Uma vez eu já escrevi aqui sobre a mudança da Ásia para a Europa e agora quero escrever o que estou fazendo nesta Europa. Existe uma profissão - DevOps , ou melhor, não, mas aconteceu que é exatamente isso que estou fazendo agora. Agora, para a orquestração de tudo o que é executado na janela de encaixe, usamos um fazendeiro , sobre o qual também escrevi . Mas então aconteceu uma coisa terrível: o Rancher 2.0 saiu e mudou-se para o kubernetes (daqui em diante simplesmente k8s) e como o k8s agora é realmente o padrão para gerenciar o cluster, havia um desejo de construir toda a infraestrutura novamente com blackjack e bibliotecários. O que acrescenta interesse é que a empresa contrata constantemente especialistas de diferentes países e com tradições diferentes, e alguém traz puppet , alguém é ansible que ansible e alguém geralmente acredita que Makefile + bash é o nosso tudo. Portanto, simplesmente não há uma opinião inequívoca de como tudo deve funcionar, mas eu realmente quero.
Esse zoológico de tecnologias e ferramentas foi montado anteriormente:

Gerenciamento de infraestrutura
- Minikube
- Rke
- Terraform
- Kops
- Kubespray
- Ansible
Gerenciamento de aplicativos
- Kubernetes
- Rancheiro
- Kubectl
- Elmo
- Confd
- Kompose
- Jenkins
Registro e Monitoramento
- Elasticsearch
- Kibana
- Bit fluente
- Telegraf
- Influxdb
- Zabbix
- Prometeu
- Grafana
- Kapacitor
Em seguida, tentarei descrever brevemente cada ponto deste zoológico, descrever por que é necessário e por que essa solução foi escolhida. De fato, quase qualquer item pode ser substituído por uma dúzia de análogos e ainda não temos certeza absoluta da escolha; portanto, se alguém tiver uma opinião ou recomendações, vou lê-lo nos comentários com prazer.
O Kubernetes será o centro de tudo, porque agora é realmente uma solução que simplesmente não possui alternativas, suportada por todos os provedores da Amazon e da Microsoft ao mail.ru. Como as alternativas foram consideradas
Swarm - que nunca decolouNomad - que parece ser escrito por estranhos para predadoresCattle é o motor do ranger 1.x, no qual vivemos agora, em princípio, está tudo bem, mas o fazendeiro já o abandonou a favor dos k8s, para que não haja desenvolvimento.
Construção de infraestrutura
Primeiro, precisamos criar a infraestrutura e implantar um cluster k8s nela. Existem várias opções, todas elas funcionam e, portanto, é difícil escolher a melhor.
O Minikube é uma ótima opção para iniciar um cluster na máquina de um desenvolvedor, para fins de teste.
Rke - mecanismo kubernetes Rancher, simples como uma porta; configuração mínima para criar um cluster
nodes: - address: localhost role: [controlplane,worker,etcd]
E isso é o suficiente para iniciar o cluster na máquina local, enquanto permite criar clusters de alta disponibilidade para produção, alterar a configuração, atualizar o cluster, despejar o banco de dados etcd e muito mais.
Kops - não apenas permite criar um cluster, mas também pré-criar instâncias no aws ou gce. Também permite gerar uma configuração para terraform. Uma ferramenta interessante, mas ainda não criamos raízes. É completamente substituído pelo terraform + rke enquanto é mais simples e flexível.
Kubespray - na verdade, é apenas um papel ansível que cria um cluster do k8s, poderoso, flexível e configurável. Essa é praticamente a solução padrão para a implantação do k8s.
O Terraform é uma ferramenta para a construção de infraestrutura em aws, azure ou em vários outros lugares. Flexível, estável - eu recomendo.
O Ansible não é realmente sobre o k8s, mas o usamos em todos os lugares e também aqui: ajustes de configurações, instalação / atualização de software, distribuição de certificados. Barato e alegre.
Gerenciamento de aplicativos
Portanto, temos um cluster, agora precisamos iniciar algo útil, tudo o que resta é a questão de como fazer isso.
Opção 1: use k8s nus, todos implementados usando o kubectl . Em princípio, esta opção tem direito à vida. O Kubectl é uma ferramenta poderosa o suficiente que nos permite fazer tudo o que precisamos, incluindo implantação, atualização, monitoramento do estado atual, alteração da configuração em tempo real, visualização de logs e conexão a contêineres específicos. Mas às vezes eu quero que tudo seja um pouco mais conveniente, então seguimos em frente.
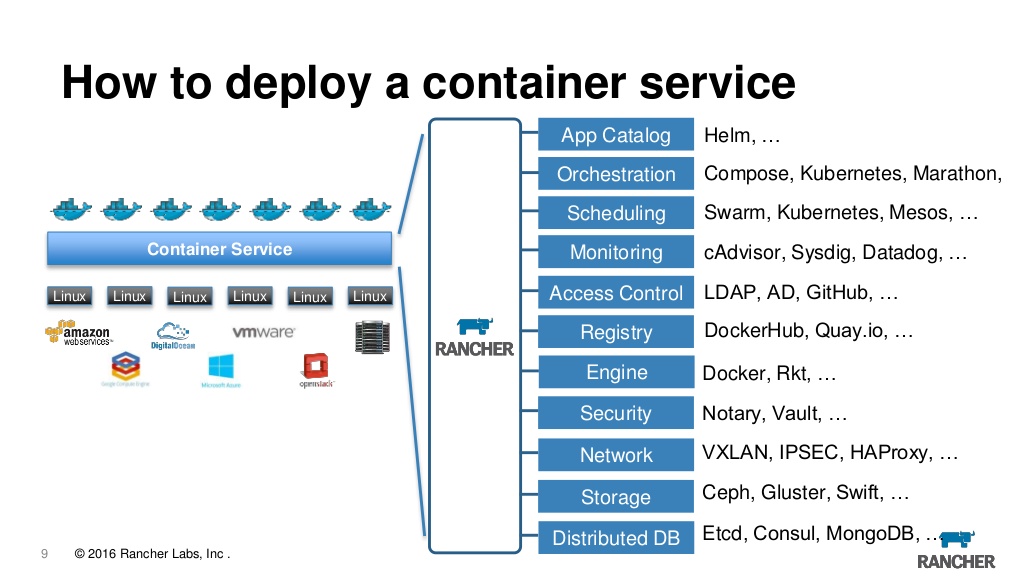
De fato, agora o fazendeiro é um focinho da web para gerenciar k8s e ao mesmo tempo muitos pequenos bolos que adicionam conveniência. Aqui você pode visualizar logs, acessar o console e configurar e atualizar aplicativos e controle de acesso baseado em funções e um servidor de metadados integrado, alarmes, redirecionamento de logs, gerenciamento de segredos e muito mais. Estamos usando a primeira versão do rancher há vários anos e estamos completamente satisfeitos com ela, embora devamos admitir que, ao mudar para o k8s, surge a pergunta se realmente precisamos dela. É bom que você possa importar qualquer cluster criado anteriormente para o rancher e, de qualquer provedor, ou seja, você pode importar um cluster do EKS do azure e criado localmente e conduzi-los de um local para um servidor. Além disso, se você ficar entediado de repente, poderá simplesmente demolir o servidor e continuar usando o cluster diretamente através do kubeclt ou de qualquer outra ferramenta.
O conceito muito correto de tudo como código agora é popular. Por exemplo, a infraestrutura como código é implementada usando terraform , a montagem como código é implementada através do jenkins pipeline . Agora chegou a vez do aplicativo. A instalação e a configuração do aplicativo também devem ser descritas em algum manifesto e salvas no git. As versões 1.x do Rancher usavam o docker-compose.yml padrão e tudo estava bem, mas quando mudaram para o k8s, mudaram para os helm charts . Helm é, do meu ponto de vista, um compartilhamento absolutamente terrível com lógica e arquitetura estranhas. Esse é um daqueles projetos dos quais permanece o sentimento de que foi escrito por predadores para estranhos ou vice-versa. O único problema é que no mundo do leme do k8s simplesmente não há alternativas e esse é de fato o padrão. Portanto, seremos levados a chorar, mas continuaremos a usar o leme. Na versão 3.x, os desenvolvedores prometem reescrevê-lo do zero, jogando fora todas as esquisitices e simplificando a arquitetura. É então que vamos curar, mas por enquanto vamos comer o que é.
Também precisamos pelo menos mencionar jenkins aqui, ele não se relaciona diretamente ao tópico do kubernetis, mas é com sua ajuda que os aplicativos são implantados no cluster. Ele é, ele trabalha e é um tópico para um artigo separado.
Monitoramento
Agora temos um cluster e ele está girando até algum tipo de aplicativo, parece que você pode expirar, mas, na verdade, tudo está apenas começando. Quão estável é a nossa aplicação? Quão rápido Ele tem recursos suficientes? O que geralmente está acontecendo no cluster?
Sim, o próximo tópico é monitoramento e registro. Existem apenas três respostas definidas. Armazene os logs na pesquisa elasticsearch , observe-os no kibana desenhar gráficos no grafana . Para todas as outras perguntas, há uma dúzia de respostas corretas.
Aqui começamos com o grafana por si só, ele praticamente não faz nada, mas pode ser fixado como um rosto bonito em qualquer um dos sistemas descritos abaixo e obter gráficos bonitos e às vezes claros; além disso, você pode configurar alarmes imediatamente, mas é melhor usar outras soluções para isso, por exemplo, prometheus alertmanager e ElastAlert .
Do meu ponto de vista, no momento, este é o melhor agregador e roteador de logs, além disso, pronto para uso, ele tem o suporte do k8s. Também existe o Fluentd mas é escrito em rublos e extrai muito código legado, o que o torna muito menos atraente. Portanto, se você precisar de algum módulo específico do fluentd que ainda não tenha sido portado para o bit fluente, use-o, em todo o resto - o bit é a melhor escolha. É mais rápido, mais estável, consome menos memória. Permite coletar logs de todos ou de contêineres selecionados, filtrá-los, enriquecê-los adicionando dados específicos ao kubernetis e enviá-los para a elasticsearch ou para muitos outros repositórios. Se você compará-lo com o tradicional logstash + docker-bit + file-bit esta solução é definitivamente melhor em todos os aspectos. Historicamente, ainda usamos logspout + logstash mas o bit fluente definitivamente vence.
Um sistema de monitoramento criado especificamente para a arquitetura de microsserviço. Além disso, o padrão de fato da indústria também existe um projeto chamado Prometheus Operator , escrito especificamente para os k8s. Todo mundo decide o que escolher, mas é melhor começar com o prometheus, apenas para entender a lógica de seu trabalho, é bem diferente dos sistemas usuais. Também precisamos mencionar node-exporter que permite coletar métricas no nível da máquina e prometheus-rancher-exportador, que permite coletar métricas através da API do fazendeiro. Em geral, se você possui um cluster no kubernetes, o prometheus é obrigatório.
Pode-se parar por aqui, mas historicamente, temos vários outros sistemas de monitoramento. Primeiramente, zabbix muito conveniente para o zabbix ver todos os problemas de toda a infraestrutura em um painel. A presença da descoberta automática permite encontrar e adicionar rapidamente novas redes, nós, serviços e geralmente quase tudo ao monitoramento, o que a torna mais do que uma ferramenta conveniente para monitorar infraestruturas dinâmicas. Além disso, na versão 4.0, uma coleção de métricas de exportadores de prometheus foi adicionada ao zabbix e acontece que tudo isso pode ser muito bem integrado em um sistema. Embora ainda não haja uma resposta definitiva se é necessário arrastar o zabbix para um cluster k8s, é definitivamente interessante tentar.
Como alternativa, você pode usar o TIG (telegraf + influxdb + grafana) fácil de configurar, funciona de forma estável, permite agregar métricas por contêiner, aplicativo, nó etc., mas duplica essencialmente a funcionalidade do prometheus, e deve haver apenas um.
E, portanto, antes de iniciar qualquer coisa útil, você precisa instalar e configurar a ligação a partir de algumas dezenas de serviços e ferramentas auxiliares. Ao mesmo tempo, o artigo não levantou questões sobre o gerenciamento de dados persistentes, segredos e outras coisas estranhas, cada um dos quais pode ser direcionado para uma publicação separada.
E como você vê a infraestrutura ideal?
Se você tem uma opinião, escreva nos comentários ou talvez se junte à nossa equipe e ajude a juntar tudo.