O desenvolvimento de redes neurais profundas para reconhecimento de imagens dá nova vida às áreas já conhecidas de pesquisa em aprendizado de máquina. Uma dessas áreas é a adaptação do domínio. A essência dessa adaptação é treinar o modelo em dados do domínio de origem (domínio de origem) para que ele mostre uma qualidade comparável no domínio de destino (domínio de destino). Por exemplo, um domínio de origem pode ser dados sintéticos que podem ser gerados de forma barata e um domínio de destino pode ser fotos do usuário. A tarefa de adaptação do domínio é treinar o modelo em dados sintéticos, que funcionarão bem com objetos "reais".
No grupo de visão de máquina Vision.BIZ.Ru, estamos trabalhando em vários problemas aplicados e, entre eles, geralmente existem aqueles para os quais existem poucos dados de treinamento. Nesses casos, a geração de dados sintéticos e a adaptação do modelo treinado neles podem ajudar bastante. Um bom exemplo aplicado dessa abordagem é a tarefa de detectar e reconhecer mercadorias nas prateleiras de uma loja. Tirar fotos dessas prateleiras e marcá-las é bastante trabalhoso, mas elas podem ser geradas de maneira bastante simples. Portanto, decidimos aprofundar o tema da adaptação do domínio.

Estudos em adaptação de domínio afetam o uso de experiências anteriores obtidas por uma rede neural em uma nova tarefa. A rede poderá extrair alguns recursos do domínio de origem e usá-los no domínio de destino? Embora uma rede neural no aprendizado de máquina esteja apenas distante das redes neurais no cérebro humano, no entanto, o Santo Graal dos pesquisadores de inteligência artificial é ensinar às redes neurais os recursos que uma pessoa possui. E as pessoas são capazes de usar a experiência anterior e o conhecimento acumulado para entender novos conceitos.
Além disso, a adaptação do domínio pode ajudar a resolver um dos problemas fundamentais da aprendizagem profunda: para treinar grandes redes com alta qualidade de reconhecimento, é necessária uma quantidade muito grande de dados, o que na prática nem sempre está disponível. Uma solução pode ser usar métodos de adaptação de domínio em dados sintéticos que podem ser gerados em quantidades praticamente ilimitadas.
Frequentemente, em problemas aplicados, há um caso em que dados de apenas um domínio estão disponíveis para treinamento e o modelo deve ser aplicado em outro domínio. Por exemplo, a rede que determina a qualidade estética da fotografia pode ser treinada em um banco de dados disponível na rede, coletado no site amador. E está planejado usar essa rede em fotografias comuns, cujo nível de qualidade difere, em média, do nível de uma foto de um site especializado em fotos. Como solução, podemos considerar a adaptação do modelo a fotografias comuns não rotuladas.
Tais questões teóricas e aplicadas estão no domínio da adaptação. Neste artigo, falarei sobre as principais pesquisas nessa área, baseadas em aprendizado profundo e conjuntos de dados para comparar diferentes métodos. A idéia principal da adaptação de domínio profundo é treinar uma rede neural profunda no domínio de origem, que traduzirá a imagem em uma incorporação (geralmente a última camada da rede) que, quando usada no domínio de destino, será obtida alta qualidade.
Benchmarks principais
Como em qualquer campo do aprendizado de máquina, uma certa quantidade de pesquisa é acumulada na adaptação do domínio ao longo do tempo, que deve ser comparada entre si. Para isso, a comunidade desenvolve conjuntos de dados, na parte de treinamento em que os modelos são treinados e na parte de teste são comparados. Apesar do domínio de pesquisa de adaptação profunda de domínio ainda ser relativamente jovem, já existe um número bastante grande de artigos e bancos de dados usados nesses artigos. Vou listar os principais, com foco na adaptação do domínio de dados sintéticos para "real".
Figuras
Aparentemente, de acordo com a tradição instituída por Yann LeCun (um dos pioneiros da aprendizagem profunda, diretor da Facebook AI Research), na visão por computador, os conjuntos de dados mais simples estão associados a números ou letras manuscritas. Existem vários conjuntos de dados com números que apareceram originalmente para experimentar modelos de reconhecimento de imagem. Nos artigos sobre adaptação de domínios, é possível encontrar uma variedade de combinações em pares de domínios de origem e destino. Entre esses conjuntos de dados:
- MNIST - números manuscritos, não precisa de apresentação adicional;
- USPS - números manuscritos em baixa resolução;
- SVHN - números de residência com o Google Street View;
- Números sintéticos são números sintéticos, como o nome sugere.
Do ponto de vista da tarefa de treinar dados sintéticos para uso no mundo "real", os mais interessantes são os pares:
- Fonte: MNIST, Alvo: SVHN;
- Fonte: USPS, Alvo: MNIST;
- Fonte: Números Synth, Alvo: SVHN.

A maioria dos métodos possui referências em conjuntos de dados "digitais". Mas os outros tipos de domínios podem ser encontrados longe de todos os artigos.
Escritório
Este conjunto de dados contém 31 categorias de vários itens, cada um dos quais está representado em 3 domínios: uma imagem da Amazon, uma foto de uma webcam e uma foto de uma câmera digital.

É útil para verificar como o modelo responderá à adição de plano de fundo e qualidade ao domínio de destino.
Sinais de trânsito
Outro par de conjuntos de dados para treinar o modelo em dados sintéticos e aplicá-lo a dados "reais":
- Fonte: Sinais Synth - imagens de sinais de trânsito gerados para que pareçam sinais reais na rua;
- Alvo: O GTSRB é uma base de reconhecimento bastante conhecida que contém sinais de estradas alemãs.

Uma característica desse par de bancos de dados é que os dados do Synth Signs são bastante semelhantes aos dados "reais", de modo que os domínios são bastante próximos.
Da janela do carro
Conjuntos de dados para segmentação. Um casal bastante interessante, o mais próximo das condições reais. Os dados de origem são obtidos usando o mecanismo de jogo (GTA 5), e os dados de destino são da vida real. Abordagens semelhantes são usadas para treinar modelos usados em carros autônomos.
- Mecanismo SYNTHIA ou GTA 5 - imagens de uma cidade vista da janela de um carro gerada usando um mecanismo de jogo;
- Paisagens urbanas - Fotos de um carro tirado em 50 cidades diferentes.

VisDA
Este conjunto de dados é usado no Visual Domain Adaptation Challenge , que faz parte de um workshop sobre ECCV e ICCV. O domínio de origem contém 12 categorias de objetos rotulados gerados usando CAD, como um avião, um cavalo, uma pessoa etc. O domínio de destino contém imagens não identificadas das mesmas 12 categorias obtidas no ImageNet. Na competição, realizada em 2018, foi adicionada a 13ª categoria: Desconhecido.
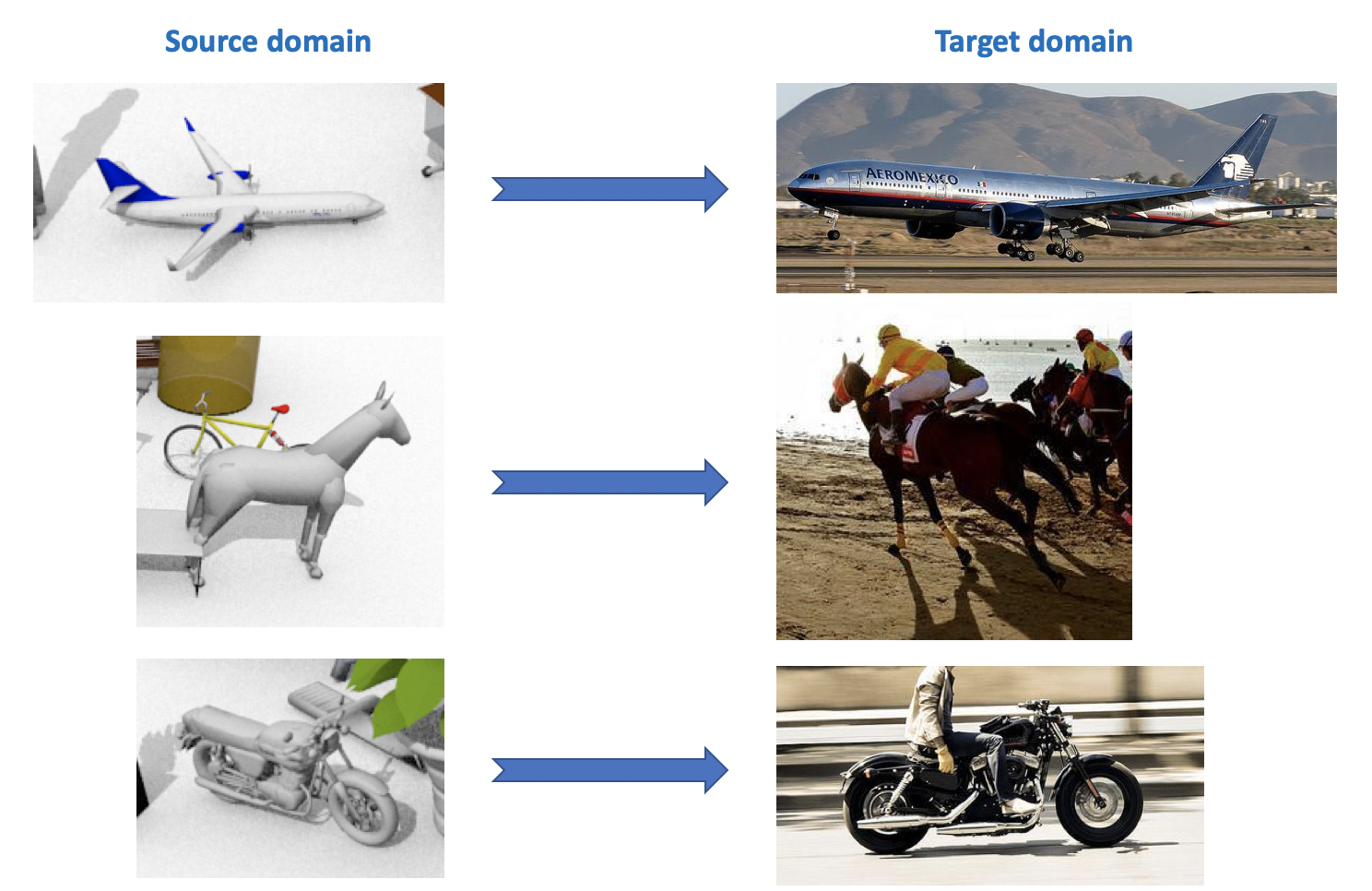
Como você pode ver em tudo isso, existem muitos conjuntos de dados interessantes e diversos para adaptação de domínio, você pode treinar e testar modelos neles para várias tarefas (classificação, segmentação, detecção) e várias condições (dados sintéticos, fotos, vistas da rua).
Adaptação profunda do domínio
Existe uma classificação bastante extensa e variada dos métodos de adaptação de domínio (por exemplo , veja aqui ). Darei neste artigo uma divisão simplificada de métodos de acordo com seus principais recursos. Os métodos modernos de adaptação profunda do domínio podem ser divididos em 3 grandes grupos:
- Baseado em discrepância : abordagens baseadas em minimizar a distância entre representações vetoriais nos domínios de origem e de destino, introduzindo essa distância na função de perda.
- Baseado em Adversarial : essas abordagens usam a função de perda de contraditório introduzida nas GANs para treinar uma rede invariável em domínio. Os métodos dessa família foram desenvolvidos ativamente nos últimos dois anos.
- Métodos mistos que não usam perdas contraditórias, mas aplicam idéias da família baseada em discrepâncias, bem como os desenvolvimentos mais recentes do aprendizado profundo: auto-montagem, novas camadas, funções de perda, etc. Essas abordagens mostram os melhores resultados na competição VisDA.
Em cada seção, vários resultados básicos, na minha opinião, serão considerados.
Baseado em discrepâncias
Quando surge o problema de adaptar um modelo a novos dados, a primeira coisa que vem à mente é o uso de ajustes finos, ou seja, treinando novamente o modelo em novos dados. Para fazer isso, considere a discrepância entre os domínios. Esse tipo de adaptação de domínio pode ser dividido em três abordagens: Critério de Classe, Critério Estatístico e Critério de Arquitetura.
Critério de classe
Os métodos dessa família são usados principalmente quando temos acesso a dados marcados do domínio de destino. Uma das opções populares do critério de classe é a abordagem de aprendizado de métrica de transferência profunda . Como o nome indica, ele se baseia no aprendizado de métricas, cuja essência é treinar uma representação vetorial obtida de uma rede neural que os representantes de uma classe estarão próximos uns dos outros nessa representação de acordo com uma determinada métrica (geralmente usada L 2 ou métricas de cosseno). No artigo Aprendizado métrico de transferência profunda (DTML) , uma perda que consiste na soma dos termos é usada para implementar esta abordagem:
- A proximidade de representantes de uma classe entre si (compactação intraclasse);
- Maior distância entre representantes de diferentes classes (separabilidade entre classes);
- Métrica de discrepância média máxima (MMD) entre domínios. Essa métrica pertence à família de critérios estatísticos (veja abaixo), mas também é usada no critério de classe.
MMD entre domínios é escrito como
MMD2(Ds,Dt)= Ver frac1M sumMi=1 phi(xsi)− frac1N sumNj=1 phi(xtj) Ver2H,
onde phi(x) - este é um núcleo, no nosso caso - uma representação vetorial da rede, xsi,i em1 ldotsM - dados do domínio de origem, xti,i in1 ldotsN - dados do domínio de destino. Assim, ao minimizar a métrica MMD durante o treinamento, essa rede é selecionada phi(x) para que suas representações vetoriais médias nos dois domínios estejam próximas. A principal idéia do DTML:
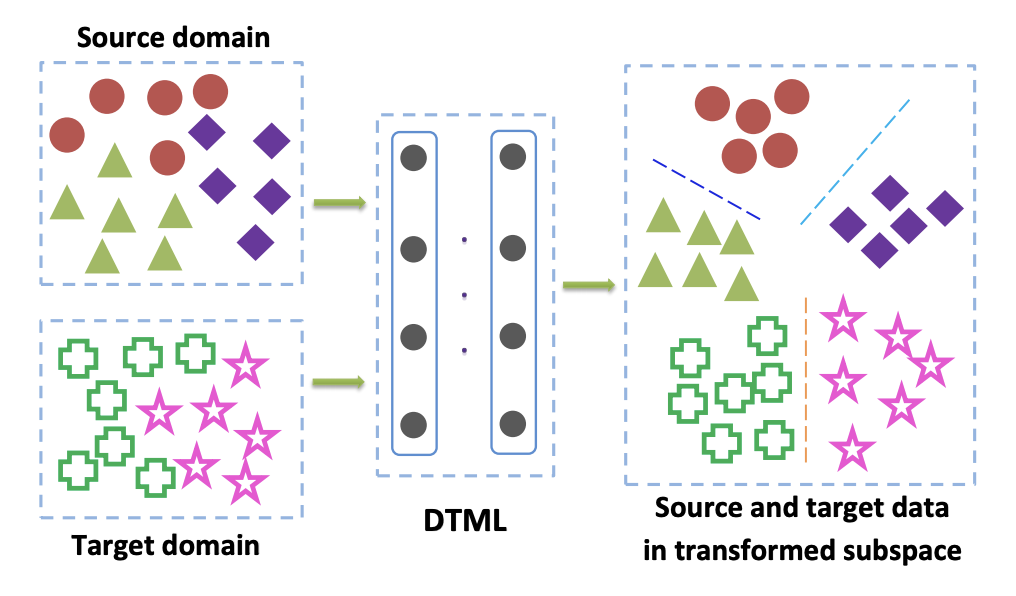
Se os dados no domínio de destino forem uma adaptação de domínio não supervisionado, o método descrito em Considerar o viés de peso da classe: discrepância média máxima ponderada para adaptação de domínio não supervisionado sugere treinar o modelo no domínio de origem e usá-lo para obter pseudo-rótulos (pseudo- rótulos) no domínio de destino. I.e. os dados do domínio de destino são executados na rede e o resultado é chamado de pseudo-rótulos. Em seguida, eles são usados como marcação para o domínio de destino, o que permite que o critério MMD seja aplicado na função de perda (com pesos diferentes para os componentes responsáveis por diferentes domínios).
Critério estatístico
Métodos relacionados a essa família são usados para resolver o problema de adaptação de domínio não supervisionado. O caso em que o domínio de destino não está atribuído ocorre em muitos problemas e todos os métodos de adaptação de domínio, que serão discutidos mais adiante neste artigo, resolvem exatamente esse problema.
Abordagens baseadas em critérios estatísticos tentam medir a diferença entre as distribuições da representação vetorial da rede obtidas a partir dos dados dos domínios de origem e de destino. Eles então usam a diferença calculada para reunir essas duas distribuições.
Um desses critérios é a discrepância média máxima (MMD) já descrita acima. Suas variantes são usadas em vários métodos:
Os diagramas desses três métodos são apresentados abaixo. Nelas, as variantes MMD são usadas para determinar a diferença entre as distribuições nas camadas da rede neural convolucional aplicada aos domínios de origem e de destino. Observe que cada um deles usa a modificação MMD como uma perda entre as camadas das redes de convolução (figuras amarelas no diagrama).

O critério CORAL (CORrelation ALignment) e sua extensão com a ajuda de redes Deep CORAL visam a aprender essa representação de dados, para que as estatísticas de segunda ordem entre domínios correspondam ao máximo. Para isso, são utilizadas matrizes de covariância de representações vetoriais da rede. A convergência de estatísticas de segunda ordem em ambos os domínios, em alguns casos, permite obter melhores resultados de adaptação do que no MMD.
LCORAL= frac14d2 VertCS−CT Vert2F,
onde ||∗||2F É o quadrado da norma da matriz de Frobenius e Cs e Ct - dados da matriz de covariância dos domínios de origem e de destino, respectivamente, d - a dimensão da representação vetorial.
No conjunto de dados do Office, a qualidade média da adaptação usando o Deep CORAL para pares de domínios da Amazon e Webcam é de 72,1%. Nos domínios Sinais Sintéticos -> GTSRB, o resultado também é muito médio: 86,9% de precisão no domínio de destino.
O desenvolvimento das idéias de MMD e CORAL é o critério de Discrepância de Momento Central (CMD) , que compara os momentos centrais dos dados dos domínios de origem e destino de todos os pedidos até K inclusive ( K - parâmetro do algoritmo). No conjunto de dados do Office, a qualidade média de adaptação do CMD para pares de domínios da Amazon e Webcam é de 77,0%.
Critério de arquitetura
Algoritmos desse tipo são baseados no pressuposto de que as informações básicas responsáveis pela adaptação a um novo domínio estão incorporadas nos parâmetros de uma rede neural.
Em vários artigos [1] , [2], ao treinar redes para os domínios de origem e de destino usando funções de perda para cada par de camadas, as informações que são invariantes em relação ao domínio são estudadas nos pesos dessas camadas. Um exemplo dessas arquiteturas é dado abaixo.
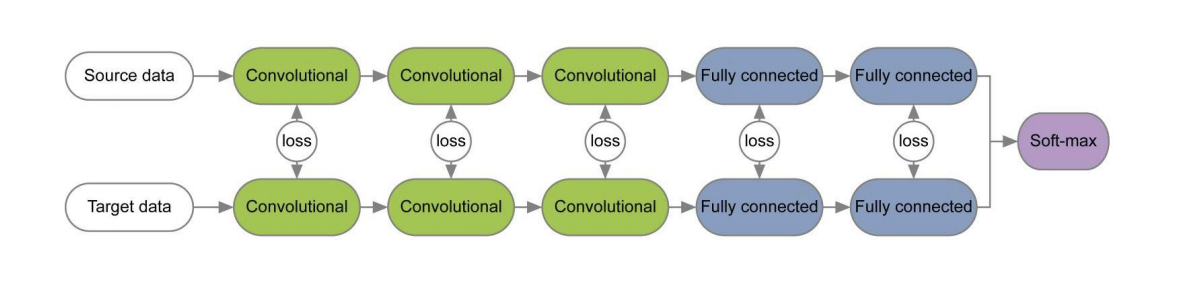
No artigo “ Revisitando a normalização de lotes para adaptação prática ao domínio”, foi apresentada a ideia de que as escalas de rede contêm informações relacionadas às classes nas quais a rede está estudando e as informações do domínio são incorporadas nas estatísticas (média e desvio padrão) das camadas de Normalização de lotes (BN). Portanto, para adaptação, é necessário recalcular essas estatísticas nos dados do domínio de destino. O uso dessa técnica em conjunto com o CORAL pode melhorar a qualidade da adaptação no conjunto de dados do Office para pares de domínios da Amazon e Webcam em até 75,0%. Foi então demonstrado que o uso da camada Normalização de Instância (IN) em vez de BN melhora ainda mais a qualidade da adaptação. Ao contrário de BN, que normaliza o tensor de entrada para lotes, o IN calcula estatísticas para normalização por canais e, portanto, não depende do lote.
Abordagens baseadas em adversários
Nos últimos 1-2 anos, a maioria dos resultados na adaptação profunda do domínio está relacionada à abordagem baseada no contraditório. Isso se deve em grande parte ao rápido desenvolvimento e popularidade das Redes Adversárias Generativas (GAN) , porque a abordagem baseada no contraditório para a adaptação do domínio usa a mesma função objetiva do adversário no treinamento que o GAN. Ao otimizá-lo, esses métodos de adaptação de domínio profundo minimizam a distância entre as distribuições empíricas das representações de dados vetoriais nos domínios de origem e de destino. Ao treinar a rede dessa maneira, eles tentam torná-la invariável em relação ao domínio.
O GAN consiste em dois modelos: gerador G , na saída em que são obtidos dados de uma determinada distribuição de destino; e discriminador D , que determina se os dados do conjunto de treinamento ou gerados usando G . Esses dois modelos são treinados usando a função objetivo adversário:
minG maxDV(D,G)= mathbbEx simpdados(x)[ logD(x)]+ mathbbEz simp(z)[1− logD(G(z))].
Com esse treinamento, o gerador aprende a "enganar" o discriminador, o que permite aproximar a distribuição dos domínios de destino e de origem.
Existem duas grandes abordagens na adaptação de domínio baseada no contraditório que diferem quanto ao uso ou não de um gerador. G .
Modelos não generativos
Uma característica chave dos métodos dessa família é o treinamento de uma rede neural com uma representação vetorial invariável em relação aos domínios de origem e de destino. Em seguida, a rede treinada no domínio de origem marcado pode ser usada no domínio de destino, idealmente - praticamente sem perda da qualidade da classificação.
Introduzido em 2015, o algoritmo ( código ) do Treinamento Adversarial de Domínio de Redes Neurais (DANN ) consiste em 3 partes:
- A rede principal, com a ajuda da qual é obtida uma representação vetorial (extrator de característica) (a parte verde na ilustração abaixo);
- "Chefes" responsáveis pela classificação no domínio de origem (parte azul na ilustração);
- Uma "cabeça" que aprende a distinguir dados do domínio de origem do domínio de destino (a parte vermelha na ilustração).
Ao treinar usando a descida do gradiente (SGD) (setas para inserir na ilustração), as perdas de classificação e domínio são minimizadas. Além disso, quando o erro de aprendizado é propagado para trás pela “cabeça” responsável pelos domínios, é usada a camada de reversão Gradiente (a parte preta na ilustração), que multiplica o gradiente que passa por ele por uma constante negativa, aumentando a perda de domínio. Isso garante que as distribuições de representações vetoriais nos dois domínios se aproximem.
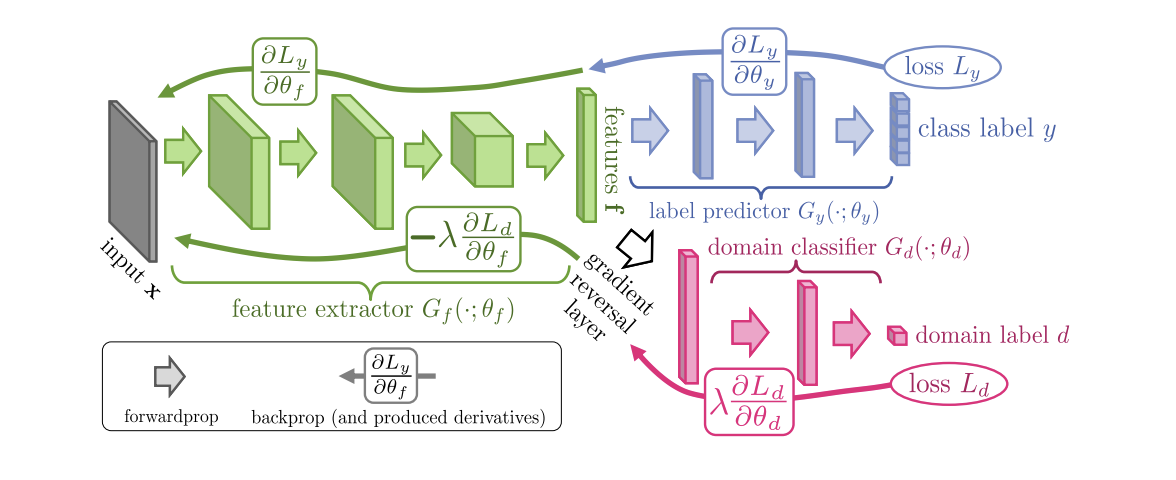
Resultados de referência da DANN:
- Em um par de domínios digitais, Synth Numbers -> SVHN: 91,09%.
- Em Sinais Sintéticos -> sinais de trânsito GTSRB, supera CORAL com um resultado de 88,7%.
- No conjunto de dados do Office, a qualidade média de adaptação para pares de domínios da Amazon e Webcam é de 73,0%.
O próximo representante importante da família de modelos não-generativos é o método ( código ) ADDA (Adversarial Discriminative Domain Adaptation ), que envolve a separação da rede para o domínio de origem e da rede para o domínio de destino. O algoritmo consiste nas seguintes etapas:
- Primeiro, treinamos a rede classificadora no domínio de origem. Denotamos sua representação vetorial Ms e mathbfXs - domínio de origem.
- Agora inicialize a rede neural para o domínio de destino usando a rede treinada da etapa anterior. Deixe ela Mt e mathbfXt - domínio de destino.
- Vamos para o treinamento adversário: treinaremos o discriminador D em fixo Ms e Mt usando a seguinte função objetivo:
minDLadvD( mathbfXs, mathbfXt,Ms,Mt)=− mathbbExs sim mathbfXs[ logD(Ms(xs))]− mathbbExt sim mathbfXt[ log(1−D(Mt(xt)))]
- Congelar discriminador e reciclagem Mt no domínio de destino:
minMs,MtLadvM( mathbfXs, mathbfXt,D)=− mathbbExt sim mathbfXt[ logD(Mt(xt))]
3 4 . ADDA , , adversarial- , . :
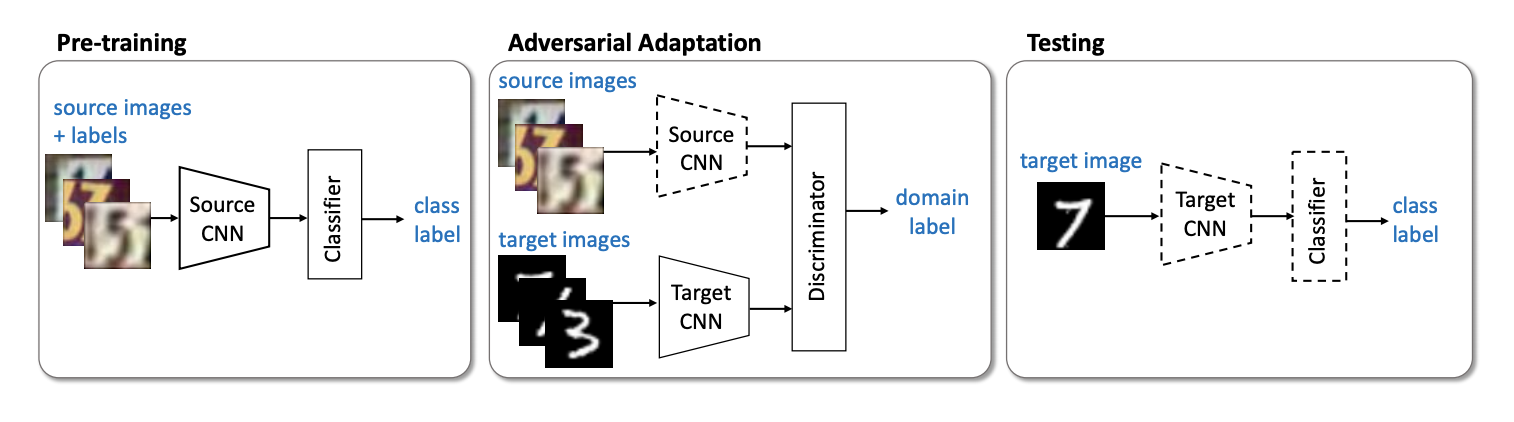
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, L2 -. 1 ADDA - Triplet loss ( ( ) ). , K ( K — ). Cj,j∈1…K .
ADDA, .. 2-4. 4 , Cj , :
Ext∼Xt[minj||Mt(xt)−Cj||2].
.
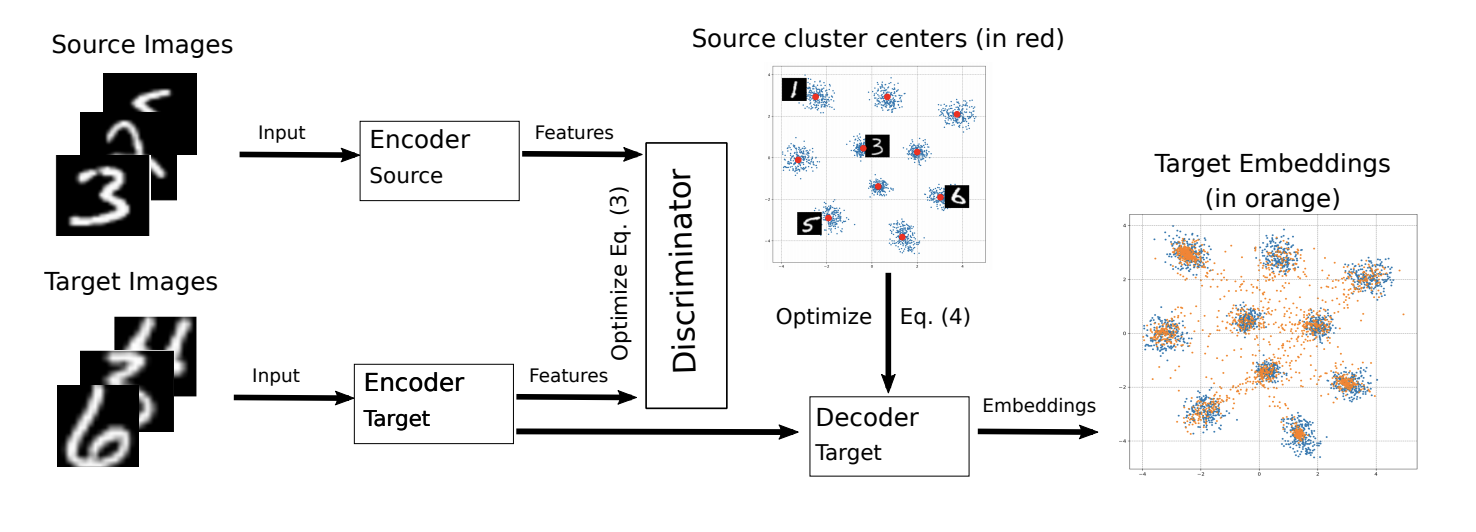
M-ADDA USPS -> MNIST 94,0 %.
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
G — , F1 e F2 — , . , G , F1 e F2 -; , ; , ; F1 e F2 .
, adversarial-, G , .
(Discrepancy Loss)
d(p1,p2)=1KK∑k=1|p1k−p2k|,
K — , p1kp2k — softmax k - F1 e F2 .
3 :
- A. G , F1 e F2 .
- B. , .
- C . , , Discrepancy Loss.
n ( ). B C:
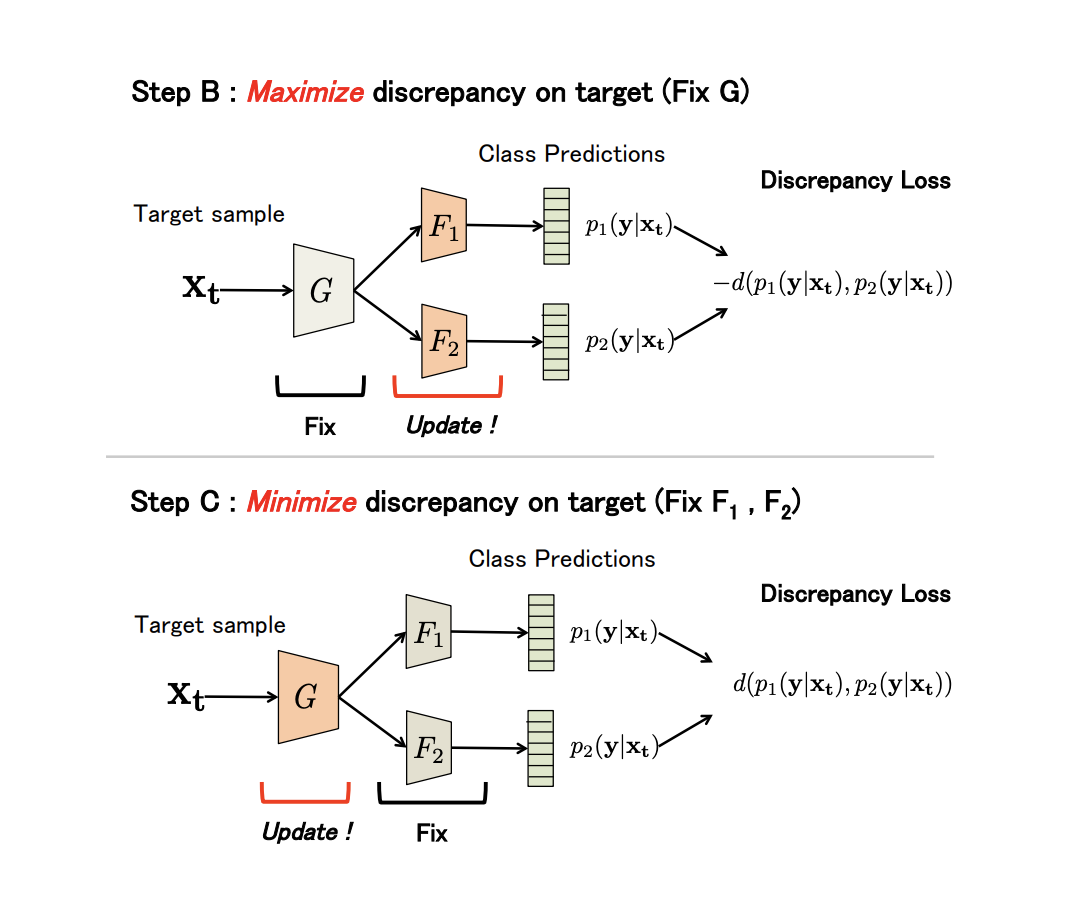
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
Examinamos os principais conjuntos de dados para adaptação de domínio, abordagens baseadas em discrepâncias: critério de classe, critério estatístico e critério de arquitetura, bem como a primeira família não-generativa de métodos baseados em contraditórios. Os modelos dessas abordagens mostram bom desempenho nos benchmarks e são aplicáveis a muitas tarefas de adaptação. Na próxima parte, consideraremos as abordagens mais complexas e eficazes: modelos generativos e métodos mistos não baseados em contraditórios.