Apresentamos a sua atenção a técnica de criação de programas assembler com instruções sobrepostas - para proteger o bytecode compilado da desmontagem. Essa técnica é capaz de suportar análises de bytecode estáticas e dinâmicas. A idéia é selecionar um fluxo de bytes que, quando desmontado de dois deslocamentos diferentes, resulte em duas cadeias de instruções diferentes, ou seja, em duas maneiras diferentes de executar o programa. Para fazer isso, seguimos as instruções do assembler multibyte e ocultamos o código protegido nas partes variáveis do bytecode dessas instruções. Para enganar o desmontador, colocando-o em uma trilha falsa (de acordo com uma cadeia de instruções ocultas) e para proteger de seus olhos uma cadeia oculta de instruções.

Três pré-requisitos para criar uma "sobreposição" eficaz
Para enganar o desmontador, o código sobreposto deve atender às três condições a seguir: 1) As instruções da cadeia de máscara e da cadeia oculta devem sempre se cruzar, isto é, não devem estar alinhados um com o outro (o primeiro e o último bytes não devem coincidir). Caso contrário, parte do código oculto será visível na cadeia de mascaramento. 2) Ambas as correntes devem consistir em instruções de montagem plausíveis. Caso contrário, o mascaramento já será detectado no estágio da análise estática (após encontrar um código inadequado para execução, o desmontador corrigirá o ponteiro do comando e expõe o mascaramento). 3) Todas as instruções de ambas as cadeias devem ser não apenas plausíveis, mas também executadas corretamente (para impedir que isso aconteça, o programa travou ao tentar executá-las). Caso contrário, durante a análise dinâmica, as falhas atrairão a atenção do reverso e a máscara será revelada.
Descrição da técnica de instruções de montagem "sobrepostas"
Para tornar o processo de criação de código sobreposto o mais flexível possível, é necessário selecionar apenas essas instruções multibyte, para as quais o maior número possível de bytes possa assumir qualquer valor. Essas instruções multibyte constituirão uma cadeia de instruções de mascaramento.
Em busca do objetivo de criar código sobreposto que satisfaça as três condições acima, consideramos cada instrução de máscara como uma sequência de bytes no formato: XX YY ZZ.
Aqui XX é o prefixo da instrução (código de instrução e outros bytes estáticos - que não podem ser alterados).
AA são bytes que podem ser alterados arbitrariamente (como regra, esses bytes armazenam o valor numérico direto passado para a instrução; ou o endereço do operando armazenado na memória). Deve haver o máximo de bytes YY possível, para que mais instruções ocultas se ajustem a eles.
ZZ - também são bytes que podem ser alterados arbitrariamente, com a única diferença de que a combinação de bytes ZZ com os próximos bytes XX (ZZ XX) deve formar uma instrução válida que satisfaça as três condições formuladas no início do artigo. Idealmente, o ZZ deve ocupar apenas um byte, de modo que em YY (essa é essencialmente a parte mais importante - nosso código oculto é colocado aqui), deve haver o maior número possível de bytes. A última instrução oculta deve terminar em ZZ, - criando um ponto de convergência para as duas cadeias de execução.
Instruções de colagem
A combinação ZZ XX - chamaremos a instrução de colagem. Uma instrução de colagem é necessária, em primeiro lugar, para unir instruções ocultas localizadas em instruções de máscara adjacentes e, em segundo lugar, para atender à primeira condição necessária declarada no início do artigo: as instruções de ambas as cadeias sempre devem se cruzar (portanto, a instrução de colagem sempre localizado na interseção de duas instruções de máscara).
A instrução de colar é executada em uma cadeia oculta de comandos e, portanto, deve ser selecionada de maneira a impor o mínimo de restrições possível ao código oculto. Suponha que, quando executado, os registradores de uso geral e o registro EFLAGS sejam alterados, o código oculto não poderá usar efetivamente os registradores correspondentes e os comandos condicionais (por exemplo, se a instrução de colagem for precedida pelo operador de comparação e a própria instrução de colagem alterar o valor do registro EFLAGS, a transição condicional, que segue as instruções de colagem não funcionará corretamente).
A descrição acima da técnica de sobreposição é ilustrada na figura a seguir. Se a execução começar com os bytes iniciais (XX), uma cadeia de instruções de mascaramento será ativada. E se a partir dos bytes YY, uma cadeia de instruções oculta é ativada.

Instruções de montagem adequadas para a função de "instruções de mascaramento"
A mais longa das instruções, que à primeira vista nos convém, é uma versão de 10 bytes do MOV, onde o deslocamento especificado pelo registro e pelo endereço de 32 bits é transferido como o primeiro operando e o número de 32 bits como o segundo operando. Esta instrução contém o máximo de bytes que podem ser alterados arbitrariamente (até 8 partes).

No entanto, embora essa instrução pareça plausível (teoricamente, pode ser executada corretamente), ainda não nos convém, porque seu primeiro operando, como regra, apontará para um endereço inacessível e, portanto, ao tentar executar esse MOV, o programa entrará em colapso. T.O. esse MOV de 10 bytes não atende à terceira condição necessária: todas as instruções de ambas as cadeias devem ser executadas corretamente.
Portanto, escolheremos para o papel de instruções de mascaramento apenas os candidatos que não apresentem risco de colapso do programa. Essa condição reduz significativamente o intervalo de instruções adequadas para a criação de códigos sobrepostos, mas ainda existem as adequadas. Abaixo estão quatro deles. Cada uma dessas quatro instruções contém cinco bytes, que podem ser alterados arbitrariamente, sem o risco de uma falha no programa.
- LEA. Esta instrução calcula o endereço de memória especificado pela expressão no segundo operando e armazena o resultado no primeiro operando. Como podemos nos referir à memória sem acesso real a ela (e, consequentemente, sem o risco de uma falha no programa), os últimos cinco bytes desta instrução podem assumir valores arbitrários.

- CMOVcc. Esta instrução executa a operação MOV se a condição "cc" for atendida. Para que esta instrução atenda ao terceiro requisito, a condição deve ser selecionada para que, em qualquer circunstância, tenha o valor FALSE. Caso contrário, esta instrução pode tentar acessar um endereço de memória inacessível, e assim por diante. derrubar o programa.

- SETcc Ele opera com o mesmo princípio que o CMOVcc: define o byte como um se a condição "cc" for atendida. Esta instrução tem o mesmo problema que o CMOVcc: acessar um endereço inválido causará uma falha no programa. Portanto, a escolha da condição "cc" deve ser abordada com muito cuidado.

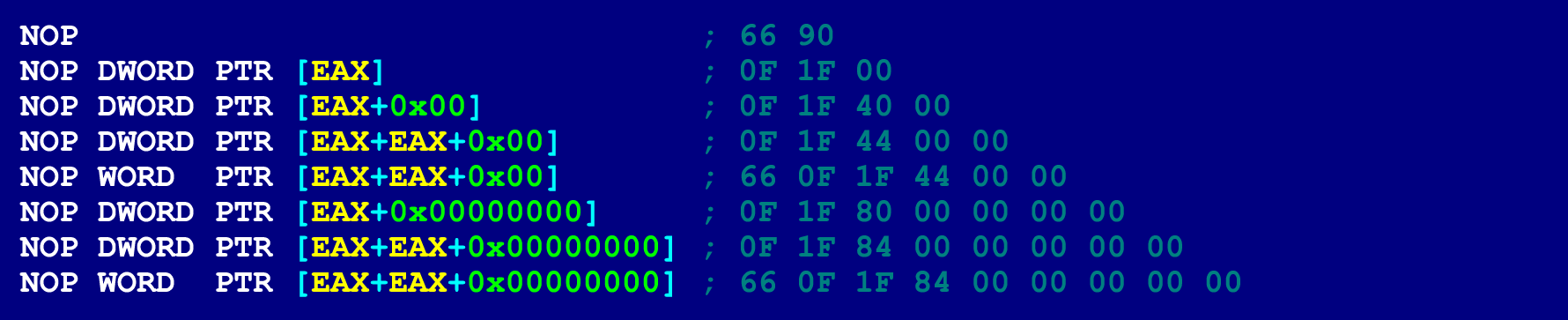
- NOP. Os NOPs podem ter comprimentos diferentes (de 2 a 15 bytes), dependendo de quais operandos são indicados neles. Nesse caso, não haverá risco de travamento do programa (devido ao acesso a um endereço de memória inválido). Como a única coisa que os NOPs fazem é aumentar o contador de instruções (eles não executam nenhuma operação nos operandos). Portanto, os bytes NOP nos quais os operandos são especificados podem assumir um valor arbitrário. Para nossos propósitos, um NOP de 9 bytes é mais adequado.

Para referência, aqui estão algumas outras opções de NOP.
Instruções de montagem adequadas para o papel de "instruções de colagem"
A lista de instruções adequadas para o papel de uma instrução de colagem é exclusiva para cada instrução de máscara específica. Abaixo está uma lista (gerada pelo algoritmo mostrado na figura a seguir) usando NOP de 9 bytes como exemplo.

Para formar esta lista, levamos em conta apenas as opções nas quais o ZZ ocupa 1 byte (caso contrário, haverá pouco espaço para o código oculto). Aqui está uma lista de instruções adesivas adequadas para um NOP de 9 bytes.

Entre esta lista de instruções, não há uma que estaria livre de efeitos colaterais. Cada um deles altera o EFLAGS, ou os registros de uso geral, ou ambos de uma vez. Esta lista é dividida em 4 categorias, de acordo com o efeito colateral da instrução.
A primeira categoria inclui instruções que alteram o registro EFLAGS, mas não alteram os registros de uso geral. As instruções desta categoria podem ser usadas quando não houver saltos condicionais ou quaisquer instruções na cadeia de instruções ocultas com base na avaliação de informações do registro EFLAGS. Nesse caso, neste caso (para um NOP de 9 bytes), existem apenas duas instruções: TEST e CMP.

A seguir, é apresentado um exemplo simples de código oculto que usa TEST como uma instrução de colagem. Este exemplo faz uma chamada ao sistema de saída, que retorna um valor de 1 para qualquer versão do Linux.Para formar corretamente a instrução TEST para nossas necessidades, precisamos definir o último byte do primeiro NOP como 0xA9. Este byte, quando associado aos quatro primeiros bytes do próximo NOP (66 0F 1F 84), se transformará em uma instrução TEST EAX, 0x841F0F66. As duas figuras a seguir mostram o código do montador correspondente (para cadeia de máscara e cadeia oculta). A cadeia oculta é ativada quando o controle é transferido para o quarto byte do primeiro NOP.


A segunda categoria inclui instruções que alteram os valores dos registros gerais ou da memória disponível (pilha, por exemplo), mas não alteram o registro EFLAGS. Ao executar uma instrução PUSH ou qualquer variante MOV, onde um valor imediato é especificado como o segundo operando, o registro EFLAGS permanece inalterado. T.O. as instruções de colagem da segunda categoria podem até ser colocadas entre a instrução de comparação (TEST, por exemplo) e a instrução que avalia o registro EFLAGS. No entanto, as instruções nesta categoria limitam o uso do registro que aparece nas instruções de colagem correspondentes. Por exemplo, se MOV EBP, 0x841F0F66 for usado como uma instrução de colagem, as possibilidades de uso do registro EBP (do restante do código oculto) serão significativamente limitadas.
A terceira categoria inclui instruções que alteram o registro EFLAGS e os registros de uso geral (ou memória). Essas instruções não têm vantagens óbvias sobre as instruções das duas primeiras categorias. No entanto, eles também podem ser utilizados, uma vez que não contradizem as três condições formuladas no início do artigo. A quarta categoria inclui instruções, cuja implementação não garante que o programa não falhe - existe o risco de acesso ilegal à memória. É extremamente indesejável usá-los, porque eles não satisfazem a terceira condição.
Instruções do assembler que podem ser usadas em uma cadeia oculta
No nosso caso (quando os NOPs de 9 bytes são usados como instruções de mascaramento), o comprimento de cada instrução da cadeia oculta não deve exceder quatro bytes (essa restrição não se aplica a instruções fixas que ocupam 5 bytes). No entanto, essa não é uma limitação muito crítica, porque a maioria das instruções com mais de quatro bytes pode ser decomposta em várias instruções mais curtas. A seguir, é apresentado um exemplo de um MOV de 5 bytes muito grande para caber em uma cadeia oculta.
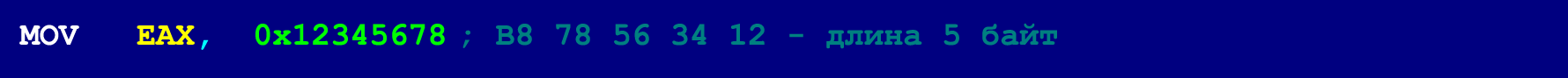
No entanto, esse MOV de cinco bytes pode ser decomposto em três instruções, cujo comprimento não excede quatro bytes.

Aprimorando o mascaramento dispersando os NOPs de mascaramento ao longo do programa
Um grande número de NOPs consecutivos parece, do ponto de vista inverso, muito suspeito. Concentrando seu interesse nesses NOPs suspeitos, um reversor experiente pode chegar ao fundo do código oculto neles. Para evitar essa exposição, os NOPs mascarados podem ser espalhados por todo o programa.
A cadeia correta de execução do código oculto nesse caso pode ser suportada por instruções de byte duplo de salto incondicional. Nesse caso, os dois últimos bytes de cada NOP ocuparão um JMP de 2 bytes.
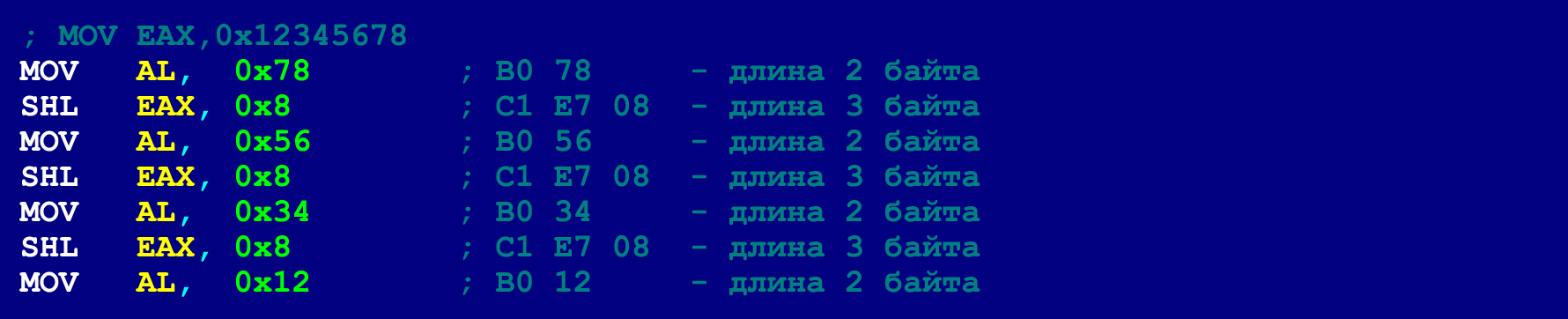
Esse truque permite dividir uma longa sequência de NOPs em várias curtas (ou até usar um NOP cada). No último NOP de uma sequência tão curta, apenas 3 bytes da carga útil podem ser alocados (o 4º byte será obtido pela instrução de salto incondicional). T.O. aqui há uma restrição adicional no tamanho das instruções válidas. No entanto, como mencionado acima, instruções longas podem ser dispostas em uma cadeia de instruções mais curtas. Abaixo está um exemplo do mesmo MOV de 5 bytes, que já estabelecemos para caber no limite de 4 bytes. No entanto, agora decompomos esse MOV de forma a caber no limite de 3 bytes.
Tendo decomposto todas as instruções longas em instruções mais curtas, de acordo com o mesmo princípio, podemos, para mascarar mais, geralmente usar apenas NOPs espalhados por todo o programa. As instruções JMP de dois bytes podem avançar e retroceder 127 bytes, o que significa que dois NOPs consecutivos (consecutivos, em termos de uma cadeia de instruções ocultas) devem estar dentro de 127 bytes.
Esse truque tem outra vantagem significativa (além do mascaramento aprimorado): com sua ajuda, você pode colocar código oculto nos NOPs existentes do arquivo binário compilado (ou seja, inserir uma carga útil no binário após compilá-lo). Nesse caso, não é necessário que esses NOPs órfãos tenham 9 bytes. Por exemplo, se houver vários NOPs de byte único em uma linha no binário, eles poderão ser convertidos em NOPs de vários bytes, sem interromper a funcionalidade do programa. Abaixo está um exemplo de uma técnica para dispersar NOPs (esse código é funcionalmente equivalente ao exemplo discutido acima).

Esse código oculto, oculto no NOP espalhado por todo o programa, já é muito mais difícil de detectar.
Um leitor atento deve ter notado que o primeiro NOP não tem último byte. No entanto, não há nada com que se preocupar. Como esse byte não reclamado é precedido por um salto incondicional. T.O. o controle nunca será transferido para ele. Então, está tudo em ordem.
Aqui está uma técnica para criar código sobreposto. Use na saúde. Esconda seu código precioso de olhares indiscretos. Mas adote outras instruções, não um NOP de 9 bytes. Porque os inversores provavelmente também lerão este artigo.