Publico o segundo relatório do nosso
primeiro mitap , realizado em setembro. A última vez que você pôde ler (e ver) sobre o
uso do Consul para dimensionar serviços estatais de Ivan Bubnov do BIT.GAMES, e hoje falaremos sobre o CICD. Mais precisamente, nosso administrador de sistema Egor Panov falará sobre isso, que é responsável pela disponibilidade de infraestrutura e serviços na Pixonic. Sob o corte - decodificação do desempenho.
Para começar, a indústria de jogos é mais arriscada - você nunca sabe o que exatamente vai afundar no coração do jogador. E assim criamos muitos protótipos. Obviamente, criamos protótipos no joelho de paus, cordas e outros materiais improvisados.
Parece que, com essa abordagem, fazer algo que possa ser apoiado é geralmente impossível. Mas mesmo nesta fase, estamos aguentando. Mantemos três pilares:
- excelente experiência dos testadores;
- interação íntima com eles;
- o tempo que dedicamos aos testes.
Portanto, se não construirmos nossos processos, por exemplo, implantação ou IC (integração contínua), mais cedo ou mais tarde chegaremos à conclusão de que a duração do teste aumentará e aumentará o tempo todo. E faremos tudo devagar e perderemos o mercado, ou simplesmente explodiremos a cada implantação.
Mas construir um processo CICD não é tão simples. Alguns dirão: bem, eu vou colocar Jenkins, vou ligar rapidamente para algo, agora estou pronto para o CICD. Não, isso não é apenas uma ferramenta, é também uma prática. Vamos começar em ordem.

O primeiro. Muitos artigos escrevem que tudo precisa ser mantido em um repositório: código, testes, implantação e até o esquema do banco de dados e configurações de IDE comuns a todos. Nós seguimos nosso próprio caminho.
Alocamos repositórios diferentes: implante em nosso repositório, testes em outro. Funciona mais rápido. Pode não lhe agradar, mas para nós é muito mais conveniente. Como existe um ponto importante neste momento - você precisa criar um simples e transparente para todos os fluxos de hits. Obviamente, você pode fazer o download do finalizado em algum lugar, mas, em qualquer caso, é necessário ajustá-lo por conta própria, aprimorá-lo. Para nós, por exemplo, uma implantação vive em seu próprio gitflow, que é mais parecido com um fluxo do GitHub, e o desenvolvimento do servidor vive em seu próprio gitflow.
O próximo parágrafo. Você precisa configurar uma compilação totalmente automática. É claro que, no primeiro estágio, o próprio desenvolvedor coleta o projeto pessoalmente, depois o implanta pessoalmente com a ajuda do SCP, o lança ele mesmo, o envia para quem precisar. Esta opção não durou muito, um script bash apareceu. Bem, desde que o ambiente dos desenvolvedores está mudando constantemente, um servidor de compilação dedicado especial apareceu. Ele viveu muito tempo; durante esse tempo, conseguimos aumentar até 500 servidores, configurar o servidor no Puppet, acumular legado no Puppet, recusar o Puppet, mudar para o Ansible e esse servidor de build continuou a funcionar.
Eles decidiram mudar tudo depois de duas ligações, não esperaram uma terceira. A história é clara: o servidor de compilação é um ponto único de falha e, é claro, quando precisávamos implantar algo, o data center caiu completamente junto com o nosso compilador. E a segunda chamada: precisávamos atualizar a versão Java - atualizamos no servidor de compilação, instalamos no palco, tudo é legal, tudo é ótimo e foi necessário executar algumas pequenas correções no prod. Claro, esquecemos de retroceder e tudo simplesmente desmoronou.
Depois disso, eles reescreveram tudo para que toda a compilação pudesse acontecer em absolutamente qualquer agente do TeamCity e reescreveu no Ansible, porque foi configurado no Ansible, por que não usar a mesma ferramenta também para a implantação.
A seguinte regra: quanto mais você confirmar, melhor. Porque Porque existe um quarto: todo commit é coletado. E, de fato, ainda mais do que todo commit. Eu já disse que temos o TeamCity, e isso permite que você execute uma confirmação do seu IDE favorito (você adivinha o que eu quero dizer). Na verdade, feedback rápido, tudo está ótimo.
Uma compilação quebrada é reparada imediatamente. Assim que você configura a implantação automática, é necessário configurar a notificação automática no Slack. Todos sabemos muito bem que um desenvolvedor sabe como seu código funciona apenas no momento em que ele o escreve. Portanto: a pessoa descobriu - reparado imediatamente.
Testamos no ambiente repetindo prod. É simples, escolhemos o Ansible e o AWX. Alguém pode perguntar, mas e o Docker, o Kubernetes, o OpenShift, onde todos os problemas já estão resolvidos há muito tempo? Esqueci de dizer que temos componentes do Linux e do Windows. E, por exemplo, o servidor Photon, que está no Windows, apenas recentemente conseguimos empacotar mais ou menos normalmente em um contêiner de docker de 10 GB. Portanto, temos um aplicativo do Windows que não se comporta bem em um contêiner; Há um aplicativo no Linux (que está em Java), que é perfeitamente empacotado, mas não há motivo para que funcione bem onde quer que você o execute. Isto é Java.
Em seguida, escolhemos entre Ansible e Chef. Ambos funcionam bem com o Windows, mas o Ansible acabou sendo muito mais fácil para nós. Quando já instalamos o AWX - em geral, todo o fogo se tornou. AWX tem segredos, gráficos, história. Você pode mostrar a uma pessoa longe de tudo isso, ela imediatamente verá tudo e tudo ficará claro.
E você sempre precisa manter a compilação rápida. Não sei por que, mas sempre que você lança um novo projeto, você esquece completamente o servidor de compilação, os agentes e seleciona algum computador que estava por aí - este é o nosso servidor de compilação. É indesejável repetir esse erro, porque tudo o que estou falando (feedback rápido, vantagens) - tudo não será tão relevante se a montagem iniciar no seu laptop muito mais rapidamente do que em algum tipo de farm de criação de servidores.

7 pontos - e já construímos algum tipo de processo de IC. Ótimo O diagrama a seguir não está visível, mas ainda existe o Graylog ao lado. Quem lê nossos artigos sobre Habré, que já viu
como escolhemos o Graylog e
como instalar . De qualquer forma, ajuda a desviar se algum problema ainda ocorreu.
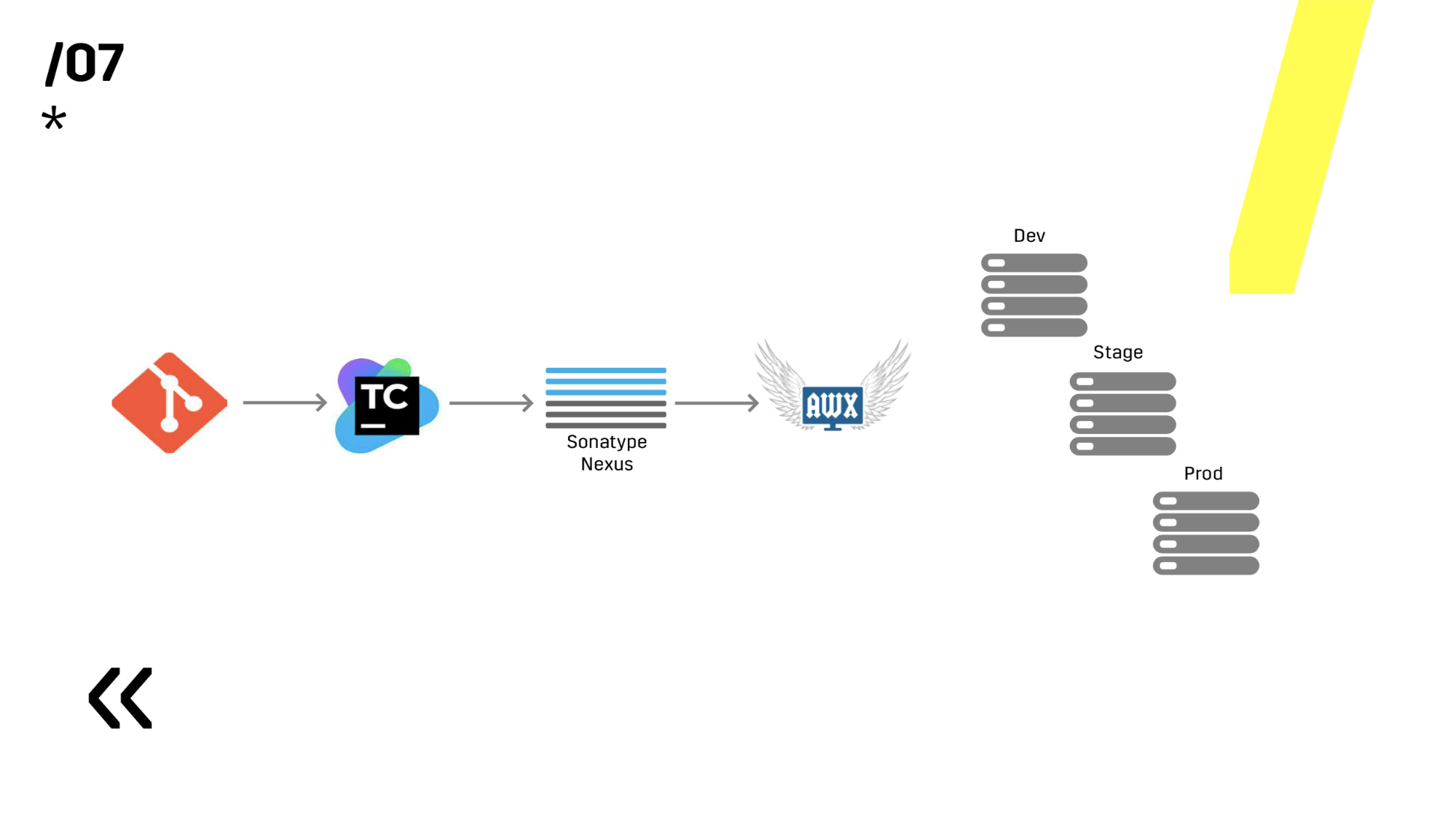
Agora, nesta base, já é possível prosseguir para a implantação.

Mas eu já falei sobre a implantação no segundo parágrafo, então não vou me alongar muito nisso. Vou dizer uma coisa sobre a vida: se você usa o Ansible, adicione esta série, que está no slide. Aconteceu mais de uma vez que você iniciou algo e entendeu, mas eu o iniciei errado, errado ou errado, e então você vê que este é apenas um servidor. E podemos facilmente perder um servidor e você apenas o carrega novamente, ninguém percebeu.
Além disso, eles instalaram o repositório de artefatos no Nexus - é um ponto de entrada único para absolutamente todos, não apenas para o IC.
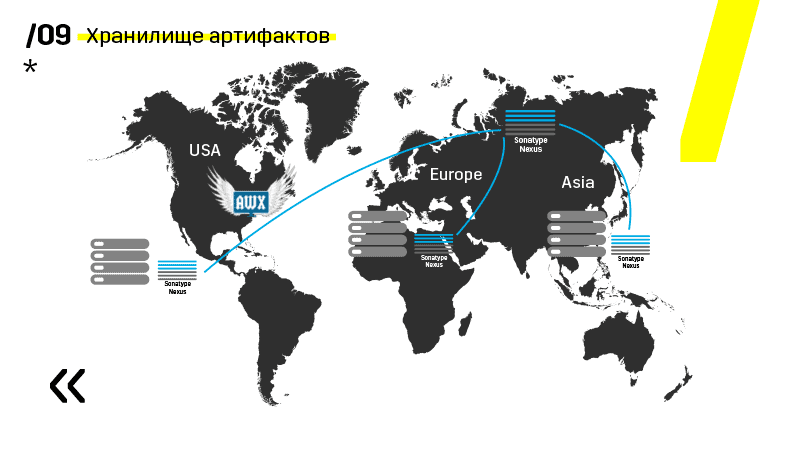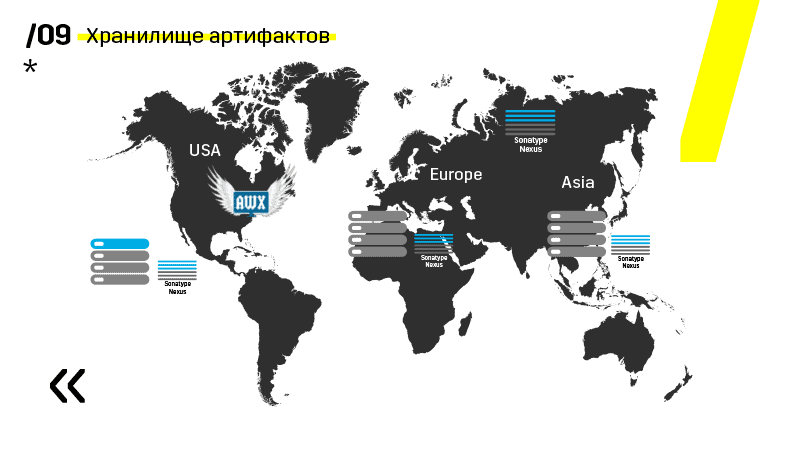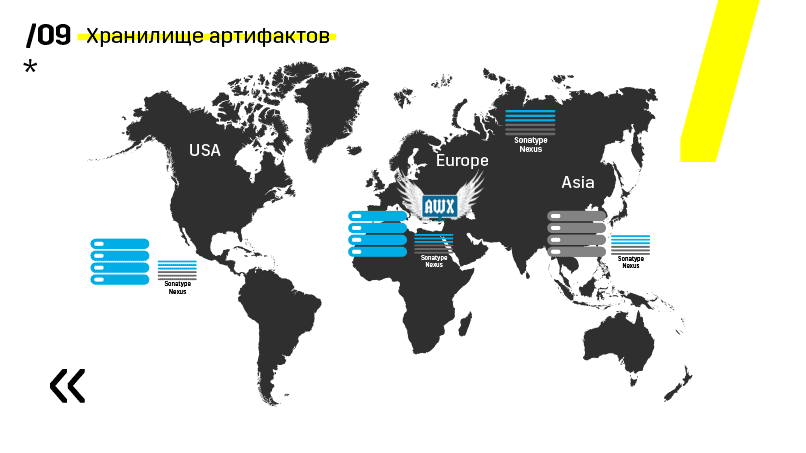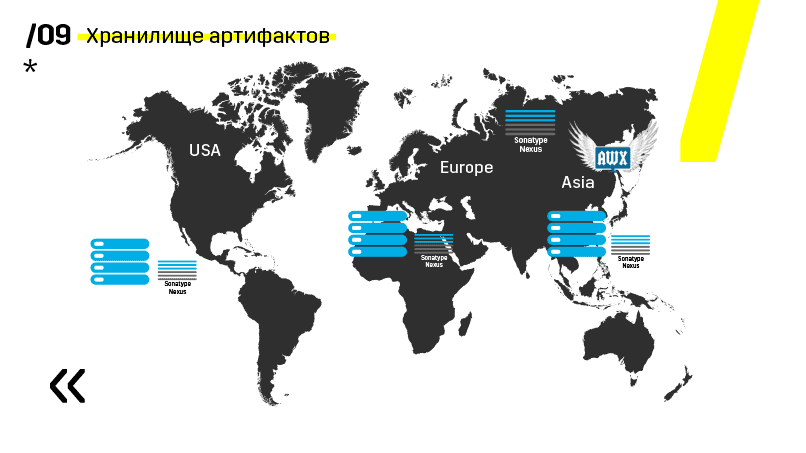
E isso nos ajuda muito a garantir a repetibilidade. Bem, como o nexus pode funcionar como serviços de proxy em diferentes regiões, eles aceleram a implantação, a instalação de pacotes rpm, imagens do docker, qualquer coisa.
Quando você está lançando um novo projeto, é aconselhável escolher componentes fáceis de automatizar. Por exemplo, não tivemos êxito com o servidor Photon. De qualquer forma, era a melhor solução em outros aspectos. Mas Cassandra, por exemplo, é muito convenientemente atualizado e automatizado.
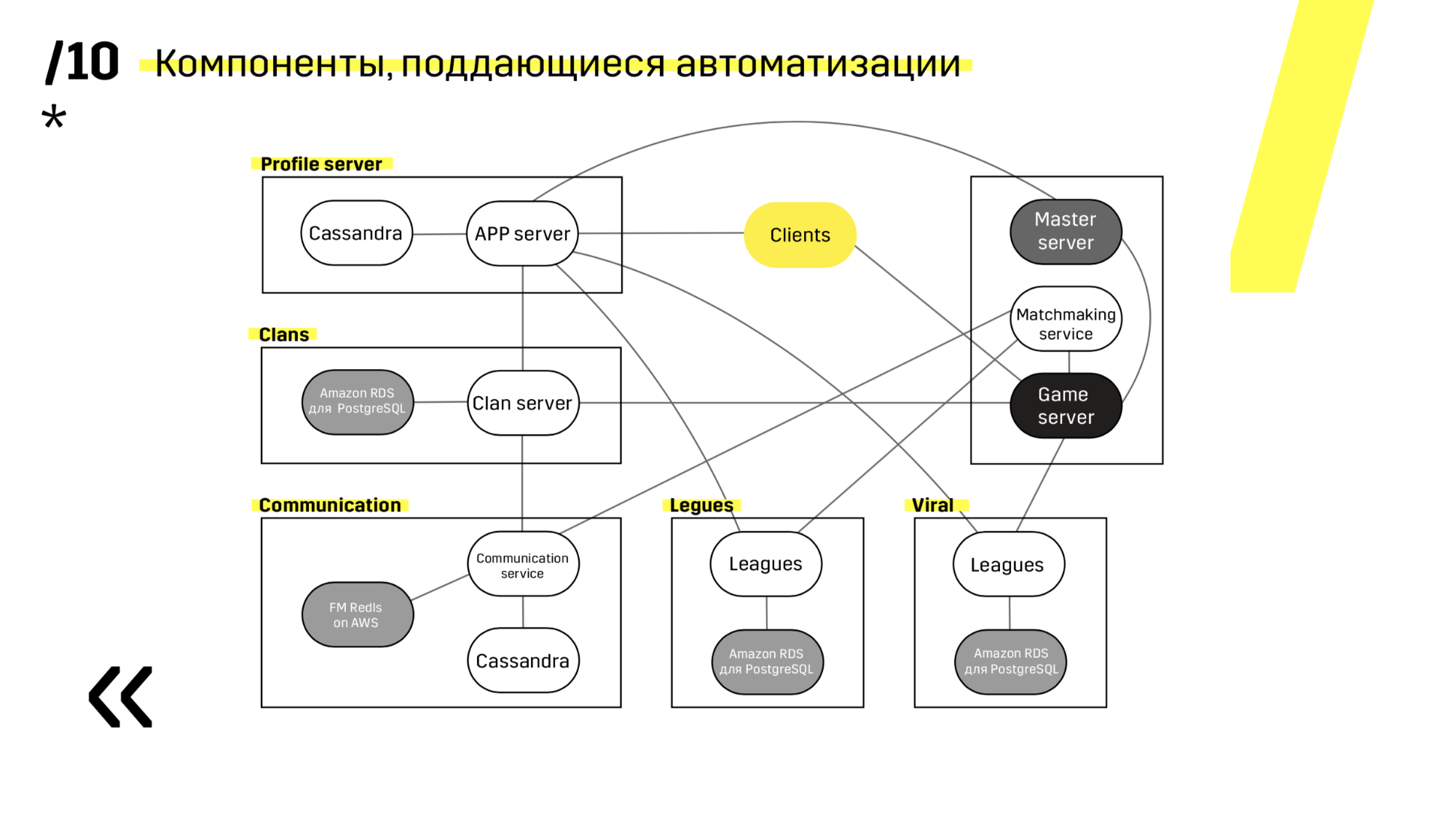
Aqui está um exemplo de um de nossos projetos. O cliente chega ao servidor APP, onde ele tem um perfil no banco de dados Cassandra, e depois vai para o servidor mestre, que com a ajuda da criação de partidas, oferece a ele um servidor de jogos com algum tipo de sala. Todos os outros serviços são feitos na forma de um "banco de dados de aplicativos" e são atualizados exatamente da mesma maneira.
O segundo ponto - você precisa fornecer uma arquitetura de implantação simples e pouco acoplada. Nós conseguimos.
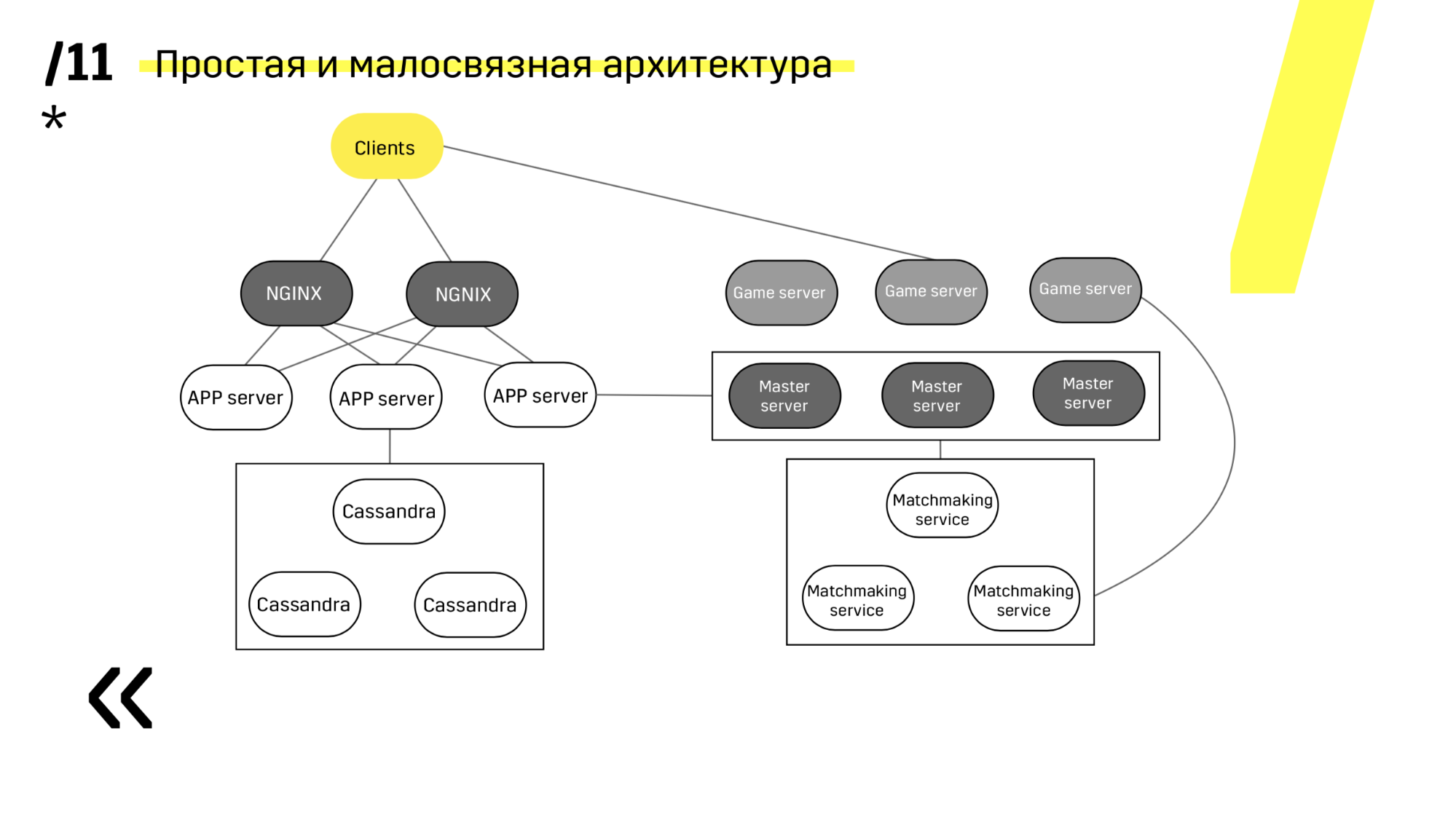
Veja, atualizando, por exemplo, o servidor de aplicativos. Dedicamos serviços de descoberta que reconfiguram o balanceador, então apenas acessamos o servidor de aplicativos, o apagamos, ele falha com o balanceamento, atualizamos tudo. E assim com cada um individualmente.
Servidores principais são atualizados quase de forma idêntica. O cliente faz ping em cada servidor principal da região e vai para aquele em que o ping é melhor. Assim, se atualizarmos o servidor principal, talvez o jogo vá um pouco mais devagar, mas é atualizado de maneira fácil e simples.
Os servidores de jogos são atualizados de maneira um pouco diferente, porque ainda existe um jogo em andamento. Vamos ao matchmaking, pedimos que ele jogue um certo servidor fora de equilíbrio, chegue ao servidor do jogo, espere até que os jogos se tornem exatamente zero e atualize. Então voltamos ao equilíbrio.
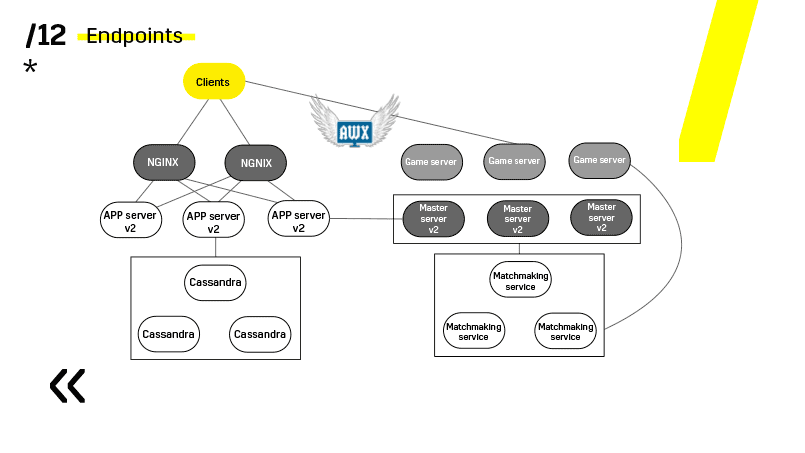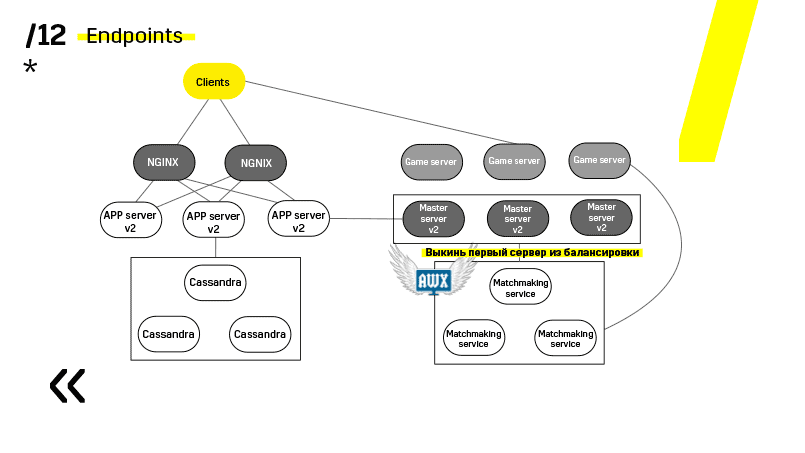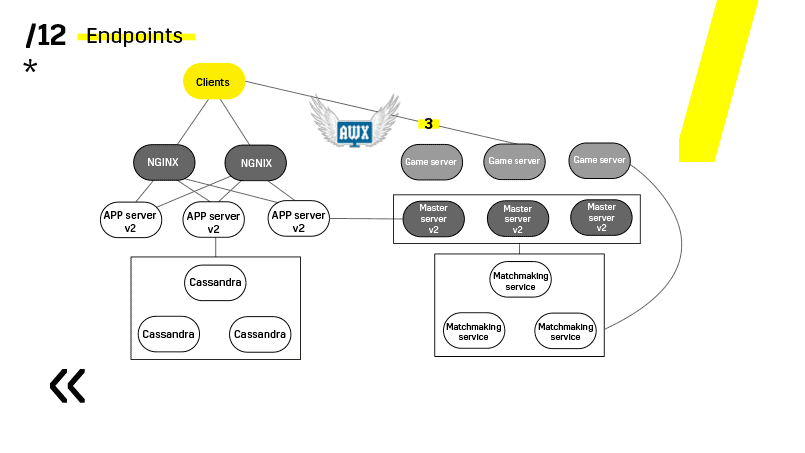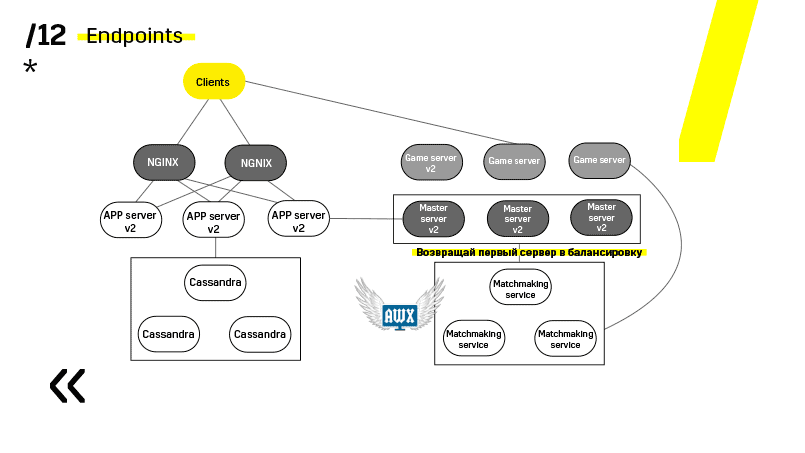
O ponto principal aqui são os pontos de extremidade que cada um dos componentes possui e com os quais é fácil e simples a comunicação. Se você precisar de um exemplo, existe um cluster do Elasticsearch. Usando solicitações http regulares em JSON, você pode se comunicar facilmente com ele. E ele imediatamente no mesmo JSON fornece todos os tipos de métricas diferentes e informações de alto nível sobre o cluster: verde, amarelo e vermelho.
Depois de concluir essas 12 etapas, aumentamos o número de ambientes, começamos a testar mais, a implantação foi acelerada, as pessoas começaram a receber feedback rápido.

O que é muito importante, conseguimos a simplicidade e a velocidade dos experimentos. E isso é muito importante, porque quando existem muitos experimentos, podemos filtrar facilmente idéias erradas e focar nas corretas. E não com base em avaliações subjetivas, mas com base em indicadores objetivos.
Na verdade, eu não sigo mais quando temos uma implantação lá, quando o lançamento. Não há "oh, solte!" Sentimento, tudo se acumulou e arrepios. Agora, essa é uma operação tão rotineira, vejo periodicamente em uma sala de bate-papo que algo surgiu, ok. Isso é muito legal. Os administradores do sistema rugirão de alegria quando você o fizer.
Mas o mundo não pára, às vezes salta. Temos algo a melhorar. Por exemplo, eu gostaria de colocar os logs da compilação no Graylog também. Isso exigirá um aprimoramento adicional do registro para que não haja uma história separada, mas claramente: é assim que a construção foi montada, testada, implantada e se comportando no produto. E monitoramento contínuo - essa é uma história mais complicada.

Nós usamos o Zabbix, e ele não está preparado para tais abordagens. A quarta versão será lançada em breve, descobriremos o que está lá e, se tudo estiver ruim, encontraremos uma solução diferente. Vou lhe contar como será a próxima reunião.
Perguntas da platéia
E o que acontece quando você despeja um pouco de lixo na produção? Por exemplo, você não calculou algo de acordo com o desempenho e está tudo bem na integração, mas na produção, veja - seus servidores estão começando a falhar. Como você reverte? Existe algum botão me salvar?Tentamos fazer a automação de reversão. Você pode falar sobre relatórios sobre o quão legal é, como é maravilhoso. Mas primeiro, projetamos para que as versões sejam compatíveis com versões anteriores e testamos isso. E quando fizemos essa coisa totalmente automática, que verifica alguma coisa e a reverte, e então começamos a conviver com ela, percebemos que nos esforçamos muito mais do que se apenas pegássemos a versão antiga com o mesmo pedal .
Em relação à atualização automática da implantação: por que você está fazendo alterações no servidor atual e não adicionando um novo e apenas adicionando-o ao grupo de destino ou ao balanceador?Tão mais rápido.
Por exemplo, se você precisar atualizar a versão Java, altere o estado da instância na Amazon, atualizando a versão Java ou algo mais, como reverter nesse caso? Você está fazendo alterações no servidor de produção?Sim, cada componente funciona bem com a nova versão e a antiga. Sim, pode ser necessário recarregar o servidor.
Há mudanças de estado quando grandes problemas são possíveis ...Então exploda.
Parece-me adicionar um novo servidor e colocá-lo no grupo-alvo no grupo-alvo - uma pequena tarefa em complexidade e uma prática muito boa.Estamos hospedados em hardware, não nas nuvens. Podemos adicionar um servidor - é possível, mas um pouco mais do que apenas clicar na nuvem. Portanto, pegamos nosso servidor atual (não temos essa carga para não podermos retirar algumas das máquinas) - pegamos algumas das máquinas, atualizamos, colocamos no tráfego de vendas, vemos como funciona, se tudo estiver bem, continuaremos fazendo tudo outros carros.
Você diz que se todo commit for coletado e se tudo estiver ruim - o desenvolvedor governa tudo imediatamente. Você entende que tudo está ruim? Quais confirmações são feitas?Naturalmente, no começo era algum tipo de teste manual, o feedback é lento. Então, com algum tipo de teste automático no Appium, tudo isso é coberto, funciona e fornece algum tipo de feedback sobre se os testes caíram ou não.
I.e. Primeiro, cada confirmação é lançada e os testadores estão assistindo?Bem, nem todo mundo, isso é prática. Fizemos uma prática desses 12 pontos - acelerada. De fato, este é um trabalho longo e árduo, talvez durante o ano. Mas, idealmente, você chega a isso e tudo funciona. Sim, precisamos de algum tipo de autoteste, pelo menos um conjunto mínimo, para que tudo funcione para você.
E a pergunta é menor: há um servidor de aplicativos na imagem e assim por diante, é isso que me interessa lá? Você disse que não parece ter o Docker, o que é um servidor? Java nu ou o quê?Em algum lugar como o Photon no Windows (um servidor de jogos), o servidor de aplicativos é um aplicativo Java no Tomcat.
I.e. sem virtualoks, sem contêineres, nada?Bem, Java é, você poderia dizer, um contêiner.
E tudo isso acontece com o Ansible?Sim I.e. em um determinado momento, simplesmente não investimos em orquestração, porque por quê? Se, em qualquer caso, o Windows precisar ser gerenciado separadamente da mesma maneira, e aqui absolutamente tudo será coberto com uma única ferramenta.
E como o banco de dados é implantado? Dependência de componente ou serviço?Há um esquema no próprio serviço que será implantado quando aparecer e precisar ser desenvolvido para que nada seja excluído, mas apenas algo seja adicionado e seja compatível com versões anteriores.
Sua base também é de ferro ou está em algum lugar da nuvem na Amazônia?A maior base é de ferro, mas existem outras. Existem pequenos, o RDS não é mais ferro, virtual. Esses pequenos serviços que mostrei: bate-papos, ligas, conversando com o Facebook, clãs, um deles é o RDS.
Servidor mestre - como é?Este, de fato, é o mesmo servidor de jogo, apenas com um sinal do mestre e ele é um balanceador. I.e. o cliente faz ping em todos os mestres e recebe aquele em que o ping é menor, e o servidor mestre que usa matchmaking coleta salas nos servidores de jogos e envia o jogador.
Entendi corretamente que para cada lançamento que você escreve (se algum recurso aparecer) uma migração para atualizar os dados? Você disse que pega artefatos antigos e os preenche - o que acontece com os dados? Você está escrevendo uma migração para reverter a base?Esta é uma operação de reversão muito rara. Sim, você escreve a migração de canetas e o que fazer.
Como uma atualização do servidor é sincronizada com as atualizações do cliente? I.e. você precisa lançar uma nova versão do jogo - você primeiro atualizará todos os servidores e os clientes serão atualizados? O servidor suporta a versão antiga e a nova?Sim, estamos desenvolvendo a alternância de recursos c e o escurecimento dos recursos. I.e. Essa é uma alça especial, uma alavanca que permite ativar alguns recursos posteriormente. Você pode absolutamente atualizar com calma, ver se tudo funciona para você, mas não inclui esse recurso. E quando você já dispersou o cliente, pode aumentar em 10% o tempo de folga, ver se está tudo bem e, em seguida, ao máximo.
Você diz que armazenou partes do projeto separadamente em diferentes repositórios, ou seja, você tem algum tipo de processo de desenvolvimento? Se você mudar o projeto em si, seus testes deverão cair porque você mudou o projeto. Portanto, os testes que estão separados precisam ser corrigidos o mais rápido possível.Eu falei sobre a baleia "interação estreita com testadores". Esse esquema com repositórios diferentes funciona muito bem apenas se houver alguma comunicação muito densa. Isso não é um problema para nós, todos se comunicam facilmente, há uma boa comunicação.
I.e. os testadores suportam o repositório de testes em sua equipe? E os autotestes estão separados?Sim Você criou algum recurso e pode coletar exatamente os autotestes necessários no repositório de testadores e não verifica todo o resto.
Tal abordagem, quando tudo acontece rapidamente - você pode ir imediatamente ao produto para cada confirmação. Você segue essas táticas ou compõe alguns lançamentos? I.e. uma vez por semana, não às sextas-feiras, nem nos finais de semana, você tem alguma tática de lançamento ou o recurso está pronto, posso lançá-lo? Porque, se você fizer um pequeno lançamento com pequenos recursos, é menos provável que tudo vá quebrar e, se algo quebrar, você definitivamente saberá o que.Forçar os usuários do cliente a baixar uma nova versão a cada cinco minutos ou todos os dias não é uma idéia do gelo. Em qualquer caso, você será anexado ao cliente. É ótimo quando você tem um projeto da Web no qual pode atualizar pelo menos todos os dias e não precisa fazer nada. A história é mais complicada com o cliente, temos algum tipo de tática de lançamento e mantemos isso.
Você falou sobre a implantação da automação nos servidores do produto e (como eu a entendo) também há a implantação da automação para um teste - e os ambientes de desenvolvimento? Existe algum tipo de automação implantada pelos desenvolvedores?Quase a mesma coisa. A única coisa não são os servidores de ferro, mas a máquina virtual, mas a essência é a mesma. Ao mesmo tempo, no mesmo Ansible, escrevemos (temos o Ovirt) a criação dessa máquina virtual e a serrilhada nela.
Você tem toda a história armazenada em um projeto, juntamente com os produtos Ansible e as configurações de teste, ou ela vive e se desenvolve separadamente?Podemos dizer que esses são projetos separados. Dev (chamamos de devbox) é uma história quando tudo está em um pacote e, no prod, é uma história distribuída.
Mais conversas com o Pixonic DevGAMM Talks