Olá Habr! Meu nome é Nikolai Izhikov, trabalho para a Sberbank Technologies na equipe de desenvolvimento de soluções de código aberto. Atrás de 15 anos de desenvolvimento comercial em Java. Sou um colaborador do Apache Ignite e colaborador do Apache Kafka.
Abaixo do gato, você encontrará uma versão em vídeo e texto do meu relatório no Apache Ignite Meetup sobre como usar o Apache Ignite com o Apache Spark e quais recursos foram implementados para isso.
O que o Apache Spark pode fazer
O que é o Apache Spark? Este é um produto que permite executar rapidamente consultas distribuídas de computação e analíticas. Basicamente, o Apache Spark é escrito em Scala.
O Apache Spark possui uma API rica para conectar-se a vários sistemas de armazenamento ou receber dados. Um dos recursos do produto é um mecanismo de consulta universal semelhante ao SQL para dados recebidos de várias fontes. Se você possui várias fontes de informação, deseja combiná-las e obter alguns resultados, o Apache Spark é o que você precisa.
Uma das principais abstrações que o Spark fornece é Data Frame, DataSet. Em termos de banco de dados relacional, essa é uma tabela, uma fonte que fornece dados de maneira estruturada. A estrutura, o tipo de cada coluna, seu nome etc. são conhecidos. Os quadros de dados podem ser criados a partir de várias fontes. Exemplos incluem arquivos json, bancos de dados relacionais, vários sistemas hadoop e Apache Ignite.
O Spark suporta junções em consultas SQL. Você pode combinar dados de várias fontes e obter resultados, executar consultas analíticas. Além disso, há uma API para salvar dados. Quando você conclui as consultas, realiza um estudo, o Spark fornece a capacidade de salvar os resultados no destinatário que suporta esse recurso e, consequentemente, resolver o problema do processamento de dados.
Quais recursos implementamos para integrar o Apache Spark com o Apache Ignite
- Lendo dados das tabelas SQL do Apache Ignite.
- Gravando dados nas tabelas SQL do Apache Ignite.
- IgniteCatalog dentro do IgniteSparkSession - a capacidade de usar todas as tabelas SQL existentes do Ignite sem registrar "manualmente".
- Otimização de SQL - a capacidade de executar instruções SQL dentro do Ignite.
O Apache Spark pode ler dados das tabelas SQL do Apache Ignite e gravá-los na forma de uma tabela. Qualquer DataFrame formado no Spark pode ser salvo como uma tabela SQL do Apache Ignite.
O Apache Ignite permite que você use todas as tabelas existentes do Ignite SQL na sessão Spark sem registrar "manualmente" - usando o IgniteCatalog na extensão padrão do SparkSession - IgniteSparkSession.
Aqui você precisa se aprofundar um pouco mais no dispositivo Spark. Em termos de banco de dados regular, um diretório é um local onde as metainformações são armazenadas: quais tabelas estão disponíveis, quais colunas estão nelas etc. Quando uma solicitação chega, as meta-informações são extraídas do catálogo e o mecanismo SQL faz algo com tabelas e dados. Por padrão, no Spark, todas as tabelas de leitura (não importa, de um banco de dados relacional, Ignite, Hadoop) devem ser registradas manualmente na sessão. Como resultado, você tem a oportunidade de fazer uma consulta SQL nessas tabelas. Spark descobre sobre eles.
Para trabalhar com os dados que enviamos para o Ignite, precisamos registrar as tabelas. Porém, em vez de registrar cada tabela com nossas mãos, implementamos a capacidade de acessar automaticamente todas as tabelas do Ignite.
Qual é o recurso aqui? Por algum motivo, não sei, o diretório no Spark é uma API interna, ou seja, um estranho não pode vir e criar sua própria implementação de catálogo. E, desde que o Spark saiu do Hadoop, ele suporta apenas o Hive. E você deve registrar tudo o mais com as mãos. Os usuários frequentemente perguntam como você pode contornar isso e fazer consultas SQL imediatamente. Eu implementei um diretório que permite navegar e acessar as tabelas Ignite sem registrar ~ e sms ~, e propus inicialmente esse patch na comunidade Spark, à qual recebi uma resposta: esse patch não é interessante por alguns motivos internos. E eles não forneceram a API interna.
Agora, o catálogo Ignite é um recurso interessante implementado usando a API interna do Spark. Para usar esse diretório, temos nossa própria implementação da sessão.Este é o SparkSession usual, dentro do qual você pode fazer solicitações, processar dados. As diferenças são que integramos o ExternalCatalog a ele para trabalhar com tabelas Ignite, bem como IgniteOptimization, que serão descritas abaixo.
Otimização de SQL - a capacidade de executar instruções SQL dentro do Ignite. Por padrão, ao executar junção, agrupamento, cálculo agregado e outras consultas SQL complexas, o Spark lê dados no modo linha por linha. A única coisa que a fonte de dados pode fazer é filtrar as linhas com eficiência.
Se você usar junção ou agrupamento, o Spark atrai todos os dados da tabela para sua memória para o trabalhador, usando os filtros especificados, e somente os agrupa ou executa outras operações SQL. No caso do Ignite, isso não é o ideal, porque o próprio Ignite possui uma arquitetura distribuída e possui conhecimento dos dados armazenados nela. Portanto, o próprio Ignite pode calcular com eficiência agregados e executar agrupamentos. Além disso, pode haver muitos dados e, para agrupá-los, você precisará subtrair tudo, aumentar todos os dados no Spark, o que é bastante caro.
O Spark fornece uma API com a qual você pode alterar o plano inicial da consulta SQL, executar a otimização e encaminhar a parte da consulta SQL que pode ser executada no Ignite. Isso será eficaz em termos de velocidade e consumo de memória, porque não os usaremos para extrair dados que serão imediatamente agrupados.
Como isso funciona
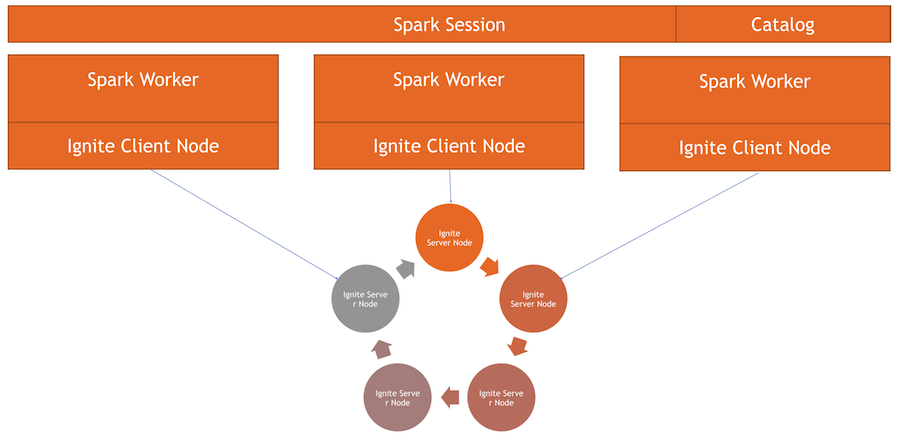
Temos um cluster Ignite - esta é a metade inferior da imagem. Não há Zookeeper, pois existem apenas cinco nós. Existem trabalhadores spark, em cada trabalhador o nó do cliente Ignite é gerado. Através dele, podemos fazer uma solicitação e ler os dados, interagir com o cluster. Além disso, o nó do cliente aumenta dentro do IgniteSparkSession para o diretório funcionar.
Ignorar quadro de dados
Passamos ao código: como ler dados de uma tabela SQL? No caso do Spark, tudo é bem simples e bom: dizemos que queremos calcular alguns dados, indicar o formato - essa é uma constante constante. Além disso, temos várias opções - o caminho para o arquivo de configuração do nó do cliente, que inicia ao ler dados. Nós indicamos qual tabela queremos ler e dizemos ao Spark para carregar. Obtemos os dados e podemos fazer o que queremos com eles.
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
Depois de gerar os dados - opcionalmente a partir do Ignite, de qualquer fonte -, podemos salvar tudo com a mesma facilidade, especificando o formato e a tabela correspondente. Nós comandamos o Spark para escrever, especificamos um formato. Na configuração, prescrevemos a qual cluster se conectar. Especifique a tabela na qual queremos salvar. Além disso, podemos prescrever opções de utilidade - especifique a chave primária que criamos nesta tabela. Se os dados simplesmente perturbarem sem criar uma tabela, esse parâmetro não será necessário. No final, clique em Salvar e os dados são gravados.
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
Agora vamos ver como tudo funciona.
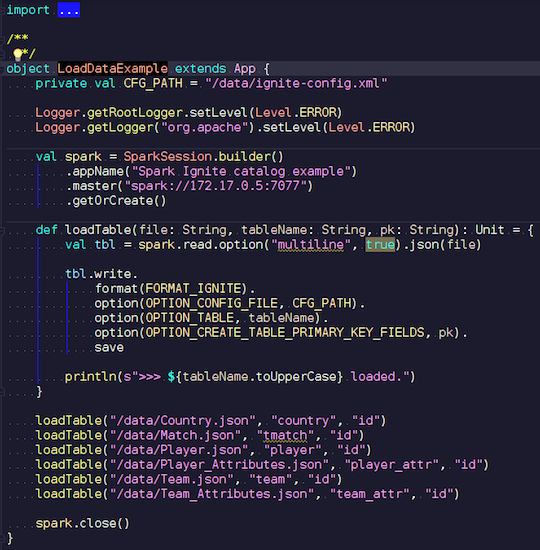 LoadDataExample.scala
LoadDataExample.scalaEsta aplicação óbvia demonstrará primeiro os recursos de gravação. Por exemplo, escolhi os dados das partidas de futebol, baixei as estatísticas de um recurso conhecido. Ele contém informações sobre torneios: ligas, partidas, jogadores, equipes, atributos de jogadores, atributos de equipes - dados que descrevem partidas de futebol em ligas de países europeus (Inglaterra, França, Espanha, etc.).
Quero enviá-los para o Ignite. Criamos uma sessão do Spark, especificamos o endereço do assistente e chamamos o carregamento dessas tabelas, passando parâmetros. O exemplo está no Scala, não no Java, porque o Scala é menos detalhado e, portanto, melhor por exemplo.
Nós transferimos o nome do arquivo, lemos, indicamos que é multilinha, este é um arquivo json padrão. Então nós escrevemos em Ignite. A estrutura do nosso arquivo não pode ser descrita em nenhum lugar - o próprio Spark determina quais dados temos e qual é a estrutura deles. Se tudo correr bem, é criada uma tabela na qual existem todos os campos necessários dos tipos de dados necessários. É assim que podemos carregar tudo dentro do Ignite.
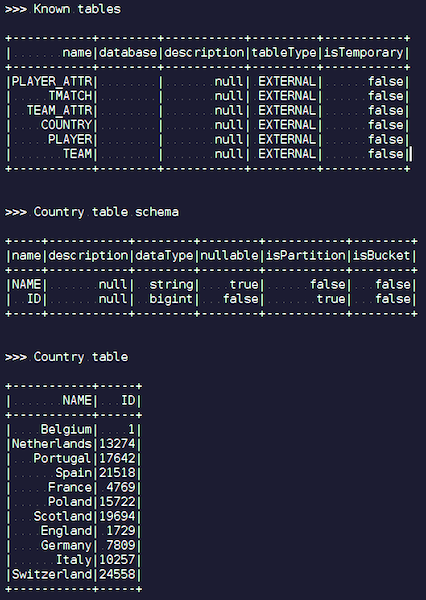
Quando os dados são carregados, podemos vê-los no Ignite e usá-los imediatamente. Como um exemplo simples, uma consulta que permite saber qual time jogou mais partidas. Temos duas colunas: hometeam e awayteam, anfitriões e convidados. Selecionamos, agrupamos, contamos, somamos e juntamos os dados do comando - para inserir o nome do comando. Ta-dam - e os dados de json-chiks que entramos no Ignite. Vemos Paris Saint-Germain, Toulouse - temos muitos dados sobre as equipes francesas.
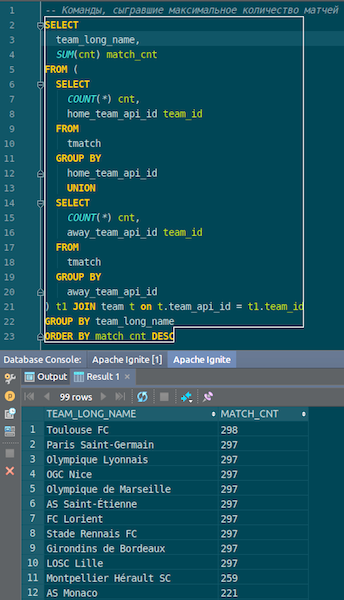
Resumimos. Agora, carregamos dados da fonte, arquivo json, para Ignite, e rapidamente. Talvez, do ponto de vista do big data, isso não seja muito grande, mas decente para um computador local. O esquema da tabela é obtido do arquivo json em sua forma original. A tabela foi criada, os nomes das colunas foram copiados do arquivo de origem e a chave primária foi criada. O ID está em toda parte e a chave primária é o ID. Esses dados entraram no Ignite, podemos usá-los.
IgniteSparkSession e IgniteCatalog
Vamos ver como isso funciona.
 CatalogExample.scala
CatalogExample.scalaDe uma maneira bastante simples, você pode acessar e consultar todos os seus dados. No último exemplo, iniciamos a sessão padrão do spark. E não havia especificidade no Ignite - exceto que você precisa colocar um jar com a fonte de dados correta - trabalho completamente padrão por meio da API pública. Mas, se você deseja acessar as tabelas Ignite automaticamente, pode usar nossa extensão. A diferença é que, em vez do SparkSession, escrevemos IgniteSparkSession.
Assim que você cria um objeto IgniteSparkSession, você vê no diretório todas as tabelas que foram carregadas no Ignite. Você pode ver o diagrama e todas as informações. O Spark já conhece as tabelas que o Ignite possui e você pode obter facilmente todos os dados.
Otimização de ignição
Quando você faz consultas complexas no Ignite usando JOIN, o Spark puxa os dados primeiro e somente depois JOIN os agrupa. Para otimizar o processo, criamos o recurso IgniteOptimization - ele otimiza o plano de consulta do Spark e permite encaminhar as partes da solicitação que podem ser executadas no Ignite dentro do Ignite. Mostramos otimização em uma solicitação específica.
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
Atendemos o pedido. Temos uma mesa pessoal - alguns funcionários, pessoas. Cada funcionário conhece o ID da cidade em que vive. Queremos saber quantas pessoas vivem em cada cidade. Nós filtramos - em qual cidade mais de uma pessoa vive. Aqui está o plano inicial que o Spark cria:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
A relação é apenas uma tabela Ignite. Não há filtros - simplesmente bombeamos todos os dados da tabela Pessoa pela rede a partir do cluster. Então o Spark agrega tudo isso - de acordo com a solicitação e retorna o resultado da solicitação.
É fácil ver que toda essa subárvore com filtro e agregação pode ser executada no Ignite. Isso será muito mais eficiente do que extrair todos os dados de uma tabela potencialmente grande no Spark - é isso que nosso recurso IgniteOptimization faz. Após analisar e otimizar a árvore, obtemos o seguinte plano:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
Como resultado, temos apenas uma relação, pois otimizamos toda a árvore. E, por dentro, você já pode ver que o Ignite enviará uma solicitação próxima o suficiente da solicitação original.
Suponha que estamos juntando fontes de dados diferentes: por exemplo, temos um DataFrame do Ignite, o segundo do json, o terceiro do Ignite novamente e o quarto de algum tipo de banco de dados relacional. Nesse caso, apenas a subárvore será otimizada no plano. Otimizamos o que podemos, colocamos no Ignite e o Spark fará o resto. Devido a isso, obtemos um ganho de velocidade.
Outro exemplo com JOIN:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
Nós temos duas mesas. Permanecemos juntos por valor e selecionamos todos eles - IDs, valores. O Spark oferece esse plano:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
Vemos que ele extrai todos os dados de uma tabela, todos os dados da segunda, junta-se a eles dentro de si e fornece os resultados. Após o processamento e a otimização, recebemos exatamente a mesma solicitação que é enviada ao Ignite, onde é executada relativamente rapidamente.
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
Eu vou te mostrar um exemplo
 OptimizationExample.scala
OptimizationExample.scalaEstamos criando uma sessão do IgniteSpark na qual todos os nossos recursos de otimização já estão incluídos automaticamente. Aqui está o pedido: encontre os jogadores com a classificação mais alta e mostre seus nomes. Na tabela de jogadores, seus atributos e dados. Estamos nos unindo, filtrando dados indesejados e exibindo jogadores com a classificação mais alta. Vamos ver o tipo de plano que temos após a otimização e mostrar os resultados dessa consulta.
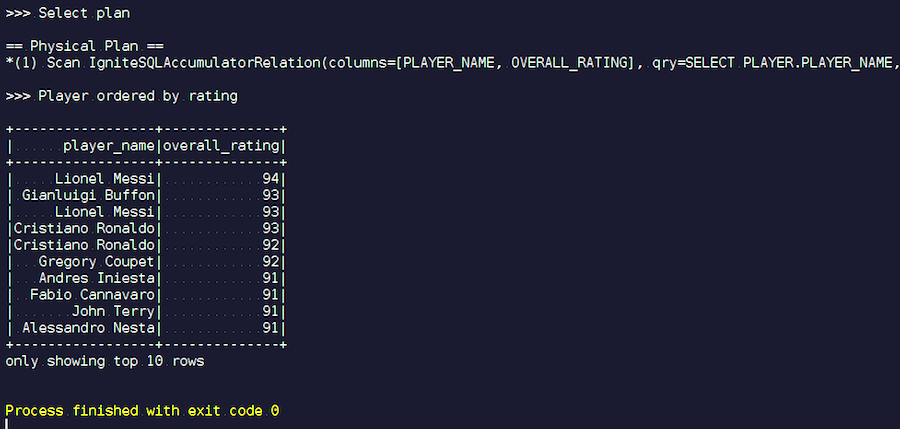
Começamos. Vemos sobrenomes familiares: Messi, Buffon, Ronaldo, etc. A propósito, alguns, por algum motivo, se encontram de duas formas: Messi e Ronaldo. Os amantes do futebol podem achar estranho que jogadores desconhecidos apareçam na lista. Estes são goleiros, jogadores com características bastante altas - no contexto de outros jogadores. Agora, examinamos o plano de consulta que foi executado. No Spark, quase nada foi feito, ou seja, enviamos todo o pedido novamente ao Ignite.
Apache Ignite Development
Nosso projeto é um produto de código aberto, por isso estamos sempre felizes com as correções e o feedback dos desenvolvedores. Sua ajuda, feedback e correções são muito bem-vindos. Estamos esperando por eles. 90% da comunidade Ignite é de língua russa. Por exemplo, para mim, até começar a trabalhar no Apache Ignite, o melhor conhecimento de inglês não era um impedimento. Dificilmente vale a pena escrever em russo em uma lista de desenvolvedores, mas mesmo se você escrever algo errado, eles responderão e o ajudarão.
O que pode ser aprimorado nessa integração? Como posso ajudar se você tem esse desejo? Listar abaixo. Asteriscos indicam complexidade.

Para testar a otimização, você precisa escrever testes com consultas complexas. Acima, mostrei algumas consultas óbvias. É claro que se você escrever muitos agrupamentos e muitas junções, algo poderá cair. Essa é uma tarefa muito simples - venha e faça. Se encontrarmos algum bug com base nos resultados do teste, eles precisarão ser corrigidos. Será mais difícil lá.
Outra tarefa clara e interessante é a integração do Spark com um thin client. Inicialmente, ele pode especificar alguns conjuntos de endereços IP, e isso é suficiente para ingressar no cluster Ignite, o que é conveniente em caso de integração com um sistema externo. Se de repente você quiser se juntar à solução para esse problema, eu ajudarei pessoalmente.
Se você deseja ingressar na comunidade Apache Ignite, aqui estão alguns links úteis:
Temos uma lista de desenvolvedores responsiva, que o ajudará. Ainda está longe do ideal, mas em comparação com outros projetos, ele está realmente vivo.
Se você conhece Java ou C ++, está procurando trabalho e deseja desenvolver Open Source (Apache Ignite, Apache Kafka, Tarantool, etc.) escreva aqui: join-open-source@sberbank.ru.