Olá pessoal. Como você deve saber, eu costumava escrever e falar mais sobre armazenamento, Vertica, armazenamento de big data e outras coisas analíticas. Agora todos os outros bancos de dados, não apenas analíticos, mas também o OLTP (PostgreSQL) e o NOSQL (MongoDB, Redis, Tarantool) também se enquadram na minha área de responsabilidade.
Essa situação me permitiu olhar para uma organização que possui vários bancos de dados como uma organização que possui um banco de dados heterogêneo (heterogêneo) distribuído. Um único banco de dados heterogêneo distribuído, composto por um monte de PostgreSQL, Redis e Mong ... E, possivelmente, um ou dois bancos de dados Vertica.
O trabalho dessa única base distribuída gera várias tarefas interessantes. Primeiro de tudo, do ponto de vista dos negócios, é importante que tudo esteja normal com os dados se movendo ao longo dessa base. Eu não uso especificamente o termo integridade, consistência, porque o termo é complexo e, em diferentes nuances da consideração de um SGBD (teorema A C ID e C AP), ele tem um significado diferente.
A situação com uma base distribuída é agravada se uma empresa tentar mudar para uma arquitetura de microsserviço. Sob o argumento, falo sobre como garantir a integridade dos dados em uma arquitetura de microsserviço, sem transações distribuídas e conectividade rígida. (E, no final, explico por que escolhi esta ilustração para o artigo).

De acordo com Chris Richardson (um dos evangelistas mais famosos da arquitetura de microsserviços), essa arquitetura tem duas abordagens para trabalhar com bancos de dados: banco de dados compartilhado e banco de dados por serviço.

O banco de dados compartilhado é um bom primeiro passo, uma ótima solução para uma pequena empresa sem planos de crescimento ambiciosos. Além disso, esse padrão em si é um antipadrão do ponto de vista da arquitetura de microsserviço, como dois serviços que compartilham uma base comum não podem ser testados e dimensionados independentemente. I.e. em vez disso, esses serviços são um serviço que tende a se tornar um monólito.
O padrão de banco de dados por serviço pressupõe que cada serviço tenha seu próprio banco de dados. Um serviço pode acessar os dados de outro serviço apenas através da API (no sentido amplo), sem uma conexão direta com seu banco de dados.
O padrão de banco de dados por serviço permite que as equipes dos serviços correspondentes selecionem os bancos de dados como desejarem. Alguém é capaz no MongoDB, alguém acredita no PostgreSQL, alguém precisa do Redis (o risco de perda de dados ao desligar é aceitável para este serviço) e alguém geralmente armazena dados em arquivos CSV no disco (e por que, na verdade, e não?).
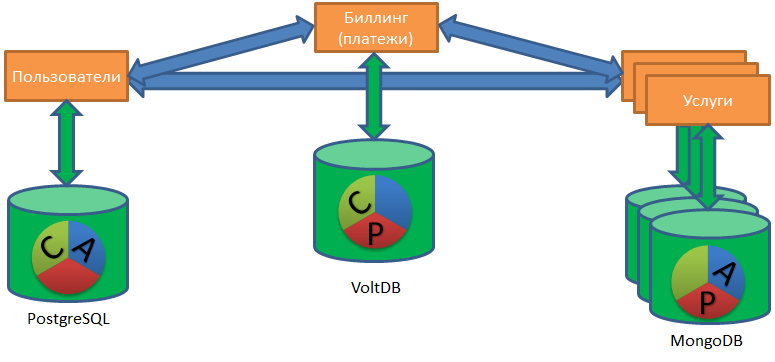
Trabalhar com esse "zoológico" de bancos de dados aumenta a tarefa de restaurar a ordem nos dados para um nível totalmente novo de complexidade.
Arquitetura ACID e microsserviço
Vejamos a tarefa de colocar as coisas em ordem através do prisma do conjunto clássico de requisitos de ACID baseado em DBMS: expandiremos a essência de cada letra da abreviação e ilustraremos as dificuldades dessa letra na arquitetura de microsserviços.
(A) CID - Atomicidade. Atomicidade - tudo ou nada.
De acordo com o requisito de atomicidade, é imperativo concluir todas as etapas (com possíveis repetições); se uma etapa importante falhar, cancele as etapas concluídas.
A ilustração acima demonstra o processo de teste de compra de um serviço VIP: o dinheiro é reservado no faturamento (1), um serviço de bônus é ativado para um usuário (2), o tipo de usuário é alterado para Pro (3), o dinheiro reservado no faturamento é debitado (4). Todas as quatro etapas devem ser concluídas ou não concluídas.
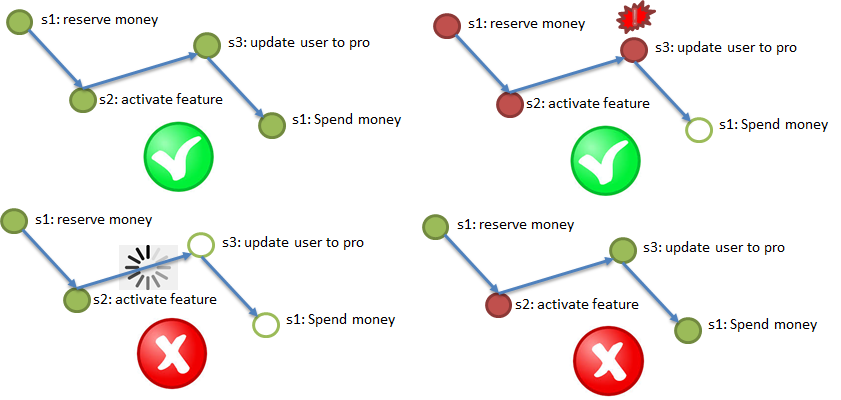
Nesse caso, você não pode travar no meio do processo; portanto, é preferível a assincronia, em casos extremos, o sincronismo com o tempo limite interno.
A (C) ID - Consistência. Consistência - cada etapa não deve contradizer as condições de contorno.
Exemplos clássicos de condições para, por exemplo, enviar dinheiro do cliente A no serviço 1 para o cliente B no serviço 2: como resultado desse envio, o dinheiro não deve ser menor (o dinheiro não deve ser perdido durante a transferência) ou mais (é inaceitável enviar o mesmo dinheiro para dois usuários ao mesmo tempo). Para cumprir esse requisito, é necessário codificar as condições em algum lugar e verificar os dados para as condições (idealmente, sem chamadas adicionais).

ACI (D) - Durabilidade. O requisito de durabilidade significa que os efeitos das operações não desaparecem.
Sob as condições de persistência do Polyglot, um serviço pode operar em um banco de dados que pode "perder" regularmente os dados registrados nele. Um truque semelhante pode ser obtido mesmo em bancos de dados sólidos como o PostgreSQL, se a replicação assíncrona estiver ativada lá. A ilustração mostra como as alterações registradas no Master, mas que não atingiram o Slave por meio de replicação assíncrona, podem ser destruídas com a queima do servidor Master. Para garantir os requisitos de durabilidade, é necessário ser capaz de diagnosticar e recuperar adequadamente essas perdas.
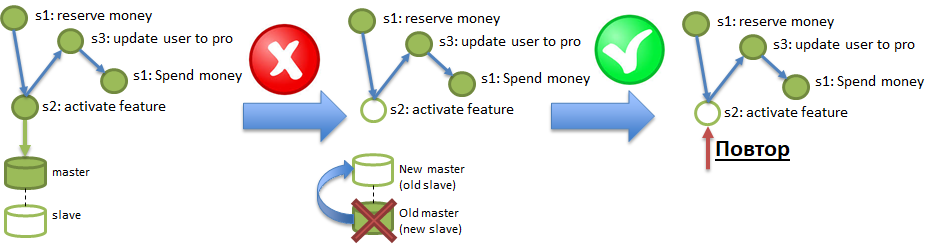
E onde eu estou, você pergunta?
E em lugar nenhum. O isolamento em um ambiente de vários serviços assíncronos independentes é um requisito técnico. Pesquisas modernas mostraram que processos de negócios reais podem ser implementados sem isolamento. O isolamento simplifica o pensamento, minimizando a simultaneidade (o desenvolvimento de computação paralela é mais difícil para um programador), mas a arquitetura de microsserviços é inerentemente paralela em massa, o isolamento em um ambiente como esse é redundante.
Existem muitas abordagens para alcançar a conformidade com os requisitos acima. O algoritmo mais conhecido de transações distribuídas fornecido pelo chamado commit de duas fases (2PC). Infelizmente, a implementação de confirmações em duas fases requer a reescrita de todos os serviços envolvidos. E o mais sério: esse algoritmo não é muito produtivo. As ilustrações acima, de estudos recentes, mostram que esse algoritmo mostra um certo desempenho em uma base distribuída de dois servidores, mas com um aumento no número de servidores, a produtividade não cresce linearmente ... Ou melhor, não cresce.

Uma das principais vantagens da arquitetura de microsserviço é a capacidade de aumentar linearmente o desempenho simplesmente adicionando mais e mais servidores. Acontece que, se usarmos um commit em duas fases para garantir a integridade distribuída, esse processo se tornará um gargalo, limitador do crescimento da produtividade, apesar do aumento no número de servidores.
Como você pode garantir a integridade distribuída (requisitos do ACiD) sem confirmações de duas fases, com a capacidade de dimensionar linearmente o desempenho?
Pesquisas modernas (por exemplo, Uma avaliação do controle de concorrência distribuída. VLDB 2017 ) argumentam que a chamada "abordagem otimista" pode ajudar. A diferença entre o commit em duas fases e a "abordagem otimista" generalizada pode ser ilustrada pela diferença entre a antiga loja soviética (com um balcão) e um supermercado moderno como Auchan. Em uma loja com balcão, todo cliente é considerado suspeito e é atendido com o máximo controle. Daí as linhas e os conflitos. E no supermercado, o comprador é considerado honesto por padrão, eles dão a ele a oportunidade de se aproximar das prateleiras e encher os carrinhos. Obviamente, existem ferramentas de monitoramento para capturar bandidos (câmeras, segurança), mas a maioria dos compradores nunca precisa lidar com eles.
Portanto, o supermercado pode ser dimensionado, expandido, simplesmente colocando mais caixas de dinheiro. É semelhante à arquitetura de microsserviço: se a integridade distribuída é garantida por uma "abordagem otimista", quando apenas processos onde algo deu errado são carregados adicionalmente com verificações. E processos normais passam sem verificações adicionais.
É importante. A "abordagem otimista" inclui vários algoritmos. Eu gostaria de falar sobre a saga - o algoritmo para manter a integridade distribuída, recomendado por Chris Richardson.
Sagas - elementos do algoritmo
O algoritmo sag tem duas opções. Portanto, no começo, eu gostaria de descrever universalmente os elementos necessários do algoritmo para que a descrição seja adequada para ambas as opções.
Elemento 1. Canal persistente e confiável de entrega de eventos entre serviços, garantindo "pelo menos uma vez a entrega". I.e. se a etapa 2 do processo foi concluída com êxito, uma notificação (evento) sobre isso deve atingir a etapa 3 pelo menos uma vez; entregas repetidas são aceitáveis, mas nada deve ser perdido. “Persistente” significa que o canal deve armazenar notificações por algum tempo (2-3 dias, uma semana) para que um serviço que tenha perdido as alterações mais recentes devido à perda do banco de dados (veja o exemplo Durabilidade, na ilustração esta é a etapa 2), possa restaurar essas alterações reproduzindo eventos do canal.
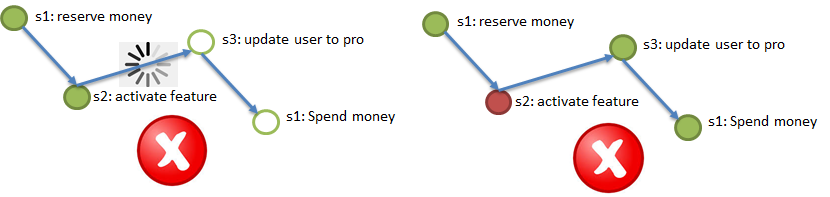
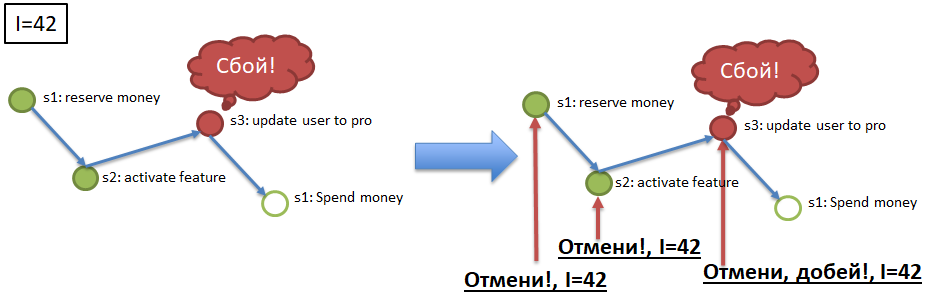
Elemento 2. Idempotência de serviço chama através do uso de uma chave de idempotência exclusiva. Imagine que eu (o usuário) inicio o processo de compra de um pacote VIP (veja o exemplo para Atomicity). No início do processo, recebi uma chave exclusiva, a chave de idempotência, por exemplo, 42. Em seguida, a chamada para cada uma das etapas (1 → 2 → 3 → 4) deve ser executada com a tecla de idempotência indicada. No parágrafo acima, é mencionada a possibilidade da chegada repetida da mesma mensagem ao serviço (na etapa). O serviço (etapa) deve poder ignorar automaticamente a chegada repetida do evento processado, verificando a repetição pela tecla idempotency. Ou seja, se todos os serviços (etapas do processo) são idempotentes, para atender aos requisitos de Atomicidade e Durabilidade, basta redirecionar para as etapas correspondentes aos eventos dos canais. As etapas que ignoraram os eventos as executam e as etapas que já concluíram os eventos as ignoram devido à idempotência.

Elemento 3. Cancelamento de chamadas de serviço (etapas) por chave de idempotência.
Para garantir Atomicity (veja o exemplo), se o processo com a chave de idempotência 42, por exemplo, parou / caiu na etapa 3, é necessário cancelar a execução bem-sucedida das etapas 1 e 2 da chave 42. Para isso, cada etapa obrigatória do processo deve ter uma etapa "compensadora" , Um método de API que cancela a execução da etapa necessária para a chave de idempotência especificada (42). A implementação de chamadas compensatórias é um elemento difícil, mas necessário, no refinamento de serviços como parte da implementação do algoritmo sag.
Os três elementos listados acima são relevantes para ambas as versões da implementação do "sag": orquestrado e coreográfico.
Sagas orquestradas
O algoritmo mais simples e mais óbvio para sagas orquestradas é mais fácil de entender e implementar. Em um excelente artigo, kevteev descreveu o algoritmo e o processo de implementação do mecanismo de sagas orquestradas em Avito. O algoritmo deles assume a existência de um serviço de controle, "orquestrando" as chamadas de serviço na estrutura dos processos de negócios atendidos. O mesmo serviço de monitoramento pode ter seu próprio banco de dados (por exemplo, PostgreSQL), que atua como um canal confiável de entrega de eventos persistentes (elemento 1).
Sagas coreográficas
A saga coreográfica é mais complicada. Aqui, um barramento de dados que implementa os seguintes requisitos deve atuar como um canal persistente confiável: publicação de disparar e esquecer, entrega de eventos de publicação e assinatura, pelo menos uma vez. I.e. cada etapa de cada processo deve receber um comando para operar no barramento e enviar a mensagem sobre a conclusão bem-sucedida, sobre o início da próxima etapa, para que ele também a leia no barramento e continue o processo. Além disso, para cada mensagem, pode haver vários assinantes.
A saga coreográfica também deve ter um serviço de controle, um serviço de sagas, mas muito mais "leve". O serviço deve conhecer os processos de negócios registrados no sistema, sobre a composição das etapas incluídas em cada processo. Ele também deve ouvir o barramento, monitorar a execução de cada processo (cada chave de idempotência), e somente se algo der errado, jogue “repetições” de etapas específicas ou jogue “cancela”, “compensações” pelas etapas executadas.
Nuances
Uma das nuances mais importantes das sagas que as distinguem das transações clássicas é um desvio da linearidade, sequência e obrigação de cada etapa. Uma saga não é necessariamente uma cadeia linear de eventos, pode ser um gráfico direcionado: um novo evento de registro de usuário pode gerar várias etapas em paralelo (enviar SMS, registrar um login, gerar uma senha, enviar um email), algumas das quais podem ser opcionais. Numa primeira aproximação, parece que em uma saga "ramificada" com etapas opcionais é difícil determinar a conclusão da saga (processo), mas, de fato, tudo é simples: a saga (processo) é concluída quando todas as etapas necessárias são concluídas, em qualquer ordem.

A segunda nuance, mais típica para sagas coreográficas, mas também possível para orquestradas, é escolher uma abordagem para registrar processos de negócios, tipos de sagas no serviço sagas. O exemplo Atomicity descreve um processo de quatro etapas necessárias consecutivas.
Quem registrou esse processo, indicou todas as etapas, colocou as dependências e as etapas obrigatórias? A resposta óbvia, mas antiquada, é que o registro do processo deve ser feito centralmente no serviço sag. Mas essa resposta não é muito consistente com a arquitetura de microsserviço. Na arquitetura de microsserviço, é mais promissor, mais produtivo e mais rápido registrar processos de baixo para cima. I.e. não para anotar todas as nuances do processo no serviço sag, mas para permitir que serviços individuais "se ajustem" aos processos existentes por conta própria, indicando sua natureza obrigatória / opcional e predecessores obrigatórios.
I.e. o processo de registro de um usuário no serviço sag pode consistir inicialmente em três etapas e, durante o desenvolvimento do sistema, mais sete etapas serão ajustadas e uma etapa será gravada, e haverá nove delas. É difícil testar esse esquema "anarquista" e "descentralizado", para implementar um processo estrito e coordenado, mas é muito mais conveniente para as equipes Agile, para a evolução contínua multidirecional do produto.
Na verdade aqui. Com uma apresentação séria, acho que vale a pena terminar, caso contrário, o artigo acabou sendo muito grande.
Aqui está um link para a apresentação deste material, fiz um relatório sobre este tópico no Highload Siberia 2018.
UPD - e vídeo da conferência:
Epílogo
No final, eu gostaria de tentar explicar tudo isso em uma linguagem mais figurativa.
Afinal, o que é uma saga desde o início? Este enredo, esta aventura da Idade Média ... Ou do Game of Thrones. Um evento acontece (uma batalha, um casamento, alguém morre), a notícia disso voa ao redor do mundo através de mensageiros, através de pombos-correio, através de comerciantes. Quando as notícias chegam aos interessados (em uma semana, em um mês, em um ano), eles reagem: eles enviam exércitos, declaram guerra, executam alguém e novas mensagens voam.
Não existe um órgão regulador que monitore a sequência de ações. Nenhuma transação, nenhuma reversão, no sentido de desfazer a ação, como se nunca tivesse acontecido. Tudo de uma maneira adulta, toda ação acontece para sempre. Pode ser compensado, mas é precisamente ação (assassinato) e compensação (pagamento pela cabeça, vira), e não a abolição da morte.
Os eventos demoram muito tempo, vêm de diferentes fontes, as ações ocorrem em paralelo e não estritamente em sequência. E, muitas vezes, novos participantes aparecem subitamente na trama, que decidem participar (os dragões chegam;)) ... e alguns dos antigos participantes morrem repentinamente.
Essas coisas. Parece uma bagunça e caos, mas tudo funciona, a coordenação interna do mundo não é violada, o enredo está se desenvolvendo e é consistente ... Embora às vezes imprevisível.