 Um passo a passo completo do aprendizado de máquina em Python: parte dois
Um passo a passo completo do aprendizado de máquina em Python: parte doisJuntar todas as partes de um projeto de aprendizado de máquina pode ser complicado. Nesta série de artigos, percorreremos todas as etapas da implementação do processo de aprendizado de máquina usando dados reais e descobriremos como as várias técnicas são combinadas entre si.
No
primeiro artigo, limpamos e estruturamos os dados
, realizamos uma análise exploratória, coletamos um conjunto de atributos para uso no modelo e definimos uma linha de base para avaliar os resultados. Com a ajuda deste artigo, aprenderemos como implementar no Python e comparar vários modelos de aprendizado de máquina, executar o ajuste hiperparamétrico para otimizar o melhor modelo e avaliar o desempenho do modelo final em um conjunto de dados de teste.
Todo o código do projeto está
no GitHub , e
aqui está o segundo bloco de anotações relacionado ao artigo atual. Você pode usar e modificar o código como desejar!
Avaliação e Seleção de Modelos
Lembrete: Estamos trabalhando em uma tarefa de regressão controlada, usando
as informações de energia para edifícios em Nova York para criar um modelo que prediz qual
Energy Star Score um edifício em particular receberá. Estamos interessados tanto na precisão da previsão quanto na interpretabilidade do modelo.
Hoje você pode escolher entre os
vários modelos de aprendizado de máquina disponíveis , e essa abundância pode ser intimidadora. Obviamente, existem
análises comparativas na rede que o ajudarão a navegar na escolha de um algoritmo, mas prefiro tentar algumas e ver qual é melhor. Na maioria das vezes, o aprendizado de máquina é baseado em resultados
empíricos e não teóricos , e é quase
impossível entender com antecedência qual modelo é mais preciso .
Geralmente, é recomendável que você comece com modelos simples e interpretáveis, como regressão linear, e se os resultados forem insatisfatórios, passe para métodos mais complexos, mas geralmente mais precisos. Este gráfico (muito anticientífico) mostra a relação entre a precisão e a interpretabilidade de alguns algoritmos:
 Interpretabilidade e precisão ( fonte ).
Interpretabilidade e precisão ( fonte ).Vamos avaliar cinco modelos de graus variados de complexidade:
- Regressão linear.
- O método dos k-vizinhos mais próximos.
- "Floresta aleatória".
- Aumento de gradiente.
- Método de vetores de suporte.
Consideraremos não o aparato teórico desses modelos, mas sua implementação. Se você estiver interessado em teoria, consulte
Introdução à aprendizagem estatística (disponível gratuitamente) ou
Aprendizado de máquina prático com o Scikit-Learn e o TensorFlow . Nos dois livros, a teoria é perfeitamente explicada e a eficácia do uso dos métodos mencionados nas linguagens R e Python é mostrada, respectivamente.
Preencha os valores ausentes
Embora quando limpamos os dados, descartamos as colunas nas quais mais da metade dos valores está ausente, ainda temos muitos valores. Os modelos de aprendizado de máquina não podem funcionar com dados ausentes, portanto, precisamos
preenchê- los.
Primeiro, consideramos os dados e lembramos como eles se parecem:
import pandas as pd import numpy as np
Cada valor
NaN é um registro ausente nos dados.
Você pode preenchê-los de maneiras diferentes , e usaremos o método de imputação mediana bastante simples, que substitui os dados ausentes pelos valores médios das colunas correspondentes.
No código abaixo, criaremos um
objeto Scikit-Learn Imputer com uma estratégia mediana. Em seguida, treinamos nos dados de treinamento (usando
imputer.fit ) e aplicamos para preencher os valores ausentes nos conjuntos de treinamento e teste (usando
imputer.transform ). Ou seja, os registros ausentes nos
dados de teste serão preenchidos com o valor mediano correspondente dos
dados de treinamento .
Realizamos o preenchimento e não treinamos o modelo nos dados como estão, para evitar o problema de
vazamento dos dados de teste quando as informações do conjunto de dados de teste entram no treinamento.
Agora todos os valores estão preenchidos, não há lacunas.
Escala de recursos
Escala é o processo geral de alterar o alcance de uma característica.
Este é um passo necessário , porque os sinais são medidos em unidades diferentes, o que significa que cobrem intervalos diferentes. Isso distorce bastante os resultados de algoritmos como
o método do
vetor de suporte e o método vizinho k-mais próximo, que levam em consideração as distâncias entre as medições. E o dimensionamento permite evitar isso. Embora métodos como
regressão linear e “floresta aleatória” não exijam escala de recursos, é melhor não negligenciar esta etapa ao comparar vários algoritmos.
Escalaremos usando cada atributo para um intervalo de 0 a 1. Pegamos todos os valores do atributo, selecionamos o mínimo e dividimos pela diferença entre o máximo e o mínimo (intervalo). Esse método de dimensionamento é geralmente chamado de
normalização e a outra maneira principal é a padronização .
Esse processo é fácil de implementar manualmente, portanto, usaremos o objeto MinMaxScaler do Scikit-Learn. O código para esse método é idêntico ao código para preencher os valores ausentes, somente a escala é usada em vez de colar. Lembre-se de que aprendemos o modelo apenas no conjunto de treinamento e depois transformamos todos os dados.
Agora, cada atributo tem um valor mínimo de 0 e máximo de 1. Preenchendo os valores ausentes e a escala dos atributos - esses dois estágios são necessários em quase qualquer processo de aprendizado de máquina.
Implementamos modelos de aprendizado de máquina no Scikit-Learn
Depois de todo o trabalho preparatório, o processo de criação, treinamento e execução de modelos é relativamente simples. Usaremos a biblioteca
Scikit-Learn em Python, que é lindamente documentada e com sintaxe elaborada para a construção de modelos. Ao aprender como criar um modelo no Scikit-Learn, você pode implementar rapidamente todos os tipos de algoritmos.
Ilustraremos o processo de criação, treinamento (
.fit ) e teste (
.predict ) usando o aumento de gradiente:
from sklearn.ensemble import GradientBoostingRegressor
Apenas uma linha de código para criação, treinamento e teste. Para construir outros modelos, usamos a mesma sintaxe, alterando apenas o nome do algoritmo.

Para avaliar objetivamente os modelos, calculamos o nível base usando o valor mediano da meta e obtivemos 24,5. E os resultados foram muito melhores, para que nosso problema possa ser resolvido usando o aprendizado de máquina.
No nosso caso, o
aumento do gradiente (MAE = 10,013) acabou sendo um pouco melhor que a "floresta aleatória" (10,014 MAE). Embora esses resultados não possam ser considerados completamente honestos, porque para os hiperparâmetros usamos principalmente os valores padrão. A eficácia dos modelos depende fortemente dessas configurações,
especialmente no método do vetor de suporte . No entanto, com base nesses resultados, escolheremos o aumento de gradiente e começaremos a otimizá-lo.
Otimização de modelo hiperparamétrico
Depois de escolher um modelo, você pode otimizá-lo para a tarefa a ser resolvida ajustando os hiper parâmetros.
Mas antes de tudo, vamos entender o
que são hiperparâmetros e como eles diferem dos parâmetros comuns ?
- Os hiperparâmetros do modelo podem ser considerados as configurações do algoritmo, que definimos antes do início de seu treinamento. Por exemplo, o hiperparâmetro é o número de árvores na "floresta aleatória" ou o número de vizinhos no método k-vizinhos mais próximos.
- Parâmetros do modelo - o que ela aprende durante o treinamento, por exemplo, pesos em regressão linear.
Ao controlar o hiperparâmetro, influenciamos os resultados do modelo, alterando o equilíbrio entre a
falta de educação e a reciclagem . Sob a aprendizagem, há uma situação em que o modelo não é complexo o suficiente (possui poucos graus de liberdade) para estudar a correspondência de sinais e objetivos. Um modelo pouco treinado tem um
alto viés, que pode ser corrigido complicando o modelo.
A reciclagem é uma situação em que o modelo essencialmente se lembra dos dados de treinamento. O modelo reciclado possui uma
alta variação, que pode ser ajustada limitando a complexidade do modelo através da regularização. Os modelos mal treinados e reciclados não serão capazes de generalizar bem os dados de teste.
A dificuldade em escolher os hiperparâmetros certos é que, para cada tarefa, haverá um conjunto ideal exclusivo. Portanto, a única maneira de escolher as melhores configurações é tentar combinações diferentes no novo conjunto de dados. Felizmente, o Scikit-Learn possui vários métodos que permitem avaliar efetivamente os hiperparâmetros. Além disso, projetos como o
TPOT estão tentando otimizar a busca por hiperparâmetros usando abordagens como
a programação genética . Neste artigo, nos restringimos ao uso do Scikit-Learn.
Pesquisa aleatória cruzada
Vamos implementar um método de ajuste de hiperparâmetro chamado pesquisas aleatórias de validação cruzada:
- Pesquisa aleatória - uma técnica para selecionar hiperparâmetros. Definimos uma grade e, em seguida, selecionamos aleatoriamente várias combinações, em contraste com a pesquisa de grade, na qual tentamos sucessivamente cada combinação. A propósito, a pesquisa aleatória funciona quase tão bem quanto a pesquisa em grade , mas muito mais rápido.
- A verificação cruzada é uma maneira de avaliar a combinação selecionada de hiperparâmetros. Em vez de dividir os dados em conjuntos de treinamento e teste, o que reduz a quantidade de dados disponíveis para treinamento, usaremos a validação cruzada do bloco k (validação cruzada do K-Fold). Para fazer isso, dividiremos os dados de treinamento em k blocos e, em seguida, executaremos o processo iterativo, durante o qual treinamos primeiro o modelo em blocos k-1 e, em seguida, comparamos o resultado ao aprender no k-ésimo bloco. Repetiremos o processo k vezes e, no final, obteremos o valor médio do erro para cada iteração. Essa será a avaliação final.
Aqui está uma ilustração gráfica da validação cruzada do bloco k em k = 5:

Todo o processo de pesquisa aleatória de validação cruzada se parece com o seguinte:
- Estabelecemos uma grade de hiperparâmetros.
- Selecione aleatoriamente uma combinação de hiperparâmetros.
- Crie um modelo usando essa combinação.
- Avaliamos o resultado do modelo usando a validação cruzada do bloco k.
- Decidimos quais hiperparâmetros dão o melhor resultado.
Obviamente, tudo isso é feito não manualmente, mas usando o
RandomizedSearchCV do Scikit-Learn!
Usaremos um modelo de regressão baseado em aumento de gradiente. Este é um método coletivo, ou seja, o modelo consiste em numerosos "alunos fracos", neste caso, de árvores de decisão separadas. Se os alunos aprendem em
algoritmos paralelos
como “floresta aleatória” e o resultado da previsão é selecionado por votação, em
algoritmos de otimização como aumento de gradiente, os alunos aprendem em sequência e cada um deles “se concentra” nos erros cometidos por seus antecessores.
Nos últimos anos, os algoritmos de otimização tornaram-se populares e geralmente vencem em competições de aprendizado de máquina.
O aumento de gradiente é uma das implementações nas quais o Gradient Descent é usado para minimizar o custo da função. A implementação do aumento de gradiente no Scikit-Learn é considerada não tão eficaz quanto em outras bibliotecas, por exemplo, no
XGBoost , mas funciona bem em pequenos conjuntos de dados e fornece previsões bastante precisas.
Voltar para a configuração hiperparamétrica
Na regressão usando o aumento de gradiente, há muitos hiperparâmetros que precisam ser configurados. Para obter detalhes, refiro-o à documentação do Scikit-Learn. Vamos otimizar:
loss : minimização da função de perda;n_estimators : o número de árvores de decisão fracas usadas (árvores de decisão);max_depth : profundidade máxima de cada árvore de decisão;min_samples_leaf : o número mínimo de exemplos que devem estar no nó folha da árvore de decisão;min_samples_split : o número mínimo de exemplos necessários para dividir o nó da árvore de decisão;max_features : o número máximo de recursos usados para separar nós.
Não tenho certeza se alguém realmente entende como tudo funciona, e a única maneira de encontrar a melhor combinação é tentar opções diferentes.
Nesse código, criamos uma grade de hiperparâmetros, depois criamos um objeto
RandomizedSearchCV e pesquisamos usando a validação cruzada em quatro blocos para 25 combinações diferentes de hiperparâmetros:
Você pode usar esses resultados para uma pesquisa em grade, selecionando parâmetros para a grade que estão próximos desses valores ótimos. Porém, é improvável que ajustes adicionais melhorem significativamente o modelo. Existe uma regra geral: a construção competente de recursos terá um impacto muito maior na precisão do modelo do que na configuração mais cara do hiperparâmetro. Esta é a
lei da diminuição da lucratividade em relação ao aprendizado de máquina : o design de atributos oferece o maior retorno e o ajuste hiperparamétrico traz apenas benefícios modestos.
Para alterar o número de estimadores (árvores de decisão) e preservar os valores de outros hiperparâmetros, pode ser realizado um experimento que demonstrará o papel dessa configuração. A implementação é dada
aqui , mas aqui está o resultado:
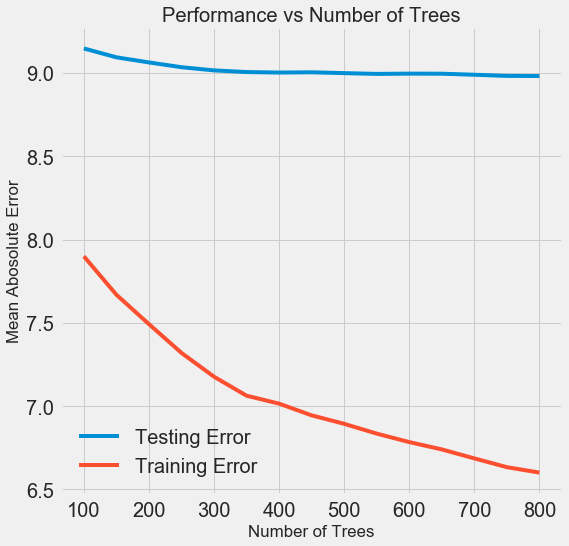
À medida que o número de árvores usadas pelo modelo aumenta, o nível de erros durante o treinamento e o teste diminui. Mas os erros de aprendizado diminuem muito mais rapidamente e, como resultado, o modelo é treinado novamente: mostra excelentes resultados nos dados de treinamento, mas funciona pior nos dados de teste.
Nos dados de teste, a precisão sempre diminui (porque o modelo vê as respostas corretas para o conjunto de dados de treinamento), mas uma queda significativa
indica reciclagem . Esse problema pode ser resolvido aumentando a quantidade de dados de treinamento ou
reduzindo a complexidade do modelo usando hiperparâmetros . Aqui não abordaremos os hiperparâmetros, mas recomendo que você sempre preste atenção ao problema da reciclagem.
Para o nosso modelo final, levaremos 800 avaliadores, pois isso nos dará o menor nível de erro na validação cruzada. Agora teste o modelo!
Avaliação usando dados de teste
Como pessoas responsáveis, garantimos que nosso modelo não tivesse acesso aos dados de teste durante o treinamento. Portanto,
podemos usar a precisão ao trabalhar com dados de teste como um indicador de qualidade do modelo quando ele é admitido em tarefas reais.
Alimentamos os dados de teste do modelo e calculamos o erro. Aqui está uma comparação dos resultados do algoritmo padrão de aumento de gradiente e nosso modelo personalizado:
O ajuste hiperparamétrico ajudou a melhorar a precisão do modelo em cerca de 10%. Dependendo da situação, isso pode ser uma melhoria muito significativa, mas leva muito tempo.
Você pode comparar o tempo de treinamento para ambos os modelos usando o
%timeit magic
%timeit nos cadernos Jupyter. Primeiro, meça a duração padrão do modelo:
%%timeit -n 1 -r 5 default_model.fit(X, y) 1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
Um segundo para estudar é muito decente. Mas o modelo ajustado não é tão rápido:
%%timeit -n 1 -r 5 final_model.fit(X, y) 12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
Essa situação ilustra o aspecto fundamental do aprendizado de máquina:
trata-se de compromissos . É constantemente necessário escolher um equilíbrio entre precisão e interpretabilidade, entre
deslocamento e dispersão , entre precisão e tempo de operação, e assim por diante. A combinação certa é completamente determinada pela tarefa específica. No nosso caso, um aumento de 12 vezes na duração do trabalho em termos relativos é grande, mas em termos absolutos é insignificante.
Obtivemos os resultados finais da previsão, agora vamos analisá-los e descobrir se há algum desvio perceptível. À esquerda, há um gráfico da densidade da previsão e dos valores reais, à direita, um histograma do erro
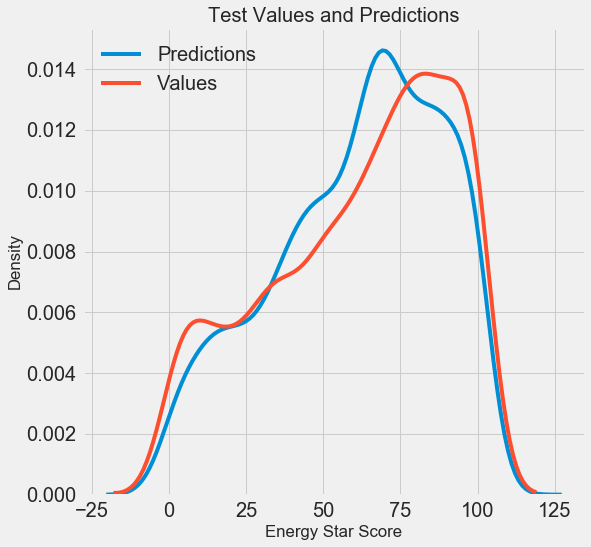

A previsão do modelo repete bem a distribuição dos valores reais, enquanto nos dados de treinamento, o pico de densidade está localizado mais próximo do valor mediano (66) do que o pico de densidade real (cerca de 100). Os erros têm uma distribuição quase normal, embora existam vários valores negativos grandes quando a previsão do modelo é muito diferente dos dados reais. No próximo artigo, examinaremos mais detalhadamente a interpretação dos resultados.
Conclusão
Neste artigo, examinamos várias etapas da solução do problema de aprendizado de máquina:
- Preenchendo valores ausentes e recursos de dimensionamento.
- Avaliação e comparação dos resultados de vários modelos.
- Ajuste hiperparamétrico usando pesquisa aleatória em grade e validação cruzada.
- Avaliação do melhor modelo usando dados de teste.
Os resultados indicam que podemos usar o aprendizado de máquina para prever o Energy Star Score com base nas estatísticas disponíveis. Com a ajuda do aumento de gradiente, foi obtido um erro de 9,1 nos dados de teste. O ajuste hiperparamétrico pode melhorar muito os resultados, mas ao custo de uma desaceleração significativa. Esse é um dos muitos compromissos a serem considerados no aprendizado de máquina.
No próximo artigo, tentaremos descobrir como nosso modelo funciona. Também veremos os principais fatores que influenciam o Energy Star Score. Se soubermos que o modelo é preciso, tentaremos entender por que ele prediz dessa maneira e o que isso nos diz sobre o problema em si.