 Um passo a passo completo do aprendizado de máquina em Python: parte três
Um passo a passo completo do aprendizado de máquina em Python: parte trêsMuitas pessoas não gostam que os modelos de aprendizado de máquina sejam
caixas pretas : colocamos dados neles e obtemos respostas sem nenhuma explicação - geralmente respostas muito precisas. Neste artigo, tentaremos descobrir como o modelo que criamos faz previsões e o que ele pode dizer sobre o problema que estamos resolvendo. E concluímos com uma discussão da parte mais importante do projeto de aprendizado de máquina: documentamos o que fizemos e apresentamos os resultados.
Na
primeira parte, examinamos a limpeza de dados, análise exploratória, design e seleção de recursos. Na
segunda parte, estudamos o preenchimento de dados ausentes, a implementação e comparação de modelos de aprendizado de máquina, o ajuste hiperparamétrico usando pesquisa aleatória com validação cruzada e, finalmente, a avaliação do modelo resultante.
Todo o
código do projeto está no GitHub. E o terceiro Caderno Jupyter relacionado a este artigo está
aqui . Você pode usá-lo para seus projetos!
Portanto, estamos trabalhando em uma solução para o problema usando aprendizado de máquina, ou melhor, usando regressão supervisionada. Com base nos
dados de energia de edifícios em Nova York, criamos um modelo que prevê o Energy Star Score. Obtivemos o modelo de “
regressão baseada em aumento de gradiente ”, capaz de prever dentro do intervalo de 9,1 pontos (no intervalo de 1 a 100) com base em dados de teste.
Interpretação do modelo
A regressão de aumento de gradiente está localizada aproximadamente no meio da
escala de interpretabilidade do modelo : o modelo em si é complexo, mas consiste em centenas de
árvores de decisão bastante simples. Existem três maneiras de entender como nosso modelo funciona:
- Avalie a importância dos sintomas .
- Visualize uma das árvores de decisão.
- Aplique o método LIME - Explicações Independentes do Modelo Interpretável Local , explicações independentes do modelo interpretadas localmente.
Os dois primeiros métodos são característicos dos conjuntos de árvores e o terceiro, como você pode entender pelo nome, pode ser aplicado a qualquer modelo de aprendizado de máquina. LIME é uma abordagem relativamente nova, é um avanço significativo na tentativa de
explicar o funcionamento do aprendizado de máquina .
A importância dos sintomas
A importância dos sinais permite que você veja a relação de cada sinal com o objetivo de prever. Os detalhes técnicos deste método são complexos (a média da diminuição da impureza ou a
diminuição do erro devido à inclusão de uma característica é medida ), mas podemos usar valores relativos para entender quais características são mais relevantes. No Scikit-Learn, você pode
extrair a importância dos atributos de qualquer conjunto "aluno" baseado em árvore.
No código abaixo,
model é nosso modelo treinado e, usando
model.feature_importances_ é possível determinar a importância dos atributos. Em seguida, enviamos para o quadro de dados do Pandas e exibimos os 10 atributos mais importantes:
import pandas as pd
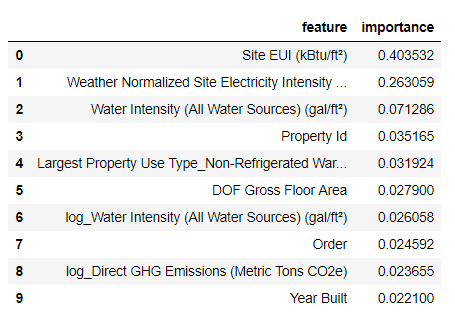
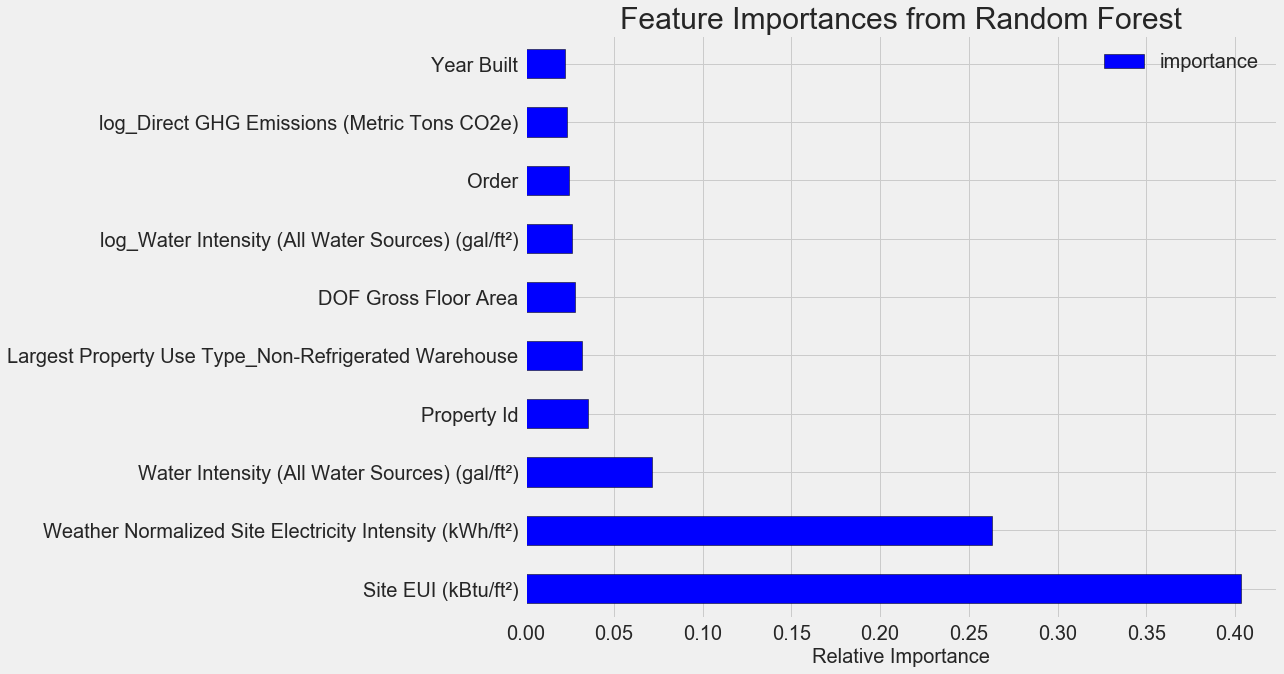
Os recursos mais importantes são o
Site EUI (
Intensidade de consumo de energia ) e
Weather Normalized Site Electricity Intensity , representando mais de 66% da importância total. Já no terceiro recurso, a importância cai drasticamente, isso
sugere que não precisamos usar todos os 64 recursos para obter alta precisão de previsão (no
notebook Jupyter, essa teoria é testada usando apenas os 10 recursos mais importantes e o modelo não é muito preciso).
Com base nesses resultados, uma das perguntas iniciais pode finalmente ser respondida: os indicadores mais importantes do Energy Star Score são o EUI do local e a intensidade de eletricidade normalizada no local do tempo. Não vamos nos
aprofundar muito na importância dos atributos , apenas dizeremos que com eles você pode começar a entender o mecanismo de previsão pelo modelo.
Visualização de uma única árvore de decisão
É difícil compreender todo o modelo de regressão com base no aumento do gradiente, o que não pode ser dito sobre as árvores de decisão individuais. Você pode visualizar qualquer árvore usando a
Scikit-Learn- export_graphviz . Primeiro, extraia a árvore do conjunto e salve-a como um arquivo de ponto:
from sklearn import tree
Usando o
visualizador Graphviz, converta o arquivo de ponto em png, digitando:
dot -Tpng images/tree.dot -o images/tree.pngTem uma árvore de decisão completa:

Um pouco pesado! Embora essa árvore tenha apenas 6 camadas de profundidade, é difícil rastrear todas as transições. Vamos alterar a
export_graphviz função
export_graphviz e limitar a profundidade da árvore em duas camadas:
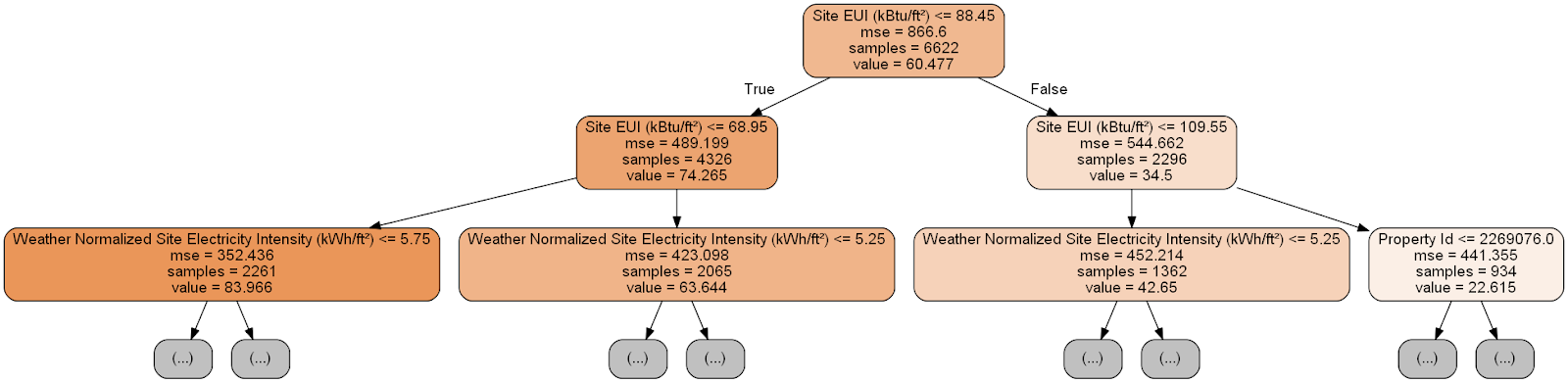
Cada nó (retângulo) da árvore contém quatro linhas:
- Pergunta feita sobre o valor de um dos sinais de uma dimensão específica: depende de qual direção sairemos deste nó.
Mse é uma medida de erro em um nó.Samples - o número de amostras de dados (medições) no nó.Value - avaliação da meta para todas as amostras de dados no nó.
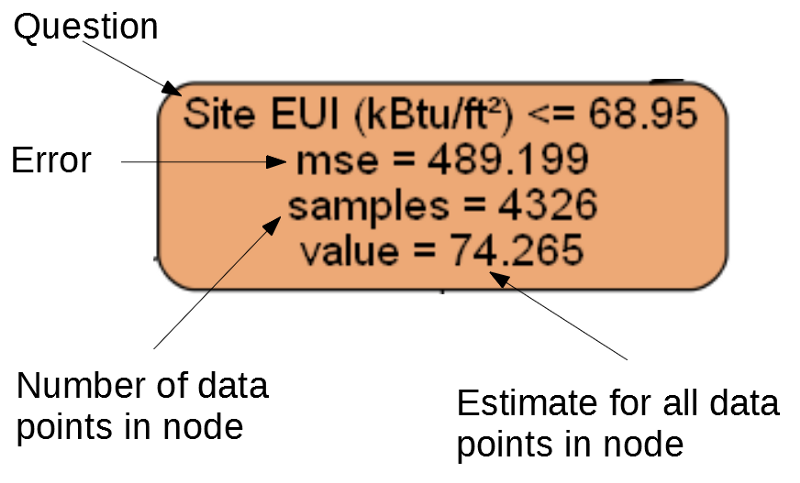 Nó separado.
Nó separado.(As folhas contêm apenas 2. –4., Porque representam a pontuação final e não têm nós filhos).
A previsão para uma determinada medida na árvore de decisão começa no nó superior - a raiz e depois desce a árvore. Em cada nó, você precisa responder à pergunta "sim" ou "não". Por exemplo, a ilustração anterior pergunta: "O EUI do site está construindo menor ou igual a 68,95?" Se sim, o algoritmo vai para o nó filho direito, se não, então para a esquerda.
Este procedimento é repetido em cada camada da árvore até que o algoritmo atinja o nó da folha na última camada (esses nós não são mostrados na ilustração com a árvore reduzida). A previsão para qualquer dimensão na planilha é
value . Se várias medidas chegarem à planilha, cada uma delas receberá a mesma previsão. À medida que a profundidade da árvore aumenta, o erro nos dados de treinamento diminui, pois haverá mais folhas e as amostras serão divididas com mais cuidado. No entanto, uma árvore muito profunda levará à
reciclagem de dados de treinamento e não poderá generalizar dados de teste.
No
segundo artigo, configuramos o número de hiperparâmetros do modelo que controlam cada árvore, por exemplo, a profundidade máxima da árvore e o número mínimo de amostras necessárias para cada folha. Esses dois parâmetros afetam fortemente o equilíbrio entre super e subaprendizagem, e a visualização da árvore de decisão nos permitirá entender como essas configurações funcionam.
Embora não possamos estudar todas as árvores do modelo, uma análise de uma delas ajudará a entender como cada “aluno” prevê. Esse método baseado em fluxograma é muito semelhante ao modo como uma pessoa toma uma decisão.
Conjuntos de árvores de decisão combinam previsões de inúmeras árvores individuais, o que permite criar modelos mais precisos com menos variabilidade. Tais conjuntos são
muito precisos e fáceis de explicar.
Explicações dependentes do modelo local interpretável (LIME)
A última ferramenta com a qual você pode tentar descobrir como o nosso modelo "pensa". O LIME permite explicar
como uma única previsão é gerada para qualquer modelo de aprendizado de máquina . Para fazer isso, localmente, próximo a algumas medidas, um modelo simplificado é criado com base em um modelo simples, como a regressão linear (os detalhes são descritos neste trabalho:
https://arxiv.org/pdf/1602.04938.pdf ).
Usaremos o método LIME para estudar a previsão completamente incorreta do nosso modelo e entender por que ele está errado.
Primeiro, encontramos esta previsão incorreta. Para isso, treinaremos o modelo, geraremos uma previsão e selecionaremos o valor com o maior erro:
from sklearn.ensemble import GradientBoostingRegressor
Previsão: 12.8615
Valor real: 100,0000Em seguida, criamos um explicador e fornecemos os dados de treinamento, informações de modo, rótulos para os dados de treinamento e os nomes dos atributos. Agora é possível transmitir os dados observacionais e a função de previsão ao explicador e, em seguida, pedir que expliquem o motivo do erro de previsão.
import lime
Gráfico de explicação da previsão:
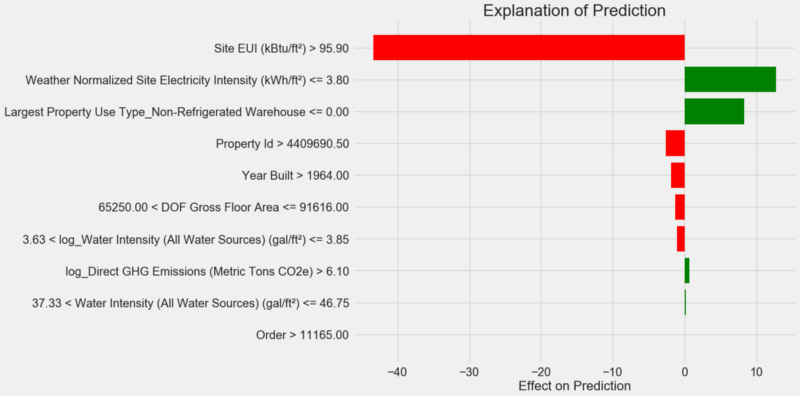
Como interpretar o diagrama: cada registro no eixo Y indica um valor da variável e as barras vermelha e verde refletem a influência desse valor na previsão. Por exemplo, de acordo com o registro superior, a influência do
Site EUI superior a 95,90, como resultado, cerca de 40 pontos são subtraídos da previsão. De acordo com o segundo registro, a influência da
Weather Normalized Site Electricity Intensity do
Weather Normalized Site Electricity Intensity menor que 3,80 e, portanto, cerca de 10 pontos são adicionados à previsão. A previsão final é a soma da interceptação e os efeitos de cada um dos valores listados.
Vamos olhar para o outro lado e chamar o método
.show_in_notebook() :

O processo de tomada de decisão pelo modelo é mostrado à esquerda: o efeito na previsão de cada variável é exibido visualmente. A tabela à direita mostra os valores reais das variáveis para uma determinada medição.
Nesse caso, o modelo previu cerca de 12 pontos, mas na verdade era 100. No começo, você pode se perguntar por que isso aconteceu, mas se você analisar a explicação, verifica-se que essa não é uma suposição extremamente ousada, mas o resultado do cálculo com base em valores específicos.
Site EUI era relativamente alto e era de se esperar um baixo Energy Star Score (porque é fortemente influenciado pelo EUI), o que nosso modelo fez. Mas, neste caso, essa lógica acabou sendo errônea, porque, de fato, o edifício recebeu a pontuação mais alta do Energy Star - 100.
Os erros do modelo podem incomodá-lo, mas essas explicações ajudarão você a entender por que o modelo estava errado. Além disso, graças às explicações, você pode começar a descobrir por que o prédio obteve a maior pontuação, apesar da alta EUI do site. Talvez possamos aprender algo novo sobre nossa tarefa que iludiria nossa atenção se não começássemos a analisar erros de modelo. Tais ferramentas não são ideais, mas podem facilitar muito o entendimento do modelo e tomar
melhores decisões .
Documentação do trabalho e apresentação dos resultados
Muitos projetos prestam pouca atenção à documentação e relatórios. Você pode fazer a melhor análise do mundo, mas se você não
apresentar os resultados corretamente , eles não importarão!
Ao documentar um projeto de análise de dados, empacotamos todas as versões dos dados e do código para que outras pessoas possam reproduzir ou coletar o projeto. Lembre-se de que o código é lido com mais frequência do que escrito, portanto, nosso trabalho deve ser claro para outras pessoas e para nós, se voltarmos a ele em alguns meses. Portanto, insira comentários úteis no código e explique suas decisões.
Os Notebooks Jupyter são uma ótima ferramenta para documentar; eles permitem que você explique primeiro as soluções e depois mostre o código.
Além disso, o Jupyter Notebook é uma boa plataforma para interagir com outros especialistas. Usando as
extensões para notebooks, você pode
ocultar o código do relatório final , porque, por mais difícil que seja acreditar, nem todo mundo quer ver um monte de código no documento!
Você pode não querer apertar, mas mostre todos os detalhes. No entanto, é importante
entender o seu público ao apresentar seu projeto e
preparar um relatório de acordo . Aqui está um exemplo de um resumo da essência do nosso projeto:
- Usando dados sobre o consumo de energia de edifícios em Nova York, você pode construir um modelo que prevê o número de pontos Energy Star com um erro de 9,1 pontos.
- O EUI do local e a intensidade de eletricidade normalizada pelo clima são os principais fatores que influenciam a previsão.
Escrevemos uma descrição detalhada e conclusões no Jupyter Notebook, mas em vez de PDF, convertemos o arquivo .tex em
Latex , que editamos no
texStudio e a
versão resultante foi convertida em PDF. O fato é que o resultado padrão da exportação do Jupyter para PDF parece bastante decente, mas pode ser bastante aprimorado em apenas alguns minutos de edição. Além disso, o Latex é um poderoso sistema de preparação de documentos que é útil de possuir.
Por fim, o valor do nosso trabalho é determinado pelas decisões que ele ajuda a tomar e é muito importante poder "entregar as mercadorias pessoalmente". Ao documentar corretamente, ajudamos outras pessoas a reproduzir nossos resultados e nos fornecer feedback, o que nos permitirá ter mais experiência e confiar nos resultados obtidos no futuro.
Conclusões
Em nossa série de publicações, abordamos um tutorial de aprendizado de máquina do início ao fim. Começamos limpando os dados, depois criamos um modelo e, no final, aprendemos a interpretá-los. Lembre-se da estrutura geral do projeto de aprendizado de máquina:
- Limpeza e formatação de dados.
- Análise exploratória de dados.
- Design e seleção de recursos.
- Comparação das métricas de vários modelos de aprendizado de máquina.
- Ajuste hiperparamétrico do melhor modelo.
- Avaliação do melhor modelo em um conjunto de dados de teste.
- Interpretação dos resultados do modelo.
- Conclusões e relatório bem documentado.
O conjunto de etapas pode variar dependendo do projeto, e o aprendizado de máquina geralmente é iterativo e não linear, portanto, este guia o ajudará no futuro. Esperamos que agora você possa implementar seus projetos com confiança, mas lembre-se: ninguém age sozinho! Se você precisar de ajuda, há muitas comunidades muito úteis nas quais você receberá conselhos.
Essas fontes podem ajudá-lo: