Entre as redes sociais, o Twitter é mais adequado do que outros para a extração de dados de texto devido à restrição estrita do tamanho da mensagem na qual os usuários são forçados a colocar tudo o que é mais essencial.
Sugiro adivinhar que tecnologia essa palavra nuvem enquadra?
Usando a API do Twitter, você pode extrair e analisar uma grande variedade de informações. Um artigo sobre como fazer isso com a linguagem de programação R.
Escrever o código não leva muito tempo, podem surgir dificuldades devido a alterações e restrições da API do Twitter, aparentemente a empresa estava seriamente preocupada com questões de segurança depois de ter sido arrastada para fora no Congresso dos EUA após a investigação da influência de "hackers russos" nas eleições dos EUA em 2016.
API de acesso
Por que alguém precisaria recuperar dados industriais do Twitter? Bem, por exemplo, ajuda a fazer previsões mais precisas sobre o resultado de eventos esportivos. Mas tenho certeza de que existem outros cenários de usuário.
Para começar, é claro que você precisa ter uma conta no Twitter com um número de telefone. Isso é necessário para criar o aplicativo, é esta etapa que dá acesso à API.
Vamos para a página do desenvolvedor e clique no botão Criar um aplicativo . A seguir, é apresentada a página na qual você precisa preencher as informações sobre o aplicativo. Atualmente, a página consiste nos seguintes campos.
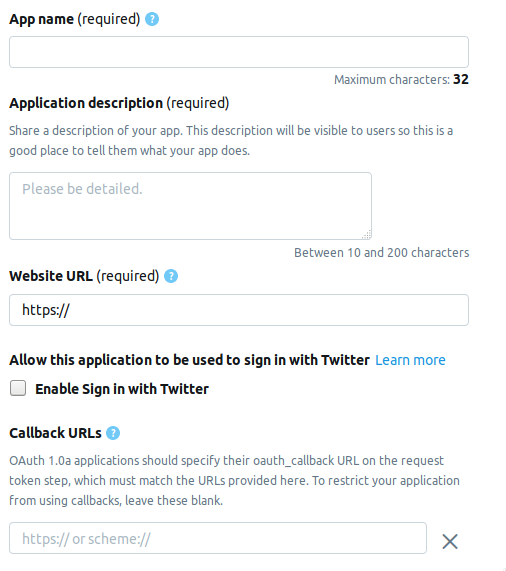
- AppName - nome do aplicativo (obrigatório).
- Descrição do aplicativo - descrição do aplicativo (obrigatório).
- URL do site - página do site do aplicativo (obrigatório), você pode inserir qualquer coisa que se pareça com um URL.
- Ativar login no Twitter (caixa de seleção) - O login na página do aplicativo no Twitter pode ser omitido.
- URLs de retorno de chamada - o retorno de chamada do aplicativo durante a autenticação (obrigatório) e necessário , você pode deixar
http://127.0.0.1:1410 .
Os campos a seguir são opcionais: o endereço da página para os termos de serviço, o nome da organização etc.
Ao criar uma conta de desenvolvedor, escolha uma das três opções possíveis.
- Padrão - A versão básica, você pode procurar registros até uma profundidade de ≤ 7 dias, gratuitamente.
- Premium - Uma opção mais avançada, você pode procurar registros com profundidade ≤ 30 dias e desde 2006. Grátis, mas eles não são exibidos imediatamente ao considerar um aplicativo.
- Empresa - Classe executiva, tarifa paga e confiável.
Eu escolhi o Premium , demorou cerca de uma semana para aguardar a aprovação. Não posso dizer a todos se eles fazem isso em sequência, mas vale a pena tentar de qualquer maneira, e o Standard não vai a lugar nenhum.
Conexão com o Twitter
Depois de criar o aplicativo, um conjunto contendo os seguintes elementos aparecerá na guia Chaves e tokens . Abaixo estão os nomes e variáveis correspondentes de R.
Chaves da API do consumidor
- Chave da API -
api_key - Chave secreta da API -
api_secret
Acessar token e acessar token secret
- Token de acesso -
access_token - Segredo do token de acesso -
access_token_secret
Instale os pacotes necessários.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
Este trecho de código ficará assim.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
Após a autenticação, o R solicitará que você salve os códigos OAuth no disco para uso posterior.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
Ambas as opções são aceitáveis, eu escolhi o primeiro.
Pesquisar e filtrar resultados
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
A tecla include_rts permite controlar se os retweets são incluídos ou excluídos da pesquisa. Na saída, obtemos uma tabela com muitos campos nos quais há detalhes e detalhes de cada registro. Aqui estão os 20 primeiros.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
Você pode compor uma sequência de pesquisa mais complexa.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
Os resultados da pesquisa podem ser salvos em um arquivo de texto.
write.table(tweets$text, file="datamine.txt")
Nos fundimos no corpo dos textos, filtramos as palavras de serviço, os sinais de pontuação e traduzimos tudo para minúsculas.
Há outra função de pesquisa - searchTwitter , que requer a biblioteca twitteR . De certa forma, é mais conveniente do que os search_tweets , mas de certa forma inferior a ele.
Plus - a presença de um filtro por tempo.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
Menos - a saída não é uma tabela, mas um objeto do tipo status . Para usá-lo em nosso exemplo, precisamos extrair um campo de texto da saída. Isso faz sapply na segunda linha.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
Na segunda linha, a função tm_map necessária para converter todos os tipos de caracteres emoji para minúsculas, caso contrário, a conversão para minúsculas usando tolower falhará.
Construindo uma nuvem de palavras
As nuvens de palavras apareceram pela primeira vez na hospedagem de fotos do Flickr , até onde eu sei, e desde então ganharam popularidade. Para esta tarefa, precisamos da biblioteca wordcloud .
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
A função search_string permite definir o idioma como parâmetro.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
No entanto, devido ao fato de o pacote NLP para R ser pouco russificado, em particular, não há uma lista de serviço ou palavras de parada, não consegui criar uma nuvem de palavras com uma pesquisa em russo. Ficarei feliz se você encontrar uma solução melhor nos comentários.
Bem, na verdade ...
script inteiro library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Materiais usados.
Links curtos:
Links originais:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS Dica, a palavra-chave nuvem no KDPV não é usada no programa, está associada ao meu artigo anterior .