Olá pessoal.
Ele escreveu uma biblioteca para treinar uma rede neural. Quem se importa, por favor.
Há muito que eu queria me tornar um instrumento desse nível. No verão, ele começou a trabalhar. Aqui está o que aconteceu:
- a biblioteca foi escrita do zero em C ++ (apenas STL + OpenBLAS para cálculo), interface C, win / linux;
- estrutura de rede é especificada em JSON;
- camadas de base: totalmente conectadas, convolucionais, agrupadas. Adicional: redimensionar, cortar ..;
- recursos básicos: batchNorm, desistência, otimizadores de peso - adam, adagrad ..;
- O OpenBLAS é usado para calcular a CPU, CUDA / cuDNN para a placa de vídeo. Ele também colocou a implementação no OpenCL, para o futuro;
- para cada camada, há uma oportunidade de definir separadamente o que considerar - CPU ou GPU (e qual);
- o tamanho dos dados de entrada não está definido rigidamente, pode mudar durante o trabalho / treinamento;
- fez interfaces para C ++ e Python. C # virá mais tarde também.
A biblioteca foi chamada SkyNet. (Tudo é complicado com nomes, outros eram opções, mas algo não está certo ..)
Comparação com PyTorch usando o exemplo MNIST:
PyTorch: Precisão: 98%, Tempo: 140 seg
SkyNet: Precisão: 95%, Tempo: 150 seg
Máquina: i5-2300, GF1060. Código de teste.
Arquitetura de software
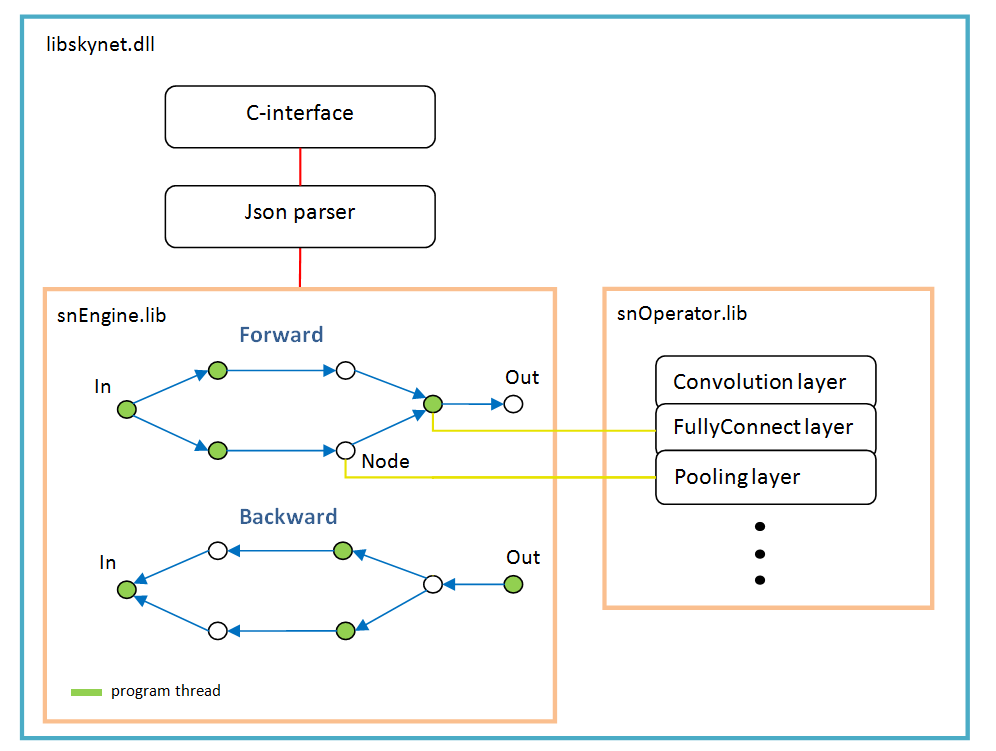
Ele se baseia em um gráfico de operações que é criado dinamicamente uma vez após a análise da estrutura da rede.
Para cada ramificação, um novo encadeamento. Cada nó da rede (Nó) é uma camada de cálculo.
Existem características do trabalho:
- função de ativação, normalização por lote, desistência - todos são implementados como parâmetros de camadas específicas, ou seja, essas funções não existem como camadas separadas. Talvez batchNorm deva ser selecionado em uma camada separada no futuro;
- O softMax também não é uma camada separada; pertence à camada especial LossFunction. No qual é usado ao escolher um tipo específico de cálculo de erro;
- a camada “LossFunction” é usada para calcular automaticamente o erro; obviamente, você não pode usar as etapas de avanço / retrocesso (abaixo está um exemplo de como trabalhar com essa camada);
- não existe uma camada "Achatar", não é necessária, pois a própria camada "FullyConnect" desenha a matriz de entrada;
- o otimizador de peso deve ser definido para cada camada de peso; por padrão, 'adam' é usado por todos.
Exemplos
Mnist

O código C ++ fica assim: O código completo está disponível
aqui . Adicionadas algumas fotos ao repositório, localizadas ao lado do exemplo. Usei o opencv para ler imagens, não o incluí no kit.
Outra rede do mesmo plano, mais complicada.

Código para criar essa rede: Nos exemplos, não é, você pode copiar daqui.
No Python, o código também parece // snet = snNet.Net() snet.addNode("Input", Input(), "C1 C2 C3") \ .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") \ .addNode("P1", Pooling(calcMode.CUDA), "FC1") \ .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") \ .addNode("P2", Pooling(calcMode.CUDA), "FC3") \ .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") \ .addNode("P3", Pooling(calcMode.CUDA), "FC5") \ \ .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") \ .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") \ .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") \ .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") \ .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") \ .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") \ .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output") .............
CIFAR-10

Aqui eu já tinha que ativar o batchNorm. Essa grade aprende até 50% de precisão em 1000 iterações, lote 100.
Este código acabou sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4") .addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6") .addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2") .addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3") .addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
Acho claro que qualquer classe de imagem pode ser substituída.
U-net tyni
Último exemplo. U-Net nativo simplificado para demonstração.

Deixe-me explicar um pouco: camadas DC1 ... - convolução reversa, camadas Concat1 ... - camadas de adição de canais,
Rsz1 ... - são usados para concordar com o número de canais na etapa oposta, pois o erro da soma de canais volta da camada Concat.
Código C ++. sn::Net snet; snet.addNode("In", sn::Input(), "C1") .addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1") .addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1") .addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4") .addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2") .addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2") .addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6") .addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1") .addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3") .addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2") .addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7") .addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8") .addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2") .addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4") .addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1") .addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9") .addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10"); sn::Convolution convOut(1, 0, sn::calcMode::CUDA); convOut.act = sn::active::sigmoid; snet.addNode("C10", convOut, "Output");
Código completo e imagens estão
aqui .
Matemática de código aberto como esta .
Testei todas as camadas no MNIST; o TF serviu como padrão para avaliar erros.
O que vem a seguir
A biblioteca não aumentará em largura, ou seja, não abrirá, soquetes etc., para não inflar.
A interface da biblioteca não será alterada / expandida, não direi isso e nunca, mas por último mas não menos importante.
Apenas em profundidade: farei o cálculo no OpenCL, a interface para C #, a rede RNN pode ser ...
MKL Acho que não faz sentido adicionar, porque a rede é um pouco mais profunda - de qualquer maneira, é mais rápida na placa de vídeo e a placa de desempenho média não é uma falta.
Importação / exportação de pesos com outras estruturas - através do Python (ainda não implementado). O roteiro será se surgir interesse nas pessoas.
Quem pode suportar o código, por favor. Mas existem limitações para que a arquitetura atual não seja quebrada.
Você pode expandir a interface do python para a impossibilidade, assim como docas e exemplos são necessários.
Para instalar a partir do Python:
* pip install libskynet - CPU
* pip install libskynet-cu - CUDA9.2 + cuDNN7.3.1
Guia do Usuário do Wiki.
O software é distribuído gratuitamente, licença MIT.
Obrigada