Quase todos os novos funcionários da Yandex estão surpresos com a magnitude do estresse que nossos produtos sofrem. Milhares de hosts com centenas de milhares de solicitações por segundo. E este é apenas um dos serviços. Ao mesmo tempo, devemos responder às solicitações em uma fração de segundo. Mesmo uma pequena alteração no produto pode ter um impacto significativo no desempenho, por isso é importante testar e avaliar o impacto do seu código no serviço.
Em nosso serviço de tecnologias de publicidade, o teste funciona dentro da estrutura da metodologia de integração contínua, que discutiremos em mais detalhes sobre a organização de 25 de outubro no evento Yandex por dentro , e hoje compartilharemos com os leitores da Habr a experiência de automatizar a avaliação de métricas importantes de produtos relacionadas ao desempenho do serviço. Você aprenderá como confiar a análise em uma máquina e não segui-la nos gráficos. Vamos lá!

Não se trata de como testar o site. Existem muitas ferramentas online para isso. Hoje falaremos sobre um serviço de back-end interno altamente carregado, que faz parte de um grande sistema e prepara informações para um serviço externo. No nosso caso, para páginas de resultados de pesquisa e sites parceiros. Se nosso componente não tiver tempo para responder, as informações dele simplesmente não serão fornecidas ao usuário. Então, a empresa vai perder dinheiro. Portanto, é muito importante responder a tempo.
Quais métricas importantes do servidor podem ser destacadas?
- Solicitação por segundo (RPS) . A felicidade de um usuário é, obviamente, importante para nós. Mas e se não um, mas milhares de usuários vieram até você. Quantas solicitações por segundo o servidor pode suportar e não cair?
- Tempo por solicitação . O conteúdo do site deve ser renderizado o mais rápido possível, para que o usuário não esteja cansado de esperar e não vá à loja para pipoca. No nosso caso, ele não verá uma parte importante das informações na página.
- Tamanho do conjunto residente (RSS) . Certifique-se de monitorar quanto seu programa consome memória. Se o serviço consome toda a memória, dificilmente é possível falar sobre tolerância a falhas.
- Erros de HTTP .
Então, vamos colocá-lo em ordem.
Solicitação por segundo
Nosso desenvolvedor, que lida com o teste de carga há muito tempo, gosta de falar sobre os recursos críticos do sistema. Vamos ver o que é.
Cada sistema possui suas próprias características de configuração que determinam a operação. Por exemplo, comprimento da fila, tempo limite de resposta, pool de threads de trabalho, etc. E assim, pode acontecer que a capacidade do seu serviço esteja em um desses recursos. Você pode realizar um experimento. Aumente cada recurso por vez. Um recurso, cujo aumento aumentará a capacidade do seu serviço, será crítico para você. Em um sistema bem configurado, para aumentar a capacidade, você precisará aumentar não um recurso, mas vários. Mas isso ainda pode ser "sentido". Será ótimo se você puder configurar seu sistema para que todos os recursos funcionem com força total e o serviço caiba dentro dos prazos fornecidos a ele.
Para estimar quantas solicitações por segundo seu servidor suportará, é necessário direcionar um fluxo de solicitações para ele. Como temos esse processo incorporado no sistema de CI, usamos uma "pistola" muito simples com funcionalidade limitada. Mas, a partir do software de código aberto, o Yandex.Tank é perfeito para esta tarefa. Ele possui documentação detalhada. Um presente para o Tank é um serviço para visualizar os resultados.
Um pequeno offtop. O Yandex.Tank possui uma funcionalidade bastante rica, não se limitando a automatizar solicitações de descasque. Também ajudará a coletar métricas do seu serviço, criar gráficos e fixar o módulo com a lógica que você precisa. Em geral, é altamente recomendável conhecê-lo.
Agora você precisa enviar solicitações ao tanque para que ele possa disparar em nosso serviço. Os pedidos com os quais você fará o shell do servidor podem ser do mesmo tipo, criados e propagados artificialmente. No entanto, as medições serão muito mais precisas se você puder coletar um conjunto real de solicitações dos usuários por um determinado período de tempo.
A capacidade pode ser medida de duas maneiras.
Modelo de carga aberta (teste de estresse)
Crie "usuários", ou seja, vários threads que enviarão uma solicitação ao seu sistema. A carga que não forneceremos é constante, mas a acumula ou alimenta em ondas. Então nos aproximará da vida real. Aumentamos o RPS e captamos o ponto em que o serviço em shell "rompe" o SLA. Assim, você pode encontrar os limites do sistema.
Para calcular o número de usuários, você pode usar a fórmula Little (você pode ler sobre isso aqui ). Omitindo a teoria, a fórmula fica assim:
RPS = 1000 / T * trabalhadores, onde
• T - tempo médio de processamento da solicitação (em milissegundos);
• trabalhadores - o número de threads;
• Solicitações de 1000 / T por segundo - esse valor será gerado por um gerador de thread único.
Modelo de carga fechada (teste de carga)
Tomamos um número fixo de "usuários". Você precisa configurá-lo para que a fila de entrada correspondente à configuração do seu serviço esteja sempre entupida. Ao mesmo tempo, não faz sentido aumentar o número de encadeamentos além do limite da fila, pois permaneceremos nesse número e as solicitações restantes serão descartadas pelo servidor com um erro 5xx. Examinamos quantas solicitações por segundo o design poderá emitir. Esse esquema, no caso geral, não é semelhante ao fluxo real de solicitações, mas ajudará a mostrar o comportamento do sistema em carga máxima e avaliar sua taxa de transferência atual.
Para a grande maioria dos sistemas (onde o recurso crítico não está relacionado ao processamento de conexões), o resultado será o mesmo. Ao mesmo tempo, o modelo fechado tem menos ruído, porque o sistema está na área de carga de seu interesse o tempo todo do teste.
Ao testar nosso serviço, usamos um modelo fechado. Após o disparo, a arma nos dá quantos pedidos por segundo nosso serviço foi capaz de emitir. Yandex.Toque neste indicador também é fácil de dizer.
Tempo por solicitação
Se voltarmos ao parágrafo anterior, torna-se óbvio que, com esse esquema, não faz sentido avaliar o tempo de resposta a uma solicitação. Quanto mais forte for o carregamento do sistema, mais ele se degradará e mais ele responderá. Portanto, para testar o tempo de resposta, a abordagem deve ser diferente.
Para obter o tempo médio de resposta, usaremos o mesmo Yandex.Tank. Somente agora definiremos o RPS correspondente ao indicador médio do seu sistema em produção. Após o bombardeio, obtemos tempos de resposta para cada solicitação. Com base nos dados coletados, os percentis dos tempos de resposta podem ser calculados.
Em seguida, você precisa entender o percentil que consideramos importante. Por exemplo, desenvolvemos a produção. Podemos deixar 1% das solicitações de erros, não respostas, solicitações de depuração que funcionam por um longo tempo, problemas com a rede etc. Portanto, consideramos significativo o tempo de resposta, que acomoda 99% das solicitações.
Tamanho do conjunto residente
Nosso servidor trabalha diretamente com arquivos através do mmap . Medindo o índice RSS, queremos saber quanta memória o programa consumiu do sistema operacional durante a operação.
No Linux, o arquivo / proc / PID / smaps é gravado - esta é uma extensão baseada em mapa que mostra o consumo de memória para cada um dos mapeamentos de processos. Se o seu processo usar tmpfs, a memória anônima e a não anônima entrarão em smaps. A memória não anônima inclui, por exemplo, arquivos carregados na memória. Aqui está um exemplo de entrada nos smaps. Um arquivo específico é especificado e seu parâmetro Anonymous = 0kB.
7fea65a60000-7fea65a61000 r--s 00000000 09:03 79169191 /place/home/.../some.yabs Size: 4 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 4 kB Private_Dirty: 0 kB Referenced: 4 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd mr me ms
E este é um exemplo de alocação de memória anônima. Quando um processo (o mesmo mmap) faz uma solicitação ao sistema operacional para alocar um determinado tamanho de memória, um endereço é alocado para ele. Enquanto o processo ocupa apenas memória virtual. Neste ponto, ainda não sabemos qual parte física da memória será alocada. Vemos um registro sem nome. Este é um exemplo de alocação de memória anônima. Foi solicitado ao sistema o tamanho de 24572 kB, mas eles não o utilizaram e, na verdade, apenas RSS = 4 kB foi obtido.
7fea67264000-7fea68a63000 rw-p 00000000 00:00 0 Size: 24572 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 4 kB Referenced: 4 kB Anonymous: 4 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac
Como a memória não anônima alocada não irá a lugar algum após a interrupção do processo, o arquivo não será excluído, não estamos interessados nesse RSS.
Antes de começar a filmar no servidor, resumimos o RSS de / proc / PID / smaps, alocado para memória anônima e lembre-se dele. Realizamos bombardeios, semelhante ao tempo de teste por solicitação. Depois de terminar, considere o RSS novamente. A diferença entre o estado inicial e o final será a quantidade de memória que seu processo usou durante a operação.
Erros HTTP
Não esqueça de seguir os códigos de resposta que o serviço retorna durante o teste. Se algo na configuração de teste ou ambiente deu errado, e o servidor retornou erros 5xx e 4xx para todas as suas solicitações, não havia muito sentido em tal teste. Estamos monitorando a proporção de respostas ruins. Se houver muitos erros, o teste será considerado inválido.
Um pouco sobre a precisão da medição
E agora a coisa mais importante. Vamos voltar aos parágrafos anteriores. Os valores absolutos das métricas calculadas por nós, ao que parece, não são tão importantes para nós. Não, é claro, você pode alcançar a estabilidade dos indicadores, levando em consideração todos os fatores, erros e flutuações. Paralelamente, escreva um trabalho científico sobre esse tópico (a propósito, se alguém estava procurando um, essa pode ser uma boa opção). Mas não é isso que nos interessa.
É importante influenciarmos o commit específico no código em relação ao estado anterior do sistema. Ou seja, a diferença entre as métricas de confirmação para confirmação é importante. E aqui é necessário configurar um processo que compare essa diferença e, ao mesmo tempo, garanta a estabilidade do valor absoluto nesse intervalo.
O ambiente, solicitações, dados, status do serviço - todos os fatores disponíveis para nós devem ser corrigidos. É esse sistema que trabalha para nós como parte da integração contínua, fornecendo informações sobre todos os tipos de mudanças que ocorreram em cada confirmação. Apesar disso, não será possível consertar tudo, haverá ruído. Podemos reduzir o ruído, obviamente, aumentando a amostra, ou seja, fazendo várias iterações do disparo. Além disso, depois de gravar, digamos, 15 iterações, podemos calcular a mediana da amostra resultante. Além disso, é necessário encontrar um equilíbrio entre o ruído e a duração do disparo. Por exemplo, resolvemos um erro de 1%. Se você deseja escolher um método estatístico mais complexo e preciso, de acordo com seus requisitos, recomendamos um livro que lista as opções com uma descrição de quando e qual é usado.
O que mais pode ser feito com barulho?
Observe que o ambiente em que você realiza os testes desempenha um papel importante nesses testes. A bancada de testes deve ser confiável, não deve executar outros programas, pois podem levar à degradação do seu serviço. Além disso, os resultados podem e dependerão do perfil de carga, ambiente, banco de dados e várias "tempestades magnéticas".
Como parte de um único teste de confirmação, realizamos várias iterações em hosts diferentes. Em primeiro lugar, se você usar a nuvem, tudo poderá acontecer lá. Mesmo que a nuvem seja especializada, como a nossa, os processos de serviço ainda funcionam lá. Portanto, você não pode confiar no resultado de um host. E se você tem um host de ferro, onde não há, como na nuvem, mecanismo padrão para elevar o ambiente, pode quebrá-lo acidentalmente uma vez e deixá-lo dessa maneira. E ele sempre mentirá para você. Portanto, conduzimos nossos testes na nuvem.
É verdade que outra questão surge disso. Se suas medidas são feitas a cada vez em hosts diferentes, os resultados podem fazer um pouco de barulho e, por causa disso, incluir. Em seguida, você pode normalizar as leituras para o host. Ou seja, de acordo com dados históricos, colete o "coeficiente do host" e leve em consideração ao analisar os resultados.
A análise de dados históricos mostra que o hardware é diferente. A palavra "hardware" aqui inclui a versão do kernel e as conseqüências do tempo de atividade (aparentemente, objetos do kernel não móveis na memória).
Assim, para cada "host" (na reinicialização, o host "morre" e um "novo" aparece), associamos uma correção pela qual multiplicamos o RPS antes da agregação.
Consideramos e atualizamos as emendas de uma maneira extremamente desajeitada, reminiscentemente suspeita de alguma opção de treinamento de reforço.
Para um determinado vetor de correções pós -ost, consideramos a função objetivo:
- em cada teste, consideramos o desvio padrão dos resultados do RPS "corrigido" obtidos
- tirar a média deles com pesos iguais ,
- temos tau = 1 semana.
Em seguida, fixamos uma correção (para o host com a maior soma desses pesos) em 1,0 e procuramos os valores de todas as outras correções que fornecem um mínimo da função objetivo.
Para validar os resultados em dados históricos, consideramos as correções nos dados antigos, consideramos o resultado corrigido no fresco, comparamos com o não corrigido.
Outra opção para ajustar resultados e reduzir o ruído é normalizar para "sintéticos". Antes de iniciar o serviço a ser testado, execute um "programa sintético" no host, no qual você pode avaliar o estado do host e calcular o fator de correção. Mas, no nosso caso, usamos correções baseadas em host, e essa ideia permaneceu uma ideia. Talvez um de vocês goste dela.
Apesar da automação e de todas as suas vantagens, não se esqueça da dinâmica de seus indicadores. É importante garantir que o serviço não se degrade ao longo do tempo. Você pode não perceber pequenos rebaixamentos, eles podem se acumular e, por um longo período, seus indicadores podem ceder. Aqui está um exemplo de nossos gráficos que estamos vendo no RPS. Ele mostra o valor relativo em cada confirmação verificada, seu número e a capacidade de ver de onde a liberação foi alocada.
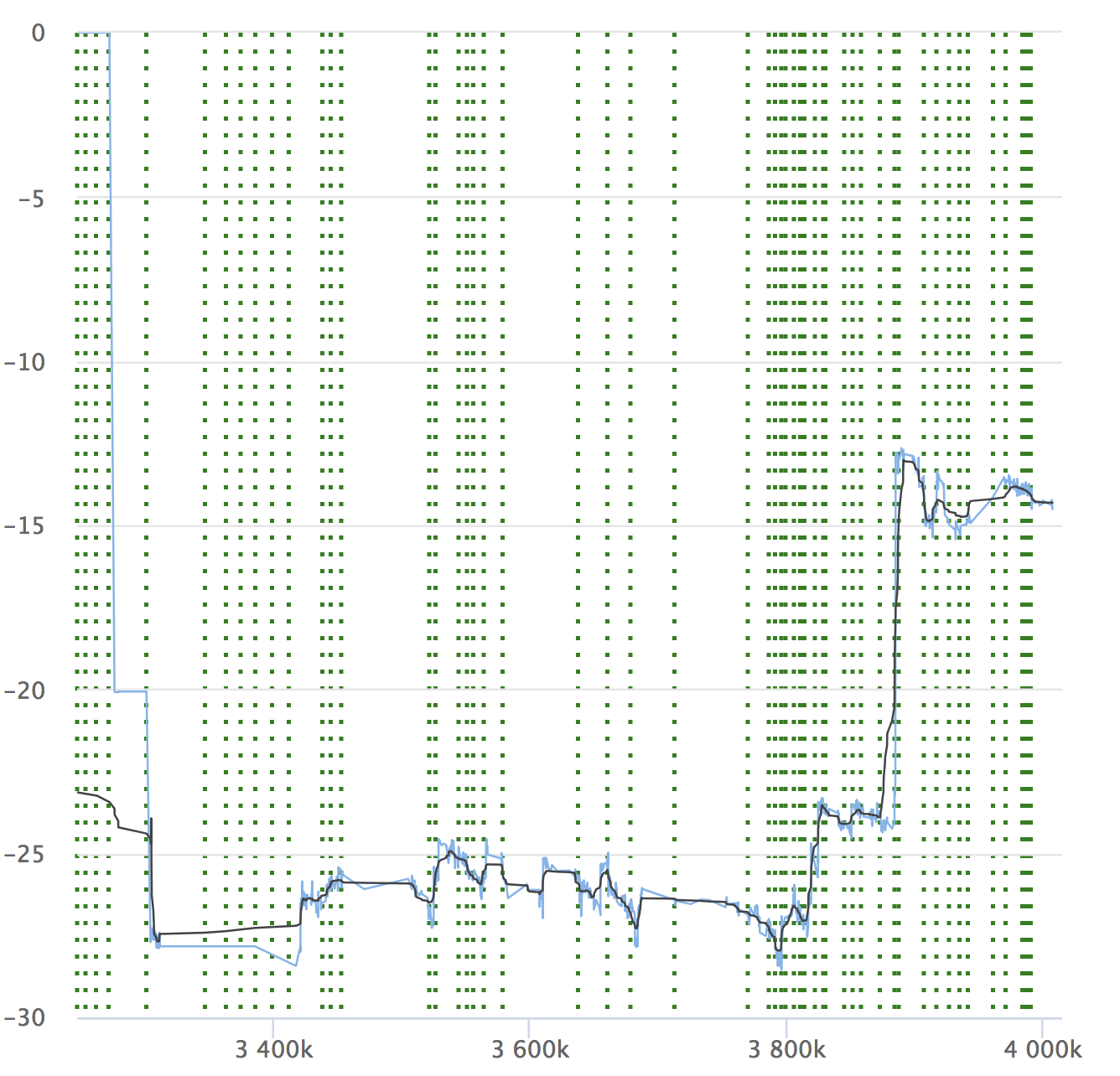
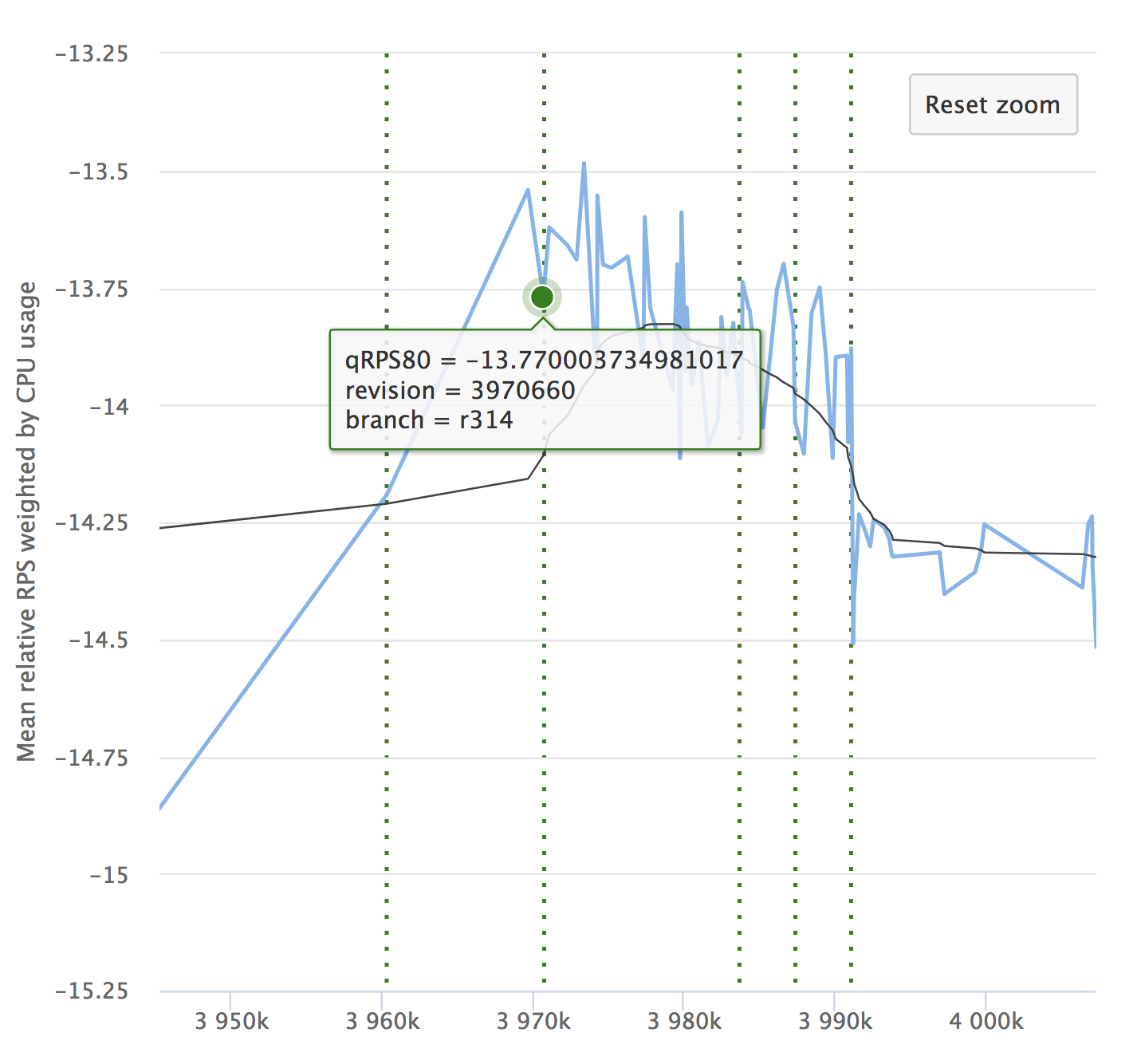
Se você ler o artigo, será definitivamente interessante ver um relatório sobre o Yandex.Tank e uma análise dos resultados dos testes de carga.
Também lembramos que, com mais detalhes sobre a organização da integração contínua, falaremos sobre 25 de outubro no evento Yandex por dentro . Venha visitar!