Continuo fazendo o upload de relatórios com o Pixonic DevGAMM Talks, nossa reunião de setembro para desenvolvedores de sistemas altamente carregados. Eles compartilharam muitas experiências e casos, e hoje eu publico uma transcrição do discurso do desenvolvedor de back-end do Sabre Interactive Roman Rogozin. Ele falou sobre a prática de aplicar o modelo de ator usando o exemplo de gerenciamento de atores e seus estados (outros relatórios podem ser encontrados no final do artigo, a lista é complementada).
Nossa equipe está trabalhando em um back-end para o jogo Quake Champions, e falarei sobre qual é o modelo de ator e como ele é usado no projeto.
Um pouco sobre a pilha de tecnologia. Escrevemos código em C #, respectivamente, todas as tecnologias estão ligadas a ele. Quero observar que haverá algumas coisas específicas que mostrarei no exemplo dessa linguagem, mas os princípios gerais permanecerão inalterados.

No momento, hospedamos nossos serviços no Azure. Existem algumas primitivas muito interessantes que não queremos abandonar, como Table Storage e Cosmos DB (mas tentamos não ficar muito rígidas com elas por causa do projeto de plataforma cruzada).
Agora eu gostaria de contar um pouco sobre o que é um modelo de ator. E, para começar, apareceu como princípio há mais de 40 anos.
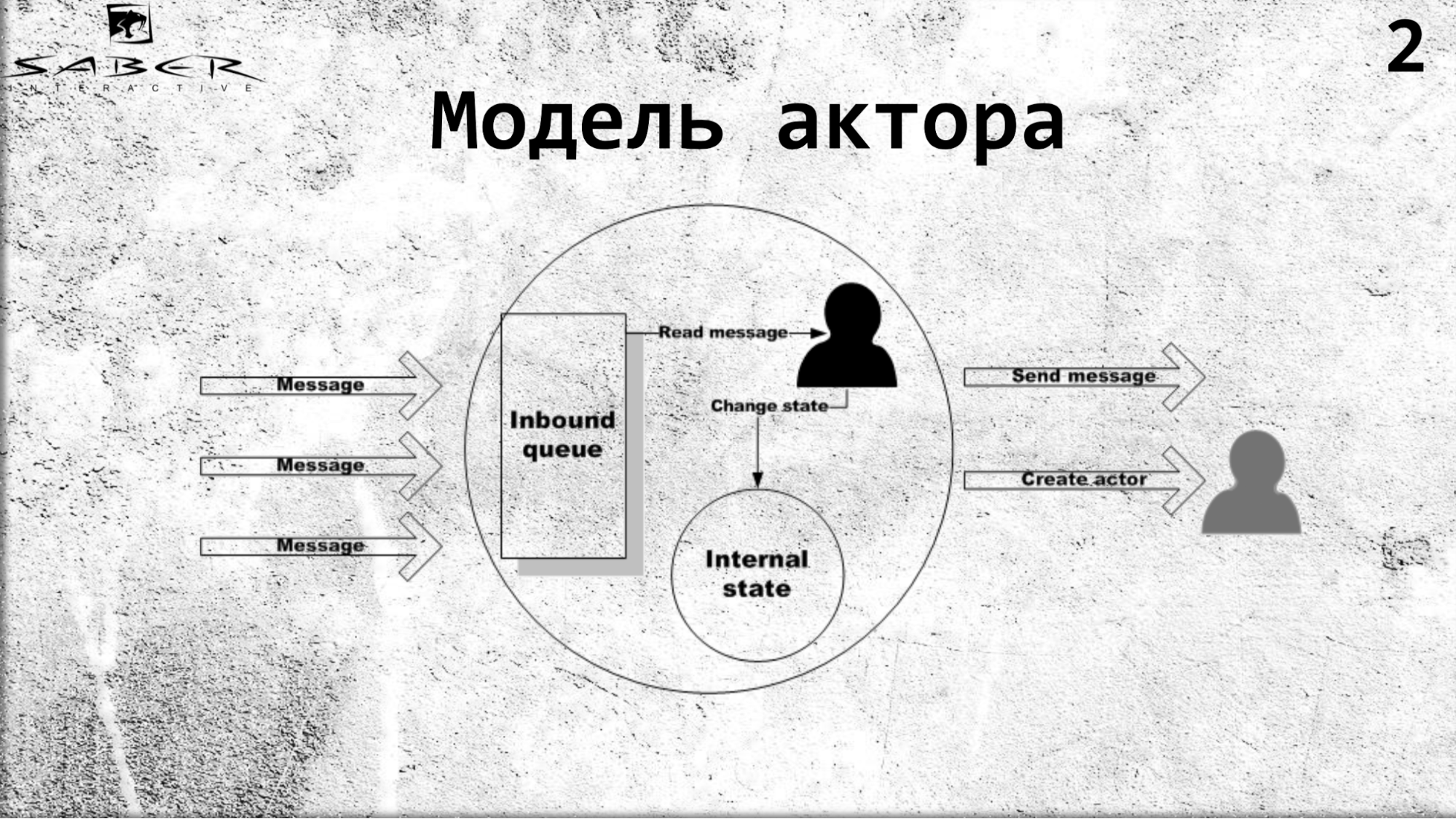
Um ator é um modelo de computação paralela que afirma que existe um certo objeto isolado que possui seu próprio estado interno e acesso exclusivo para alterar esse estado. Um ator pode ler mensagens e, além disso, executar seqüencialmente algum tipo de lógica comercial, se ele quiser alterar seu estado interno e enviar mensagens para serviços externos, incluindo outros atores. E ele sabe como criar outros atores.
Os atores se comunicam de forma assíncrona, o que permite criar sistemas em nuvem distribuídos altamente carregados. Nesse sentido, o modelo de ator tem sido amplamente utilizado recentemente.
Resumindo, vamos imaginar que temos uma nuvem em que existe algum tipo de cluster de servidores e nossos atores estão girando nesse cluster.
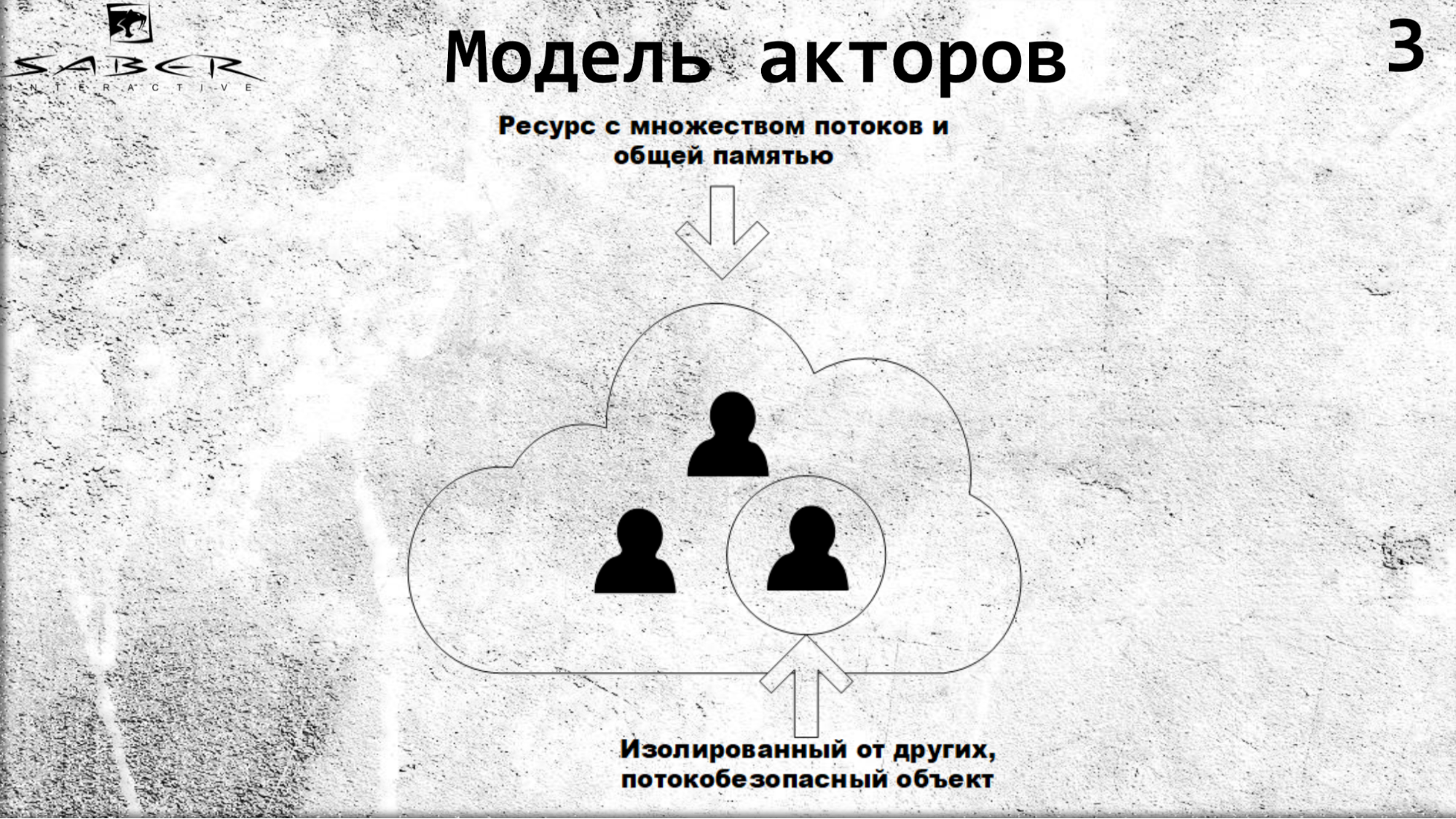
Os atores são isolados um do outro, se comunicam através de chamadas assíncronas e, dentro de si, os atores são seguros para threads.
Como pode parecer. Suponha que tenhamos vários usuários (não muito grande) e, em algum momento, entendemos que há um afluxo de jogadores e precisamos urgentemente fazer um upscale.
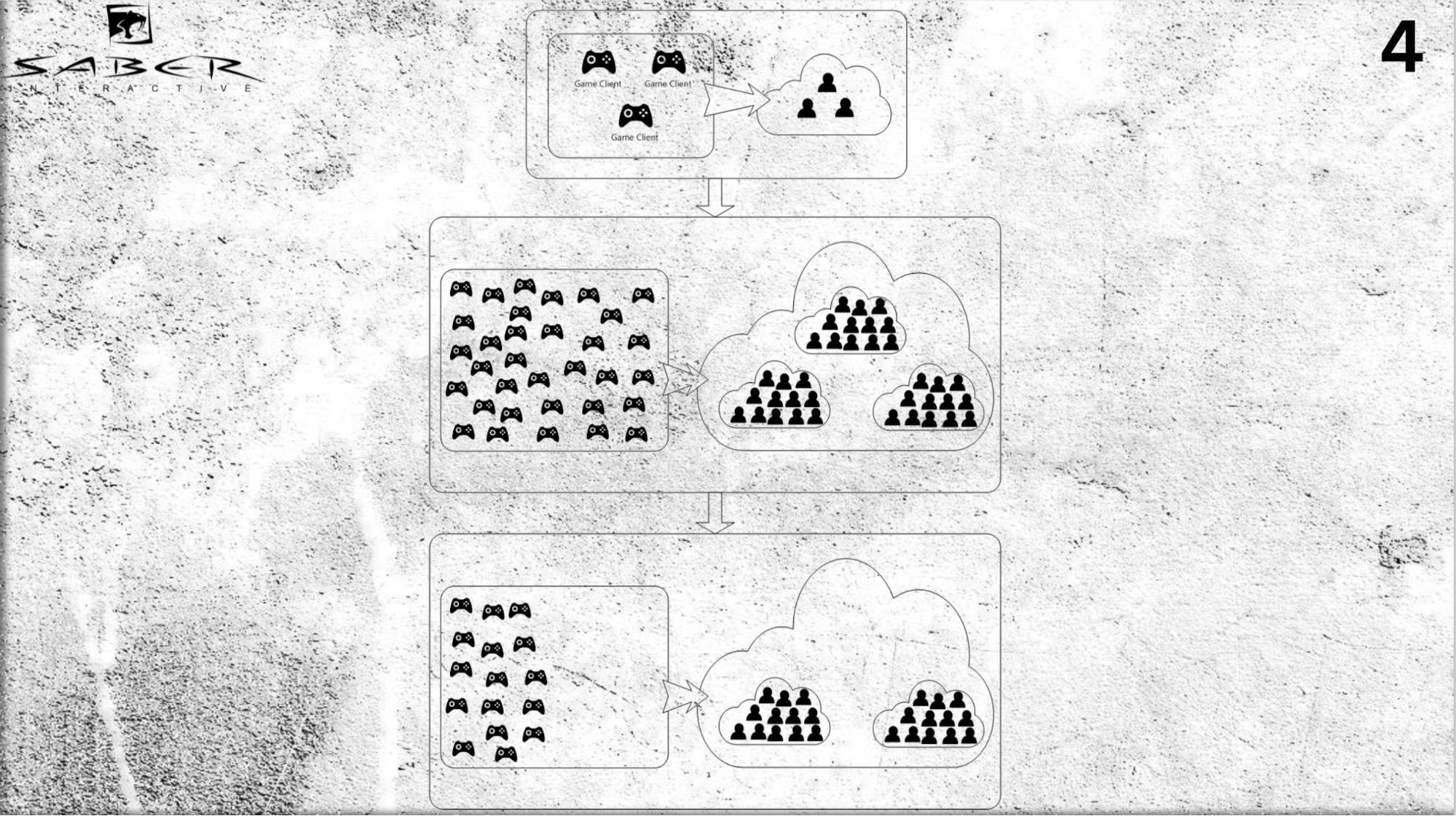
Podemos adicionar servidores à nossa nuvem e, usando o modelo de ator, empurrar usuários individuais - atribuir cada ator individual e alocar espaço para memória e tempo de processador para esse ator na nuvem.
Assim, o ator, em primeiro lugar, desempenha o papel de cache e, em segundo lugar, é um "cache inteligente", que pode processar algumas mensagens e executar a lógica de negócios. Novamente, se você precisar fazer um downscale (por exemplo, os jogadores foram embora) - também não há problema em remover esses atores do sistema.
Nós, no back-end, não usamos o modelo clássico de ator, mas com base na estrutura de Orleans. Qual é a diferença - tentarei lhe dizer agora.

Primeiro, Orleans introduz o conceito de ator virtual ou, como também é chamado, grão. Diferente do modelo clássico de ator, em que um serviço é responsável por criar esse ator e colocá-lo em alguns servidores, Orleans assume o trabalho. I.e. se um determinado serviço do usuário solicitar uma determinada classificação, o Orleans entenderá qual dos servidores está agora menos carregado, colocará o ator lá e retornará o resultado ao serviço do usuário.
Um exemplo Para grãos, é importante conhecer apenas o tipo de ator, por exemplo, estados do usuário e ID. Suponha que o usuário ID 777 obtenha o grão desse usuário e não pense em como armazená-lo, não controlamos o ciclo de vida do grão. Orleans, no entanto, por si só armazena os caminhos de todos os atores de uma maneira muito esperta. Se não houver ator, ele os cria; se o ator estiver vivo, ele retornará e, para os serviços do usuário, tudo parecerá para que todos os atores estejam sempre vivos.
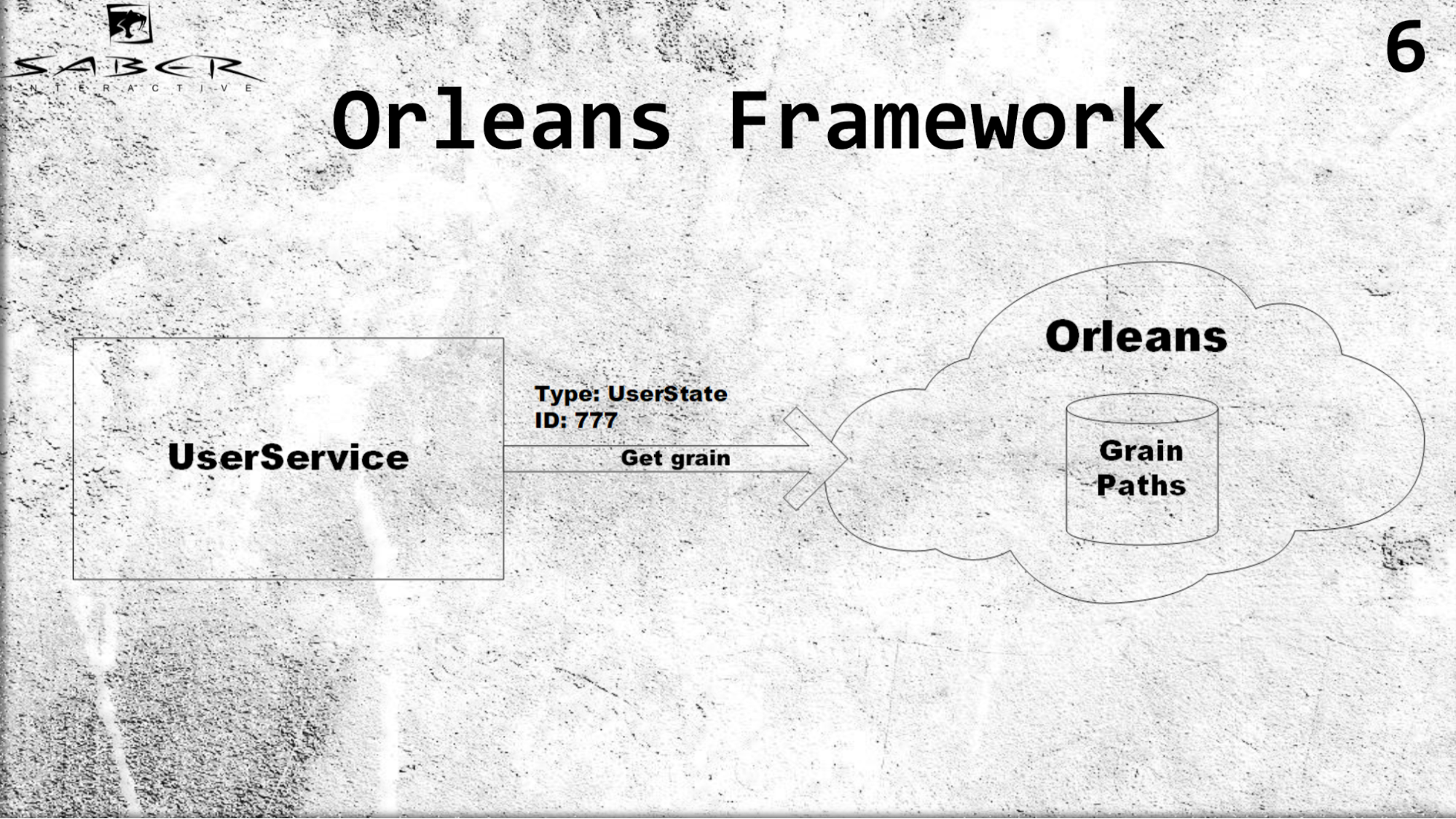
Que benefícios isso nos dá? Primeiro, o balanceamento de carga transparente devido ao fato de o programador não precisar gerenciar a localização do próprio ator. Ele simplesmente diz Orleans, que é implantado em vários servidores: me dê um ator dos seus servidores.
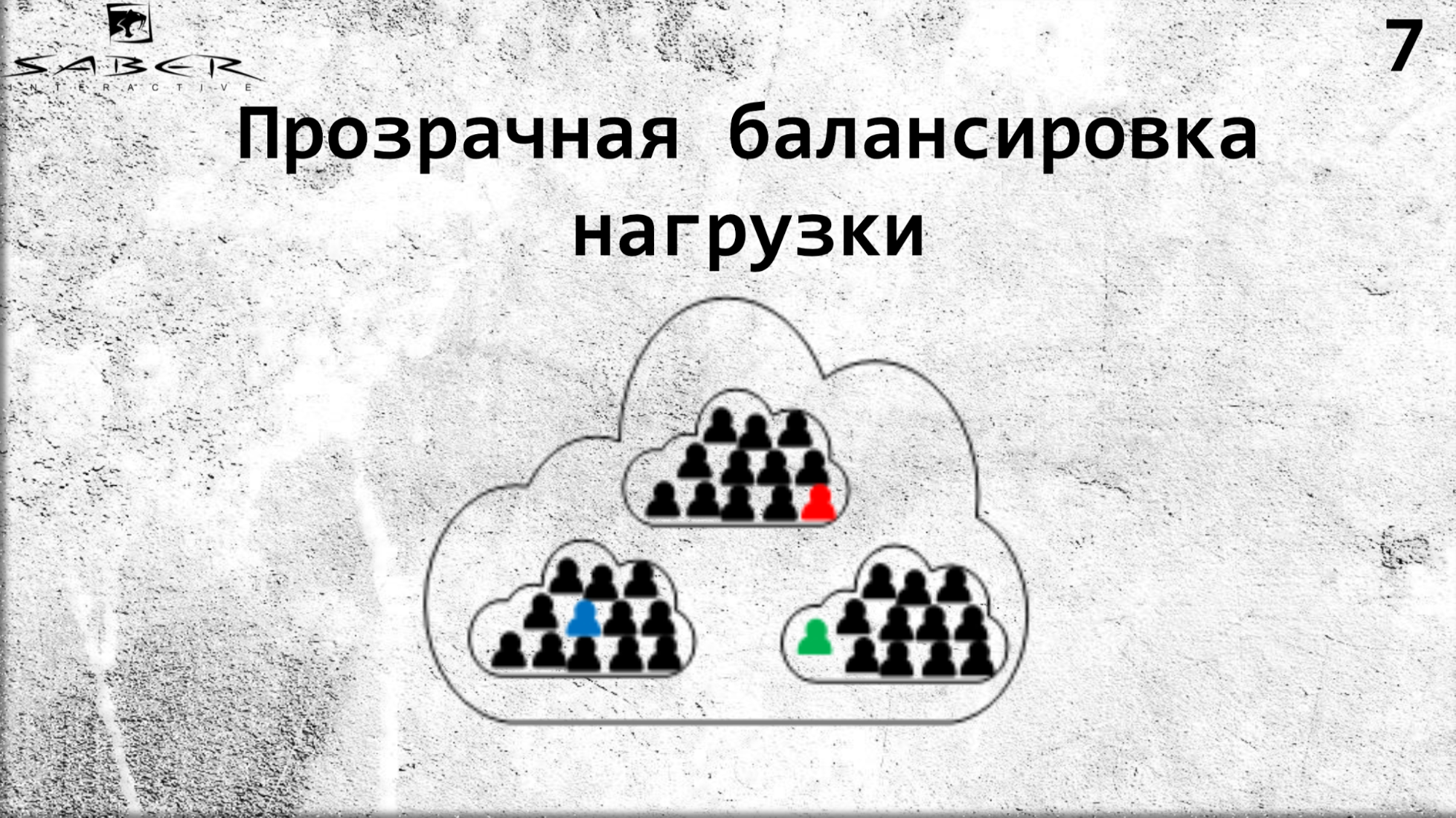
Se desejar, você pode reduzir a escala se a carga no processador e na memória for pequena. Mais uma vez, você pode fazer o upscale na direção oposta. Mas o serviço não sabe nada sobre isso, ele pede o grão, e Orleans lhe dá esse grão. Assim, Orleans assume cuidados de infraestrutura para o ciclo de vida dos grãos.
Em segundo lugar, Orleans lida com falhas no servidor.

Isso significa que, no modelo clássico, o programador é responsável por lidar com esse caso por conta própria (eles colocaram o ator em algum servidor e esse servidor travou, e nós mesmos devemos criar esse ator em um dos servidores ativos), o que adiciona mais recursos mecânicos. ou trabalho de rede complexo para um programador, em Orleans parece transparente. Solicitamos um grão, o Orleans vê que ele não está disponível, o coleta (o coloca em alguns servidores ativos) e o devolve ao serviço.
Para deixar um pouco mais claro, vamos dar uma olhada em um pequeno exemplo de como um usuário lê um pouco de seu estado.
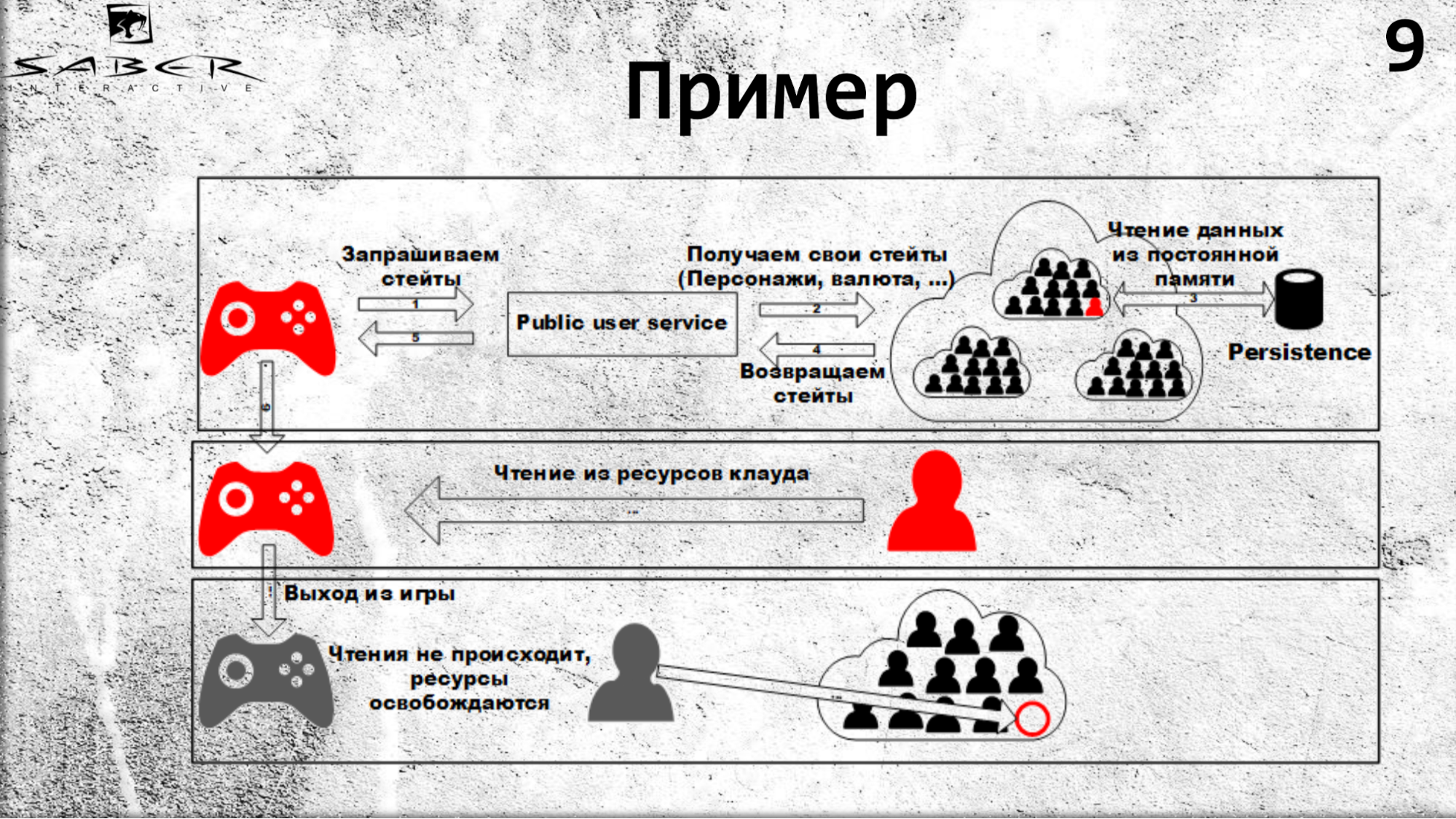
Um estado pode ser sua condição econômica, que armazena a armadura, armas, moeda ou campeões desse usuário. Para obter esses estados, ele chama o PublicUserService, que se volta para Orleans para o estado. O que está acontecendo: Orleans vê que ainda não existe um ator (por exemplo, grão), ele o cria em um servidor gratuito e o grão lê seu estado em alguma loja Persistence.
Portanto, na próxima vez em que você ler recursos da nuvem, como mostrado no slide, todas as leituras virão do cache do cache. No caso em que o usuário sai do jogo, os recursos de leitura não ocorrem, então Orleans entende que o grão não é mais usado por ninguém e pode ser desativado.
Se tivermos vários clientes (cliente do jogo, servidor do jogo), eles podem solicitar estados do usuário e um deles aumentará esse nível. Mais precisamente, isso fará com que Orleans atenda e, em seguida, todas as chamadas, como já sabemos, ocorrem nele com segurança de thread, sequencialmente. Primeiro, o cliente receberá o estado e, em seguida, o servidor do jogo.
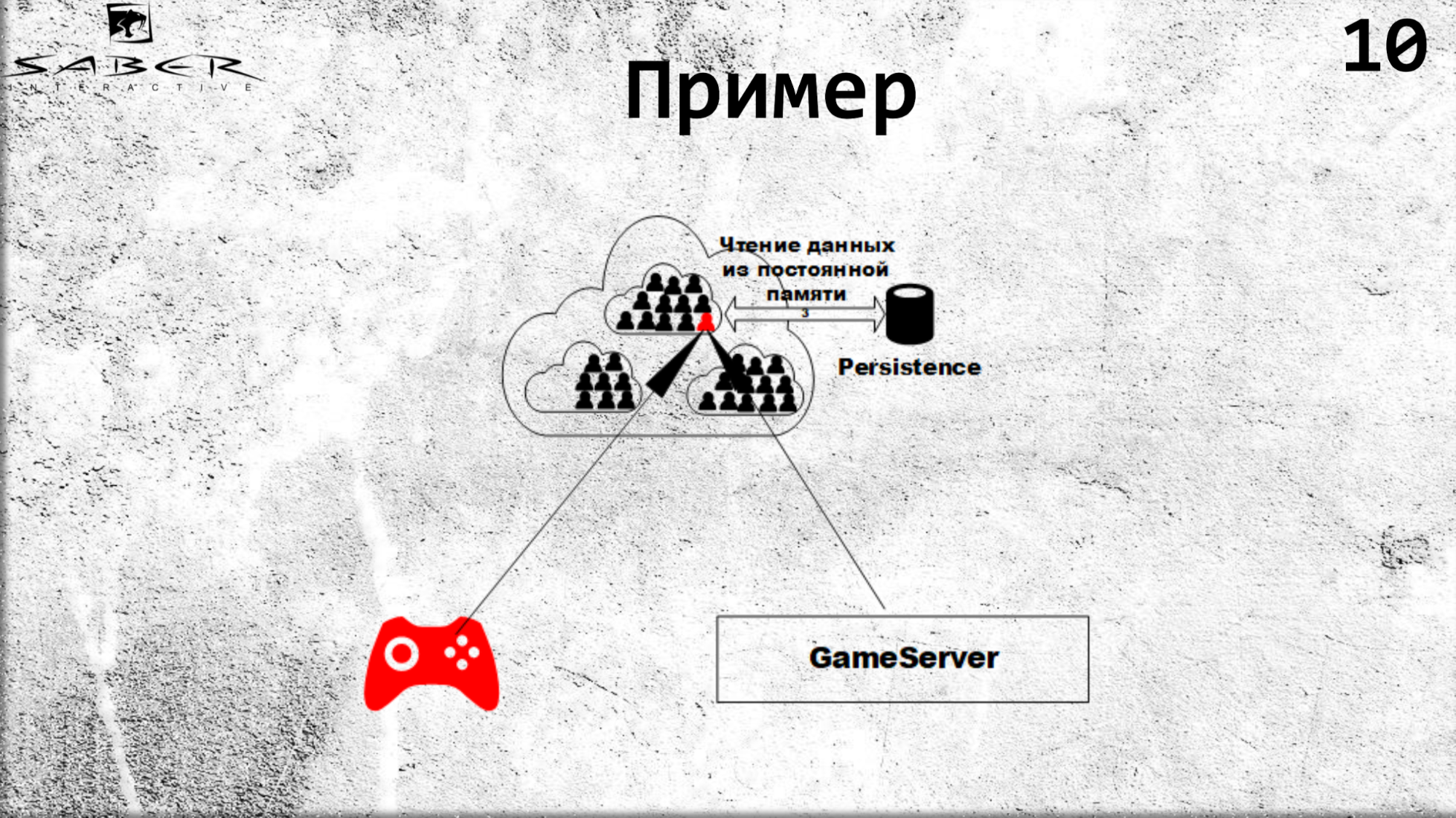
O mesmo fluxo na atualização. Quando um cliente deseja atualizar um estado, ele transfere essa responsabilidade para o grão, ou seja, dirá a ele: “dê a esse usuário 10 ouro” e o grão aumenta, ele processa esse estado com algum tipo de lógica de negócios dentro do grão. E então vem a atualização do cache do cache e, se desejado, a persistência no Persistence.

Por que a persistência é necessária aqui? Esse é um tópico separado e reside no fato de que, às vezes, não é particularmente importante para nós que o Grain mantenha constantemente seus estados em Persistência. Se esse é o estado do jogador on-line, estamos prontos para arriscar perdê-lo por uma questão de produtividade, se se trata da economia, então devemos ter certeza de que seus estados serão preservados.
O caso mais simples: para cada chamada do estado de gravação, escreva esta atualização em Persistence. Portanto, se o grayn cair repentinamente inesperadamente, o próximo aumento de granulação em alguns dos outros servidores causará uma atualização de cache com os dados atuais.
Um pequeno exemplo de como fica.

Como eu já disse, um grão consiste em um tipo e alguma chave (nesse caso, o tipo é IPlayerState, a chave é IGrainWithGuidKey, o que significa que é Guid). E temos uma interface que implementamos, ou seja, GetStates retorna uma lista de estados e ApplyState, que algum estado se aplica. Os métodos de Orleans retornam Tarefa. O que isso significa: Tarefa é uma promessa que nos diz que quando o estado retornar, a promessa estará em estado resolvido. Também temos alguns PlayerState que obtemos com o GrainFactory. I.e. aqui obtemos um link e não sabemos nada sobre a localização física desse grão. Ao chamar GetStates, Orleans aumentará nossa granulação, lerá o estado do armazenamento Persistence em sua memória e, quando ApplyState aplicar um novo estado, ele também atualizará esse estado em sua memória e em Persistence.
Gostaria de fazer um exemplo um pouco mais complexo da arquitetura de alto nível do nosso serviço UserStates.
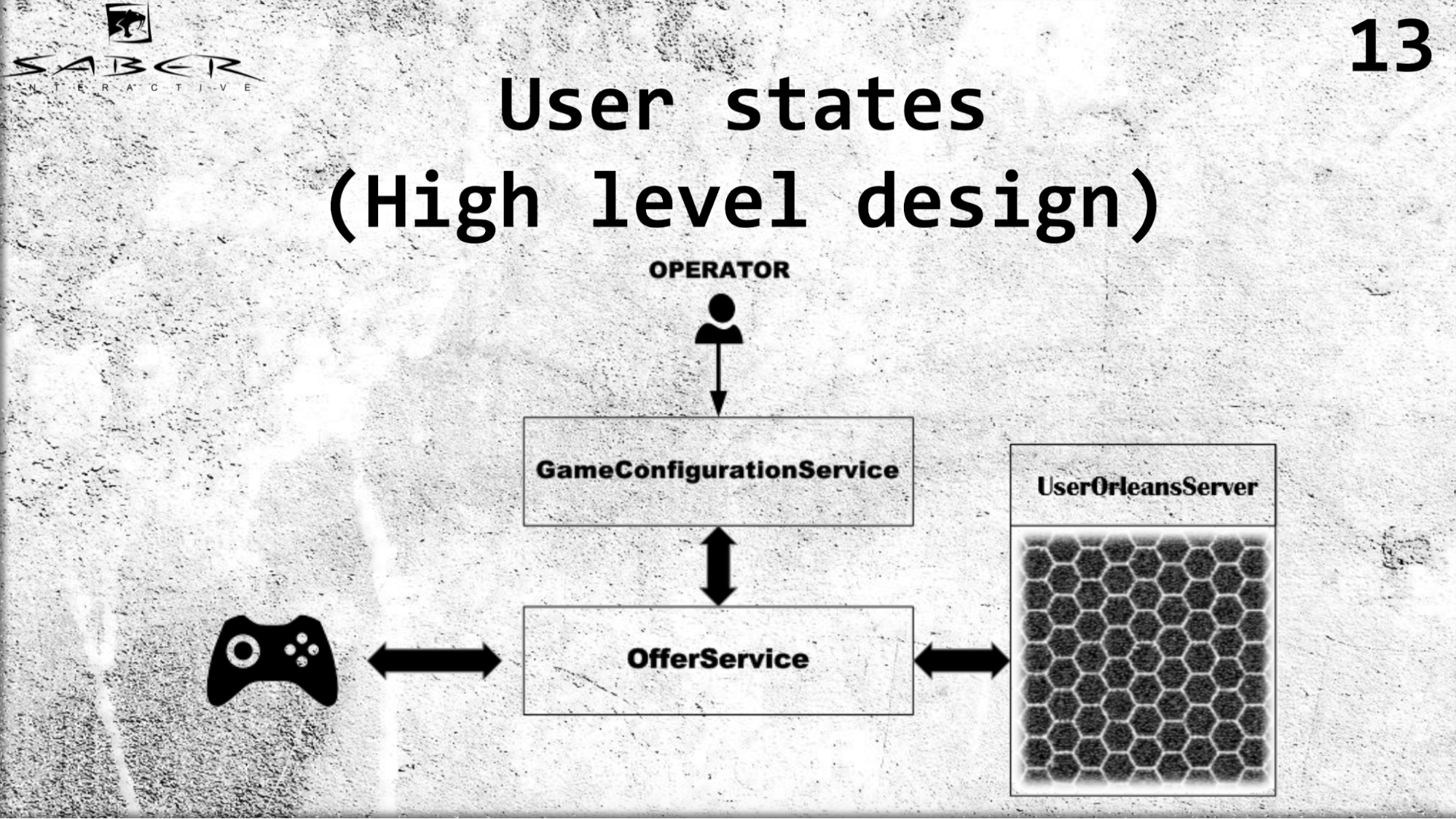
Temos algum tipo de cliente de jogo que obtém seus estados através do OfferSevice. Temos um GameConfigurationService, responsável pelo modelo econômico de um grupo de usuários, neste caso, nosso usuário. E temos uma operadora que está mudando esse modelo econômico. De acordo com ele, o usuário solicita um OfferSevice para receber seus estados. E o OfferSevice já está acessando o serviço UserOrleans, que consiste nesses grãos, eleva esse estado do usuário em sua memória, possivelmente executa algum tipo de lógica de negócios e retorna os dados ao usuário por meio do OfferService.
Em geral, gostaria de chamar a atenção para o fato de Orleans ser boa por sua alta capacidade de paralelismo, devido ao fato de os grãos serem independentes um do outro. Por outro lado, dentro do graine, não precisamos usar primitivas de sincronização, porque sabemos que cada chamada para esse graine será de alguma forma consistente.
Aqui eu gostaria de entender algumas das armadilhas deste modelo.

O primeiro é muito granulado. Como todas as chamadas no greine são seguras para threads, uma após a outra, e se tivermos uma lógica oleosa no greine, teremos que esperar muito tempo. Novamente, muita memória é alocada para um desses grãos. Não existe um algoritmo exato para o tamanho do grão, porque um grão muito pequeno também é ruim. Aqui é bastante necessário proceder a partir do valor ideal. Não vou dizer exatamente qual, cabe ao programador decidir.
O segundo problema não é tão óbvio - essa é a chamada reação em cadeia. Quando um usuário cria alguns grãos, e ele, por sua vez, pode implicitamente criar outros grãos no sistema. Como isso acontece: o usuário recebe seus status, e o usuário tem amigos e ele recebe o status de seus amigos. Portanto, todo o sistema mantém todos os grãos na memória e, se tivermos 1000 usuários e cada um tiver 100 amigos, 100.000 grãos poderão ser ativados assim. Esse caso também precisa ser evitado - de alguma forma, armazene os estados dos amigos em algum tipo de memória compartilhada.

Bem, quais tecnologias existem para implementar o modelo de ator. Talvez o mais famoso seja o Akka, que chegou até nós com Java. Existe uma bifurcação chamada Akka.NET for .NET. Existe o Orleans, que é de código aberto e está em outros idiomas, como uma implementação. Existem primitivas do Azure, como o Service Fabric Actor - existem muitas tecnologias.
Perguntas da platéia
- Como você resolve problemas clássicos como o CICD, atualizando esses atores, usa o Docker e é necessário?- Ainda não estamos usando o docker. Em geral, o DevOps está envolvido na implantação; eles implantam nossos serviços no serviço de nuvem do Azure.
- Atualização contínua, sem paradas, como isso acontece? O próprio Orleans decide em qual servidor o servidor irá, em qual servidor a solicitação irá e como atualizar esse serviço. I.e. uma nova lógica de negócios apareceu, uma atualização do mesmo ator apareceu - como essas atualizações são lançadas?- Se estamos falando sobre atualizar todo o serviço, e se atualizamos alguma lógica comercial do ator, podemos lançar um novo serviço de Orleans para ele. Geralmente isso é resolvido com nossas primitivas chamadas topologia. Lançamos um novo serviço de Orleans, que, por enquanto, está vazio, e sem ator, exibe o serviço antigo e o substitui por um novo. Não haverá atores no sistema, mas na próxima solicitação do usuário, esses atores já serão criados. Provavelmente haverá algum tipo de pico no começo. Nesses casos, a atualização geralmente ocorre pela manhã, já que pela manhã temos o menor número de jogadores.
"Como Orleans entende que o servidor travou?" Você disse que ele rapidamente joga os atores para outro servidor ...- Ele tem um pingador que entende periodicamente quais servidores estão ativos.
- Ele executa ping em um ator ou servidor especificamente?- Especificamente, o servidor.
- Tal pergunta: ocorreu um erro dentro do ator, você diz que ele vai passo a passo, cada instrução. Mas ocorreu um erro e o que acontece com o ator? Suponha um erro que não seja processado. O ator está morrendo?- Não, Orleans lança uma exceção no esquema .NET padrão.
- Olha, nós não lidamos com exceção, o ator aparentemente morreu. O jogador eu não sei como vai ficar, mas então o que acontece? Você está tentando, de alguma forma, reiniciar esse ator ou fazer algo assim?- Depende de qual caso, depende de qual caso. Por exemplo recuperável ou não recuperável.
- I.e. Isso tudo é configurável?- Antes, programado. Estamos lidando com algumas exceções. I.e. vemos claramente que esse código de erro, e alguns, como exceções não tratadas, já foram aprimorados.
- Você tem várias persistências - é como um banco de dados?- Persistência, sim, um banco de dados com armazenamento persistente.
- Digamos que um banco de dados estabeleceu o dinheiro do jogo (condicionalmente). O que acontece se um ator não puder alcançá-la? Como você lida com isso?- Primeiro de tudo, é Storage. No momento, estamos usando o Armazenamento de tabelas do Azure e esses problemas realmente acontecem - falhas de armazenamento. Normalmente, neste caso, você deve reconfigurá-lo.
- Se o ator não conseguiu algo no armazenamento, como é o jogador? Ele simplesmente não tem esse dinheiro ou fecha imediatamente o jogo?- Essas são mudanças críticas para o usuário. Como cada serviço tem sua própria gravidade, nesse caso, o serviço do usuário é um estado terminal e o cliente apenas trava.
- Pareceu-me que as mensagens dos atores ocorrem através de filas assíncronas. Como é essa solução otimizada? Não incha, não faz o jogador desligar? Não é melhor usar uma abordagem reativa?- O problema das filas nos atores é bastante conhecido, porque claramente não podemos controlar o tamanho da fila, você está certo. Mas Orleans, em primeiro lugar, assume algum tipo de trabalho de gerenciamento e, em segundo lugar, acho que simplesmente com o tempo limite o acesso ao ator cairá, ou seja, não podemos alcançar o ator, por exemplo.
- E como isso afetará o jogador?- Como o serviço do usuário entra em contato com o ator, eles lançam uma exceção de tempo limite de exceção e, se for um serviço "crítico", o cliente gera um erro e fecha. E se for menos crítico, esperará.
- I.e. Você tem uma ameaça DDoS? Um grande número de pequenas ações pode colocar um jogador? Digamos que alguém rapidamente comece a convidar amigos, etc.- Não, existe um limitador de solicitações que não permitirá que você acesse serviços com muita frequência.
- Como você lida com a consistência dos dados? Suponha que tenhamos dois usuários, precisamos pegar algo de um e cobrar algo para o outro, para que seja transacional.Boa pergunta. Primeiro, o Orleans 2.0 suporta a transação de ator distribuído - este é o primeiro lançamento. Mais precisamente, já é necessário falar sobre a economia. E como a maneira mais fácil - na última Orleans, as transações entre os atores são implementadas sem problemas.
- I.e. Ele já sabe como garantir que os dados persistam em integridade?Sim.
Mais conversas com o Pixonic DevGAMM Talks