Certa vez, em uma entrevista, um conhecido músico russo disse: "Estamos trabalhando para mentir e cuspir no teto". Não posso discordar dessa afirmação, porque o fato de a preguiça ser a força motriz do desenvolvimento da tecnologia não pode ser discutido. De fato, somente no século passado passamos de máquinas a vapor para a industrialização digital, e agora a inteligência artificial, descrita por escritores de ficção científica e futurologistas do século passado, está se tornando uma realidade cada vez maior do mundo todos os dias. Jogos de computador, dispositivos móveis, relógios inteligentes e muito mais basicamente usam algoritmos associados a mecanismos de aprendizado de máquina.
Atualmente, devido ao crescimento das capacidades de computação dos processadores gráficos e à grande quantidade de dados que apareceu, as redes neurais ganharam popularidade, usando as quais resolvem problemas de classificação e regressão, treinando-os em dados preparados. Muitos artigos já foram escritos sobre como treinar redes neurais e quais estruturas usar para isso. Mas há uma tarefa anterior que também precisa ser resolvida, e essa é a tarefa de formar uma matriz de dados - um conjunto de dados, para treinamento adicional da rede neural. Isso será discutido neste artigo.
Há pouco tempo, era necessário criar um classificador acústico de ruídos de carros, capaz de extrair dados de um fluxo de áudio comum: cacos de vidro, portas que se abrem e a operação de um motor de carro em vários modos. O desenvolvimento do classificador não foi difícil, mas onde obter o conjunto de dados para que ele atenda a todos os requisitos?
O Google veio em socorro (sem ofensa à Yandex - falarei sobre suas vantagens um pouco mais tarde), com a ajuda da qual foi possível destacar vários grupos principais que contêm os dados necessários. Quero observar com antecedência que as fontes indicadas neste artigo incluem uma grande quantidade de informações acústicas, com várias classes, permitindo que você crie um conjunto de dados para diferentes tarefas. Agora, passamos a uma visão geral dessas fontes.
Freesound.org
Provavelmente, o
Freesound.org fornece o maior volume de dados acústicos, sendo um repositório conjunto de amostras de música licenciadas, que atualmente possui mais de 230.000 cópias de efeitos sonoros. Cada amostra de som pode ser distribuída sob uma licença diferente; portanto, é melhor se familiarizar com o
contrato de licença com antecedência. Por exemplo, a licença
zero (cc0) tem o status "Sem direitos autorais" e permite copiar, modificar e distribuir, incluindo uso comercial, e permite usar os dados de maneira absolutamente legal.
Para a conveniência de encontrar elementos de informação acústica em uma variedade de freesound.org, os desenvolvedores forneceram uma
API projetada para analisar, pesquisar e baixar dados de repositórios. Para trabalhar com isso, você precisa obter acesso, para isso, precisa ir ao
formulário e preencher todos os campos necessários, após os quais a chave individual será gerada.

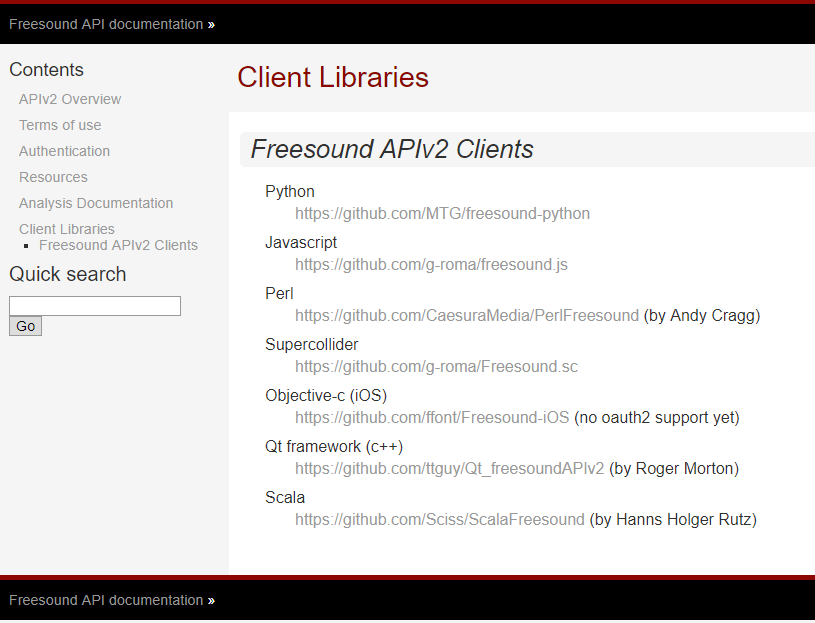
Os desenvolvedores do Freesound.org fornecem
APIs para várias linguagens de programação, permitindo assim resolver o mesmo problema com ferramentas diferentes. A lista de idiomas e links suportados para acessá-los no GitHub estão listados abaixo.
Para atingir esse objetivo, o python foi usado, pois essa bela linguagem de programação de digitação dinâmica ganhou popularidade devido à sua facilidade de uso, apagando completamente o mito da complexidade do desenvolvimento de software.
O módulo para trabalhar com o freesound.org para python pode ser clonado no repositório github.com.
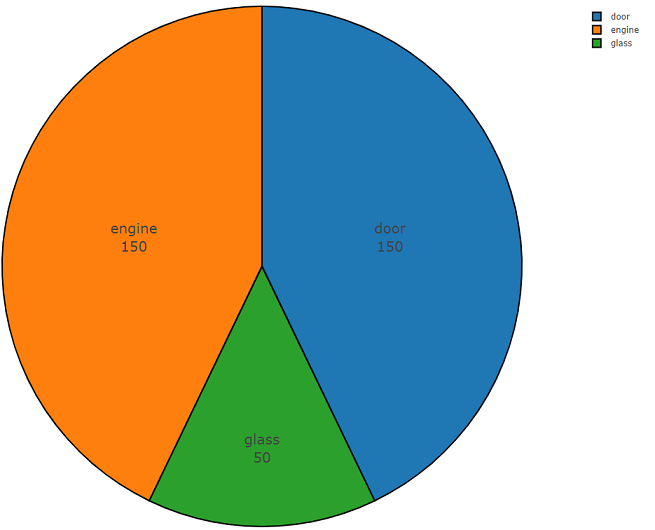
Abaixo está o código de duas partes que demonstra a facilidade de uso desta API. A primeira parte do código do programa executa a tarefa de análise de dados, cujo resultado é a densidade da distribuição de dados para cada classe solicitada, e a segunda parte carrega dados dos repositórios do freesound.org para as classes selecionadas. A densidade de distribuição ao procurar informações acústicas com as palavras-chave
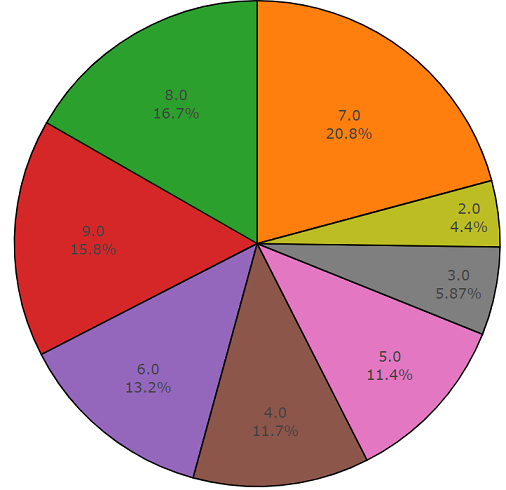
glass, engine, door é apresentada abaixo em um gráfico de pizza como exemplo.
Código de exemplo da análise de dados do Freesound.org
import plotly import plotly.graph_objs as go import freesound import os import termcolor
Código de exemplo para baixar dados do freesound.org
Uma característica do freesound é que a análise dos dados de áudio pode ser realizada sem o download de um arquivo de áudio, permitindo obter MFCC, energia espectral, centróide espectral e outros coeficientes. Leia mais sobre informações de baixo nível na
documentação do
freesound.ord .
Usando a API freesound.org, o tempo gasto na busca e no download de dados é minimizado, permitindo que você economize horas de trabalho estudando outras fontes de informação, uma vez que os classificadores acústicos de alta precisão exigem um grande conjunto de dados com grande variabilidade, representando dados com diferentes harmônicos em um e a mesma classe de eventos.
YouTube-8M e AudioSet
Eu acho que o youtube não é particularmente necessário na apresentação, mas, no entanto, a Wikipedia nos diz que o youtube é um site de hospedagem de vídeo que fornece aos usuários serviços de exibição de vídeo, esquecendo de dizer que o youtube é um grande banco de dados e que essa fonte deve ser usada no aprendizado de máquina , e o Google Inc nos fornece um projeto chamado
Conjunto de dados YouTube-8M .
O conjunto de dados YouTube-8M é um conjunto de dados que inclui mais de um milhão de arquivos de vídeo do YouTube em alta qualidade, para fornecer informações mais precisas. Em maio de 2018, havia 6,1 milhões de vídeos com 3862 classes. Este conjunto de dados está licenciado sob
Creative Commons Attribution 4.0 International (CC BY 4.0) . Essa licença permite copiar e distribuir material em qualquer mídia e formato.
Você provavelmente se pergunta: de onde vêm os dados do vídeo quando são necessárias informações acústicas para a tarefa e você estará muito certo. O fato é que o Google fornece não apenas conteúdo de vídeo, mas também aloca separadamente um subprojeto com dados de áudio chamados
AudioSet .
 AudioSet
AudioSet - fornece um conjunto de dados obtido a partir de vídeos do YouTube, onde muitos dados são apresentados em uma hierarquia de classes usando
um arquivo de ontologia , e sua representação gráfica está localizada abaixo.
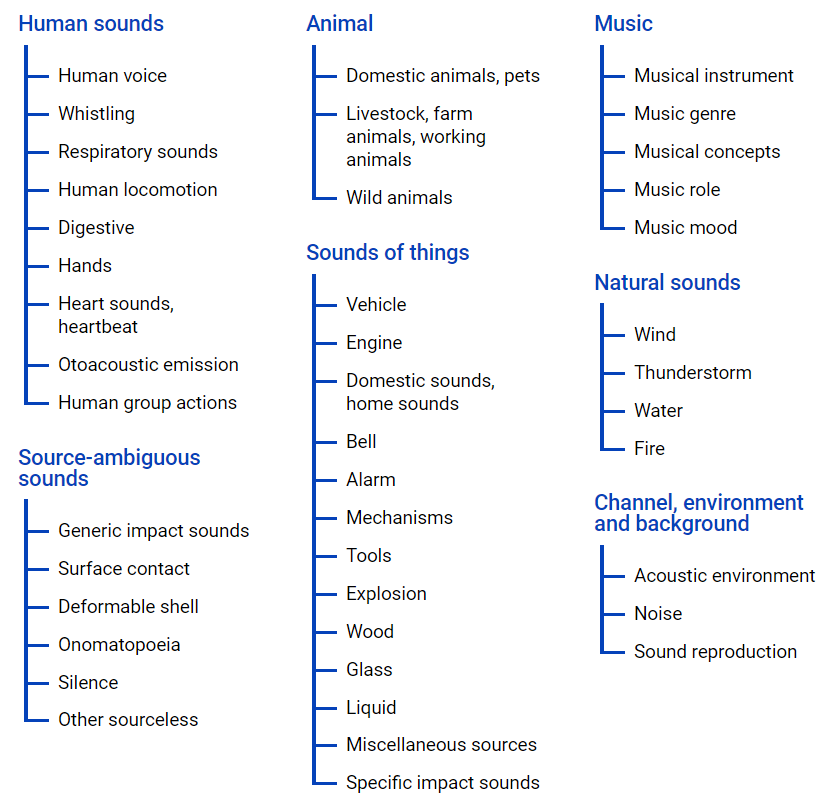
Este arquivo permite que você tenha uma idéia do aninhamento de classes, bem como acesso a vídeos do youtube. Para fazer upload de dados do espaço da Internet, você pode usar o módulo python - youtube-dl, que permite baixar conteúdo de áudio ou vídeo, dependendo da tarefa necessária.
O AudioSet representa um cluster dividido em três conjuntos: conjunto de dados de teste, treinamento (balanceado) e treinamento (desbalanceado).
Vamos examinar esse cluster e analisar cada um desses conjuntos separadamente para ter uma idéia das classes contidas.
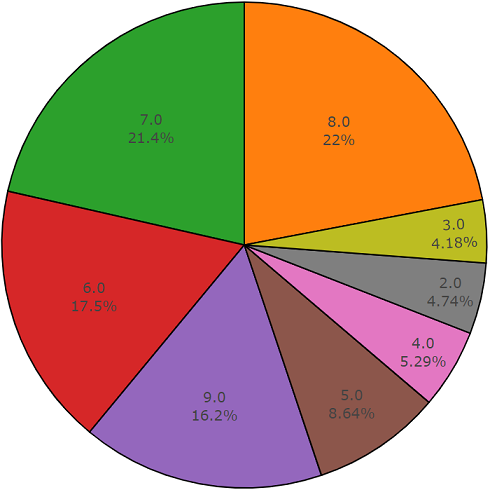
Treinamento (equilibrado)De acordo com a documentação, esse conjunto de dados consiste em
22.176 segmentos obtidos de vários vídeos selecionados por palavras-chave, fornecendo a cada classe pelo menos 59 cópias. Se observarmos a densidade de distribuição das classes raiz na hierarquia do conjunto, veremos que a classe Music é o maior grupo de arquivos de áudio.
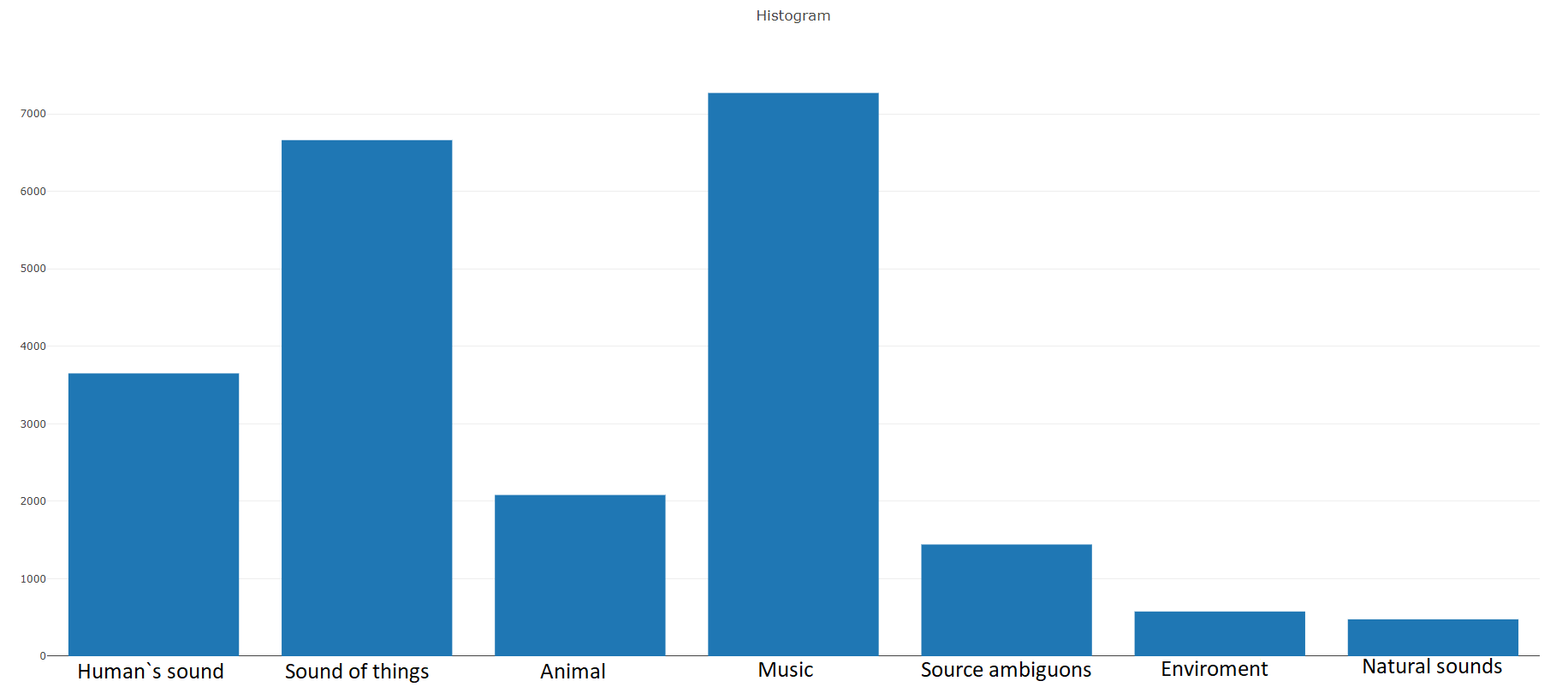
As classes organizadas são decompostas em subconjuntos de classes, permitindo obter informações mais detalhadas ao usá-las. Esse conjunto de treinamento equilibrado possui uma densidade de distribuição na qual fica claro que o equilíbrio está presente, mas também as classes individuais são muito distintas da visão geral.
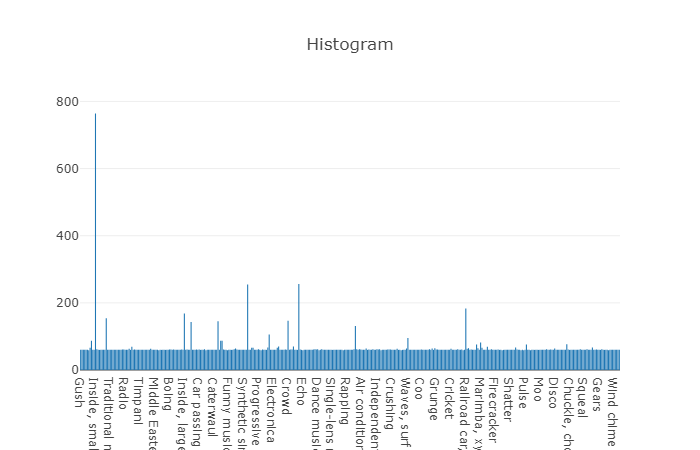
A distribuição de classes cujo número de elementos excede o valor médio
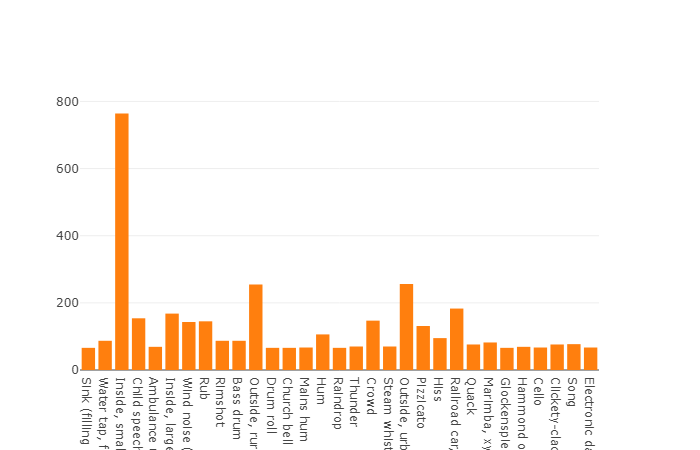
A duração média de cada um dos arquivos de áudio é de 10 segundos. Informações mais detalhadas são apresentadas no diagrama de disco, que mostra que a duração de alguns arquivos difere do conjunto principal. Este gráfico também é apresentado.
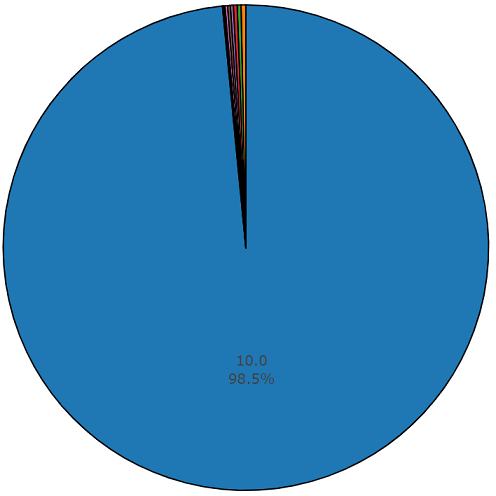
Diagrama de duração não média de um por cento e meio por cento de um conjunto de audioset equilibrado
 Treinamento (desequilibrado)
Treinamento (desequilibrado)A vantagem desse conjunto de dados é seu tamanho. Imagine que, de acordo com a documentação, este conjunto inclua 2.042.985 segmentos e, em comparação com conjuntos de dados balanceados, represente grande variabilidade, mas a entropia desse conjunto é muito maior.
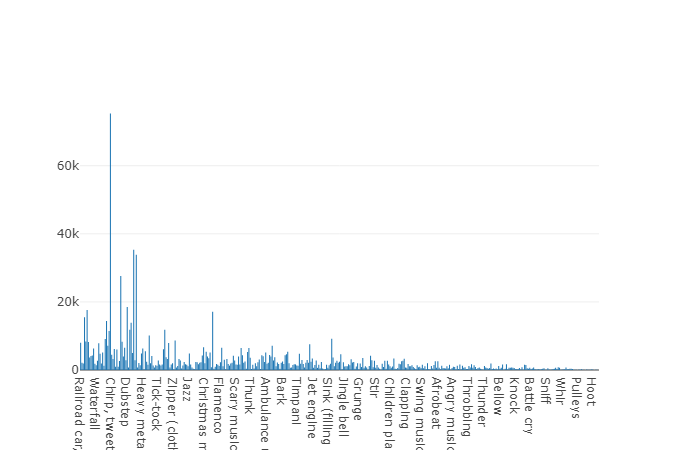
Neste conjunto, a duração média de cada um dos arquivos de áudio também é igual a 10 segundos, o diagrama do disco para este conjunto de dados é apresentado abaixo.
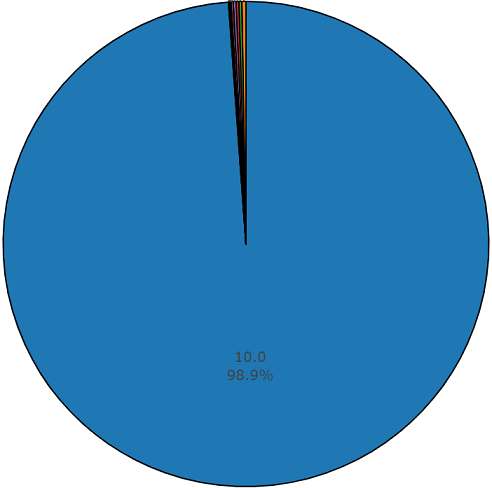
Gráfico de duração não média de um conjunto de audioset desequilibrado
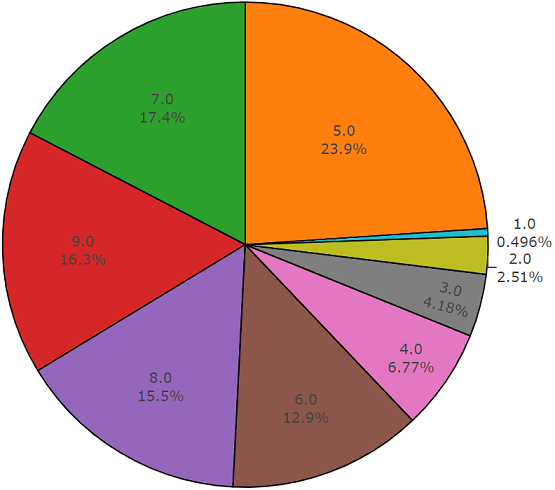 Conjunto de teste
Conjunto de testeEste conjunto é muito semelhante a um conjunto equilibrado, com a vantagem de que os elementos desses conjuntos não se cruzam. Sua distribuição é apresentada abaixo.
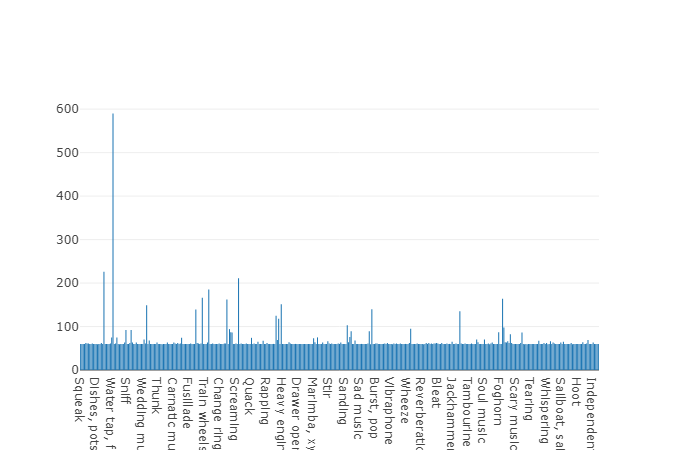
A distribuição de classes cujo número de elementos excede o valor médio
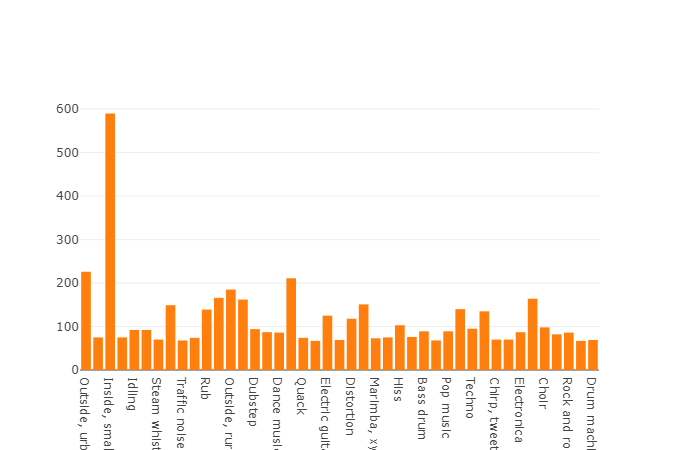
A duração média de um segmento desse conjunto de dados também é igual a 10 segundos
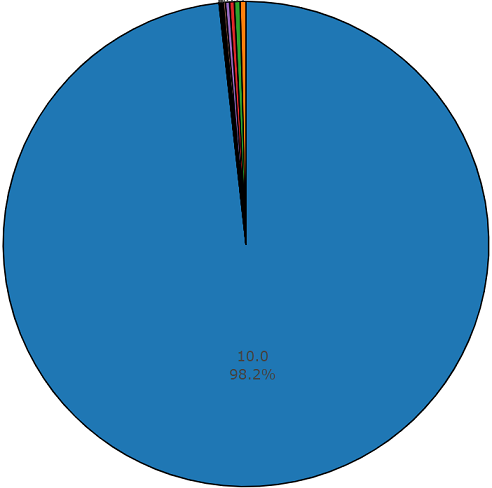
e o restante tem a duração mostrada no diagrama de disco
Exemplo de código para análise e download de dados acústicos de acordo com o conjunto de dados selecionado:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
Para obter informações mais detalhadas sobre a análise dos dados do audioset ou fazer upload desses dados do espaço yotube de acordo com o
arquivo de ontologia e o
conjunto selecionado
de audioset , o código do programa está disponível gratuitamente
no repositório GitHub .
urbansound
Urbansound é um dos maiores conjuntos de dados com eventos sonoros marcados, cujas classes pertencem ao ambiente urbano. Esse conjunto é chamado taxonômico (categórico), ou seja, cada classe é dividida em suas subclasses. Essa multidão pode ser representada como uma árvore.
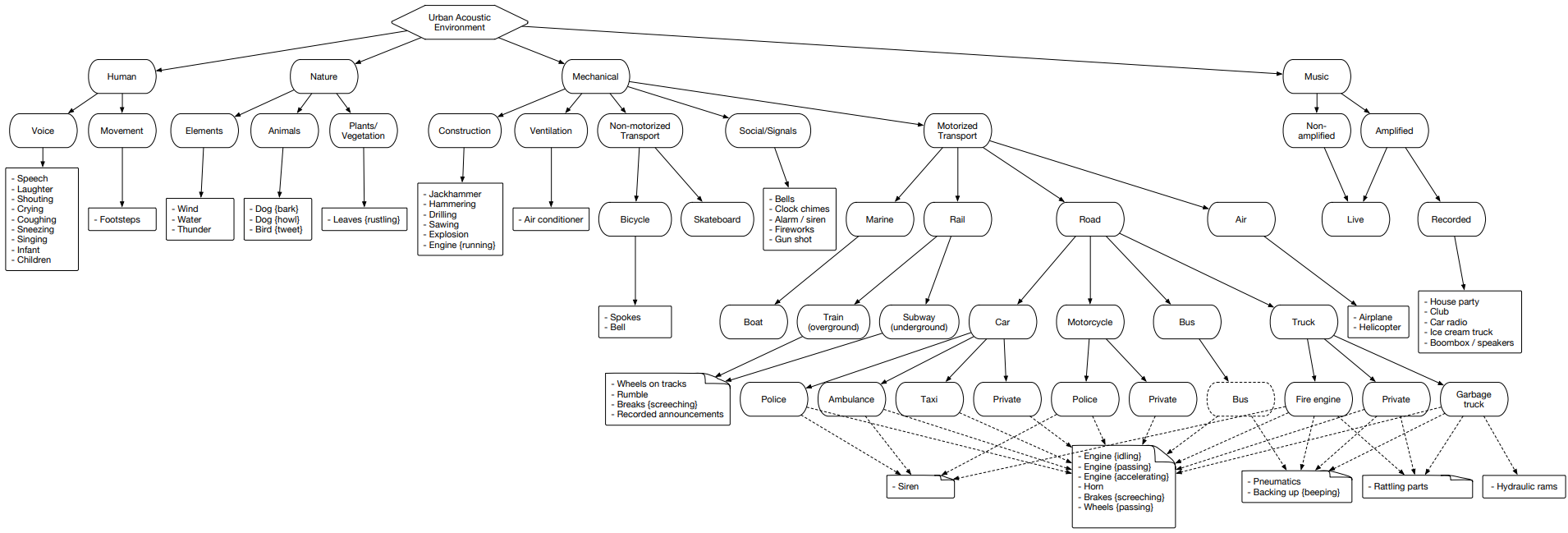
Para fazer upload de dados de som urbano para uso posterior, basta ir à página e clicar em
download .
Como a tarefa não precisa usar todas as subclasses e apenas uma classe é necessária associada ao carro, é necessário primeiro filtrar as classes necessárias usando o metarquivo localizado na raiz do diretório obtido ao descompactar o arquivo baixado.
Depois de descarregar todos os dados necessários das fontes listadas, acabou formando um conjunto de dados contendo mais de 15.000 arquivos. Esse volume de dados nos permite passar à tarefa de treinar o classificador acústico, mas ainda resta uma questão não resolvida em relação à "pureza" dos dados, ou seja, O conjunto de treinamento inclui dados não relacionados às classes necessárias do problema que está sendo resolvido. Por exemplo, ao ouvir arquivos da classe "quebra de vidro", você pode encontrar pessoas falando sobre "como não é bom quebrar o vidro". Portanto, somos confrontados com a tarefa de filtrar dados e, como uma ferramenta para resolver esse tipo de problema, uma ferramenta é perfeitamente adequada, cujo núcleo foi desenvolvido por caras da Bielorrússia e recebeu o nome estranho "Yandex.Toloka".
Yandex.Toloka
O Yandex.Toloka é um projeto de crowdfunding criado em 2014 para marcar ou coletar uma grande quantidade de dados para uso posterior no aprendizado de máquina. De fato, esta ferramenta permite coletar, marcar e filtrar dados usando um recurso humano. Sim, este projeto não apenas permite resolver problemas, mas também permite que outras pessoas ganhem dinheiro. O ônus financeiro nesse caso recai sobre seus ombros, mas devido ao fato de mais de 10.000 tolkers agirem por parte dos artistas, os resultados do trabalho serão recebidos em um futuro próximo. Uma boa descrição do funcionamento dessa ferramenta pode ser encontrada no
blog Yandex .
Em geral, o uso do esmagamento não é particularmente difícil, pois a publicação de uma tarefa requer apenas registro no
site , um valor mínimo de 10 dólares americanos e uma tarefa executada corretamente. Como formular corretamente uma tarefa, você pode ver a
documentação do
Yandex.Tolok ou não há um
artigo ruim
sobre o Habr . De mim mesmo a este artigo, quero acrescentar que, mesmo que um modelo adequado ao requisito da sua tarefa esteja ausente, seu desenvolvimento levará mais do que algumas horas de trabalho, com uma pausa para café e cigarro, e os resultados dos artistas poderão ser obtidos até o final do dia útil.
ConclusãoNo aprendizado de máquina, ao resolver o problema de classificação ou regressão, uma das principais tarefas é desenvolver um conjunto de dados confiável - um conjunto de dados. Neste artigo, foram consideradas fontes de informação com uma grande quantidade de dados acústicos que permitiram formar e equilibrar o conjunto de dados necessário para uma tarefa específica. O código do programa apresentado nos permite simplificar a operação de upload de dados ao mínimo, reduzindo assim o tempo para receber dados e gastar o restante no desenvolvimento de um classificador.
Quanto à minha tarefa, depois de coletar dados de todas as fontes apresentadas neste artigo e subsequente filtragem dos dados, consegui formar o conjunto de dados necessário para o treinamento do classificador acústico, que é baseado em uma rede neural. Espero que este artigo permita que você e sua equipe economizem tempo e gastem no desenvolvimento de novas tecnologias.
PS Um módulo de software desenvolvido em python, para análise e upload de dados acústicos para cada uma das fontes apresentadas, você pode encontrar no
repositório do github