Essence
Acontece que, para isso, basta executar exatamente esse conjunto de comandos:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
e depois polir um pouco com um script para pós-processamento
python3 process_wikipedia.py
O resultado é um arquivo .csv finalizado com seu corpo.
É claro que:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 pode ser alterado para o idioma necessário, mais detalhes aqui [4] ;- Todas as informações sobre os parâmetros do
wikiextractor podem ser encontradas no manual (parece que até o dock oficial não foi atualizado, diferentemente do mana);
Um script de pós-processamento converte arquivos wiki em uma tabela como esta:
| idx | article_uuid | sentença | frase limpa | duração da sentença limpa |
|---|
| 0 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (conde de Pentevre) Jean I de ... | jean i de châtillon conde de pentevre jean i de cha ... | 38. |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Esteve sob a proteção de Robert de Vera, conde O ... | foi guardado por robert de vera graph oxford ... | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | No entanto, Henry de Gromont, gr ... | no entanto, Henry de Gromon gras se opôs a isso ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | O rei ofereceu-lhe outra característica importante como esposa ... | o rei ofereceu à esposa outra pessoa importante de fili ... | 48. |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean foi libertado e voltou à França em 138 ... | Jean libertado volta França ano casamento m ... | 52 |
article_uuid - uma chave pseudo-exclusiva, a ordem das ideias deve ser preservada após esse pré-processamento.
Porque
Talvez, no momento, o desenvolvimento de ferramentas ML tenha atingido tal nível [8] que, literalmente, alguns dias seja suficiente para construir um modelo / pipeline de PNL em funcionamento. Os problemas surgem apenas na ausência de conjuntos de dados confiáveis / modelos incorporados / linguagem pronta. O objetivo deste artigo é aliviar um pouco a sua dor, mostrando que algumas horas são suficientes para processar toda a Wikipedia (em teoria, o corpus mais popular para o treinamento de incorporação de palavras na PNL). Afinal, se alguns dias são suficientes para criar um modelo simples, por que gastar muito mais tempo obtendo dados para esse modelo?
O princípio do script
wikiExtractor salva artigos do Wiki como texto separado por blocos <doc> . Na verdade, o script é baseado na seguinte lógica:
- Faça uma lista de todos os arquivos na saída;
- Dividimos arquivos em artigos;
- Remova todas as tags HTML restantes e caracteres especiais;
- Usando
nltk.sent_tokenize dividimos em sentenças; - Para que o código não cresça em tamanho enorme e permaneça legível, cada artigo recebe seu próprio uuid;
Como pré-processamento de texto, é simples (você pode cortá-lo facilmente):
- Excluir caracteres que não sejam letras;
- Excluir palavras de parada;
Conjunto de dados é, e agora?
Aplicação principal
Na maioria das vezes, na prática, na PNL, você precisa lidar com a tarefa de construir casamentos.
Para resolvê-lo, geralmente use uma das seguintes ferramentas:
- Vetores prontos / incorporação de palavras [6];
- Os estados internos da CNN treinaram em tarefas como definir frases falsas / modelagem / classificação de linguagem [7];
- Uma combinação dos métodos acima;
Além disso, já foi demonstrado muitas vezes [9] que como uma boa linha de base para a incorporação de frases, também é possível obter vetores de palavras com média (com alguns detalhes menores, que serão omitidos agora).
Outros casos de uso
- Usamos frases aleatórias do Wiki como exemplos negativos para perda de trigêmeos;
- Nós treinamos codificadores para frases usando a definição de frases falsas [10];
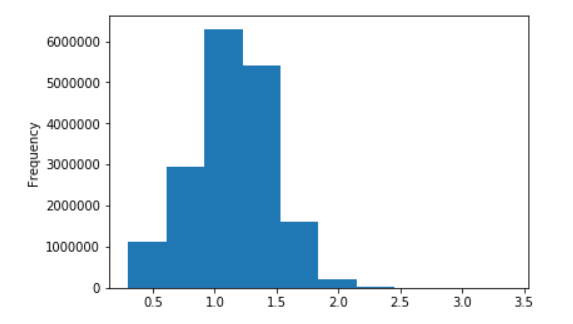
Alguns gráficos para o Russian Wiki
Distribuição do comprimento das frases da Wikipedia em russo
Sem logaritmos (no eixo X, os valores são limitados a 20)
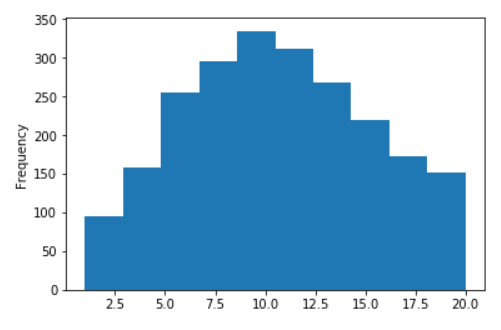
Em logaritmos decimais
Referências
- Vetores de palavras de texto rápido treinados em um wiki;
- Modelos de texto rápido e Word2Vec para o idioma russo;
- Biblioteca extratora wiki impressionante para python;
- A página oficial com links para Wiki;
- Nosso script para pós-processamento;
- Principais artigos sobre incorporação de palavras: Word2Vec , Fast-Text , tuning ;
- Várias abordagens SOTA atuais:
- InferSent ;
- CNN pré-treinamento generativo;
- ULMFiT ;
- Abordagens contextuais para a representação de palavras (Elmo);
- Momento Imagenet na PNL ?
- Linhas de base para incorporar as propostas 1 , 2 , 3 , 4 ;
- Definição de frases falsas para codificador de oferta;