Verificar um servidor não é um problema. Você pega a lista de verificação e faz a ordem: processador, memória, discos. Mas com cem servidores, é improvável que esse método funcione bem. Para excluir o fator humano, para tornar as verificações mais confiáveis e rápidas, é necessário automatizar o processo. Quem precisa saber como fazer isso melhor do que um provedor de hospedagem? Artyom Artemyev, no HighLoad ++ Siberia, disse que métodos podem ser usados, o que é melhor executar com as mãos e o que funciona bem para automatizar. A seguir, é apresentada uma versão em texto do relatório com dicas que podem ser repetidas por quem trabalha com ferro e precisa verificar regularmente seu desempenho.
 Sobre o palestrante:
Sobre o palestrante: Artyom Artemyev (
artemirk ), diretor técnico de um grande provedor de hospedagem FirstVDS, trabalha com ferro.
O FirstVDS possui dois data centers. A primeira é a deles, eles construíram seu próprio prédio, trouxeram e instalaram seus racks, eles mesmos mantêm, se preocupam com a corrente e o resfriamento do data center. O segundo data center é uma sala grande em um grande data center alugado, tudo fica mais fácil com ele, mas também existe. No total, são 60 racks e cerca de 3000 servidores de ferro. Havia algo para treinar e testar diferentes abordagens, o que significa que estamos aguardando recomendações praticamente confirmadas. Vamos começar a visualizar ou ler o relatório.
Há cerca de 6 a 7 anos, percebemos que simplesmente colocar o sistema operacional no servidor não é suficiente. O sistema operacional está ativado, o servidor está acordado e pronto para a batalha. Nós o lançamos em produção - reinicializações e congelamentos incompreensíveis começam. O que fazer, não está claro - o processo está em andamento, transferir todo o calado de trabalho para um novo pedaço de metal é difícil, caro e doloroso. Para onde correr?
Os métodos modernos de implantação nos permitem evitar isso e transportar o servidor em 5 segundos, mas nossos clientes (especialmente há 6 anos) simplesmente não voavam nas nuvens, caminhavam no chão e usavam peças comuns de ferro.

Neste artigo, mostrarei quais métodos tentamos, quais criamos raiz, quais não criaram raiz, quais são bons para executar com as mãos e como automatizar tudo isso. Vou dar um conselho e você pode repeti-lo em sua empresa se trabalhar com ferro e tiver essa necessidade.
Qual é o problema?
Em teoria, verificar o servidor não é um problema. Inicialmente, tivemos um processo, como na figura abaixo. Um homem se senta, faz uma lista de verificação, verifica: processador, memória, discos, enruga a testa, toma uma decisão.
Em seguida, 3 servidores foram instalados por mês. Mas, quando há mais e mais servidores, essa pessoa começa a chorar e reclamar que está morrendo no trabalho. Uma pessoa está cada vez mais enganada, porque a verificação se tornou uma rotina.
Tomamos uma decisão: automatizamos! Uma pessoa fará coisas mais úteis.
Excursão curta
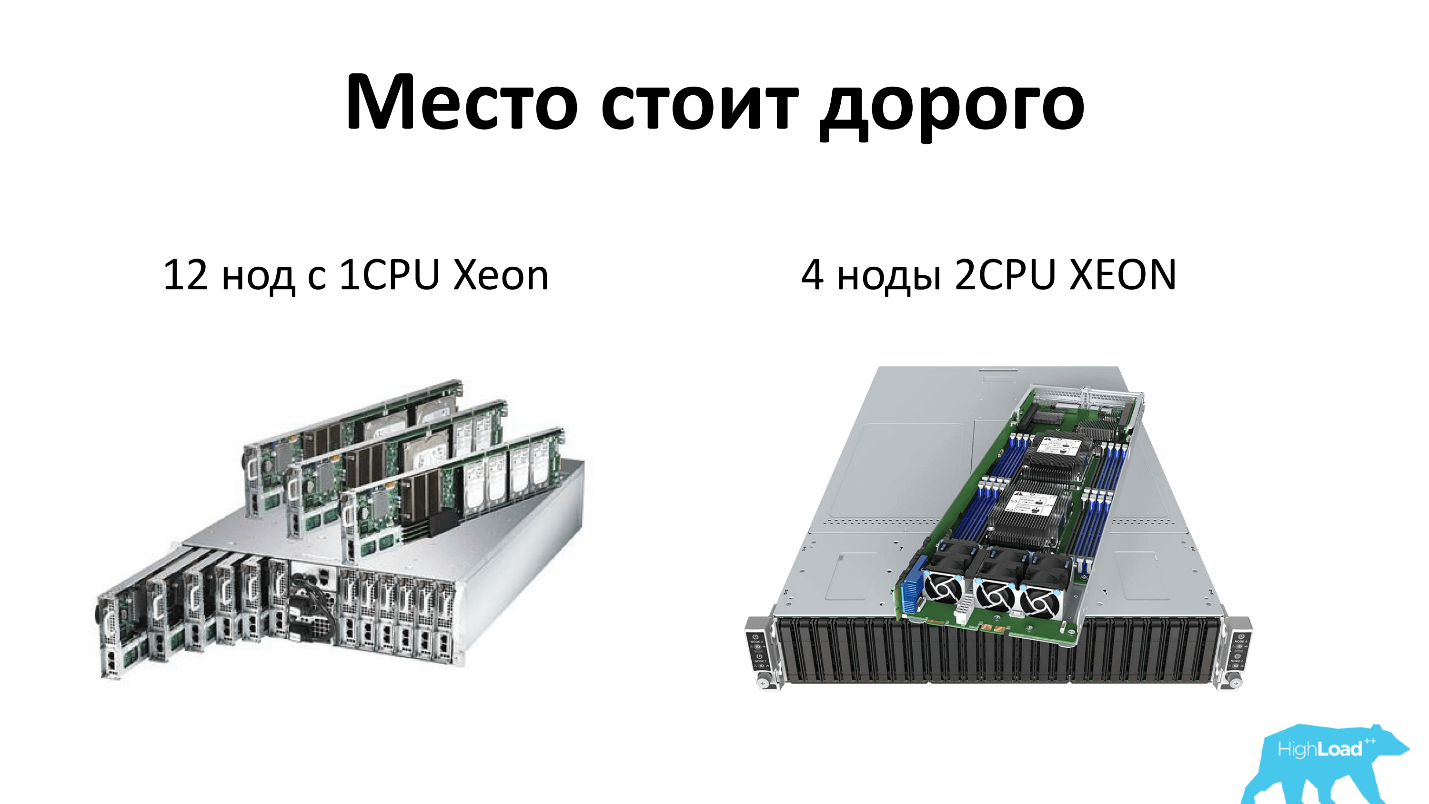
Esclarecerei o que quero dizer quando falo sobre o servidor hoje. Nós, como todo mundo, economizamos espaço em rack e usamos servidores de alta densidade. Hoje, são 2 unidades, que podem acomodar 12 nós de servidores de processador único ou 4 nós de servidores de processador duplo. Ou seja, cada servidor recebe 4 discos - tudo honestamente. Além disso, existem duas fontes de alimentação no rack, ou seja, tudo é redundante e todo mundo gosta.
De onde é o ferro?
O ferro é trazido para o nosso centro de dados pelos nossos fornecedores - geralmente Supermicro e Intel. No datacenter, nossos operadores instalam servidores em um espaço vazio no rack e conectam duas conexões, uma rede e energia. Também é responsabilidade dos operadores configurar o BIOS no servidor. Ou seja, conecte o teclado, monitore e configure dois parâmetros:
Restore on AC/Power Loss — [Power On] , para que o servidor sempre ligue assim que a energia aparecer. Deve funcionar sem parar. O segundo
First boot device — [PXE] , ou seja, colocamos o primeiro dispositivo de rede na rede, caso contrário não conseguiremos acessar o servidor, pois não é fato que ele tenha discos imediatamente etc.

Depois disso, o operador abre o painel contábil dos servidores iron, no qual você precisa registrar o fato de instalar o servidor, para o qual é indicado:
- rack;
- adesivo
- portas de rede
- portas de energia
- número da unidade.
Depois disso, a porta de rede em que o operador instalou o novo servidor, por motivos de segurança, vai para uma VLAN de quarentena especial, que também trava DHCP, Pxe, TFtp. Em seguida, o servidor carrega o nosso Linux favorito, que possui todos os utilitários necessários, e o processo de diagnóstico é iniciado.
Como o servidor ainda possui o primeiro dispositivo de inicialização na rede, para servidores que entram em produção, a porta muda para outra VLAN. Não há DHCP em outra VLAN e não temos medo de reinstalar acidentalmente nosso servidor de produção. Para isso, temos uma VLAN separada.
Acontece que o servidor foi instalado, está tudo bem, mas não inicializou no sistema de diagnóstico. Isso acontece, em regra, devido ao fato de que, com um atraso na troca de VLANs, nem todos os comutadores de rede trocam rapidamente VLANs, etc.

Em seguida, o operador recebe a tarefa de reiniciar o servidor com as mãos. Anteriormente, não havia IPMI, configuramos soquetes remotos e fixamos em que porta os soquetes do servidor, puxamos o soquete pela rede e o servidor foi reinicializado.
Mas as tomadas gerenciadas também nem sempre funcionam bem, por isso agora gerenciamos a energia do servidor sobre IPMI. Mas quando o servidor é novo, o IPMI não está configurado, ele pode ser reinicializado apenas subindo e pressionando o botão. Portanto, um homem senta, espera - a luz se acende - corre e pressiona o botão. Esse é o trabalho dele.
Se depois disso o servidor não inicializar, ele será inserido em uma lista especial para reparo. Esta lista inclui servidores nos quais o diagnóstico não foi iniciado ou seus resultados não foram satisfatórios. Uma pessoa individual - que adora ferro - senta e desmonta todos os dias - coleta, olha, por que não funciona.
CPU
Está tudo bem, o servidor foi iniciado, estamos começando a testar. Primeiro, testamos o processador como um dos elementos mais importantes.

O primeiro impulso foi usar o aplicativo do fornecedor. Temos quase todos os processadores Intel - eles foram ao site, baixaram a Ferramenta de diagnóstico do processador Intel - está tudo bem, mostra muitas informações interessantes, incluindo o horário de funcionamento do servidor em horas e o gráfico do consumo de energia.
Mas o problema é que o Intel PTD funciona no Windows, do qual não gostamos mais. Para iniciar um teste, basta mover o mouse, pressionar o botão "INICIAR" e o teste começará. O resultado é exibido na tela, mas não há como exportá-lo para qualquer lugar. Isso não nos convém, porque o processo não é automatizado.

Fomos ler os fóruns e descobrimos as duas maneiras mais fáceis.
- O laço eterno cat / dev / zero> / dev / null . Você pode verificar no topo - 100% de um núcleo é consumido. Contamos o número de núcleos, executamos o número necessário de cat / dev / zero, multiplicado pelo número desejado de núcleos. Tudo funciona muito bem!
- Utilitário / compartimento / estresse . Ela constrói matrizes na memória e começa a entregá-las constantemente. Está tudo bem também - o processador está aquecendo, há uma carga.
Damos os servidores em produção, os usuários voltam e dizem que o processador é instável. Verificado - o processador está instável. Eles começaram a investigar, pegaram um servidor que passou nas verificações, mas ele travou em uma batalha, ativou o kernel de depuração no Linux e coletou o Core dump. O servidor antes da reinicialização libera para o arquivo tudo o que estava na memória antes da falha.

Várias otimizações são incorporadas aos processadores para operações frequentes. Podemos ver sinalizadores refletindo quais otimizações o processador suporta, por exemplo, otimizações para trabalhar com números de ponto flutuante, otimizações de multimídia etc. Mas nosso / bin / stress e o ciclo eterno apenas queimam o processador em uma operação e não usam recursos adicionais. A investigação mostrou que a CPU falha ao tentar usar a funcionalidade de um dos sinalizadores internos.
O primeiro impulso foi deixar / bin / stress - deixar o processador aquecer. Então, em um ciclo, percorremos todas as bandeiras e as puxamos. Enquanto pensamos em como implementar isso, quais comandos chamar para chamar as funções de cada sinalizador, lemos os fóruns.
No fórum de overclockers, deparamos com um projeto interessante para procurar números primos
Great Internet Mersenne Prime Search . Os cientistas criaram uma rede distribuída à qual qualquer pessoa pode se conectar e ajudar a encontrar um número primo. Os cientistas não acreditam em ninguém, então o programa funciona de maneira inteligente: primeiro você o executa, calcula os números primos que já conhece e compara o resultado com o que sabe. Se o resultado não corresponder, o processador está com defeito. Nós realmente gostamos desta propriedade: com qualquer absurdo, é provável que caia.
Além disso, o objetivo do projeto é encontrar o maior número possível de números primos; portanto, o programa é constantemente otimizado para as propriedades dos novos processadores, resultando em muitas bandeiras.
Mprime não tem limite de tempo; se não for parado, funciona para sempre. Executamos por 30 minutos.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
Após concluir o trabalho, verificamos se não há erros em result.txt e observamos os logs do kernel, em particular no arquivo / proc / kmsg, que procuramos por erros.
Outra excursão

Em 3 de janeiro de 2018, eles encontraram o 50º número primo de Mersenne (2
p -1). Desse número, apenas 23 milhões de dígitos. Você pode baixá-lo para visualizá-lo -
este é
um arquivo zip de 12 Mb .
Por que precisamos de números primos? Primeiro, qualquer criptografia RSA usa números primos. Quanto mais primos soubermos, mais confiável será sua chave SSH. Em segundo lugar, os cientistas testam suas hipóteses e teoremas matemáticos, e não nos importamos em ajudar os cientistas - não nos custa nada. Acontece que a história ganha-ganha.

Então, o processador está funcionando, está tudo bem. Resta descobrir que tipo de processador é esse. Usamos o processador dmidecode -t e vemos todos os slots que estão na placa-mãe e quais processadores estão nesses slots. Esta informação entra no nosso sistema contábil, nós a interpretaremos mais tarde.
Catch
Assim, surpreendentemente, pernas quebradas podem ser encontradas. / bin / stress e o ciclo perpétuo funcionaram, e o Mprime caiu. Eles dirigiram por um longo tempo, procuraram, descobriram - o resultado na imagem abaixo - tudo está claro aqui.

Esse processador simplesmente não foi iniciado. O operador era muito forte, pegou o processador errado - mas conseguiu entregar.

Outro caso bonito. A linha preta na foto abaixo é a ventoinha, a seta mostra como o ar sopra. Vemos: o radiador fica do outro lado da corrente. Claro, tudo superaqueceu e desligou.

A memória
Com a memória, tudo é bem simples. São células nas quais escrevemos informações e depois de um tempo as lemos novamente. Se permanecer o mesmo que anotamos, essa célula estará funcionando.

Todo mundo conhece o bom programa
Memtest86 + , diretamente clássico, que é executado a partir de qualquer mídia, pela rede ou até mesmo de um disquete. É feito para verificar o maior número possível de células de memória. Qualquer célula ocupada não pode mais ser verificada. Portanto, o memtest86 + tem um tamanho mínimo para não ocupar memória. Infelizmente, o
memtest86 + exibe apenas suas estatísticas na tela . Tentamos expandi-lo de alguma forma, mas tudo se resumiu ao fato de que dentro do programa não havia nem mesmo uma pilha de rede. Para expandi-lo, seria necessário trazer o kernel do Linux e tudo mais.
Existe uma versão paga deste programa que já sabe como soltar informações no disco. Mas nossos servidores nem sempre têm um disco e nem sempre existe um sistema de arquivos nesses discos. Mas a unidade de rede, como já descobrimos, não pode ser conectada.
Começamos a cavar ainda mais e encontramos um programa similar do
Memtester . Este programa funciona no nível do SO do Linux. O maior ponto negativo é que o sistema operacional e o Memtester ocupam algumas células de memória e essas células não serão verificadas.
O Memtester é iniciado com o comando: memtester `cat / proc / meminfo | grep MemFree | awk '{print $ 2-1024}' 'k 5
Aqui, transferimos a quantidade de memória livre menos 1 MB. Isso é feito porque, caso contrário, o Memtester ocupa toda a memória e o assassino mata-a. Realizamos este teste por 5 ciclos, na saída temos uma placa com OK ou com falha.
| Endereço bloqueado | ok |
| Valor aleatório | ok |
| Compare o XOR | ok |
| Comparar SUB | ok |
| Comparar MUL | ok |
| Compare DIV | ok |
| Compare OU | ok |
| Compare E | ok |
Salvamos o resultado final e analisamos mais as falhas.

Para entender a extensão do problema - nosso menor servidor possui 32 GB de memória, nossa imagem do Linux com Memtester ocupa 60 MB,
não verificamos 2% da memória . Mas, de acordo com as estatísticas dos últimos 6 anos, não houve tal coisa que a memória francamente batida entrou em produção. Este é o compromisso com o qual concordamos, e que é caro para nós consertar, e vivemos com ele.
Ao longo do caminho, também coletamos a memória dmidecode -t, que fornece todos os bancos de memória que temos na placa-mãe (geralmente até 24 peças) e quais dados estão em cada banco. Esta informação é útil se quisermos atualizar o servidor - saberemos onde adicionar o quê, quantas tiras levar e para qual servidor ir.
Dispositivos de armazenamento
Há 6 anos, todos os discos estavam com panquecas que giravam. Uma história separada era reunir apenas uma lista de todos os discos. Havia várias abordagens diferentes, pois não se acreditava que você pudesse apenas olhar ls / dev / sd. Mas no final, paramos de olhar para ls / dev / sd * e ls / dev / cciss / c0d *. No primeiro caso, é um dispositivo SATA, no segundo - SCSI e SAS.

Literalmente este ano, eles começaram a vender discos nvme e adicionaram a lista nvme aqui.
Depois que a lista de discos é compilada, tentamos ler 0 bytes para entender que este é um dispositivo de bloco e está tudo bem. Se você não conseguiu ler, acreditamos que isso é algum tipo de fantasma, e não temos e nunca tivemos esse disco.
A primeira abordagem para verificar discos foi a óbvia: “Vamos gravar dados aleatórios no disco e ver a velocidade” -
dd -o nocache -o direct if=/dev/urandom of=${disk} . Como regra, os discos de panqueca fornecem 130-150 Mb / s. Apertamos os olhos e decidimos por nós mesmos que 90 MB / s é a figura após a qual existem discos que podem ser reparados, e todos os menores são defeituosos.
Mas, novamente, os usuários começaram a retornar e dizer que as unidades são ruins. Aconteceu que a física insidiosa estava brincando conosco novamente.
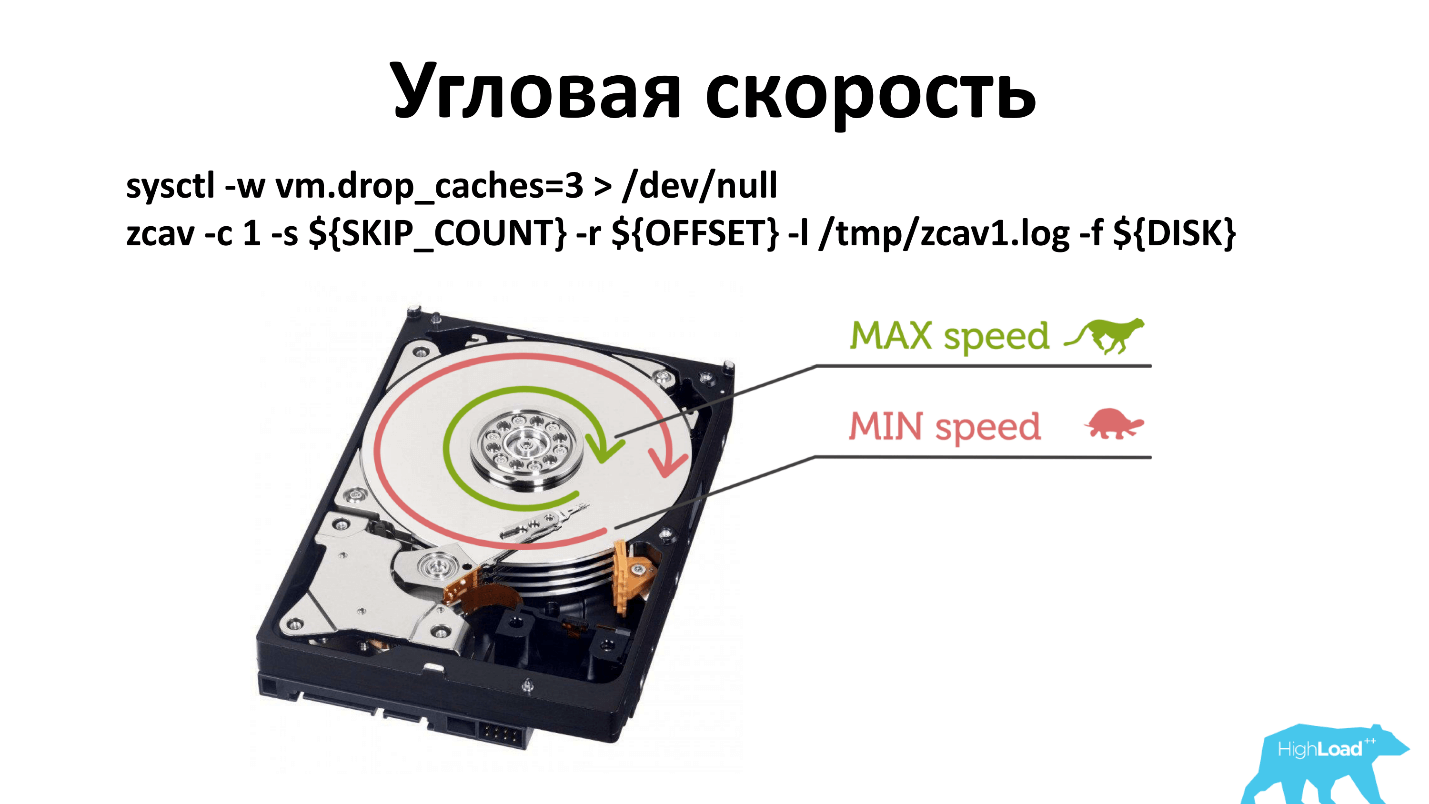
Existe velocidade angular e, como regra, quando você executa -dd, ele grava próximo ao eixo. Se, por algum motivo, a velocidade do eixo diminuiu, isso será menos perceptível do que se você escrever da borda do disco.
Eu tive que mudar o princípio da verificação. Agora, verificamos três locais: perto do eixo, no meio e fora. Provavelmente, só pode ser verificado de fora, mas é assim que historicamente aconteceu. E o que funciona, não toque.
Você pode usar o
smartctl para perguntar ao disco como está. Acreditamos que uma boa unidade:
- Não há setores realocados ( contagem de setores realocados = 0) , ou seja, todos os setores que deixaram o trabalho de fábrica.
- Não usamos discos com mais de 4 anos , embora estejam funcionando bem. Antes de introduzirmos essa prática, tínhamos discos por 7 anos. Agora acreditamos que, após 4 anos, o disco valeu a pena e não estamos prontos para aceitar o risco de desgaste.
- Não há setores que serão realocados ( Current_Pending_Sector = 0 ).
- Contagem de erros do UltraDMA CRC = 0 - são erros no cabo SATA. Se houver um erro, você só precisa trocar o fio, não precisa trocar o disco.

Os SSDs distribuídos geralmente são unidades excelentes, funcionam rapidamente, não fazem barulho, não esquentam. Acreditamos que um bom SSD tem uma velocidade de gravação superior a 200 MB / s. Nossos clientes adoram preços baixos, e os modelos de servidor que emitem 320-350 MB / s nem sempre chegam até nós.
Para SSDs, também procuramos smartctl. O mesmo Realocado, Power_On_Hours, Current_Pending_Sector. Todos os SSDs podem exibir o grau de desgaste, mostra o parâmetro Media_Wearout_Indicator. Limpamos os discos até 5% da vida útil e só então os tiramos. Esses discos às vezes encontram uma segunda vida nas necessidades pessoais dos funcionários. Por exemplo, descobri recentemente que em 2 anos esse disco se desgastou em mais 1% no laptop de um funcionário, embora em nosso país o cache do SSD se esgote em 95% em cerca de 10 meses.
Mas o problema é que nem todos os fabricantes de disco concordaram com os nomes dos parâmetros, e este Media_Wearout_Indicator, por exemplo, é chamado Percent_Lifetime_Used para Toshiba, outra contagem de nível de desgaste, porcentagem de tempo restante para outros fabricantes ou simplesmente.
Crucial não tem essa opção. Depois, consideramos a quantidade de reescritas do disco - “byte writed” - quantos bytes já gravamos nesse disco. Além disso, de acordo com a especificação, estamos tentando descobrir quantas reescritas esse disco é calculado pelo fabricante. Pela matemática elementar, determinamos quanto mais ele viverá. Se é hora de mudar - mude.
RAID
Não sei por que, no mundo moderno, nossos clientes ainda querem RAIDs. As pessoas compram RAID, colocam 4 SSDs lá, que são muito mais rápidos que este RAID (6 Gb). Eles têm algum tipo de instrução e a coletam. Eu acho que isso é uma coisa quase desnecessária.
Havia 3 fabricantes: Adaptec; 3ware; Intel Tínhamos 3 utilitários, nos preocupamos, mas executamos diagnósticos para todos. Agora, a LSI comprou a todos - resta apenas um utilitário.
Quando nosso sistema de diagnóstico vê o RAID, ele analisa o volume lógico em discos separados, para que você possa medir a velocidade de cada disco e ler seu Smart. Depois disso, resta ao RAID verificar a bateria. Quem não sabe - há baterias suficientes no RAID para girar todos os discos por mais 2 horas. Ou seja, você desliga o servidor, retira-o e ele gira o disco por mais 2 horas para concluir todas as gravações.
Rede
Com a rede, tudo é bem simples - deve haver menos de 300 Mbit dentro do data center. Se menos, você precisa corrigi-lo. Também analisamos os erros na interface.
Os erros na interface de rede não devem ser , e se forem, tudo está ruim.
Estamos tentando atualizar o firmware do BIOS e IPMI ao longo do caminho. Aconteceu que não gostamos de todos os BIOS. Ainda temos BIOS que não sabem como UEFI e outros recursos que usamos. Tentamos atualizá-lo automaticamente, mas isso nem sempre funciona, nem tudo é muito simples lá. Se não funcionar, a pessoa vai e atualiza com as mãos.
Nós não fornecemos o IPMI Supermicro para o mundo, temos em endereços cinza através do OpenVPN. No entanto, temos medo de que um dia outra vulnerabilidade apareça e sofreremos. Portanto, tentamos manter o firmware IPMI sempre o último. Caso contrário, atualize.
De uma coisa estranha, descobriu-se recentemente que a Intel em placas de rede de 10 e 40 gigabit não inclui inicialização PXE. Acontece que, se o servidor estiver em um rack no qual há apenas uma placa de 40 gigabit, é impossível inicializar pela rede, porque você precisa inicializar em uma placa de gigabit. Flash separadamente as placas de rede em 40G para que elas tenham PXE e possam continuar funcionando.
Depois que tudo é verificado, o servidor entra imediatamente à venda . Seu preço é calculado, no qual é colocado no site e vendido.

No total, realizamos aproximadamente 350 verificações por mês, 69% dos servidores podem ser reparados, 31% não podem ser reparados. Isso se deve ao fato de termos uma história rica, alguns servidores permanecem em pé há 10 anos. A maioria dos servidores que não passaram no teste, apenas jogamos.
Para os curiosos: temos 3 clientes que ainda vivem no Pentium IV e não querem sair de lugar nenhum. Eles têm 512 MB de RAM.
O futuro chegou! Se eu cercasse esse sistema hoje ...

Um utilitário maravilhoso, o
Hardware Lister (lshw), foi lançado, o qual pode se comunicar com o kernel, exibindo lindamente que tipo de hardware existe no kernel, o que o kernel pode detectar. Nem todas essas danças são necessárias. Se você repetir - eu recomendo fortemente que você olhe para este utilitário e use-o. Tudo se tornará muito mais simples.
Resumo:
- O compromisso não é ruim, é apenas uma questão de preço. Se a solução for muito cara, é necessário procurar um nível em que a confiabilidade e o preço sejam aceitáveis.
- Às vezes, programas não essenciais são interessantes para testes. Resta apenas encontrá-los.
- Teste tudo o que você alcança!
O próximo grande HighLoad ++ já está nos dias 8 e 9 de novembro em Moscou. O programa inclui especialistas famosos e novos nomes, tarefas tradicionais e novas. Na seção DevOps, por exemplo, o seguinte já é aceito:
Estude a lista de relatórios e corra para participar. Ou assine nossa newsletter e você receberá análises regulares de relatórios, relatórios de novos artigos e vídeos.