Outra conversa com o
Pixonic DevGAMM Talks - desta vez de nossos colegas do PanzerDog. O engenheiro líder de software da empresa Pavel Platto desmontou o meta-servidor do jogo com uma arquitetura orientada a serviços, informou quais soluções e tecnologias foram escolhidas, o que e como elas foram dimensionadas e quais dificuldades tiveram que enfrentar. O texto do relatório, slides e links para outros discursos do mitap, como sempre, sob o corte.
Primeiro, quero demonstrar um pequeno trailer do nosso jogo:
O relatório consistirá em 3 partes. No primeiro, falarei sobre quais tecnologias escolhemos e por que, no segundo - como o nosso meta-servidor está organizado, e no terceiro, sobre as várias infra-estruturas de suporte que usamos e como implementamos a atualização sem tempo de inatividade .
 Pilha tecnológica
Pilha tecnológicaO meta servidor está hospedado na Amazon e escrito em Elixir. É uma linguagem de programação funcional com um modelo de ator de computação. Como não temos Ops, os programadores estão envolvidos na operação e a maior parte da infraestrutura é descrita como código usando o HashiCorp Terraform.
Atualmente, o Tacticool está em beta aberto, o meta servidor está em desenvolvimento há pouco mais de um ano e está em operação há quase um ano. Vamos ver como tudo começou.

Quando entrei na empresa, já tínhamos funcionalidades básicas implementadas como um monólito em um mix C / C ++ e armazenamento PostageSQL. Esta implementação teve alguns problemas.
Em primeiro lugar, devido ao baixo nível de C, havia alguns bugs evasivos. Por exemplo, para alguns jogadores, as partidas ficam travadas devido ao zeramento incorreto da matriz antes de sua reutilização. Obviamente, encontrar a relação entre esses dois eventos foi bastante difícil. E como o estado de vários encadeamentos foi universalmente modificado no código, as condições de corrida não deixaram de existir.
O processamento paralelo de um grande número de tarefas também estava fora de questão, porque o servidor iniciou no início de cerca de 10 processos de trabalho, que foram bloqueados por consultas à Amazon ou ao banco de dados. E mesmo se esquecermos dessas solicitações de bloqueio, o serviço começou a desmoronar em algumas centenas de conexões que não realizavam nenhuma operação, exceto o ping. Além disso, o serviço não pôde ser dimensionado horizontalmente.
Depois de algumas semanas procurando e corrigindo os bugs mais críticos, decidimos que era mais fácil reescrever tudo do zero do que tentar corrigir todas as deficiências da solução atual.
E quando você começa do zero, faz sentido tentar escolher um idioma que ajude a evitar alguns dos problemas anteriores. Tivemos três candidatos:

C # estava na lista de "conhecidos", como o cliente e o servidor do jogo são escritos no Unity, e a maior parte da experiência da equipe foi com essa linguagem de programação. Go e Elixir foram considerados porque são linguagens modernas e bastante populares criadas para o desenvolvimento de aplicativos de servidor.
Os problemas da iteração anterior nos ajudaram a determinar os critérios para avaliar os candidatos.
O primeiro critério foi a conveniência de trabalhar com operações assíncronas. No C #, o trabalho conveniente com operações assíncronas não apareceu na primeira tentativa. Isso levou ao fato de termos um “zoológico” de soluções que, na minha opinião, ainda estão um pouco de lado. No Go e Elixir, esse problema foi levado em consideração ao projetar essas linguagens, ambos usam threads leves (no Go são goroutines, no Elixir são processos). Esses fluxos têm uma sobrecarga muito menor que os encadeamentos do sistema e, como podemos criá-los em dezenas e centenas de milhares, não lamentamos bloqueá-los.
O segundo critério foi a capacidade de trabalhar com processos competitivos. O C # pronto para uso não oferece nada além de conjuntos de threads e memória compartilhada, cujo acesso deve ser protegido usando várias primitivas de sincronização. O Go possui um modelo menos propenso a erros na forma de goroutines e canais. O Elixir, por outro lado, oferece um modelo de ator sem memória compartilhada com mensagens. A falta de memória compartilhada tornou possível implementar tecnologias úteis para um ambiente de execução competitivo em tempo de execução, como multitarefa de take-away honesta e coleta de lixo sem interrupções no mundo.
O terceiro critério foi a disponibilidade de ferramentas para trabalhar com tipos de dados imutáveis. Toda a minha experiência em desenvolvimento mostrou que uma parte bastante grande dos erros está associada a alterações incorretas dos dados. Uma solução para isso existe há muito tempo - tipos de dados imutáveis. Em C #, esses tipos de dados podem ser criados, mas ao custo de uma tonelada de clichê. No Go, isso não é possível. E no Elixir, todos os tipos de dados são imutáveis.
E o último critério foi o número de especialistas. Aqui os resultados são óbvios. No final, optamos pelo Elixir.
Com a escolha da hospedagem, tudo ficou muito mais simples. Já hospedamos servidores de jogos no Amazon GameLift. Além disso, a Amazon oferece um grande número de serviços que nos permitiriam reduzir o tempo de desenvolvimento.
Nós nos rendemos completamente à nuvem e não implantamos nenhuma solução de terceiros - bancos de dados, filas de mensagens - tudo isso é gerenciado pela Amazon para nós. Na minha opinião, esta é a única solução para uma equipe pequena que deseja desenvolver um jogo online, e não a infraestrutura para ele.
Descobrimos a escolha das tecnologias, vamos seguir como o servidor meta funciona.
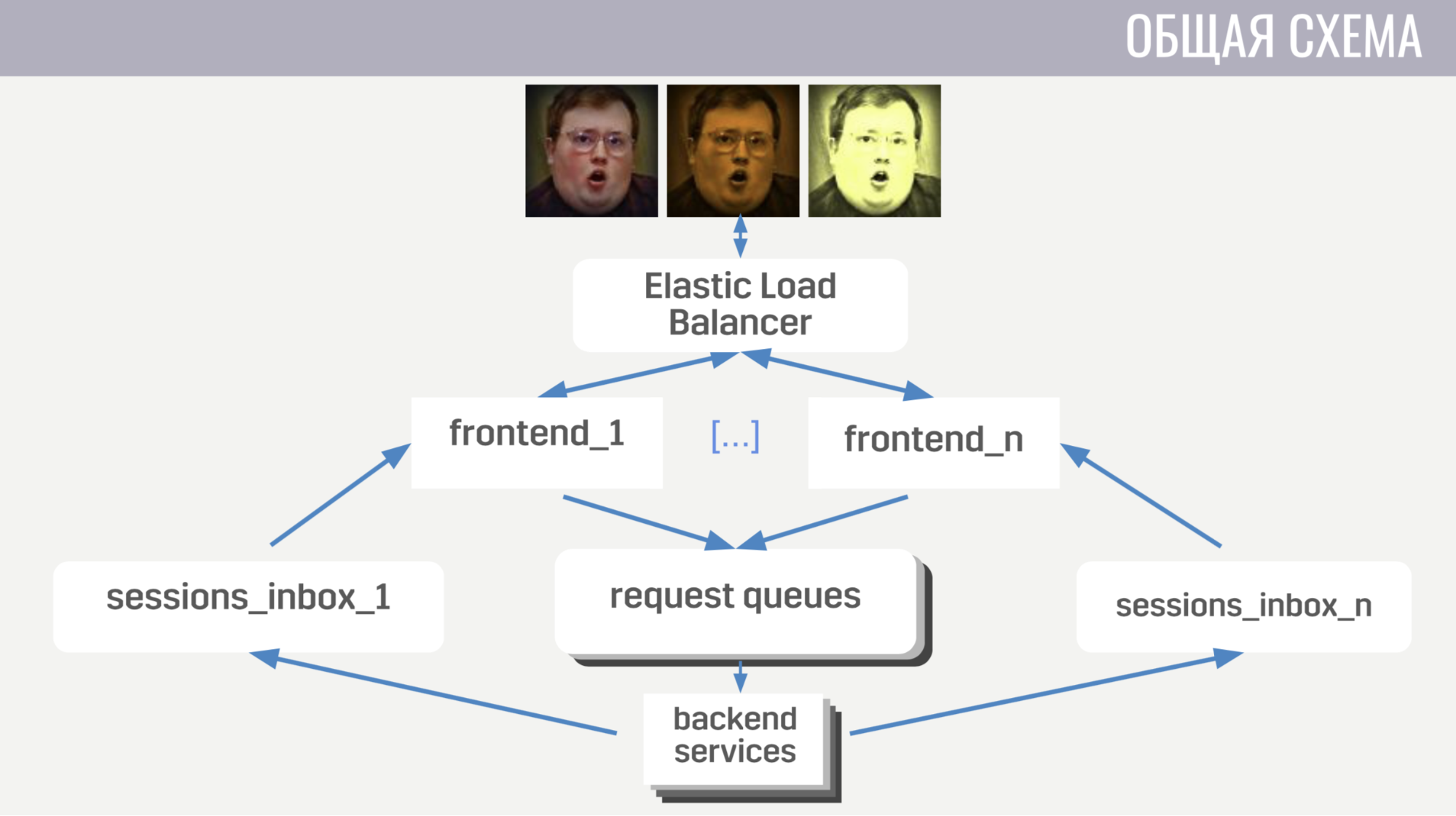
Em geral: os clientes se conectam ao balanceador de carga da Amazon por meio de conexões de soquete da web; o balanceador dispersa essas conexões entre várias instâncias de front-end, o front-end envia solicitações de cliente para back-end. Mas o front-end e o back-end se comunicam indiretamente, por meio de filas de mensagens. Há uma fila separada para cada tipo de mensagem, e o front-end, pelo tipo de mensagem, determina onde escrevê-la, e os back-end escutam essas filas.
Para que o back-end possa enviar uma resposta à solicitação ao cliente ou algum tipo de evento, cada front-end possui uma fila separada (especialmente alocada para ele). E em cada solicitação, o back-end recebe um identificador de front-end para determinar em qual fila a resposta deve ser gravada. Se ele precisar enviar um evento, ele chamará o banco de dados para descobrir a qual instância de front-end o cliente está conectado.
Com o esquema geral, vamos aos detalhes.

Primeiramente, falarei sobre alguns recursos da interação cliente-servidor. Utilizamos nosso protocolo binário porque é bastante eficiente e permite economizar tráfego. Em segundo lugar, para quaisquer operações com uma conta que a altere, o servidor não envia essas alterações para o cliente, mas a versão completa (atualizada) desta conta. Isso é um pouco menos eficiente, mas não ocupa muito espaço e simplifica bastante nossa vida no cliente e no servidor. Além disso, o front-end garante que o cliente não execute mais de uma solicitação por vez. Isso permite capturar erros no cliente, por exemplo, quando ele alterna para outra tela antes de o jogador ver o resultado da operação anterior.
Agora, um pouco sobre como o frontend está organizado.

Um front-end é essencialmente um servidor Web que escuta conexões de soquete da Web. Para cada sessão, dois processos são criados. O primeiro processo atende à própria conexão do soquete da Web e o segundo é uma máquina de estado que descreve o estado atual do cliente. Com base nesse estado, determina a validade das solicitações do cliente. Por exemplo, quase todas as solicitações não podem ser concluídas até que a autorização seja concluída. Como não há estado no frontend além dessas sessões, é muito fácil adicionar novas instâncias de frontend, mas é um pouco mais difícil excluir as antigas. Antes de desinstalar, você precisa permitir que todos os clientes concluam suas solicitações atuais e solicite que eles se reconectem a outra instância.
Agora, sobre a aparência do back-end. No momento, ele consiste em cinco serviços.
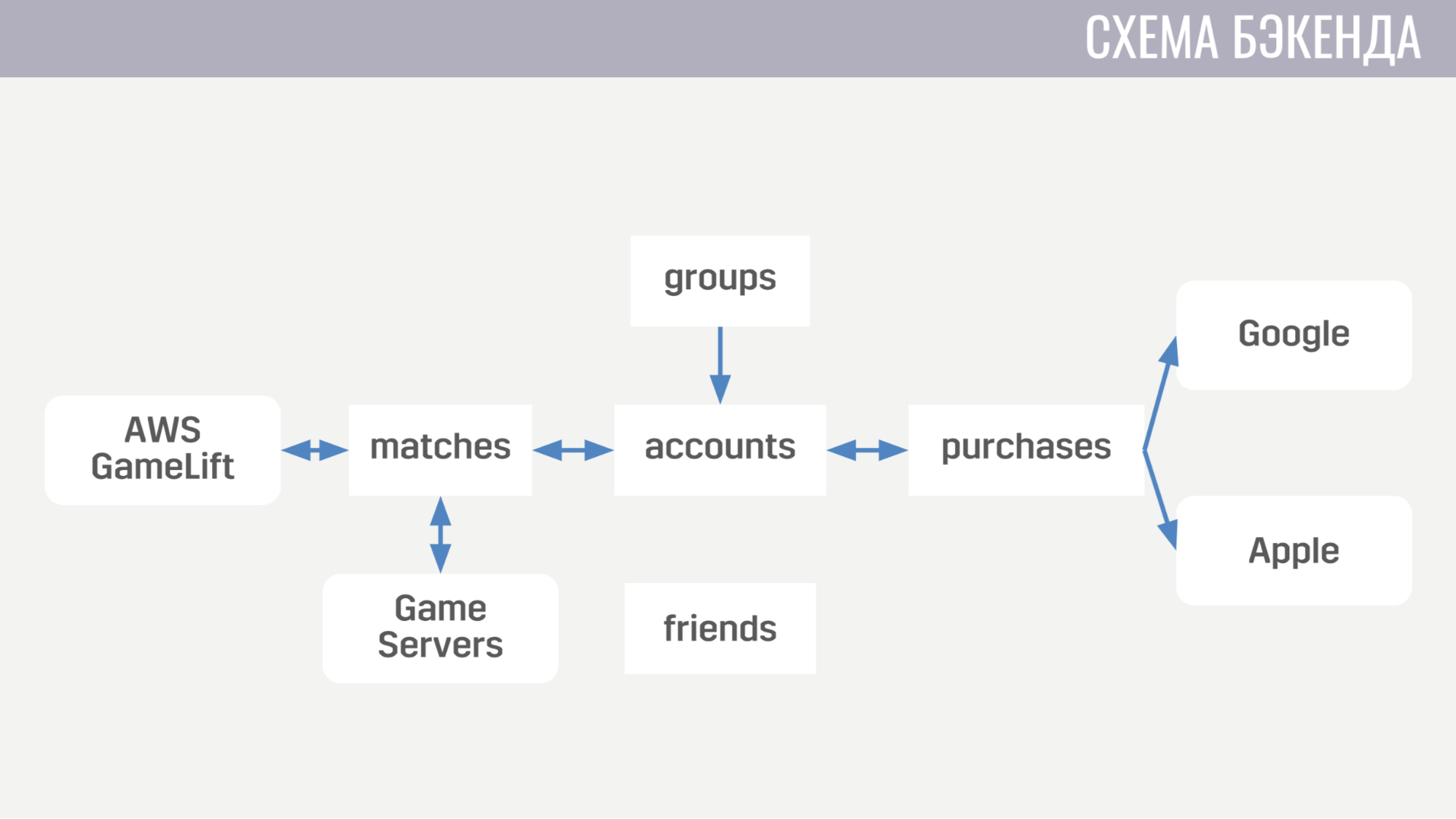
O primeiro trata de tudo relacionado a contas - desde compras de moeda no jogo até a conclusão de missões. O segundo trabalha com tudo relacionado a jogos - ele interage diretamente com o GameLift e os servidores de jogos. O terceiro serviço é comprar dinheiro real. O quarto e o quinto são responsáveis pelas interações sociais - uma para os amigos e a outra para um jogo de festa.
Cada um dos serviços de back-end do ponto de vista da arquitetura parece absolutamente idêntico. Eles são um conjunto de pipelines, cada um dos quais processa um tipo de mensagem. O pipeline consiste em dois elementos: produtor e consumidor.

A única tarefa do produtor é ler as mensagens da fila. Portanto, é implementado de uma forma completamente geral e, para cada pipeline, precisamos apenas indicar quantos produtores existem, de qual fila ler e quantos consumidores cada produtor atenderá. O consumidor, por outro lado, é implementado separadamente para cada pipeline e é um módulo com a única função obrigatória que aceita uma mensagem, faz todo o trabalho necessário e retorna uma lista de mensagens que precisam ser enviadas a outros serviços ao cliente ou ao servidor do jogo. O produtor também implementa a contrapressão, para que, com um aumento acentuado no número de mensagens, não haja sobrecarga, e solicite mensagens não mais do que possui consumidores livres.
Os serviços de back-end não contêm nenhum estado; portanto, é fácil adicionar e remover instâncias antigas. A única coisa a fazer antes de excluir é pedir aos produtores que parem de ler novas mensagens e dê aos consumidores um tempo para concluir o processamento das mensagens ativas.
Como acontece a interação com o GameLift? O GameLift consiste em vários componentes. Entre os que usamos, esse é um matchmaker FlexMatch, uma fila de posicionamento que determina em que região específica será realizada uma sessão de jogo com esses jogadores e as próprias frotas, que consistem em servidores de jogos.
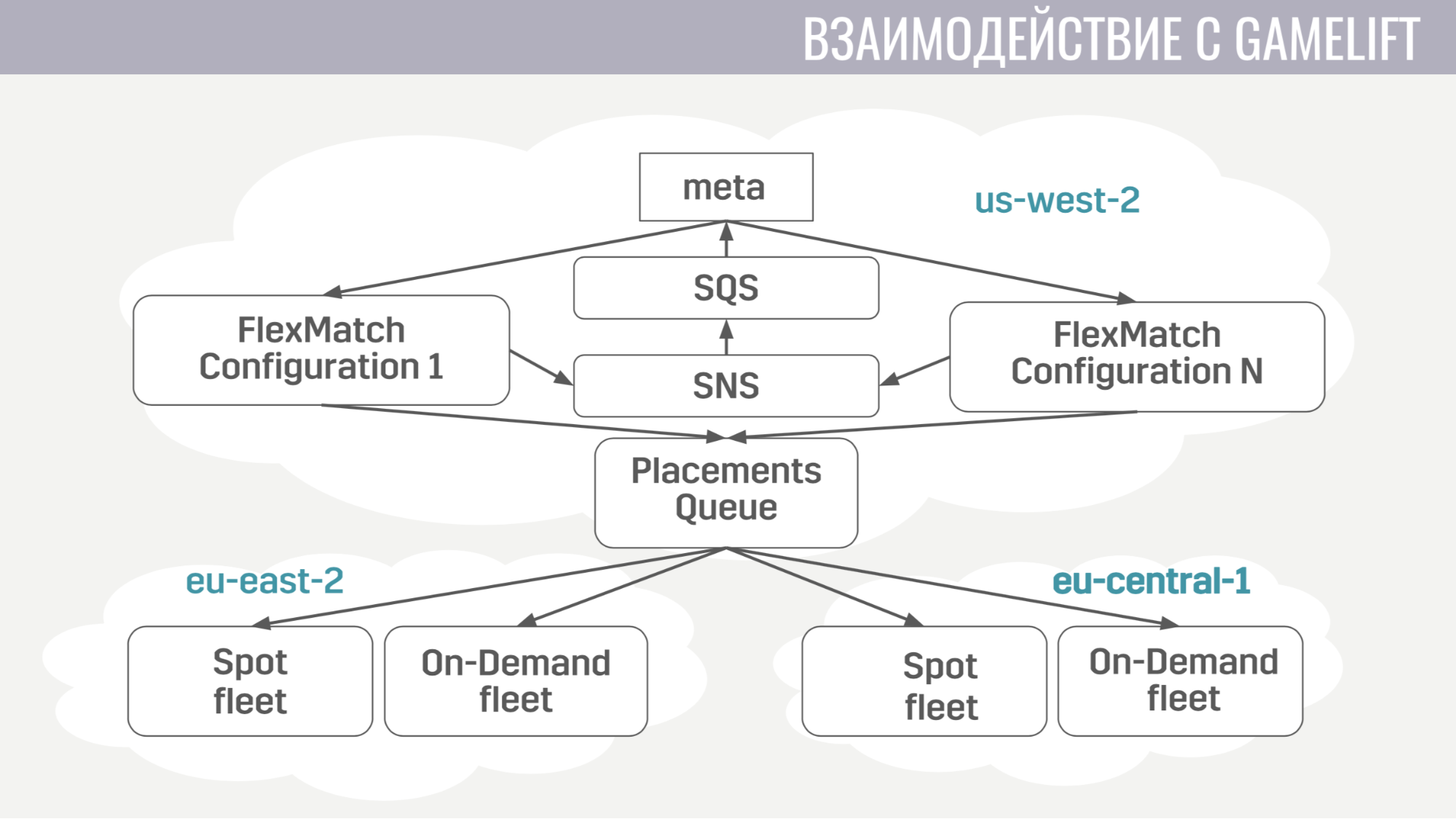
Como está indo essa interação? Meta se comunica diretamente apenas com o casamenteiro, envia pedidos para encontrar a partida. E ele notifica a meta de todos os eventos durante as partidas através das mesmas filas de mensagens. E assim que encontra um grupo adequado de jogadores para iniciar a partida, ele envia uma solicitação para a fila de colocação, que por sua vez seleciona um servidor para eles.
A interação da meta com o servidor do jogo é extremamente simples. O servidor do jogo precisa de informações sobre contas, bots e um mapa, e a meta envia todas essas informações para a fila criada especificamente para essa partida em uma única mensagem.

E o servidor do jogo, após a ativação, começa a ouvir essa fila e recebe todos os dados necessários. No final da partida, ele envia seus resultados para a fila geral que a meta está ouvindo.
Agora vamos para a infraestrutura adicional que usamos.

A implantação de serviços é bastante simples. Todos eles trabalham em contêineres de encaixe e usamos o Amazon ECS para orquestração. É muito mais simples que o Kubernetes, é claro, menos sofisticado, mas executa as tarefas que precisamos dele. A saber: serviços de escala e lançamentos contínuos, quando precisamos preencher algum tipo de correção de bug.
E o último serviço que também usamos é o AWS Fargate. Isso evita que tenhamos que gerenciar de forma independente o cluster de máquinas nas quais nossos contêineres docker são executados.

Como armazenamento principal, usamos o DynamoDB. Primeiro, escolhemos porque é muito fácil de operar e dimensionar. Também usamos o Redis como armazenamento adicional por meio do serviço gerenciado Amazon ElasiCache. Nós o usamos para a tarefa de classificação global de jogadores e para armazenar informações básicas da conta em cache em situações em que precisamos retornar dados de centenas de contas de jogos para o cliente imediatamente (por exemplo, na mesma tabela de classificação ou na lista de amigos).
Para armazenar configurações, mecânica de meta-jogabilidade, descrições de armas, heróis, etc. usamos um arquivo JSON que anexamos às imagens dos serviços que precisam dele. Como é muito mais fácil lançar uma nova versão do serviço com dados atualizados (se algum bug foi descoberto) do que tomar uma decisão que atualizará dinamicamente esses dados de algum armazenamento externo em tempo de execução.
Para registro e monitoramento, usamos muitos serviços.
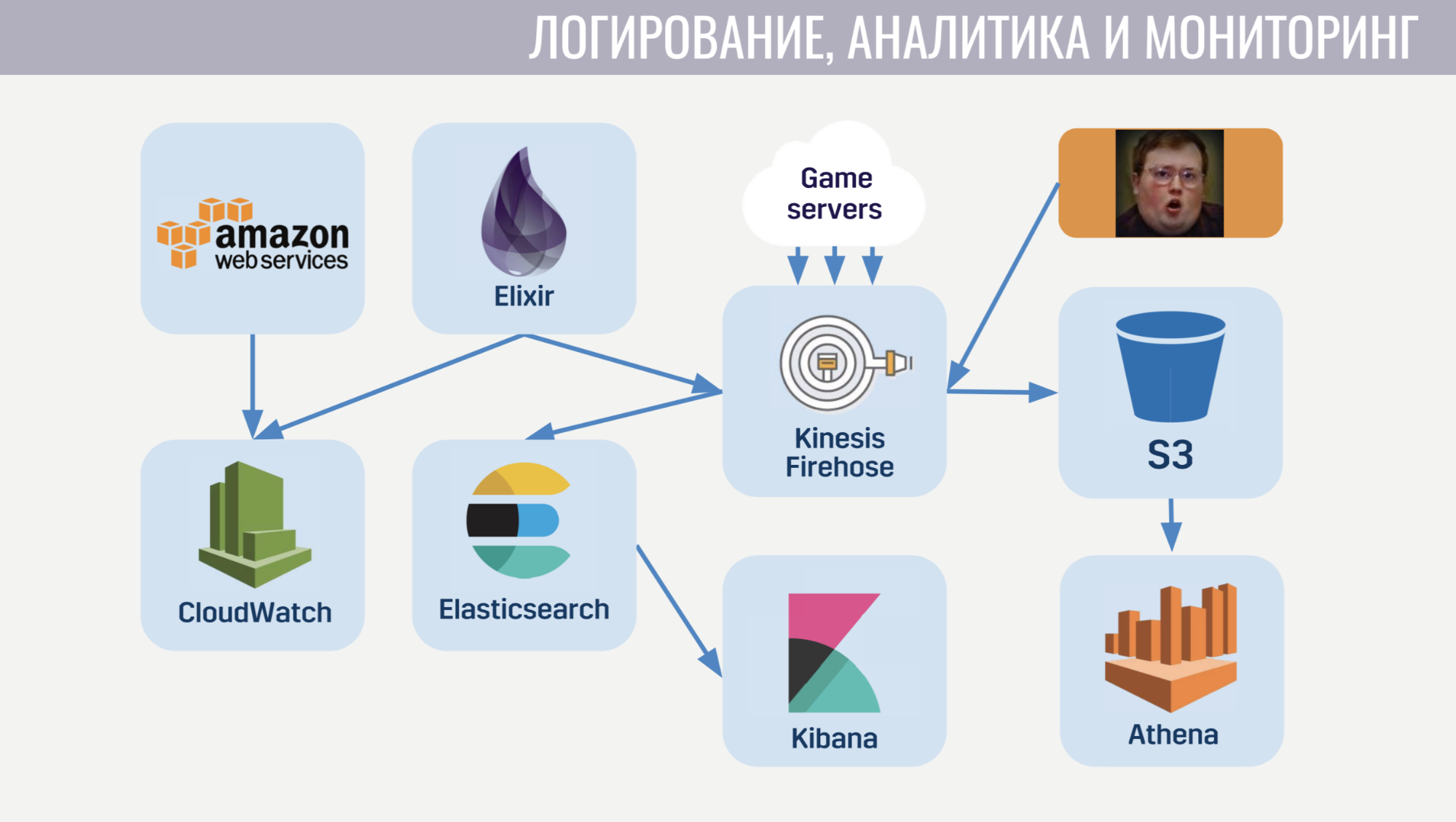
Vamos começar com o CloudWatch. Este é um serviço de monitoramento no qual as métricas de todos os serviços da Amazon se agrupam. Portanto, decidimos enviar as métricas do nosso meta servidor para lá também. E para o registro, usamos uma abordagem comum no cliente e no servidor do jogo e no meta servidor. Enviamos todos os logs para o serviço amazônico Kinesis Firehose, que por sua vez os transfere para Elasticseach e S3.
No Elasticseach, armazenamos apenas dados relativamente recentes e, com a ajuda do Kibana, procuramos erros, resolvemos algumas das tarefas de análise de jogos e construímos painéis operacionais, por exemplo, com um cronograma da CCU e o número de novas instalações. O S3 contém todos os dados históricos e os usamos através do serviço Athena, que fornece uma interface SQL sobre os dados no S3.
Agora um pouco sobre como usamos o Terraform.

O Terraform é uma ferramenta que permite descrever declarativamente a infraestrutura e, se houver alguma alteração na descrição, ela determina automaticamente as ações que você precisa executar para trazer sua infraestrutura a uma aparência atualizada. Assim, tendo uma descrição única, obtemos um ambiente quase idêntico para preparação e produção. Além disso, esses ambientes são completamente isolados, porque são implantados em contas diferentes. A única desvantagem significativa do Terraform para nós é o suporte incompleto do GameLift.
Também falarei sobre como implementamos a atualização sem tempo de inatividade.

Quando lançamos atualizações, criamos uma cópia da maioria dos recursos: serviços, filas de mensagens, alguns rótulos no banco de dados. E os jogadores que baixarem a nova versão do jogo se conectarão a esse cluster atualizado. Mas os jogadores que ainda não atualizaram podem continuar jogando por algum tempo na versão antiga do jogo, conectando-se ao cluster antigo.
Como nós o implementamos. Primeiramente, usando o mecanismo de módulo no Terraform. Alocamos um módulo no qual descrevemos todos os recursos com versão. E esses módulos podem ser importados várias vezes, com parâmetros diferentes. Assim, para cada versão, importamos este módulo, indicando o número dessa versão. Além disso, a ausência de um esquema no DynamoDB nos ajudou, o que possibilita realizar migrações de dados não durante a atualização, mas adiá-las para cada conta até que o proprietário faça login na nova versão do jogo. E no balanceador, simplesmente indicamos para cada versão da regra para que ela saiba para onde direcionar jogadores com versões diferentes.
Finalmente, algumas coisas que aprendemos. Primeiro, a configuração de toda a infraestrutura deve ser automatizada. I.e. montamos algumas coisas com as mãos por um tempo, mas mais cedo ou mais tarde cometemos um erro nas configurações, por causa das quais houve fakaps.

E a última coisa - você precisa ter uma réplica ou uma cópia de backup para cada elemento da sua infraestrutura. E se você não fizer isso por algo, essa coisa em particular nos decepcionará.
Perguntas da platéia
- Mas não se incomoda com o fato de o escalonamento automático poder ficar muito alto devido a algum tipo de erro e você receberá muito dinheiro?- Para dimensionamento automático, os limites ainda estão definidos. Não definiremos um limite muito grande para não cair em muito dinheiro. Esta é a principal solução + monitoramento. Você pode definir alertas se algo estiver muito forte.
- Quais são seus limites atuais? Relativo à infraestrutura atual como uma porcentagem.- Agora, temos uma fase de teste beta aberto em 11 países, por isso não é uma CCU tão grande avaliar de alguma forma. Agora, a infraestrutura está com excesso de provisionamento para o número de pessoas que temos.
- E ainda não há limites?- Sim, apenas 10 a 100 vezes mais que a nossa UCC. Não faça menos.
- Você disse que tem linhas entre a frente e o back-end - isso é muito incomum. Por que não diretamente?- Queríamos que os serviços sem estado implementassem facilmente o mecanismo de backup, para que o serviço não solicite mais mensagens do que possui manipuladores gratuitos. Além disso, por exemplo, quando um manipulador falha, a fila passa a mesma mensagem para outro manipulador - talvez seja bem-sucedida.
- A fila persiste de alguma forma?Sim. Este é um serviço SQS da Amazônia.
- Em relação às filas: quantos canais são criados durante o jogo? Você tem um certo número de canais para cada partida?- Cria relativamente pouco. A maioria das filas, como filas de solicitação, é estática. Há uma fila de pedidos de autorização, há uma fila para o início da partida. Das filas criadas dinamicamente, só temos filas para cada front-end (ele cria mensagens de entrada para clientes na inicialização) e, para cada correspondência, criamos uma fila. Nesse serviço, não custa quase nada, eles têm qualquer solicitação cobrada da mesma maneira. I.e. qualquer solicitação para o SQS (crie uma fila, leia algo dela) custa o mesmo e, ao mesmo tempo, não excluímos essas filas para salvar, elas serão excluídas mais tarde. E o fato de existirem não nos custa nada.
- Nesta arquitetura, isso não será um limite para você?- não.
Mais conversas com o Pixonic DevGAMM Talks