Em setembro, foi realizado o sexto Hyperbaton - a conferência Yandex sobre tudo relacionado à documentação técnica. Publicaremos várias palestras da Hyperbaton, que, em nossa opinião, podem ser de maior interesse para os leitores da Habr.
Svetlana Kayushina, chefe do departamento de documentação e localização:
- Parece que no mundo não há mais pessoas que traduzam manualmente. Hoje, queremos falar sobre ferramentas e abordagens que ajudam as empresas a organizar um processo eficaz de localização, e os tradutores facilitam a solução dos problemas do dia a dia. Hoje falaremos sobre tradução automática, sobre a avaliação da eficácia de mecanismos de máquina e sobre sistemas de tradução automatizada para tradutores.
Vamos começar com o relatório de nossos colegas. Convido Irina Rybnikova e Anastasia Ponomareva - eles falarão sobre a experiência da Yandex na introdução da tradução automática em nossos processos de localização.
Irina Rybnikova:
Obrigado. Vamos falar sobre o histórico da tradução automática e como a usamos no Yandex.

No século XVII, os cientistas estavam pensando na existência de uma linguagem que conecta outras línguas, e isso provavelmente é muito longo. Vamos voltar mais perto. Todos nós queremos entender as pessoas ao nosso redor - não importa de onde viemos - queremos ver o que está escrito nas placas, queremos ler anúncios, informações sobre shows. A idéia do peixe babilônico sulca a mente dos cientistas, é encontrada na literatura, no cinema - em toda parte. Queremos reduzir o tempo pelo qual obtemos acesso à informação. Queremos ler artigos sobre tecnologias chinesas, entender todos os sites que vemos e queremos obtê-lo aqui e agora.

Nesse contexto, é impossível não falar em tradução automática. É isso que ajuda a resolver esse problema.

O ponto de partida é 1954, quando 60 frases sobre o assunto geral de química orgânica foram traduzidas do russo para o inglês nos EUA em uma máquina IBM 701, e tudo isso foi baseado em 250 termos do glossário e seis regras gramaticais. Isso foi chamado de experimento de Georgetown, e foi tão chocante que os jornais ficaram cheios de manchetes que, por mais três a cinco anos, e o problema será completamente resolvido, todos ficarão felizes. Mas como você sabe, tudo foi um pouco diferente.
Nos anos 70, a tradução automática baseada em regras apareceu. Também foi baseado em dicionários bilíngues, mas também nos mesmos conjuntos de regras que ajudaram a descrever qualquer idioma. Qualquer, mas com limitações.

São necessários especialistas linguísticos sérios que estabelecem as regras. Esse é um trabalho bastante complicado, ainda não foi possível levar em conta o contexto, cobrir completamente qualquer idioma, mas eles eram especialistas e, portanto, não era necessário alto poder de computação.

Se falamos de qualidade, um exemplo clássico é uma citação da Bíblia, que depois foi traduzida assim. Ainda não é suficiente. Portanto, as pessoas continuaram trabalhando na qualidade. Nos anos 90, apareceu um modelo de tradução estatística, SMT, que falava sobre a distribuição probabilística de palavras e frases, e esse sistema era fundamentalmente diferente, pois nada sabia sobre as regras e a lingüística. Ela recebeu uma quantidade enorme de textos idênticos, emparelhados em um idioma e em outro, e depois tomou as próprias decisões. Era fácil de manter, não eram necessários montes de especialistas, nem espera. Você pode baixar e obter o resultado.

Os requisitos para dados recebidos eram bastante médios, de 1 a 10 milhões de segmentos. Segmentos - frases, frases pequenas. Mas as dificuldades permaneceram e o contexto não foi levado em consideração; tudo não foi muito fácil. E na Rússia, por exemplo, esses casos apareceram.

Eu também gosto do exemplo de tradução de jogos GTA, o resultado foi ótimo. Tudo não parou. 2016 foi um marco importante quando a tradução automática neural começou. Foi um evento bastante marcante que mudou muito a vida. Meu colega, depois de examinar as traduções e como as usamos, disse: "Legal, ele fala em minhas palavras". E foi realmente ótimo.
Quais recursos? Altos requisitos de entrada, material de treinamento. É difícil de manter dentro da empresa, mas é para isso que foi concebido um aumento significativo na qualidade. Somente uma tradução de alta qualidade resolverá as tarefas e facilitará a vida de todos os participantes do processo, os mesmos tradutores que não desejam corrigir uma tradução incorreta, desejam realizar novas tarefas criativas e fornecer frases de rotina à máquina.
Existem duas abordagens para tradução automática. Avaliação de especialistas / análise lingüística de textos, ou seja, verificação por linguistas reais, especialistas quanto ao cumprimento do significado, alfabetização da língua. Em alguns casos, ainda havia especialistas, eles podiam subtrair o texto traduzido e avaliavam a eficácia desse ponto de vista.

Quais são os recursos desse método? Nenhuma tradução de amostra é necessária. Examinamos o texto traduzido finalizado agora e o avaliamos objetivamente para qualquer seção. Mas é caro e longo.

Existe uma segunda abordagem - métricas de referência automáticas. Existem muitos, cada um com seus prós e contras. Não vou mais fundo. Você pode ler mais sobre essas palavras-chave mais tarde.
Qual recurso? De fato, esta é uma comparação de textos automáticos traduzidos com algumas traduções exemplares. Essas são métricas quantitativas que mostram a discrepância entre tradução exemplar e o que aconteceu. É rápido, barato e pode ser feito de maneira bastante conveniente. Mas existem recursos.

De fato, na maioria das vezes eles usam métodos híbridos. É quando algo é automaticamente avaliado inicialmente, então uma matriz de erro é analisada e, em seguida, uma análise lingüística especializada é realizada em um corpo menor de textos.

Recentemente, a prática ainda é generalizada quando não chamamos linguistas para lá, mas simplesmente usuários. Está sendo feita uma interface - mostre qual tradução você mais gosta. Ou, quando você acessa tradutores on-line, insere texto e pode votar com frequência no que mais gosta, se essa abordagem é adequada ou não. De fato, agora todos treinamos esses mecanismos e eles usam tudo para treinar para treinar e trabalhar em sua qualidade.
Eu gostaria de dizer como usamos a tradução automática em nosso trabalho. Eu passo a palavra para Anastasia.
Anastasia Ponomareva:
- Nós da Yandex, no departamento de localização, percebemos rapidamente que a tecnologia de tradução automática tem um grande potencial e decidimos tentar usá-la em nossas tarefas diárias. Por onde começamos? Decidimos realizar um pequeno experimento. Decidimos traduzir os mesmos textos através de um tradutor de rede neural regular e também montar um tradutor de máquina treinado. Para fazer isso, preparamos corpus de textos em um par de russo-inglês para os anos em que estivemos no Yandex envolvidos na localização de textos nesses idiomas. Em seguida, viemos com esse corpus de textos para os colegas da Yandex.Translate e pedimos para treinar o mecanismo.

Quando o motor foi treinado, traduzimos o próximo lote de textos e, como Irina disse, com a ajuda de especialistas, avaliamos os resultados. Pedimos aos tradutores que estudassem alfabetização, estilo, ortografia e transmissão de significado. Mas o ponto de virada foi quando um dos tradutores disse que "reconheço meu estilo, reconheço minhas traduções".
Para reforçar essas sensações, decidimos calcular os indicadores estatísticos. Primeiro, calculamos o coeficiente BLEU para transferências feitas através de um mecanismo de rede neural regular e obtivemos esse valor (0,34). Parece que precisa ser comparado com alguma coisa. Novamente fomos aos colegas da Yandex.Translator e pedimos para explicar qual coeficiente de BLEU é considerado limite para transferências feitas por uma pessoa real. Isso é de 0,6.
Decidimos então verificar quais são os resultados nas traduções treinadas. Obteve 0,5. Os resultados são realmente encorajadores.

Eu dou um exemplo Esta é uma frase russa real da documentação do Direct. Em seguida, foi transferido por meio de um mecanismo de rede neural comum e, em seguida, por um mecanismo de rede neural treinado em nossos textos. Já na primeira linha, percebemos que o tipo tradicional de publicidade do Direct não é reconhecido. E já no mecanismo de rede neural treinado, nossa tradução aparece e até a abreviação está quase correta.
Ficamos muito animados com os resultados e decidimos que provavelmente vale a pena usar o mecanismo em outros pares, em outros textos, não apenas nesse conjunto básico de documentação técnica. Uma série de experimentos foi realizada por vários meses. Diante de muitos recursos e problemas, esses são os problemas mais comuns que tivemos que resolver.

Vou falar mais sobre cada um.

Se você, como nós, planeja criar um mecanismo personalizado, precisará de uma quantidade bastante grande de dados paralelos de alta qualidade. O grande motor pode ser treinado no valor de 10 mil ofertas; no nosso caso, preparamos 135 mil ofertas paralelas.

Nem em todos os tipos de texto, seu mecanismo mostrará resultados igualmente bons. Na documentação técnica, onde há frases longas, estrutura, documentação do usuário e até na interface, onde existem botões curtos, mas claros, provavelmente você ficará bem. Mas talvez, como conosco, você encontre problemas de marketing.
Realizamos um experimento, traduzindo playlists de músicas e tivemos um exemplo.

É isso que um tradutor de máquinas pensa sobre os trabalhadores da fábrica. Quais são os bateristas do trabalho.

Ao traduzir através de um mecanismo de máquina, o contexto não é levado em consideração. Este não é mais um exemplo tão ridículo, mas bastante real, da documentação técnica do Yandex.Direct. Parece que esses são compreensíveis quando você lê a documentação técnica, esses são os técnicos. Mas não, o motor não bateu.

Você também deve considerar que a qualidade e o significado da tradução dependerão muito do idioma original. Traduzimos a frase para o francês do russo, obtemos um resultado. Temos uma frase semelhante com o mesmo significado, mas do inglês, e obtemos um resultado diferente.

Se você, como em nosso texto, tiver um grande número de tags, marcação, alguns recursos técnicos, provavelmente precisará rastreá-los, editar e escrever alguns scripts.
Aqui estão exemplos de frases reais do navegador. Entre parênteses são informações técnicas que não devem ser traduzidas, em particular várias formas. Em inglês, eles estão em inglês e em alemão também devem permanecer em inglês, mas são traduzidos. Você terá que acompanhar esses pontos.
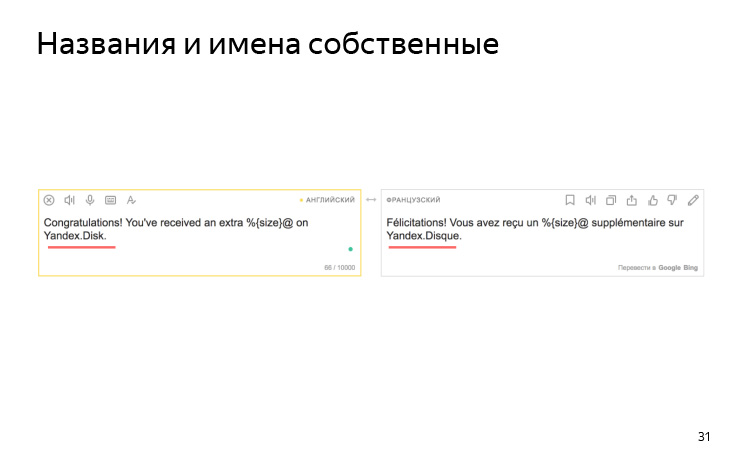
O mecanismo não sabe nada sobre suas convenções de nomenclatura. Por exemplo, temos um acordo que sempre chamamos Yandex.Disk em latim em todos os idiomas. Mas em francês, ele se transforma em um disco em francês.

Às vezes, as abreviações são reconhecidas corretamente, outras não. Neste exemplo, BY, denotando pertencer aos requisitos técnicos de publicidade da Bielorrússia, se transforma em uma desculpa em inglês.

Um dos meus exemplos favoritos são palavras novas e emprestadas. Aqui está um exemplo legal, a palavra isenção de responsabilidade, "russo nativo". A terminologia terá que ser verificada para cada parte do texto.
E mais um problema não tão significativo - a escrita desatualizada.

Anteriormente, a Internet era uma novidade, era maiúscula em todos os textos e, quando treinamos nosso mecanismo, em toda parte a Internet era capitalizada. Agora é uma nova era, a Internet já está sendo escrita com uma pequena letra. Se você deseja que seu mecanismo continue a escrever na Internet com uma letra pequena, será necessário treiná-lo novamente.

Não nos desesperamos, resolvemos esses problemas. Primeiro, eles mudaram o corpo de textos, tentaram traduzir em outros tópicos. Transmitimos nossos comentários aos colegas da Yandex.Translator, treinamos novamente a rede neural e analisamos os resultados, avaliamos e pedimos para finalizar. Por exemplo, reconhecimento de marca, processamento de marcação HTML.
Vou mostrar casos de uso reais. Temos uma boa tradução automática para documentação técnica. Este é um caso real.

Aqui está a frase em inglês e em russo. O tradutor que lidou com esta documentação foi muito encorajado pela escolha apropriada da terminologia. Outro exemplo

O tradutor apreciou a escolha de é em vez do traço, que a estrutura da frase mudou para inglês, uma escolha adequada do termo correto e a palavra você, que não está no original, mas torna essa tradução exatamente inglesa, natural.

Outro caso é a tradução de interfaces em tempo real. Um dos serviços decidiu não se preocupar com a localização e traduzir textos diretamente no momento da inicialização. Mas depois de trocar o mecanismo cerca de uma vez por mês, a palavra "entrega" mudou em um círculo. Sugerimos que a equipe conecte não um mecanismo de rede neural comum, mas o nosso, treinado em documentação técnica, para que o mesmo termo seja sempre usado, acordado com a equipe que já está na documentação.

Como tudo isso funciona por um momento monetário? Originalmente, aconteceu que um par de russo-ucraniano requer uma edição mínima da tradução em ucraniano. Portanto, alguns meses atrás, decidimos mudar para um sistema de pós-edição. É assim que nossas economias crescem. Setembro ainda não acabou, mas calculamos que reduzimos nossos custos de pós-edição em cerca de um terço em ucraniano e vamos editar quase tudo, exceto textos de marketing. A palavra Irina para resumir.
Irina:
- Para todos, fica óbvio que é necessário usá-lo, já é nossa realidade e é impossível excluí-lo de nossos processos e interesses. Mas você precisa pensar em algumas coisas.

Decida sobre os tipos de documentos, o contexto com o qual você trabalha. Esta tecnologia é adequada para você?
Segundo momento. Falamos sobre o Yandex.Translator, porque mantemos um bom relacionamento, temos acesso direto aos desenvolvedores e assim por diante, mas, na verdade, você precisa decidir qual mecanismo será o melhor para você, especificamente para o seu idioma e seu assunto. O
próximo relatório será dedicado a este tópico. Esteja preparado para que ainda haja dificuldades, os desenvolvedores dos motores estão trabalhando juntos para resolver as dificuldades, mas até agora eles ainda estão se reunindo.

Eu gostaria de entender o que nos espera no futuro. Mas, de fato, isso não está mais longe, mas nosso tempo atual, o que está acontecendo aqui e agora. Todos nós precisamos de personalização de nossa terminologia, de nossos textos, e é isso que agora está se tornando público. Agora todos estão trabalhando para garantir que você não entre na empresa, não concorde com os desenvolvedores de um mecanismo específico, como otimizar isso para você. Você poderá recebê-lo em mecanismos públicos abertos na API.
A personalização não está apenas nos textos, mas também na terminologia, para configurar a terminologia para suas próprias necessidades. Este é um ponto importante. O segundo tópico é tradução interativa. Quando um tradutor traduz um texto, a tecnologia permite prever as seguintes palavras, levando em consideração o idioma de origem, o texto de origem. Este eixo helicoidal pode facilitar muito o trabalho.
Isso agora é realmente caro. Todo mundo pensa em ensinar alguns mecanismos com muito menos eficiência, com menores quantidades de texto. É o que acontece em todo lugar e corre em todo lugar. Eu acho que o tópico é muito interessante, e então será ainda mais interessante.
Reunimos vários artigos que podem lhe interessar. Obrigada
-
Dois modelos são melhores que um. Experiência do Yandex.Translator-
Como a Yandex aplicou a tecnologia de inteligência artificial para traduzir páginas da webTradução automática. Da guerra fria à diplomacia