
stderr . Os programas de espaço do usuário obtêm esses recursos da biblioteca padrão (
glibc para a maioria dos sistemas Linux). Considere o seguinte:
$# file /bin/date /bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a, stripped
Os binários ELF têm um intérprete, assim como os scripts Bash e Python. Mas não precisa ser especificado através de
#! como nos scripts, porque o ELF é um formato nativo do Linux. O interpretador ELF fornece ao arquivo binário todos os recursos necessários, chamando
_start() , uma função disponível no pacote de origem
glibc , que pode ser aprendida através do
GDB . O kernel, obviamente, não possui um intérprete e deve se fornecer independentemente, mas como?
Um estudo sobre como iniciar um kernel com GDB fornece uma resposta para esta pergunta. Para começar, instale o pacote de depuração do kernel, que contém a versão sem cortes do
vmlinux , por exemplo,
apt-get install linux-image-amd64-dbg . Ou compile e instale seu próprio kernel de alguma fonte, por exemplo, seguindo as instruções do excelente
Debian Kernel Handbook .
gdb vmlinux seguido pelos
info files mostra a seção ELF
init.text . Indique o início da execução do programa no
init.text com
l *(address) , em que endereço é o início hexadecimal do
init.text . O GDB indicará que o kernel x86_64 é iniciado no
arch/x86/kernel/head_64.S , onde encontramos a função build
start_cpu0() e o código que cria explicitamente a pilha e descompacta o zImage antes de chamar
x86_64 start_kernel() . Os núcleos ARM de 32 bits têm um
arch/arm/kernel/head.S. start_kernel() arch/arm/kernel/head.S. start_kernel() é independente da arquitetura, portanto, a função está localizada no kernel
init/main.c Podemos dizer que
start_kernel() é uma função real
main() Linux.
Do start_kernel () ao PID 1Manifesto de hardware do kernel: tabelas ACPI e árvores de dispositivosAo inicializar, o kernel precisa de informações sobre o hardware, além do tipo de processador para o qual foi compilado. As instruções no código são complementadas por dados de configuração, que são armazenados separadamente. Existem dois métodos principais para armazenar dados:
Árvores de dispositivos e
tabelas ACPI . A partir desses arquivos, o kernel descobre qual equipamento precisa ser executado em cada inicialização.
Para dispositivos incorporados, a árvore de dispositivos (DU) é um manifesto do equipamento instalado. DU é um arquivo que é compilado ao mesmo tempo que a fonte do kernel e geralmente está localizado em / boot junto com o
vmlinux . Para ver o que há na árvore de dispositivos binários no dispositivo ARM, basta usar o comando
strings do pacote binutils no arquivo cujo nome corresponde a
/boot/*.dtb , pois
dtb significa o arquivo binário da árvore de dispositivos (Device-Tree Binary). Você pode alterar o controle remoto editando os arquivos semelhantes a JSON nos quais ele consiste e reiniciando o compilador dtc especial fornecido com a fonte do kernel. DU é um arquivo estático cujo caminho geralmente é passado para o kernel por gerenciadores de inicialização na linha de comando, mas nos últimos anos uma
sobreposição de árvore de dispositivo foi adicionada, na qual o kernel pode carregar dinamicamente fragmentos adicionais em resposta a eventos de hotplug após o carregamento.
A família x86 e muitos dispositivos no nível de negócios ARM64 usam o mecanismo alternativo
ACPI (Advanced Configuration and Power Interface
) . Diferentemente do controle remoto, as informações da ACPI são armazenadas no sistema de arquivos virtual
/sys/firmware/acpi/tables , criado pelo kernel na inicialização, acessando a ROM interna. Para ler tabelas ACPI, use o comando
acpica-tools pacote
acpica-tools . Aqui está um exemplo:
 As tabelas ACPI nos laptops Lenovo estão prontas para o Windows 2001.
As tabelas ACPI nos laptops Lenovo estão prontas para o Windows 2001.Sim, seu sistema Linux está pronto para o Windows 2001, se você deseja instalá-lo. A ACPI possui métodos e dados, em contraste com o controle remoto, que é mais como uma linguagem de descrição de hardware. Os métodos ACPI continuam ativos após a inicialização. Por exemplo, se você executar o comando acpi_listen (do pacote apcid) e fechar e abrir a tampa do laptop, veremos que a funcionalidade da ACPI continuou funcionando todo esse tempo. É possível
reescrever temporariamente e dinamicamente as
tabelas ACPI , mas as alterações permanentes exigirão interação com o menu do BIOS na inicialização ou na atualização da ROM. Em vez de tais complexidades, talvez você deva
instalar o coreboot , um substituto para o firmware de código aberto.
Do start_kernel () ao espaço do usuário
O código em
init/main.c é surpreendentemente fácil de ler e, curiosamente, ainda possui os direitos autorais originais de Linus Torvalds de 1991-1992. Linhas encontradas em
dmesg | head dmesg | head sistema em execução se origina basicamente desse arquivo de origem. A primeira CPU é registrada pelo sistema, as estruturas de dados globais são inicializadas, uma após a outra, o agendador, manipuladores de interrupção (IRQs), temporizadores e console são gerados. Todos os registros de data e hora antes de executar
timekeeping_init() são zero. Essa parte da inicialização do kernel é síncrona, ou seja, a execução ocorre em apenas um encadeamento. As funções não são executadas até a última delas ser concluída e retornada. Como resultado, a saída do
dmesg será totalmente reproduzível mesmo entre os dois sistemas, desde que eles tenham as mesmas tabelas de controle remoto ou ACPI. O Linux também se comporta como um sistema operacional em tempo real (RTOS) em execução em um MCU, como QNX ou VxWorks. Essa situação é armazenada na função
rest_init() , chamada por
start_kernel() no momento de sua conclusão.
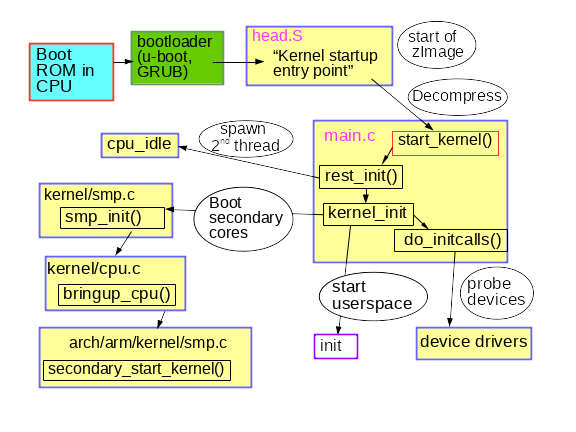 Uma breve descrição do processo inicial de inicialização do kernel
Uma breve descrição do processo inicial de inicialização do kernel
O nome modesto
rest_init() cria um novo thread que executa
kernel_init() , que por sua vez chama
do_initcalls() . Os usuários podem monitorar a operação de
initcalls adicionando
initcalls_debug à linha de comando do kernel. Como resultado, você obterá a entidade
dmesg toda vez que executar a função
initcall .
initcalls passa por sete níveis consecutivos: early, core, postcore, arch, subsys, fs, device e late. A parte mais notável do
initcalls para os usuários é a identificação e instalação de dispositivos periféricos do processador: barramentos, rede, armazenamento, monitores e assim por diante, acompanhados pelo carregamento de seus módulos do kernel.
rest_init() também cria um segundo encadeamento no processador de inicialização, que começa executando
cpu_idle() enquanto o planejador distribui seu trabalho.
kernel_init() também configura o
multiprocessamento simétrico (SMP). Nos kernels modernos, você pode encontrar esse momento na saída dmesg na linha “Trazendo CPUs secundárias ...”. O SMP então faz o hot plug da CPU, o que significa que ele gerencia seu ciclo de vida usando uma máquina de estado condicionalmente semelhante àquelas usadas em dispositivos como cartões de memória USB com detecção automática. O sistema de gerenciamento de energia do kernel geralmente desliga núcleos individuais (núcleos) e os ativa conforme necessário, para que o mesmo código da CPU de hotplug seja chamado repetidamente em uma máquina desocupada. Veja como um sistema de gerenciamento de energia chama um hotplug da CPU usando
uma ferramenta BCC chamada
offcputime.py .
Observe que o código em
init/main.c quase terminou de executar quando
smp_init() executado. O processador de inicialização concluiu a maior parte da inicialização única, que outros kernels não precisam repetir. No entanto, os threads devem ser criados para cada núcleo para controlar interrupções (IRQs), fila de trabalho, temporizadores e eventos de energia em cada um. Por exemplo, observe os encadeamentos do processador que atendem softirqs e linhas de trabalho com o comando
ps -o psr. psr
ps -o psr. $\
onde o campo PSR significa "processador". Cada núcleo deve ter seus próprios temporizadores e manipuladores de hotplug cpuhp.
E, finalmente, como o espaço do usuário é lançado? No final, o
kernel_init() procurando por um
initrd que possa iniciar o processo
init em seu nome. Caso contrário, o kernel executa o
init sozinho. Por que então o
initrd pode ser necessário?
Espaço inicial do usuário: quem solicitou o initrd?Além da árvore de dispositivos, outro caminho init para o arquivo, opcionalmente fornecido pelo kernel na inicialização, pertence ao
initrd .
initrd geralmente
initrd localizado em / boot junto com o arquivo bzImage vmlinuz no x86, ou com uma uImage e uma árvore de dispositivos semelhantes para o ARM. Uma lista do conteúdo
intrd pode ser visualizada usando a ferramenta
lsinitramfs , que faz parte do pacote
initramfs-tools-core . A imagem de distribuição do initrd contém os diretórios mínimos
/bin ,
/sbin e
/etc , além de módulos e arquivos do kernel em
/scripts . Tudo deve parecer mais ou menos familiar, já que o
initrd em grande parte semelhante ao sistema de arquivos raiz simplificado do Linux. Essa semelhança é um pouco enganadora, já que quase todos os executáveis em
/bin e
/sbin dentro do ramdisk são links simbólicos para o
binário BusyBox , o que torna os diretórios / bin e / sbin 10 vezes menores do que na
glibc .
Por que tentar criar um
initrd se a única coisa que ele faz é carregar alguns módulos e executar
init em um sistema de arquivos raiz normal? Considere um sistema de arquivos raiz criptografado. A descriptografia pode depender do carregamento do módulo do kernel armazenado em
/lib/modules sistema de arquivos raiz ... e, como esperado, no
initrd . O módulo de criptografia pode ser estaticamente compilado no kernel e não carregado a partir de um arquivo, mas há vários motivos para recusar isso. Por exemplo, a compilação estática de um kernel com módulos pode torná-lo muito grande para caber no armazenamento disponível ou a compilação estática pode violar os termos de licença do software. Sem surpresa, drivers de armazenamento, redes e HIDs (dispositivos de entrada humanos) também podem ser representados no
initrd - essencialmente qualquer código que não seja uma parte necessária do kernel necessária para montar o sistema de arquivos raiz. Também no initrd, os usuários podem armazenar
seu próprio código ACPI para tabelas .
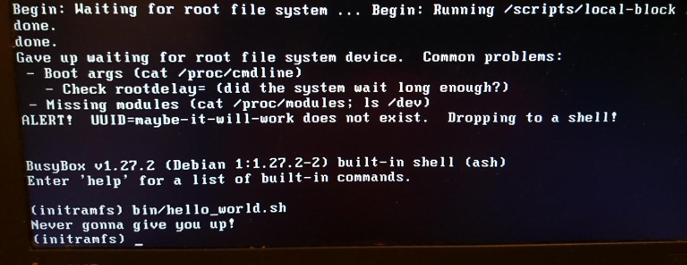 Diversão com shell de resgate e initrd personalizado.
Diversão com shell de resgate e initrd personalizado.initrd também
initrd ótimo para testar sistemas de arquivos e dispositivos de armazenamento. Coloque as ferramentas de teste no
initrd e execute os testes da memória, não do objeto de teste.
Finalmente, quando o
init execução, o sistema está em execução! Como os processadores secundários já estão em execução, a máquina se tornou uma criatura assíncrona, paginada, imprevisível e de alto desempenho que todos conhecemos e amamos. De fato,
ps -o pid,psr,comm -p indica que o processo de
init espaço do usuário não está mais em execução no processador de inicialização.
SumárioO processo de inicialização do Linux parece proibido, dada a quantidade de software afetada, mesmo em um simples dispositivo incorporado. Por outro lado, o processo de inicialização é bastante simples, pois não há complexidade excessiva causada pela exclusão de multitarefa, RCU e condições de corrida. Prestando atenção apenas ao kernel e ao PID 1, é possível ignorar o excelente trabalho realizado pelos gerenciadores de inicialização e processadores auxiliares para preparar a plataforma para o lançamento do kernel. O kernel certamente é diferente de outros programas Linux, mas o uso de ferramentas para trabalhar com outros binários ELF ajudará a entender melhor sua estrutura. Estudar um processo de inicialização viável se preparará para futuras falhas.
O FIM
Estamos aguardando seus comentários e perguntas, como de costume, aqui ou na nossa
aula aberta, onde Leonid será surpreendido.