Muitos dos participantes regulares do
treinamento em ML consideram que participar de concursos é a maneira mais rápida de ingressar na profissão. Até tivemos
um artigo sobre esse assunto. O autor da palestra de hoje, Arthur Kuzin, usando seu próprio exemplo, mostrou como é possível treinar em dois anos a partir de um campo que não está relacionado à programação a um especialista em análise de dados.
Olá pessoal. Meu nome é Arthur Cousin, sou um dos principais cientistas de dados da Dbrain.
Emil tinha um relatório bastante abrangente, falando sobre muitos aspectos. Vou me concentrar no que considero mais importante e divertido. Antes de abordar o tópico do relatório, quero me apresentar. De um modo geral, me formei em Física e, por cerca de 8 anos, a partir do terceiro ano, trabalhei no laboratório, localizado no piso da NK. Este laboratório está envolvido na criação de micro e nanoestruturas.

Todo esse tempo eu trabalhei como pesquisador, e isso não tinha nada a ver com ML ou mesmo com programação. Isso mostra quão baixo é o limite para entrar no aprendizado de máquina, quão rápido você pode desenvolver isso. Além disso, na região de 2013, meus amigos me ligaram para uma startup que estava envolvida em ML. E, durante 2-3 anos, estudei programação e ML ao mesmo tempo. Meu progresso foi bastante lento - estudei os materiais, mergulhei nele, mas não era tão rápido quanto está acontecendo agora. Para mim, tudo mudou quando comecei a participar de competições de ML. A primeira competição foi da Avito, sobre a classificação de carros. Eu realmente não sabia participar, mas consegui ficar em terceiro lugar. Imediatamente depois disso, outra competição começou, já dedicada à classificação dos anúncios. Havia fotos, texto, descrição, preço - era uma competição complexa. Nele, ocupei o primeiro lugar, após o qual quase imediatamente recebi uma oferta e eles me levaram a Avito. Então não havia uma posição júnior, fui levado imediatamente pelo meio - quase sem experiência relevante.
Além disso, quando eu já estava trabalhando na Avito, comecei a participar de competições no Kaggle e em cerca de um ano recebi grandes mestres. Agora estou na 58ª posição no ranking geral. Este é o meu perfil. Tendo trabalhado no Avito por um ano e meio, mudei-me para Dbrain e agora sou um pouco diretor de ciência de dados, coordenando o trabalho de sete cientistas de dados. Tudo o que uso no meu trabalho aprendi nas competições. Portanto, acredito que este é um tópico muito interessante e, de todas as maneiras possíveis, defendo a participação em competições e o desenvolvimento.
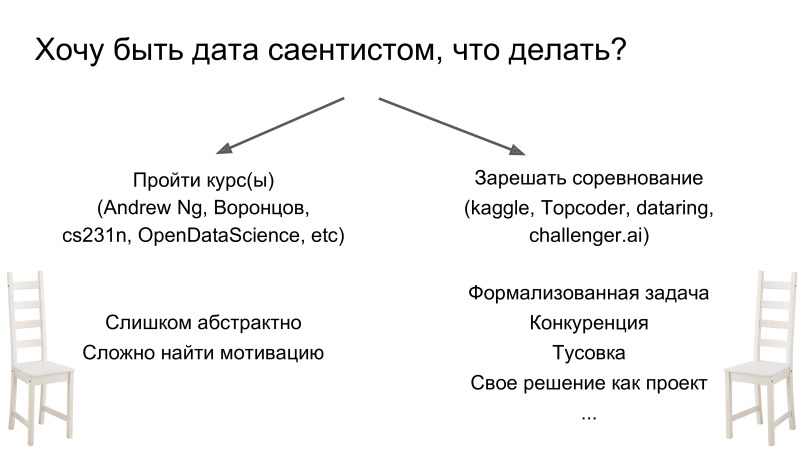
Às vezes, eles me perguntam o que precisa ser feito se você deseja se tornar um cientista de dados. Existem duas maneiras. Primeiro ouça algum curso. Existem muitos deles, todos eles são de alta qualidade. Mas para mim, pessoalmente, não funciona. Todas as pessoas são diferentes, mas eu não gosto disso, simplesmente porque, em regra, os cursos são tarefas muito abstratas e, quando passo uma seção, nem sempre entendo por que preciso conhecê-lo. Em contraste com essa abordagem, você pode simplesmente aceitar e começar a resolver a concorrência. E este é um fluxo completamente diferente em termos de abordagem. A diferença é que você adquire imediatamente uma certa quantidade de conhecimento e começa a estudar um novo tópico quando se depara com um desconhecido. Ou seja, você começa a decidir e entender que não possui conhecimento sobre como treinar uma rede neural. Você pega, pesquisa e estuda - somente quando você precisar. É muito simples em termos de motivação, progresso, porque você já possui uma tarefa estritamente formulada no âmbito da competição, uma métrica de objetivo e muito apoio em termos de bate-papo sobre ciência de dados abertos. E, como um bônus distante, é que sua decisão será um projeto que ainda não está lá.

Por que é tão divertido? De onde vêm as emoções positivas? A idéia é que, quando você envia uma inscrição e ela é um pouco melhor que a anterior, eles dizem - você melhorou a métrica, é legal. Você sobe na tabela de classificação. Por outro lado, se você não fizer nada e não enviar envios, será desativado. E isso gera um feedback: você se sente bem quando avança e vice-versa. Esse é um mecanismo legal que explora, ao que parece, apenas o Kaggle. E outro ponto: o Kaggle explora o mesmo mecanismo de dependência das máquinas caça-níqueis e do Tinder. Você não sabe se o seu envio é melhor ou pior. Isso causa uma expectativa de um resultado desconhecido para você. Assim, o Kaggle é altamente viciante, mas é bastante construtivo: você desenvolve e tenta melhorar sua decisão.
Como obter a primeira dose? Você precisa entrar na seção de kernels. Eles colocam alguns pedaços de pipeline ou toda a solução. Uma pergunta separada é por que as pessoas fazem isso. Um homem passou um tempo desenvolvendo - qual o sentido de publicá-lo? Eles podem tirar vantagem e ignorar o autor.
A idéia é que, em primeiro lugar, as melhores soluções não sejam apresentadas. Como regra geral, essas soluções não são ideais do ponto de vista dos modelos de treinamento, elas não têm todas as nuances, mas existe todo um pipeline do começo ao fim para que você não resolva tarefas rotineiras relacionadas ao processamento de dados, pós-processamento, pós-coleta, etc. Isso está diminuindo o limite de entrada para atrair novos participantes. Você precisa entender que a comunidade de cientistas de dados é muito aberta à discussão e, em geral, bastante positiva. Eu não vi isso na comunidade científica. A principal motivação é que novas pessoas venham com novas idéias. Desenvolve a discussão do problema, a concorrência e permite que toda a comunidade se desenvolva.
Se você tomou a decisão de outra pessoa, lançou-a e começou a treinar, a próxima coisa que recomendo é analisar os dados. Conselho banal, mas você não vai acreditar quantas pessoas de cima não o usam. Para entender por que isso é importante, aconselho você a ver o relatório de Eugene Nizhibitsky. Ele fala sobre os
rostos nas competições de filmes e sobre o
rosto na Airbus , que também pode ser visto simplesmente olhando os dados. Isso não leva muito tempo e ajuda a entender o problema. E os rostos nas fotos eram sobre o fato de que em diferentes plataformas e competições diferentes era possível obter respostas de teste do trem. Ou seja, não foi possível treinar nenhum modelo, mas apenas observe os dados e entenda como você pode coletar as respostas para o seu teste - parcial ou completamente. Esse é um hábito que é importante não apenas nas competições, mas também na prática real, quando você trabalha com cientistas de dados. Na vida real, muito provavelmente, a tarefa será mal formulada. Você não a formula, mas precisa entender qual é a essência e a essência dos dados. O hábito de olhar para os dados é muito importante, gaste tempo com eles.
Em seguida, você precisa entender qual é a tarefa. Se você analisou os dados e entendeu qual é o alvo ... Você, se bem entendi, em sua maioria, é de Fiztekh. Você deve ter um pensamento crítico que o levante à questão: por que as pessoas que criaram a competição fizeram tudo certo? Por que não mudar, por exemplo, a métrica de destino, procurar outra coisa e coletar as coisas certas da nova métrica? Na minha opinião, agora que há vários tutoriais e código de outras pessoas, fazer previsões de feeds não é um problema. Treinar um modelo, treinar uma rede neural é uma tarefa muito simples, acessível a um círculo muito amplo de pessoas. Mas é importante entender qual é sua meta, o que você prevê e como montar sua métrica. Se você prevê algo irrelevante na realidade objetiva, o modelo simplesmente não aprende e você obtém uma velocidade muito ruim.
Exemplos. Houve uma competição no Topcoder Konica-Minolta.

Consistia no seguinte: você tem duas fotos, a de cima e uma delas tem sujeira, um pequeno ponto à direita. Era necessário destacar e segmentar. Parece uma tarefa muito simples, e as redes neurais devem resolvê-la de cada vez. Mas o problema é que essas são duas fotos que foram tiradas com uma diferença de horário ou de câmeras diferentes. Como resultado, uma imagem mudou um pouco em relação à outra. A balança era realmente muito pequena. Mas havia outra característica dessa tarefa: as máscaras também são pequenas. Há uma imagem que se moveu em relação a outra, enquanto a máscara ainda se moveu em relação a ela. É aproximadamente claro qual é a dificuldade.

Aleksey Buslaev em terceiro lugar, ele pegou a rede neural siamesa com duas entradas, para que esses chefes siameses aprendessem algumas transformações em relação a esse quadro distorcido. Depois disso, ele combinou esses recursos, teve um conjunto de convoluções e obteve algum tipo de previsão. Para nivelar essa escala nos dados, ele montou uma rede bastante complicada. Por exemplo, nunca treinei uma rede siamesa, não precisei fazer isso. Ele fez isso, é muito legal, ele ficou em terceiro lugar. Em primeiro lugar, estava Evgeny (nrzb.), Que simplesmente redimensionou a imagem. Ele viu isso como um erro nos dados, porque olhou para eles, redimensionou as fotos e treinou o UNet de baunilha. Essa é uma rede neural muito simples, está apenas no livro, nos artigos. Isso mostra que, se você olhar para os dados e selecionar o destino correto, poderá estar no topo com uma solução simples.
Acabei em segundo lugar, porque sou amigo de Zhenya; depois disso, os codificadores ficaram ofendidos por algum motivo e não me levaram à equipe do Kaggle. Mas eles são caras muito legais, o Topcoder ficou em 5-6, este (NRZB.) E Victor Durnov. Alexander Buslaev ficou em terceiro lugar. Eles se uniram e mostraram a classe em uma competição que estava no Kaggle. Este também é um exemplo de uma solução muito bonita, quando os caras não apenas desenvolveram uma arquitetura monstruosa, mas escolheram o alvo certo.

A tarefa aqui era segmentar as células, e não apenas dizer onde a célula está e onde não, mas era necessário isolar células individuais, como instilar a segmentação de cada célula independente. Além disso, antes desta competição, havia muitas competições de segmentação, e alegava-se que o problema de segmentação foi resolvido pela comunidade ODS muito bem, no nível do ofício, uma certa ciência de ponta que nos permite resolver bem esse problema.
Ao mesmo tempo, a tarefa de inst segmentação, quando você precisa separar as células, foi muito mal resolvida. O estado da arte antes desta competição era o MacrCNN, que é um tipo de detector, algum extrator de recursos e, em seguida, um bloco que realiza segmentação de máscaras, e tudo é muito difícil de treinar, você precisa treinar cada parte do pipeline separadamente, é uma música inteira.
Em vez disso, a Topcoder desenvolveu um pipeline quando você apenas prevê células e bordas. A segmentação de pipeline é complicada por pequenas e permite fazer uma segmentação muito bonita, subtraindo as bordas das células. Depois disso, eles elevaram a fasquia em termos da precisão desse algoritmo, enquanto sua rede neural separada prediz células melhor do que qualquer coisa que os acadêmicos já haviam feito nessa área antes. Isso é legal para os codificadores e muito ruim para os acadêmicos. Até onde eu sei, recentemente os acadêmicos tentaram publicar um artigo sobre esse dado, eles o rejeitaram porque não conseguiram superar o resultado no Kaggle. Tempos difíceis chegaram para os acadêmicos, agora precisamos fazer algo normal, e não apenas fazer o trabalho criptografado em seu campo.

A próxima coisa pela qual eu me afogo muito, não apenas no Kaggle, mas também no trabalho, é o treinamento com tubos. Não vejo muitos valores em criar uma arquitetura de rede neural monstruosa, criando peças bacanas com atenuação, com concatenações de recursos. Tudo funciona, mas é muito mais importante treinar uma rede neural. E não há foguete sensato, é uma coisa bem simples, considerando que agora existem vários artigos, tutoriais e assim por diante. Eu vejo muitos valores no fato de você ter apenas um treinamento em pipeline. Entendo isso como um código que é executado em uma configuração e ensina uma rede neural de maneira controlada, previsível e bastante rápida.
Este slide mostra os registros de treinamento da competição que está ocorrendo agora, Kaggle Salt. Eu ainda tenho um monte de placas de vídeo, isso também é um bônus. A idéia é que, com a ajuda do pipeline, fiz uma pesquisa em grade das arquiteturas que me pareciam mais interessantes. Acabei de fazer uma configuração de lançamento para todas as arquiteturas, por convenção, um fórum no zoológico de redes neurais, percorri e treinei todas as redes neurais sem nenhum esforço. Esse é um bônus muito grande, e é isso que reutilizo de uma competição para outra e no trabalho. Portanto, estou extremamente agitado não apenas para treinar redes neurais, mas também para pensar sobre o que você está ensinando e o que você escreve em termos do pipeline, para que você possa reutilizá-lo.

Aqui, destaquei algumas coisas importantes que deveriam estar no pipeline de treinamento. Esta é uma configuração de inicialização que define totalmente o processo de aprendizado. Onde você especifica todos os parâmetros sobre dados, redes neurais, perdas - tudo deve estar na configuração de inicialização. Isso deve ser controlável. Registro adicional. Os belos registros que mostrei são o resultado do registro de cada passo que dou.
Modularidade significa que não leva muito tempo para adicionar uma nova rede neural, uma nova ampliação, um novo conjunto de dados. Tudo isso deve ser muito simples e sustentável.
A reprodutibilidade está apenas consertando as sementes, enquanto não apenas as aleatórias no NumPy e Random, mas ainda existem alguns paiterchiks, vou lhe contar mais. E reutilização. Depois de desenvolver um pipeline, ele pode ser usado em outras tarefas. E esse é um grande bônus, aqueles que começam a participar de competições mais cedo, podem continuar usando esses pipelines em competições e no trabalho, tudo isso dá um grande bônus a outros participantes.
Alguns podem perguntar: não sei como codificar, o que fazer, como desenvolver um pipeline? Existe uma solução.

Sergey Kolesnikov é meu colega que trabalha em Dbrain, ele desenvolve uma coisa dessas há muito tempo. No começo, ele a chamou de PyTorch Common, depois ele chamou Prometheus, agora é chamado Catalist. Provavelmente, em uma semana o nome será diferente, mas o link será para o próximo nome, siga o link "Catalist".
A idéia é que Sergey tenha desenvolvido algum tipo de lib, que é um trilho de trem. E na versão atual tem quase todas as propriedades que descrevi. Ainda existem vários exemplos de como fazer a classificação, segmentação e várias outras coisas interessantes que ele desenvolveu.
Aqui está uma lista de recursos que estão sendo desenvolvidos. Você pode pegar essa biblioteca e começar a usá-la para treinar seus algoritmos, suas redes neurais na competição que está ocorrendo atualmente. Eu recomendo a todos que o façam.
Por outro lado, há outra FastAI, versão 1.0 lançada recentemente, mas há um código repugnante e nada está claro.
Você pode dominá-lo, isso lhe dará algum crescimento, mas, devido ao fato de ser muito mal escrito em termos de código, eles têm seu próprio fluxo em termos de como deve ser escrito. Começando em algum momento, você não entenderá o que está acontecendo. Portanto, eu não recomendo o FastAI, recomendo usar qualquer "catalisador".

Agora, suponha que você tenha passado por tudo isso, tenha seu próprio pipeline, sua própria decisão e agora possa participar da equipe. Emil foi questionado sobre o quão justificável é ingressar em uma equipe se você participar de como isso acontece. Parece-me que a parceria vale a pena de qualquer maneira, mesmo que você não esteja no topo, mas em algum lugar no meio. Se você mesmo desenvolveu sua solução, ela sempre difere da decisão de outras pessoas em alguns detalhes. E quando combinada, quase sempre dá impulso com outros participantes.
Além disso, é divertido, é um trabalho de equipe em termos do fato de que agora você terá um repositório comum onde poderá ver o código um do outro, um formato comum para envios e uma sala de bate-papo em que toda a diversão acontece. A interação social e as habilidades sociais também são muito importantes no trabalho, que também vale a pena desenvolver.
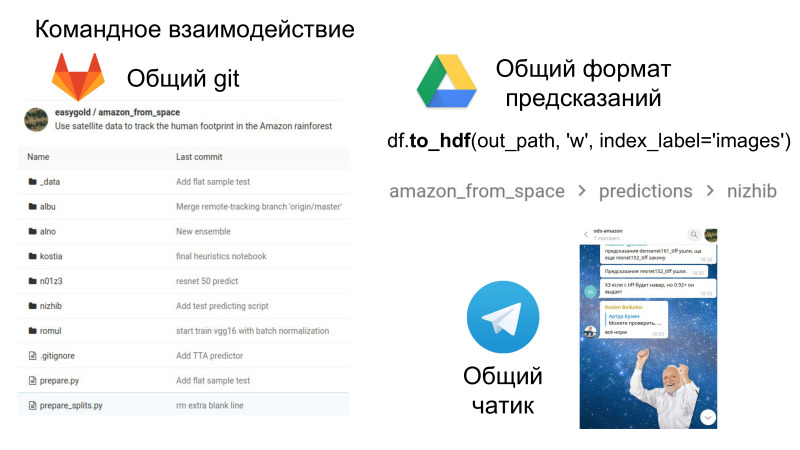
Este é um grande bônus no sentido de que agora você vê o código de outras pessoas, como elas tomam essa ou aquela decisão. E, muitas vezes, olho para o repositório com meus comandos anteriores, encontro soluções legais em termos do próprio código. É isso que pode ser retirado da competição na forma de trabalho em equipe.
Suponha que você tenha passado toda essa rodada. O que você suportou?

Provavelmente, você aprendeu a executar o código de outra pessoa. Eu realmente espero que você tenha desenvolvido o hábito de analisar dados. Você entende o problema, aprendeu a conduzir experimentos, tem algum tipo de solução própria e agora pode projetá-lo na forma de um projeto. Se você olhar abstratamente, é muito semelhante ao trabalho normal em alguma empresa de TI. Se você passou por uma competição e mostrou um bom resultado, este é um ponto forte no currículo, pelo menos para mim. Por volta de 20-25, fui entrevistado quando recrutei na Dbrain. Alguns casos de fronteira podem ser identificados lá. Havia um cara que acabou de rodar o kernel público e realmente não descobriu. Parecia ruim para mim, eu só queria que o cara entendesse a questão, não aceitei.
Outro cara que honestamente disse que estava na frente do placar, mas ao mesmo tempo contou todos os detalhes de sua decisão, que estava no Datascience Bowl, nós a aceitamos, gosto muito de trabalhar com ele. Kaggle e sua decisão: há um ponto bastante forte em seu currículo: se você pode formatá-lo corretamente na forma de uma apresentação, é um bom show para o futuro empregador.
Se tiver dúvidas sobre ganhos pessoais, espero encerrar, por que as empresas precisam disso?

Eu trabalhei na Avito, eles realizavam regularmente concursos sobre análise de dados. Existem várias razões para isso. Quando a competição é realizada, você precisa coletar pelo menos um conjunto de dados e formular muito bem a tarefa, o que é um pouco trabalhoso.

Ou seja, a declaração do problema mais o conjunto de dados já é muito para a empresa. , «» , , , , . — , , .
, , , , . , , . - , , , .
, , — . , . , «» , . «» — , .

, — . , - . , — , . , , , . — importance XGBoost . , , . . , . , . , .
Se as empresas não querem participar, não querem se organizar, apenas têm alguma tarefa relevante; depois, como regra, após a competição, as pessoas publicam análises de suas decisões e até mesmo um código. E se você tem uma tarefa relevante que é muito semelhante, pode começar e começar a trabalhar na forma de uma revisão de literatura, uma revisão de soluções a partir do topo. Como exemplo, um curso do Coursera sobre como vencer competições. O próximo é o site de treinamento de ML e a sala de bate-papo ODS para discussão. Eu tenho tudo.
Como exemplo, um curso do Coursera sobre como vencer competições. O próximo é o site de treinamento de ML e a sala de bate-papo ODS para discussão. Eu tenho tudo.