Este artigo é uma tradução do artigo de Kevin Goldberg "Uma análise de desempenho de servidores WSGI Python: Parte 2" dzone.com/articles/a-performance-analysis-of-python-wsgi-servers-part com algumas adições do tradutor.
1. Introdução
Na
primeira parte desta série, você se encontrou com o
WSGI e os seis servidores mais populares, de acordo com o autor do
WSGI . Nesta parte, você verá o resultado da análise do desempenho desses servidores. Para esse fim, uma sandbox de teste especial foi criada.
Participantes
Devido a restrições de tempo, a pesquisa foi limitada a seis servidores WSGI. Todas as instruções de inicialização deste projeto
estão hospedadas no GitHub . Talvez com o tempo, o projeto se expanda e as análises de desempenho para outros servidores WSGI sejam apresentadas. Mas, por enquanto, falaremos sobre seis servidores:
- Bjoern se descreve como um "servidor WSGI ultrarrápido" e se orgulha de ser "o servidor WSGI mais rápido, menor e mais leve". Criamos um pequeno aplicativo que usa a maioria das configurações da biblioteca padrão.
- CherryPy é um framework e servidor WSGI extremamente popular e estável. Este pequeno script foi usado para servir nosso aplicativo de amostra através do CherryPy .
- Gunicorn foi inspirado no servidor Unicorn do Ruby (daí o nome). Ele modestamente afirma que é "simplesmente implementado, fácil de usar e bastante rápido". Ao contrário do Bjoern e do CherryPy , o Gunicorn é um servidor independente. Nós o criamos usando este comando . O parâmetro "WORKER_COUNT" foi definido para o dobro do número de núcleos de processador disponíveis, mais um. Isso foi feito com base nas recomendações da documentação do Gunicorn .
- O Meinheld é um servidor da Web compatível com WSGI de alto desempenho que afirma ser leve. Com base no exemplo mostrado no site do servidor, criamos nosso aplicativo .
- mod_wsgi foi criado pelo mesmo criador que mod_python . Como o mod_python , ele está disponível apenas para o Apache. No entanto, inclui uma ferramenta chamada "mod_wsgi express" que cria a menor instância possível do Apache. Nós configuramos e usamos mod_wsgi express com este comando . Para combinar com o Gunicorn , ajustamos o mod_wsgi para criar o dobro de trabalhadores que os núcleos do processador.
- O uWSGI é um servidor de aplicativos completo. Normalmente, o uWSGI é emparelhado com um servidor proxy (por exemplo: Nginx). No entanto, para avaliar melhor o desempenho de cada servidor, tentamos usar apenas servidores simples e criamos dois trabalhadores para cada núcleo de processador disponível.
Referência
Para tornar o teste o mais objetivo possível, foi criado um contêiner do
Docker para isolar o servidor em teste do restante do sistema. Além disso, o uso do contêiner Docker garantiu que todo lançamento fosse iniciado do zero.
Servidor:
- Isolado em um contêiner de estivador.
- 2 núcleos de processador alocados.
- A RAM do contêiner estava limitada a 512 MB.
Teste:
- O wrk , uma moderna ferramenta de benchmarking HTTP, executou testes.
- Os servidores foram testados em ordem aleatória, com um aumento no número de conexões simultâneas no intervalo de 100 a 10.000.
- O wrk estava limitado a dois núcleos de CPU não utilizados pelo Docker.
- Cada teste durou 30 segundos e foi repetido 4 vezes.
Métrica:
- O número médio de solicitações persistentes, erros e atrasos foi fornecido pelo wrk .
- Integrado ao Docker, o monitoramento mostrou os níveis de uso da CPU e da RAM.
- As leituras mais alta e mais baixa foram descartadas e os demais valores foram calculados como média.
- Para os curiosos, enviamos o script completo para o GitHub .
Resultados
Todos os indicadores de desempenho iniciais
foram incluídos no repositório do projeto e também
foi fornecido um
arquivo CSV de resumo. Além disso, para visualização, os gráficos foram criados no ambiente do
Google Doc .
RPS versus número de conexões simultâneas
Este gráfico mostra o número médio de solicitações simultâneas; Quanto maior o número, melhor.
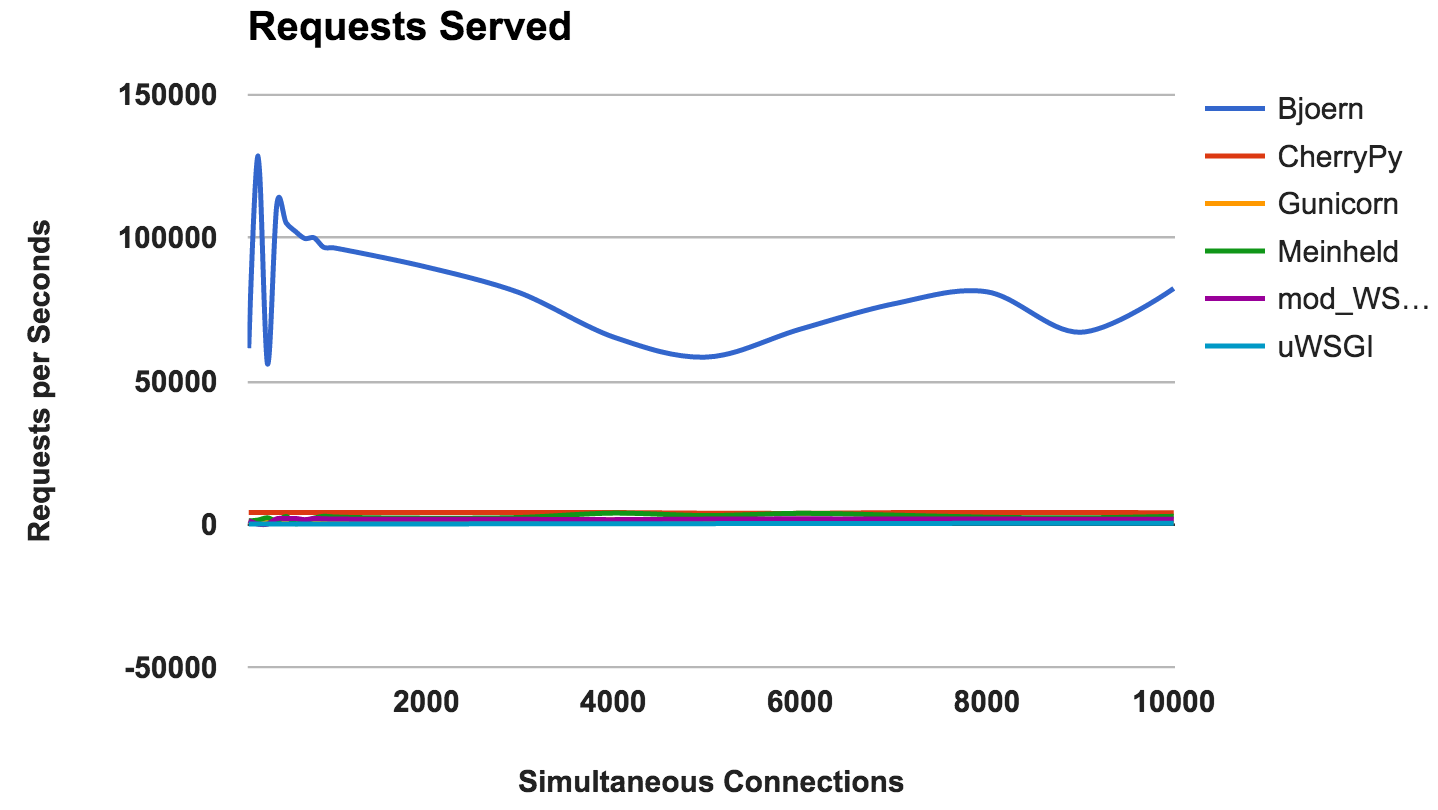
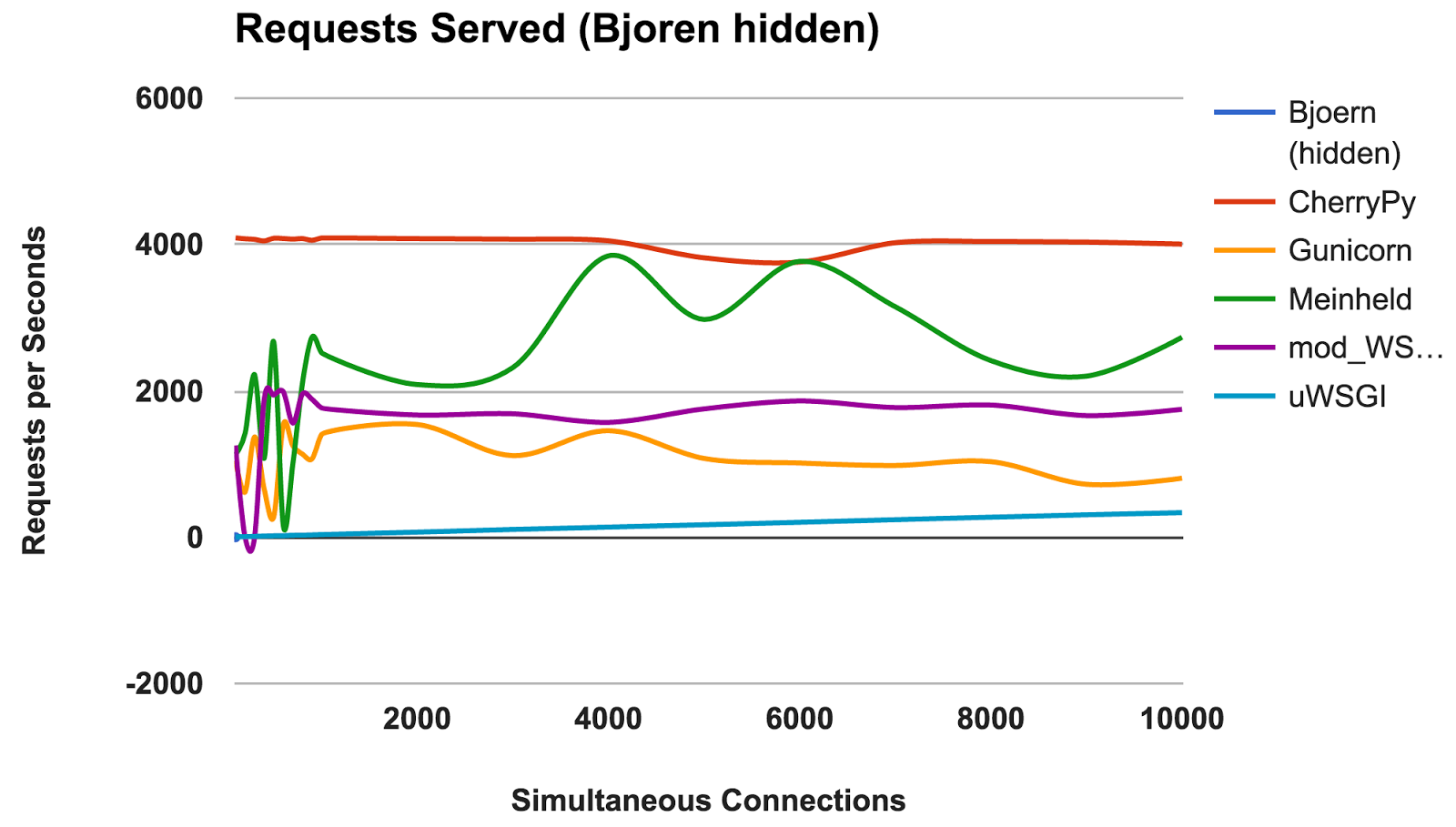
- Bjoern: Um vencedor claro.
- CherryPy: Apesar de ter sido escrito em Python puro, ele foi o melhor artista.
- Meinheld: Excelente desempenho, devido aos escassos recursos de contêineres.
- mod_wsgi: Não é o mais rápido, mas o desempenho foi consistente e adequado.
- Gunicorn: Bom desempenho em cargas mais baixas, mas há uma briga com um grande número de conexões.
- uWSGI: Frustrado com resultados ruins.
VENCEDOR: BjoernBjoern
Pelo número de pedidos constantes,
Bjoern é o vencedor. No entanto, dado que os números são muito maiores que os dos concorrentes, somos um pouco céticos. Não temos certeza de que o
Bjoern seja realmente tão incrivelmente rápido. Inicialmente, testamos os servidores em ordem alfabética e pensamos que o
Bjoern tinha uma vantagem injusta. No entanto, mesmo depois de iniciar os servidores em uma ordem aleatória e testar novamente, o resultado permanece o mesmo.
uWSGI
Ficamos decepcionados com os fracos resultados do
uWSGI . Esperávamos que ele estivesse na liderança. Durante o teste, observamos que os logs do
uWSGI são impressos na tela e, inicialmente, explicamos a falta de desempenho com o trabalho adicional que o servidor fez. No entanto, mesmo após a opção “
--disable-logging ” ter sido adicionada, o
uWSGI ainda é o servidor mais lento.
Conforme mencionado no manual do
uWSGI , ele geralmente faz interface com um servidor proxy como o Nginx. No entanto, não temos certeza de que isso possa explicar uma diferença tão grande.
Atraso
Atraso é a quantidade de tempo decorrido entre a solicitação e sua resposta. Números mais baixos são melhores.
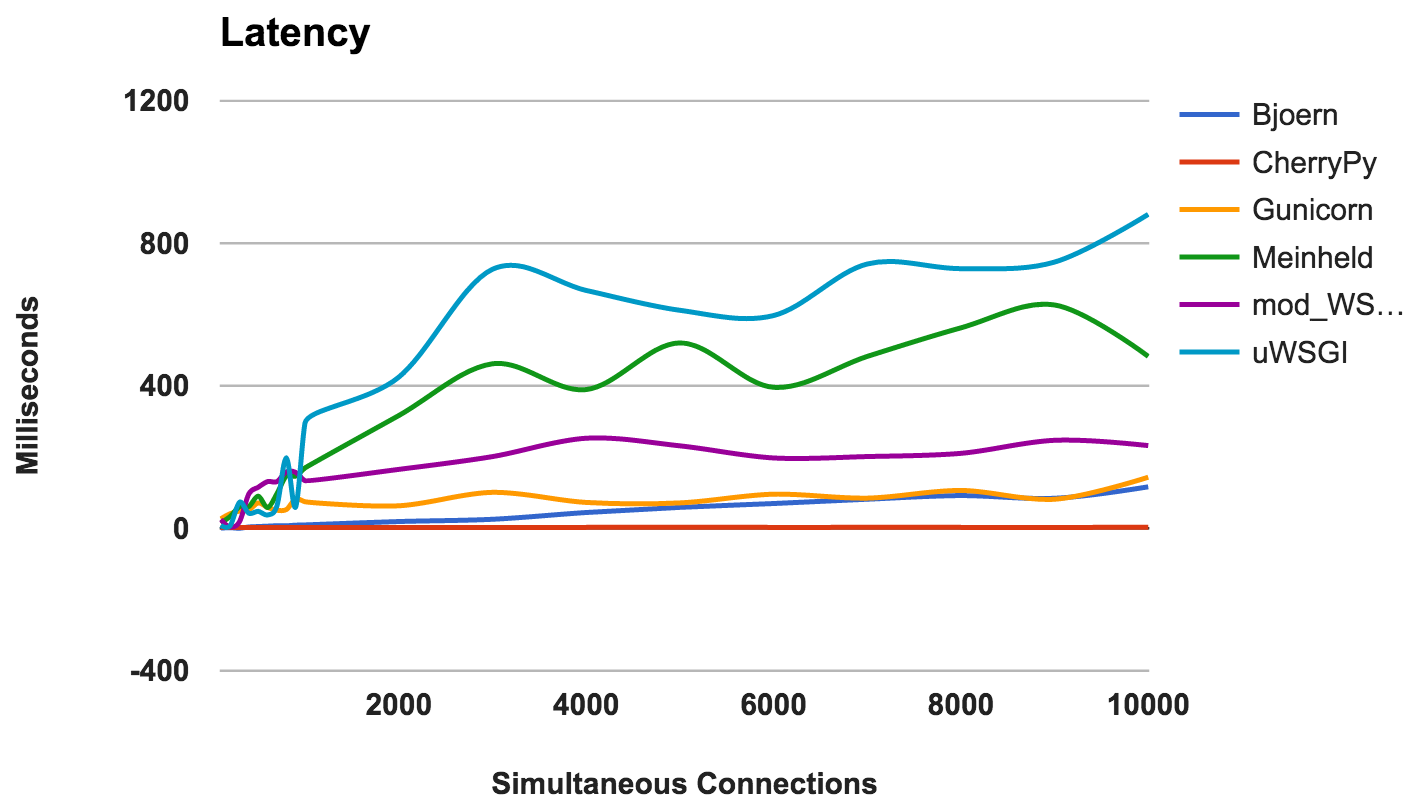
- CherryPy: Manejou bem a carga.
- Bjoern: latência geralmente baixa, mas funciona melhor com menos conexões simultâneas.
- Gunicorn: bom e consistente.
- mod_wsgi: desempenho médio, mesmo com um grande número de conexões simultâneas.
- Meinheld: desempenho geral aceitável.
- uWSGI: uWSGI está novamente em último lugar.
VENCEDOR: CherryPyUso de RAM
Essa métrica mostra os requisitos de memória e a "leveza" de cada servidor. Números mais baixos são melhores.
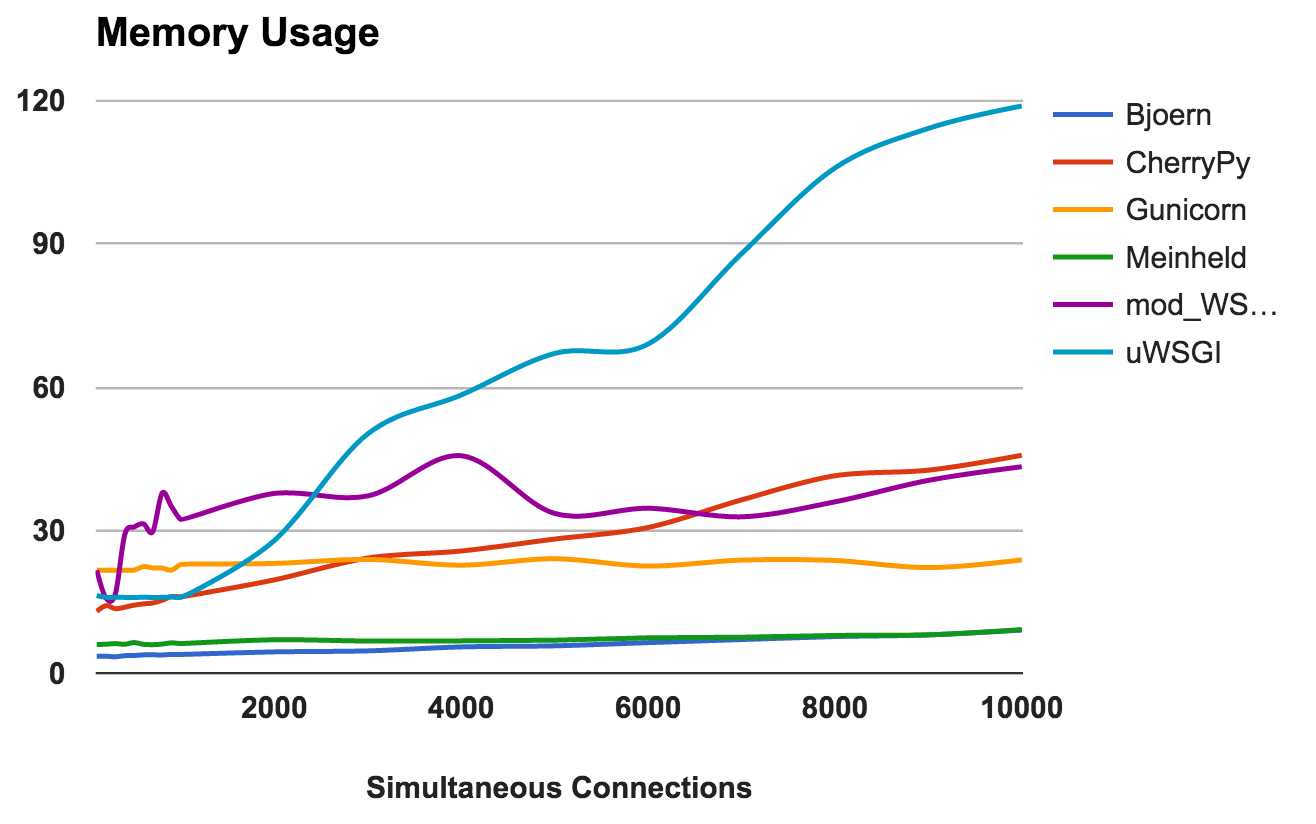
- Bjoern: Extremamente leve. Ele usa apenas 9 MB de RAM para processar 10.000 solicitações simultâneas.
- Meinheld: O mesmo que Bjoern .
- Gunicorn: Habilmente lida com altas cargas com um consumo de memória quase imperceptível.
- CherryPy: Inicialmente precisava de uma pequena quantidade de RAM, mas seu uso aumentou rapidamente com o aumento da carga.
- mod_wsgi: Em níveis mais baixos, foi um dos mais intensos na memória, mas permaneceu bastante consistente.
- uWSGI: Obviamente, a versão que estamos testando tem problemas com a quantidade de memória consumida.
VENCEDORES: Bjoern e MeinheldNúmero de erros
Ocorre um erro quando o servidor trava, é interrompido ou o tempo limite da solicitação. Quanto menor, melhor.
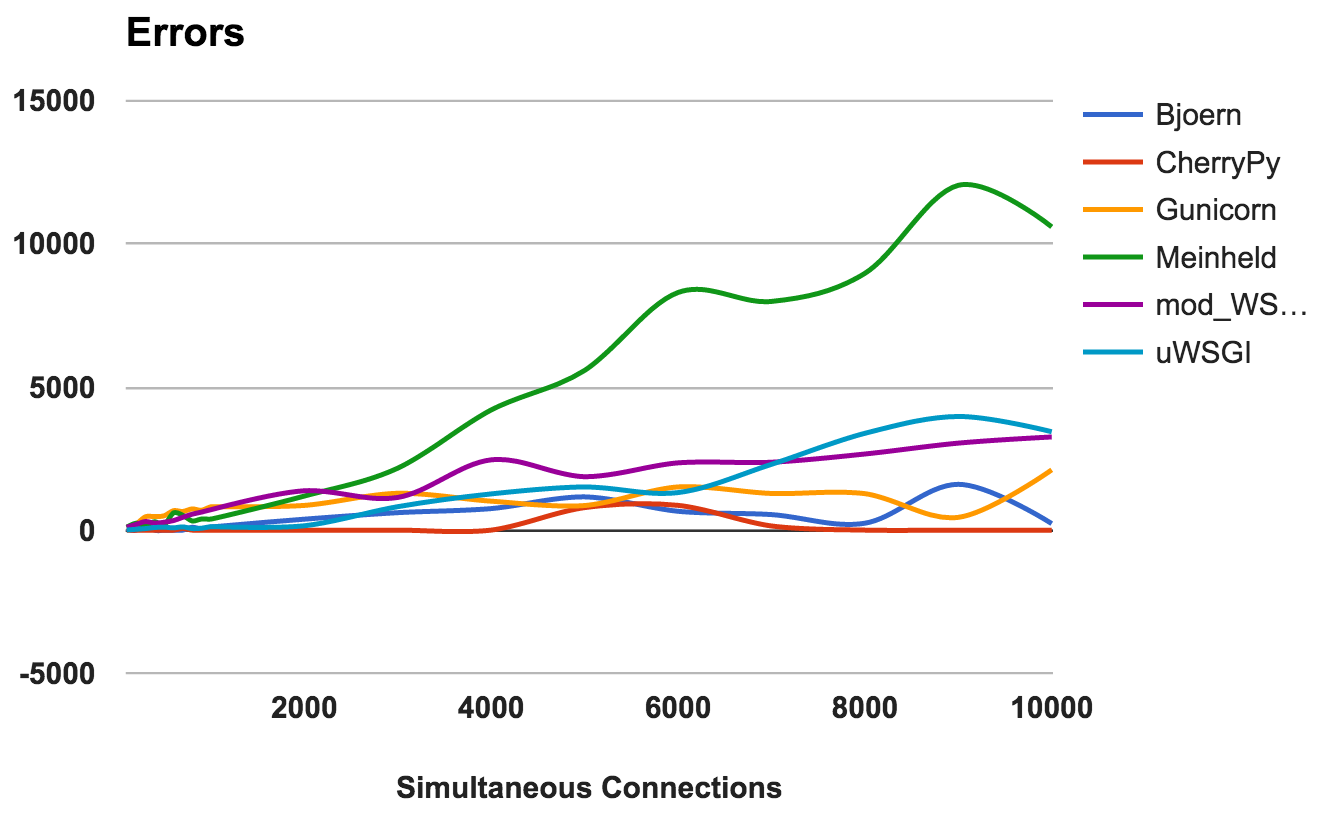
Para cada servidor, calculamos a proporção da proporção total do número de solicitações para o número de erros:
- CherryPy: taxa de erro em torno de 0, mesmo com um número alto de conexões.
- Bjoern: Ocorreram erros, mas isso foi compensado pelo número de solicitações processadas.
- mod_wsgi: funciona bem com uma taxa de erro aceitável de 6%.
- Gunicorn: trabalha com uma taxa de erro de 9%.
- uWSGI: Dado o baixo número de solicitações atendidas, a taxa de erro foi de 34%.
- Meinheld: caiu em cargas mais altas, lançando mais de 10.000 erros durante o teste mais exigente.
VENCEDOR: CherryPyUso da CPU
A alta utilização da CPU não é boa ou ruim se o servidor estiver funcionando bem. No entanto, isso fornece algumas informações interessantes sobre o servidor. Como dois núcleos de CPU foram usados, o uso máximo possível é de 200%.
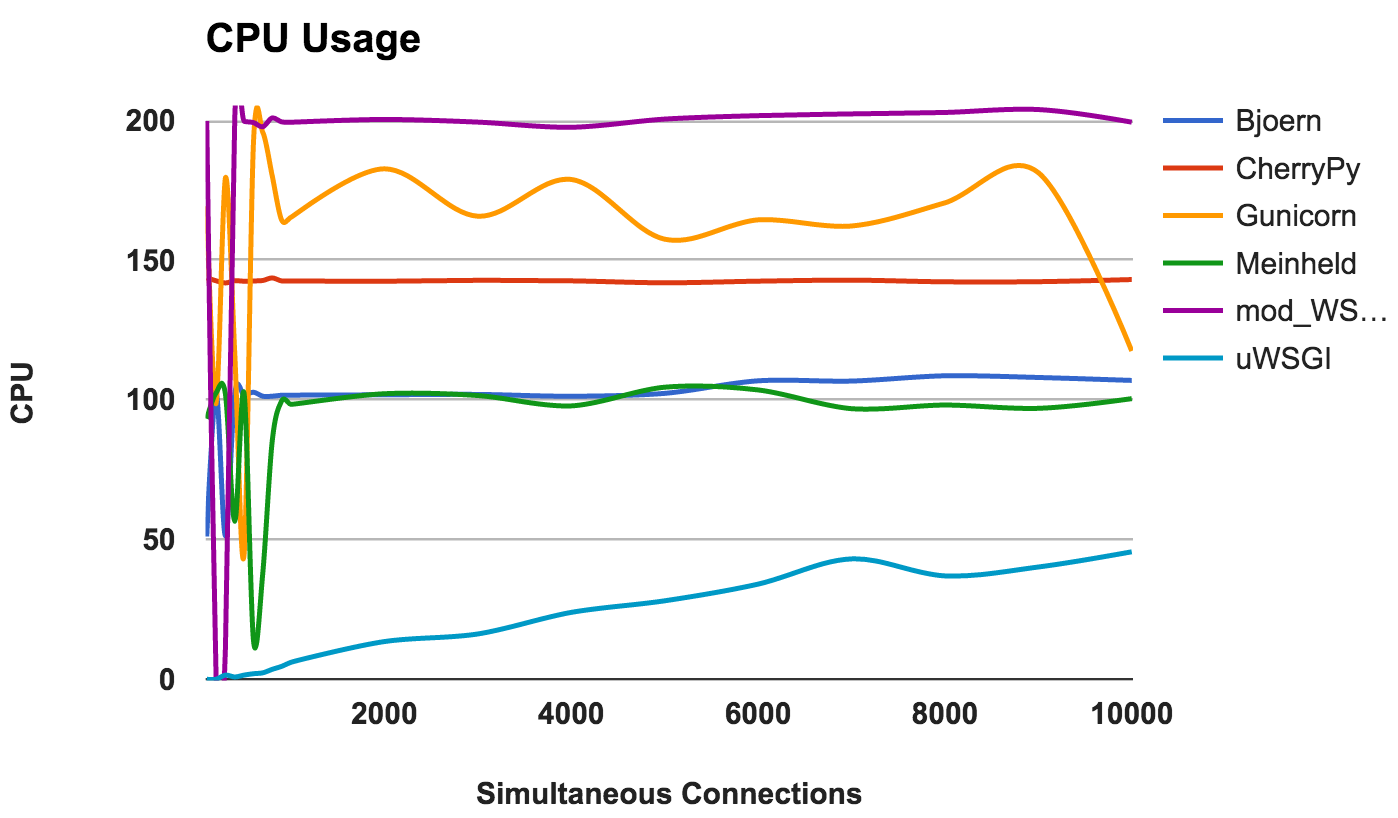
- Bjoern: um servidor de thread único, como evidenciado pelo uso consistente de 100% da CPU.
- CherryPy: multithread, mas preso em 150 por cento. Isso pode ser devido ao Python GIL .
- Gunicorn: usa vários processos com uso total dos recursos da CPU em níveis mais baixos.
- Meinheld: Um servidor de thread único usando recursos de CPU como o Bjoern.
- mod_wsgi: um servidor multiencadeado usando todos os núcleos da CPU em todas as medições
- uWSGI: uso muito baixo da CPU. O consumo da CPU não excede 50%. Essa é uma evidência de que o uWSGI não está configurado corretamente.
VENCEDOR: Não, porque isso é mais uma observação de comportamento do que uma comparação de desempenho.Conclusão
Para resumir! Aqui estão algumas idéias gerais que você pode extrair dos resultados de cada servidor:
- Bjoern: Justifica-se como um "servidor WSGI super rápido e ultra leve".
- CherryPy: Alto desempenho, baixo consumo de memória e baixas taxas de erro. Nada mal para o Python puro.
- Gunicorn: Um bom servidor para cargas médias.
- Meinheld: Funciona bem e requer recursos mínimos. No entanto, lutando com cargas mais altas.
- mod_wsgi: Integra-se ao Apache e funciona muito bem.
- uWSGI: Muito decepcionado. Ou configuramos o uWSGI incorretamente ou a versão que instalamos possui erros básicos.