
Views, ou views, é um dos conceitos da plataforma CUBA, não o mais comum no mundo das estruturas da web. Entender isso significa evitar erros estúpidos quando, devido ao carregamento incompleto de dados, o aplicativo para de funcionar repentinamente. Vamos ver o que são representações (trocadilhos) e por que é realmente conveniente.
O problema dos dados descarregados
Vamos simplificar uma área de assunto e considerar o problema usando seu exemplo. Suponha que tenhamos uma entidade Customer que se refira a uma entidade CustomerType em um relacionamento muitos-para-um, ou seja, o comprador tenha um link para um determinado tipo que a descreva: por exemplo, "cash cow", "snapper" etc. A entidade CustomerType possui um atributo de nome no qual o nome do tipo está armazenado.
E, provavelmente, todos os recém-chegados (ou mesmo usuários avançados) no CUBA, mais cedo ou mais tarde, receberam este erro:
IllegalStateException: Cannot get unfetched attribute [type] from detached object com.rtcab.cev.entity.Customer-e703700d-c977-bd8e-1a40-74afd88915af [detached].
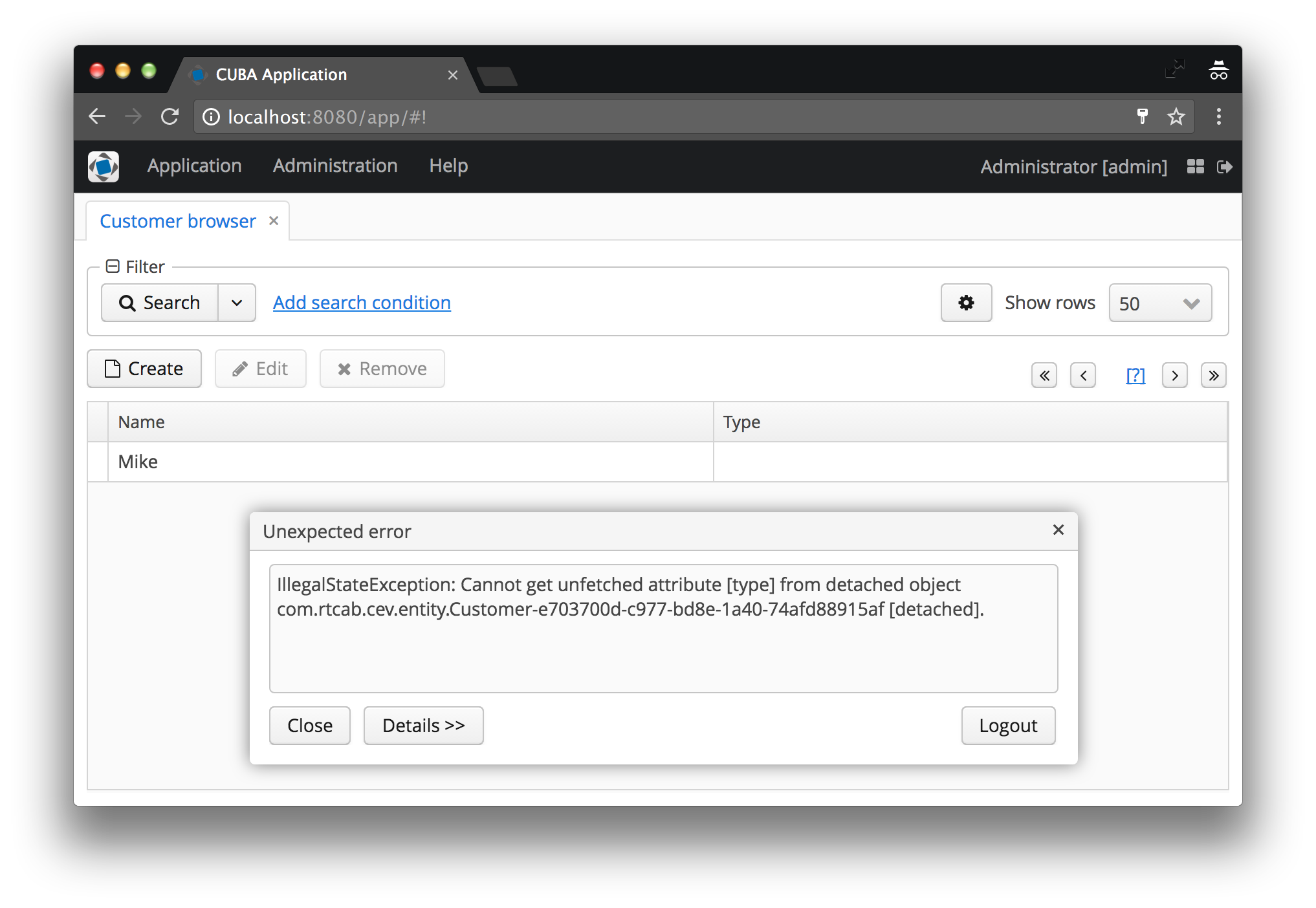
Admita, você também viu com seus próprios olhos? Eu - sim, em uma centena de situações diferentes. Neste artigo, examinaremos a causa desse problema, por que ele existe e como resolvê-lo.
Para iniciantes, uma pequena introdução ao conceito de visualizações.
O que é uma visão?
Uma exibição no CUBA é essencialmente uma coleção de colunas em um banco de dados que deve ser carregado juntos em uma única consulta.
Suponha que desejemos criar uma interface do usuário com uma tabela de clientes, em que a primeira coluna seja o nome do cliente e a segunda seja o nome do tipo do atributo customerType (como na captura de tela acima). É lógico supor que nesse modelo de dados teremos duas tabelas separadas no banco de dados, uma para a entidade Cliente e outra para CustomerType . A SELECT * from CEV_CUSTOMER retornará dados de apenas uma tabela ( name atributo, etc.). Obviamente, para obter dados também de outras tabelas, usaremos JOINs.
No caso de usar consultas SQL clássicas usando JOIN, a hierarquia de associações (atributos de referência) se expande do gráfico para uma lista simples.
Nota do tradutor: em outras palavras, as relações entre as tabelas são apagadas e o resultado é apresentado em uma única matriz de dados que representa a união das tabelas.
No caso do CUBA, é utilizado o ORM, que não perde informações sobre relacionamentos entre entidades e apresenta o resultado de consultas na forma de um gráfico integral dos dados solicitados. Nesse caso, o JPQL, um análogo de objeto do SQL, é usado como a linguagem de consulta.
No entanto, os dados ainda precisam ser descarregados de alguma forma do banco de dados e transformados em um gráfico de entidade. Para isso, o mecanismo de mapeamento objeto-relacional (que é o JPA) possui duas abordagens principais para consultas ao banco de dados.
Carregamento lento vs. busca ansiosa
Carregamento lento e carregamento ganancioso são duas estratégias possíveis para obter dados do banco de dados. A diferença fundamental entre os dois é quando os dados das tabelas vinculadas são carregados. Um pequeno exemplo para uma melhor compreensão:
Lembra-se da cena do livro "O Hobbit, ou Viagem de ida e volta", em que um grupo de gnomos na companhia de Gandalf e Bilbo está tentando pedir uma noite na casa de Beorn? Gandalf ordenou que os anões aparecessem estritamente e só depois que ele concordou cuidadosamente com Beorn e começou a apresentá-los um de cada vez para não chocar o proprietário pela necessidade de acomodar 15 convidados de uma só vez.

Então, Gandalf e os gnomos na casa de Beorn ... Essa provavelmente não é a primeira coisa que vem à mente quando se pensa em downloads preguiçosos e gananciosos, mas há definitivamente semelhanças. Gandalf agiu sabiamente aqui, pois estava ciente das limitações. Pode-se dizer que ele escolhe conscientemente o carregamento lento dos gnomos, pois entendeu que o download de todos os dados ao mesmo tempo seria uma operação muito pesada para esse banco de dados. No entanto, após o 8º gnomo, Gandalf mudou para um carregamento ganancioso e carregou vários gnomos restantes, porque percebeu que chamadas muito freqüentes para o banco de dados começam a torná-lo menos irritante.
A moral é que tanto o carregamento preguiçoso quanto o ganancioso têm seus prós e contras. O que aplicar em cada situação específica, você decide.
Problema de solicitação N + 1
O problema de consulta N + 1 geralmente surge se você estiver usando o carregamento lento sem pensar em onde quer que vá. Para ilustrar, vejamos um pedaço do código Grails. Isso não significa que no Grails tudo carregue preguiçosamente (na verdade, você mesmo escolhe o método de inicialização). No Grails, por padrão, uma consulta ao banco de dados retorna instâncias de entidade com todos os atributos de sua tabela. Essencialmente, SELECT * FROM Pet é executado.
Se você deseja aprofundar as relações entre entidades, deve fazê-lo após o factum. Aqui está um exemplo:
function getPetOwnerNamesForPets(String nameOfPet) { def pets = Pet.findAll(sort:"name") { name == nameOfPet } def ownerNames = [] pets.each { ownerNames << it.owner.name } return ownerNames.join(", ") }
O gráfico é it.owner.name aqui por uma única linha: it.owner.name . Proprietário é um relacionamento que não foi carregado na solicitação original ( Pet.findAll ). Assim, toda vez que essa linha for chamada, o GORM fará algo como SELECT * FROM Person WHERE id='…' . Carga preguiçosa em água pura.
Se você calcular o número total de consultas SQL, obtém N (um proprietário para cada chamada it.owner ) + 1 (para o Pet.findAll original). Se você quiser se aprofundar no gráfico de entidades relacionadas, é provável que seu banco de dados encontre rapidamente seus limites.
Como desenvolvedor, é improvável que você perceba isso, porque, do seu ponto de vista, você está apenas percorrendo o gráfico de objetos. Esse aninhamento oculto em uma linha curta causa problemas reais ao banco de dados e torna o carregamento lento, às vezes, perigoso.
Desenvolvendo uma analogia de hobby, o problema do N + 1 pode se manifestar da seguinte forma: imagine que Gandalf não consiga armazenar os nomes dos gnomos em sua memória. Portanto, apresentando os anões um a um, ele é forçado a voltar ao seu grupo e pedir ao anão seu nome. Com essas informações, ele volta para Beorn e representa Thorin. Então ele repete essa manobra para Bifur, Bofur, Fili, Kili, Dori, Nori, Ori, Oin, Gloyn, Balin, Dvalin e Bombur.

É fácil imaginar que seria improvável que tal cenário acontecesse: qual destinatário gostaria de esperar as informações solicitadas por tanto tempo? Portanto, você não deve usar essa abordagem sem pensar e confiar cegamente nas configurações padrão do seu mapeador de persistência.
Resolvendo o problema de consultas N + 1 usando visualizações CUBA
No CUBA, você provavelmente nunca encontrará o problema de consulta N + 1, já que a plataforma decidiu não usar carregamento oculto lento. Em vez disso, o CUBA introduziu o conceito de representações. As visualizações são uma descrição de quais atributos devem ser selecionados e carregados junto com as instâncias da entidade. Algo como
SELECT pet.name, person.name FROM Pet pet JOIN Person person ON pet.owner == person.id
Por um lado, a exibição descreve as colunas que precisam ser carregadas da tabela principal ( Pet ) (em vez de carregar todos os atributos por meio de *); por outro lado, descreve as colunas que devem ser carregadas das tabelas c-JOIN.
Você pode imaginar a visualização CUBA como a visualização SQL do OR-Mapper: o princípio de operação é aproximadamente o mesmo.
Na plataforma CUBA, você não pode invocar uma consulta através do DataManager sem usar a visualização. A documentação fornece um exemplo:
@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { LoadContext<Book> loadContext = LoadContext.create(Book.class) .setId(bookId).setView("book.edit"); return dataManager.load(loadContext); }
Aqui queremos fazer o download do livro por seu ID. O setView("book.edit") , ao criar um contexto de carregamento, indica com qual exibição o livro deve ser carregado no banco de dados. Caso você não seja aprovado, o gerenciador de dados usa uma das três visualizações padrão que cada entidade possui: a _local view . Local aqui refere-se a atributos que não fazem referência a outras tabelas, tudo é simples.
Resolvendo o problema com IllegalStateException através de visualizações
Agora que temos um pouco de compreensão do conceito de representações, voltemos ao primeiro exemplo desde o início do artigo e tentemos evitar a exceção.
A mensagem IllegalStateException: Não é possível obter o atributo não recuperado [] do objeto desanexado significa apenas que você está tentando exibir algum atributo que não está incluído na exibição com a qual a entidade está carregada.
Como você pode ver, no descritor da tela de navegação, usei a visualização _local , e este é o problema:
<dsContext> <groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="_local"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource> </dsContext>
Para se livrar do erro, primeiro você precisa incluir o tipo de cliente na exibição. Como não podemos alterar a exibição padrão de _local , podemos criar a nossa. No Studio, isso pode ser feito, por exemplo, da seguinte forma (clique com o botão direito do mouse em entidades> criar exibição):
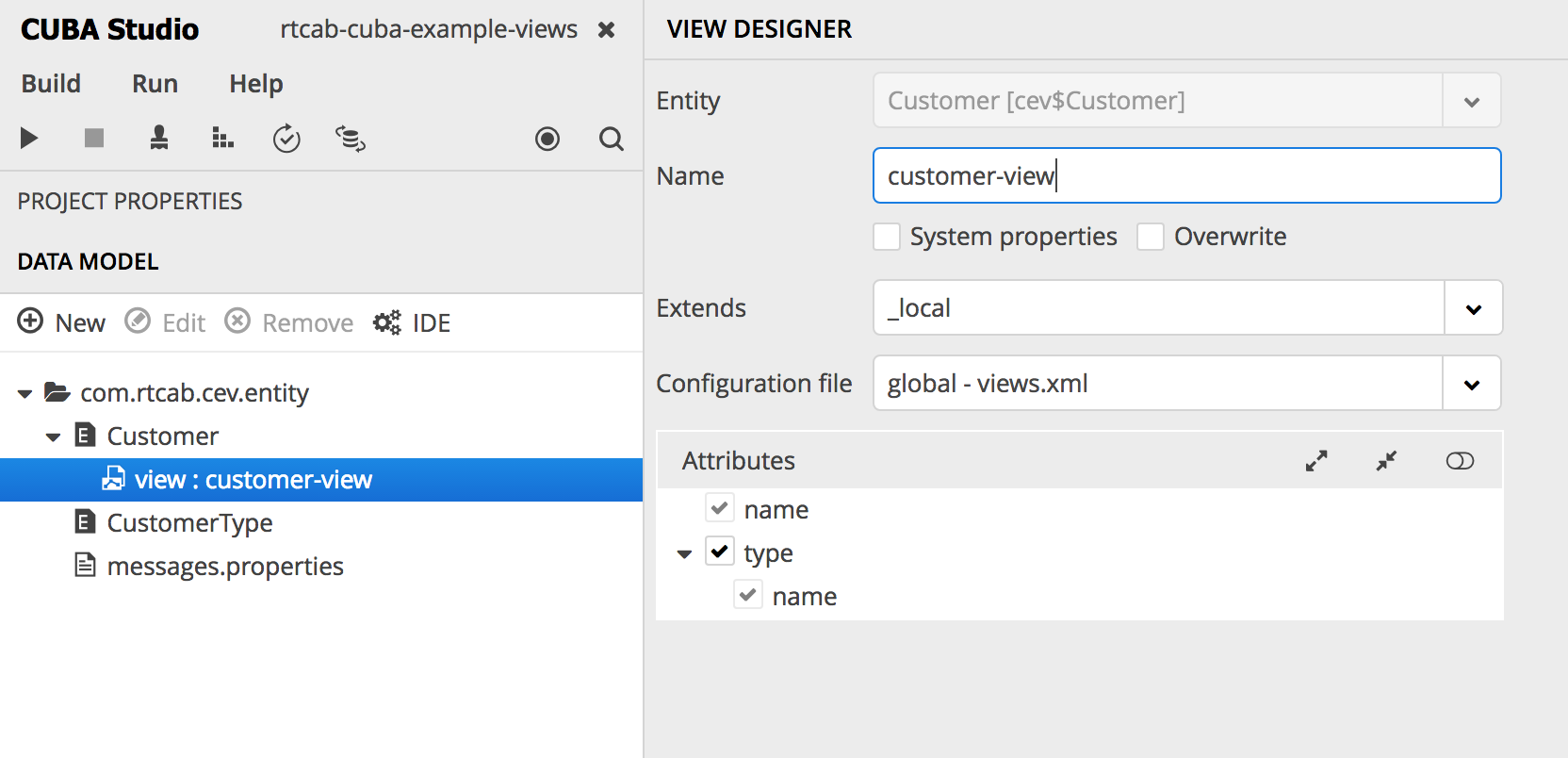
diretamente no descritor views.xml do nosso aplicativo:
<view class="com.rtcab.cev.entity.Customer" extends="_local" name="customer-view"> <property name="type" view="_minimal"/> </view>
Depois disso, alteramos o link para a visualização na tela de navegação, assim:
<groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="customer-view"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource>
Isso resolve completamente o problema e agora os dados do link são exibidos na tela de visualização do cliente.
_Minimal view e nome da instância
O que mais vale a pena mencionar no contexto de visualizações é a visão _minimal . A visualização local tem uma definição muito clara: inclui todos os atributos da entidade, que são atributos diretos da tabela (que não são chaves estrangeiras).
A definição de uma representação mínima não é tão óbvia, mas também bastante clara.
CUBA tem o conceito de um nome de instância de entidade - nome da instância. O nome da instância é equivalente ao toString() no bom e velho Java. Esta é uma representação em cadeia de uma entidade para exibição em uma interface do usuário e para uso em links. O nome da instância é definido usando a anotação da entidade NamePattern .
É usado assim: @NamePattern("%s (%s)|name,code") . Temos dois resultados:
O nome da instância define o mapeamento da entidade para a interface do usuário
Primeiro, o nome da instância determina o que e em que ordem será exibida na interface do usuário se uma entidade se referir a outra entidade (como Customer se refere a CustomerType ).
No nosso caso, o tipo de cliente será exibido como o nome da instância CustomerType , à qual o código é adicionado aos colchetes. Se o nome da instância não estiver definido, o nome da classe da entidade e o ID da instância específica serão exibidos - concorde que isso não é exatamente o que o usuário gostaria de ver. Veja as capturas de tela antes e depois abaixo para ver exemplos de ambos os casos.
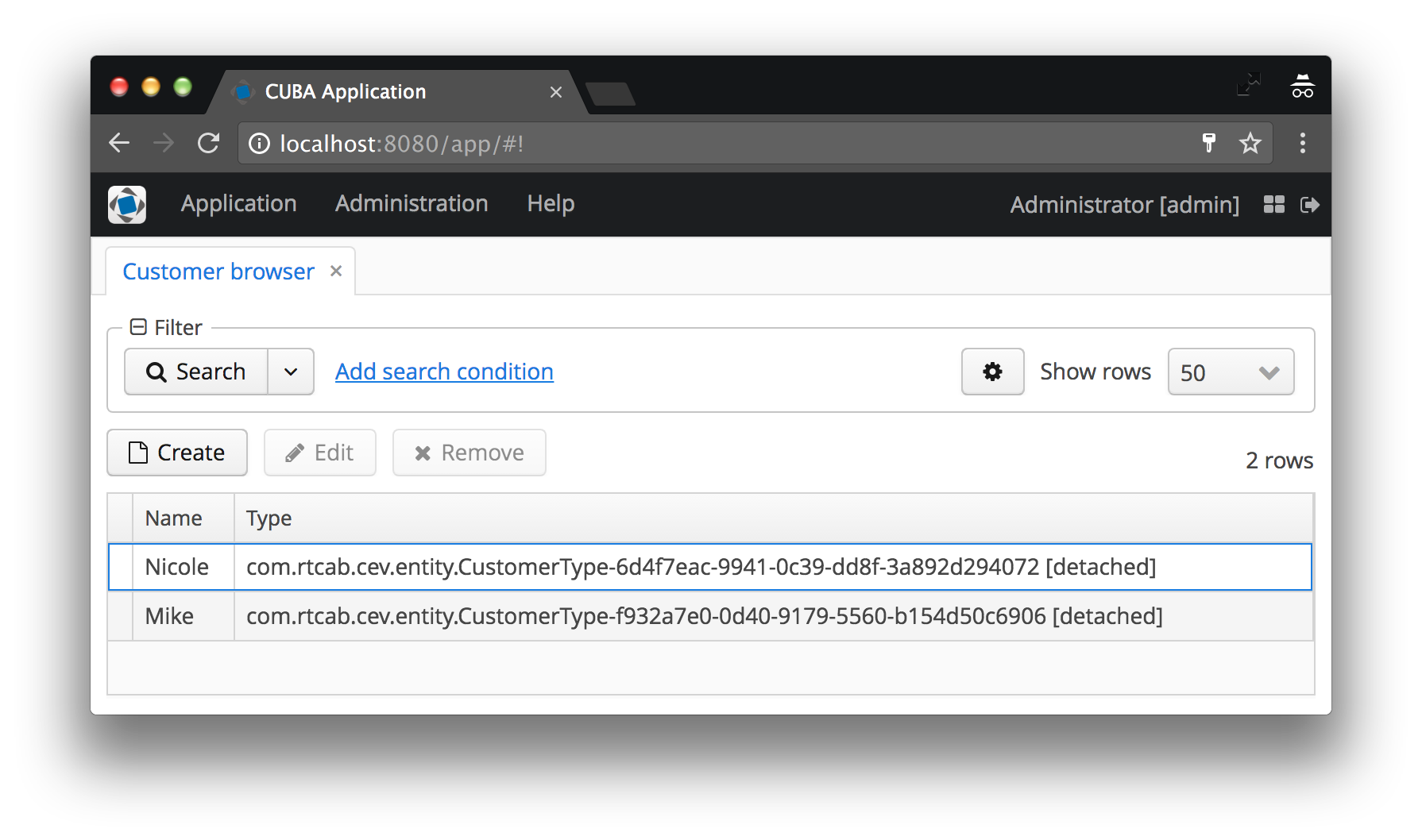
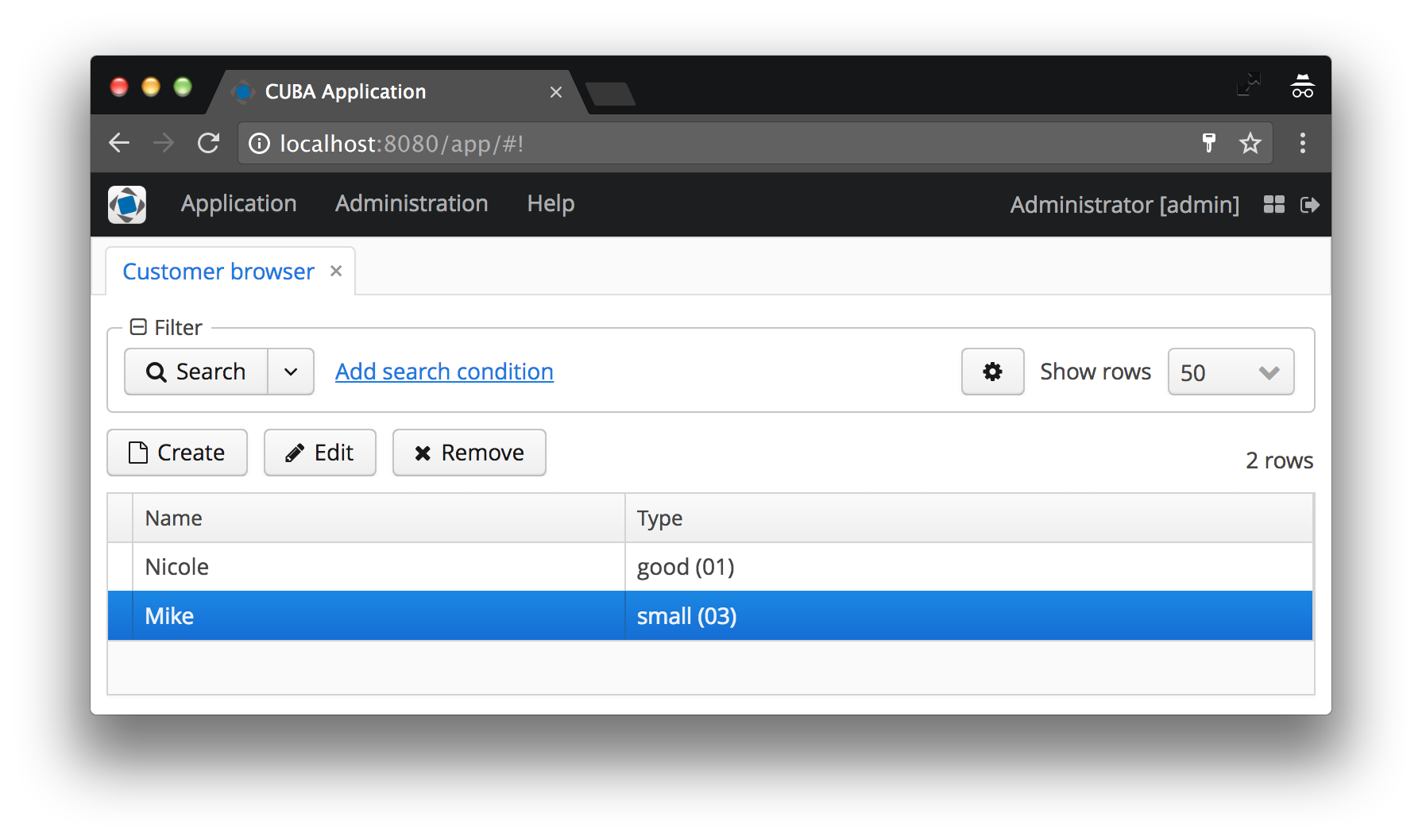
O nome da instância define atributos mínimos de exibição
A segunda coisa que a anotação NamePattern afeta é: todos os atributos especificados após a barra vertical formam automaticamente uma exibição _minimal . À primeira vista, isso parece óbvio, porque os dados de alguma forma precisam ser exibidos na interface do usuário, o que significa que você deve primeiro baixá-los do banco de dados. Embora, para ser sincero, raramente pense nesse fato.
É importante observar aqui que a representação mínima, se comparada com a local, pode conter referências a outras entidades. Por exemplo, para o comprador do exemplo acima, defino um nome de instância, que inclui um atributo local da entidade Cliente ( name ) e um atributo de referência ( type ):
@NamePattern("%s - %s|name,type")
A representação mínima pode ser usada recursivamente: (Cliente [Nome da Instância] -> CustomerType [Nome da Instância])
Nota do tradutor: desde a publicação do artigo, outra exibição do sistema apareceu - _base view, que inclui todos os atributos locais que não são do sistema e atributos especificados na anotação @NamePattern (ou seja, _minimal + _local ).
Conclusão
Em conclusão, resumimos o tópico mais importante. Graças às visualizações, no CUBA, podemos indicar explicitamente o que deve ser carregado no banco de dados. As visualizações determinam o que será carregado com avidez, enquanto a maioria das outras estruturas realiza secretamente um carregamento lento.
As representações podem parecer um mecanismo complicado, mas a longo prazo elas se justificam.
Espero ter conseguido explicar de maneira acessível o que realmente são essas visões misteriosas. Obviamente, existem cenários mais avançados para seu uso, bem como armadilhas ao trabalhar com representações em geral e com representações mínimas em particular, mas vou escrever sobre isso em um post separado de alguma forma.