
* Fazenda - (da agricultura inglesa) - uma repetição longa e chata de certas ações do jogo para um propósito específico (ganhar experiência, obter recursos etc.).
1. Introdução
Recentemente (1 de outubro), foi lançada uma nova sessão do excelente curso DS / ML (eu recomendo quem quiser, como é chamado agora, "entrar" no DS como um curso inicial). E, como sempre, após concluir qualquer curso, os graduados têm uma pergunta - onde obter experiência prática agora para consolidar o conhecimento teórico ainda bruto. Se você fizer esta pergunta em qualquer fórum de perfis, a resposta provavelmente será única: resolva o Kaggle. Kaggle é sim, mas por onde começar e como usar essa plataforma de maneira mais eficaz para habilidades práticas? Neste artigo, o autor tentará responder a essas perguntas com base em sua própria experiência, além de descrever a localização do rake principal no campo do DS competitivo, para acelerar o processo de bombeamento e obter um fã dele.
Algumas palavras sobre o curso de seus criadores:
O curso mlcourse.ai é uma das atividades de grande escala da comunidade OpenDataScience. A @yorko e a empresa (~ 60 pessoas) demonstram que habilidades legais podem ser obtidas fora da universidade e até mesmo totalmente gratuitas. A idéia principal do curso é a combinação ideal de teoria e prática. Por um lado, a apresentação dos conceitos básicos não acontece sem a matemática, por outro lado - muito dever de casa, os concursos e projetos do Kaggle Inclass darão, com um certo investimento de esforço de sua parte, excelentes habilidades de aprendizado de máquina. Deve-se notar a natureza competitiva do curso - uma avaliação geral dos alunos está sendo realizada, o que motiva fortemente. O curso também é diferente, pois ocorre em uma comunidade verdadeiramente vibrante.
O curso inclui duas competições Kaggle Inclass. Ambos são muito interessantes, funcionam bem na construção de signos. O primeiro é a identificação do usuário pela sequência de sites visitados . O segundo é a previsão da popularidade de um artigo no Medium . O principal benefício é de dois trabalhos de casa, nos quais você precisa ser inteligente e vencer as linhas de base nessas competições.
Depois de prestar homenagem ao curso e seus criadores, continuamos nossa história ...
Lembro-me de um ano e meio atrás, um curso (ainda a primeira versão) de Andrew Ng foi concluído, a especialização do Instituto de Física e Tecnologia de Moscou foi concluída , uma montanha de livros foi lida - a cabeça do conhecimento teórico está cheia, mas quando você tenta resolver qualquer tarefa básica de combate, surge um estupor. Não, como resolver o problema - é claro quais algoritmos aplicar - também é compreensível, mas o código é muito difícil de escrever, com a ajuda do sklearn / pandas acessada a cada minuto, etc. Por que isso - não há pipelines acumulados e a sensação do código "ao seu alcance".
Isso não vai funcionar, pensou o autor, e foi para o Kaggle. Foi assustador começar imediatamente de uma competição de combate, e a Casa da Concorrência " Preços da Casa: Técnicas Avançadas de Regressão " se tornou o primeiro sinal, que formou a abordagem para o bombeamento eficaz descrito neste artigo.
No que será descrito mais adiante, não há know-how, todas as técnicas, métodos e técnicas são óbvias e previsíveis, mas isso não prejudica sua eficácia. Pelo menos, seguindo-os, o autor conseguiu levar o dado do Kaggle Competition Master por seis meses e três competições no modo solo e, no momento da redação deste artigo, entre os 200 primeiros na classificação mundial do Kaggle . A propósito, isso responde à pergunta por que o autor se permitiu a coragem de escrever um artigo desse tipo.
Em poucas palavras, o que é Kaggle
O Kaggle é uma das plataformas mais famosas para a realização de competições em Data Science. Em cada competição, os organizadores enviam uma descrição do problema, dados para resolvê-lo, a métrica pela qual a solução será avaliada - e estabelecem prazos e prêmios. Os participantes recebem de 3 a 5 tentativas (por vontade dos organizadores) por dia para "enviar" (enviar sua própria solução).
Os dados são divididos em uma amostra de treinamento (trem) e teste (teste). Para a parte de treinamento, o valor da variável de destino (alvo) é conhecido, para a parte de teste - não. A tarefa dos participantes é criar um modelo que, sendo treinado na parte de treinamento dos dados, produza o resultado máximo no teste.
Cada participante faz previsões para a amostra de teste - e envia o resultado para o Kaggle, então o robô (que conhece a variável de destino para o teste) avalia o resultado enviado, que é exibido na tabela de classificação.
Mas nem tudo é tão simples - os dados de teste, por sua vez, são divididos em uma certa proporção na parte pública (pública) e privada (privada). Durante a competição, a decisão enviada é avaliada, de acordo com a métrica definida pelos organizadores, na parte pública dos dados e apresentada na tabela de classificação (a chamada tabela de classificação pública) - pela qual os participantes podem avaliar a qualidade de seus modelos. A decisão final (geralmente duas - por escolha do participante) é avaliada na parte privada dos dados do teste - e o resultado cai na tabela de classificação privada, que está disponível somente após o final da competição e pela qual, de fato, os resultados finais são avaliados, prêmios, pães e medalhas são distribuídos.
Assim, durante a competição, apenas as informações estão disponíveis para os participantes, conforme seu modelo se comportou (qual resultado - ou mostrou velocidade) na parte pública dos dados do teste. Se, no caso de um cavalo esférico no vácuo, a parte privada dos dados coincidir com a distribuição e as estatísticas com o público - está tudo bem, mas se não estiver -, um modelo que tenha um bom desempenho em público pode não funcionar na parte privada, ou seja, overfix (reciclagem). E aqui surge o que é chamado de "vôo" no jargão, quando as pessoas do 10º lugar em público voam de 1000 a 2000 lugares em uma parte privada, devido ao fato de que o modelo que escolheram foi treinado novamente e não pôde fornecer a precisão necessária para novos dados.

Como evitar isso? Para isso, antes de tudo, é necessário criar o esquema de validação correto, algo que é ensinado nas primeiras lições em quase todos os cursos do DS. Porque se seu modelo não puder fornecer a previsão correta dos dados que ele nunca viu - não importa qual técnica sofisticada você use, não importa quão complexas redes neurais você construa - na produção, esse modelo não poderá ser produzido, porque seus resultados são inúteis.
Para cada competição no Kaggle, é criada uma página separada na qual há uma seção com dados, com uma descrição da métrica - e mais interessante para nós - um fórum e kernels.
Fórum ele e o fórum Kaggle, as pessoas escrevem, discutem e compartilham idéias. Mas os núcleos já são mais interessantes. De fato, essa é a capacidade de executar seu próprio código que tem acesso direto aos dados da concorrência na nuvem Kaggle (análogo da AWS da Amazônia, GCE do Google etc.) Recursos limitados são alocados para cada kernel; portanto, se não houver muitos dados, trabalhe com com eles, você pode diretamente do navegador no site da Kaggle - escreva o código, execute-o para execução, envie o resultado. Há dois anos, o Kaggle foi adquirido pelo Google, portanto, não é de surpreender que essa funcionalidade use o Google Cloud Engine "sob o capô".
Além disso, houve várias competições (recentes - Mercari ), nas quais você pode trabalhar com dados em geral somente através de kernels. Um formato muito interessante, nivelando a diferença de hardware entre os participantes e forçando o cérebro a ativar a otimização de código e abordagens, uma vez que, naturalmente, os kernels tinham um limite estrito de recursos na época - 4 núcleos / 16 GB RAM / 60 minutos em tempo de execução / 1 GB de espaço de disco de rascunho e saída. Enquanto trabalhava nessa competição, o autor aprendeu mais sobre otimização de redes neurais do que em qualquer curso teórico. Um pouco não foi suficiente para o ouro, terminou solo no dia 23, mas recebeu experiência e prazer praticamente ...
Aproveitando esta oportunidade, quero agradecer novamente aos meus colegas do ods.ai - Arthur Stepanenko (Arthur) , Konstantin Lopukhin (Kostia) , Sergey Fironov (Sergeif) por seus conselhos e apoio nesta competição. Em geral, havia muitos pontos interessantes, Konstantin Lopukhin (kostia) , que ficou em primeiro lugar com Paweł Jankiewicz , depois expôs o que foi chamado de " humilhação de referência de 75 linhas " na sala de bate-papo - um núcleo em 75 linhas de código que gera o resultado na zona dourada do placar. Isso, é claro, deve ser visto :)
Ok, distraído e assim - as pessoas escrevem o código e distribuem kernels com soluções, idéias interessantes e muito mais. Geralmente, em cada competição, depois de algumas semanas, um ou dois excelentes EDAs (análise exploratória de dados) são exibidos, com uma descrição detalhada do conjunto de dados, estatísticas, características, etc. E algumas linhas de base (soluções básicas), que, obviamente, não mostram o melhor resultado na tabela de classificação, mas podem ser usadas como ponto de partida para criar sua própria solução.
Por que Kaggle?

De fato, não importa em que plataforma você jogue, apenas o Kaggle é um dos primeiros e mais populares, com uma excelente comunidade e um ambiente bastante confortável (espero que eles refinem os kernels para estabilidade e desempenho, e muitos se lembram do inferno que estava acontecendo Mercari ) Mas, em geral, a plataforma é muito conveniente e auto-suficiente, e seus dados ainda são apreciados.
Uma pequena digressão em geral sobre o tema do DS competitivo. Muitas vezes, em artigos, conversas e outras comunicações, o pensamento parece que tudo isso é besteira, a experiência em competições não tem nada a ver com tarefas reais, e as pessoas estão envolvidas no ajuste da quinta casa decimal, que é insanidade e divorciada de realidade. Vejamos esse problema com mais detalhes:
Como praticantes de especialistas em DS, diferentemente da academia e da ciência, em nosso trabalho, devemos e resolveremos os problemas de negócios. Ou seja (aqui está uma referência ao CRISP-DM ) para resolver a tarefa que é necessária:
- entender o desafio do negócio
- avaliar dados sobre o assunto se a resposta para esta tarefa de negócios pode estar oculta neles
- coletar dados adicionais se existentes não forem suficientes para obter uma resposta
- escolha a métrica que mais se aproxima da meta de negócios
- e somente depois disso selecione o modelo, converta os dados para o modelo selecionado e "drene hgbusta". (C)
Os quatro primeiros pontos desta lista não são ensinados em nenhum lugar (corrija-me, se esses cursos aparecerem - vou me inscrever sem hesitar); aqui só podemos aprender com a experiência de colegas que trabalham nesta indústria. E aqui está o último ponto - a partir da escolha do modelo e além, é possível e necessário participar de competições.
Em qualquer competição, a maior parte do trabalho foi feita pelos organizadores. Temos o objetivo comercial descrito, a métrica aproximada foi selecionada, os dados foram coletados - e nossa tarefa é criar um pipeline de trabalho com todo esse lego. E aqui as habilidades são aprimoradas - como trabalhar com passes, como preparar dados para redes e árvores neurais (e por que as redes neurais exigem uma abordagem especial), como construir corretamente a validação, como não treinar novamente, como escolher hiperparâmetros, como ....... uma dúzia ou duas de "como", cuja atuação competente distingue um bom especialista das pessoas que estão passando em nossa profissão.
O que você pode "cultivar" no Kaggle

Basicamente, e isso é razoável, todos os recém-chegados vêm ao Kaggle para obter e aproveitar a experiência prática, mas não se esqueça de que, além disso, há pelo menos mais dois objetivos:
- Dados e medalhas de fazenda
- Reputação da Fazenda na Comunidade Kaggle
O principal a lembrar é que esses três objetivos são completamente diferentes, são necessárias abordagens diferentes para alcançá-los, e você não deve confundi-los especialmente no estágio inicial!
Não é à toa que é enfatizado "no estágio inicial" quando você está bombeando - esses três objetivos se fundem em um e serão resolvidos em paralelo, mas enquanto você está apenas começando - não os misture ! Desta forma, você evitará dor, decepção e ressentimento neste mundo injusto.
Vamos resumir os objetivos de baixo para cima:
- Reputação - estimulada escrevendo boas postagens (e comentários) no fórum e criando kernels úteis. Por exemplo, kernels da EDA (veja acima), postagens descrevendo técnicas fora do padrão etc.
- As medalhas são um tópico muito controverso e de ódio, mas tudo bem. É bombeado combinando os kernels públicos (*), a participação em uma equipe com um viés de experiência e a criação de seu próprio pipeline superior.
- Experiência - bombeada pela análise de decisões e trabalho com erros.
(*) mistura pública de kernel é uma técnica de medalha de fazenda na qual os kernels dispostos são selecionados com a velocidade máxima na tabela de classificação pública, suas previsões são calculadas em média (combinadas) e o resultado é enviado. Normalmente, esse método leva a um super ajuste rígido (reciclagem para treinar) e a voar em privet, mas às vezes permite que você receba um envio quase em prata. O autor, na fase inicial, não recomenda uma abordagem semelhante (leia abaixo sobre o cinto e a calça).
Eu recomendo o primeiro objetivo a escolher "experiência" e cumpri-lo até o momento em que você sentir que está pronto para trabalhar em dois / três objetivos ao mesmo tempo.
Há mais dois pontos que vale a pena mencionar (Vladimir Iglovikov (ternaus) - obrigado pelo lembrete).
A primeira é a conversão dos esforços investidos no Kaggle em um novo local de trabalho mais interessante e / ou altamente remunerado. Não importa como as matrizes Kaggle estão niveladas agora, para entender as pessoas, a linha no resumo do mestre da competição Kaggle e outras conquistas ainda valem alguma coisa.
Para ilustrar esse ponto, podemos citar duas entrevistas ( uma , duas ) com nossos colegas Sergey Mushinsky (cepera_ang) e Alexander Buslaev (albu)
E também a opinião de Valery Babushkin ( venheads) :
Valery Babushkin - Chefe de Ciência de Dados do X5 Retail Group (o número atual de funcionários é de 30 pessoas + 20 vagas desde 2019)
Chefe do grupo de análise Yandex Advisor
O Kaggle Competition Master é uma excelente métrica de proxy para avaliar um futuro membro da equipe. Obviamente, em conexão com os últimos eventos na forma de equipes de 30 pessoas e locomotivas não disfarçadas, é necessário um estudo um pouco mais aprofundado do perfil do que antes, mas isso ainda é uma questão de vários minutos. Uma pessoa que alcançou o título de mestre, com um alto grau de probabilidade, sabe escrever código de qualidade pelo menos média, é versada em aprendizado de máquina, sabe como limpar dados e criar soluções estáveis. Se você ainda não consegue se gabar da língua de um mestre, o fato de participar também é uma vantagem, pelo menos o candidato sabe da existência de Kagl e não era muito preguiçoso e passou um tempo dominando-o. E se algo diferente de um kernel público foi lançado e a solução resultante excedeu seus resultados (o que é bastante fácil de verificar), então esta é uma ocasião para uma discussão detalhada sobre os detalhes técnicos, que é muito melhor e mais interessante do que as perguntas da teoria clássica, cujas respostas dão menos compreensão de como uma pessoa fará o trabalho no futuro. A única coisa que eu deveria ter medo e com o que me deparei é que algumas pessoas pensam que o trabalho do DS é algo como Kagl, que é fundamentalmente errado. Muitos mais pensam que DS = ML, o que também é um erro
O segundo ponto é que a solução para muitos problemas pode ser estruturada na forma de pré-impressões ou artigos, o que, por um lado, permite que o conhecimento que a mente coletiva deu à luz durante a competição não morra nos confins do fórum, mas, por outro lado, acrescenta mais uma linha ao portfólio dos autores. e +1 à visibilidade, que de qualquer forma afeta positivamente o índice de carreira e de citação.
Por exemplo, a lista de trabalhos de nossos colegas após os resultados de várias competiçõesAutores (em ordem alfabética):
Andrei o. snikolenko, ternaus, twoleggedeye, versus, viciante, zfturbo
Como evitar a dor de perder uma medalha

Para marcar!
Eu vou explicar Em quase todas as competições, mais perto do fim, um kernel é apresentado ao público com uma solução que eleva toda a classificação, mas para você, com sua decisão, de acordo. E toda vez que o fórum começa DOR! Como é que eu tomei uma decisão sobre prata e agora nem uso bronze. O que há, recupere-o.
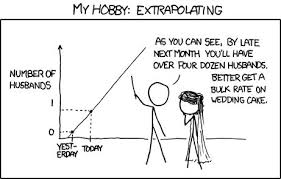
Lembre-se: o Kaggle é um DS competitivo. O lugar na tabela de classificação em que você está depende é de você. , , , .
— .
, — . , , , - . , — . , - .
, , — … . , , — — .
, . — . ( Talking Data , 8- ) , (ppleskov) : " , , — ". , .
— :
" "()
, .

— python 3.6 jupyter notebook ubuntu . Python - DS, , jupyter , jupyter_contrib_nbextensions , , ubuntu — , bash :)
jupyter_contrib_nbextensions :
- Collapsible headings ( )
- Code folding ( )
- Split cells (, - )
.
- , . — . — .
, jupyter notebook , , . ( , , ( (ternaus) )
, jupyter - IDE, pycharm .
, , " ". , .
/OOF (.) .
(*) OOF — out of folds , -. . .
Como :
Em geral, na comunidade há uma tendência de mudar gradualmente para a terceira opção, porque e o primeiro e o segundo têm suas desvantagens, mas são simples, confiáveis e, francamente, para o Kaggle são suficientes.

Sim, mais sobre python para quem não é programador - não tenha medo disso. Sua tarefa é entender a estrutura básica do código e a essência básica da linguagem para entender os kernels de outras pessoas e escrever suas bibliotecas. Existem muitos bons cursos para iniciantes na Web, talvez nos comentários eles digam exatamente onde. Infelizmente (ou felizmente) não posso avaliar a qualidade desses cursos, por isso não forneço links no artigo.
Então, vamos para a estrutura.

Nota
Toda a descrição adicional será baseada no trabalho com dados tabulares e de texto. As imagens, que agora estão muito no Kaggle, são um tópico separado com estruturas separadas. Em um nível básico, é bom poder processá-los, mesmo que apenas dirija através de algo como ResNet / VGG e retire recursos, mas um trabalho mais profundo e sutil com eles é um tópico separado e muito extenso que não é considerado na estrutura deste artigo.
O autor honestamente admite que não é muito bom em fotos. A única tentativa de se envolver com a bela foi na competição de identificação de câmera , na qual, a propósito, nossas equipes com a etiqueta [ ods.ai ] explodiram a classificação inteira a tal ponto que os administradores do Kaggle tiveram que nos visitar na folga para garantir que tudo estivesse dentro regras - e tranquilizar a comunidade. Então, nessa competição, eu ganhei a prata honorária com o 46º lugar e, quando li a descrição das principais soluções de nossos colegas, percebi que não podia ficar mais alto e eles realmente usam magia negra com aumento, qualidade de 300 GB de dados, sacrifícios e assim por diante.
Em geral, se você deseja começar com imagens, precisará de outras estruturas e outros guias.
Objetivo principal
Sua tarefa é escrever pipelines (projetados como blocos de anotações jupyter + módulos) para as seguintes tarefas:
- EDA (análise exploratória de dados) . Aqui precisamos fazer um comentário - há pessoas especialmente treinadas no Kaggle :) que viram impressionantes núcleos da EDA em todas as competições. Você dificilmente conseguirá superá-los, mas ainda precisará entender como pode ver os dados, porque Em missões de combate, essa pessoa especialmente treinada será você. Portanto, estudamos abordagens, expandimos nossas bibliotecas.
- Limpeza de dados - tudo sobre limpeza de dados. Emissões, omissões, etc.
- Preparação de dados - tudo relacionado à preparação de dados para o modelo. Alguns quarteirões:
- Modelos
- Modelos lineares
- Modelos de árvore
- Redes neurais
- Exótico (FM / FFM)
- Seleção de recursos
- Pesquisa de hiperparâmetros
- Ensemble
Nos kernels, geralmente todas essas tarefas são coletadas em um único código, o que é compreensível, mas eu recomendo que para cada uma dessas subtarefas seja criado um laptop separado e um módulo separado (um conjunto de módulos). Portanto, será mais fácil para você mais tarde.
Advertindo o possível holivar - a estrutura dessa estrutura não é a verdade última, existem muitas outras maneiras de estruturar seus pipelines - essa é apenas uma delas.
Os dados são transmitidos entre os módulos na forma de CSV, ou feather / pickle / hdf - o que é mais conveniente para você e para o que você está acostumado ou a alma está.
Na verdade, muito ainda depende da quantidade de dados, no TalkingData, por exemplo, eu tive que passar pelo memmap para contornar a falta de memória ao criar um conjunto de dados para lgb.
Em outros casos, os dados principais são armazenados em hdf / feather, algo pequeno (como um conjunto de atributos selecionados) está em CSV . Repito - não há modelos, quem está acostumado com o que, trabalha com isso.
Fase inicial
Vamos a qualquer competição de Introdução (como já mencionado, o autor começou com Preços da Casa: Técnicas Avançadas de Regressão ) e começamos a criar nossos laptops. Lemos kernels públicos, copiamos trechos de código, procedimentos, abordagens etc. etc. Executamos os dados no pipeline, enviamos - observamos o resultado, melhoramos e assim por diante em um círculo.
A tarefa nesse estágio é coletar um pipeline de ciclo completo com funcionamento eficiente, desde os dados de carregamento e limpeza até o envio final.
Uma lista de amostra do que deve estar pronto e funcionando 100% antes de passar para a próxima etapa:
- EDA . (estatísticas sobre conjunto de dados, boxplots, faixa de categorias, ...)
- Limpeza de dados. (passa por fillna, categorias de limpeza, combinando categorias)
- Preparação de dados
- Geral (categorias de processamento - etiqueta / ohe / frequência, projeção de números em categorias, transformação de números, classificação)
- Para regressões (várias escalas)
- Modelos
- Modelos lineares (várias regressões - crista / logística)
- Modelos em árvore (lgb)
- Seleção de recursos
- grade / pesquisa aleatória
- Ensemble
Vá para a batalha

Escolha qualquer competição que você gosta e ... comece :)
Embora não exista um esquema de validação de trabalho - não há mais etapas !!!
- Execute os dados através do nosso pipeline gerado e envie o resultado
- Nós agarramos nossas cabeças, loucos, nos acalmamos ... e continuamos ...
- Lemos todos os kernels sobre as técnicas e abordagens utilizadas.
- Leia todas as discussões do fórum
- Remodeamos / complementamos oleodutos com novas técnicas
- Passamos para o passo 1
Lembre-se - nosso objetivo nesta fase é ganhar experiência ! Encha nossos pipelines com abordagens e métodos de trabalho, encha nossos módulos com código de trabalho. Não nos preocupamos com medalhas - ou melhor, é ótimo se você pode imediatamente tomar seu lugar na tabela de classificação, mas se não, não se preocupe. Nós não viemos aqui por cinco minutos, medalhas e matrizes não vão a lugar algum.
Aqui a competição acabou, você está em algum lugar por aí, parece que todo mundo está pegando o próximo?
NÃO!
O que você faz a seguir:
- Esperando cinco dias. Não leia o fórum, esqueça o Kaggle no momento. Deixe seu cérebro relaxar e embaçar os olhos.
- Volte para a competição. Durante esses cinco dias, pelas regras do bom gosto, todos os principais membros postarão uma descrição de suas decisões - em posts no fórum, na forma de kernels, na forma de repositórios do github.
E aqui começa o seu INFERNO pessoal!
- Você pega várias folhas no formato A4, em cada uma delas escreve o nome do módulo na estrutura acima (EDA / Preparação / Modelo / Conjunto / Seleção de recursos / Pesquisa de hiperparâmetros / ...)
- Leia consistentemente todas as soluções, escreva novas técnicas, métodos e abordagens novas para você nos folhetos correspondentes.
E a pior coisa:
- Consistentemente para cada módulo, escreva (espie) a implementação dessas abordagens e métodos, expandindo seu pipeline e bibliotecas.
- No modo pós-envio, execute os dados através do seu pipeline atualizado até ter uma solução na zona dourada ou até que a paciência e os nervos acabem.
E somente depois disso prosseguiremos para a próxima competição.
Não, eu não estou ferrado. Sim, é possível e mais fácil. Você decide.
Por que esperar 5 dias e não ler imediatamente, porque no fórum você pode fazer perguntas? Nesta fase (na minha opinião), é melhor ler os tópicos já formados com a discussão de soluções, perguntas que você possa ter - ou alguém perguntará, ou é melhor não perguntar, mas procurar a resposta)
Por que tudo isso faz isso? Bem, mais uma vez - a tarefa desta etapa é desenvolver um banco de dados de soluções, métodos e abordagens. Base de trabalho de combate. Para que, na próxima competição, você não perca tempo, mas diga imediatamente - sim, a codificação de destino média pode chegar e, a propósito, eu tenho o código correto para isso através das dobras nas dobras. Ou oh! Lembro que o conjunto passou por scipy.optimize e, a propósito, o código já está pronto para mim.
Algo assim ...
Vá para o modo de trabalho
Nesse modo, resolvemos várias competições. Cada vez que percebemos que há cada vez menos registros nas planilhas e mais e mais códigos nos módulos. Gradualmente, a tarefa de análise é reduzida ao fato de você apenas ler a descrição da solução, dizer sim, uau, ai está! E adicione um ou dois novos feitiços ou abordagens ao seu cofrinho.
Depois disso, o modo muda para o modo de tratamento de erros. A base está pronta para você, agora só precisa ser aplicada corretamente. Após cada competição, ao ler a descrição das soluções, veja o que você não fez, o que poderia ser feito melhor, o que você perdeu, ou onde você entrou, como eu fiz em Toxic . Ele andou muito bem, no ventre de ouro, e em privado voou 1.500 posições. É uma pena as lágrimas ... mas se acalmou, encontrou um erro, escreveu um post com folga - e aprendeu uma lição.
Um sinal da saída final para o modo operacional pode ser o fato de que uma das descrições da solução principal será escrita a partir do seu apelido.
O que deve estar aproximadamente nos pipelines até o final desta etapa:
- Todos os tipos de opções para pré-processamento e criação de recursos numéricos - projeções, relacionamentos,
- Vários métodos de trabalho com categorias - codificação de destino média na versão correta, frequência, rótulo / ohe,
- Vários esquemas de incorporação sobre texto (Glove, Word2Vec, Fasttext)
- Vários esquemas de vetorização de texto (Count, TF-IDF, Hash)
- Vários esquemas de validação (N * M para validação cruzada padrão, com base no tempo, por grupo)
- Otimização bayesiana / hiperopt / outra coisa para selecionar hiperparâmetros
- Aleatório / Permutação de alvo / Boruta / RFE - para selecionar recursos
- Modelos lineares - no mesmo estilo em um conjunto de dados
- LGB / XGB / Catboost - no mesmo estilo em um conjunto de dados
O autor criou metaclasses separadamente para modelos lineares e baseados em árvore, com uma única interface externa para nivelar as diferenças na API para diferentes modelos. Mas agora você pode executar em uma única linha uma linha, por exemplo, LGB ou XGB em um único conjunto de dados processados.
- Várias redes neurais para todas as ocasiões (não tiramos fotos por enquanto): incorporação / CNN / RNN para texto, RNN para sequências, Feed-Forward para todo o resto. É bom entender e poder codificar automaticamente .
- Conjunto baseado em lgb / regression / scipy - para tarefas de regressão e classificação
- É bom já poder algoritmos genéticos , às vezes eles vão bem
Resumir
Qualquer esporte, e o DS competitivo também é um esporte, é muito suor e muito trabalho. Isso não é bom nem ruim, é um fato. A participação em competições (se você abordar o processo corretamente) aprimora muito bem as habilidades técnicas, além de abalar mais ou menos o espírito esportivo quando você realmente não quer fazer algo, quebra tudo diretamente - mas você acessa seu laptop, refaz o modelo, inicia o cálculo, para que descobrir essa infeliz quinta casa decimal.
Então decida Kaggle - experiência na fazenda, medalhas e fãs!
Algumas palavras sobre os pipelines do autor
Nesta seção, tentarei descrever a idéia principal dos oleodutos e módulos coletados ao longo de um ano e meio. Novamente - essa abordagem não afirma ser universal ou única, mas de repente alguém vai ajudar.
- Todo o código de engenharia de recursos, exceto a codificação de destino médio, é retirado em um módulo separado na forma de funções. Tentei coletar objetos, acabou sendo complicado e, nesse caso, também não é necessário.
- Todos os recursos da engenharia de recursos são criados no mesmo estilo e possuem uma única chamada e assinatura de retorno:
def do_cat_dummy(data, attrs, prefix_sep='_ohe_', params=None): # do something return _data, new_attrs
Passamos o conjunto de dados, atributos para o trabalho, um prefixo para novos atributos e parâmetros adicionais para a entrada. Na saída, obtemos um novo conjunto de dados com novos atributos e uma lista desses atributos. Além disso, esse novo conjunto de dados é salvo em um pickle / feather separado.
O que isso dá é que temos a oportunidade de montar rapidamente um conjunto de dados para treinamento a partir de cubos pré-gerados. Por exemplo, para categorias, fazemos três processamento de uma só vez - Label Encoding / OHE / Frequency, salvamos em três penas separadas e, na fase de modelagem, simplesmente brincamos com esses blocos, criando vários conjuntos de dados de treinamento em um movimento elegante.
pickle_list = [ 'attrs_base', 'cat67_ohe', # 'cat67_freq', ] short_prefix = 'base_ohe' _attrs, use_columns, data = load_attrs_from_pickle(pickle_list) cat_columns = []
Se você precisar criar outro conjunto de dados, altere pickle_list , reinicie e trabalhe com o novo conjunto de dados.
O conjunto principal de funções sobre dados tabulares (real e categórico) inclui várias codificações de categorias, a projeção de atributos numéricos em categóricos, bem como várias transformações.
def do_cat_le(data, attrs, params=None, prefix='le_'): def do_cat_dummy(data, attrs, prefix_sep='_ohe_', params=None): def do_cat_cnt(data, attrs, params=None, prefix='cnt_'): def do_cat_fact(data, attrs, params=None, prefix='bin_'): def do_cat_comb(data, attrs_op, params=None, prefix='cat_'): def do_proj_num_2cat(data, attrs_op, params=None, prefix='prj_'):
Uma faca suíça universal para combinar atributos, na qual transferimos uma lista de atributos de origem e uma lista de funções de conversão. Na saída, obtemos, como sempre, um conjunto de dados e uma lista de novos atributos.
def do_iter_num(data, attrs_op, params=None, prefix='comb_'):
Além de vários conversores específicos adicionais.
Para processar dados de texto, é usado um módulo separado, que inclui vários métodos de pré-processamento, tokenização, lematização / stemming, tradução em uma tabela de frequências e assim por diante. etc. Tudo é padrão usando sklearn , nltk e keras .
As séries temporais também são processadas por um módulo separado, com funções para converter o conjunto de dados original para tarefas comuns (regressão / classificação) e sequência para sequência. Agradecemos a François Chollet por terminar keras para que a construção dos modelos seq-2-seq não se assemelhe a um ritual vodu de chamar demônios.
No mesmo módulo, a propósito, também existem funções da análise estatística usual de séries - verificação de estacionariedade, decomposição de STL, etc. ... Ajuda muito no estágio inicial da análise "sentir" a série e ver como ela é.
As funções que não podem ser aplicadas imediatamente a todo o conjunto de dados, mas precisam ser usadas dentro das dobras durante a validação cruzada, são colocadas em um módulo separado:
- Significado de codificação de destino
- Upsampling / downsampling
Eles são passados dentro da classe de modelo (leia sobre os modelos abaixo) na fase de treinamento.
_fpreproc = fpr_target_enc _fpreproc_params = fpr_target_enc_params _fpreproc_params.update(**{ 'use_columns' : cat_columns, })
- Para modelagem, foi criada uma metaclasse que generaliza o conceito de um modelo com métodos abstratos: fit / predizer / set_params / etc. Para cada biblioteca específica (LGB, XGB, Catboost, SKLearn, RGF, ...) é criada uma implementação dessa metaclasse.
Ou seja, para trabalhar com LGB, criamos um modelo
model_to_use = 'lgb' model = KudsonLGB(task='classification')
Para XGB:
model_to_use = 'xgb' metric_name= 'auc' task='classification' model = KudsonXGB(task=task, metric_name=metric_name)
E todas as funções ainda funcionam com o model .
Para validação, foram criadas várias funções que calculam imediatamente a previsão e o OOF para várias sementes durante a validação cruzada, bem como uma função separada para validação regular via train_test_split. Todas as funções de validação são operadas usando métodos de metamodelo, o que fornece um código independente de modelo e facilita a conexão com o pipeline de qualquer outra biblioteca.
res = cv_make_oof( model, model_params, fit_params, dataset_params, XX_train[use_columns], yy_train, XX_Kaggle[use_columns], folds, scorer=scorer, metric_name=metric_name, fpreproc=_fpreproc, fpreproc_params=_fpreproc_params, model_seed=model_seed, silence=True ) score = res['score'] XX_train [use_columns], yy_train, XX_Kaggle [use_columns], dobras, marcador = marcador, METRIC_NAME = METRIC_NAME, fpreproc = _fpreproc, fpreproc_params = _fpreproc_params, model_seed = model_seed, silêncio = True res = cv_make_oof( model, model_params, fit_params, dataset_params, XX_train[use_columns], yy_train, XX_Kaggle[use_columns], folds, scorer=scorer, metric_name=metric_name, fpreproc=_fpreproc, fpreproc_params=_fpreproc_params, model_seed=model_seed, silence=True ) score = res['score']
Para seleção de recursos - nada interessante, RFE padrão e minha permutação aleatória favorita de todas as maneiras possíveis.
Para pesquisar por hiperparâmetros, a otimização bayesiana é usada principalmente, novamente de forma unificada, para que você possa executar uma pesquisa por qualquer modelo (por meio do módulo de validação cruzada). Esta unidade vive no mesmo laptop que a simulação.
Várias funções foram feitas para conjuntos, unificadas para tarefas de regressão e classificação baseadas em Ridge / Logreg, LGB, rede Neural e meu scipy.optimize favorito.
Uma pequena explicação - cada modelo do pipeline fornece dois arquivos como resultado: sub_xxx e oof_xxx , que são a previsão para o teste e a previsão OOF para o trem. Em seguida, no módulo ensemble do diretório especificado, carregamos pares de previsões de todos os modelos em dois quadros de dados - df_sub / df_oof . Bem, então olhamos para as correlações, selecionamos as melhores e construímos modelos de nível 2 sobre df_oof e aplicamos ao df_sub .
Às vezes, para procurar o melhor subconjunto de modelos, a busca por algoritmos genéticos é boa (o autor usa essa biblioteca ), às vezes o método de Caruana . Nos casos mais simples, as regressões padrão e o scipy.optimize funcionam bem.
As redes neurais vivem em um módulo separado, o autor usa keras em um estilo funcional , sim, não tão flexível quanto o pytorch , mas o suficiente por enquanto. Novamente, são escritas funções de treinamento universal que são invariantes ao tipo de rede.
Esse pipeline foi novamente testado em uma recente competição da Home Credit , o uso cuidadoso e preciso de todos os blocos e módulos trouxe o 94º lugar e a prata.
O autor geralmente está pronto para expressar uma ideia sediciosa de que, para dados tabulares e um pipeline normalmente feito, o envio final para qualquer competição deve chegar ao ranking dos 100 melhores. Naturalmente, há exceções, mas, em geral, essa afirmação parece verdadeira.
Sobre o trabalho em equipe

Não é tão simples decidir Kaggle em equipe ou solo depende muito da pessoa (e da equipe), mas meu conselho para quem está começando é tentar iniciar um solo. Porque Vou tentar explicar meu ponto de vista:
- Primeiro, você entenderá seus pontos fortes, verá pontos fracos e, em geral, poderá avaliar seu potencial como uma prática de DS.
- Em segundo lugar, mesmo ao trabalhar em equipe (a menos que seja uma equipe estabelecida com separação de funções), eles ainda estarão esperando uma solução completa pronta para você - ou seja, você já deve ter pipelines de trabalho. (" Enviar ou não ") (C)
- E em terceiro lugar, é ideal quando o nível de jogadores na equipe é aproximadamente o mesmo (e bastante alto), para que você possa aprender algo realmente útil de alto nível) Em equipes fracas (não há nada depreciativo, estou falando sobre o nível de treinamento e experiência no Kaggle) é muito difícil aprender alguma coisa, é melhor morder o fórum e os kernels. Sim, você pode ganhar medalhas, mas veja os objetivos acima e um cinto para manter as calças)
Dicas úteis do capitão para obter provas e o cartão de rake prometido :)

Essas dicas refletem a experiência do autor, não são dogmas e podem (e devem) ser verificadas por nossos próprios experimentos
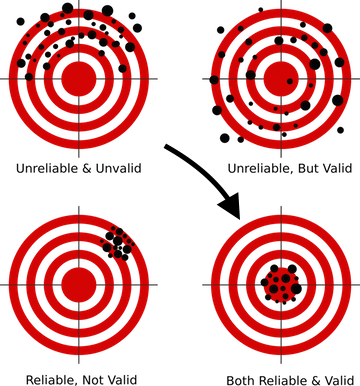
Sempre comece construindo uma validação competente - não haverá nenhuma; todos os outros esforços voarão para o forno. Olhe novamente para a tabela de classificação da Mercedes .
O autor está realmente satisfeito com o fato de que nesta competição ele construiu um esquema estável de validação cruzada (3x10 dobras), que manteve a velocidade e trouxe o legítimo 42º lugar
Se a validação competente for criada, sempre confie nos resultados da sua validação . Se a velocidade de seus modelos melhorar na validação, mas piorar em público - é mais razoável confiar nas validações. Ao analisar, basta ler os dados nos quais a classificação pública é considerada outra dobra. Você não deseja sobrecarregar seu modelo uma vez?
Se o modelo e o esquema permitir, sempre faça previsões de OOF e mantenha-as próximas ao modelo. Na fase do conjunto, você nunca sabe o que será acionado.
Sempre mantenha o código / OOF próximo ao resultado para recebê-lo . Não importa no github, localmente, em qualquer lugar. Duas vezes, verificou-se que, no conjunto, o melhor modelo foi o que foi feito há duas semanas fora da caixa e para o qual o código não foi salvo. Dor
Martelo na seleção do sid "certo" para validação cruzada , ele próprio pecou primeiro. Melhor escolha três e faça a validação cruzada 3xN. O resultado será mais estável e mais fácil.
Não persiga o número de modelos no conjunto - é melhor menos, mas mais diversificado - mais diversificado nos modelos, no pré-processamento, nos conjuntos de dados. No pior dos casos, de acordo com os parâmetros, por exemplo, uma árvore profunda com regularização rígida, outra rasa.
Use shuffle / boruta / RFE para selecionar recursos , lembre-se de que a importância do recurso em vários modelos baseados em árvores é uma métrica em papagaios em um saco de serragem.
Opinião pessoal do autor (pode não coincidir com a opinião do leitor) Otimização bayesiana > pesquisa aleatória> hiperoperação para seleção de hiperparâmetros. (">" == melhor)
O cabeçalho de rasgo estabelecido em um kernel público é melhor tratado da seguinte maneira:
- Há tempo - olhamos o que há de novo e construímos em nós mesmos
- Menos tempo - refaça-o para nossa validação, faça OOF - e prenda-o ao conjunto
- Não há tempo - misturamos-nos estupidamente com a nossa melhor solução e parecemos rápidos.
Como escolher duas submissões finais - por intuição, é claro. Mas, falando sério, geralmente todos praticam as seguintes abordagens:
- Submissão conservadora (em modelos sustentáveis) / submissão arriscada.
- Melhor no Ranking OOF / Público
Lembre-se - tudo é um dígito e as possibilidades de seu processamento dependem apenas da sua imaginação. Use classificação em vez de regressão, trate sequências como uma imagem etc.
E finalmente:
Links úteis

Geral
http://ods.ai/ - para quem deseja participar da melhor comunidade do DS :)
https://mlcourse.ai/ - site do curso ods.ai
https://www.Kaggle.com/general/68205 - publique sobre o curso no Kaggle
Em geral, eu recomendo que, no mesmo modo descrito no artigo, assista ao ciclo de vídeo de treinamentos - existem muitas abordagens e técnicas interessantes.
Vídeo
Cursos
Você pode aprender mais sobre os métodos e abordagens para resolver problemas no Kaggle a partir do segundo ano de especialização , " Como vencer um concurso de ciência de dados: aprenda com os melhores praticantes de kagglers"
Leitura extracurricular:
Conclusão

O tópico Ciência de Dados em geral e Ciência de Dados competitiva em particular é tão inesgotável quanto o átomo (C). Neste artigo, o autor revelou apenas um pouco o tópico de bombear habilidades práticas usando plataformas competitivas. Se ficou interessante - conecte-se, olhe em volta, acumule experiência - e escreva seus artigos. Quanto mais conteúdo bom, melhor para todos nós!
Antecipando as perguntas - não, os pipelines e as bibliotecas do autor ainda não foram disponibilizados gratuitamente.
Muito obrigado aos colegas do ods.ai: Vladimir Iglovikov (ternaus) , Yuri Kashnitsky (yorko) , Valery Babushkin ( venheads) , Alexei Pronkin (pronkin_alexey) , Dmitry Petrov (dmitry_petrov) , Arthur Kuzin (n01z3) e também todo mundo que lê você artigo antes da publicação, para edições e resenhas.
Agradecimentos especiais a Nikita Zavgorodnoy (njz) pela revisão final.
Agradecemos sua atenção. Espero que este artigo seja útil para alguém.
Meu apelido em Kaggle / ods.ai : kruegger