Nota perev. : O artigo original foi escrito por um escritor técnico do Google, trabalhando na documentação de Kubernetes (Andrew Chen) e diretor de engenharia de software da SAP (Dominik Tornow). Seu objetivo é explicar clara e claramente as noções básicas de organização e implementação de alta disponibilidade no Kubernetes. Parece-nos que os autores tiveram sucesso, por isso estamos felizes em compartilhar a tradução.
O Kubernetes é um mecanismo de orquestração de contêiner projetado para executar aplicativos em contêiner em vários nós, geralmente chamado de cluster. Nestas publicações, usamos uma abordagem de modelagem de sistemas para melhorar o entendimento do Kubernetes e seus conceitos subjacentes. Recomenda-se aos leitores que já tenham um entendimento básico do Kubernetes.
O Kubernetes é um mecanismo de orquestração de contêiner escalável e confiável. A escalabilidade aqui é determinada pela capacidade de resposta na presença de carga, e a confiabilidade é determinada pela capacidade de resposta na presença de falhas.
Observe que a escalabilidade e a confiabilidade do Kubernetes não significam a escalabilidade e a confiabilidade do aplicativo em execução. O Kubernetes é uma plataforma escalável e confiável, mas todos os aplicativos do K8s ainda precisam passar por certas etapas para se tornar um e evitar gargalos e pontos únicos de falha.
Por exemplo, se o aplicativo for implantado como ReplicaSet ou Deployment, o Kubernetes (re) planeja e (re) lança pods afetados por falhas no nó. No entanto, se o aplicativo for implantado como um pod, o Kubernetes não executará nenhuma ação no caso de uma falha no nó. Portanto, embora o próprio Kubernetes permaneça operacional, a capacidade de resposta do seu aplicativo depende da arquitetura e das decisões de implantação escolhidas.
Esta publicação foca na confiabilidade do Kubernetes. Ela fala sobre como o Kubernetes mantém a capacidade de resposta na presença de falhas.
Arquitetura Kubernetes
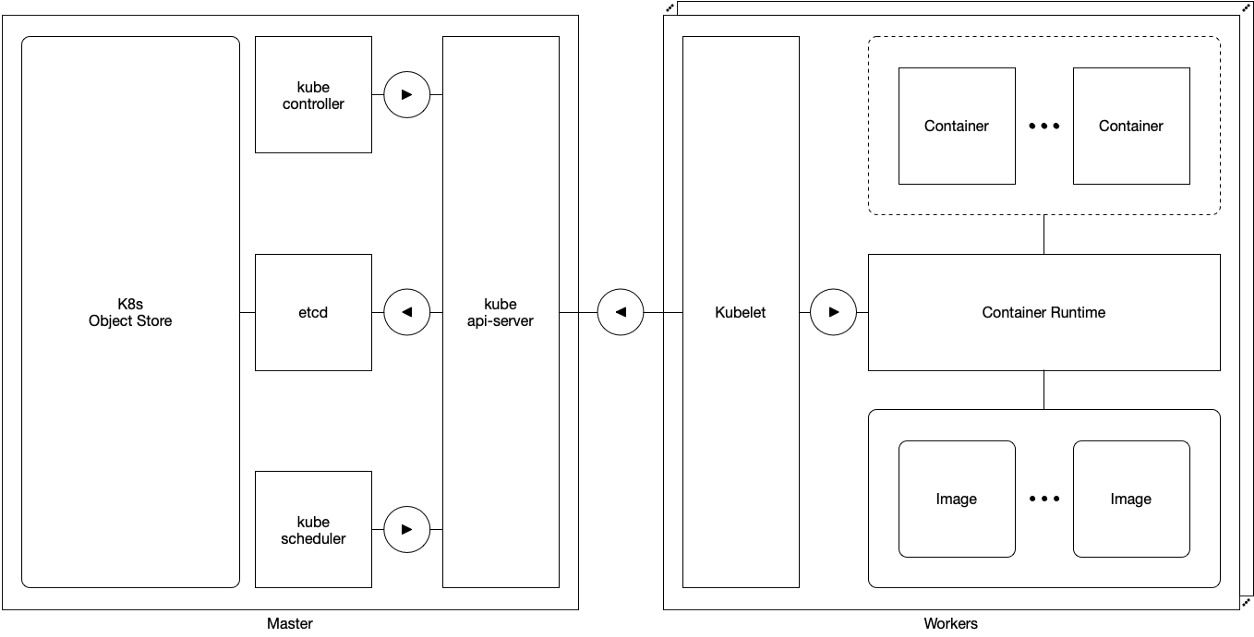
 Esquema 1. Mestre e trabalhador
Esquema 1. Mestre e trabalhadorNo nível conceitual, os componentes do Kubernetes são agrupados em duas classes distintas: componentes
mestre e componentes
trabalhador .
Os mestres são responsáveis por gerenciar tudo, exceto a execução das lareiras. Os componentes do assistente incluem:
Os trabalhadores são responsáveis por gerenciar a execução das lareiras. Eles têm um componente:
Os trabalhadores são trivialmente confiáveis: uma falha temporária ou permanente de qualquer trabalhador no cluster não afeta o mestre ou outros trabalhadores do cluster. Se o aplicativo for implantado adequadamente, o Kubernetes (re) planeja e (re) inicia qualquer um afetado pela falha do trabalhador.
Configuração de assistente único
 Esquema 2. Configuração com um único mestre
Esquema 2. Configuração com um único mestreEm uma configuração de mestre único, o cluster Kubernetes consiste em um mestre e muitos trabalhadores. Os últimos estão diretamente conectados ao assistente do kube-apiserver e interagem com ele.
Nesta configuração, a capacidade de resposta do Kubernetes depende de:
- o único mestre
- conectando trabalhadores a um único mestre.
Como o único mestre é um ponto único de falha, essa configuração não pertence à categoria de alta disponibilidade.
Configuração multi-assistente
 Esquema 3. Configuração com muitos mestres
Esquema 3. Configuração com muitos mestresEm uma configuração com vários assistentes, o cluster Kubernetes consiste em muitos assistentes e muitos trabalhadores. Os funcionários se conectam ao kube-apiserver de qualquer mestre e interagem com ele por meio de um balanceador de carga altamente acessível.
Nesta configuração, o Kubernetes
é independente de:
- o único mestre
- conectando trabalhadores a um único mestre.
Como não há um ponto único de falha nessa configuração, ela é considerada altamente acessível.
Líder e seguidor em Kubernetes
Em uma configuração multi-assistente, vários kube-controller-manager e kube-schedulers estão envolvidos. Se dois componentes modificarem os mesmos objetos, poderão surgir conflitos.
Para evitar possíveis conflitos, o Kubernetes implementa o padrão "
mestre-escravo "
(líder / seguidor) para o kube-controller-manager e o kube-scheduler. Cada grupo escolhe um líder
(ou líder) , e os demais membros do grupo assumem o papel de seguidores. A qualquer momento, apenas um líder está ativo e os seguidores são passivos.
 Figura 4. Assistente de componente de implantação redundante em detalhes
Figura 4. Assistente de componente de implantação redundante em detalhesEsta ilustração mostra um exemplo detalhado no qual o kube-controller-1 e o kube-scheduler-2 são líderes entre os gerenciadores de controladores de kube e os planejadores de kube. Como cada grupo escolhe seu próprio líder, eles não precisam estar no mesmo mestre.
Seleção de leads
Um novo líder é selecionado pelos membros do grupo no momento do lançamento ou no caso de um líder cair. Lead - um membro com o chamado
arrendamento de líder (status de líder atualmente "arrendado").
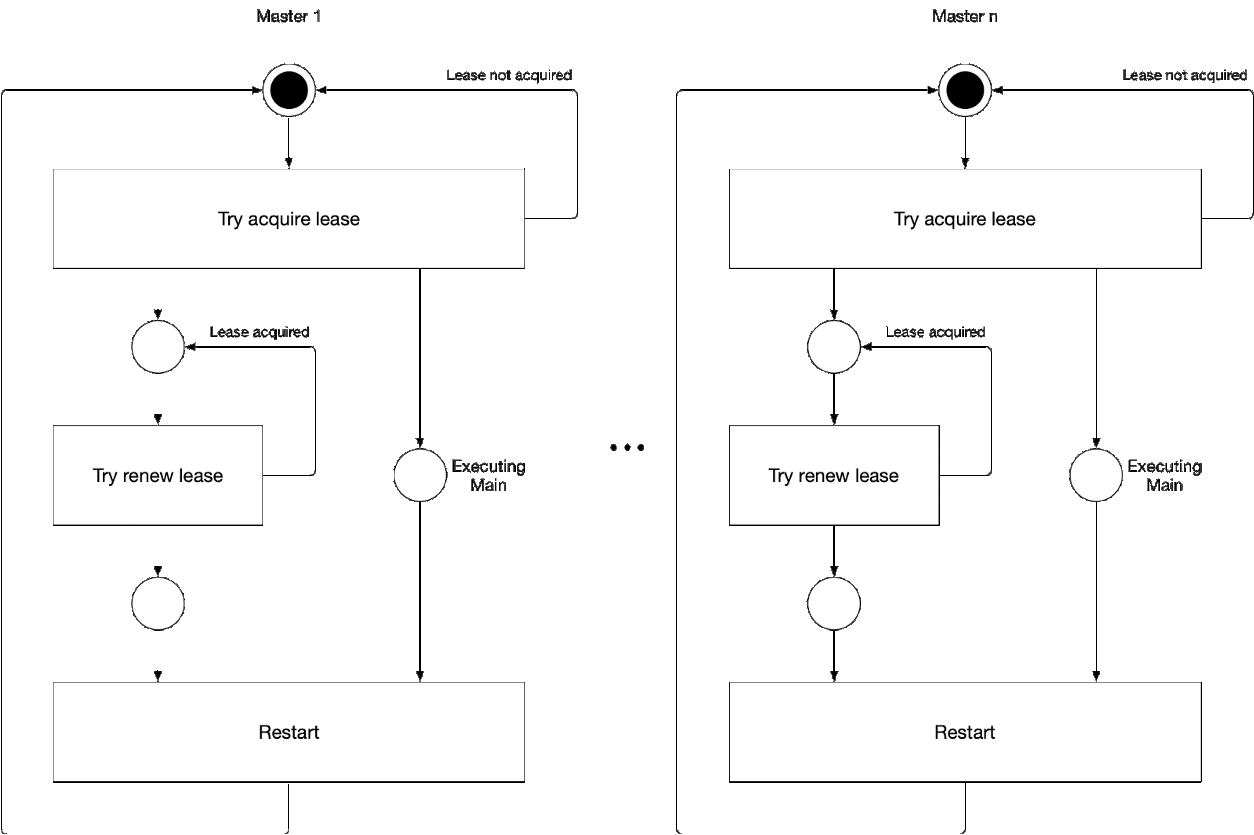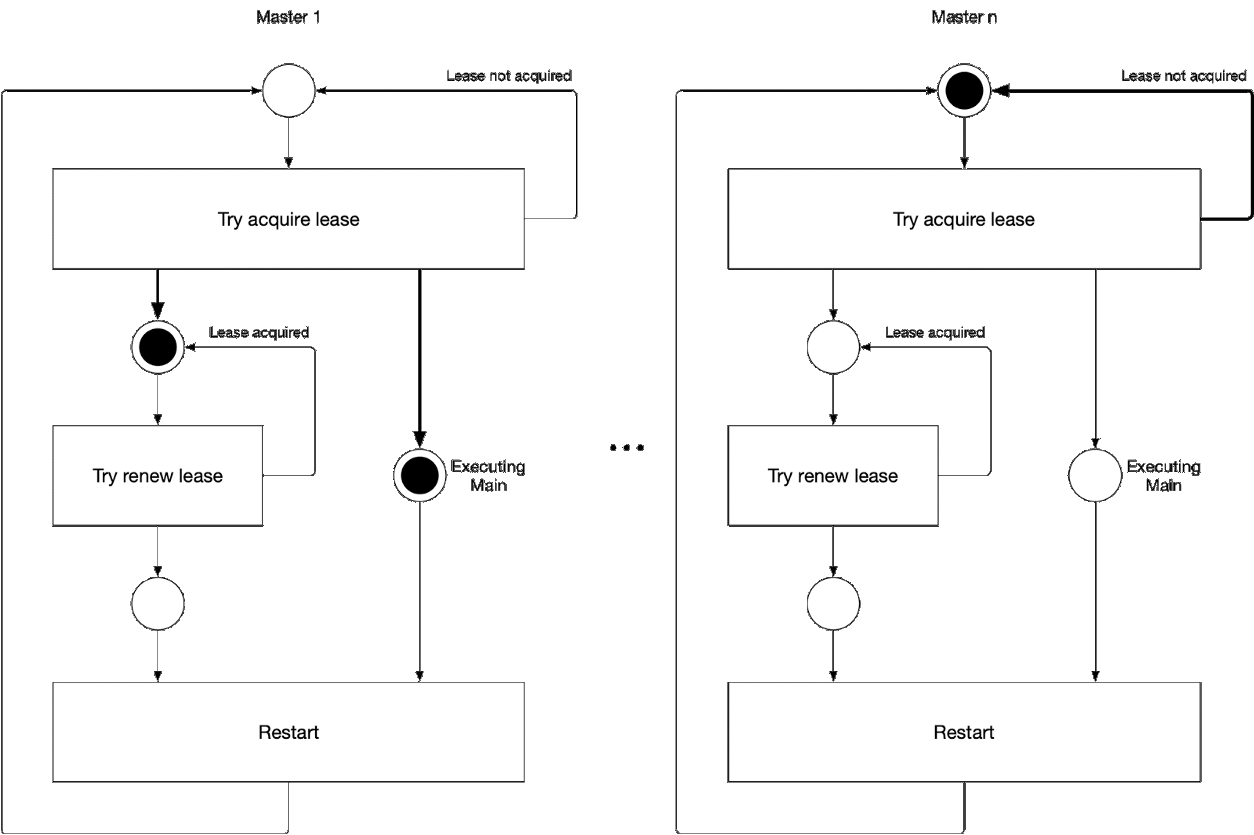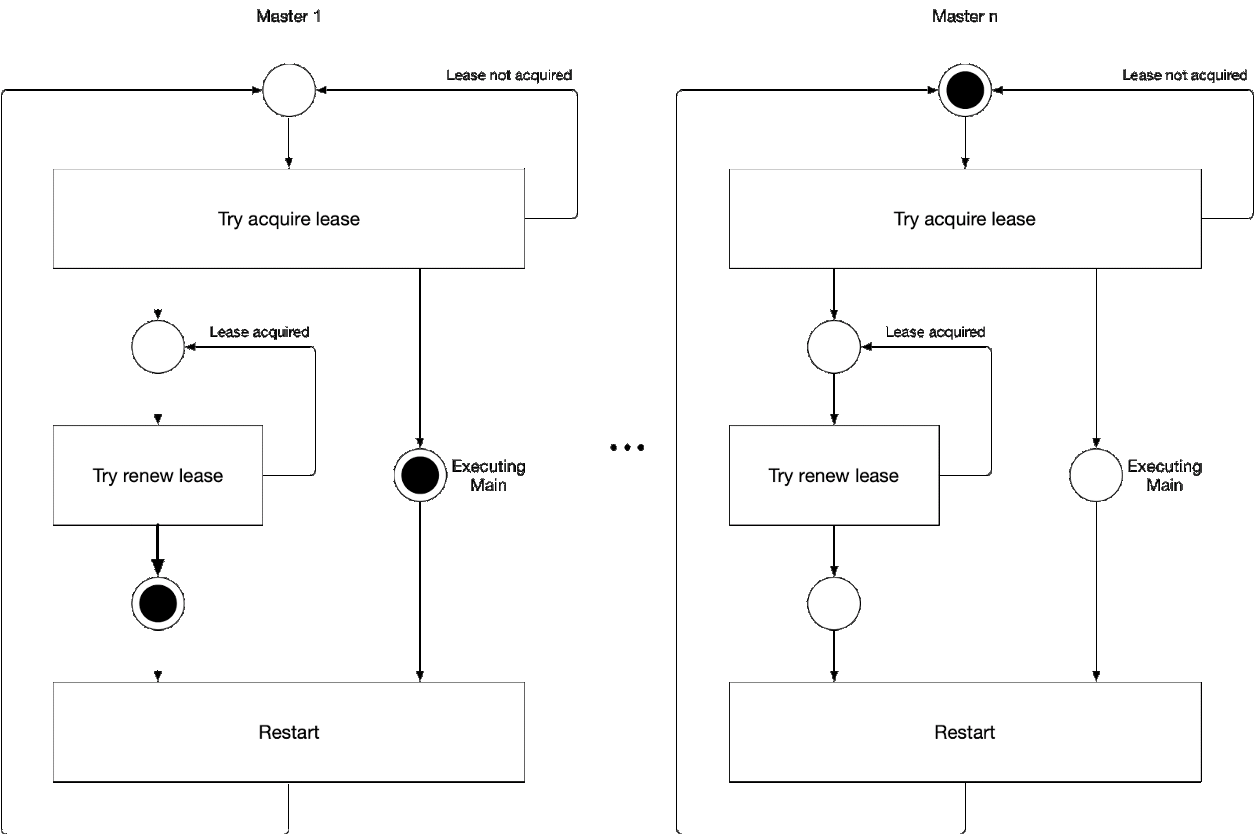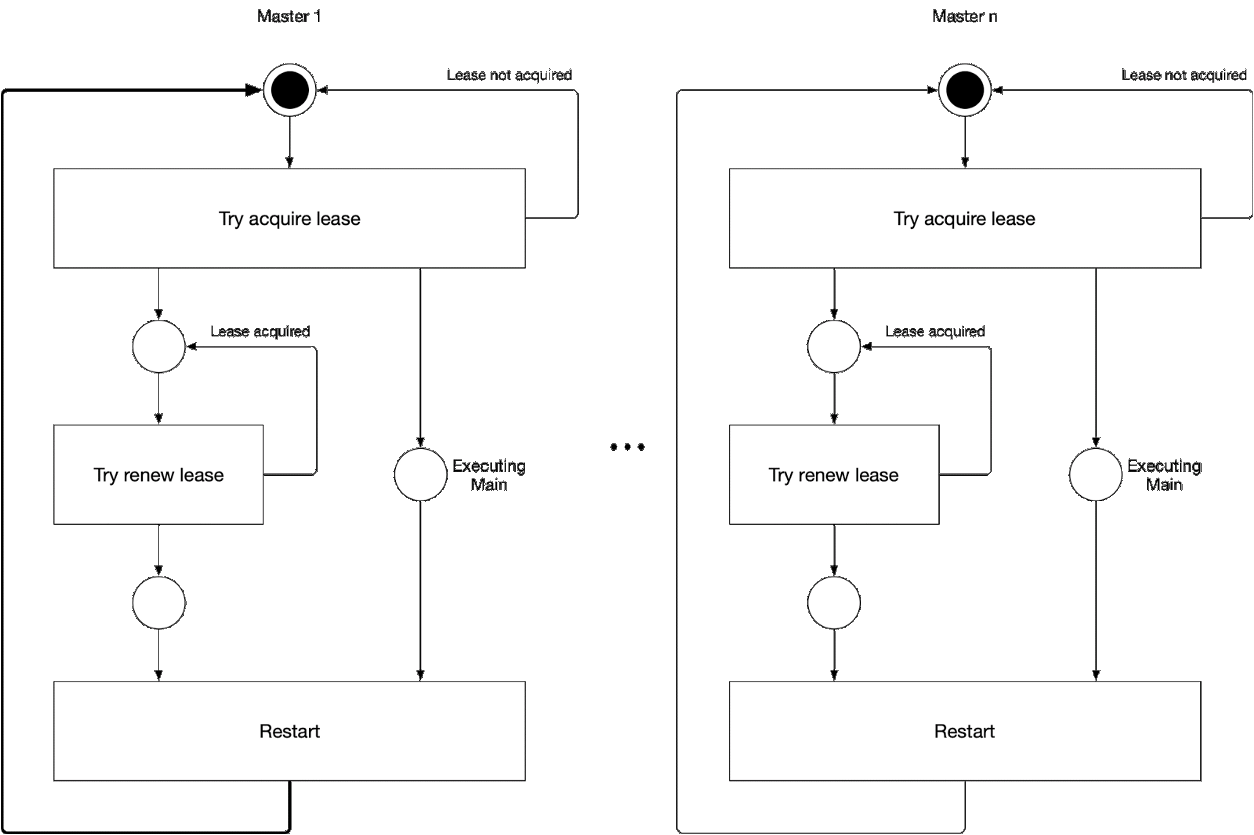 Diagrama 5. O processo de seleção do componente principal do assistente
Diagrama 5. O processo de seleção do componente principal do assistenteEsta ilustração demonstra o processo de seleção principal para o kube-controller-manager e o kube-scheduler. A lógica desse processo é a seguinte:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'Rastreamento líder
Os status atuais do líder para o kube-controller-manager e o kube-scheduler são permanentemente armazenados no armazenamento de
objetos do
kube-system como
objetos de terminais no espaço de nomes do
kube-system do
kube-system . Como dois objetos Kubernetes não podem ter o mesmo nome, tipo
(tipo) e espaço para nome ao mesmo tempo, só pode haver um
ponto de
extremidade para o kube-scheduler e o kube-controller-manager.
Demonstração usando o utilitário do console
kubectl :
$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m
O kube-scheduler e o kube-controller-manager do endpoint armazenam informações de líder na anotação
control-plane.alpha.kubernetes.io/leader :
$ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" }
Embora o Kubernetes garanta que haverá um mestre por vez, o Kubernetes não garante que dois ou mais componentes do assistente não
acreditem erroneamente que eles estão liderando atualmente - esse estado é conhecido como
cérebro dividido .
Uma discussão instrutiva sobre o tópico do cérebro dividido e as possíveis soluções pode ser encontrada no artigo
Como fazer o bloqueio distribuído de Martin Kleppmann.
O Kubernetes não usa nenhuma contramedida cerebral dividida. Em vez disso, ele confia em sua capacidade de lutar pelo estado desejado ao longo do tempo, o que mitiga as conseqüências das decisões de conflito.
Conclusão
Em uma configuração multimestre, o Kubernetes é um mecanismo de orquestração de contêiner escalável e confiável. Nesta configuração, o Kubernetes fornece confiabilidade usando uma variedade de assistentes e muitos trabalhadores. Muitos mestres trabalham no padrão mestre / escravo, e os trabalhadores trabalham em paralelo. O Kubernetes possui seu próprio processo de seleção de host, no qual as informações do host são armazenadas como
objetos de terminais .
Para obter informações sobre como preparar um cluster de alta disponibilidade do Kubernetes para operação, consulte a
documentação oficial .
Sobre publicação
Esta publicação faz parte de uma iniciativa conjunta do CNCF, Google e SAP para melhorar o entendimento do Kubernetes e seus conceitos subjacentes.PS do tradutor
Leia também em nosso blog: