
Cada um de nós percebe os textos à sua maneira, sejam notícias na Internet, poesia ou romances clássicos. O mesmo se aplica aos algoritmos e métodos de aprendizado de máquina, que, via de regra, percebem textos em forma matemática, na forma de um espaço vetorial multidimensional.
O artigo é dedicado à visualização usando t-SNE calculado pelas representações vetoriais multidimensionais de palavras do Word2Vec. A visualização ajudará a entender melhor o princípio do Word2Vec e como interpretar o relacionamento entre os vetores de palavras antes do uso posterior em redes neurais e outros algoritmos de aprendizado de máquina. O artigo foca na visualização, pesquisas adicionais e análise de dados não são consideradas. Como fonte de dados, usamos artigos do Google Notícias e obras clássicas de L.N. Tolstoi. Escreveremos o código em Python no Jupyter Notebook.
Incorporação estocástica de vizinhos distribuídos em T
O T-SNE é um algoritmo de aprendizado de máquina para visualização de dados com base no método de redução dimensional não linear, descrito em detalhes no artigo original [1] e em
Habré . O princípio básico da operação do t-SNE é reduzir as distâncias entre pares entre os pontos, mantendo sua posição relativa. Em outras palavras, o algoritmo mapeia dados multidimensionais para um espaço de menor dimensão, mantendo a estrutura da vizinhança dos pontos.
Representações vetoriais de palavras e Word2Vec
Primeiro de tudo, precisamos apresentar as palavras em forma de vetor. Para esta tarefa, escolhi o utilitário de semântica de distribuição do Word2Vec, projetado para exibir o significado semântico das palavras no espaço vetorial. O Word2Vec localiza relacionamentos entre palavras, assumindo que palavras semanticamente relacionadas são encontradas em contextos semelhantes. Você pode ler mais sobre o Word2Vec no artigo original [2], bem como
aqui e
aqui .
Como entrada, utilizamos artigos do Google Notícias e romances de L.N. Tolstoi. No primeiro caso, usaremos os vetores pré-treinados no conjunto de dados do Google Notícias (cerca de 100 bilhões de palavras) publicado pelo Google
na página do projeto .
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Além de vetores pré-treinados usando a biblioteca Gensim [3], treinaremos outro modelo nos textos de L.N. Tolstoi. Como o Word2Vec aceita uma matriz de frases como entrada, usamos o modelo pré-treinado do Punkt Sentença Tokenizer do pacote NLTK para dividir automaticamente o texto em frases. O modelo para o idioma russo pode ser baixado
aqui .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Em seguida, usando a biblioteca Gensim, treinaremos o modelo Word2Vec com os seguintes parâmetros:
- tamanho = 200 - dimensão do espaço de atributo;
- window = 5 - o número de palavras do contexto que o algoritmo analisa;
- min_count = 5 - a palavra deve ocorrer pelo menos cinco vezes para que o modelo a leve em consideração.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualização de representações vetoriais de palavras usando t-SNE
O T-SNE é extremamente útil para visualizar semelhanças entre objetos em um espaço multidimensional. À medida que a quantidade de dados aumenta, torna-se cada vez mais difícil criar um gráfico visual; portanto, na prática, as palavras relacionadas são combinadas em grupos para visualização adicional. Tomemos, por exemplo, algumas palavras de um dicionário do modelo Word2Vec previamente treinado no Google Notícias.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
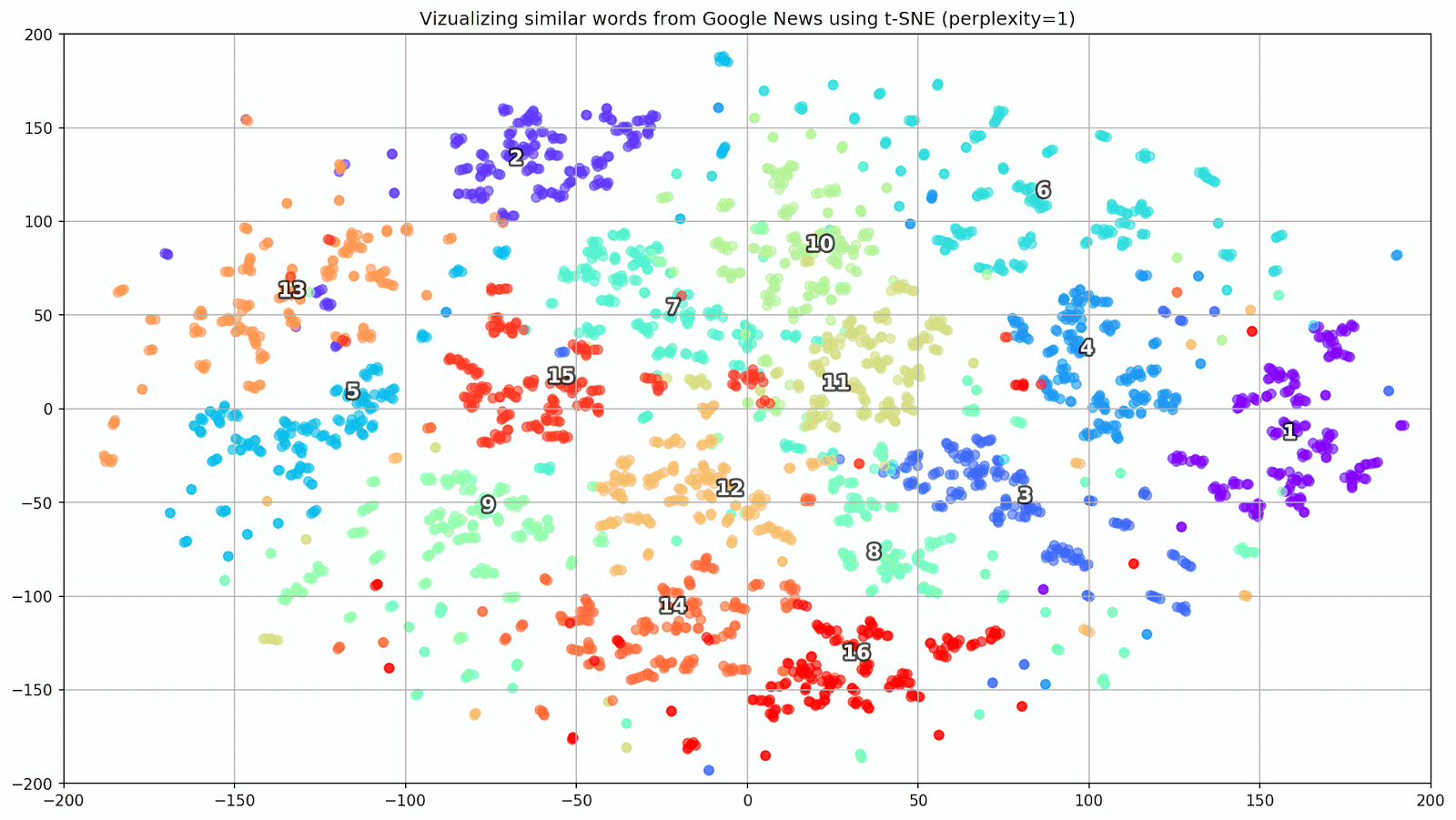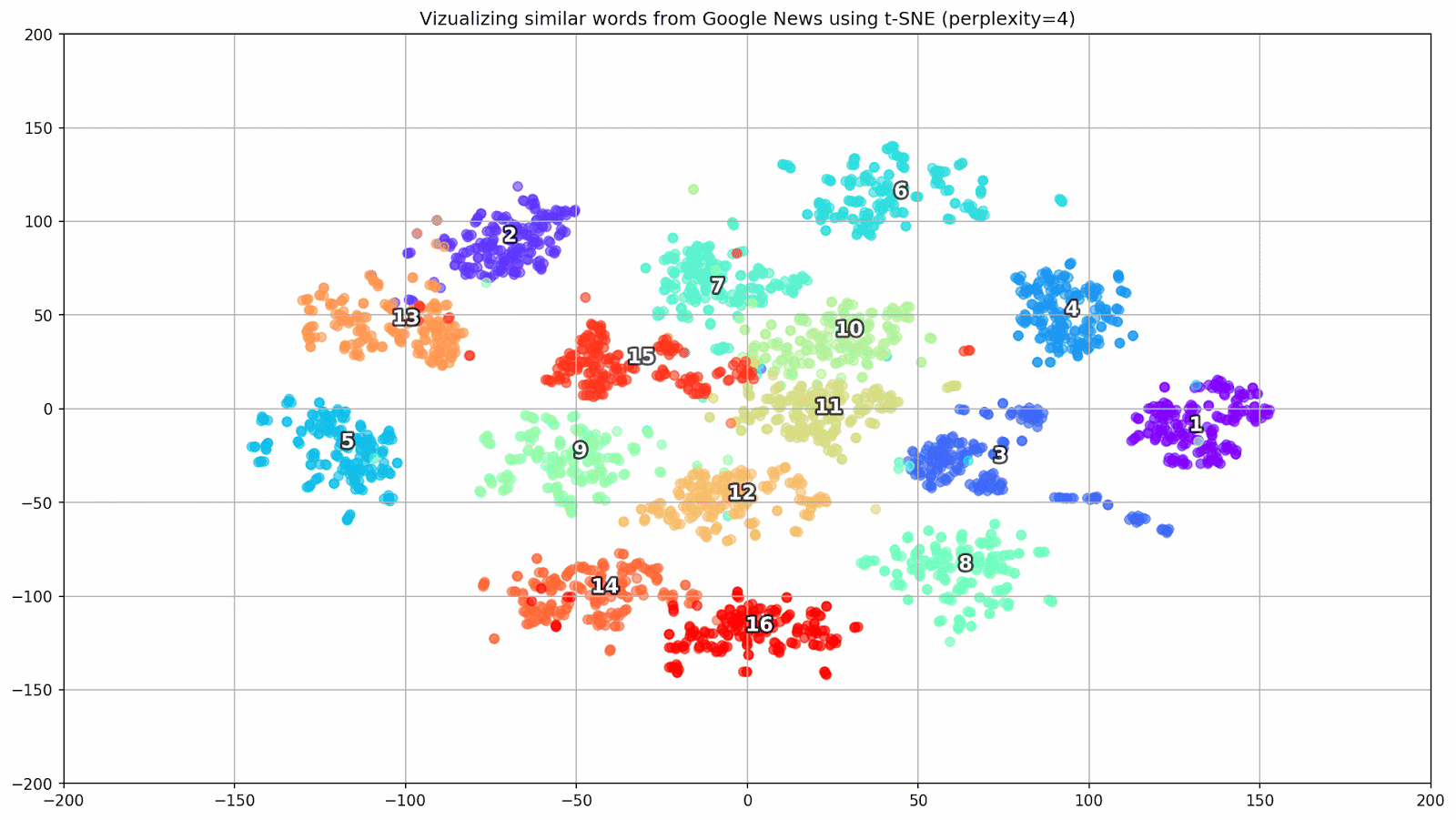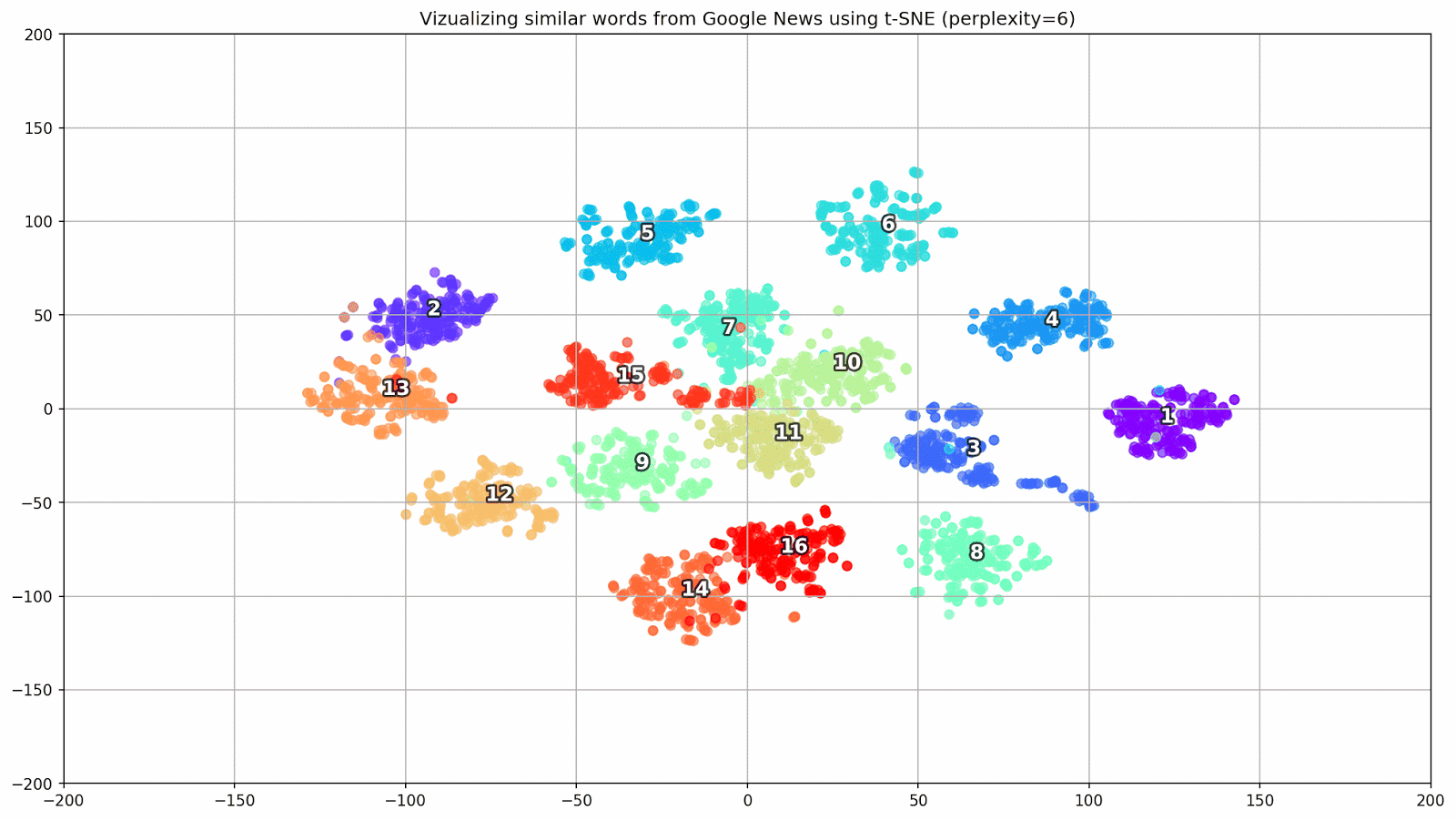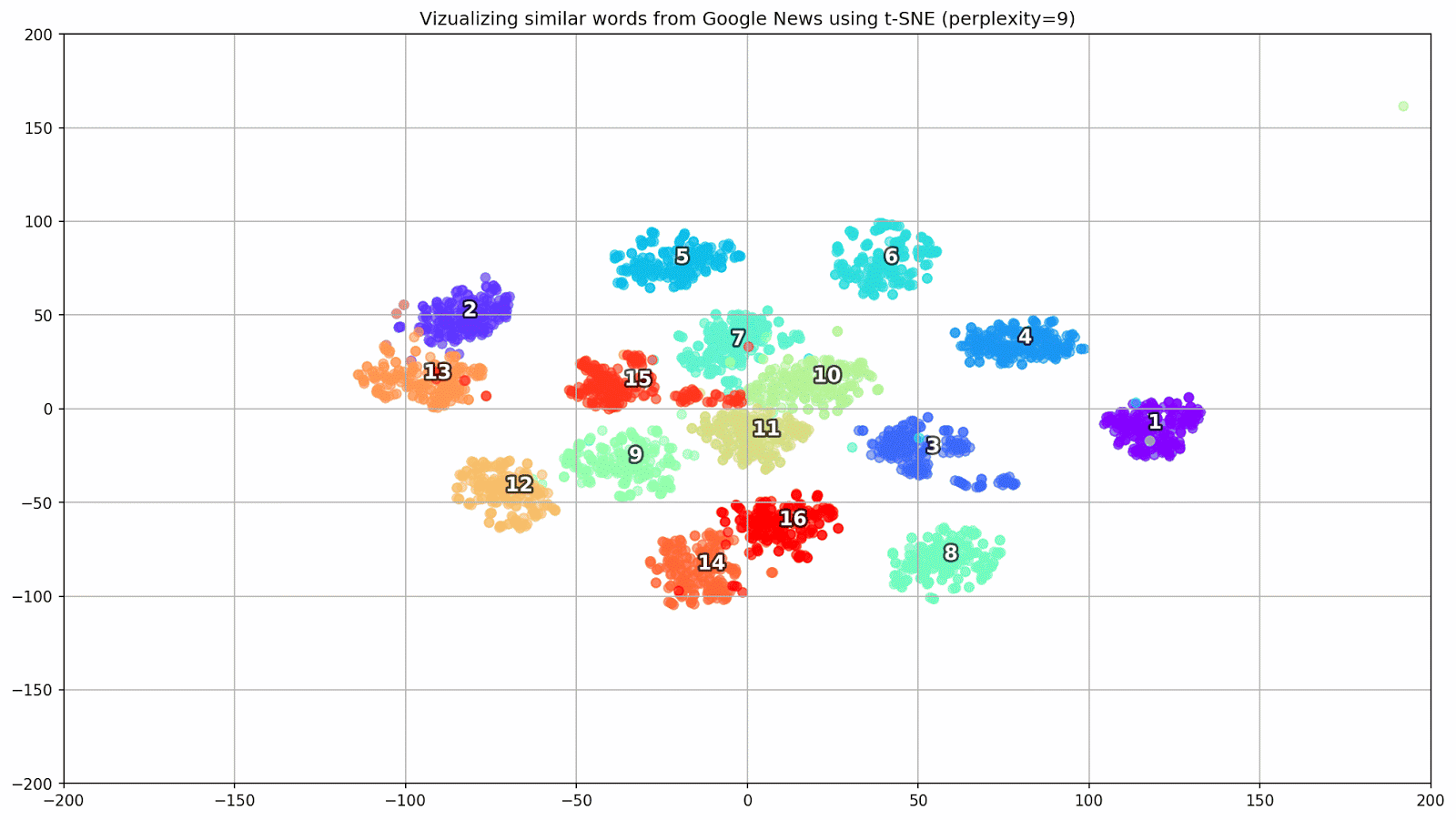 Figura 1. Grupos de palavras semelhantes do Google Notícias com diferentes valores de preplexidade.
Figura 1. Grupos de palavras semelhantes do Google Notícias com diferentes valores de preplexidade.Em seguida, passamos ao fragmento mais notável do artigo, a configuração t-SNE. Aqui, antes de tudo, você deve prestar atenção aos seguintes hiperparâmetros:
- n_components - o número de componentes, isto é, a dimensão do espaço de valor;
- perplexidade - perplexidade, cujo valor em t-SNE pode ser igualado ao número efetivo de vizinhos. Está relacionado ao número de vizinhos mais próximos, que é usado em outros modelos de aprendizado com base em variedades (veja a figura acima). Seu valor é recomendado [1] para ser definido na faixa de 5-50;
- init - tipo de inicialização inicial de vetores.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Abaixo está um script para criar um gráfico bidimensional usando o Matplotlib, uma das bibliotecas mais populares para visualização de dados no Python.
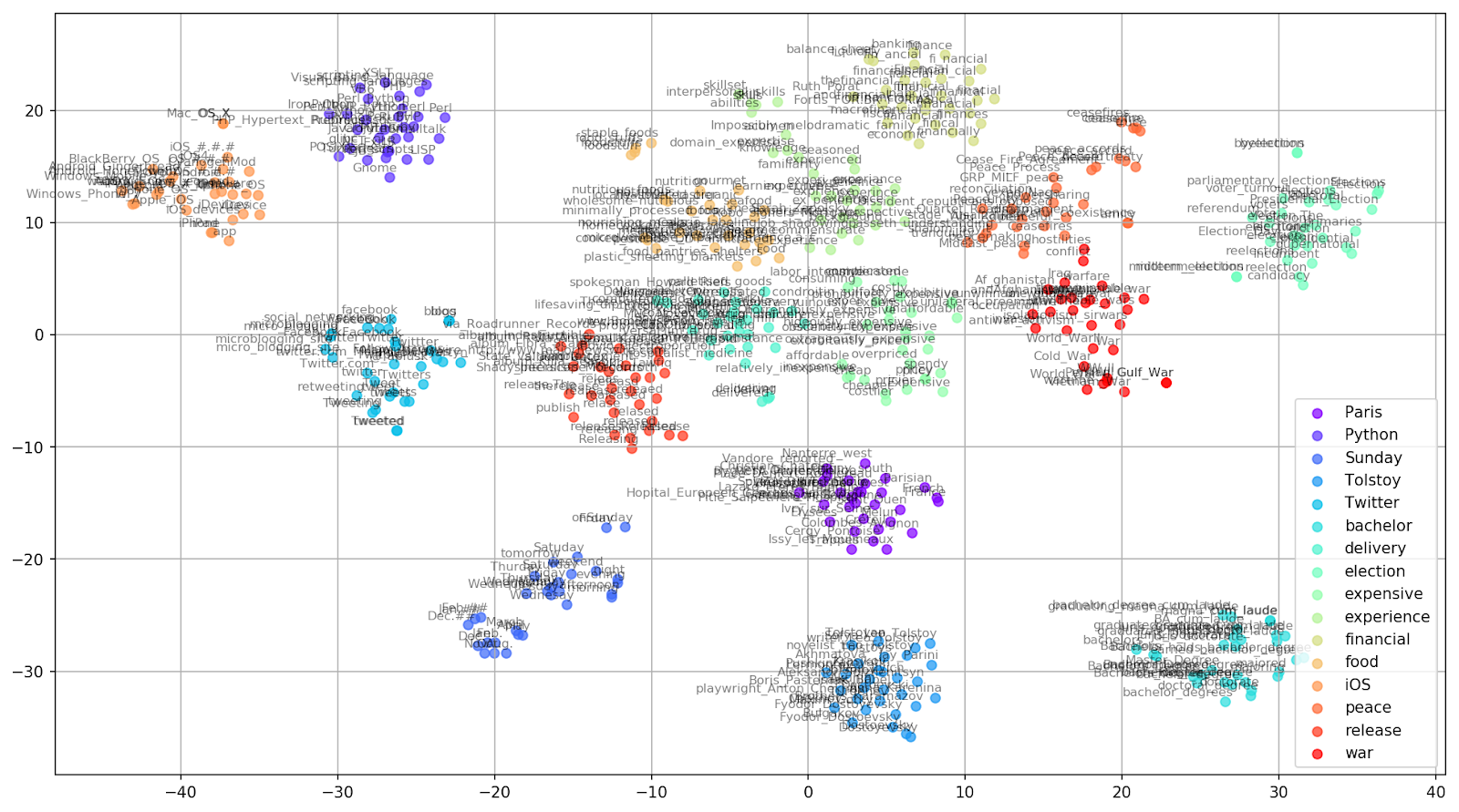 Figura 2. Grupos de palavras semelhantes do Google Notícias (preplexity = 15).
Figura 2. Grupos de palavras semelhantes do Google Notícias (preplexity = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Às vezes é necessário criar não grupos separados de palavras, mas todo o dicionário. Para esse fim, vamos analisar Anna Karenina, a grande história de paixão, traição, tragédia e expiação.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
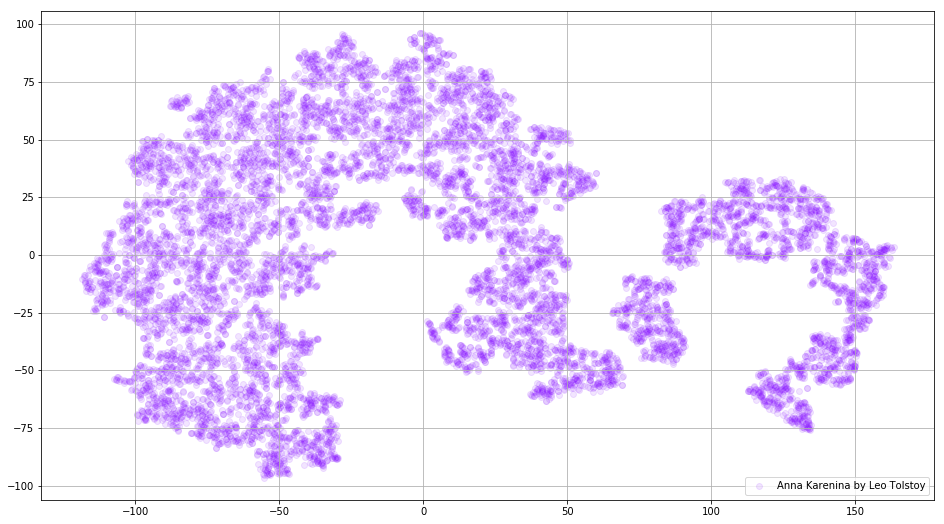
 Figura 3. Visualização do dicionário do modelo Word2Vec, treinado no romance "Anna Karenina".
Figura 3. Visualização do dicionário do modelo Word2Vec, treinado no romance "Anna Karenina".A imagem pode se tornar ainda mais informativa se usarmos o espaço tridimensional. Dê uma olhada em Guerra e Paz, um dos principais romances da literatura mundial.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
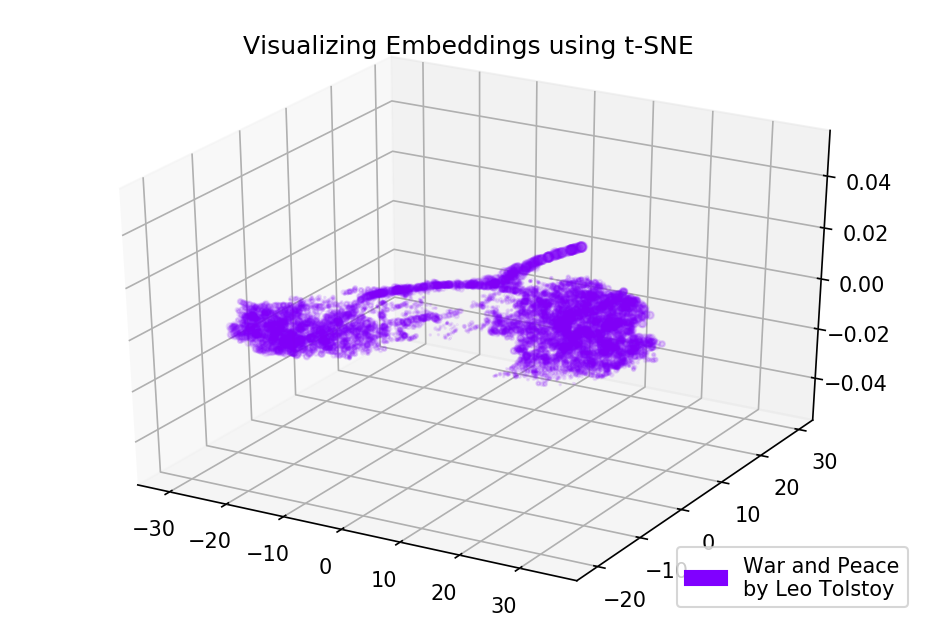 Figura 4. Visualização do dicionário do modelo Word2Vec, treinado no romance "Guerra e Paz".
Figura 4. Visualização do dicionário do modelo Word2Vec, treinado no romance "Guerra e Paz".Código fonte
O código está disponível no
GitHub . Lá você pode encontrar o código para renderizar animações.
Fontes
- Maaten L., Hinton G. Visualizando dados usando t-SNE // Jornal de pesquisa de aprendizado de máquina. - 2008. - T. 9. - S. 2579-2605.
- Representações distribuídas de palavras e frases e sua composicionalidade // Avanços nos sistemas de processamento de informações neurais . - 2013 .-- S. 3111-3119.
- Rehurek R., Sojka P. Framework de software para modelagem de tópicos com grandes corpora // Em Anais do LREC 2010 Workshop on New Challenges for NLP Frameworks. - 2010.