Olá pessoal! Como parte do curso
Python Developer, realizamos outra lição aberta sobre o tópico "Como não escrever em Python". A lição foi ministrada pelo professor e criador do curso,
Stanislav Stupnikov , que tem uma vasta experiência em desenvolvimento industrial e científico. Foram considerados os antipadrões de programação, más práticas e outros males que você precisa conhecer e que devem ser evitados no processo de escrever código.
Veja o vídeo e o resumo para obter detalhes. Aviso: alguns exemplos de código não são recomendados para serem executados no seu computador!
Durante a aula aberta, o professor mostrou slides gerados com o Jupyter Notebook.
Então, vamos começar!
Então, por que não escrever em Python?
Para a conveniência de enviar material, foi preparada uma lista de técnicas que não devem ser usadas no processo de programação. Cada exemplo foi acompanhado por uma amostra de código clara (disponível para visualização gratuita em vídeo). Descrevemos brevemente os principais antipadrões:
- Padrão de fralda. Tratava-se do chamado padrão de "fralda", que geralmente significa tentativa muito ampla, exceto. Por exemplo, você chama uma função que é um invólucro para algo, por exemplo, agrupa uma lib de cliente para algum tipo de banco de dados. Em um bom caso (o sistema é pequeno), tudo ficará bem em 99% dos casos, mas se o sistema for grande, as probabilidades de um problema não serão multiplicadas da melhor maneira. Como resultado, algo constantemente cai ou quebra.
- Antiglobalismo. Todo mundo sabe que variáveis globais são ineficientes, exceto em alguns casos excepcionais. É muito melhor passar tudo na forma de atributos para funções, etc., etc., obtendo os resultados desejados. No entanto, alguns têm uma "ótima idéia" - para usar objetos mutáveis. Consiste em passar não variáveis globais, mas objetos mutáveis para funções, depois alterá-las por dentro e depois não retornar nada. Isso é muito legal!) De fato, um pedaço de um modelo de programação da linguagem C, transferido para o mundo Python.
- Escada para o céu. Como você deve ter adivinhado, esta é uma "escada para o céu". Esse problema é melhor caracterizado por uma imagem simples:
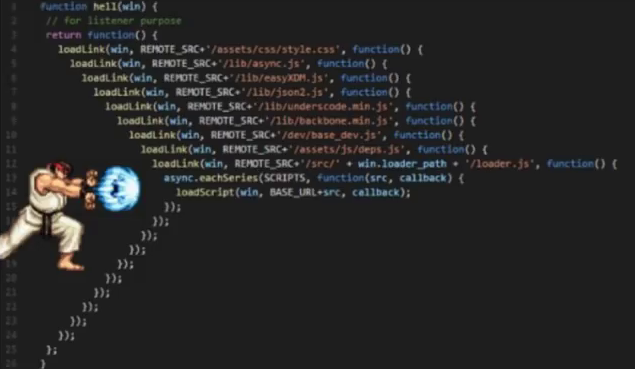
- Javatar. Os erros desse plano geralmente são cometidos por programadores que, por um motivo ou outro, mudaram de Java para Python. Naturalmente, eles vêm com seu próprio estatuto e violam as regras de desenvolvimento do Python em massa. Essa é a aparência do recuo insano e do CamelCase, e o desejo de criar mais classes ... Como resultado, a estrutura do código se torna mais complicada. Onde um script de 300 linhas pode ser dispensado, vemos 10 a 20 arquivos.
- Overengineering. Muitas vezes, a segunda iteração de um projeto nunca é concluída ou é implementada de uma maneira muito complicada. Isso acontece se você deseja reescrever um código existente, mas com falhas, tornando-o ideal. Ao mesmo tempo, você esquece que o melhor é o inimigo do bem. Como resultado, o programador cai na armadilha padrão da reengenharia, quando a implementação se torna mais cara, pesada e pesada do que o necessário para resolver as tarefas. De fato: os sedãs familiares devem atingir velocidades de até 350 km / h, e os smartphones, cuja moda muda a cada ano, funcionam por 100 anos?
- Oneliner Outro problema urgente é a "linha única". É sobre programadores que estão tentando, com um zelo invejável, colocar tudo em uma linha, cinco andares de comerciais)). Devido à excessiva complexidade do código e às peculiaridades da implementação de expressões regulares da máquina no Python, esses scripts às vezes ficam "presos" à análise, portanto, é necessário usar um módulo especial para corrigir o problema.
- Copiar na leitura. Isso não é tanto um erro como um recurso da programação Python. Muitos estão familiarizados com a abordagem Copy-On-Write. A ideia dele é que, ao ler uma área de dados, uma cópia compartilhada seja usada e, quando uma alteração é feita, uma nova cópia é criada, ou seja, estamos falando sobre a otimização dos processos de desempenho. Se falamos sobre Python, em alguns casos, não apenas lemos a matriz dos elementos, mas nos referimos a todas as estruturas subjacentes que estão na memória, ou seja, "reescrevemos" a memória, alterando-a. Assim, em vez de Copiar na gravação, obtemos o Copiar na leitura quando parecemos estar lendo memória, mas, na realidade, temos que copiar essas informações do espaço pai para nós como um processo filho, o que a torna triste, pois a otimização não funciona e o consumo está crescendo.
- Não há garfo. Garfo - clonando um novo processo. O problema está relacionado às especificidades do trabalho com sistemas Unix e à não-obviedade de algumas estruturas de dados que estão ocultas na implementação. Um processo "bifurcado" é um processo que inicia no momento em que o thread capturou o log na fila para colocar algo nele. Ou seja, o novo processo que surgiu também quer escrever algo, mas para isso ele precisa pegar o log dessa fila, mas não pode fazer isso, pois o log já está capturado. Como resultado, temos um bloqueio. Tudo isso mais uma vez confirma que não vale a pena programar, sem conhecer os recursos da implementação do ambiente em que você trabalha e as ferramentas que você usa.
Ainda havia muitas coisas interessantes, então é melhor assistir ao vídeo, porque a recontagem ainda é curta.
Como sempre, estamos aguardando perguntas, comentários e sugestões aqui ou na
porta aberta .