
Esta postagem é uma tradução do
artigo original
de Paid Nidrinhouse, engenheiro de software de pilha completa. Sua principal especialidade é o JavaScript, mas Paige também estuda outras linguagens e estruturas. E ele compartilha sua experiência com seus leitores. A propósito, o artigo será interessante para iniciantes.
Recentemente, me deparei com uma tarefa que me interessava - era necessário extrair certos dados do enorme volume de arquivos não estruturados da Comissão Federal de Eleições dos EUA. Como não trabalhei muito com dados brutos, decidi aceitar o desafio e assumir essa tarefa. Como ferramenta para resolvê-lo, escolhi o Node.js.
A Skillbox recomenda: O curso on-line Profissão Frontend Developer .
Lembramos que: para todos os leitores de "Habr" - um desconto de 10.000 rublos ao se inscrever em qualquer curso Skillbox usando o código promocional "Habr".
A tarefa foi descrita em quatro pontos:
- O programa deve calcular o número total de linhas no arquivo.
- Cada oitava coluna contém o nome de uma pessoa. Você precisa carregar esses dados e criar uma matriz com todos os nomes contidos no arquivo. É necessário exibir o nome 432º e 43,243º.
- Cada quinta coluna contém a data da doação pelos voluntários. Conte quantas doações totais são feitas a cada mês e imprima o resultado total.
- Cada oitava coluna contém o nome de uma pessoa. Crie uma matriz selecionando apenas o primeiro nome, sem o sobrenome. Descubra qual nome é encontrado com mais frequência e quantas vezes?
(A tarefa original pode ser
visualizada aqui neste link .)
O arquivo com o qual você precisa trabalhar é um .txt regular de 2,55 GB. Há também uma pasta que contém partes do arquivo principal (você pode depurar o programa nelas sem precisar analisar toda a enorme variedade).
Duas soluções possíveis no Node.js
Em princípio, trabalhar com arquivos grandes não assusta um especialista em JavaScript. Além disso, esta é uma das principais funções do Node.js. Existem várias soluções possíveis para ler e gravar em arquivos.
O familiar é fs.readFile (). Ele permite que você leia o arquivo inteiro, coloque-o na memória e use o Node.
Uma alternativa é fs.createReadStream (), uma função que transmite dados semelhantes à forma como são organizados em outras linguagens - por exemplo, em Python ou Java.
A solução que eu escolhi
Como eu precisava calcular o número total de linhas e analisar os dados para analisar nomes e datas, decidi parar na segunda opção. Aqui eu poderia usar a função rl.on ('line', ...) para obter os dados necessários a partir das linhas.
Código Node.js CreateReadStream () e ReadFile ()
Abaixo está o código que escrevi usando o Node.js e a função fs.createReadStream ().
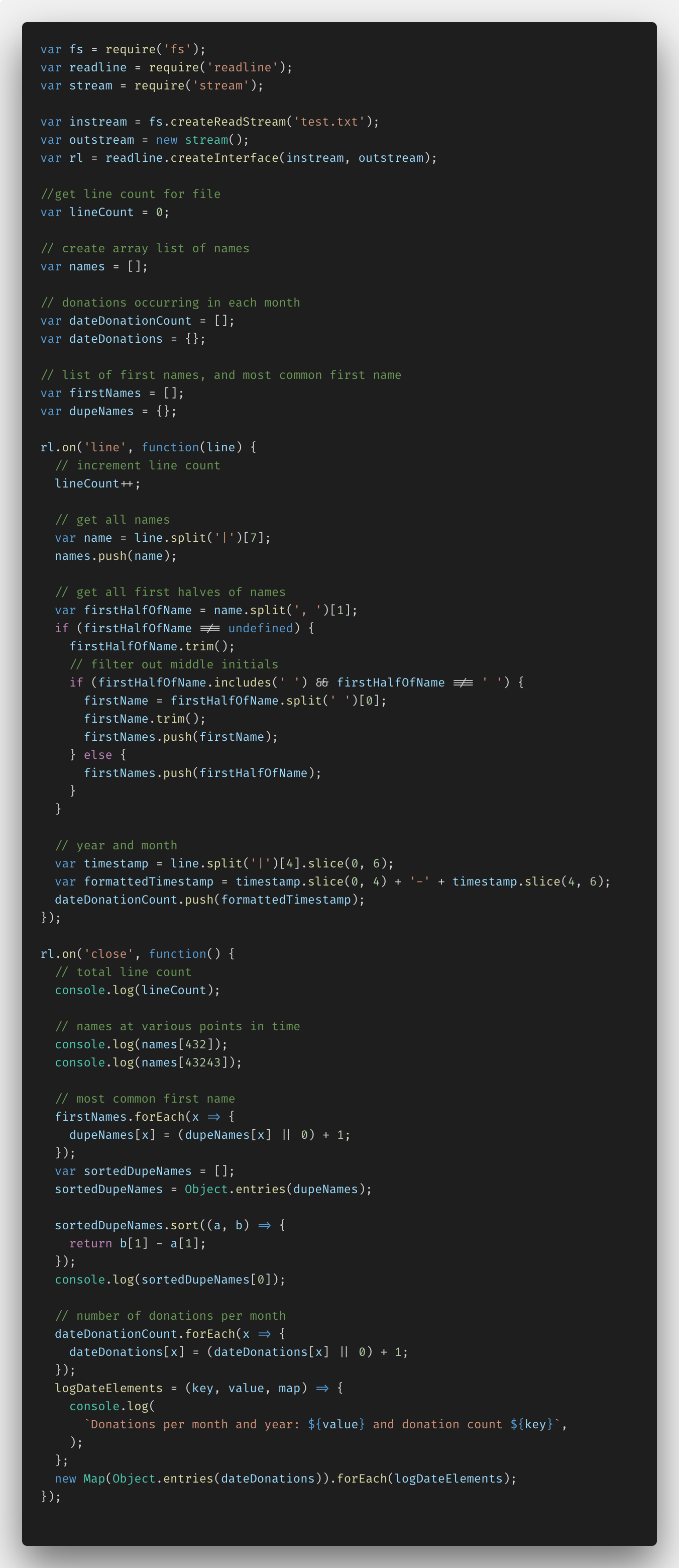
Inicialmente, eu precisava configurar tudo, percebendo que a importação de dados requer funções do Node.js. como fs (sistema de arquivos), linha de leitura e fluxo. Em seguida, consegui criar um fluxo interno e um fluxo externo junto com readLine.createInterface (). O código resultante tornou possível analisar o arquivo linha por linha, levando os dados necessários.
Além disso, adicionei várias variáveis e comentários para trabalhar com dados específicos. Estes são lineCount, dupeNames e matrizes de nomes, doação e firstNames.
Na função rl.on ('line', ...), consegui definir a análise de arquivos linha por linha. Então, entrei na variável lineCount para cada linha. Usei o método JavaScript split () para analisar nomes adicionando-os à minha matriz de nomes. Em seguida, separei apenas nomes sem sobrenome, destacando exceções, como a presença de nomes duplos, iniciais no meio do nome etc. Em seguida, separei o ano e a data da coluna de dados, convertendo tudo isso no formato AAAA-MM e adicionando o dateDonationCount à matriz.
Na função rl.on ('close', ...), realizei todas as transformações dos dados adicionados às matrizes, com as informações recebidas no console.log.
lineCount e nomes são necessários para determinar os nomes 432 e 43 433; não são necessárias conversões aqui. Mas a identificação do nome mais comum na matriz e a determinação do número de doações são tarefas mais complicadas.
Para identificar o nome mais comum, tive que criar um objeto de pares de valores para cada nome (chave) e o número de referências a Object.entries (). (valor) e depois converta tudo isso em uma matriz de matrizes usando a função ES6. Depois disso, a tarefa de classificar nomes e identificar os mais duplicados não era mais difícil.
Com as doações, fiz o mesmo truque: criei um objeto de pares de valores e a função logDateElements (), que me permitiu, usando a interpolação ES6, exibir as chaves e os valores de cada mês. Em seguida, criei o novo Map (), convertendo o objeto dateDonations em um metamarray e passei por cada matriz usando logDateElements (). (Acabou não sendo tão simples como parecia no começo.)
Mas funcionou, consegui ler um arquivo relativamente pequeno de 400 MB, destacando as informações necessárias.
Depois disso, tentei fs.createReadStream () - implementei a tarefa em fs.readFile () para ver a diferença. Aqui está o código:
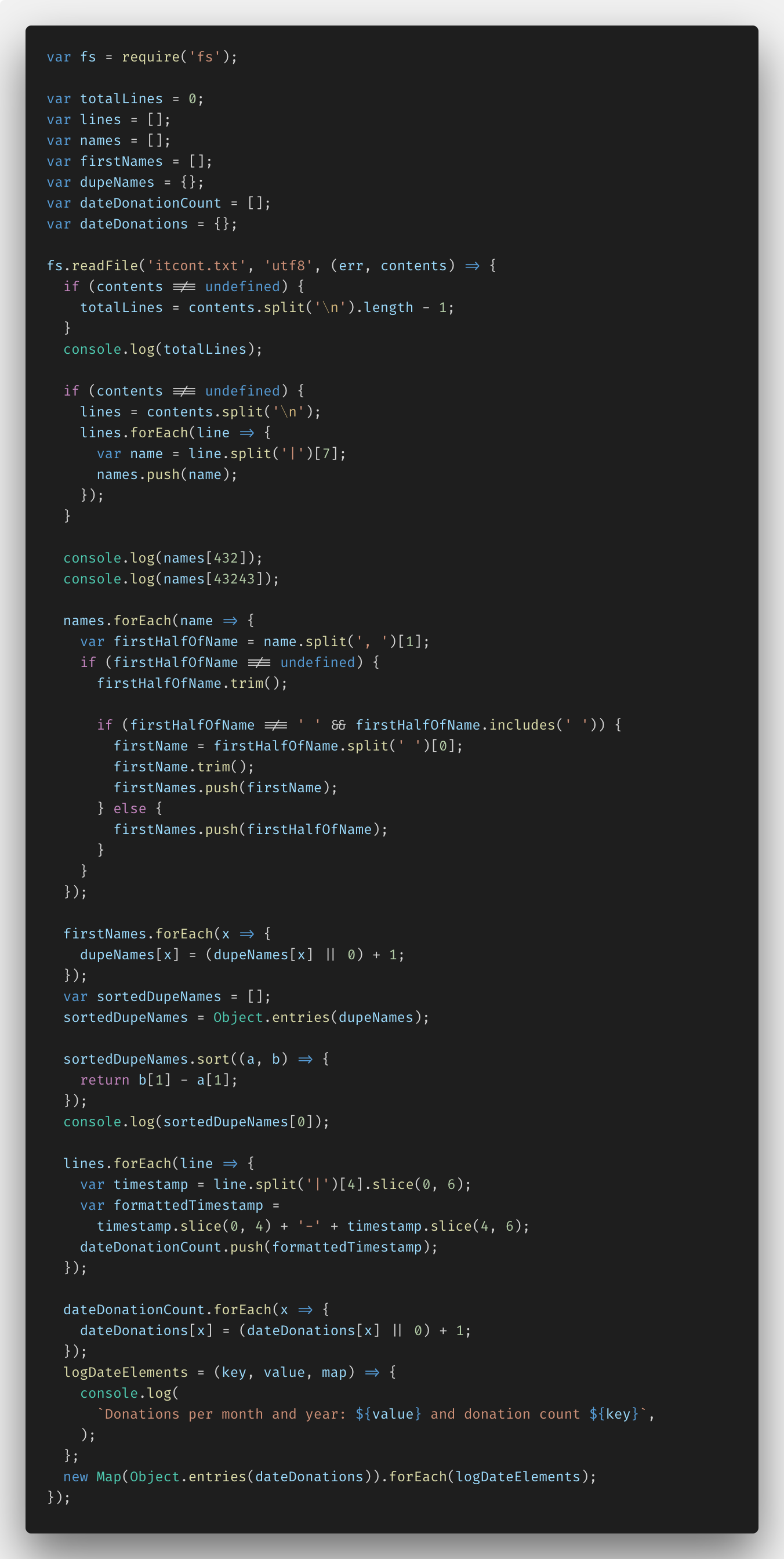
Você pode ver toda a solução
aqui .
Resultados do trabalho com Node.js
A solução acabou funcionando. Adicionei o caminho ao arquivo readFileStream.js e ... assisti o servidor Node travar com um erro de falta de memória na pilha do JavaScript.

Aconteceu que, embora tudo funcionasse, mas essa solução tentou transferir todo o conteúdo do arquivo para a memória, o que era impossível com uma capacidade de 2,55 GB. O Node pode trabalhar simultaneamente com 1,5 GB de memória, não mais.
Portanto, nenhuma das minhas decisões surgiu. Foi preciso um novo que pudesse funcionar mesmo com esses arquivos volumosos.
Nova solução
Como se viu, era necessário usar o popular módulo NPM EventStream.
Tendo estudado a documentação, pude entender o que precisa ser feito. Aqui está a terceira versão do código do programa.

A documentação do módulo indicava que o fluxo de dados deve ser dividido em elementos separados usando o caractere \ n no final de cada linha do arquivo txt.
Basicamente, a única coisa que tive que mudar foi a resposta dos nomes. Não pude colocar 130 milhões de nomes na matriz - o erro de falta de memória apareceu novamente. Resolvi o problema calculando os nomes 432 e 43 433 e os adicionando à minha própria matriz. Um pouco, não o que foi pedido nas condições, mas quem disse que você não pode ser criativo?
Rodada 2. Tentamos o programa no trabalho
Sim, todo o mesmo arquivo com um volume de 2,55 GB, cruzamos os dedos e seguimos o resultado.
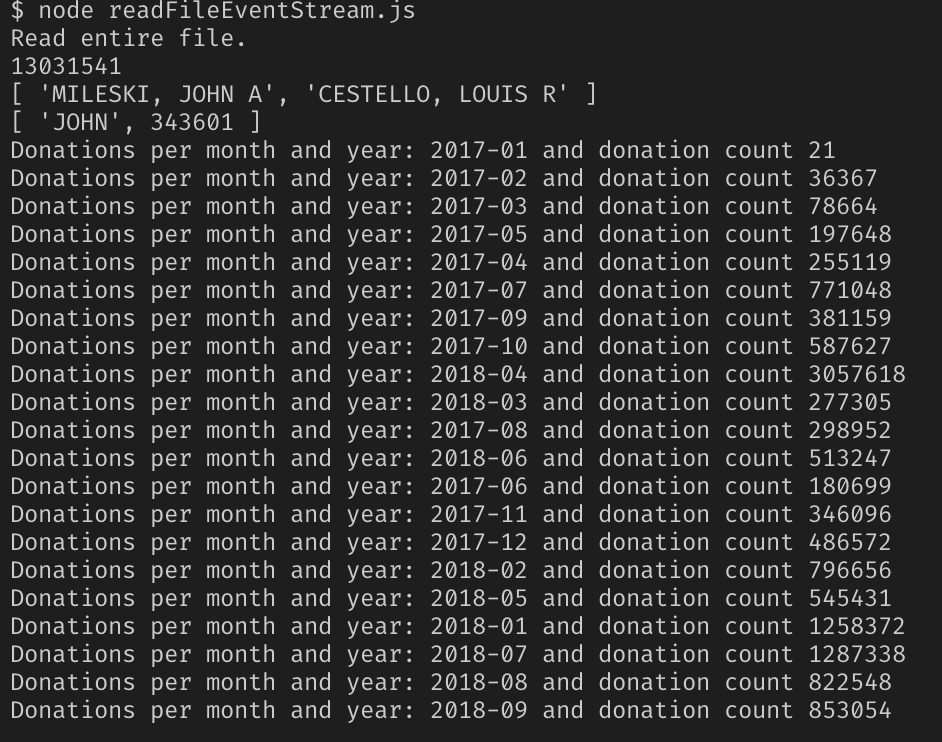
Sucesso!
Como se viu, apenas o Node.js não é adequado para resolver esses problemas, seus recursos são um pouco limitados. Mas expandindo-os usando módulos, você pode trabalhar com arquivos tão grandes.
A Skillbox recomenda: