Spam nas redes sociais e mensagens instantâneas é uma dor. Dor para usuários honestos e desenvolvedores. Como eles combatem no Badoo, disse Mikhail Ovchinnikov no Highload ++, a versão em texto deste relatório.
Sobre o palestrante: Mikhail Ovchinnikov trabalha no Badoo e é anti-spam nos últimos cinco anos.
O Badoo possui 390 milhões de usuários registrados (dados de outubro de 2017). Se compararmos o tamanho da audiência do serviço com a população da Rússia, podemos dizer que, segundo as estatísticas, cada 100 milhões de pessoas são protegidas por 500 mil policiais e, no Badoo, apenas um funcionário do Antispam protege cada 100 milhões de usuários de spam. Mas mesmo um número tão pequeno de programadores pode proteger os usuários de vários problemas na Internet.
Temos um grande público e ele pode ter diferentes usuários:
- Bom e muito bom, nossos clientes pagantes favoritos;
- Os maus são aqueles que, pelo contrário, estão tentando ganhar dinheiro conosco: enviam spam, fraudam dinheiro e se envolvem em fraudes.
Quem tem que lutar
O spam pode ser diferente, geralmente não pode ser distinguido do comportamento de um usuário comum. Pode ser manual ou automático - os bots envolvidos no envio automático também querem chegar até nós.
Talvez você também tenha escrito bots - estava criando scripts para postagem automática. Se você está fazendo isso agora, é melhor não ler mais - você nunca deve descobrir o que vou lhe dizer agora.
Isso, é claro, é uma piada. O artigo não terá informações que simplifiquem a vida dos spammers.

Então, com quem temos que lutar? Estes são spammers e scammers.
O spam apareceu há muito tempo, desde o início do desenvolvimento da Internet. Em nosso serviço, os remetentes de spam, em regra, tentam registrar uma conta carregando uma
foto de uma garota atraente lá . Na forma mais simples, eles começam a enviar os tipos mais óbvios de links de spam.
Uma opção mais complicada é quando as pessoas não enviam nada explícito, não enviam links, não anunciam nada, mas
atraem o usuário para um local mais conveniente para eles, por exemplo, mensageiros instantâneos : Skype, Viber, WhatsApp. Lá eles podem, sem nosso controle, vender qualquer coisa ao usuário, promover etc.
Mas os
spammers não são o maior problema . Eles são óbvios e fáceis de combater. Personagens muito mais complexos e interessantes são
golpistas que fingem ser outra pessoa e tentam enganar os usuários de todas as formas existentes na Internet.
Obviamente, as ações dos spammers e scammers nem sempre são muito diferentes do comportamento dos usuários comuns que também fazem isso às vezes. Existem muitos sinais formais nos dois que não permitem traçar uma linha clara entre eles. Isso quase nunca é possível.
Como lidar com spam na era mesozóica
- A coisa mais simples que se podia fazer era escrever expressões regulares separadas para cada tipo de spam e inserir cada palavrão e cada domínio separado nesse regular. Tudo isso foi feito manualmente e, é claro, foi o mais inconveniente e ineficiente possível.
- Você pode encontrar manualmente endereços IP duvidosos e inseri-los na configuração do servidor para que usuários suspeitos nunca mais acessem seu recurso. Isso é ineficiente porque os endereços IP são constantemente reatribuídos, redistribuídos.
- Escreva scripts únicos para cada tipo de remetente de spam ou bot, raspe seus logs, encontre manualmente padrões. Se um pouco de algo muda no comportamento do remetente de spam, tudo para de funcionar - também completamente ineficaz.

Primeiro, mostrarei os métodos mais simples de combate ao spam que todos podem implementar por si mesmos. Em seguida, explicarei detalhadamente os sistemas mais complexos que desenvolvemos usando aprendizado de máquina e outras artilharia pesada.
As maneiras mais fáceis de lidar com spam
Moderação manual
Em qualquer serviço, você pode contratar moderadores que visualizam manualmente o conteúdo e o perfil do usuário e decidem o que fazer com esse usuário. Normalmente, esse processo parece encontrar uma agulha no palheiro. Temos um grande número de usuários, moderadores menos.

Além do fato de que os moderadores obviamente precisam de muito, você precisa de muita infraestrutura. Mas, de fato, a coisa mais difícil é outra - surge um problema: como, pelo contrário, protege os usuários dos moderadores.
É necessário garantir que os moderadores não tenham acesso aos dados pessoais. Isso é importante porque os moderadores também podem, teoricamente, tentar causar danos. Ou seja, precisamos de antispam para antispam, para que os moderadores estejam sob controle rígido.
Obviamente, você não pode verificar todos os usuários dessa maneira. No entanto, a
moderação é necessária em qualquer caso , porque quaisquer sistemas no futuro precisam de treinamento e de uma mão humana que determine o que fazer com o usuário.
Coleta de estatísticas
Você pode tentar usar as estatísticas - para coletar vários parâmetros para cada usuário.
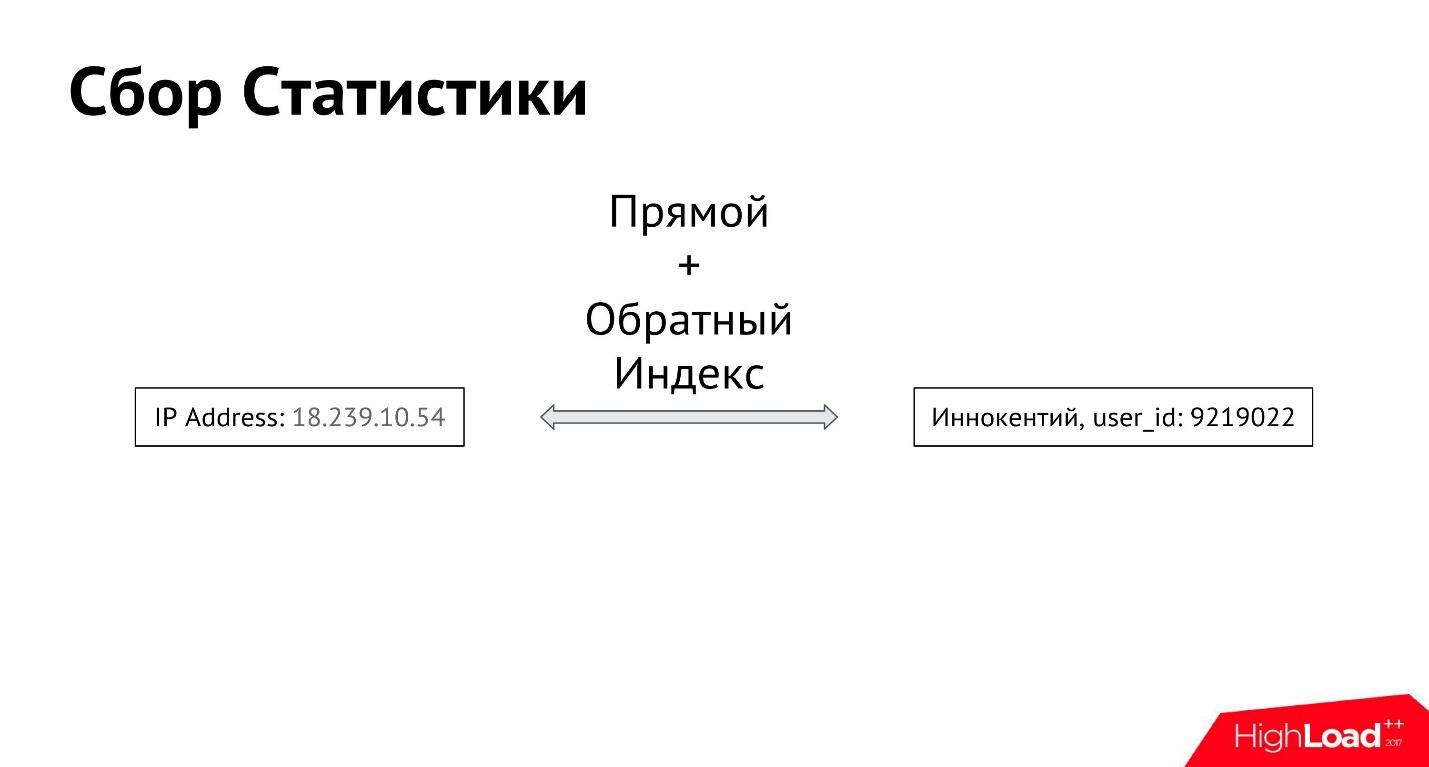
O usuário Innokenty efetua login no seu endereço IP. A primeira coisa que fazemos é fazer login no endereço IP digitado. Em seguida, criamos um índice de avanço e reversão entre todos os endereços IP e todos os usuários, para que você possa obter todos os endereços IP dos quais um usuário específico efetua login, bem como todos os usuários que efetuam login a partir de um endereço IP específico.
Dessa forma, obtemos a conexão entre o atributo e o usuário. Pode haver muitos desses atributos. Podemos começar a coletar informações não apenas sobre endereços IP, mas também fotos, dispositivos dos quais o usuário entrou - sobre tudo o que podemos determinar.
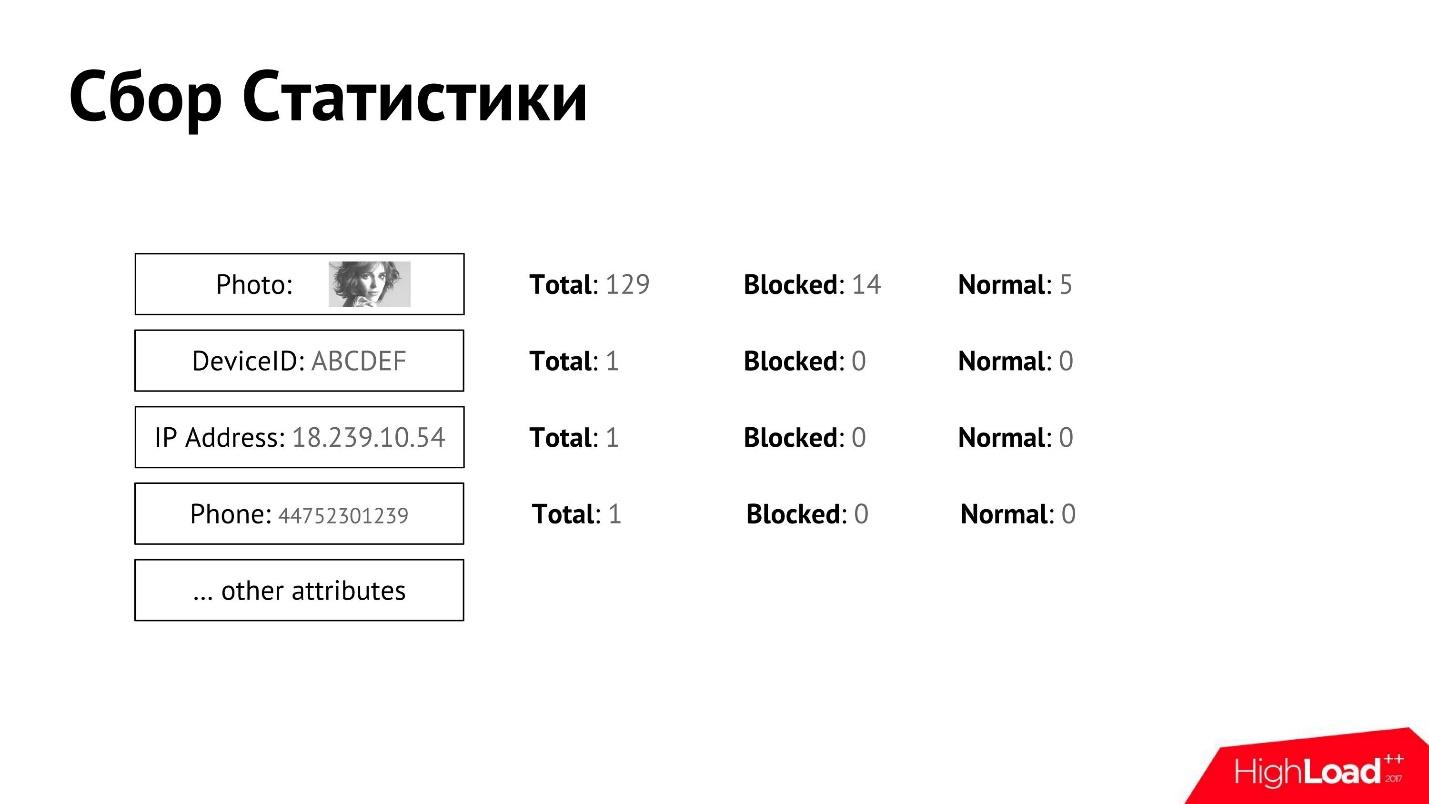
Coletamos essas estatísticas e as associamos ao usuário. Para cada um dos atributos, podemos coletar contadores detalhados.
Temos uma moderação manual que decide qual usuário é bom, o que é ruim e, em algum momento, o usuário é bloqueado ou reconhecido como normal. Podemos obter dados separadamente para cada atributo, quantos usuários totais, quantos deles estão bloqueados, quantos são reconhecidos como normais.
Tendo essas estatísticas para cada um dos atributos, podemos determinar aproximadamente quem é o remetente de spam e quem não é.

Digamos que temos dois endereços IP - 80% dos spammers em um e 1% no segundo. Obviamente, o primeiro é muito mais spam, você precisa fazer algo com ele e aplicar algum tipo de sanção.
O mais simples é escrever
regras heurísticas . Por exemplo, se os usuários bloqueados tiverem mais de 80% e os que forem considerados normais - menos de 5%, esse endereço IP será considerado ruim. Em seguida, banimos ou fazemos outra coisa com todos os usuários com esse endereço IP.
Coleção de estatísticas de textos
Além dos atributos óbvios que os usuários possuem, você também pode fazer uma análise de texto. Você pode analisar automaticamente as mensagens do usuário, isolar delas tudo o que está relacionado ao spam: mencionar mensageiros, telefones, email, links, domínios etc. e coletar exatamente as mesmas estatísticas.

Por exemplo, se um nome de domínio foi enviado em mensagens por 100 usuários, dos quais 50 foram bloqueados, esse nome de domínio está incorreto. Pode ser colocado na lista negra.
Receberemos uma grande quantidade de estatísticas adicionais para cada um dos usuários com base nos textos das mensagens. Não é necessário aprendizado de máquina para isso.
Pare palavras
Além das coisas óbvias - telefones e links - você pode extrair frases ou palavras do texto que são especialmente comuns para spammers. Você pode manter essa lista de palavras de parada manualmente.
Por exemplo, nas contas de spammers e scammers, a frase: "Existem muitas falsificações" é frequentemente encontrada. Eles escrevem que geralmente são os únicos aqui preparados para algo sério, todos os outros fingimentos, dos quais em nenhum caso se pode confiar.
Nos sites de namoro de acordo com as estatísticas, os remetentes de spam com mais frequência do que as pessoas comuns usam a frase: "Estou procurando um relacionamento sério". É improvável que uma pessoa comum escreva isso em um site de namoro - com uma probabilidade de 70%, este é um spammer que está tentando atrair alguém.
Pesquise contas semelhantes
Com estatísticas sobre atributos e palavras de parada encontradas nos textos, você pode criar um sistema para procurar contas semelhantes. Isso é necessário para encontrar e banir todas as contas criadas pela mesma pessoa. Um remetente de spam bloqueado pode registrar imediatamente uma nova conta.
Por exemplo, um usuário Harold efetua login, acessa o site e fornece seus atributos bastante exclusivos: endereço IP, foto, palavra de parada que ele usou. Talvez ele até tenha se inscrito com uma conta falsa no Facebook.
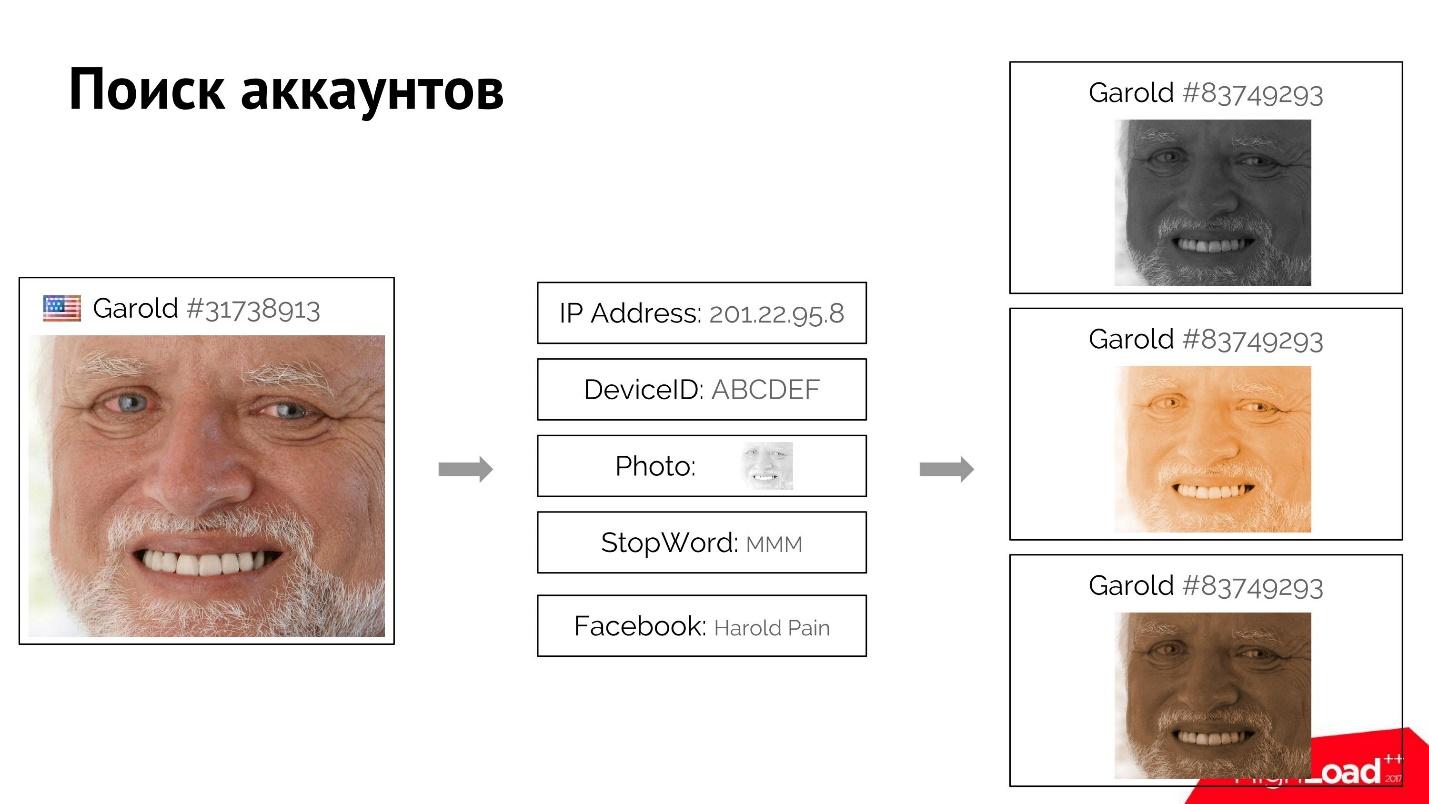
Podemos encontrar todos os usuários semelhantes a ele que possuem um ou mais desses atributos correspondentes. Quando sabemos com certeza que esses usuários estão conectados, usando o índice direto e reverso, encontramos os atributos, e por eles de todos os usuários, e os classificamos. Se, digamos o primeiro Harold, bloquearmos, o resto também será fácil de "matar" usando esse sistema.
Todos os métodos que acabei de descrever são muito simples: é fácil coletar estatísticas e, em seguida, pesquisar usuários usando esses atributos. Mas, apesar da facilidade, com a ajuda de coisas simples - moderação simples, estatísticas simples, palavras simples de parada - eles conseguem
derrotar 50% do spam .
Em nossa empresa, nos primeiros seis meses de trabalho, o departamento Antispam ganhou 50% de spam. Os 50% restantes, como você sabe, são muito mais complicados.
Como dificultar a vida dos spammers
Os spammers estão inventando algo, tentando complicar nossas vidas, e estamos tentando combatê-los. Esta é uma guerra sem fim. Existem muito mais deles do que nós e, a cada passo, criamos seu próprio caminho múltiplo.
Estou certo de que as conferências de spammers estão ocorrendo em algum lugar onde os palestrantes falam sobre como derrotaram o Badoo Antispam, sobre seus KPIs ou sobre como criar spam escalável e tolerante a falhas usando a tecnologia mais recente.
Infelizmente, não somos convidados para tais conferências.
Mas podemos dificultar a vida dos spammers. Por exemplo, em vez de mostrar diretamente ao usuário a janela "Você está bloqueado", você pode usar o chamado
banimento Stealth - é quando não dizemos ao usuário que ele foi banido. Ele nem deveria suspeitar disso.

O usuário entra na caixa de areia (Silent Hill), onde tudo parece real: você pode enviar mensagens, votar, mas na verdade tudo fica no vazio, no nevoeiro. Ninguém nunca verá e ouvirá, ninguém receberá suas mensagens e votos.
Tivemos um caso em que um spammer enviou spam por muito tempo, promoveu seus bens e serviços ruins e seis meses depois decidiu usar o serviço como pretendido. Ele registrou sua conta real: fotos reais, nome etc. Naturalmente, nosso mecanismo de pesquisa de contas semelhantes descobriu rapidamente e colocou-o na proibição Stealth. Depois disso, ele escreveu por seis meses no vazio que estava muito sozinho, ninguém respondeu. Em geral, ele derramou toda a sua alma no nevoeiro de Silent Hill, mas não recebeu nenhuma resposta.
Os spammers, é claro, não são tolos. Eles estão tentando, de alguma forma, determinar que entraram na caixa de areia e foram bloqueados, encerraram a conta antiga e encontraram uma nova. Às vezes até chegamos à ideia de que seria bom enviar vários desses spammers para a sandbox juntos, para que eles vendessem um ao outro tudo o que quisessem e se divertissem como quiser. Porém, embora não tenhamos chegado a esse ponto, estamos desenvolvendo outros métodos, por exemplo, verificação de foto e telefone.

Como você sabe, é difícil para um spammer que é um bot e não uma pessoa passar na verificação por telefone ou foto.
No nosso caso, a verificação por foto é assim: o usuário é solicitado a tirar uma foto com um certo gesto, a foto resultante é comparada com as fotos que já estão carregadas no perfil. Se os rostos são os mesmos, provavelmente a pessoa é real, carregou suas fotos reais e pode ser deixada para trás por algum tempo.
Não é fácil para os spammers passarem neste teste. Temos até um pequeno jogo dentro da empresa chamado Guess Who the Spammer. Dadas quatro fotos, você precisa entender qual delas é um spammer.
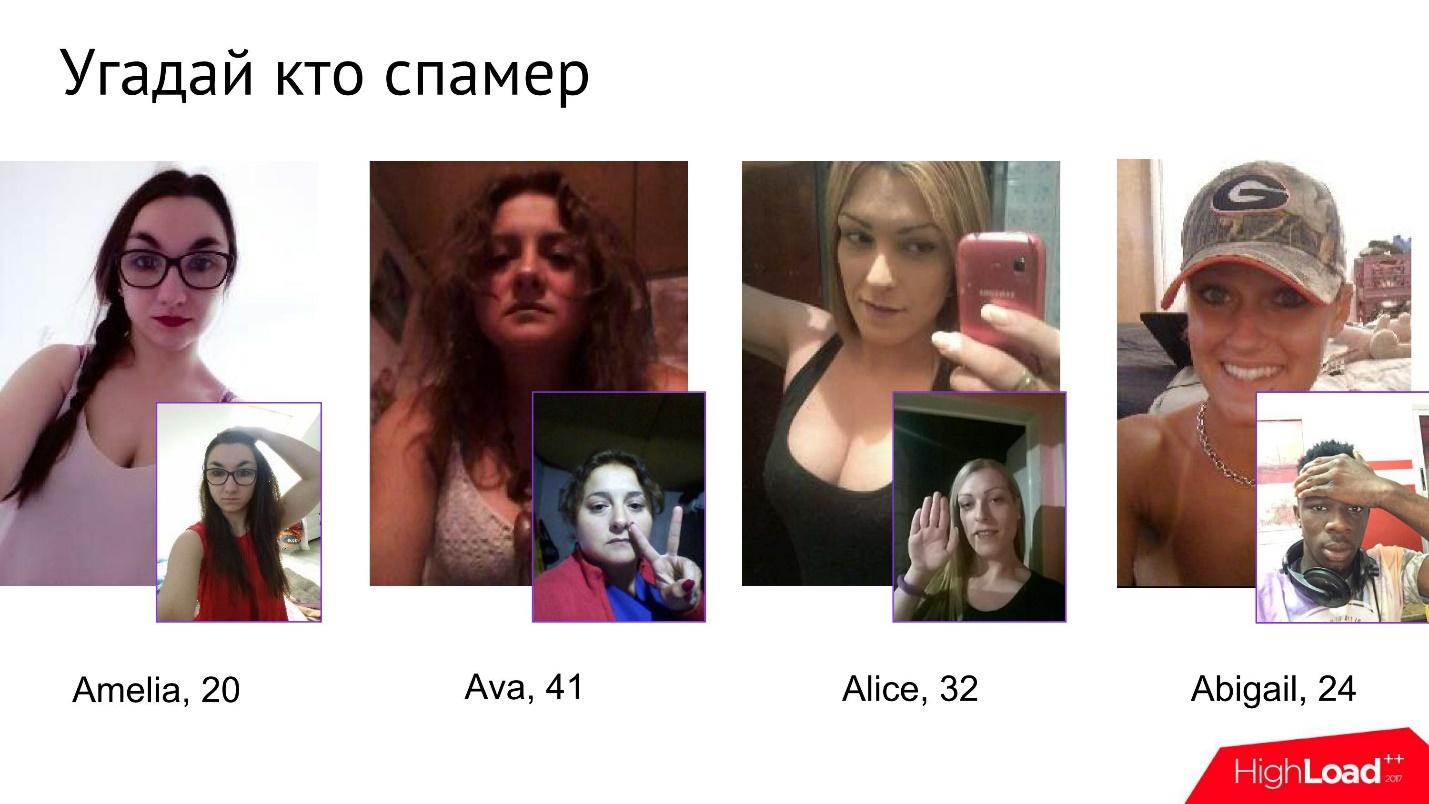
À primeira vista, essas meninas parecem completamente inofensivas, mas assim que começam a ser submetidas à verificação de fotos, a partir de algum ponto, fica claro que uma delas não é completamente o que ela afirma ser.
De qualquer forma, os spammers têm dificuldade em combater a verificação de fotos. Eles realmente sofrem, tentam contornar isso, enganar e demonstrar todas as suas habilidades no photoshop.

Os spammers estão fazendo tudo o que podem e, às vezes, pensam, provavelmente, que tudo isso é completamente processado por algumas tecnologias modernas incríveis, tão mal construídas que são tão fáceis de enganar.
Eles não sabem que cada foto é novamente verificada manualmente pelos moderadores.
Sem tempo
De fato, apesar de termos encontrado várias maneiras de dificultar a vida dos spammers, geralmente não há tempo suficiente, porque o anti-spam deve funcionar instantaneamente. Ele deve encontrar e neutralizar o usuário antes de iniciar sua atividade negativa.
A melhor coisa que pode ser feita é determinar, no estágio de registro, que o usuário não é muito bom. Isso pode ser feito, por exemplo, usando cluster.
Cluster de usuário
Podemos coletar todas as informações possíveis logo após o registro. Ainda não temos dispositivos com os quais o usuário efetua login, nem fotografias, não há estatísticas. Não temos nada para enviá-lo para verificação, ele não fez nada de suspeito. Mas já temos informações primárias:
- sexo
- idade
- país de registro;
- país e provedor de IP;
- Domínio de email
- operadora de telefonia (se houver);
- dados do fb (se houver) - quantos amigos ele tem, quantas fotos ele carregou, quanto tempo ele se registrou lá, etc.
Todas essas informações podem ser usadas para localizar clusters de usuários. Utilizamos o algoritmo de agrupamento
K-means simples e popular. É perfeitamente implementado em qualquer lugar, é suportado em qualquer biblioteca MachineLearning, é perfeitamente paralelo, funciona rapidamente. Existem versões de streaming desse algoritmo que permitem distribuir usuários em clusters em tempo real. Mesmo em nossos volumes, tudo isso funciona muito rapidamente.
Após receber esses grupos de usuários (clusters), podemos executar qualquer ação. Se os usuários forem muito parecidos (o cluster está altamente conectado), provavelmente esse é o registro em massa, ele deve ser interrompido imediatamente. O usuário ainda não teve tempo de fazer nada, apenas clicou no botão "Registrar" - e isso é tudo, ele já entrou na caixa de areia.
As estatísticas podem ser coletadas nos clusters - se 50% do cluster estiver bloqueado, os 50% restantes poderão ser enviados para verificação ou moderados individualmente todos os clusters manualmente, examinar os atributos pelos quais eles coincidem e tomar uma decisão. Com base nesses dados, os analistas podem identificar padrões.
Padrões
Padrões são conjuntos dos atributos de usuário mais simples que conhecemos imediatamente. Alguns dos padrões realmente funcionam de maneira muito eficaz contra certos tipos de spammers.
Por exemplo, considere uma combinação de três atributos completamente independentes e bastante comuns:
- O usuário está registrado nos EUA;
- Seu provedor é Privax LTD (operador de VPN);
- Domínio de email: [mail.ru, list.ru, bk.ru, inbox.ru].
Esses três atributos, aparentemente separadamente representando nada de si mesmos, juntos dão a probabilidade de que seja um spammer, quase 90%.
Você pode extrair esses padrões quantos desejar para cada tipo de spammer. Isso é muito mais eficiente e fácil do que exibir manualmente todas as contas ou até clusters.
Cluster de texto
Além de agrupar usuários por atributos, você pode encontrar usuários que escrevem os mesmos textos. Claro, isso não é tão simples. O fato é que nosso serviço funciona em muitos idiomas. Além disso, os usuários costumam escrever com abreviações, gírias, às vezes com erros. Bem, as próprias mensagens são geralmente muito curtas, literalmente de 3-4 palavras (cerca de 25 caracteres).
Portanto, se queremos encontrar textos semelhantes entre os bilhões de mensagens que os usuários escrevem, precisamos criar algo incomum. Se você tentar usar métodos clássicos com base na análise da morfologia e no processamento honesto verdadeiro da linguagem, então com todas essas restrições, gírias, acrônimos e várias línguas, isso é muito difícil.
Você pode fazer um pouco mais simples - aplicar o algoritmo
n-gram . Cada mensagem que aparece é dividida em n gramas. Se n = 2, esses são bigrams (pares de letras). Gradualmente, a mensagem inteira é dividida em pares de letras e as estatísticas são coletadas, quantas vezes cada bigrama ocorre no texto.

Você não pode parar em bigrams, mas adicione trigramas, skipgrams (estatísticas de letras após 1, 2, etc.). Quanto mais informações obtivermos, melhor. Mas mesmo os bigrams já funcionam muito bem.
Em seguida, obtemos um vetor dos bigrams de cada mensagem cujo comprimento é igual ao quadrado do comprimento do alfabeto.
É muito conveniente trabalhar com esse vetor e agrupá-lo, porque:
- consiste em números;
- comprimido, não há espaços vazios;
- tamanho sempre fixo.
- o algoritmo k-means com vetores compactados de tamanho fixo é muito rápido. Nossos bilhões de mensagens estão agrupados literalmente em alguns minutos.
Mas isso não é tudo. Infelizmente, se simplesmente coletarmos todas as mensagens com frequência semelhante aos bigrams, obteremos mensagens com frequência semelhante aos bigrams. No entanto, eles não precisam ter, de fato, pelo menos um significado semelhante. Muitas vezes, existem textos longos nos quais os vetores são muito próximos, quase os mesmos, mas os textos em si são completamente diferentes. Além disso, a partir de um determinado comprimento de texto, esse método de agrupamento geralmente para de funcionar, porque as frequências dos bigrams são iguais.

Portanto, você precisa adicionar a filtragem. Como os clusters já existem, eles são muito pequenos, podemos filtrar facilmente dentro do cluster usando Stemming ou Bag of Words. Dentro de um pequeno cluster, você pode literalmente comparar todas as mensagens com todos e obter o cluster no qual são garantidas as mesmas mensagens que coincidem não apenas nas estatísticas, mas também na realidade.
Portanto, fizemos clustering - e, no entanto, para nós (e para clustering) é muito importante saber a verdade sobre o usuário. Se ele está tentando esconder a verdade de nós, precisamos agir.
— VPN, TOR, Proxy, . , , , .
, , « IP».

VPN — , IP- , IP- VPN, Proxy .
:
- ISP (Internet Service Provider), IP- . , .
- Whois . IP- Whois : ; ; , IP-; , IP- .. , IP-.
- GeolP. , IP- , , IP- , , , IP- - .
- — IP- , GeolP, Whois, .
, , , IP- VPN .
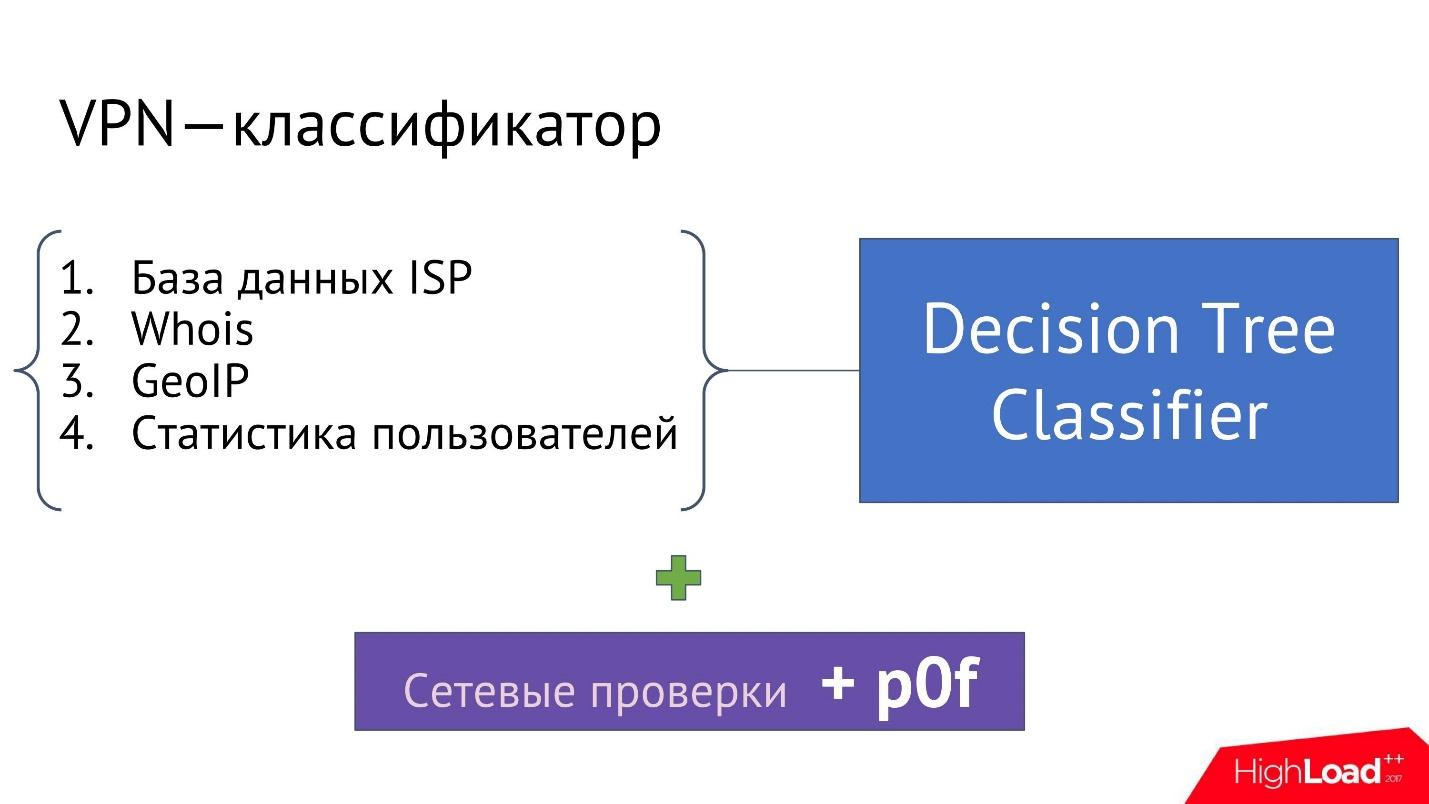
, — , , .., , IP- VPN.
, . , advanced-, 100% . .
, IP- VPN, , IP- . , , . SOCKS-proxy, IP- .
, , ,
p0f . , fingerprinting , : , VPN-, Proxy .. , .
, , , , , : ? — ! , , , .
— ? . 2 , .
, , , , , , , .

, , ?
«User Decency»
— , .
«» :
.
. , , , .
, , «
». , , , , . .
1, , , , — .
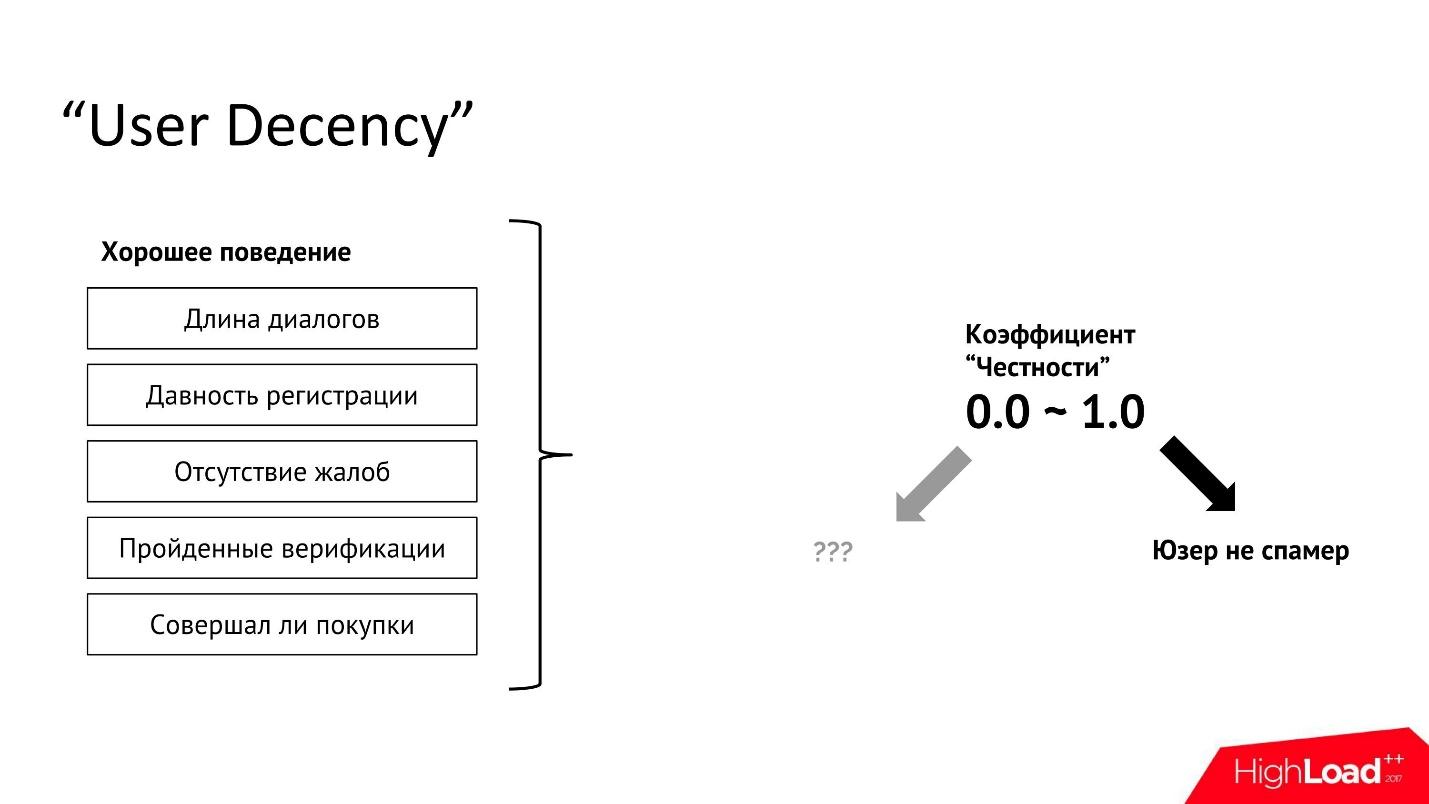
.
False positive
, — . , IP-. , -, . , fingerprint, , , — , , , , - .
: : «, — Pornhub — ?» , - , .
. , , , .
- «Pornhub». - , - .
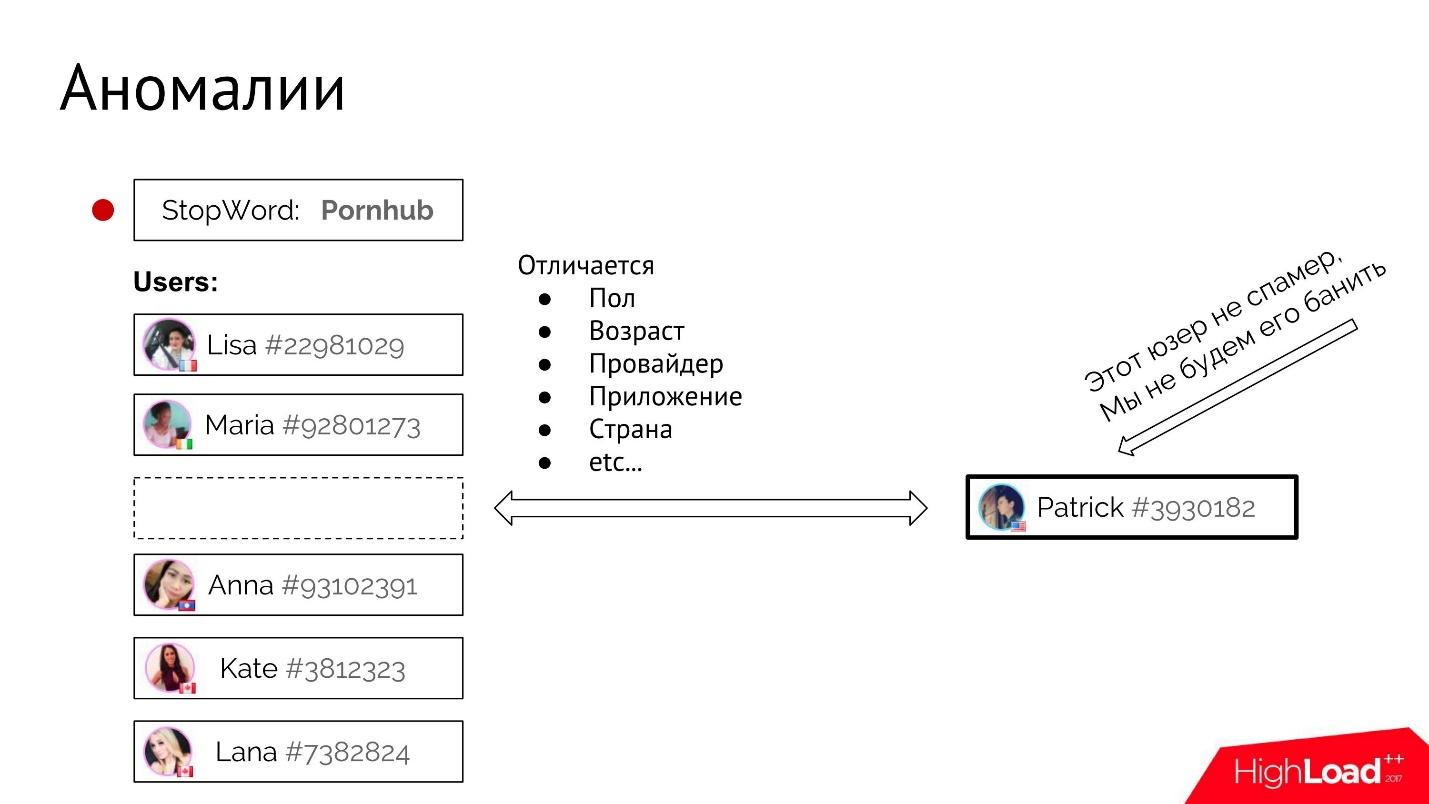
- -, .
, , . : , , , , .. , «» . , , , . , , .
, .
-
— MachineLearning, , 0 1 — .
, ,
, . , , . , - , .
, — . — , .
, ( ) , , . , , , : , , . .
HighLoad++ 2018 , , :
- ML- ,
- NVIDIA , .
- use case .
youtube- , — , .