
Olá novamente, Alexey Pristavko está em contato, e esta é a segunda parte da minha história sobre o DataLine de armazenamento de objetos S3 baseado no Cloudian HyperStore.
Hoje vou falar detalhadamente sobre como nosso armazenamento S3 é organizado e quais dificuldades encontramos no processo de criação. Certifique-se de tocar no tópico “ferro” e analisar o equipamento no qual acabamos ficando.
Vamos lá!
Se, durante a leitura, você deseja se familiarizar com a arquitetura de aplicativos da solução Cloudian, encontrará sua análise detalhada no
artigo anterior . Aqui discutimos em detalhes o dispositivo interno Cloudian, a tolerância a falhas e a lógica do SDS embutido.
O esquema final do equipamento físico
Como mais tarde falaremos sobre o nosso "tormento de escolha", darei imediatamente a lista final de ferro a que chegamos. Pequeno aviso: a escolha do equipamento de rede deveu-se em grande parte à sua presença em nosso (a propósito, muito sólido) armazém.
Portanto, no nível físico do armazenamento, temos o seguinte equipamento:
Nome
| Função
| Configuração
| Qtde
|
Servidor Lenovo System x3650 M5
| Nó de trabalho
| 1x Xeon E5-2630v4 2.2GHz,
4x DDR4 de 16 GB,
14x 10 TB 7.2K 6Gbps SATA 3.5 ",
2x SSD de 480 GB,
Intel x520 de porta dupla 10GbE SFP +,
PSU HS de 2x750W
| 4
|
Servidor HP ProLiant DL360 G9
| Nó do balanceador de carga
| 2 E5-2620 v3,
128G RAM,
2 SSD de 600 GB,
4 SAS HDD,
SFP + 10GbE de porta dupla Intel x520
| 2
|
Switch Cisco C4500
| Gateway de fronteira
| Catalisador WS-C4500X-16SFP +
| 2
|
Switch Cisco C3750
| Extensor de porta
| Catalisador WS-C3750X-24T com C3KX-NM-10G
| 2
|
Switch Cisco C2960
| plano de controle
| Catalisador WS-C2960 + 48PST-L
| 1
|
Para uma melhor compreensão da arquitetura, examinaremos todos os elementos e falaremos sobre seus recursos e tarefas.
Vamos começar com os servidores. Os servidores Lenovo têm uma configuração especial implementada em conjunto e em total conformidade com as recomendações e especificações da Cloudian. Por exemplo, eles usam um controlador com acesso direto ao disco. Como no nosso caso, o RAID é organizado no nível do software aplicativo, esse modo aumenta a confiabilidade e acelera o subsistema de disco. Exatamente os mesmos servidores podem ser adquiridos como um Cloudian Appliance junto com todas as licenças.
Os servidores de balanceamento de carga com o Nginx for CentOS garantem uma distribuição de carga uniforme nos nós de trabalho e abstraem o usuário da organização de tráfego interno. E como um bônus agradável - se necessário, você pode organizar um cache neles.
O par Cisco 4500X dezesseis 10 GB SFP + serve como o núcleo e a fronteira de nossa pequena, mas orgulhosa rede de armazenamento. Obviamente, o ferro é um pouco antiquado, mas não é inferior ao “novo” em confiabilidade, possui redundância interna e sua funcionalidade atende a todos os nossos requisitos. C3750 desempenha o papel de extensor de fábrica, não há necessidade de empurrar transceptores 1G em slots 10G. E mudar completamente para links de 10 GB também não faz muito sentido ainda. Como os testes demonstraram, encontramos o processador e os discos anteriormente.
O diagrama abaixo ilustra com detalhes suficientes a organização física descrita por mim:
 1. Esquema da organização de armazenamento físico
1. Esquema da organização de armazenamento físicoVamos seguir o esquema. Como você pode ver, a tolerância a falhas no nível físico é realizada duplicando e conectando cada um dos dispositivos com pelo menos dois links ópticos, um para cada dispositivo em um par. Isso nos garante a manutenção da conectividade física no circuito durante um acidente de qualquer dispositivo de rede ou dois dispositivos de pares diferentes ao mesmo tempo.
Vamos abaixo do esquema. Os dois pares da Cisco (4500/4500, 3750/3750) são combinados em um único dispositivo lógico usando a pilha e o VSS. A pilha é montada com dois cabos, VSS através de três links ópticos de 10G. Isso permite garantir que os dois dispositivos de cada par interajam como um todo. Esse agrupamento nos permite trabalhar na estrutura de um segmento L2 transparente por meio de ambos os dispositivos de um par e fazer agregação geral de links usando o LACP, uma vez que essa tecnologia é suportada nativamente pelo SO do servidor e pelo Cisco IOS. Do lado do servidor, parece que ele está trabalhando com um switch em vez de dois e, acima do aplicativo, há um canal agregado de capacidade dupla.
Todo o equipamento de rede que alterna entre si e para os canais de entrada é feito usando links 10G ópticos, o equipamento para servidor é conectado usando cabos 10G Twinax Cisco e cobre 1G.
O BGP é usado para tolerância a falhas no canal de entrada e o Round Robin DNS é usado para equilibrar entre endereços IP externos. Os próprios endereços externos estão estacionados nos servidores de balanceamento de carga e, se necessário, migram entre os nós usando o pacote Pacemaker / Corosync.
O monitoramento e controle via IPMI são realizados através de um link interno direto. Todas as interfaces de gerenciamento (servidores e Cisco) são conectadas através de comutadores de plano de controle separados. Eles, por sua vez, estão incluídos na rede de controle do data center. Isso nos garante a impossibilidade de perder a comunicação com o equipamento durante o trabalho ou como resultado de um acidente em uma rede externa. Para o caso mais extremo, há atendentes na KVM.
Rede lógica
Para entender como funciona a rede lógica S3 do armazenamento DataLine, passemos para outro esquema:
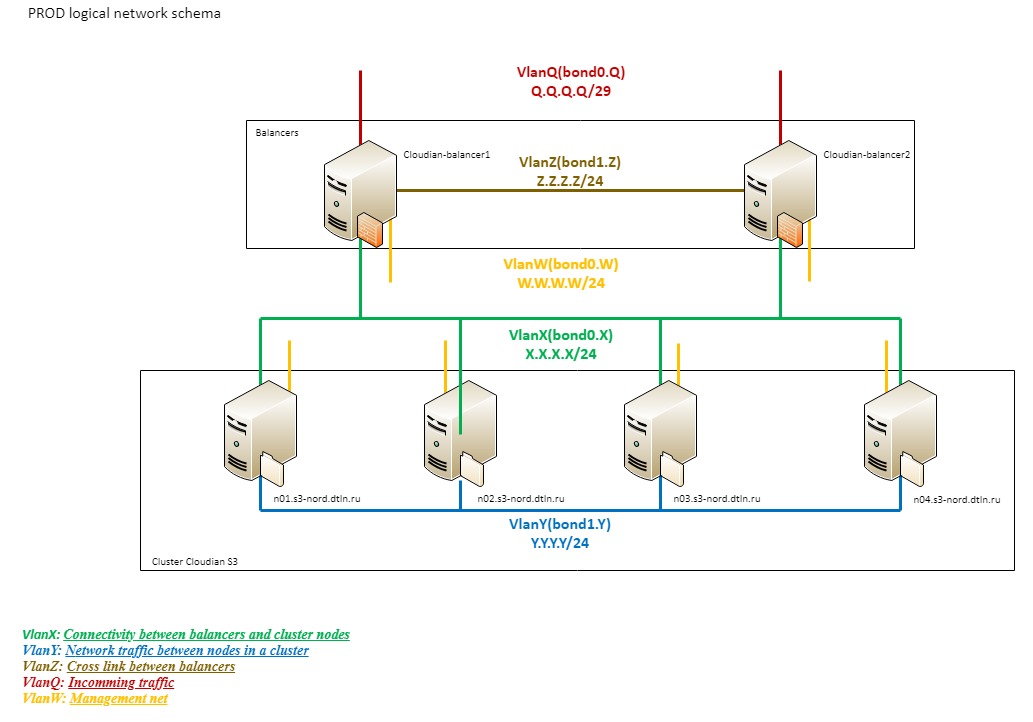 2. Diagrama de rede lógica de armazenamento
2. Diagrama de rede lógica de armazenamentoComo você pode ver, a lógica da rede consiste em vários segmentos.
Uma rede externa (Q) com capacidade total de 20G é conectada diretamente ao Provider Edge. Isto é seguido pelo Cisco 4500 e balanceadores.
O próximo bloco lógico (X) é a VLAN entre os balanceadores e os nós de trabalho. Os balanceadores usam a mesma conexão que para o tráfego recebido. Os nós de trabalho são conectados via pilha 3750 com 4 links 1G (dois para cada 3750). Todos os links físicos são montados em um único lógico usando o LACP também. Essa rede é usada apenas para processar o tráfego do cliente.
Todas as conexões no cluster Cloudian (Y) passam por um terceiro segmento lógico construído sobre o 10G. Essa organização ajuda a evitar problemas no canal externo devido ao tráfego interno e vice-versa. Este é um segmento extremamente carregado e importante para a operação do cluster. É através dele que dados e metadados são replicados, usados por quaisquer procedimentos de reequilíbrio etc., portanto, distinguimos sua “impossibilidade de afundar” como uma tarefa separada.
Um pouco de beleza
É assim que tudo se parece:
 3. Equipamento de rede e balanceadores completos
3. Equipamento de rede e balanceadores completos 4. A mesma vista traseira
4. A mesma vista traseiraPreste atenção à mudança. Em artigos anteriores, meus colegas escreveram sobre a importância dos cabos de marcação de cores, mas não será fora do lugar abordar esse tópico aqui.
Usamos a troca de cores não apenas para a rede, mas também para energia. Isso permite que nossos engenheiros naveguem rapidamente no rack e reduz a influência do fator humano durante a troca.
 5. Nós de trabalho
5. Nós de trabalho 6. Vista traseira
6. Vista traseiraNesta foto, você pode ver claramente como os servidores em funcionamento estão cheios de discos - praticamente não há slots vazios nem na parte de trás. A propósito, essa organização de cabos em feixes compactos desempenha não apenas uma função estética, mas também evita a sobreposição de ventiladores de fontes de alimentação, poupando ferro do superaquecimento.
Lista de permissões
Nos comentários do último artigo, prometi falar mais sobre o dispositivo da lista de permissões.
Se, por algum motivo, concordamos com o cliente em excluir das contas todo o trabalho com armazenamento do interior do datacenter ou através de canais diretos para o equipamento, precisamos organizar uma conexão privada com o armazenamento.
Lembre-se, no primeiro diagrama, havia um ramo no DIST e no Cloud? Além do principal canal da Internet de 20Gb, usamos um canal agregado para comutadores, ao qual conectamos todos os clientes no nível do datacenter. Se o cliente desejar um link direto para o armazenamento, podemos configurar a VLAN do cliente para o nosso 4500X com a construção de uma rota separada (ou sem ela) e iniciar o L3. Depois disso, a ligação ao plano tarifário é configurada nos endereços do cliente já no próprio Cloudian. Então, para todos os que estão conectados a esse plano tarifário, o uso do S3 nos endereços da lista de permissões não será considerado.
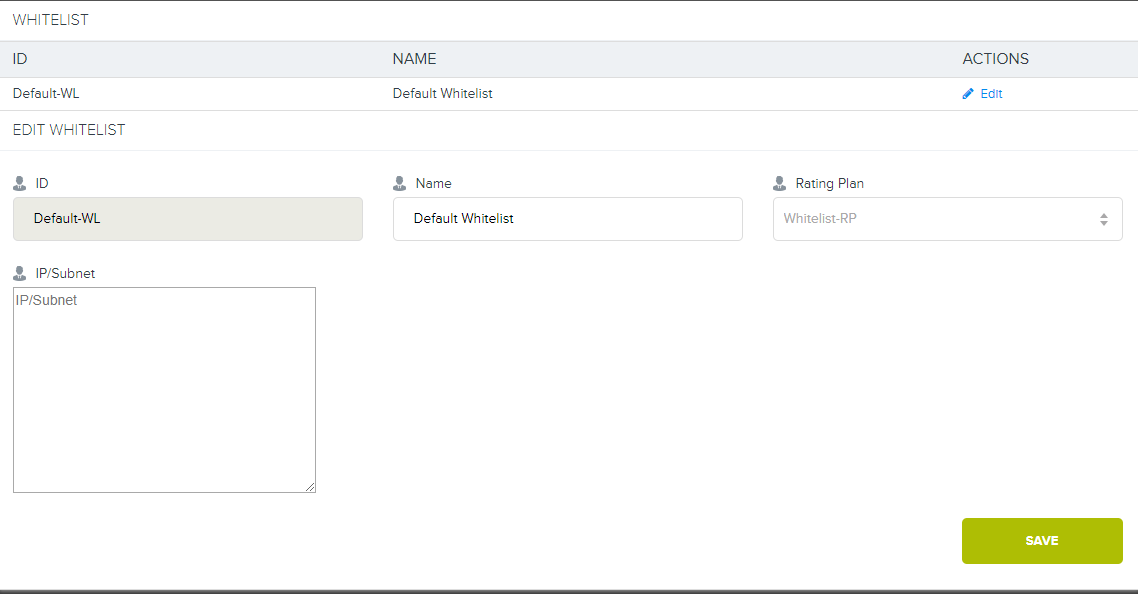 7. E aqui está uma interface especial no Cloudian.
7. E aqui está uma interface especial no Cloudian.Agora não temos essa tarifa na rede, mas se você realmente quiser, podemos fornecê-la.
História da construção
Estamos gradualmente nos aproximando da parte mais interessante da história - a construção de uma instalação de armazenamento. Haverá muitas fotos, até três tentativas de organizar o balanceamento de tráfego e algumas dicas ruins. Espero que a análise dos problemas que encontramos no caminho seja útil para aqueles que estão se preparando para trabalhar com velocidades de 10Gb + na web.
Experimentando 10G
Antes de ir diretamente para a essência desta seção, permito-me fazer outro pequeno aviso.
De acordo com uma tradição estabelecida, antes de comprar novos equipamentos auxiliares, vamos ao armazém e selecionamos componentes mais ou menos adequados. Isso permite que você realize testes rapidamente e decida uma lista de compras futura. Obviamente, enquanto não estamos alcançando um resultado 100% confiável, nada é gasto na produtividade.
Então foi dessa vez. E se a Cisco não lançou nenhuma surpresa, então os balanceadores de carga "ganância" quase nos arruinaram.
A primeira experiência. Servidores Supermicro
Aqui, ficamos decepcionados com o desejo de realizar um teste rápido com custo mínimo. No armazém, encontramos servidores Supermicro com tudo bem, exceto pela falta de interfaces SFP. Decidimos instalar o nosso amado Intel 520DA2 neles e enfrentamos imediatamente o primeiro problema: as máquinas são de unidade única, mas não há risers. Ao mesmo tempo, por algum motivo, nosso corpo não estava em listas de compatibilidade, mas havia muitos risers nativos.
A conselho do diretor de desenvolvimento inovador, Misha Solovyov, conectamos tudo com risers flexíveis para fazendas de mineração. O resultado foi um "cadáver":
 8. Protótipo nº 1
8. Protótipo nº 1Eu tive que usar a famosa fita elétrica azul em alguns lugares, para que, Deus me livre, faça qualquer coisa curta. Sim, a fazenda coletiva. Sim, envergonhado. Mas essa "configuração" é bastante aceitável para o período do experimento.
 9. Vista traseira
9. Vista traseiraO que veio disso é claramente visível na captura de tela do iperf:
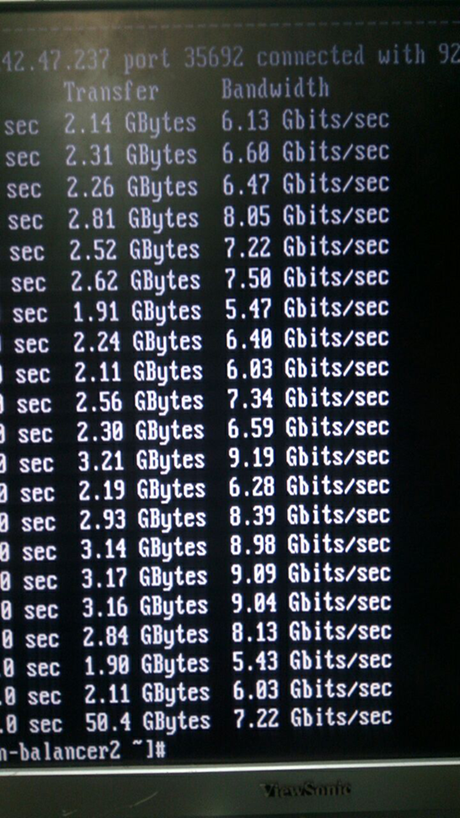 10. Na verdade, isso não é uma captura de tela :)
10. Na verdade, isso não é uma captura de tela :)As métricas são muito interessantes, certo? Então ficamos tristes. A princípio, pensamos em chips espiões, desmontamos e ajeitamos tudo.
 11. À primeira vista, não há chips de espionagem aqui
11. À primeira vista, não há chips de espionagem aquiEles recordaram o curso da física: interferência eletromagnética, sinais de alta frequência, etc. ... É claro que continuar o experimento com uma quantidade e qualidade dessa "fazenda coletiva" não fazia sentido. Finalmente, desmontamos o sistema e colocamos os servidores de volta no lugar.
A segunda experiência. Citrix Netscaler MPX8005
No processo de devolução dos servidores ao local, encontramos novos heróis: Citrix Netscaler MPX8005. Além disso, este é um ferro de marca maravilhoso, quase nunca usado. Eles se parecem com isso:
 12. O slide no rack não cabia no comprimento, mas nós, visionários, decidimos adiá-lo para mais tarde
12. O slide no rack não cabia no comprimento, mas nós, visionários, decidimos adiá-lo para mais tardeEquipamento colocado em um rack, comutado e configurado. Estes são realmente excelentes pedaços de ferro “adultos”, 2 slots SFP para 10 GB cada, HA, algoritmos avançados, há até L7. É verdade, até 5 gigabits sob licença, mas ainda usamos L3, mas não existem limites.
Dedos cruzados, teste. Não há velocidade. Nas interfaces - erros sólidos sobre transceptores inadequados, velocidade de cerca de 5 gigabits, quedas constantes. Lembraram-se dos tirantes flexíveis, ficaram tristes novamente. Mesmo lá, a velocidade era maior e menos erros. Começamos a entender:
show channel LA/1 1) Interface LA/1 (802.3ad Link Aggregate) #10 flags=0x4100c020 <ENABLED, UP, AGGREGATE, UP, HAMON, HEARTBEAT, 802.1q> MTU=9000, native vlan=1, MAC=XXX, uptime 0h03m23s Requested: media NONE, speed AUTO, duplex NONE, fctl NONE, throughput 160000 Link Redundancy Throughput 80000 Actual: throughput 20000 LLDP Mode: NONE RX: Pkts(9388) Bytes(557582) Errs(0) Drops(1225) Stalls(0) TX: Pkts(10514) Bytes(574232) Errs(0) Drops(0) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) bandwidthHigh: 160000 Mbits/sec, bandwidthNormal: 160000 Mbits/sec. LA mode: AUTO > show interface 10/1 1) Interface 10/1 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #1 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m44s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8921) Bytes(517626) Errs(0) Drops(585) Stalls(0) TX: Pkts(9884) Bytes(545408) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set. > show interface 10/2 1) Interface 10/2 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #0 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m58s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8944) Bytes(530975) Errs(0) Drops(911) Stalls(0) TX: Pkts(10819) Bytes(785347) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set.
Usamos transceptores nativos da Cisco, com os quais, em teoria, não devem surgir problemas. Eles até checaram a ótica e, por precaução, mudaram os transceptores - a mesma imagem. Nosso carro não vai, e é isso! Nós olhamos mais de perto.
Transceptores Cisco "bonitos":
ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CISCO-AVAGO , part number XXX , 10G 0x10 1G 0x00 CT 0x00 *** Unsupported SFP+/SFP type!
Os transceptores não são detectados normalmente, sem suporte!
Eu tive que encontrar a maioria dos "parentes":
 13. Os transceptores mais nativos do oeste selvagem
13. Os transceptores mais nativos do oeste selvagem ix0: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe020-0xe03f mem 0xf7820000-0xf783ffff,0xf7844000-0xf7847fff irq 16 at device 0.0 on pci1 platform: Manufacturer Citrix Inc. platform: NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 675320 (28), manufactured at 8/10/2015 platform: serial 4NP602H7H0 platform: sysid 675320 - NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 ix0: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00 ix0: [ITHREAD] 10/2: Ethernet address: 00:e0:ed:45:39:f8 ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00
Esses transceptores foram determinados sem problemas, mas isso não salvou a situação. Firmware atualizado - a mesma coisa. O suporte da Citrix decidiu ficar quieto com muito tato (não, não por causa do pedigree do transceptor).
Respiramos fundo e enterramos as especificações de hardware. Aconteceu que a resposta todo esse tempo estava diante de nossos olhos:
velocidade do barramento ixgbe = 5,0 Gbps e largura da pista PCIe = 8. Esse é um problema com a placa. Ela própria não tem velocidade PCIe. Nosso Citrix tem o desempenho máximo do slot PCI-e para uma placa com transceptores de
5,0 Gbps, que ele gritou para nós durante todo esse tempo. Como o Citrix no MPX8015 (é exatamente o mesmo em hardware!) Eles queriam distribuir 15 gigabits, não está claro. Mas entendemos por que esses balanceadores "legais" todo esse tempo estavam em um armazém. Eles não podem funcionar corretamente com links 10G em princípio.
A última experiência. Usamos o ferro certo e o tornamos bonito
Aqui, nossa paciência terminou com nossa fé na humanidade, e tivemos que usar a tecnologia "sobressalente" para obter o hardware normal na forma do HP ProLiant DL360 G9 nas fotos acima. Eles não começaram a arranjar surpresas para nós, eles baixam o 10G e não reclamam. :)
Teste de carga
Como não aceitamos a abordagem hujak-hujak-and-production, e sabemos por experiência própria que um sistema não testado após a montagem com quase 100% de garantia será inoperante, decidimos realizar testes de estresse. Além disso, com sua ajuda, você pode fazer alguns ajustes para o futuro.
Para gerar a carga, foi escolhida a ferramenta usual - Apache Jmetr. Por si só, é muito bom, como
escrevi alguns artigos, e esta é uma das soluções mais flexíveis do mercado, mesmo que o Java goste de comer. Para trabalhar com o S3, usamos um módulo auto-escrito usando o AWS SDK, também em Java. Nos testes, conseguimos atingir uma velocidade de 12,5 Gbps para gravar arquivos com mais de 250 megabytes com carregamento paralelo por partes de 5 megabytes e arquivos com menos de 5 megabytes - processando cerca de 3000 solicitações HTTP por segundo. Ao executar os dois testes em paralelo, resultou em cerca de 11 Gigabits e 2200 solicitações por segundo. Ao mesmo tempo, existe a possibilidade de melhorar o trabalho com uma carga mista e com pequenos objetos. Nós "enterramos" na CPU, e o segundo soquete é gratuito. No gerador de carga, os arquivos de teste foram retirados da RAM para excluir a influência nos resultados do subsistema de disco do próprio gerador. Para testes, lembrando o amor do Java pela RAM e a necessidade de trabalhar com um grande número de threads durante o carregamento paralelo, usamos o servidor HP DL980 g7 como gerador. Este é um servidor de oito unidades com 8 processadores Intel E7-4870 e 512 GB de RAM a bordo.
Dentro da equipe, o apelido carinhoso Behemoth grudava nele.
 14. Nosso hipopótamo. Verdade, algo semelhante?
14. Nosso hipopótamo. Verdade, algo semelhante? 15. Vista traseira. Os cabos assustadores no centro inferior são uma conexão cruzada do barramento interno da ponte
15. Vista traseira. Os cabos assustadores no centro inferior são uma conexão cruzada do barramento interno da ponte 16. Este é um dos dois objetivos do servidor. Cada um possui 4 processadores e 16 slots de 16 gigabytes de RAM
16. Este é um dos dois objetivos do servidor. Cada um possui 4 processadores e 16 slots de 16 gigabytes de RAM 17. Para usar o Htop confortavelmente no console desse servidor, você precisa de um monitor grande :)
17. Para usar o Htop confortavelmente no console desse servidor, você precisa de um monitor grande :)Na prática, um teste misto carregou notavelmente até um servidor tão poderoso.
Para chegar aos resultados de desempenho obtidos, tivemos que transferir a rede interna do cluster para jumbo frames de 9k e ajustar ligeiramente a pilha de balanceadores e nós de trabalho da rede (usamos o CentOS Linux), além de otimizar vários outros parâmetros do kernel nos nós de trabalho:
cat /etc/sysctl.conf … kernel.printk = 3 4 1 7 read_ahead_kb = 1024 write_expire = 250 read_expire = 250 fifo_batch = 128 front_merges = 0 net.core.wmem_default = 16777216 net.core.wmem_max = 16777216 net.core.rmem_default = 16777216 net.core.rmem_max = 16777216 net.core.somaxconn = 5120 net.core.netdev_max_backlog = 50000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_max_syn_backlog = 30000 net.ipv4.tcp_max_tw_buckets = 2000000 fs.file-max = 196608 vm.overcommit_memory = 1 vm.overcommit_ratio = 100 vm.max_map_count = 65536 vm.dirty_ratio = 40 vm.dirty_background_ratio = 5 vm.dirty_expire_centisecs = 100 vm.dirty_writeback_centisecs = 100 net.ipv4.tcp_fin_timeout=10 net.ipv4.tcp_congestion_control=htcp net.ipv4.netfilter.ip_conntrack_max=1048576 net.core.rmem_default=65536 net.core.wmem_default=65536 net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.ipv4.ip_local_port_range=1024 65535
As principais configurações submetidas ao ajuste são o tamanho dos buffers, o número de conexões de rede, o número de conexões à porta e as conexões monitoradas por firewalls, além de tempos limite.
Cisco C3750 + LACP = dorOutra armadilha no desempenho da rede é o balanceamento de carga ao usar o LACP / LAGp. Infelizmente, o Cisco 3750s não pode equilibrar a carga entre portas, apenas nos endereços de origem e destino. Para obter o balanceamento correto do tráfego, tive que pendurar 12 endereços IP nas interfaces de vínculo dos nós em funcionamento, "olhando" para os clientes. Condicionalmente, 3 para cada link físico. Com essa configuração, era possível ficar sem o LACP nas interfaces "externas" dos nós em funcionamento, pois todos os endereços são especificados na configuração do Nginx, mas se o link fosse perdido, reduziríamos automaticamente o peso do nó no balanceamento. Com o "dump", o link LACP permite manter a acessibilidade total a todos os endereços.
bond0.10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 RX packets:2390824140 errors:0 dropped:0 overruns:0 frame:0 TX packets:947068357 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:18794424755066 (17.0 TiB) TX bytes:246433289523 (229.5 GiB) bond0.10:0 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:1 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:2 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:3 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:4 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:5 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:6 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:7 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:8 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:9 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XXMask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
Teste funcional
Depois de concluir o trabalho no repositório, encontramos o serviço flexify.io. Eles ajudam a facilitar a migração entre diferentes armazenamentos de objetos. Mas para se tornar um parceiro Flexify, você deve passar por testes sérios. "Por que não?" - nós pensamos. Testes de terceiros são sempre uma experiência gratificante.
A principal tarefa dos testes é verificar a operação dos métodos do protocolo S3 por meio de seus proxies em relação a várias configurações, dentre as quais pode haver qualquer conjunto de buckets compatíveis com S3 suportados pelo provedor de serviços.
Primeiro, os métodos que funcionam com objetos no balde são verificados. Nosso armazenamento foi testado usando uma ampla variedade de dados de teste, o comportamento dos métodos foi testado para objetos de vários tamanhos e conteúdos, para chaves contendo todos os tipos de combinações de caracteres Unicode.
Em testes negativos, eles tentaram transferir dados inválidos sempre que possível. Foi dada atenção especial à segurança dos dados no processo.
Os métodos que trabalham com baldes também foram testados, mas principalmente em cenários positivos. O objetivo desses testes foi verificar se o uso de métodos por meio de um proxy não acarreta problemas sérios, como corrupção de dados ou falhas.
A abrangência da cobertura pode ser avaliada pelos testes que foram usados por meio de proxies e diretamente. A maioria dos testes, especialmente aqueles que trabalham com objetos, são parametrizados e testam um grande número de diferentes objetos, intervalos etc.
Testes implementados para objetosSolicitação de objeto GET sem parâmetros opcionais
Solicitação de objeto GET multithread
Solicitação de objeto GET para um objeto criptografado com parâmetros sse fornecidos
Solicitação de objeto GET para um objeto criptografado sem parâmetros sse fornecidos
Solicitação de objeto GET com intervalo que cruza o intervalo de bytes do arquivo
Solicitação de objeto GET com intervalo fora do intervalo de bytes do arquivo
Solicitação de objeto GET com um parâmetro de intervalo de sufixo
Solicitação de objeto GET com um parâmetro de intervalo de sufixo fora do intervalo de bytes do arquivo
Solicitação de objeto GET com parâmetro de intervalo inválido
Solicitação de objeto principal para um objeto existente
Solicitação de objeto principal para um objeto excluído recentemente
Solicitação de objeto principal com uma chave que nunca existiu em um balde
Solicitação de objeto principal para um objeto criptografado com parâmetros sse fornecidos
Solicitação de objeto principal para um objeto criptografado sem parâmetros sse fornecidos
Solicitar lista de objetos
Solicitação de Listar objetos v2
Solicitação de Listar objetos com o parâmetro Marker fornecido
Solicitação de Listar objetos com o parâmetro Prefixo fornecido
Solicitação de Listar objetos com os parâmetros Marker e Prefix fornecidos
Receba todos os objetos no terminal com List Objects com os parâmetros Marker e Prefix fornecidos
Solicitação de Listar objetos com o parâmetro Delimiter ignorado
Solicitação de Listar objetos com o parâmetro Marker passado, mas com o parâmetro Delimiter ignorado
Solicitação de Listar objetos com prefixo não existente passado
Solicitação de lista de objetos com marcador inexistente passado
Upload de várias partes com o método upload_file () nativo
Upload de várias partes com o método upload_fileobj () nativo
Upload de várias partes com método personalizado
Parando o upload de várias partes com o método abort_multipart_upload ()
Executando o método abort_multipart_upload () com uploadId incorreto
Executando o método abort_multipart_upload () com Key e uploadId incorretos
Upload de várias partes de 2 arquivos com a mesma chave simultaneamente. 2º arquivo carregado antes do 1º
Upload de várias partes de 2 arquivos com a mesma chave simultaneamente. 1º arquivo carregado antes do segundo
Upload de várias partes de 2 arquivos com chaves diferentes simultaneamente. 1º arquivo carregado antes do segundo
Upload de várias partes com um tamanho de peça de 512kb
Upload de várias partes com um tamanho de peça maior que o tamanho máximo permitido
Upload de várias partes de um arquivo com partes de tamanhos diferentes
Listar solicitação de upload com várias partes
Solicitação de ACL do objeto PUT para um objeto com o ID do beneficiário fornecido
Solicitação GET Object ACL para um objeto com permissões de acesso adicionais concedidas
Método de marcação de objeto PUT
Método de identificação de objetos GET
Método DELETE Object Tagging
Solicitação de objeto PUT sem parâmetros opcionais
Solicitações de objeto PUT multithread
Solicitações de objeto PUT com parâmetros de criptografia opcionais passados
Solicitações de objeto PUT com o parâmetro Body vazio passado
Objeto GET com o método nativo de download_file ()
Objeto GET com o método nativo download_fileobj ()
Objeto GET com método personalizado usando intervalos
Objeto GET com prefixo com o método nativo de download_file ()
Objeto GET com prefixo com o método nativo download_fileobj ()
Objeto GET com prefixo com método personalizado usando intervalos
DELETE Solicitação de objeto para um objeto existente
DELETE Solicitação de objeto para um objeto não existente
DELETE Solicitação de objetos para um grupo com objetos existentes
Testes realizados para baldeColocar criptografia de bucket
Criptografia de balde GET
DELETE Criptografia de bucket
Solicitação de política de segmento PUT
Solicitação GET Bucket Policy para um bucket com Policy
DELETE a solicitação da Política de bucket para um bucket com Policy
Solicitação de política de bucket do GET para um bucket sem política
EXCLUIR solicitação de Política de Balde para um balde sem Política
Colocar marcação de balde
Obter marcação de bucket
DELETE Marcação de bucket
Criar solicitação de bucket com o nome do bucket existente
Criar solicitação de bucket com o nome exclusivo do bucket
Excluir solicitação de bucket com o nome do bucket existente
Excluir solicitação de bucket com nome exclusivo do bucket
Solicitação de ACL de balde PUT para um balde com o ID do beneficiário fornecido
Solicitação GET Object ACL para um objeto com permissões de acesso adicionais concedidas
Como você pode imaginar, esse é um teste bastante difícil, mas passamos no geral de maneira positiva. Alguns problemas surgiram devido à falta de suporte para SSE e escolas pequenas com suporte Unicode na época:
Falha ao carregar o aplicativo com chaves contendo:
- U + 0000-U + 001F - os primeiros 32 caracteres de controle ilegíveis. Na Amazon, por exemplo, apenas o primeiro U + 0000 não é derramado diretamente.
- E também U + 18D7C, U + 18DA8, U + 18DB4, U + 18DBA, U + 18DC4, U + 18DCE. Esses também são caracteres ilegíveis, mas a Amazon os aceita como chaves. Não houve problemas com todos os outros personagens.
Ao ler o conteúdo do balde, há um problema na chave 66.675, que contém o símbolo U + FFFE. Não é possível obter uma lista completa de chaves em um bucket que contém um objeto com essa chave.
Caso contrário, os testes foram bem-sucedidos e, no final de setembro, aparecíamos na lista de fornecedores disponíveis!
Um breve posfácio e bônus para os leitores
Escrevi anteriormente que o Cloudian HyperStore, apesar de suas muitas vantagens, praticamente não é abordado no segmento de língua russa da Internet.
O primeiro artigo foi sobre os conceitos básicos de trabalho com o Cloudian. Desmontamos sua estrutura interna, nuances arquitetônicas e lemos a tradução da documentação oficial.
Hoje contei como construímos nosso próprio armazenamento e que nuances e armadilhas encontramos.
Aqueles de vocês que querem sentir com canetas o que estamos falando de 2 artigos seguidos podem usar o formulário de feedback
nesta página e descobrir pessoalmente o que é o sal. Como padrão, damos 15Gb por 2 semanas gratuitamente, é claro, com acesso do usuário. Se você deseja compartilhar suas impressões de trabalhar com o repositório, escreva-me no PM. :)
E para aqueles que não são suficientes 15 Gb por 2 semanas, temos uma
pequena missão! Nas fotografias do artigo, colocamos três hipopótamos. As primeiras 50 pessoas que os encontrarem receberão 30Gb por 4 semanas. Para obter um teste ampliado, escreva nos comentários os números das imagens em que os hipopótamos se escondiam e solicite o link acima. Não se esqueça de incluir um link para seu comentário no aplicativo.
Por tradição, se você tiver alguma dúvida, pergunte a eles nos comentários.
Ficarei feliz em respondê-las.