Não gosto quando não há instruções passo a passo simples na rede sem palavras inteligentes mostrando como não fazer as coisas mais óbvias. Portanto, hoje, sem apresentações desnecessárias, mostrarei como fazer backup de um cluster SQL de failover corretamente. Sim, é um cluster, não um servidor SQL independente. Muito foi escrito sobre eles, mas por algum motivo os clusters estão sendo evitados.
E sem uma longa introdução, consideraremos nosso laboratório:
- Cluster do Windows com o Windows Server 2012 r2 sob o capô e um certo número de nós. Por conveniência, existem apenas dois deles no meu laboratório. Surge uma pergunta legítima: por que colocar um cluster em um cluster? Vou explicar um pouco mais baixo.
- Três discos são conectados ao cluster via iSCSI: um quorum, um disco com base (s) e um disco para logs. Você pode fazer mais, menos, aqui, como quiser. Às vezes você gosta: dois discos locais (um para o sistema, um para instalar o próprio SQL), um disco de quorum, um disco combinado para o banco de dados raiz e do sistema, um disco para a base, um disco para logs, um disco para o TempDB e um disco para backups. Os engenheiros de sistema dizem que isso também está correto. Mas acho que quantos discos você tem não desempenharão absolutamente nenhum papel. Se funcionar para você, então você está certo e bem feito.
- Cada nó tem uma instância SQL instalada, que entende que faz parte do cluster SQL, e o cluster do Windows vê a função do SQL Server.
Agora - antes de começarmos - vamos concordar com duas coisas importantes:
- Tome uma decisão e pare de duvidar (eu queria inserir uma piada aqui sobre o balneário, uma cruz e cueca, mas
censurado decidiu prescindir). Uma infraestrutura deve ser gerenciada por apenas uma solução. Se você usar a solução A para SQL de backup e a solução B para backup de cluster, B não deverá tocar em SQL sob nenhuma circunstância. Ou é melhor não usar a solução A, se B puder fazer backups granulares de máquinas no nível do aplicativo. Porque Vamos imaginar que os dois aplicativos possam trankeyitit logs SQL e fazê-lo com sucesso. É claro que o SQL funcionará da maneira certa, mas no próximo backup você receberá uma mensagem sobre o estado inconsistente do servidor, na melhor das hipóteses, e na pior das hipóteses, você não poderá se recuperar do log de transações. - Sei que existem "milênios e mil" opções para o software de backup, todas elas sem dúvida são melhores porque input_reason_here , mas desculpe-me, vou escrever apenas sobre uma que não pode fazer isso pior do que outras, e talvez até melhor.
Vamos lá!
Portanto, como já está claro, faremos o backup de todos os nós. A primeira pergunta surge imediatamente: por que, se o cluster Microsoft SQL pronto para uso nos oferece um nível de proteção muito decente contra quedas? Por exemplo, você sempre pode tirar a função do SQL e recursos para outro nó.
Esse raciocínio é verdadeiro, mas falta a opção de que os próprios nós sejam vulneráveis. Em resumo: o cluster no nível do sistema operacional fecha os riscos associados ao funcionamento do sistema operacional de uma determinada máquina, e o cluster SQL fecha os riscos associados especificamente aos bancos de dados. Sim, e fazer backup dessa configuração é mais interessante.
Vamos imaginar que um malware criptografado chegue até nós e comece a estabelecer nós de cluster, um por um. Aqui não conseguiremos restaurar rapidamente apenas arquivos de banco de dados. E também há atualizações malsucedidas do sistema operacional, hardware em extinção etc.
Portanto, proponho considerar que concordamos com a necessidade de backup de todo o servidor e agora nos voltamos para as ferramentas. Vou escrever como atingir seus objetivos e ser incrível com o Veeam Backup & Replication 9.5. Outra versão atrás, a Veeam conseguiu fazer backup centralizado apenas de máquinas virtuais, mas agora recebeu suporte total para backups de servidores físicos, e seria um pecado não descobrir isso.
Grupos de proteção
Para backup, usaremos o Grupo de Proteção . Na verdade, é uma entidade lógica simples - um contêiner no qual as máquinas que precisam de backup são agrupadas. Por exemplo, nele você pode agrupar vários objetos do AD e não se preocupe com o fato de novas máquinas não entrarem no backup. O Grupo de proteção verifica automaticamente as alterações e executa as ações necessárias restantes de acordo com a programação especificada. Em uma palavra, uma coisa muito conveniente, especialmente em grandes infra-estruturas mistas.
Mas passamos das palavras para a ação: lançamos o Veeam Backup & Replication , acessamos a guia Inventário e lançamos o assistente de criação do Protection Group

Na primeira etapa, você precisa especificar o nome do grupo e alguma descrição conforme necessário, tudo está claro aqui.
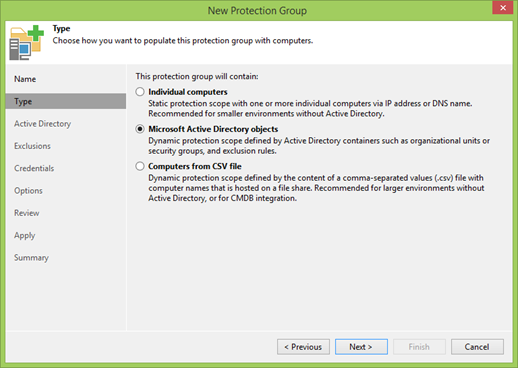
Mas na próxima etapa, você já deve escolher onde o Grupo de Proteção receberá informações sobre as máquinas protegidas. Você pode adicioná-los à maneira antiga manualmente por nomes DNS ou IP, pode fornecer uma lista na forma de um arquivo CSV, como fazem os Jedi reais, mas somos pessoas mais simples e usaremos objetos do Active Directory. No nosso caso, isso também significa que todos os nós do cluster serão detectados automaticamente, incluindo novos.
Na próxima etapa, a primeira coisa que você precisará especificar o endereço do controlador de domínio, porta e dados do usuário a serem conectados.
Se tudo estiver bem, clique em Adicionar e selecione a UO necessária.
Um ponto importante: você só precisa adicionar um cluster! Nós separados não precisam ser adicionados.
Meu cluster é chamado WINCLU, e eu o adicionarei.
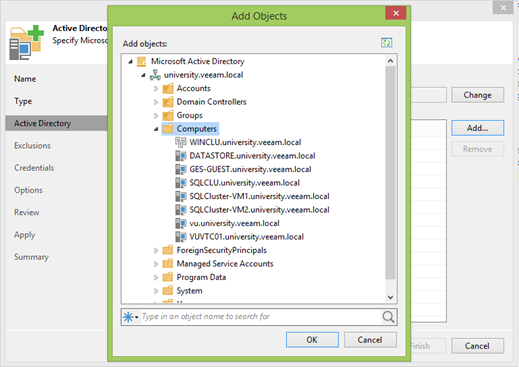
Na próxima etapa, as regras são definidas para excluir máquinas da verificação. No mundo moderno, as UOs geralmente contêm máquinas virtuais e físicas e, em alguns casos, são copiadas em cenários diferentes. De fato, existem até clusters mistos nos quais máquinas físicas e virtuais são usadas. Uma espécie de terceiro nível de proteção.
Por padrão, as duas primeiras caixas de seleção estão marcadas e talvez você não precise removê-las, mas meu laboratório é totalmente virtual e, no início, concordamos em examinar a funcionalidade de backup de máquinas físicas.
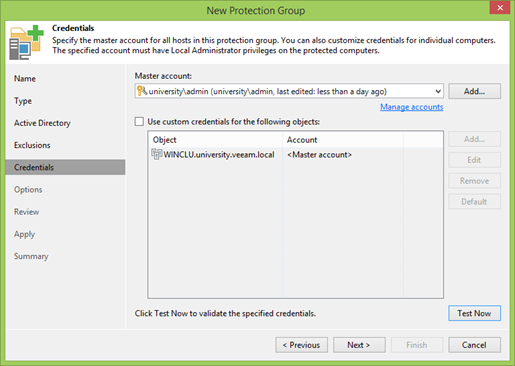
Agora precisamos especificar qual usuário usaremos. Em alguns casos ideais, criamos um usuário especial no AD que possui direitos de administrador local em todas as máquinas. Mas se não for assim, o Veeam permite atribuir um usuário separado para cada objeto.
Por que preciso de um administrador local?
- Primeiro, para instalar o Veeam Agent em cada máquina, o que gerenciará o processo de backup local.
- Em segundo lugar, para que o Veeam Agent faça esse backup, ele precisa de direitos de administrador local para trabalhar com o VSS. É assim que o Windows funciona e não há nada a ser feito sobre isso.
Separadamente, você precisa se concentrar no botão Testar agora . Uma grande coisa que permite verificar rapidamente se todas as contas foram inseridas corretamente e, no caso de um cluster, verifique com antecedência que todos os nós estão visíveis e acessíveis.
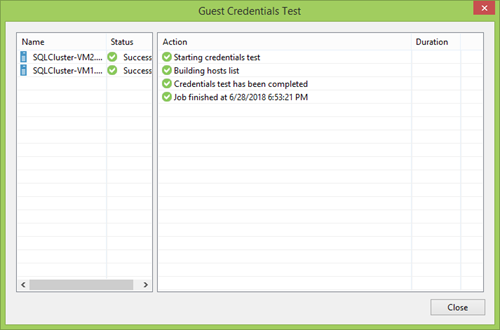
Depois, você precisa definir o intervalo e o tempo para verificar os participantes do PG. Você pode pelo menos uma vez por semana, mas pode configurar a atualização contínua. Depende de você, mas geralmente uma ótima opção é repetir a frequência de backup para que todos os novos participantes possam chegar ao ponto de recuperação mais próximo.
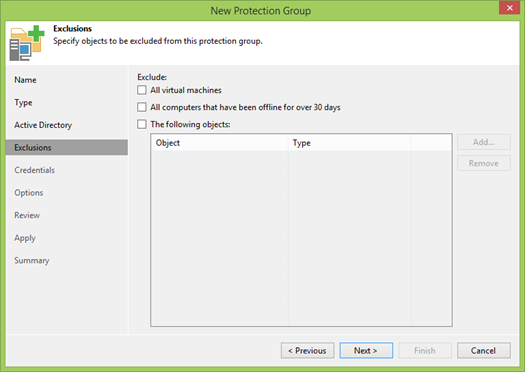
Abaixo estão as opções menos óbvias, mas importantes.
Servidor de distribuição é a máquina na qual os Veeam Agents serão instalados. Em geral, basta usar o servidor Veeam Backup, mas em infraestruturas geograficamente distribuídas e com pouca conexão, faz sentido especificar uma opção mais próxima. Em todos os outros casos, mudar não faz sentido.
Mais longe. Não sei os motivos pelos quais os agentes não devem ser instalados e não atualizados automaticamente, mas se você não confiar na automação, poderá recusar com segurança. Mas lembre-se de que, devido à diferença de versões, você pode ficar sem outro ponto de backup.
Você também pode concordar em instalar nosso driver CBT, que acompanhará a alteração de discos no nível do sistema de arquivos. Isso permitirá que você envie para o backup apenas os setores realmente alterados, o que significa que o ponto de restauração é menor, o backup é mais rápido e a carga no servidor é menor. Mas se você não confia, o tráfego não é importante para você, seus discos são grandes e a conexão é excelente, então você não pode configurá-lo.
Há uma nuance na reinicialização automática: é usada não apenas durante a primeira instalação, mas também durante as atualizações. Portanto, não se esqueça de desmarcar se você não puder pagar esse luxo.
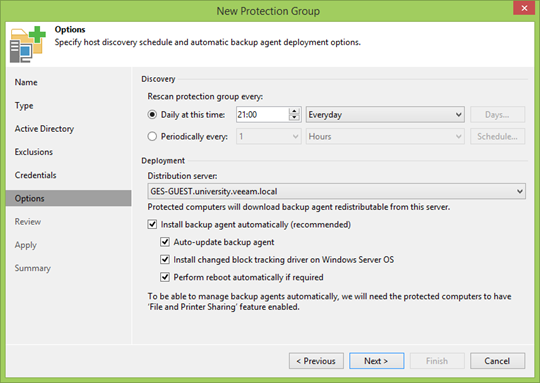
Na próxima etapa, seremos informados sobre a necessidade de reinstalar os componentes no servidor de distribuição. Mesmo se eles não estiverem lá, em um minuto eles estarão lá clicando no botão Aplicar .
Na última etapa, seremos informados de que o Grupo de Proteção (PG) foi criado com sucesso e será oferecido para iniciar a descoberta, ou seja, o grupo de acordo com as condições especificadas fará uma lista de máquinas e de acordo com as configurações iniciará a instalação dos agentes. Enquanto todas as operações necessárias ocorrerem, você pode tomar café.
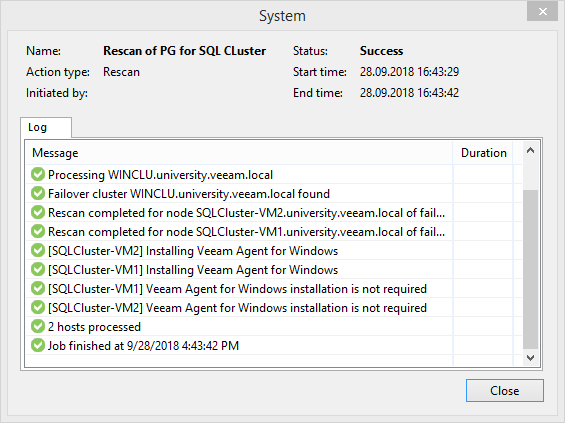
Esvaziando uma xícara de café, você pode achar que um agente não pôde ser instalado em um dos nós devido a um erro de acesso à rede. Se esse sofrimento aconteceu com você, basta desconectar o disco de quorum desse nó. Não é frequente, mas acontece. Ou talvez isso seja apenas um recurso do meu laboratório. Portanto, não tivemos perseverança para lidar com esse problema até o fim.
Criar backup
Portanto, se no estágio anterior tudo terminar com êxito, seu grupo de proteção agora terá um cluster e uma lista de seus nós com agentes instalados com sucesso. Portanto, passamos ao mais interessante: criamos um backup no modo Cluster de Failover para que todos os nós e todos os discos conectados entrem nele.
Qual é a principal diferença e por que você não pode salvá-las como máquinas separadas? Tecnicamente, você pode fazer isso com todos os nós, exceto um - o atual detentor da função de cluster. Se você começar a fazer backup diretamente na testa, os outros nós poderão perder o contato e começar a puxar o cobertor sobre si mesmos, o que levará ao colapso e à parada de todo o cluster. Isso acontece com frequência em sistemas ocupados.

Usando o botão direito do mouse (RMB), clicando em PG, iniciamos o assistente de criação de tarefas de backup e selecionamos imediatamente o modo Cluster de Failover . Essas tarefas podem ser criadas apenas no servidor de backup central, diferentemente dos backups de agentes locais. Mas isso é lógico: como você se lembra, queríamos fazer backup completo do SQL ao mesmo tempo, o que significa que os logs serão rastreados regularmente - pelo qual, em qualquer caso, você precisará de comunicação entre os servidores.
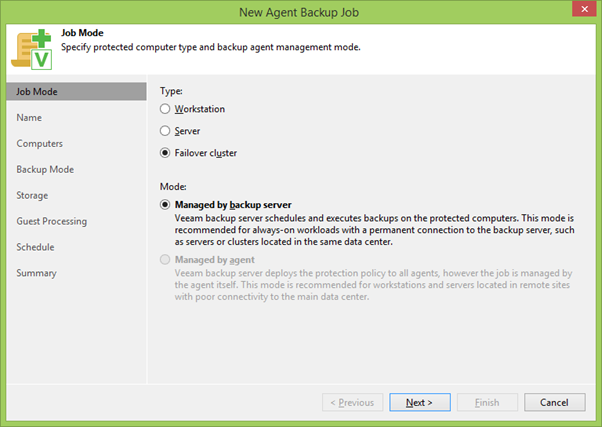
Em seguida, selecione o nome do trabalho e a lista de participantes do backup. Por padrão, haverá apenas o PG selecionado, mas aqui você também pode adicionar algo adicional.
Na próxima etapa, você precisa escolher entre o backup de discos individuais ou a máquina inteira. Em geral, se você puder fazer backup de toda a máquina, precisará fazer backup de toda a máquina. No nosso caso, isso é verdade, porque precisamos fazer backup de todos os discos do cluster que possam aparecer em qualquer nó do cluster.
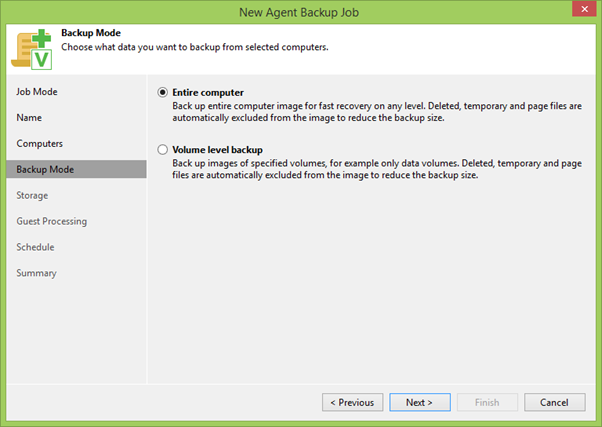
Em seguida, selecionamos um repositório para backups e especificamos quantos pontos de recuperação teremos. Usando o botão Avançado , você pode acessar o menu de ajuste fino, onde pode escolher como criar uma cadeia de backup, ativar verificações adicionais de integridade de arquivos e muito mais, o que não perderemos tempo agora, porque a seção mais interessante é a seção Processamento de Convidados .

Depende das configurações desta guia se podemos obter o chamado backup consistente do aplicativo (que às vezes é traduzido como backup integral ou como backup, levando em consideração o estado dos aplicativos ou ainda não entendemos como e, o mais importante, por que). Portanto, vá para Aplicativos , selecione nosso PG e clique em Editar .

Certifique-se de que a primeira guia inclua Processamento que reconhece aplicativos Nesse caso, o subsistema VSS estará envolvido, cujo trabalho deve passar sem erros. Em vez disso, ele pode funcionar com erros, mas, nesse caso, o backup não será criado e você precisará entender as causas da falha. Aqui você também precisa determinar o destino dos logs de transações: a Veeam pode ignorá-los, basta copiar para fazer backup ou cortar.
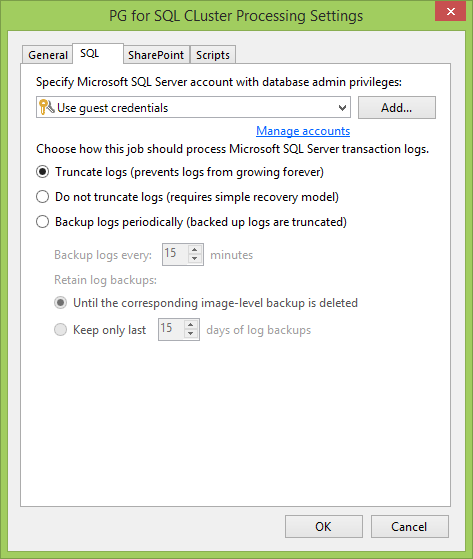
Agora vá para a guia SQL . A primeira coisa a fazer é definir a conta do usuário para interação com o servidor SQL e seus bancos de dados. Em um mundo ideal, ele corresponde ao administrador local que especificamos ao criar o PG. Caso contrário, o principal é que esse usuário deve ter direitos de Proprietário do Banco de Dados .
Depois escolhemos como vamos interagir com os logs. Por exemplo, se você possui um banco de dados no modo de Recuperação total , é muito conveniente fazer trankit de logs. Ou você pode fazer backup dos logs de transações em um agendamento separado, para que você possa reverter rapidamente o banco de dados para a hora certa e não perder tudo o que havia entre os backups. Obviamente, você não pode fazer nada com os logs.
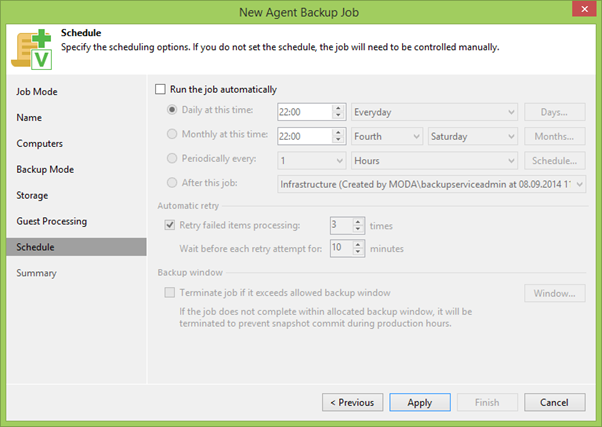
Passamos para o penúltimo ponto do Cronograma , onde definimos o cronograma de acordo com suas necessidades. É o suficiente para alguém uma vez por dia, alguém uma vez por hora, depende de você.
Concluímos a tarefa clicando em Aplicar algumas vezes e aproveitamos o resultado.
Em um mundo ideal, se você não tiver nenhum truque com a instalação de agentes que funcionem como um link entre o cluster e o Veeam Server, ou se de repente se esquecer de carregar a licença necessária para os agentes, o trabalho funcionará perfeitamente e você verá a figura a seguir.
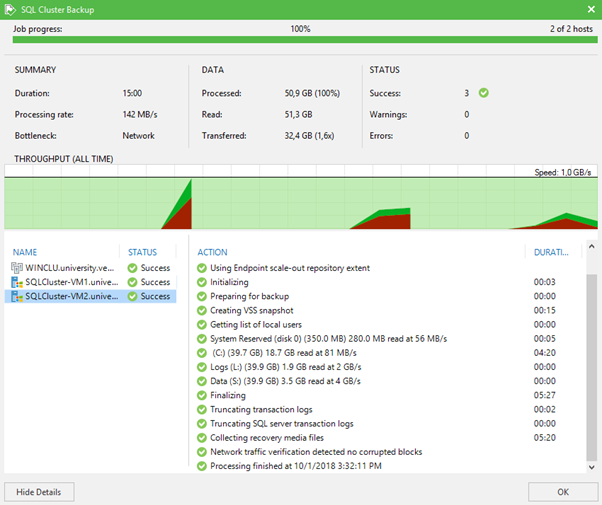
Isso é tudo. Acontece que os clusters de backup não são tão assustadores quanto costuma pensar. Mesmo que seja um cluster dentro de outro cluster.
Se você estiver interessado em aprender sobre outro cenário de backup / restaurante, escreva sobre ele nos comentários, e contaremos tudo da melhor maneira possível.