
Neste verão, ensinamos a rede neural a determinar se um documento está presente na imagem e, em caso afirmativo, qual.
Por que é necessário
Para descarregar funcionários e proteger as pessoas dos golpistas. Usamos a nova rede neural em duas áreas: quando o usuário recupera o acesso à página e oculta documentos pessoais da pesquisa geral.
Restaurando o acesso às páginas. Fotos de documentos ajudam a devolver as contas aos verdadeiros proprietários. Por exemplo, um usuário pode ter perdido o acesso ao seu número de telefone ou a autenticação em duas etapas foi ativada na página e não há mais nenhuma oportunidade de receber um código único para confirmar a entrada. O novo desenvolvimento acelera a consideração de aplicativos: os moderadores não precisam mais retornar aplicativos preenchidos incorretamente a cada vez. O sistema simplesmente não permite que o visitante envie o formulário sem as imagens necessárias e solicita a substituição da imagem aleatória por um documento. Obviamente, ainda podemos retornar o acesso à própria página apenas se houver fotos reais do proprietário. Estamos falando sobre a segurança das contas e a preservação de dados pessoais - o que significa que simplesmente não pode haver erros e acidentes.
Filtrando os resultados da pesquisa na seção " Documentos ". Todos os documentos que os usuários enviam para esta seção ou enviam via mensagens privadas ficam ocultos por olhares indiscretos por padrão e não se enquadram nos resultados da pesquisa. Mas o nível de privacidade pode ser configurado manualmente manualmente - para cada arquivo individual. Antes do advento da rede neural, era possível encontrar uma quantidade decente de documentos com dados confidenciais usando palavras-chave. Os próprios proprietários desses arquivos alteraram as configurações de privacidade. Protegemos os usuários e começamos
a remover fotos
de uma pesquisa pública na qual podemos determinar a presença de um documento.
Como resolvemos o problema
Parece que a maneira mais fácil de identificar documentos em uma imagem é configurar uma rede neural ou treiná-la do zero em uma amostra grande. Mas não é tão simples.
A amostra deve ser representativa. É difícil encontrar um número suficiente de amostras reais para cada opção: não há bancos de dados públicos com esses documentos no domínio público.
Existem muitos sistemas que reconhecem e analisam documentos. Geralmente, eles visam obter informações específicas de uma fotografia e sugerir a qualidade ideal da imagem original. Por exemplo, um usuário pode ser solicitado a alinhar o passaporte ao longo das bordas do modelo, pois ele funciona no portal de Serviços de Estado.
Tais sistemas não são adequados para nossas tarefas. Esclarecemos separadamente que, ao entrar em contato para restauração do acesso, o usuário
pode fechar todos os dados do documento, exceto fotos, nome, sobrenome e impressão. Ao mesmo tempo, ainda precisamos determinar o documento - mesmo que a série e o número estejam ocultos, se o passaporte for tirado com o ambiente ou, inversamente, apenas parte do documento com a fotografia apareceu na imagem. Ainda é necessário considerar diferentes ângulos e iluminação. A rede neural deve aceitar todos esses materiais. A questão é como ensinar isso a ela.

Existem outras dificuldades. Por exemplo, é difícil separar o passaporte de outros tipos de documentos, bem como de vários papéis manuscritos e impressos.
Tentar seguir o caminho mais fácil não teve muito sucesso. O classificador resultante acabou sendo fraco, com um pequeno erro do primeiro tipo e um grande erro do segundo. Por exemplo, houve casos interessantes em que uma pessoa escreveu o nome e sobrenome à mão, tirou uma fotografia, a capa de um passaporte - e o sistema aceitou indiferentemente esse documento.
A que chegamos
Em nossa situação, a melhor solução para o problema era usar um conjunto de grades e detectores de rosto para reconhecer um documento e determinar seu tipo. Também adicionamos um classificador diferencial, que inclui um codificador para destacar recursos de características e um classificador de formulários que permite distinguir imagens de documentos de arquivos irrelevantes. Além disso, ocorre um agrupamento preliminar do conjunto de treinamento com o objetivo de normalizar o conjunto de dados. Das arquiteturas,
VGG e
ResNet provaram o
seu melhor .
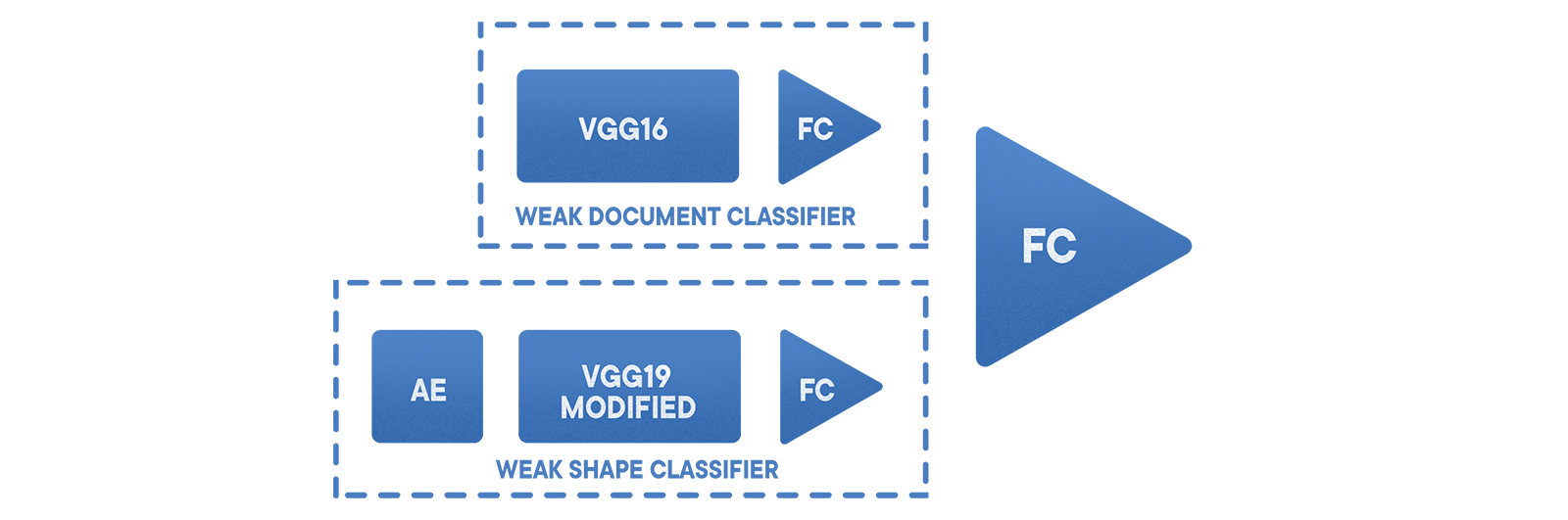
O classificador básico "documento / não documento" funciona com base em um VGG ajustado com 19 camadas e uma amostra em zonas. Além disso, é usado um conjunto combinado de classificadores, que reduzem o erro do segundo tipo e diferenciam o resultado. Primeiro vem a
amostragem estratificada , depois um codificador para extrair informações do loop próximo, depois um VGG modificado e, finalmente, uma única grade. Essa abordagem nos permitiu minimizar os erros do primeiro tipo para o nível de aproximadamente 0,002. A probabilidade de falso negativo neste caso depende do conjunto de dados selecionado e do aplicativo específico.
Agora, aprendemos como detectar automaticamente a presença de passaportes e carteiras de motorista na imagem. O reconhecimento é bem-sucedido em qualquer ângulo, com qualquer plano de fundo, mesmo em más condições de iluminação - o principal é que a imagem tenha parte do documento com uma fotografia e um nome. No entanto, para identificar outros tipos de documentos, apenas conjuntos de dados relevantes serão necessários. Nós treinamos a rede com nossos próprios dados, o tamanho da amostra dos documentos é de cinco a dez mil (mas não é representativo). Para outras imagens, a amostra é arbitrária, mas há um agrupamento a priori lá e ali.
Do ponto de vista técnico, o sistema é escrito em python /
keras /
tensorflow /
glib /
opencv . Para uma aplicação prática do novo sistema, basta integrá-lo aos manipuladores python da infraestrutura de aprendizado de máquina. No mesmo estágio, um detector de alteração de foto nos editores gráficos é adicionado, mas este tópico merece um artigo separado.
Qual é o resultado
Agora, 6% dos pedidos de restauração do acesso são retornados automaticamente ao autor com uma solicitação para adicionar ou substituir uma foto do documento e 2,5% dos pedidos são rejeitados. Se você analisar a análise de imagens como um todo, incluindo heurísticas e pesquisa de rosto em uma imagem, ela
automatiza até 20% do trabalho do departamento .
Após o lançamento da rede neural, também conseguimos calcular o número de passaportes enviados para a seção "Documentos". Descobriu-se que nos resultados gerais da pesquisa todos os dias havia cerca de dois mil cartões de identidade. Agora, a probabilidade de cair em mãos estranhas é mínima.
As redes neurais já estão nos ajudando a combater o spam e todos os tipos de fraude. Não paramos os experimentos e continuamos a falar sobre eles em nosso blog.